Download presentation
1
SPSS 軟體與統計應用 Ya-Yun Cheng, How-Ran Guo 2014.03.25
Department of Environmental and Occupational Health, NCKU

2
製造一篇PAPER所需要的統計方法…

3
Outline 第一章 編碼與變數檢視 第二章 資料轉換 (計算、變更) 第三章 資料的合併與篩選與分割
第一章 編碼與變數檢視 第二章 資料轉換 (計算、變更) 第三章 資料的合併與篩選與分割 第四章 敘述統計量 (平均值、最大小、變異) 第五章 平均數檢定 (T-test, ANOVA) 第六章 類別檢定 (Chi-square test) 第七章 迴歸分析 (線性、邏輯式) 第八章 統計圖 (Graphs)-箱形圖 ROC curve
 第三章 資料的合併與篩選與分割. 第四章 敘述統計量 (平均值、最大小、變異) 第五章 平均數檢定 (T-test, ANOVA) 第六章 類別檢定 (Chi-square test) 第七章 迴歸分析 (線性、邏輯式) 第八章 統計圖 (Graphs)-箱形圖 ROC curve.")
4
第一章 編碼與變數檢視

5
資料視窗.sav 資料編輯視窗 變數檢視視窗

6
結果視窗 .spv

7
進入SPSS之前的準備工作 編碼 輸入 1-1 數據資料的形式: 矩陣式數據要求每一個橫行代表一筆觀察值, 縱列按變數排列;成為矩陣格式。

8
1-2 編碼的概念: 根據一定的規格將研究資料轉換成可進行統計分析的數碼資料過程 問題:您以為外勞對於台北市的社會秩序是否有影響?(單選) 1□有很大影響 2□有較大影響 3□影響很小 □沒有影響 4 答案 編碼

9
資料編輯視窗 選項數值說明 小數 變項說明 對齊 寬度 遺漏值 測量尺度 類型 欄 變項名稱

10
1-3 變數檢視(Variable View) *名稱(Name) 設定變數名稱,在資料檢視視窗會呈現var1、var2,可經由變數
檢是視窗做更改,但是變數命名有其原則,如下所示: 變數名第一個字必須為英文字(a~z),其後面才可以連接數字(0~9)、英 變數命名最後一個字絕對不能是句點 變數名稱的長度不可超過8個位元(一個中文字為2位元) 空白字或特殊字元(如 !、?、* )嚴禁使用 每個變數命名必須唯一性,不能有兩個相同變數名 英文大小寫命名皆相同 SPSS的保留字不能當變數名稱,如:ALL NE EQ TO LE LT BY OR GT GE AND NOT WITH
,其後面才可以連接數字(0~9)、英. 變數命名最後一個字絕對不能是句點. 變數名稱的長度不可超過8個位元(一個中文字為2位元) 空白字或特殊字元(如 !、 、* )嚴禁使用. 每個變數命名必須唯一性,不能有兩個相同變數名. 英文大小寫命名皆相同. SPSS的保留字不能當變數名稱,如:ALL NE EQ TO LE LT BY OR GT GE AND NOT WITH.")
11
數字 Numeric:數值型變數,其數值可以正、負號 逗點 Comma:三位一小撇之貨幣符號 點 Dot:其數值前面可有正、負符號當前導字,
*類型(Type) 在此敲擊滑鼠左鍵,即跳出變數類型的對話框 數字 Numeric:數值型變數,其數值可以正、負號 逗點 Comma:三位一小撇之貨幣符號 點 Dot:其數值前面可有正、負符號當前導字, 並以一個逗號當小數點,其餘逗點當三位一小撇之貨幣符號 科學記號 Scientific notation:變數為數值且以科學記號表現 日期 Date:其有效值可以是日期and/or時間 貨幣 Dollar:變數為金額,包括$符號 自定貨幣 Custom currency:變數為金額,以自定格式顯示 字串 String:可用任何中文或英文字母 字元;可自行設定,但是必須注意一個中文字母為2位元
 在此敲擊滑鼠左鍵,即跳出變數類型的對話框. 數字 Numeric:數值型變數,其數值可以正、負號. 逗點 Comma:三位一小撇之貨幣符號. 點 Dot:其數值前面可有正、負符號當前導字, 並以一個逗號當小數點,其餘逗點當三位一小撇之貨幣符號. 科學記號 Scientific notation:變數為數值且以科學記號表現. 日期 Date:其有效值可以是日期and/or時間. 貨幣 Dollar:變數為金額,包括$符號. 自定貨幣 Custom currency:變數為金額,以自定格式顯示. 字串 String:可用任何中文或英文字母. 字元;可自行設定,但是必須注意一個中文字母為2位元.")
12
點選,即出現Value Labels畫面,即可進行編輯
*寬度(Width) 變數資料內容實際位元長度 *小數(Decimal) 變數內容的小數位數 *註解(Label) 變數內容的註解說明,最大為120個位元 *數值(Value) 給原始值一個標註,最大為60個位元 在此敲擊滑鼠左鍵,即跳出變數類型的對話框 點選,即出現Value Labels畫面,即可進行編輯 【範例】以「性別」這個變數為例 Step1:數值(U)空格中鍵入「1」 Step2:數值註解(E)空格中鍵入「M-男性」 Step3:點選新增(A)按鈕 Step4:數值(U)空格中鍵入「0」 Step5:數值註解(E)空格中鍵入「F-女性」 Step6:點選確定後即完成
 變數資料內容實際位元長度. *小數(Decimal) 變數內容的小數位數. *註解(Label) 變數內容的註解說明,最大為120個位元. *數值(Value) 給原始值一個標註,最大為60個位元. 在此敲擊滑鼠左鍵,即跳出變數類型的對話框. 點選,即出現Value Labels畫面,即可進行編輯. 【範例】以「性別」這個變數為例. Step1:數值(U)空格中鍵入「1」 Step2:數值註解(E)空格中鍵入「M-男性」 Step3:點選新增(A)按鈕. Step4:數值(U)空格中鍵入「0」 Step5:數值註解(E)空格中鍵入「F-女性」 Step6:點選確定後即完成.")
13
*遺漏(Missing) 用來定義遺失值,若變數為數值變數,則系統預設為None,表不設定使 用遺失值以空白代表 *欄(Columns) 編輯視窗中變數顯現出來欄位寬度 *對齊(Align) 輸入內容的對齊方式,分為置左對齊、置中對齊、置右對齊,系統預設 為置右對齊

14
第二章 資料轉換

15
2-1 新觀察值的計算 設定目標變數之名稱 設定目標變數之數值運算式 舊有變數 計算按鍵台 SPSS 內建函數

16
內建函數 算數函數─ 統計函數─ ABS():取絕對值 SUM():求運算式總和 RND():取四捨五入 MEAN():求運算式平均數
TRUNC():截去小數位數 MOD(X,Y):將X除以Y後取其餘數 SQRT():開根號 EXP():取自然指數函數 LG10():取以10為底之對數函數 LN():取以EXP(1)為底之對數函數 ARSIN():取反正弦函數 ARTAN():取反正切函數 SIN():取正弦函數 COS():取餘弦函數 統計函數─ SUM():求運算式總和 MEAN():求運算式平均數 SD():求運算式標準差 VARIANCE():求運算式變異數 CFVAR():求運算式變異係數 MIN():求運算值的最小值 MAX():求運算值的最大值
:截去小數位數. MOD(X,Y):將X除以Y後取其餘數. SQRT():開根號. EXP():取自然指數函數. LG10():取以10為底之對數函數. LN():取以EXP(1)為底之對數函數. ARSIN():取反正弦函數. ARTAN():取反正切函數. SIN():取正弦函數. COS():取餘弦函數. 統計函數─ SUM():求運算式總和. MEAN():求運算式平均數. SD():求運算式標準差. VARIANCE():求運算式變異數. CFVAR():求運算式變異係數. MIN():求運算值的最小值. MAX():求運算值的最大值.")
17
【範例】由於國文成績過低,所以設定原始成績開根號 且乘以10之後為最後國文成績
【範例】由於國文成績過低,所以設定原始成績開根號 且乘以10之後為最後國文成績 Step1:轉換→計算 Step2 Step3 執行step1~step3出來的結果

18
2-1-2 計算日期與年齡

19
2-2 重新編碼- 將已存在的數值變數或短字串變數的值加以重新編碼
2-2 重新編碼- 將已存在的數值變數或短字串變數的值加以重新編碼 Step1:轉換→重新編碼→成不同變數

20
Step2:把「性別」移至 數值變數(V)->輸出變數框中
Step3:設定輸出之新變數的名稱→變更(C)→舊值與新值(O)
→舊值與新值(O)")
21
Step4:先勾選 輸出變數為字串(B)→ 舊值數值框中鍵入1→新值數值鍵入male→新增(A) 舊值數值框中鍵入2→新值數值鍵入female→新增(A) →繼續→確定
→ 舊值數值框中鍵入1→新值數值鍵入male→新增(A) 舊值數值框中鍵入2→新值數值鍵入female→新增(A) →繼續→確定")
22
執行Step1~Step4的結果

24
Because the arsenic levels were divided into three categories, two dummy variables
p=0.001 p=0.001 p=0.001

25
第三章 資料的合併與篩選與分割 (Merge & Select & Cut)
")
26
3-1 資料檔之合併(Merge) 【範例】兩個資料檔做水平合併
Step1:資料→合併檔案→新增變數

27
Step2:匯入資料2檔案 Step3:按確定即可。 SPSS自動將兩個檔案有不同的變數名稱放在右邊的
框中,左邊的框中有「姓名」是因為兩個檔案皆有姓名這個變數, 所以在合併檔案的過程將其排除

28
3-1 資料檔之合併(Merge) 【範例】多對多合併 *(排序、寬度 一致)*
 【範例】多對多合併 *(排序、寬度 一致)*")
29
3-1 資料檔之合併(Merge) 【範例】多對多合併 *(以小博大)*
 【範例】多對多合併 *(以小博大)*")
30
3-2資料之篩選(Select) 【範例】篩選後只留下性別為男性的觀察值
Step1:資料→選擇觀察值

31
Step2:點選如果滿足設定條件(C)→若(I)
→若(I)")
32
Step3:把「性別」移至右邊框中並且運算=1,
此代表我們只挑選當性別為1時的觀察值

33
執行Step1~Step3的結果,發現第5、7、10比的觀察值
已被暫時刪除,當跑其他分析時並不會讀到這三筆觀察值, 換言之,只讀得到「性別」為男性的觀察值

34
3-2資料之篩選(Select)- 篩選資料另存新檔
- 篩選資料另存新檔")
35
3-3資料之分割(Cut)- 分割檔案、比較群組
- 分割檔案、比較群組")
36
第四章 敘述統計量 (Descriptive Statistics)
")
37
4-1 次數分配表(Frequencies) 目的:求得資料之次數分配表及一些特徵量數, 或繪製資料支圓餅圖、長條圖或直方圖等
點選:分析(A)→描述性統計(E)→次數分配表(F)
→描述性統計(E)→次數分配表(F)")
38
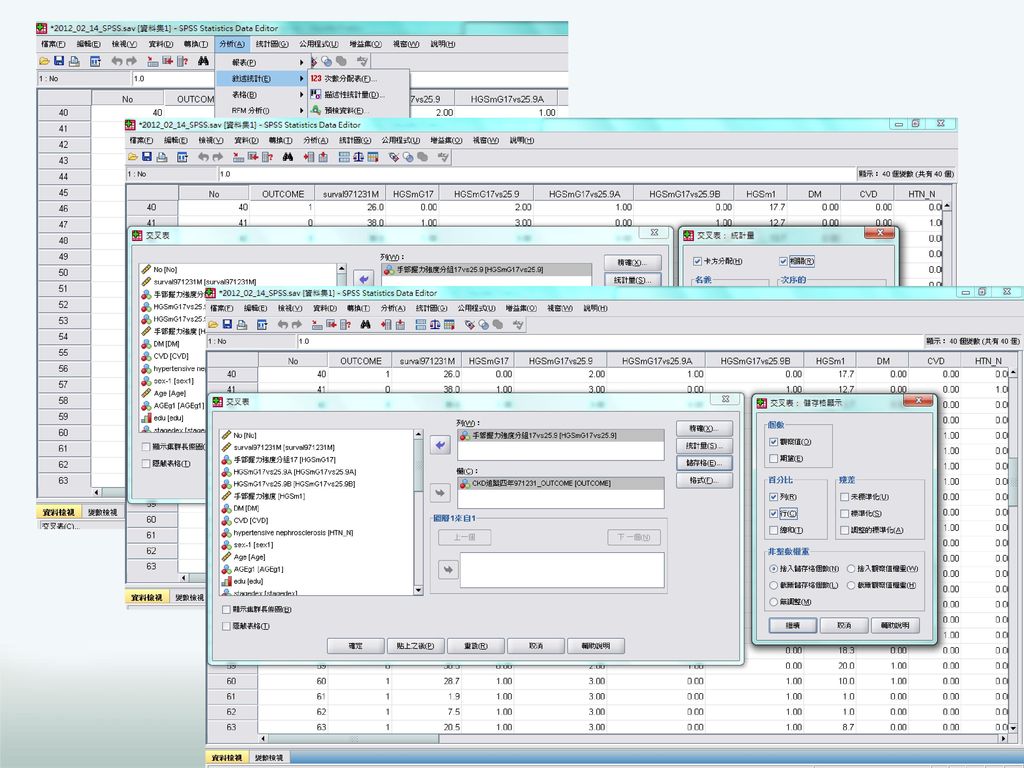
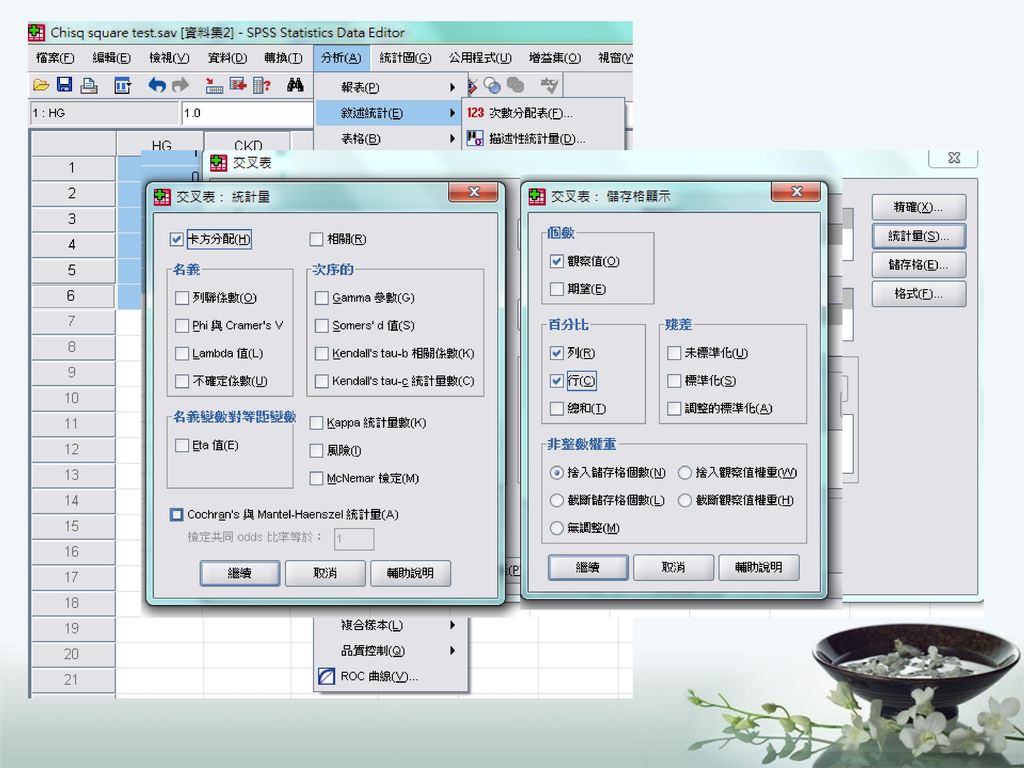
次數分配表裡有三個次指令,分別為 統計量(S)、圖表(C)、格式(F)
、圖表(C)、格式(F)")
39
圖表(C):其功能在執行所輸出之統計圖,SPSS提供長條圖(Bar charts)、 圓形圖(Pie charts)、直方圖(Histograms),其中直方圖還可進一 步界定SPSS印出常態分配曲線。而各圖形之呈現方式,可以 選擇次數(Frequencies)或百分比(Percentages) 格式(F):其功能在設定輸出報表之格式 順序依據(Order by):選擇資料呈現時排序的方式 多重變數(Multiple variance):若處理變數有多個時, 在列印統計量時, 選擇將多格變數列印在同一表 中以作比較,或分開列表
:其功能在設定輸出報表之格式. 順序依據(Order by):選擇資料呈現時排序的方式. 多重變數(Multiple variance):若處理變數有多個時, 在列印統計量時, 選擇將多格變數列印在同一表. 中以作比較,或分開列表.")
40
4-2 描述性統計量(Descriptive)
目的:可求得資料中之數值變數之敘述統計量 點選:分析(A)→描述性統計(E)→描述性統計量(D)
→描述性統計(E)→描述性統計量(D)")
41
【範例】計算英文成績的平均數、變異數、 偏態係數
Step1:分析(A)→描述性統計(E)→描述性統計量(D)
→描述性統計(E)→描述性統計量(D)")
42
Step2:將英文成績移至變數(V)框中→點選選項(O)
Step3:點選平均數(M)、變異數(V)、偏態(W)→點選繼續→確定
、變異數(V)、偏態(W)→點選繼續→確定.")
43
執行Step1~Step3的結果如下表 十個人英文成績平均為49分, 變異數為419.111代表成績差異大較分散,
偏態係數為-0.15代表這組資料為左偏

44
LINE Durbin-Watson (D-W) 來檢定有無自我一階相關的問題, 即殘差是否為獨立。
 來檢定有無自我一階相關的問題, 即殘差是否為獨立。")
45
柯-史兩樣本檢定(The Kolmogorov-Smirnov Test) 是將柯-史單一樣本檢定擴展使用,主要是檢定兩個獨立樣本的
累積觀察次數的分配是否一致。若是,則樣本可能來自同一個母體 反之,則否。 K-S檢定(Kolmogorov-Smirnov goodness-of-fit test). ▪ H0: 誤差項遵循常態分配. ▪ H1: 誤差項未遵循常態分配
. ▪ H0: 誤差項遵循常態分配. ▪ H1: 誤差項未遵循常態分配.")
47
第五章 均數檢定 (Compare Means)
")
48
【範例】現在想依「性別」作為分層之依據,求
5-1 分群之統計量(Means) 【範例】現在想依「性別」作為分層之依據,求 出男女生數學成績之平均數與變異數 Step1:分析(A)→比較平均數法(M)→平均數(M)
 【範例】現在想依「性別」作為分層之依據,求. 出男女生數學成績之平均數與變異數. Step1:分析(A)→比較平均數法(M)→平均數(M)")
49
Step2:將數學成績移至依變數清單(D),
將性別移至自變數清單(D)→點選選項(O)
→點選選項(O)")
50
Step3:將左邊的平均數與變異數移至右邊格統計量(C)框中 →繼續→確定
Step1~Step3即出現下表之結果 男性平均為66.14分,女性平均為44.67分, 整體來說男性數學成績比女性好, 此外,根據變異數可看出男性成績比起女性較為集中

51
5-2 單一母體平均數檢定 (One-Sample T Test)
【範例】檢定國文成績 :國文平均成績 50 Step1:分析(A)→比較平均數法(M)→單一樣本T檢定(S)
→比較平均數法(M)→單一樣本T檢定(S)")
52
Step2:將國文成績移至檢定變數(T)框中,檢定值(V)框
中輸入50→點選選項(O) Step3: 信賴區間設定95% →繼續→確定
 Step3: 信賴區間設定95% →繼續→確定.")
53
執行Step1~Step3結果如下報表, 依據題意得知此題為單尾檢定, 判別t值=1.31 0,所以單尾P-Value=1- =0.8885。在顯著水準95%之下,不拒絕 ,國文成績 50

54
5-3 兩獨立母體平均數檢定(Independent-Sample T Test)
【範例】檢定男生與女生數學平均成績相等 Step1:分析(A)→比較平均數法(M)→獨立樣本T檢定(T)
→比較平均數法(M)→獨立樣本T檢定(T)")
55
Step2:將數學成績移至檢定變數(T)框中,
性別移至分組變數(G)框中→點選定義組別(D) Step3:組別1(1)鍵入1, 組別2(2)鍵入2→繼續→確定
框中→點選定義組別(D) Step3:組別1(1)鍵入1, 組別2(2)鍵入2→繼續→確定.")
56
執行Step1~Step3之後得到下表 由於平均數差異檢定有一個很重要的基本假設─變異數同質性, 因此進行T檢定前會先對二組樣本之變異數是否同質進行檢定。 下表左半部就是對二組樣本進行同質行性檢定的結果, F值為0.196(P-Value=0.67)不顯著,代表二組樣本變異數相等, 於是右半部的報表則看第一列的數據, 反之,變異數不相等則看右部第二列的數據。 此例題我們看第一列之數據,發現t值之P-Value值不顯著, 因此不拒絕,代表男生與女生數學平均相等
不顯著,代表二組樣本變異數相等, 於是右半部的報表則看第一列的數據, 反之,變異數不相等則看右部第二列的數據。 此例題我們看第一列之數據,發現t值之P-Value值不顯著, 因此不拒絕,代表男生與女生數學平均相等.")
57
PAIRE T TEST

58
ANOVA test

60
第六章 類別卡方檢定

63
無原始數據情況下

65
Chisq square for trend test in SAS data b; input exposure disease no;
cards; 0 0 6 0 1 38 1 0 7 1 1 34 2 0 13 2 1 30 ; proc print; run; proc freq; weight no; table exposure * disease / chisq trend; run; proc logistic; class exposure (REF='0')/PARAM=REF; model disease (EVENT='1')=exposure /RISKLIMITS;
/PARAM=REF; model disease (EVENT= 1 )=exposure /RISKLIMITS;")
66
第七章 迴歸分析檢定

67
SEX變數p<0.001 βSEX=11.474 95%CI=8.634~14.314

68
HG變數p=0.059 OR=1.693 95%CI=0.981~2.925

69
Dummy var.

72
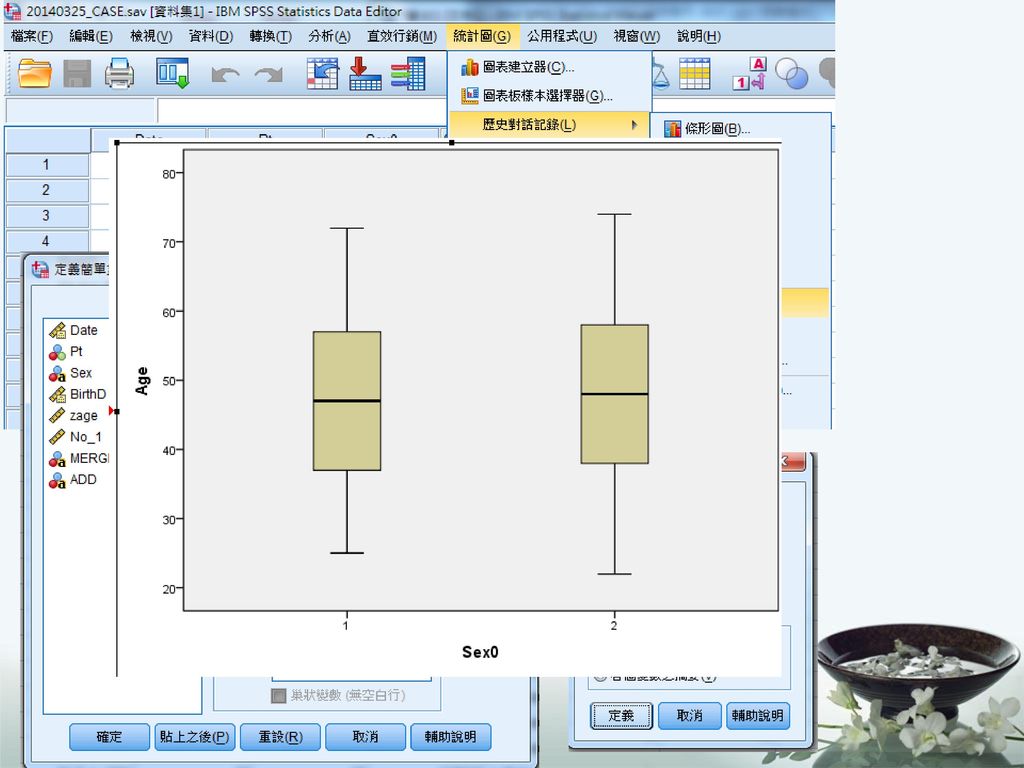
第八章 統計圖 (Graphs)- ROC curve 箱型圖 Box-Plot
- ROC curve 箱型圖 Box-Plot")
73
常用統計圖種類 10. 誤差條圖(error bar) 1. 莖葉圖(stem-and-leaf) 11. 散佈圖(scatter)
3. 折線圖(line) 4. 區域圖(area) 5. 圓餅圖(pie) 6. 高低圖(high-low) 7. 柏拉圖(Pareto) 8. 管制圖(control) 9. 箱型圖(boxplot) 10. 誤差條圖(error bar) 11. 散佈圖(scatter) 12. 直方圖(histogram) 13. P-P plot 14. Q-Q plot 15. sequence chart 16. ROC 曲線圖 17. 時間序列圖 統計圖 73
 4. 區域圖(area) 5. 圓餅圖(pie) 6. 高低圖(high-low) 7. 柏拉圖(Pareto) 8. 管制圖(control) 9. 箱型圖(boxplot) 10. 誤差條圖(error bar) 11. 散佈圖(scatter) 12. 直方圖(histogram) 13. P-P plot. 14. Q-Q plot. 15. sequence chart. 16. ROC 曲線圖. 17. 時間序列圖. 統計圖. 73.")
75
ROC 曲線在醫界研究 A B 傳統ROC分析已經廣泛使用於診斷評估測試中,但是它的限制在於分成兩個結果
用ROC曲線(Receiver Operating Characteristic Curve)來評估診斷測是在醫界已經行之多年;1971年,Lusted把ROC曲線的觀念引介給醫學界,指出ROC曲線是以「X軸與Y軸分別代表偽陽性(FPF)診斷與真陽性(TPF)診斷」的點狀圖 B 75
來評估診斷測是在醫界已經行之多年;1971年,Lusted把ROC曲線的觀念引介給醫學界,指出ROC曲線是以「X軸與Y軸分別代表偽陽性(FPF)診斷與真陽性(TPF)診斷」的點狀圖. B. 75.")
76
學者對ROC 曲線之研究與整理 1 2 3 ROC曲線下的面積做為診斷工具分辨能力的指標
這個面積(大於0,小於1)代表強迫二選一(two- alternative-forced-choice)的情形下,診斷工具猜對有病 者、無病者的機率 3 ROC曲線的用處之一,是提供研究者找出一個較好的反 折點(cut-off point),使診斷工具的敏感度與精確度能有合 理的平衡 76
代表強迫二選一(two- alternative-forced-choice)的情形下,診斷工具猜對有病. 者、無病者的機率. 3. ROC曲線的用處之一,是提供研究者找出一個較好的反. 折點(cut-off point),使診斷工具的敏感度與精確度能有合. 理的平衡. 76.")
77
ROC曲線 77

78
ROC曲線相關 傳統的ROC將測試結果分成兩類:Positive(陽性) and Negative(陰
性),如果測試結果的數值很接近陽性或陰性的邊界時,將會被 完全接受,或是拒絕 ROC認為"可以知道每一個人真實的檢驗結果"這個觀念為基礎, 一般稱之為黃金標準(Gold Standard)。但是在醫學上,一般認為 可以做為「黃金標準」的長期追蹤、組織切片檢查、造影攝影 術和屍體解剖,除了最後一項外,其他檢驗無法確定是絕對正 確,所以黃金標準又稱之為「參考標準」 黃金標準將受檢驗的人分為兩類:Diseased(有病)與Non- diseased(沒病),而黃金標準有時候並不是那麼精測的測試,所 以可以導入Fuzzy的觀念加以改進且說明 統計圖 78
,如果測試結果的數值很接近陽性或陰性的邊界時,將會被. 完全接受,或是拒絕. ROC認為 可以知道每一個人真實的檢驗結果 這個觀念為基礎, 一般稱之為黃金標準(Gold Standard)。但是在醫學上,一般認為. 可以做為「黃金標準」的長期追蹤、組織切片檢查、造影攝影. 術和屍體解剖,除了最後一項外,其他檢驗無法確定是絕對正. 確,所以黃金標準又稱之為「參考標準」 黃金標準將受檢驗的人分為兩類:Diseased(有病)與Non- diseased(沒病),而黃金標準有時候並不是那麼精測的測試,所. 以可以導入Fuzzy的觀念加以改進且說明. 統計圖. 78.")
79
ROC 曲線資料考量 檢定變數為數值變數; 它們通常是由判別分析的機率、logistic 迴歸、或任意尺度上的分數所組成,此尺度上會表示定等級者會落在某一類別或其他類別的「信賴強度」;狀態變數可以是任何類型的變數,但要指出受試者所屬的真實類別; 狀態變數的值會指出哪一個類別應視為正向 資料 假設等級者尺度上數值的增加,代表相信受試者屬於某類別的程度加深,則尺度上數值的減少,則代表相信受試者屬於其他類別的程度增加;使用者必須選擇正向; 同時假設已知各受試者屬於真的類別 假設 79

80
ROC 曲線選項 1 2 3 分類: 讓您指定在進行正向分類時,是否要加入或排除分割值 檢定方向:讓您指定與正向類別相關之尺度的方向
區域標準誤差的參數:讓您指定估計曲線下區域之標準誤的方法;可用的方法有非參數式 (nonparametric) 和雙負指數;同時您還可以設定信賴區間的等級。 有效範圍為 50.1% 到 99.9%。 統計圖 80
 和雙負指數;同時您還可以設定信賴區間的等級。 有效範圍為 50.1% 到 99.9%。 統計圖. 80.")
81
ROC 曲線在SPSS操作步驟 分析→ROC曲線 統計圖 81

82
ROC 曲線在SPSS操作步驟 選取欲檢定變數&狀態變數並設定狀態變數值 選定檢定方向&選擇雙負指數 勾選欲選取之項目 統計圖 82

83
ROC 曲線在SPSS輸出 統計圖 83

84
Thank you for your attention! ~ The END ~ Discussion (05/27) 實機操作分析實例
 實機操作分析實例")








 1 SPSS 的环境与基本操作.>")










 2015.06.27.>")



 电 话:>")


