Download presentation
1
理论联系实践 理论就是, 什么都懂,但什么都不会用 实践就是, 什么都不懂,却什么都会用 理论联系实践就是, 什么都不会用
而且还 什么都不懂

2
第六章 拟合优度检验 §6.1 卡方拟合优度检验 §6.2 列联表的独立性检验 §6.3 概率纸方法及正态性检验
§6.1 卡方拟合优度检验 §6.2 列联表的独立性检验 §6.3 概率纸方法及正态性检验 § Kolmogorov检验

3
§6.1 卡方拟合优度检验 6.1.1 分类数据的卡方拟合优度检验 我们先看一个在生物中很有名的例子。
§6.1 卡方拟合优度检验 分类数据的卡方拟合优度检验 我们先看一个在生物中很有名的例子。 在19世纪,Mendel按颜色与形状把豌豆分为四类:黄圆、青圆、黄皱和青皱。Mendel在他种的n=556个豌豆中,观测到这四类豌豆的个数分别为315,108,101,32.于是,Mendel判断这四类的比例为9:3:3:1.那Mendel的这种比例正确吗?

4
设总体X 可以分成k 类,记为 ,现对该总体作了n 次观测,k 个类出现的频数分别为:
n1,…,nk, 且 检验如下假设: 其中诸 且

5
如果H0 成立,则对每一类Ai,其频率ni /n与概率pi 应较接近。即观测频数ni 与理论频数npi 应相差不大。据此,英国统计学家K
如果H0 成立,则对每一类Ai,其频率ni /n与概率pi 应较接近。即观测频数ni 与理论频数npi 应相差不大。据此,英国统计学家K.Pearson提出如下检验统计量: (6.2) 并证明在H0 成立时对充分大的n, (6.2) 给出的检验统计量近似服从自由度为k-1的 分布。 拒绝域为:
 并证明在H0 成立时对充分大的n, (6.2) 给出的检验统计量近似服从自由度为k-1的 分布。 拒绝域为:")
6
例 为募集社会福利基金,某地方政府发 行福利彩票,中彩者用摇大转盘的方法确定 最后中奖金额。大转盘均分为20份,其中金 额为5万、10万、20万、30万、50万、100万 的分别占2份、4份、6份、4份、2份、2份。 假定大转盘是均匀的,则每一点朝下是等可 能的,于是摇出各个奖项的概率如下:

7
概率 0.1 0.2 0.3 额度 5万 10万 20万 30万 50万 100万 现20人参加摇奖,摇得5万、10万、20万、30万、50万和100万的人数分别为2、6、6、3、3、0,由于没有一个人摇到100万,于是有人怀疑大转盘是不均匀的,那么该怀疑是否成立呢?这就需要对转盘的均匀性作检验。

8
解:这是一个典型的分类数据卡方拟合优度检验,总体共有6类,其发生概率分别为0. 1、0. 2、0. 3、0. 2、0. 1和0
解:这是一个典型的分类数据卡方拟合优度检验,总体共有6类,其发生概率分别为0.1、0.2、0.3、0.2、0.1和0.1,这里k=6,检验拒绝域为: 若取 =0.05,则查表可知 由本例数据可以算出 =

9
由于 未落入拒绝域,故接受原假设, 没有理由认为转盘不均匀。 在分布拟合检验中使用p 值也是方便的。 本例中,以T 记服从 (5)的随机变量,则使用统计软件可以算出 这个p 值就反映了数据与假设的分布拟合程度的高低,p 值越大,拟合越好。

10
6.1.2 带有未知参数的卡方拟合优度检验 若诸 由r (r<k)个未知参数 确定,即 首先给出 的极大似然估计
带有未知参数的卡方拟合优度检验 若诸 由r (r<k)个未知参数 确定,即 首先给出 的极大似然估计 然后给出诸 的极大似然估计 Fisher证明了 在H0成立时近似服从自由度 为k-r-1的 分布,于是检验拒绝域为
个未知参数 确定,即. 首先给出 的极大似然估计. 然后给出诸 的极大似然估计. Fisher证明了. 在H0成立时近似服从自由度. 为k-r-1的 分布,于是检验拒绝域为.")
11
例 卢瑟福在2608个等时间间隔内观测一 枚放射性物质放射的粒子数X,表6.1是观测 结果的汇总,其中ni表示2608次观测中放射粒 子数为i的次数。 ni i 试利用该组数据检验该放射物质在单位时间内放射出的粒子数是否服从泊松分布。

12
解:本例中,要检验总体是否服从泊松分布。
观测到 0, 1, …, 11 共 12 个不同取值,这相当于把总体分成12类。这里有一个未知参数 ,采用极大似然估计, = 将 代入可以估计出诸 。 于是可计算出

13
列表如下。 1 2 3 4 5 6 7 8 9 10 11 57 203 383 525 532 408 273 139 45 27 0.0209 0.0807 0.1562 0.2015 0.1950 0.1509 0.0973 0.0538 0.0260 0.0112 0.0043 0.0022 54.5 210.5 407.4 525.5 508.6 393.5 253.8 140.3 67.8 29.2 11.2 5.7 0.1147 0.2672 1.4614 0.0005 1.0766 0.5343 1.4525 0.0120 7.6673 0.1658 0.1258 0.0158 合计 2608 1.0000 2068 = i

14
若取 =0.05,则 本例中 = <18.307,故接受原假设。使用统计软件可以计算出此处检验的p 值是0.2295。

15
§6.2 列联表的独立性检验 列联表是将观测数据按两个或更多属性 (定性变量) 分类时所列出的频数表。例如,对随机抽取的1000人按性别(男或女)及色觉(正常或色盲) 两个属性分类,得到如下二维列联表,又称2×2表或四格表。
 分类时所列出的频数表。例如,对随机抽取的1000人按性别(男或女)及色觉(正常或色盲) 两个属性分类,得到如下二维列联表,又称2×2表或四格表。")
16
男 535 65 女 382 18 性别 视觉 正常 色盲

17
一般,若总体中的个体可按两个属性A与B分类,A 有r 个类 ,B 有c个类
从总体中抽取大小为n的样本,设其中有 个个体既属于 类又属于 类, 称为频数,将rc个 排列为一个r行c列的二维列联表,简称rc表(表6.3)。
。")
18
表6.3二维列联表数据

19
列联表分析的基本问题是: 考察各属性之间有无关联,即判别两属性是否独立。如在前例中,问题是:一个人是否色盲与其性别是否有关?在rc表中,若以 和 分别表示总体中的个体仅属于 ,仅属于 和同时属于 与 的概率,可得一个二维离散分布表(表6.4),则“A、B两属性独立”的假设可以表述为
,则 A、B两属性独立 的假设可以表述为")
20
表6.4 二维离散分布表

21
这就变为上一小节中诸 不完全已知时的分布拟合检验。这里诸 共有rc个参数,在原假设H0成立时,这rc个参数 由r+c个参数 和 决定。在这r+c后个参数中存在两个约束条件:

22
在H0成立时,上式服从自由度为rc-(r+c-2)-1的
分布。 其中诸 是在H0成立下得到的 的极大似然估计,其表达式为 对给定的显著性水平 ,检验的拒绝域为:

23
例6.3 为研究儿童智力发展与营养的关系,某 研究机构调查了1436名儿童,得到如表6.5的 数据,试在显著性水平0.05下判断智力发展与 营养有无关系。 表6.5 儿童智力与营养的调查数据 营养良好 营养不良 合计 智 商 342 367 266 329 1304 56 40 20 132 16 423 382 286 345 1436 <80 8090 9099 100

24
解:用A表示营养状况,它有两个水平: 表示
营养良好, 表示营养不良;B表示儿童智商, 它有四个水平, 分别表示表中四种 情况。沿用前面的记号,首先建立假设 H0:营养状况与智商无关联,即A与B独立的。 统计表示如下: 在原假设H0成立下,我们可以计算诸参数的极大似然估计值:

25
进而可给出诸 ,如 其它结果见表6.6

26
表6.6 诸 的计算结果 由表6.5和表6.6可以计算检验统计量的值 营养良好 384.1677 346.8724 259.7631
表6.6 诸 的计算结果 营养良好 0.9081 0.2946 0.2660 0.1992 0.2403 营养不良 0.0919 <80 8090 9099 100 由表6.5和表6.6可以计算检验统计量的值

27
此处r=2,c=4,(r-1)(c-1)=3,若取 =0. 05 ,查表有 ,由于19. 2785>7
本例中检验的p 值为0.0002。

28
§6.3 正态性检验 正态分布是最常用的分布,用来判断总体分布是否为正态分布的检验方法称为正态性检验,它在实际问题中大量使用。 一、 正态概率纸 正态概率纸可用来作正态性检验,方法如下:利用样本数据在概率纸上描点,用目测方法看这些点是否在一条直线附近,若是的话,可以认为该数据来自正态总体,若明显不在一条直线附近,则认为该数据来自非正态总体。

29
例 随机选取10个零件,测得其直径与标 准尺寸的偏差如下:(单位:丝) 在正态概率纸上作图步骤如下: (1) 首先将数据排序: ; (2) 对每一个i,计算修正频率 (i-0.375)/(n+0.25), i=1,2,…,n,
 首先将数据排序: ; (2) 对每一个i,计算修正频率. (i-0.375)/(n+0.25), i=1,2,…,n,")
30
(3) 将点 逐一点在正态概率纸上, (4) 观察上述n个点的分布: 若诸点在一条直线附近,则认为该批数 据来自正态总体; 若诸点明显不在一条直线附近,则认为 该批数据的总体不是正态分布。
 将点 逐一点在正态概率纸上, (4) 观察上述n个点的分布: 若诸点在一条直线附近,则认为该批数 据来自正态总体; 若诸点明显不在一条直线附近,则认为 该批数据的总体不是正态分布。")
31
从图6.2可以看到,10个点基本在一条直线附近,故可认为直径与标准尺寸的偏差服从正态分布。

32
如果从正态概率纸上确认总体是非正态分布时,可对原始数据进行变换后再在正态概率纸上描点,若变换后的点在正态概率纸上近似在一条直线附近,则可以认为变换后的数据来自正态分布,这样的变换称为正态性变换。常用的正态性变换有如下三个:对数变换 、倒数变换 和根号变换 。

33
例6.5 随机抽取某种电子元件10个,测得其寿 命数据如下: 110.47, , , , , 539.35, , , , 图6.3 给出这10个点在正态概率纸上的图形,这10个点明显不在一条直线附近,所以可以认为该电子元件的寿命的分布不是正态分布。

34
图6.3 例6.5 的正态概率纸

35
i 对该10个寿命数据作对数变换,结果见表6.8 表6.8 对数变换后的数据 1 32.62 3.4849 0.061 6 286.80
表6.8 对数变换后的数据 1 32.62 3.4849 0.061 6 286.80 5.6588 0.549 2 97.04 4.5752 0.159 7 539.35 6.2904 0.646 3 99.16 4.5967 0.256 8 561.10 6.3299 0.743 4 110.47 4.7048 0.354 9 782.93 6.6630 0.841 5 179.49 5.1901 0.451 10 7.7275 0.939 i

36
利用表6. 8 中最后两列上的数据在正态概率纸上描点,结果见图6
利用表6.8 中最后两列上的数据在正态概率纸上描点,结果见图6.4,从图上可以看到10个点近似在一条直线附近,说明对数变换后的数据可以看成来自正态分布。这也意味着,原始数据服从对数正态分布

37
图6.4 变换后数据的正态概率纸

38
二、夏皮洛-威尔克(Shapiro-Wilk)检验
夏皮洛-威尔克检验也简称W 检验。这个检验当8n50时可以利用。过小样本(n<8)对偏离正态分布的检验不太有效。 W 检验是建立在次序统计量的基础上。 检验统计量为: (6.5) 其中系数ai 可查附表。
对偏离正态分布的检验不太有效。 W 检验是建立在次序统计量的基础上。 检验统计量为: (6.5) 其中系数ai 可查附表。")
39
拒绝域为: {WW}。 其中 分位数 可查附表. 系数 还具有如下几条性质:

40
据此可将(6.5)简化为
简化为")
41
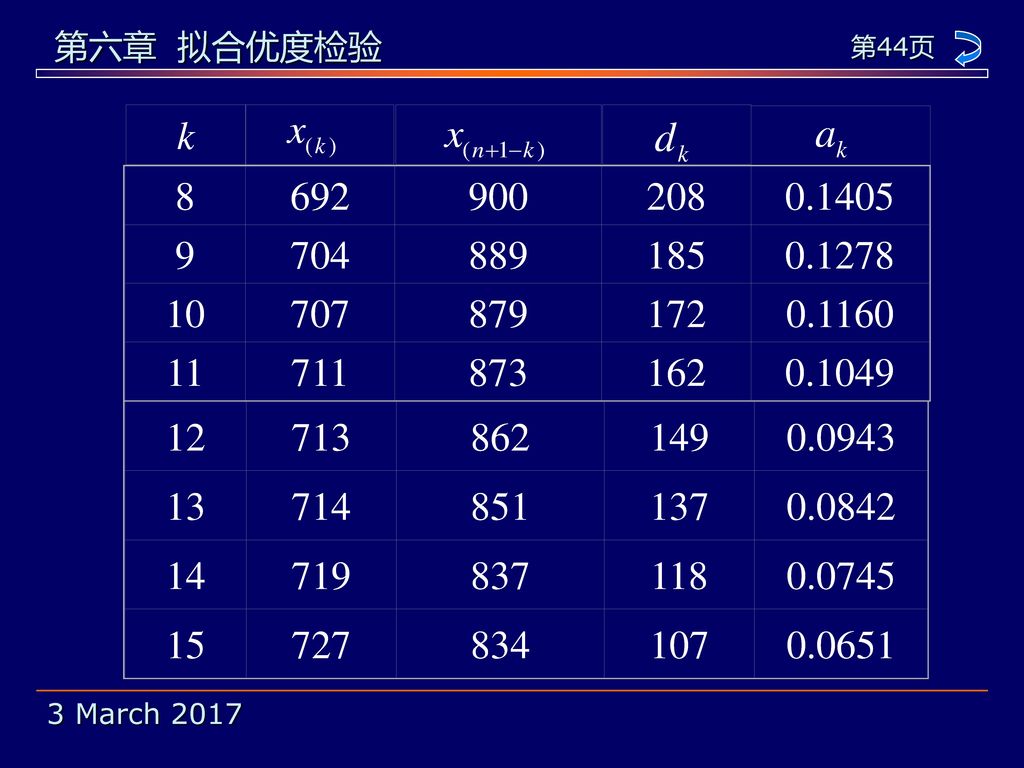
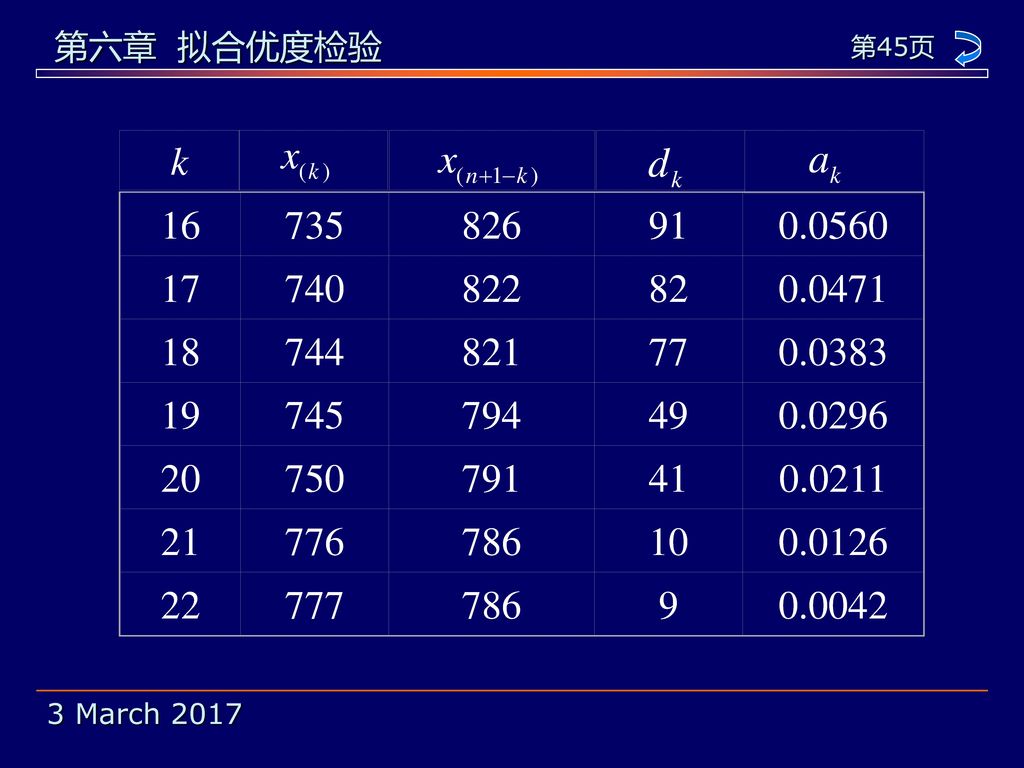
例6.6 某气象站收集了44个独立的年降雨量数 据,资料如下(已排序): 520 556 561 616 635 669 686 692 704 707 711 713 714 719 727 735 740 744 745 750 776 777 786 791 794 821 822 826 834 837 851 862 873 879 889 900 904 922 926 952 963 1056 1074 我们要根据这批数据作正态性检验。

42
首先由这批数据可算得: 我们将计算W 的过程列于表6.9中。 为便于计算,值 , 和 安排在同一行。

43
表6.9 某一气象站收集的年降雨量 1 520 1074 554 0.3872 2 556 1056 500 0.2667 3 561 963 402 0.2323 4 616 952 336 0.2072 5 635 926 291 0.1868 6 669 922 253 0.1695 7 686 904 218 0.1542 k

44
k 8 692 900 208 0.1405 9 704 889 185 0.1278 10 707 879 172 0.1160 11 711 873 162 0.1049 12 713 862 149 0.0943 13 714 851 137 0.0842 14 719 837 118 0.0745 15 727 834 107 0.0651
45
k 16 735 826 91 0.0560 17 740 822 82 0.0471 18 744 821 77 0.0383 19 745 794 49 0.0296 20 750 791 41 0.0211 21 776 786 10 0.0126 22 777 9 0.0042
46
从表6.9可以计算出W 的值: 若取 =0.05,经查表可知,在n=44时有: 由于计算得到的W 值大于该值,所以在显著性水平 =0.05上不拒绝零假设,即可以认为该批数据服从正态分布。

47
§6.4 Kolmogorov-Smirnov检验
这是检验单一样本是否来自某一特定分布的方法。比如检验一组数据是否为正态分布。 它的检验方法是以样本数据的累计频数分布与特定理论频数比较,若两者间的差距很小,则推论该样本取自某特定分布。 即考虑假设检验问题: H0 :样本所来自的总体分布服从某特定分布 H1 :样本所来自的总体分布不服从某特定分布

48
例如,收集一批周岁儿童身高的数据,需利用样本数据推断周岁儿童总体的身高是否服从正态分布。
再例如,利用收集的住房状况调查的样本数据,分析家庭人均住房面积是否服从正态分布。 这里我们仅以Kolmogorov-Smirnov正态性检验为例介绍它的统计原理。

49
F0(x)表示给定分布的分布函数, Fn(x) 表示一组随机样本的经验分布函数。设D为F0(x)与Fn(x)差距的最大值,定义如下式:
D =sup| Fn(x) - F0(x) | 结论:当实际观测D ≥ c时,则拒绝H0 ,反之则不拒绝H0假设。 c 值可通过查表得到。
 - F0(x) | 结论:当实际观测D ≥ c时,则拒绝H0 ,反之则不拒绝H0假设。 c 值可通过查表得到。")
50
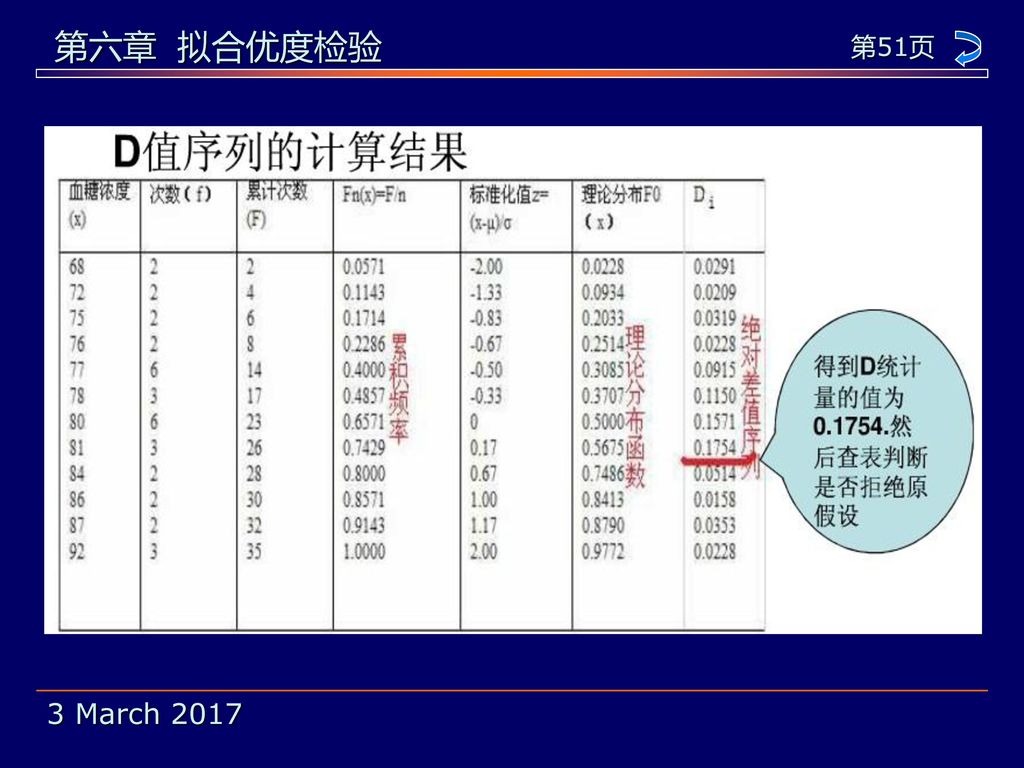
例:35位健康男性在未进食前的血糖浓度如下所示,试检验这组数据是否来自均值μ=80,标准差σ=6的正态分布.
假设 H0 :健康成人男性血糖浓度服从N(80,62) H1 :健康成人男性血糖浓度不服从N(80,62) 计算过程如表:
 H1 :健康成人男性血糖浓度不服从N(80,62) 计算过程如表:")
52
结论:上表中的理论值F0(x)是根据标准化值z查表得到,实际上
D =sup| Fn(x) - F0(x) |=0.1754<D0.05, 35=0.23 (查D值表可得D0.05, 35=0.23) 故不能拒绝H0即健康成年男人血糖浓度服从正态分布.
 - F0(x) |=0.1754<D0.05, 35=0.23. (查D值表可得D0.05, 35=0.23) 故不能拒绝H0即健康成年男人血糖浓度服从正态分布.")
53
适用范围:单样本 K-S 检验可以将一个变量的实际频数分布与高斯分布(Gaussian)、均匀分布(Uniform)、泊松分布(Poisson)、指数分布(Exponential)等进行比较。
、均匀分布(Uniform)、泊松分布(Poisson)、指数分布(Exponential)等进行比较。")
54
卡方检验与Kolmogorov-Smirnov正态性检验都采用实际频数和期望频数进行检验。它们之间最大的区别在于前者主要用于分类数据,而后者主要用于有单位的定量数据,有时前者也可以用于定量数据但必须将数据分组得到实际观测频数,并要求多变量之间独立,而后者可以不分组直接把原始数据进行检验,因此K-S检验对数据的应用较完整。


=0 变换为 x= (x), 然后建立迭代格式, 返回下一页 则称迭代格式 收敛, 否则称为发散 上一页.>")


到综合楼 205 教室集合,查看 监考安排,由考务负责人进行考务 培训。>")



 1.以大盤指數為標的之權證,和大盤指數的連動性,為什麼比和期交所期指的連動性差?>")











