Download presentation
1
統合分析臨床試驗實之文獻品質評分:以針灸療法之統合分析為例
September Journal Club 指導老師:蔡佩珊 教授 學生:謝育蓉

2
進行文獻評讀的原因 研究所產生的證據都是可信的嗎? 研究的品質決定我們可否相信其結果。
實際評讀文獻的過程,即是審視研究中有可能 的偏誤(Bias)。
。")
3
文獻評讀工具 The Cochrane Collaboration’s tool for assessing risk of bias in randomised trials 選擇性誤差 (Selection bias) 表現性誤差 (Performance bias) 偵測性偏差 (Detection bias) 削弱性誤差 (Attrition bias) 通報性誤差 (Reporting bias) 其他誤差 (Other bias) 特別強調的是,研究的品質並不是只有"設計 (design)" 還有"執行 (conduct)" 還有"報告 (report)"...
 偵測性偏差 (Detection bias) 削弱性誤差 (Attrition bias) 通報性誤差 (Reporting bias) 其他誤差 (Other bias) 特別強調的是,研究的品質並不是只有 設計 (design) 還有 執行 (conduct) 還有 報告 (report) ...")
5
選擇性偏差(Selection bias)
隨機分派(Random sequence generation) 分組隱匿(Allocation concealment) 1.必須讓所有參與研究對象都有相同機率被分派到實驗組或控制組 2.選樣性偏差是由不適當的隨機分派或引方式所造成的。
 分組隱匿(Allocation concealment) 1.必須讓所有參與研究對象都有相同機率被分派到實驗組或控制組. 2.選樣性偏差是由不適當的隨機分派或引方式所造成的。")
6
隨機分派 Random sequence generation
隨機分派指的是採用隨機的方式將受試者分派 至不同的試驗情境,以確保受試者被指派到任 何一個試驗情境的機率是均等的 詳細說明如何分派順序以及是否能產生可比較 的組別 Describe the method used to generate the allocation sequence in sufficient detail to allow an assessment of whether it should produce comparable groups. 意思是全部的樣本被挑選進入治療組與對照組的機率是相同的。

7
評讀標準:‘Low risk’ of bias
亂數表 亂數產生器 擲銅板 抽牌或是信封袋擲骰子 抽籤 最小化 The investigators describe a random component in the sequence generation process such as: 執行者於序列生成的流程中有解釋隨機的方式例如:隨機亂數表、電腦的亂數產生器、丟銅板、 Minimization: may be implemented without a random element, and this is considered to be equivalent to being random. 共變量應變式隨機分派則是屬於一種動態 (dynamic)的分派方法,某受試病人要分派到何種治療並非事先決定,而是要看該受試病人是屬於何種共變量區塊,在這區塊中先計算先前的已受試病人,在試驗組和控制組的絕對數值,然後將該病人加入絕對數值較小的哪一組,這種概念稱為最小化 (minimization)。將欲受試的病人先虛擬到任一治療組,然後計算該組別的各個共變數的卡方適合度檢定值,選取共變數的最大值之後,再比較各組別的卡方適合度檢定值,有最小的卡方適合度檢定值的組別為其接受的治療組,因為最小的卡方適合度檢定值代表其不均衡 (imbalance)的機會是最小的。
的分派方法,某受試病人要分派到何種治療並非事先決定,而是要看該受試病人是屬於何種共變量區塊,在這區塊中先計算先前的已受試病人,在試驗組和控制組的絕對數值,然後將該病人加入絕對數值較小的哪一組,這種概念稱為最小化 (minimization)。將欲受試的病人先虛擬到任一治療組,然後計算該組別的各個共變數的卡方適合度檢定值,選取共變數的最大值之後,再比較各組別的卡方適合度檢定值,有最小的卡方適合度檢定值的組別為其接受的治療組,因為最小的卡方適合度檢定值代表其不均衡 (imbalance)的機會是最小的。")
8
評讀標準:‘High risk’ of bias (1)
有些系統性的敘述,但並非隨機分派: 生日的奇數或偶數日 根據加入研究的日期(或星期) 根據醫院或診所的紀錄號碼 The description would involve some systematic, non-random approach, for example:
 根據醫院或診所的紀錄號碼. The description would involve some systematic, non-random approach, for example:")
9
評讀標準:‘High risk’ of bias (2)
明顯的非隨機方式: 由醫師指派 依受試者喜好 根據實驗室的數據或測驗結果分派 對介入措施有效者 Non-random approaches usually involve judgement or some method of non-random categorization of participants, for example: Allocation by judgement of the clinician Allocation by preference of the participant Allocation based on the results of a laboratory test or a series of tests Allocation by availability of the intervention

10
評讀標準:‘Unclear risk’ of bias
沒有足夠的資訊能辨別是否為高或 低風險

11
分組隱匿 Allocation concealment
解釋如何進行分組隱匿性,並可使讀者 了解在受試者及執行者在試驗前、中、 後皆不可預知分組結果。

12
評讀標準:‘Low risk’ of bias
中央分配(包括電話、資訊系統及隨機的藥物控 制) 相同外觀,按照順序編排好的藥罐 有序號、不透明、密封的信封袋 Participants and investigators enrolling participants could not foresee assignment because one of the following, or an equivalent method, was used to conceal allocation:
 相同外觀,按照順序編排好的藥罐. 有序號、不透明、密封的信封袋. Participants and investigators enrolling participants could not foresee assignment because one of the following, or an equivalent method, was used to conceal allocation:")
13
評讀標準:‘High risk’ of bias
使用開放式的隨機分組表格(例如:隨機號碼名單) 分組的信封沒有完善的保護措施(例如:信封沒有 密封、透明的或沒有按順序編號排列) 交替或轉換 生日 病歷號碼 其他沒有隱匿性的程序 Participants or investigators enrolling participants could possibly foresee assignments and thus introduce selection bias, such as allocation based on: 受試者或執行者可以清楚猜到所分派的組別
 分組的信封沒有完善的保護措施(例如:信封沒有 密封、透明的或沒有按順序編號排列) 交替或轉換. 生日. 病歷號碼. 其他沒有隱匿性的程序. Participants or investigators enrolling participants could possibly foresee assignments and thus introduce selection bias, such as allocation based on: 受試者或執行者可以清楚猜到所分派的組別.")
14
評讀標準:‘Unclear risk’ of bias
沒有足夠的資訊去判別為高或低風險。 例如:有解釋使用信封袋,但未解釋信封是否 有密封、序號或透明與否。

15
表現性誤差 Performance bias
是否有解釋測量工具的使用,並能否使 受試者及研究人員不知道在接受任何一 種介入措施。 說明其使用盲性之方法及是否有效。 受試者及研究人員的盲性方式(Blinding of participants and personnel):
:")
16
評讀標準:‘Low risk’ of bias
研究結果不受盲性與否影響。 確保受試者及研究人員的盲性,且這種 盲性不會輕易被破壞。

17
評讀標準:‘High risk’ of bias
沒有盲性或不完全,且其結果會受影響。 嘗試對受試者及主要研究人員進行盲性, 但盲性有能會失敗,且其研究結果亦會 受影響。

18
評讀標準:‘Unclear risk’ of bias
沒有足夠的資訊能辨別為高或低風險 此研究沒有多著墨

19
偵測性偏差 Detection bias 說明測量研究結果的方式,且施測者對 受試者所接受的介入措施為不知情的。
提供盲化的資訊及其是否能有效盲化。 結果評估的盲性方式(Blinding of outcome assessment):
:")
20
評讀標準:‘Low risk’ of bias
沒有盲性,但評讀的作者不認為會影響 受試結果。 確定有盲化,且不會輕易被破壞。

21
評讀標準:‘High risk’ of bias
施測結果沒有盲化,且其結果會受沒有 盲化而影響。 施測結果測量有盲化,但這樣易被破壞, 且結果會受沒有盲化所影響。

22
評讀標準:‘Unclear risk’ of bias
沒有足夠的資訊可判別為高或低風險。 此研究為多著墨。

23
削弱性誤差 Attrition bias 說明主要研究結果的數據完整性,包括資料分 析的耗損或流失。是否有說明耗損及流失的原 因,每一組別(與總人數作比較)耗損及流失的原 因以及使否在分析時重新納入。 未完成評估資料的處理方式(Incomplete outcome data) State whether attrition and exclusions were reported, the numbers in each intervention group (compared with total randomized participants), reasons for attrition/exclusions where reported, and any re-inclusions in analyses performed by the review authors.
 State whether attrition and exclusions were reported, the numbers in each intervention group (compared with total randomized participants), reasons for attrition/exclusions where reported, and any re-inclusions in analyses performed by the review authors.")
24
評讀標準:‘Low risk’ of bias
沒有遺失的數據 個案流失之原因與介入措施及結果無關 遺失的數據採用適當的方式將之補齊(例 如意向分析或依計畫書分析)
")
25
評讀標準:‘High risk’ of bias
個案流失是因為介入措施或不良的結果所造成 的,沒有詳細敘述流失的原因 ’As-treated’分析大幅使用在因隨機分組後之介 入措施所流失的數據 使用不合適的方法將遺失的資料補齊

26
評讀標準:‘Unclear risk’ of bias
沒有提出耗損/流失的足夠資料(例如:沒 有說明隨機數字、沒有提供遺失數據的 理由) 此研究未多著墨
 此研究未多著墨.")
27
通報性誤差 Reporting bias 研究的結果是否有選擇性的報導。 選擇性報告內容(selective reporting):
:")
28
評讀標準:‘Low risk’ of bias
研究方案是合適的及研究預期之結果(主 要或次要)是符合預先想看到的。 雖然研究方案不合適,但清楚明瞭且發 表的結果包含所預設的研究結果的及最 主要想看到的結果。
是符合預先想看到的。 雖然研究方案不合適,但清楚明瞭且發 表的結果包含所預設的研究結果的及最 主要想看到的結果。")
29
評讀標準:‘High risk’ of bias
研究預想看到的結果沒有呈現 一個或一個以上的主要結果測量分析沒有包含 預先想看的結果 一個或一個以上的主要結果並非預先想看的, 除非有明顯的理由,例如意料之外的附加作用 一個或一個以上重要的資料不完整,不能進行 統合分析。 研究的呈現不包含所期待之結果。

30
評讀標準:‘Unclear risk’ of bias
沒有足夠的資訊辨別高或低風險。 大部分的研究屬於這類。

31
其他誤差 Other bias 敘述此工具未包含之誤差。
假如特定問題/項目預先在方案中便呈現了,那 應該在文章中可以找到作者回答那些問題/項目 的答案。 其他偏差(Other sources of bias)
")
32
評讀標準:‘Low risk’ of bias
此研究似乎沒有其他的誤差。

33
評讀標準:‘High risk’ of bias
有潛在的各書研究設計之誤差。 曾經被指出是不適當的設計。 有其他的問題。

34
評讀標準:‘Unclear risk’ of bias
沒有足夠資訊來評值是否有重要風險誤 差的存在。 沒有足夠的理由或證據辨別誤差。

35
評讀練習

36
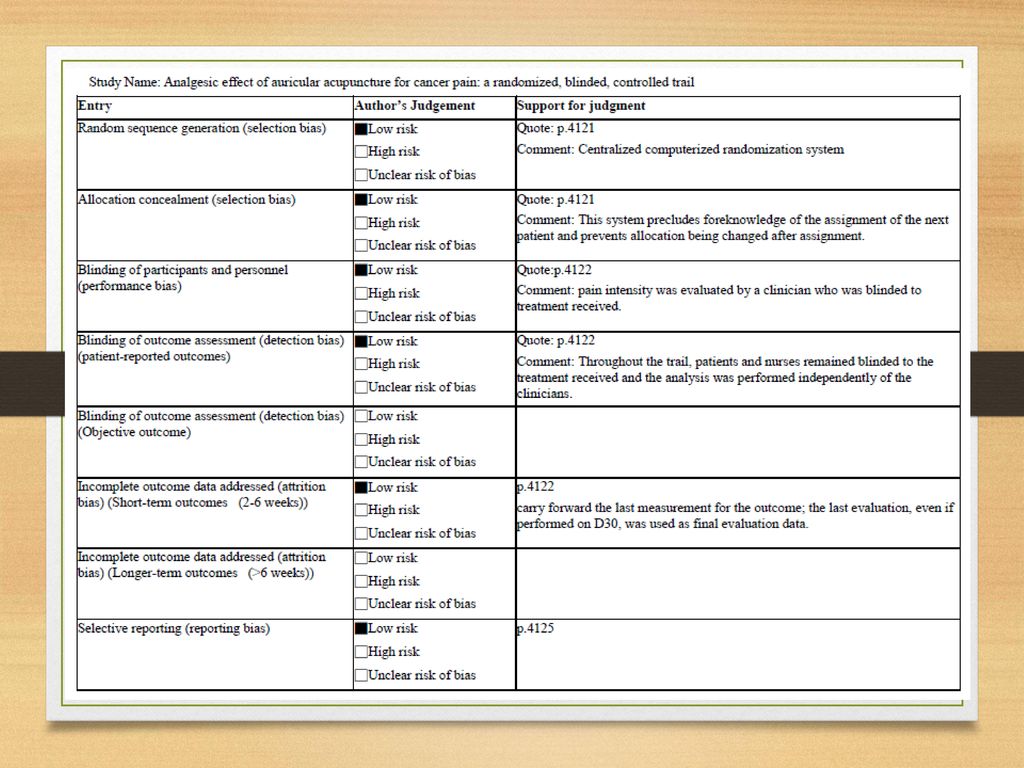
Analgesic effect of auricular acupuncture for cancer pain: a randomized, blinded, controlled trail
Alimi et al. Journal of Clinical Oncology, Vol 21, No 22, 2003: pp

38
Acupuncture combined with point injection of Chinese angelica injection for pain of advanced stomach carcinoma Wang, Yin, Li, 2010 Chinese Journal of Cancer Prevention and Treatment, Vol. 17, No. 18, 2010: pp

39
評讀因為每個人有主觀的感覺不同,有時會遇到不一致結果,故需要兩個reviewer分頭來進行評讀,在一起討論,若仍無法獲得共識,則需委託第三方公正的專家來進行仲裁。

40
綜合評讀結果

41
+= low risk; -=high risk; ?= unclear risk of bias.

42
統合分析結果判讀

43
異質性檢定 目的:研究之間的效果和綜合性效果是否有極 大的差異性
分析各論文間是否有很大的異質性,可以用卡 方異質性檢定(chi-square test for heterogeneity,Cochran Q test)統計法來分析 p 值< 0.1 可以判定研究間存在有明顯的異質性, 如果Q值接近零,代表無異質性 合併各個研究數據,各個研究的同質性很重要,研究彼此間一致性高,合併數據的可信度才較高。 若有異質性,則不能貿然將結果整合在一起,需針對異質性做探討
統計法來分析. p 值< 0.1 可以判定研究間存在有明顯的異質性, 如果Q值接近零,代表無異質性. 合併各個研究數據,各個研究的同質性很重要,研究彼此間一致性高,合併數據的可信度才較高。 若有異質性,則不能貿然將結果整合在一起,需針對異質性做探討.")
44
異質性的比例 以I2統計參數加以表示 I2 test檢測異質性大小,每25%做區隔 等於0表是有極佳的一致性 ≦25%低度異質性
>50%異質性大,不宜統合 >50%:需利用其他方式進行數據調整,並要保守的解讀整合的結論

45
效果量 信賴區間 信賴區間 樣本大小 效果量 信賴區間 信賴區間 樣本大小 Q=22.01, p=0.06; I2=40.94
與中線交界,代表沒有統計學上的意義 信賴區間與樣本大小符號與中線接觸或相交表示差異無顯著統計學意義。若在中線左邊表示acupuncture有效,在右邊表示無效。 Q=22.01, p=0.06; I2=40.94 Favours acupuncture Favours control

46
整體結果 信賴區間 Q=22.01, p=0.06; I2=40.94

47
產生異質性的原因 不同的病人群研究(patient population studies) 治療方法(interventions used)
附加治療(co-interventions) 結果評估方式(outcomes measured) 研究設計不同(different study design features) 研究品質(study quality) 隨機誤差(random error)
 結果評估方式(outcomes measured) 研究設計不同(different study design features) 研究品質(study quality) 隨機誤差(random error)")
48
異質性解決方法 次群組分析(subgroup-analysis):將欲選取的 論文,找出具有明顯的category 差別的變項,按 照此變項的等級分別作統合分析。因此就可能 產生兩個或三個的森林圖。 統合性迴歸分析(meta-regression):原則上如 果總論文數小於10篇以下,則不要作統合性迴 歸分析。統合性迴歸分析的目的是在將某些變 數當作共變數(covariates),去探索(explore) 有哪幾個變項會造成異質性。
:原則上如 果總論文數小於10篇以下,則不要作統合性迴 歸分析。統合性迴歸分析的目的是在將某些變 數當作共變數(covariates),去探索(explore) 有哪幾個變項會造成異質性。")
49
Thanks for your listening!


薪 樵,賣以給 (ㄐㄧ ˇ ) 食。 家裡雖然很窮困,但是他還是很喜歡讀書,因 不懂得如何治理產業,只能靠著上山砍材去城.>")

 的制定及临床应用体会 北京朝阳医院 呼吸与危重症医学科 曹志新 2009-10-27.>")



7731-5800 services@customer-support.com.tw The Cochrane Library 碩睿資訊有限公司 (02)7731-5800 services@customer-support.com.tw.>")




 科技编辑类论文选题与写作 任 胜 利 《自然科学进展》编辑部 www.sciencenet.cn/blog/rensl.htm (科学网博客)>")





>")

