Download presentation
1
Operating System Concepts 作業系統原理 Chapter 9 虛擬記憶體管理 (Virtual-Memory Management)
")
2
CHAPTER 9 虛擬記憶體管理 9.2 分頁需求 9.3 寫入時複製 9.4 分頁替換 9.5 欄的配置法則 9.6 輾轉現象
9.1 背景 9.2 分頁需求 9.3 寫入時複製 9.4 分頁替換 9.5 欄的配置法則 9.6 輾轉現象 9.7 記憶體對映檔案 9.8 核心記憶體的配置 9.9 其它考慮的因素

3
1.背景(Background) 虛擬記憶體 (virtual memory)乃是使用者邏輯記憶體與實體記憶體之間的分隔。這種方式可以在一個比較小的實體記憶體提供程式設計師大量的虛擬記憶體。 虛擬記憶體使得程式規劃工作變得十分容易,因為程式設計師不需要再為有多少實體記億體空間可供使用而煩惱了,而可以集中精神在要設計的問題上。 Stack Heap

4
除了將實體記憶體和邏輯記憶體分隔開來,虛擬記憶體也允許經由分頁分享,不同行程分享檔案和記憶體。
Stack Shared Library Shared Pages Heap

5
2.分頁需求(Demand Paging) Swapper是處理整個Process Pager僅處理Process的各個分頁
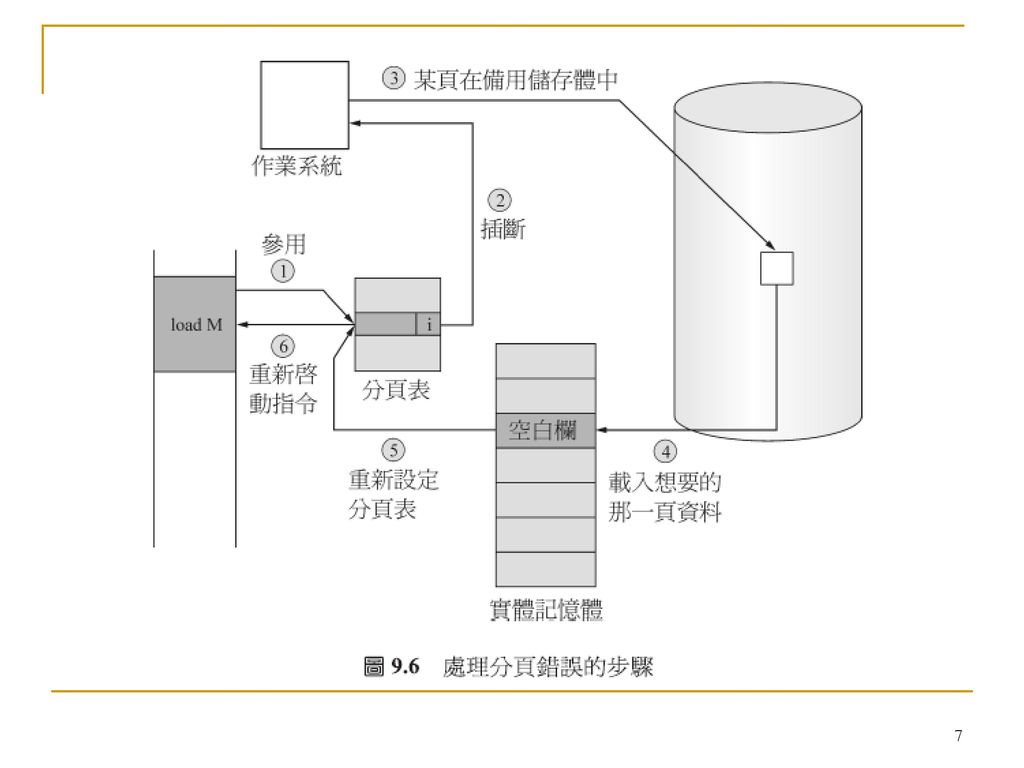
需求分頁法就像一種使用置換法的分頁系統。行程存放在輔助記憶體(通常是磁碟中)。當要執行某個行程的時候,就把那個行程置換至記憶體中。但是,並不是把整個行程都置換進來,而是使用一個懶惰置換程式(Lazy Swapper)。懶惰置換程式只有當需要某一頁的時候才把該頁置換進來。 Swapper是處理整個Process Pager僅處理Process的各個分頁 Disk
。當要執行某個行程的時候,就把那個行程置換至記憶體中。但是,並不是把整個行程都置換進來,而是使用一個懶惰置換程式(Lazy Swapper)。懶惰置換程式只有當需要某一頁的時候才把該頁置換進來。 Swapper是處理整個Process. Pager僅處理Process的各個分頁. Disk.")
6
2.1 基本觀念(Basic Concepts) 分頁表上目前若在主記憶體的分頁項就以原先的方式設定,若目前不在主記憶體的分頁則僅標示為 "無效",或是還存放該頁在磁碟上的位址。
 分頁表上目前若在主記憶體的分頁項就以原先的方式設定,若目前不在主記憶體的分頁則僅標示為 無效 ,或是還存放該頁在磁碟上的位址。")
8
2.2 需求分頁的性能(Performance of Demand Paging)
每400,000次存取才允許有一次Page Fault

9
3.寫入時複製(Copy-on-Write)
Copy-on-Write (COW) allows both parent and child processes to initially share the same pages in memory If either process modifies a shared page, only then is the page copied COW allows more efficient process creation as only modified pages are copied Free pages are allocated from a pool of zeroed-out pages
 allows both parent and child processes to initially share the same pages in memory If either process modifies a shared page, only then is the page copied. COW allows more efficient process creation as only modified pages are copied. Free pages are allocated from a pool of zeroed-out pages.")
10
4.分頁替換(Page Replacement)
過度配置(Over-allocating): 1.當執行一個使用者行程的時候,出現了一個分頁錯誤。2.作業系統確定所要的那一頁存在磁碟什麼地方,但是卻發現在可用空白欄的表中已無空白欄了。3.所有記憶空間都已被使用了。
: 1.當執行一個使用者行程的時候,出現了一個分頁錯誤。2.作業系統確定所要的那一頁存在磁碟什麼地方,但是卻發現在可用空白欄的表中已無空白欄了。3.所有記憶空間都已被使用了。")
11
4.1 基本技巧(Basic Page Replacement)
分頁替換的方法如下。如果沒有空白欄可用,就去找一個目前並未使用的欄並且把它空出來。要把某個欄空出來,可以把該欄的內涵寫入置換空間中,並且更改分頁表(以及所有相關的表格)以標示該頁已不在記憶體中了。空出來的欄現在就可以用來存放引起分頁錯誤的那一頁。 Find the location of the desired page on disk Find a free frame: If there is a free frame, use it If there is no free frame, use a page replacement algorithm to select a victim frame Bring the desired page into the (newly) free frame; update the page and frame tables Restart the process
以標示該頁已不在記憶體中了。空出來的欄現在就可以用來存放引起分頁錯誤的那一頁。 Find the location of the desired page on disk. Find a free frame: - If there is a free frame, use it - If there is no free frame, use a page replacement algorithm to select a victim frame. Bring the desired page into the (newly) free frame; update the page and frame tables. Restart the process.")
12
Want lowest page-fault rate
要執行需求分頁法必須先解決兩個主要的問題:欄的配置演算法與分頁替換演算法。如果有很多行程在記憶體中,必須決定每個行程要分給它多少欄使用。 不同的分頁替換演算法有許多種。如何去選擇一個替換演算法呢?一般來說,希望具有最低分頁錯誤比率的那一個。 Want lowest page-fault rate Evaluate algorithm by running it on a particular string of memory references (reference string) and computing the number of page faults on that string In all our examples, the reference string is 1, 4, 1, 6, 1, 6, 1, 6, 1, 6, 1 若有3 Frames可用,則只有3次Page Faults 若只有1 Frame可用,則每次參考時都會發生Page Fault (總計須11次)
 and computing the number of page faults on that string. In all our examples, the reference string is. 1, 4, 1, 6, 1, 6, 1, 6, 1, 6, 1. 若有3 Frames可用,則只有3次Page Faults. 若只有1 Frame可用,則每次參考時都會發生Page Fault (總計須11次)")
13
4.2 FIFO法則(FIFO Page Replacement)
最簡單的頁替換演算法就是先進先出 (first-in, first-out, FIFO)演算法。 畢雷地異常(Belady's anomaly) Frames越多 Page Fault反而越多
演算法。 畢雷地異常(Belady s anomaly) Frames越多. Page Fault反而越多.")
14
First-In-First-Out (FIFO) Algorithm
Reference string: 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5 3 frames (3 pages can be in memory at a time per process) 4 frames Belady’s Anomaly: more frames more page faults 1 1 4 5 2 2 1 3 9 page faults 3 3 2 4 1 1 5 4 2 2 1 5 10 page faults 3 3 2 4 4 3 14
 4 frames. Belady’s Anomaly: more frames more page faults page faults page faults")
15
4.3 最佳頁替換(Optimal Page Replacement)
最佳頁替換演算法(optimal page-replacement algorithm)是所有演算法中分頁錯誤比率最低的一種。它永遠不會遭遇到畢雷地異常的問題。目前存在的最佳頁替換演算法稱為OPT或MIN。 Replace page that will not be used for longest period of time 必須預知之後Reference String
是所有演算法中分頁錯誤比率最低的一種。它永遠不會遭遇到畢雷地異常的問題。目前存在的最佳頁替換演算法稱為OPT或MIN。 Replace page that will not be used for longest period of time. 必須預知之後Reference String.")
16
4.4 LRU (Least Recently Used)
Counter implementation Every page entry has a counter; every time page is referenced through this entry, copy the clock into the counter When a page needs to be changed, look at the counters to determine which are to change

17
Stack implementation – keep a stack of page numbers in a double link form:
Page referenced: move it to the top No search for replacement 17

18
4.5 LRU 近似換頁法(LRU-Approximation PR)
LRU需要足夠硬體來支援其Page Replacement 1. 額外的參考位元法則(Additional-Reference-Bits Algorithm) 藉著定期地記錄參考位元可以得到一些額外的次序資訊。在一個表中為每一頁保存一個8位元的位元組。每經過一段時間( 100ms),一個計時器中斷就把控制權轉交給作業系統。作業系統把每一頁的參考位元移到其 8位元位元組中較高次的位元,把其它位元右移一位元,捨棄掉低次的位元。 如果移位暫存器中保存的是 ,那麼這一頁在前八段時間內都沒有被使用過;某頁如果每段時間之內最少都被使用過一次,那麼它的移位暫存器內的值就是 。某頁暫存器中的值若是 ,那它就一定比值是 的那一頁較常被用。 > 所有 較常被使用 1
 藉著定期地記錄參考位元可以得到一些額外的次序資訊。在一個表中為每一頁保存一個8位元的位元組。每經過一段時間( 100ms),一個計時器中斷就把控制權轉交給作業系統。作業系統把每一頁的參考位元移到其 8位元位元組中較高次的位元,把其它位元右移一位元,捨棄掉低次的位元。 如果移位暫存器中保存的是 ,那麼這一頁在前八段時間內都沒有被使用過;某頁如果每段時間之內最少都被使用過一次,那麼它的移位暫存器內的值就是 。某頁暫存器中的值若是 ,那它就一定比值是 的那一頁較常被用。 > 所有 較常被使用. 1.")
19
2.第二次機會替換法(Second-Chance Algorithm)
第二次機會替換法的基本演算法是一種FIFO替換法。可是,當某頁被選出來之後,就檢視它的參考位元。如果參考位元為0,就進行替換這一頁的工作。如果參考位元是 1,就給那一頁第二次機會並且繼續去選出下一個FlFO頁。 替換此Page

20
3.加強第二次機會替換法 (Enhances Second-Chance Algorithm)
把參考位元和修改位元視為一組有序對。有了這2個位元,可以得到以下四種類型: (0,0)表示未使用過也未被修改過--最佳替換頁。 (0,1)表示近來末被使用過但曾被修改過--沒有那麼好,因為此頁需要被寫入磁碟,才可以被替換。 (1,0)表示近來被使用但末被修改過--可能很快會被再使用到。 (1,1)表示曾被使用過且被修改過--可能會被再使用到,再替換掉此頁之前,必須把它寫到儲存裝置。
表示未使用過也未被修改過--最佳替換頁。 (0,1)表示近來末被使用過但曾被修改過--沒有那麼好,因為此頁需要被寫入磁碟,才可以被替換。 (1,0)表示近來被使用但末被修改過--可能很快會被再使用到。 (1,1)表示曾被使用過且被修改過--可能會被再使用到,再替換掉此頁之前,必須把它寫到儲存裝置。")
21
4.6 計數基礎頁替換法(Counting-Based PR)
最不經常使用的法則 (LFU):最不經常使用的 (Least Frequently Used, LFU)演算法讓次數最少的那一頁被替換掉。 最常使用的法則(MFU):最常被使用的 (Most Frequently Used, MFU) 替換法認為次數最少的頁可能才被載入不久,並且將要被使用。 4.7 頁緩衝法(Page-Buffering Algorithm) 為被修改過的頁保存一個表。每當分頁用的裝置閒置了之後,就選出曾經被修改過的一頁並將它寫入磁碟中。該頁的修改位元就被重置為0。 使用一個空白欄庫存而記住在每一欄中是那些頁。因為欄的內容在我們把欄寫入磁碟的時候並不會被更改,因此在必要的時候舊的頁可以直接自尚未再用的空白欄庫存中取出來重新使用。
:最不經常使用的 (Least Frequently Used, LFU)演算法讓次數最少的那一頁被替換掉。 最常使用的法則(MFU):最常被使用的 (Most Frequently Used, MFU) 替換法認為次數最少的頁可能才被載入不久,並且將要被使用。 4.7 頁緩衝法(Page-Buffering Algorithm) 為被修改過的頁保存一個表。每當分頁用的裝置閒置了之後,就選出曾經被修改過的一頁並將它寫入磁碟中。該頁的修改位元就被重置為0。 使用一個空白欄庫存而記住在每一欄中是那些頁。因為欄的內容在我們把欄寫入磁碟的時候並不會被更改,因此在必要的時候舊的頁可以直接自尚未再用的空白欄庫存中取出來重新使用。")
22
4.8 應用程式和分頁替換(Applications and PR)
應用程式經由作業系統的虛擬記憶體存取資料,比作業系統全然不提供緩衝表現地更差。一個典型的例子,一個資料庫提供它自己的記憶管理和輸出入緩衝。像這樣的應用程式瞭解他們的記憶體使用與磁碟使用比一般用途製作演算法作業系統來的好。如果作業系統正在緩衝輸出入,而且應用程式也正在這麼做,那麼對一組輸出入將會使用到兩次記憶體存取。 另一個例子,資料倉庫時常表現大量的序列磁碟讀取,接著計算以及寫入。LRU演算法則將會除去舊的分頁而且保存新的分頁,雖然應用程式更有可能讀取較舊的分頁。(當再一次的序列讀取)。在這裡,MFU實際上將會比LRU有效率。
。在這裡,MFU實際上將會比LRU有效率。")
23
5.欄的配置法則(Allocation of Frames)
5.1 最少量的欄數(Minimum Number of Frames) 配置最少量的欄數其中一個理由是性能。很明顯的,當分配給每個行程的欄數減少之後,分頁錯誤比率就會增加,而減緩行程的執行。要記著當一個分頁錯誤在一項指令執行完畢之前發生的話,這個指令就必須重新執行一次。 5.2 配置演算法(Allocation Algorithms) 將用m個欄分給n個行程的最簡單方法就是令每個行程都能分到一樣多的量,m/n個欄。舉例來說,如果有93個欄和5個行程,那麼每個行程可以分到 18個欄。剩下的3個欄可以當做一個空白欄緩衝區的庫存。這就稱為同等分配(Equal Allocate)。 使用比例分配(Proportional Allocation)。每個行程分配可用記憶體時可以按照它的大小分配。令行程pi的虛擬記憶體大小為si並且定義S=Σ si ,那麼如果可用欄的總數是m,我們分配ai個欄給行程pi其中ai近似約為ai=(si/S)×m 。
 配置最少量的欄數其中一個理由是性能。很明顯的,當分配給每個行程的欄數減少之後,分頁錯誤比率就會增加,而減緩行程的執行。要記著當一個分頁錯誤在一項指令執行完畢之前發生的話,這個指令就必須重新執行一次。 5.2 配置演算法(Allocation Algorithms) 將用m個欄分給n個行程的最簡單方法就是令每個行程都能分到一樣多的量,m/n個欄。舉例來說,如果有93個欄和5個行程,那麼每個行程可以分到 18個欄。剩下的3個欄可以當做一個空白欄緩衝區的庫存。這就稱為同等分配(Equal Allocate)。 使用比例分配(Proportional Allocation)。每個行程分配可用記憶體時可以按照它的大小分配。令行程pi的虛擬記憶體大小為si並且定義S=Σ si ,那麼如果可用欄的總數是m,我們分配ai個欄給行程pi其中ai近似約為ai=(si/S)×m 。")
24
Fixed Allocation Equal allocation – For example, if there are 100 frames and 5 processes, give each process 20 frames. Proportional allocation – Allocate according to the size of process 24

25
5.3 全體和區域的配置(Global versus Local Allocation)
另外一種影響分配給不同行程時所採用方法的重要因素是頁替換。在許多行程競爭欄數時,可以把頁替換法分成兩大類:全體替換法 (global replacement)和區域替換法 (local replacement)。全體替換法允許一個行程從所有欄數中選出一個替換欄,即使目前該欄正分配給其它某個行程使用中;換言之,一個行程可以從其它行程獲得一欄。區域替換法要求每一行程只能從它自己選出欄。 5.4 不一致的記憶體存取(Non-Uniform Memory Access) 在一個系統中,某個特定板上的CPU存取同塊板上記憶體的延遲時間比存取其他板上的記憶體來的短。凡是記憶體存取時間有很大差別的系統,其統稱為不一致的記憶體存取(NUMA)系統。 有系統的規則改變,包含了使排班器去追蹤在每個行程執行上最後的CPU。如果排班器試圖將每個行程排進以前的CPU,那麼記憶體管理系統試圖配置欄給接近被排班的CPU的行程,然後將會有提高快取命中率和降低記憶體存取時間的結果。
和區域替換法 (local replacement)。全體替換法允許一個行程從所有欄數中選出一個替換欄,即使目前該欄正分配給其它某個行程使用中;換言之,一個行程可以從其它行程獲得一欄。區域替換法要求每一行程只能從它自己選出欄。 5.4 不一致的記憶體存取(Non-Uniform Memory Access) 在一個系統中,某個特定板上的CPU存取同塊板上記憶體的延遲時間比存取其他板上的記憶體來的短。凡是記憶體存取時間有很大差別的系統,其統稱為不一致的記憶體存取(NUMA)系統。 有系統的規則改變,包含了使排班器去追蹤在每個行程執行上最後的CPU。如果排班器試圖將每個行程排進以前的CPU,那麼記憶體管理系統試圖配置欄給接近被排班的CPU的行程,然後將會有提高快取命中率和降低記憶體存取時間的結果。")
26
6.輾轉現象(Thrashing) 6.1 輾轉現象之原因(Cause of Thrashing)
CPU排班程式發現CPU使用率降低的時候,它就增加多元程式規劃的程度。這些新的行程從其它正在執行的行程中搶來一些頁以開始工作,這樣就造成了更多的分頁錯誤,以及一個更長的等待分頁裝置的佇列。結果,CPU的使用率就更降低了,而CPU排班程式想要再提高多元程式規劃的程度。 這種非常頻繁的分頁替換行為稱為輾轉現象(Thrashing)。如果某個行程花在分頁上的時間比花在執行上的時間還要多,就稱它是處於輾轉狀態。 輾轉現象已經出現了並且使得系統的產量突然下降。分頁錯誤則大量地增加。結果造成有效記憶體存取時間也增加了。因為行程把所有的時間都花在分頁上,所以什麼工作都沒有完成。 CPU使用率降低 增加多元程式規劃 更多的分頁錯誤 CPU的使用率就更降低
。如果某個行程花在分頁上的時間比花在執行上的時間還要多,就稱它是處於輾轉狀態。 輾轉現象已經出現了並且使得系統的產量突然下降。分頁錯誤則大量地增加。結果造成有效記憶體存取時間也增加了。因為行程把所有的時間都花在分頁上,所以什麼工作都沒有完成。 CPU使用率降低 增加多元程式規劃 更多的分頁錯誤 CPU的使用率就更降低.")
27
處理輾轉現象的策略: - 工作組模式(Working-Set Model)及 - 分頁錯誤頻率(Page-Fault Frequency Scheme)。
及 - 分頁錯誤頻率(Page-Fault Frequency Scheme)。")
28
6.2 工作組模式(Working-set Model)
基於局部區域的假設而設定的。這模式中使用一個參數△,來定義工作組欄框(working-set windows)。
。")
29
Working-Set Model working-set window a fixed number of page references Example: 10,000 instruction WSSi (working set of Process Pi) = total number of pages referenced in the most recent (varies in time) if too small will not encompass entire locality if too large will encompass several localities if = will encompass entire program D = WSSi total demand frames if D > m Thrashing Policy if D > m, then suspend one of the processes 29
 = total number of pages referenced in the most recent (varies in time) if too small will not encompass entire locality. if too large will encompass several localities. if = will encompass entire program. D = WSSi total demand frames. if D > m Thrashing. Policy if D > m, then suspend one of the processes. 29.")
30
6.3 分頁錯誤頻率(Page-Fault Frequency)
分頁錯誤頻率 (page-fault frequency, PFF)策略則是一種更直接的方法。要解決的就是防止輾轉現象發生。輾轉現象有高分頁錯誤率。因此我們要去控制住分頁錯誤率。當它太高的時候,就知道該行程需要更多的欄了。同樣地,如果分頁錯誤率太低,這就表示該行程擁有太多欄了。我們可以在想要的分頁錯誤率上訂定上限與下限。
策略則是一種更直接的方法。要解決的就是防止輾轉現象發生。輾轉現象有高分頁錯誤率。因此我們要去控制住分頁錯誤率。當它太高的時候,就知道該行程需要更多的欄了。同樣地,如果分頁錯誤率太低,這就表示該行程擁有太多欄了。我們可以在想要的分頁錯誤率上訂定上限與下限。")
31
7.記憶體對映檔案(Memory-Mapped Files)
想使用標準系統呼叫open、read、和write對磁碟上檔案執行循序讀取。每次檔案被讀取時需要一次系統呼叫和磁碟的存取。 可以使用到目前為止所討論的虛擬記憶體技術將檔案I/O視為經常性的記憶體存取。這種做法被稱為記憶體對映(memory mapping)。 一個檔案,允許部份的虛擬地址空間邏輯連接到檔案。當執行I/O時,這個可能導致顯著的效能提升。
。 一個檔案,允許部份的虛擬地址空間邏輯連接到檔案。當執行I/O時,這個可能導致顯著的效能提升。")
32
7.1 基本功能(Basic Mechanism)
")
33
7.2 記憶體對映 I/O (Memory-Mapped I/O)
")
34
8.核心記憶體的配置(Allocating Kernel Memory)
8.1 夥伴系統(Buddy System) 夥伴系統的一個優點是利用一種稱為合併(coalescing)的技巧,可以將毗連的夥伴聯合形成更大的區段。在圖中當核心釋放配置的CL單位,系統能合併 CL和 CR 成為一個64KB的區段。區段BL能繼續與它的夥伴BR一起合併形成一個 128KB的區段。最後,我們能以最初的256KB的區段作為結束。
 夥伴系統的一個優點是利用一種稱為合併(coalescing)的技巧,可以將毗連的夥伴聯合形成更大的區段。在圖中當核心釋放配置的CL單位,系統能合併 CL和 CR 成為一個64KB的區段。區段BL能繼續與它的夥伴BR一起合併形成一個 128KB的區段。最後,我們能以最初的256KB的區段作為結束。")
35
8.2 平板配置(Slab Allocation)
配置核心記憶體的第二個策略稱為平版配置(slab allocation)。平板由一個或更多個實體連續分頁組成。一個快取 (cache)由一個或更多個平板所組成。
。平板由一個或更多個實體連續分頁組成。一個快取 (cache)由一個或更多個平板所組成。")
36
9.其它考慮的因素(Other Considerations)
9.1 預先分頁(Prepaging) 在純需求分頁系統中的一項明顯特徵就是當一個行程開始執行的時候就會出現一大堆分頁錯誤。這個情況乃是因為嘗試要將起始局部區域 (initial locality)載入記憶體所造成的。相同的事情可能在其它時間發生。例如,當一個被置換出去的行程想要重新啟動的時候,它所有的頁都存在備用儲存體中並且必須藉著各個分頁錯誤才能把所有的頁都載入記憶體。 預先分頁 (prepaging)就是想要防止這種高度的起始分頁。其策略就是把所有需要的頁在同一時間都載入記憶體中。 9.2 分頁的大小(Page Size) 對於現有機器的作業系統設計師來說,他們很少有能力對分頁大小做選擇的機會。但是,當要設計新機器的時候,就必須對於最佳頁的大小做一個決定。 有些因素 (內部斷裂,局部區域)贊成使用較小的頁,然而其它因素 (分頁表大小,I/O時間)則贊成使用較大的頁。
 在純需求分頁系統中的一項明顯特徵就是當一個行程開始執行的時候就會出現一大堆分頁錯誤。這個情況乃是因為嘗試要將起始局部區域 (initial locality)載入記憶體所造成的。相同的事情可能在其它時間發生。例如,當一個被置換出去的行程想要重新啟動的時候,它所有的頁都存在備用儲存體中並且必須藉著各個分頁錯誤才能把所有的頁都載入記憶體。 預先分頁 (prepaging)就是想要防止這種高度的起始分頁。其策略就是把所有需要的頁在同一時間都載入記憶體中。 9.2 分頁的大小(Page Size) 對於現有機器的作業系統設計師來說,他們很少有能力對分頁大小做選擇的機會。但是,當要設計新機器的時候,就必須對於最佳頁的大小做一個決定。 有些因素 (內部斷裂,局部區域)贊成使用較小的頁,然而其它因素 (分頁表大小,I/O時間)則贊成使用較大的頁。")
37
9.3 TLB範圍(Translation Look-aside Buffer Reach)
和擊中率相關的是一個相似的量尺:TLB範圍。TLB範圍是指TLB可以存取的記憶體數量,而且只是TLB的項數乘上分頁的大小。理想上,一個行程的工作組是存放在TLB中。如果不是的話,此行程將花費可觀的時間去解決分頁表 (而非TLB)的記憶體參考。 9.4 反轉分頁表(Inverted Page Tables) 這種分頁管理格式的目的是為了減少實體記憶體的數量,它必須知道虛擬對實體的記憶體位址轉換。藉由設立具有每一個實體記憶體分頁項的表,可以達成節省的目的。 用(Process-id, page-number)作指標。在每一個實體欄位中,可以藉由保存關於虛擬記憶體分頁的資訊之方法來儲存它。 反轉分頁表可以大量地減少儲存這些資訊所需的實體記憶體。不論如何,假如參考的分頁不能經常在記憶體之中時,反轉分頁表不再含有關於行程的邏輯位址空間的完整訊息是必須的。
的記憶體參考。 9.4 反轉分頁表(Inverted Page Tables) 這種分頁管理格式的目的是為了減少實體記憶體的數量,它必須知道虛擬對實體的記憶體位址轉換。藉由設立具有每一個實體記憶體分頁項的表,可以達成節省的目的。 用(Process-id, page-number)作指標。在每一個實體欄位中,可以藉由保存關於虛擬記憶體分頁的資訊之方法來儲存它。 反轉分頁表可以大量地減少儲存這些資訊所需的實體記憶體。不論如何,假如參考的分頁不能經常在記憶體之中時,反轉分頁表不再含有關於行程的邏輯位址空間的完整訊息是必須的。")
38
9.5 程式結構(Program Structure)
需求分頁被設計為對使用者程式來說十分簡明的型式。如果能對基本的需求分頁有所瞭解的話,將會對系統的性能上有很大的幫助。 data[0][0], data[1][0], data[2][0], …, data[127][0],data[0][1],data[1][1],…,data[127][127]

39
9.6 I/O交互上鎖(I/O Interlock)
當使用需求分頁法的時候,有時需要使它的某些頁被鎖在記憶體中。 當要將某些Frames資料儲存到I/O Device(如磁帶機),由於I/O速度較慢,必須先將此Frame上鎖,直到完成後,就可將此Frame解除,允許下次被Replacement。
,由於I/O速度較慢,必須先將此Frame上鎖,直到完成後,就可將此Frame解除,允許下次被Replacement。")




















>")