Download presentation
1
第 8 章 不确定性知识的表示与推理 8.1 不确定性处理概述 8.2 几种经典的不确定性推理模型 8.3 基于贝叶斯网络的概率推理
8.4 基于模糊集合与模糊逻辑的模糊推理 习题八

2
8.1 不确定性处理概述 8.1.1 不确定性及其类型 1. (狭义)不确定性
不确定性(uncertainty)就是一个命题(亦即所表示的事件)的真实性不能完全肯定, 而只能对其为真的可能性给出某种估计。 例如: 如果乌云密布并且电闪雷鸣, 则很可能要下暴雨。 如果头痛发烧, 则大概是患了感冒。 就是两个含有不确定性的命题。 当然, 它们描述的是人们的经验性知识。
就是一个命题(亦即所表示的事件)的真实性不能完全肯定, 而只能对其为真的可能性给出某种估计。 例如: 如果乌云密布并且电闪雷鸣, 则很可能要下暴雨。 如果头痛发烧, 则大概是患了感冒。 就是两个含有不确定性的命题。 当然, 它们描述的是人们的经验性知识。")
3
2. 不确切性(模糊性) 不确切性(imprecision)就是一个命题中所出现的某些言词其涵义不够确切, 从概念角度讲, 也就是其代表的概念的内涵没有硬性的标准或条件, 其外延没有硬性的边界, 即边界是软的或者说是不明确的。 例如, 小王是个高个子。 张三和李四是好朋友。 如果向左转, 则身体就向左稍倾。

4
这几个命题中就含有不确切性, 因为其中的言词“高”、 “好朋友”、“稍倾”等的涵义都是不确切的。我们无妨称这种涵义不确切的言词所代表的概念为软概念(soft concept)。
(注: 在模糊集合(fuzzy set)的概念出现以后, 有些文献中(包括本书的第一、 二版)将这里的不确切性称为模糊性(fuzziness), 将含义不确切的言词所代表的概念称为模糊概念, 但笔者认为将这种概念称为软概念似乎更为合理和贴切。 )
的概念出现以后, 有些文献中(包括本书的第一、 二版)将这里的不确切性称为模糊性(fuzziness), 将含义不确切的言词所代表的概念称为模糊概念, 但笔者认为将这种概念称为软概念似乎更为合理和贴切。 )")
5
3. 不完全性 不完全性就是对某事物来说, 关于它的信息或知识还不全面、不完整、不充分。例如,在破案的过程中, 警方所掌握的关于罪犯的有关信息, 往往就是不完全的。但就是在这种情况下, 办案人员仍能通过分析、 推理等手段而最终破案。

6
4. 不一致性 不一致性就是在推理过程中发生了前后不相容的结论; 或者随着时间的推移或者范围的扩大, 原来一些成立的命题变得不成立、 不适合了。例如, 牛顿定律对于宏观世界是正确的, 但对于微观世界和宇观世界却是不适合的。

7
8.1.2 不确定性知识的表示及推理 对于不确定性知识, 其表示的关键是如何描述不确定性。 一般的做法是把不确定性用量化的方法加以描述, 而其余部分的表示模式与前面介绍的(确定性)知识基本相同。对于不同的不确定性, 人们提出了不同的描述方法和推理方法。下面我们主要介绍(狭义)不确定性和不确切性知识的表示与推理方法,对于不完全性和不一致性知识的表示, 简介几种非标准逻辑。
知识基本相同。对于不同的不确定性, 人们提出了不同的描述方法和推理方法。下面我们主要介绍(狭义)不确定性和不确切性知识的表示与推理方法,对于不完全性和不一致性知识的表示, 简介几种非标准逻辑。")
8
我们只讨论不确定性产生式规则的表示。对于这种不确定性, 一般采用概率或信度来刻划。一个命题的信度是指该命题为真的可信程度, 例如,
(这场球赛甲队取胜, 0.9) 这里的0.9就是命题“这场球赛甲队取胜”的信度。它表示“这场球赛甲队取胜”这个命题为真(即该命题所描述的事件发生)的可能性程度是0.9。
 这里的0.9就是命题 这场球赛甲队取胜 的信度。它表示 这场球赛甲队取胜 这个命题为真(即该命题所描述的事件发生)的可能性程度是0.9。")
9
一般地, 我们将不确定性产生式规则表示为 A→(B, C(B|A)) (8-1) 其中C(B|A)表示规则的结论B在前提A为真的情况下为真的信度。 例如, 对上节中给出的两个不确定性命题, 若采用(8-1)式, 则可表示为 如果乌云密布并且电闪雷鸣, 则天要下暴雨(0.95)。 如果头痛发烧, 则患了感冒(0.8)。 这里的0.95和0.8就是对应规则结论的信度。它们代替了原命题中的“很可能”和“大概”, 可视为规则前提与结论之间的一种关系强度。
。 如果头痛发烧, 则患了感冒(0.8)。 这里的0.95和0.8就是对应规则结论的信度。它们代替了原命题中的 很可能 和 大概 , 可视为规则前提与结论之间的一种关系强度。")
10
信度一般是基于概率的一种度量,或者就直接以概率作为信度。例如, 在著名的专家系统MYCIN中的信度就是基于概率而定义的(详见8. 2
信度一般是基于概率的一种度量,或者就直接以概率作为信度。例如, 在著名的专家系统MYCIN中的信度就是基于概率而定义的(详见8.2.1确定性理论), 而在贝叶斯网络中就是直接以概率作为信度的。对于上面的(8-1)式, 要直接以概率作为信度则只需取C(B|A)=P(B|A)(P(B|A)为A真时B真的条件概率)即可。
, 而在贝叶斯网络中就是直接以概率作为信度的。对于上面的(8-1)式, 要直接以概率作为信度则只需取C(B|A)=P(B|A)(P(B|A)为A真时B真的条件概率)即可。 ")
11
基于不确定性知识的推理一般称为不确定性推理。 由于不确定性推理是基于不确定性知识的推理, 因此其结果仍然是不确定性的。 但对于不确定性知识, 我们是用信度即量化不确定性的方法表示的(实际是把它变成确定性的了), 所以, 不确定性推理的结果仍然应含有信度。 这就是说, 在进行不确定性推理时, 除了要进行符号推演操作外, 还要进行信度计算, 因此不确定性推理的一般模式可简单地表示为 不确定性推理=符号推演+信度计算

12
可以看出,不确定性推理与通常的确定性推理相比, 区别在于多了个信度计算过程。然而, 正是因为含有信度及其计算, 所以不确定性推理与通常的确定性推理就存在显著差别。
(1) 不确定性推理中规则的前件要与证据事实匹配成功, 不但要求两者的符号模式能够匹配(合一), 而且要求证据事实所含的信度必须达“标”, 即必须达到一定的限度。这个限度一般称为“阈值”。 (2) 不确定性推理中一个规则的触发,不仅要求其前提能匹配成功,而且前提条件的总信度还必须至少达到阈值。
 不确定性推理中规则的前件要与证据事实匹配成功, 不但要求两者的符号模式能够匹配(合一), 而且要求证据事实所含的信度必须达 标 , 即必须达到一定的限度。这个限度一般称为 阈值 。 (2) 不确定性推理中一个规则的触发,不仅要求其前提能匹配成功,而且前提条件的总信度还必须至少达到阈值。")
13
(3) 不确定性推理中所推得的结论是否有效, 也取决于其信度是否达到阈值。
(4) 不确定性推理还要求有一套关于信度的计算方法, 包括“与”关系的信度计算、“或”关系的信度计算、“非”关系的信度计算和推理结果信度的计算等等。 这些计算也就是在推理过程中要反复进行的计算。 总之, 不确定性推理要涉及信度、阈值以及信度的各种计算和传播方法的定义和选取。 所有这些就构成了所谓的不确定性推理模型。
 不确定性推理还要求有一套关于信度的计算方法, 包括 与 关系的信度计算、 或 关系的信度计算、 非 关系的信度计算和推理结果信度的计算等等。 这些计算也就是在推理过程中要反复进行的计算。 总之, 不确定性推理要涉及信度、阈值以及信度的各种计算和传播方法的定义和选取。 所有这些就构成了所谓的不确定性推理模型。")
14
8.1.3 不确切性知识的表示及推理 关于不确切性知识, 现在一般用模糊集合与模糊逻辑的理论和方法来处理。这种方法一般是用模糊集合给相关的概念或者说语言值(主要是软概念或者软语言值)建模。然而, 我们发现, 对于有些问题也可用程度化的方法来处理。本节就先简单介绍这种程度化方法, 而将模糊集合与模糊逻辑安排在8.4一节专门介绍。 所谓程度就是一个命题中所描述事物的特征(包括属性、 状态或关系等)的强度。程度化方法就是给相关语言特征值(简称语言值)附一个称为程度的参数, 以确切刻画对象的特征。例如, 我们用 刻画一个人“胖”的程度。 (胖, 0.9)
建模。然而, 我们发现, 对于有些问题也可用程度化的方法来处理。本节就先简单介绍这种程度化方法, 而将模糊集合与模糊逻辑安排在8.4一节专门介绍。 所谓程度就是一个命题中所描述事物的特征(包括属性、 状态或关系等)的强度。程度化方法就是给相关语言特征值(简称语言值)附一个称为程度的参数, 以确切刻画对象的特征。例如, 我们用. 刻画一个人 胖 的程度。 (胖, 0.9)")
15
(LV, d) 我们把这种附有程度的语言值称为程度语言值。 其一般形式为 其中, LV为语言值, d为程度, 即
(<语言值>, <程度>) 可以看出, 程度语言值实际是通常语言值的细化, 其中的<程度>一项是对对象所具有的属性值的精确刻画。 至于程度如何取值, 可因具体属性和属性值而定。例如可先确定一个标准对象, 规定其具有相关属性值的程度为1, 然后再以此标准来确定其他对象所具有该属性值的程度。这样, 一般来说, 程度的取值范围就是实数区间[α,β](α≤0,β≥1)。
 可以看出, 程度语言值实际是通常语言值的细化, 其中的<程度>一项是对对象所具有的属性值的精确刻画。 至于程度如何取值, 可因具体属性和属性值而定。例如可先确定一个标准对象, 规定其具有相关属性值的程度为1, 然后再以此标准来确定其他对象所具有该属性值的程度。这样, 一般来说, 程度的取值范围就是实数区间[α,β](α≤0,β≥1)。")
16
1. 程度元组 一般形式如下: (<对象>, <属性>, (<语言属性值>, <程度>)) 例8.1 我们用程度元组将命题“这个苹果比较甜”表示为 (这个苹果, 味道, (甜, 0.95)) 其中的0.95就代替“比较”而刻画了苹果“甜”的程度。

17
2. 程度谓词 谓词也就是语言值。按照前面程度语言值的做法, 我们给谓词也附以程度, 即细化为程度谓词, 以精确刻画相应个体对象的特征。 根据谓词的形式特点, 我们将程度谓词书写为 Pd 或 dP 其中, P表示谓词, d表示程度; Pd为下标表示法, dP为乘法表示法。

18
例8.2 采用程度谓词, 则 (1) 命题“雪是白的”可表示为 white1.0(雪) 或 1.0white(雪) (2) 命题“张三和李四是好朋友”可表示为 friends1.15(张三, 李四) 或 1.15 friends(张三, 李四)
 命题 雪是白的 可表示为 white1.0(雪) 或 1.0white(雪) (2) 命题 张三和李四是好朋友 可表示为 friends1.15(张三, 李四) 或 1.15 friends(张三, 李四)")
19
3. 程度框架 含有程度语言值的框架称为程度框架。 例8.3 下面是一个描述大枣的程度框架。 框架名: <大枣> 类属: (<干果>, 0.8) 形状: (圆, 0.7) 颜色: (红, 1.0) 味道: (甘, 1.1) 用途: 范围: (食用, 药用) 缺省: 食用
 味道: (甘, 1.1) 用途: 范围: (食用, 药用) 缺省: 食用.")
20
4. 程度语义网 含有程度语言值的语义网称为程度语义网。 例8.4 图8-1所示是一个描述狗的程度语义网。 图 8-1 程度语义网示例

21
5. 程度规则 含有程度语言值的规则称为程度规则。 其一般形式为 (Oi, Fi, (LVi, xi)) → (O, F, (LV, D(x1, x2,…, xn))) (8-2) 其中,Oi, O表示对象,Fi, F表示特征,LVi, LV表示语言特征值,x, D(x1, x2,…, xn )表示程度,D(x1, x2,…, xn )为x1, x2,…, xn 的函数。我们称其为规则的程度函数。
表示程度,D(x1, x2,…, xn )为x1, x2,…, xn 的函数。我们称其为规则的程度函数。")
22
例8.5 设有规则: 如果某人鼻塞、 头疼并且发高烧,则该人患了重感冒。 我们用程度规则描述如下:
(某人, 症状, (鼻塞,x))∧(某人,症状,(头疼, y))∧(患者, 症状, (发烧,z))→ (该人, 患病, (感冒, 1.2(0.3x+0.2y+0.5z))) 程度规则的关键是程度函数。 一个基本的方法就是采用机器学习(如神经网络学习)。 这需要事先给出一些含有具体程度值的实例规则, 学习作为样本。
)∧(某人,症状,(头疼, y))∧(患者, 症状, (发烧,z))→ (该人, 患病, (感冒, 1.2(0.3x+0.2y+0.5z))) 程度规则的关键是程度函数。 一个基本的方法就是采用机器学习(如神经网络学习)。 这需要事先给出一些含有具体程度值的实例规则, 学习作为样本。")
23
由上述程度化知识表示方法可以看出, 基于这种知识表示的推理, 同一般的确切推理相比,多了一个程度计算的手续。 就是说, 推理时, 除了要进行符号推演操作外, 还要进行程度计算。 我们称这种附有程度计算的推理为程度推理。程度推理的一般模式为 程度推理=符号推演+程度计算 这一模式类似于前面的信度推理模式。所以,程度推理也应该有程度阈值,从而在推理过程中, 规则的前件要与证据事实匹配成功, 不但要求两者的符号模式能够匹配(合一), 而且要求证据事实所含的程度必须达到阈值; 所推得的结论是否有效, 也取决于其程度是否达到阈值。
, 而且要求证据事实所含的程度必须达到阈值; 所推得的结论是否有效, 也取决于其程度是否达到阈值。")
24
需要指出的是, 程度语言值中的程度也可以转化为命题的真度。 例如, 我们可以把命题“小明个子比较高”用程度元组表示为
(小明, 身高, (高, 0.9)) 这里的0.9是小明高的程度。 但也可以表示为 ((小明, 身高, 高), 真实性, (真, 0.9)) 这里的0.9是命题“小明个子高”的真实程度, 即真度。 这样, 我们就把小明的个子高的程度, 转化为命题“小明个子高”的真度, 而且二者在数值上是相等的。
) 这里的0.9是小明高的程度。 但也可以表示为 ((小明, 身高, 高), 真实性, (真, 0.9)) 这里的0.9是命题 小明个子高 的真实程度, 即真度。 这样, 我们就把小明的个子高的程度, 转化为命题 小明个子高 的真度, 而且二者在数值上是相等的。")
25
8.1.4 多值逻辑 我们知道,人们通常所使用的逻辑是二值逻辑。即对一个命题来说, 它必须是非真即假,反之亦然。但现实中一句话的真假却并非一定如此, 而可能是半真半假, 或不真不假,或者真假一时还不能确定等等。这样, 仅靠二值逻辑有些事情就无法处理,有些推理就无法进行。于是, 人们就提出了三值逻辑、 四值逻辑、多值逻辑乃至无穷值逻辑。例如, 模糊逻辑就是一种无穷值逻辑。下面我们介绍一种三值逻辑, 称为Kleene三值逻辑。

26
∧ T F U T F U T F U F F F U F U ∨ T F U T F U T T T T F U T T U P T F
在这种三值逻辑中, 命题的真值, 除了“真”、 “假”外, 还可以是“不能判定”。 其逻辑运算定义如下: ∧ T F U T F U T F U F F F U F U ∨ T F U T F U T T T T F U T T U P T F U 其中的第三个真值U的语义为“不可判定”,即不知道。显然, 遵循这种逻辑,就可在证据不完全不充分的情况下进行推理。

27
8.1.5 非单调逻辑 所谓“单调”,是指一个逻辑系统中的定理随着推理的进行而总是递增的。那么,非单调就是逻辑系统中的定理随着推理的进行而并非总是递增的, 就是说也可能有时要减少。传统的逻辑系统都是单调逻辑。但事实上,现实世界却是非单调的。例如,人们在对某事物的信息和知识不足的情况下,往往是先按假设或默认的情况进行处理, 但后来发现得到了错误的或者矛盾的结果, 则就又要撤消原来的假设以及由此得到的一切结论。这种例子不论在日常生活中还是在科学研究中都是屡见不鲜的。这就说明,人工智能系统中就必须引入非单调逻辑。

28
在非单调逻辑中, 若由某假设出发进行的推理中一旦出现不一致, 即出现与假设矛盾的命题, 那么允许撤消原来的假设及由它推出的全部结论。基于非单调逻辑的推理称为非单调逻辑推理, 或非单调推理。
非单调推理至少在以下场合适用: (1) 在问题求解之前, 因信息缺乏先作一些临时假设, 而在问题求解过程中根据实际情况再对假设进行修正。
 在问题求解之前, 因信息缺乏先作一些临时假设, 而在问题求解过程中根据实际情况再对假设进行修正。")
29
(2) 非完全知识库。随着知识的不断获取, 知识数目渐增,则可能出现非单调现象。例如, 设初始知识库有规则:
x(bird(x)→fly(x)) 即“所有的鸟都能飞”。 后来得到了事实: bird(ostrich) 即“驼鸟是一种鸟”。如果再将这条知识加入知识库则就出现了矛盾, 因为驼鸟不会飞。这就需要对原来的知识进行修改。
→fly(x)) 即 所有的鸟都能飞 。 后来得到了事实: bird(ostrich) 即 驼鸟是一种鸟 。如果再将这条知识加入知识库则就出现了矛盾, 因为驼鸟不会飞。这就需要对原来的知识进行修改。")
30
(3) 动态变化的知识库。常见的非单调推理有缺省推理(reasoning by default )和界限推理。由于篇幅所限, 这两种推理不再详细介绍, 有兴趣的读者可参阅有关专著。
 动态变化的知识库。常见的非单调推理有缺省推理(reasoning by default )和界限推理。由于篇幅所限, 这两种推理不再详细介绍, 有兴趣的读者可参阅有关专著。")
31
8.1.6 时序逻辑 对于时变性, 人们提出了时序逻辑。时序逻辑也称时态逻辑, 它将时间词(称为时态算子, 如“过去”, “将来”, “有时”, “一直”等)或时间参数引入逻辑表达式, 使其在不同的时间有不同的真值。从而可描述和解决时变性问题。 时序逻辑在程序规范(specifications)、程序验证以及程序语义形式化方面有重要应用, 因而它现已成为计算机和人工智能科学理论的一个重要研究课题。
或时间参数引入逻辑表达式, 使其在不同的时间有不同的真值。从而可描述和解决时变性问题。 时序逻辑在程序规范(specifications)、程序验证以及程序语义形式化方面有重要应用, 因而它现已成为计算机和人工智能科学理论的一个重要研究课题。")
32
8.2几种经典的不确定性推理模型 8.2.1 确定性理论 确定性理论是肖特里菲(E.H.Shortliffe)等于1975年提出的一种不精确推理模型,它在专家系统MYCIN中得到了应用。 1. 不确定性度量 CF(Certainty Factor), 称为确定性因子, (一般亦称可信度), 其定义为
, 称为确定性因子, (一般亦称可信度), 其定义为.")
33
其中, E表示规则的前提, H表示规则的结论, P(H)是H的先验概率, P(H|E)是E为真时H为真的条件概率。
当P(H|E)>P(H) 当P(H|E)=P(H) 当P(H|E)<P(H) (8-3) 其中, E表示规则的前提, H表示规则的结论, P(H)是H的先验概率, P(H|E)是E为真时H为真的条件概率。
>P(H) 当P(H|E)=P(H) 当P(H|E)<P(H) (8-3) 其中, E表示规则的前提, H表示规则的结论, P(H)是H的先验概率, P(H|E)是E为真时H为真的条件概率。")
34
这个可信度的表达式是什么意思呢?原来, CF是由称为信任增长度MB和不信任增长度MD相减而来的。 即
CF(H, E)=MB(H, E)-MD(H, E) 而 当P(H)=1 否则 当P(H)=0 否则
=MB(H, E)-MD(H, E) 而. 当P(H)=1. 否则. 当P(H)=0. 否则.")
35
当MB(H, E)>0, 表示由于证据E的出现增加了对H的信任程度。 当MD(H, E)>0, 表示由于证据E的出现增加了对H的不信任程度。由于对同一个证据E, 它不可能既增加对H的信任程度又增加对H的不信任程度, 因此, MB(H,E)与MD(H,E)是互斥的, 即 当MB(H,E)>0时, MD(H, E)=0; 当MD(H, E)>0时, MB(H, E)=0。
>0时, MD(H, E)=0; 当MD(H, E)>0时, MB(H, E)=0。")
36
下面是MYCIN中的一条规则: 如果 细菌的染色斑呈革兰氏阳性, 且 形状为球状,且 生长结构为链形, 则 该细菌是链球菌(0.7)。 这里的0.7就是规则结论的CF值。 最后需说明的是, 一个命题的信度可由有关统计规律、 概率计算或由专家凭经验主观给出。
。 这里的0.7就是规则结论的CF值。 最后需说明的是, 一个命题的信度可由有关统计规律、 概率计算或由专家凭经验主观给出。")
37
2. 前提证据事实总CF值计算 CF(E1∧E2∧…∧En)=min{CF(E1),CF(E2),…,CF(En)} CF(E1∨E2∨…∨En)=max{CF(E1),CF(E2),…,CF(En)} 其中E1,E2,…,En是与规则前提各条件匹配的事实。

38
3.推理结论CF值计算 CF(H)=CF(H,E)·max{0,CF(E)} 其中E是与规则前提对应的各事实,CF(H,E)是规则中结论的可信度,即规则强度。
=CF(H,E)·max{0,CF(E)} 其中E是与规则前提对应的各事实,CF(H,E)是规则中结论的可信度,即规则强度。")
39
4. 重复结论的CF值计算 若同一结论H分别被不同的两条规则推出, 而得到两个可信度CF(H)1和CF(H)2, 则最终的CF(H)为 CF(H)1+CF(H)2-CF(H)1·CF(H)2 当CF(H)1≥0,且CF(H)2≥0 CF(H)= CF(H)1+CF(H)2+CF(H)1·CF(H)2 当CF(H)1<0,且CF(H)2<0 CF(H)1+CF(H) 否则 (8-7)
1≥0,且CF(H)2≥0. CF(H)= CF(H)1+CF(H)2+CF(H)1·CF(H)2. 当CF(H)1<0,且CF(H)2<0. CF(H)1+CF(H)2 否则. (8-7)")
40
例8.6 设有如下一组产生式规则和证据事实,试用确定性理论求出由每一个规则推出的结论及其可信度。
规则: ①if At hen B(0.9) ②if B and C then D(0.8) ③if A and C then D(0.7) ④if B or D then E(0.6) 事实: A,CF(A)=0.8;C,CF(C)=0.9
 ②if B and C then D(0.8) ③if A and C then D(0.7) ④if B or D then E(0.6) 事实: A,CF(A)=0.8;C,CF(C)=0.9.")
41
解 规则①得:CF(B)=0.9×0.8=0.72 由规则②得:CF(D)1=0.8×min{0.72,0.9)=0.8×0.72=0.576 由规则③得:CF(D)2=0.7×min{0.8,0.9)=0.7×0.8=0.56 从而 CF(D)=CF(D)1+CF(D)2-CF(D)1×CF(D)2 =0.576+0.56-0.576×0.56= 由规则④得: CF(E)=0.6×max{0.72, }=0.6×0.72=0.432
=CF(D)1+CF(D)2-CF(D)1×CF(D)2. =0.576+0.56-0.576×0.56= 由规则④得: CF(E)=0.6×max{0.72, }=0.6×0.72=")
42
8.2.2 主观贝叶斯方法 主观贝叶斯方法是R.O.Duda等人于1976年提出的一种不确定性推理模型, 并成功地应用于地质勘探专家系统PROSPECTOR。主观贝叶斯方法是以概率统计理论为基础, 将贝叶斯(Bayesian)公式与专家及用户的主观经验相结合而建立的一种不确定性推理模型。 1. 不确定性度量 主观贝叶斯方法的不确定性度量为概率P(x),另外还有三个辅助度量: LS,LN和O(x),分别称充分似然性因子、必要似然性因子和几率函数。
,另外还有三个辅助度量: LS,LN和O(x),分别称充分似然性因子、必要似然性因子和几率函数。")
43
在PROSPECTOR中, 规则一般表示为
if E then (LS, LN) H (P(H ) ) 或者图示为 其中, E为前提(称为证据); H为结论(称为假设); P(H)为H为真的先验概率;LS, LN分别为充分似然性因子和必要似然性因子, 其定义为 (8-8)
 H (P(H ) ) 或者图示为. 其中, E为前提(称为证据); H为结论(称为假设); P(H)为H为真的先验概率;LS, LN分别为充分似然性因子和必要似然性因子, 其定义为. (8-8)")
44
(8-9) 前者刻画E为真时对H的影响程度,后者刻画E为假时对H的影响程度。 另外, 几率函数O(x)的定义为 (8-10) 它反映了一个命题为真的概率(或假设的似然性(likelihood))与其否定命题为真的概率之比, 其取值范围为[0, +∞]。
![(8-9) 前者刻画E为真时对H的影响程度,后者刻画E为假时对H的影响程度。 另外, 几率函数O(x)的定义为 (8-10) 它反映了一个命题为真的概率(或假设的似然性(likelihood))与其否定命题为真的概率之比, 其取值范围为[0, +∞]。](http://slidesplayer.com/slide/11305657/61/images/44/%288-9%29+%E5%89%8D%E8%80%85%E5%88%BB%E7%94%BBE%E4%B8%BA%E7%9C%9F%E6%97%B6%E5%AF%B9H%E7%9A%84%E5%BD%B1%E5%93%8D%E7%A8%8B%E5%BA%A6%2C%E5%90%8E%E8%80%85%E5%88%BB%E7%94%BBE%E4%B8%BA%E5%81%87%E6%97%B6%E5%AF%B9H%E7%9A%84%E5%BD%B1%E5%93%8D%E7%A8%8B%E5%BA%A6%E3%80%82+%E5%8F%A6%E5%A4%96%2C+%E5%87%A0%E7%8E%87%E5%87%BD%E6%95%B0O%28x%29%E7%9A%84%E5%AE%9A%E4%B9%89%E4%B8%BA%EE%80%86+%288-10%29+%E5%AE%83%E5%8F%8D%E6%98%A0%E4%BA%86%E4%B8%80%E4%B8%AA%E5%91%BD%E9%A2%98%E4%B8%BA%E7%9C%9F%E7%9A%84%E6%A6%82%E7%8E%87%28%E6%88%96%E5%81%87%E8%AE%BE%E7%9A%84%E4%BC%BC%E7%84%B6%E6%80%A7%28likelihood%29%29%E4%B8%8E%E5%85%B6%E5%90%A6%E5%AE%9A%E5%91%BD%E9%A2%98%E4%B8%BA%E7%9C%9F%E7%9A%84%E6%A6%82%E7%8E%87%E4%B9%8B%E6%AF%94%2C+%E5%85%B6%E5%8F%96%E5%80%BC%E8%8C%83%E5%9B%B4%E4%B8%BA%EF%BC%BB0%2C+%2B%E2%88%9E%EF%BC%BD%E3%80%82.jpg "(8-9) 前者刻画E为真时对H的影响程度,后者刻画E为假时对H的影响程度。 另外, 几率函数O(x)的定义为 (8-10) 它反映了一个命题为真的概率(或假设的似然性(likelihood))与其否定命题为真的概率之比, 其取值范围为[0, +∞]。")
45
下面我们介绍LS, LN的来历并讨论其取值范围和意义。由概率论中的贝叶斯公式
有 两式相除得

46
O(H|E)= O(H)LS 即 亦即 从而 由此式不难看出:
LS>1 当且仅当O(H|E)>O(H), 说明E以某种程度支持H; LS<1 当且仅当O(H|E)<O(H), 说明E以某种程度不支持H; LS=1 当且仅当O(H|E)=O(H), 说明E对H无影响。
>O(H), 说明E以某种程度支持H; LS<1 当且仅当O(H|E)<O(H), 说明E以某种程度不支持H; LS=1 当且仅当O(H|E)=O(H), 说明E对H无影响。")
47
O(H| E)= O(H) ·LN 将上面贝叶斯公式中E的换为 E, 用类似的过程即可得到 进而有 由此式不难看出:
LN>1当且仅当O(H| E)>O(H), 说明 E以某种程度支持H; LN<1当且仅当O(H|E)<O(H), 说明 E以某种程度不支持H; LN=1 当且仅当O(H| E)=O(H), 说明 E对H无影响。
>O(H), 说明 E以某种程度支持H; LN<1当且仅当O(H|E)<O(H), 说明 E以某种程度不支持H; LN=1 当且仅当O(H| E)=O(H), 说明 E对H无影响。")
48
因为一个证据E及其否定E不可能同时既支持又反对一个假设H, 因此任一条规则E→H的LS、LN 只能是下列情况中的一种:

49
需说明的是,在概率论中, 一个事件的概率是在统计数据的基础上计算出来的, 这通常需要大量的统计工作。为了避免大量的统计工作, 在主观贝叶斯方法中,一个命题的概率可由领域专家根据经验直接给出, 这种概率称为主观概率。 推理网络中每个陈述H的先验概率P(H)都是由专家直接给出的主观概率。同时, 推理网络中每条规则的LS、LN也需由专家指定。这就是说, 虽然前面已有LS、LN的计算公式, 但实际上领域专家并不一定真按公式计算规则的LS、LN, 而往往是凭经验给出。所以, 领域专家根据经验所提供的LS、LN通常不满足这一理论上的限制, 它们常常在承认E支持H(即LS>1)的同时却否认E反对H(即LN<1)。例如PROSPECTOR中有规则
都是由专家直接给出的主观概率。同时, 推理网络中每条规则的LS、LN也需由专家指定。这就是说, 虽然前面已有LS、LN的计算公式, 但实际上领域专家并不一定真按公式计算规则的LS、LN, 而往往是凭经验给出。所以, 领域专家根据经验所提供的LS、LN通常不满足这一理论上的限制, 它们常常在承认E支持H(即LS>1)的同时却否认E反对H(即LN<1)。例如PROSPECTOR中有规则")
50
说明专家认为:当CVR为真时,它支持FLE为真;但当CVR为假时, FLE的成立与否与CVR无关。 而按理论限制应有LS=800>1时, LN<1。这种主观概率与理论值不一致的情况称为主观概率不一致。 当出现这种情况时,并不是要求专家修改他提供的LS、 LN使之与理论模型一致(这样做通常比较困难), 而是使似然推理模型符合专家的意愿。
, 而是使似然推理模型符合专家的意愿。")
51
2. 推理中后验概率的计算 推理中后验概率的计算有以下几个公式: (8-11) 这是当证据E肯定存在即为真时,求假设H的后验概率的计算公式。其中的LS和P(H)由专家主观给出。 (8-12) 这是当证据E肯定不存在即为假时,求假设H的后验概率的计算公式。其中的LN和P(H)由专家主观给出。
由专家主观给出。")
52
由上面介绍的LS, LN的来历, 有 由此式即可推得公式(8-11)。 类似地也可得到公式(8-12)。 (8-13)
。 类似地也可得到公式(8-12)。 (8-13)")
53
这是当证据E自身也不确定时, 求假设H的后验概率的计算公式。其中的S为与E有关的观察,即能够影响E的事件。公式(8-13)是一个线性插值函数, 其中P(H|[E),P(H|E), P(E), P(H)为公式中的已知值(前两个由公式(8-11)、(8-12)计算而得, 后两个由专家直接给出); P(E|S)为公式中的变量(其值由用户给出或由前一个规则S→E求得)。这个插值函数的几何解释如图8-2所示。
是一个线性插值函数, 其中P(H|[E),P(H|E), P(E), P(H)为公式中的已知值(前两个由公式(8-11)、(8-12)计算而得, 后两个由专家直接给出); P(E|S)为公式中的变量(其值由用户给出或由前一个规则S→E求得)。这个插值函数的几何解释如图8-2所示。")
54
图 8-2 线性插值函数的几何解释

55
由公式(8-13)和图8-2可以看出, 当证据E自身也不确定时, 假设H的后验概率是通过已知的,P(H|[E), P(E),P(H)和用户给出的概率P(E|S)或前一个规则S→E的中间结果而计算的。这也就是把原来的后验概率P(H|E)用后验概率P(H|S)来代替了。 这相当于把S对E的影响沿规则的弧传给了H。
和图8-2可以看出, 当证据E自身也不确定时, 假设H的后验概率是通过已知的,P(H|[E), P(E),P(H)和用户给出的概率P(E|S)或前一个规则S→E的中间结果而计算的。这也就是把原来的后验概率P(H|E)用后验概率P(H|S)来代替了。 这相当于把S对E的影响沿规则的弧传给了H。")
56
公式(8-13)是这样得来的: 起初, Duda等人证明了在某种合理的假定下, P(H|S)是P(E|S)的线性函数, 并且满足:
P(H|E) 当P(H| S)=1时; P(H|S)= 当P(H| S)=0时; P(H) 当P(H|S)= P(E)时 但由于P(E), P(H)都是专家给出的主观概率, 它们常常是不一致的, 因此当P(E|S)=P(E)时, 按线性函数计算出的理论值P(H|S)=Pc(H)通常并不是专家给出的先验概率P(H)。当P(E)<P(E|S)<Pc(E)时, 按专家的意图应有P(H|S)>P(H), 但按线性函数计算却是P(H|S)<P(H), 这与专家本意相矛盾。为了解决这一问题, 就采用了上述分段线性插值函数计算P(H|S)。
 当P(H| S)=1时; P(H|S)= 当P(H| S)=0时; P(H) 当P(H|S)= P(E)时. 但由于P(E), P(H)都是专家给出的主观概率, 它们常常是不一致的, 因此当P(E|S)=P(E)时, 按线性函数计算出的理论值P(H|S)=Pc(H)通常并不是专家给出的先验概率P(H)。当P(E)<P(E|S)<Pc(E)时, 按专家的意图应有P(H|S)>P(H), 但按线性函数计算却是P(H|S)<P(H), 这与专家本意相矛盾。为了解决这一问题, 就采用了上述分段线性插值函数计算P(H|S)。")
57
3. 多证据的总概率合成 对于多条件前提的规则,应用公式(8-11)、(8-12)、(8-13)求结论的后验概率时,先要计算与其前提中对应证据事实的总概率。假设已知P(E1|S),P(E2|S), …,P(En|S), 并且诸Ei是相互独立的, 则由概率的加法公式和乘法公式应有:
、(8-12)、(8-13)求结论的后验概率时,先要计算与其前提中对应证据事实的总概率。假设已知P(E1|S),P(E2|S), …,P(En|S), 并且诸Ei是相互独立的, 则由概率的加法公式和乘法公式应有: .")
58
但一条规则的前提中各条件Ei之间通常不满足独立要求,因此用这两个公式计算出的后验概率往往偏高或偏低。所以,主观贝叶斯方法中采用了如下公式:
P(E1∨E2∨…∨En|S)= P(Ei|S) P(E1∧E2∧…∧En|S)= P(Ei|S) (8-14) (8-15) 另外, 根据全概率公式有 P( |S)=1-P(E|S) (8-16) 这样, 通过公式(8-14)、(8-15)、(8-16), 就可以计算由 、 ∧、 ∨任意连接起来的组合证据的后验概率。
= P(Ei|S) P(E1∧E2∧…∧En|S)= P(Ei|S) (8-14) (8-15) 另外, 根据全概率公式有. P( |S)=1-P(E|S) (8-16) 这样, 通过公式(8-14)、(8-15)、(8-16), 就可以计算由 、 ∧、 ∨任意连接起来的组合证据的后验概率。")
59
4. 相同结论的后验概率合成 设推理网络中有多条以H为结论的规则: 如果有证据E1,E2,…,En相互独立,它们的观察依次为S1,S2,…, Sn, 则这种情况下H的后验概率可视为在E1, E2, …, En的综合作用下的后验概率。

60
O(H|E)= O(H)LS O(H|E)= O(H) LN
其求法是先用式(8-11)、(8-12)、(8-13)式分别求出在单个证据Ei的作用下H的后验概率P(H|Si)(1≤i≤n), 再利用公式(8-10)把概率P(H)和P(H|Si)转换为几率O(H)和O(H|Si), 或者直接运用公式 O(H|E)= O(H)LS (8-17) O(H|E)= O(H) LN (8-18) 得到几率O(H|Si); 然后用下面的公式 (8-19)
、(8-12)、(8-13)式分别求出在单个证据Ei的作用下H的后验概率P(H|Si)(1≤i≤n), 再利用公式(8-10)把概率P(H)和P(H|Si)转换为几率O(H)和O(H|Si), 或者直接运用公式. O(H|E)= O(H)LS. (8-17) O(H|E)= O(H) LN. (8-18) 得到几率O(H|Si); 然后用下面的公式. (8-19)")
61
来计算H的综合后验几率O(H|S1∧S2∧…∧Sn);最后再用公式。
(8-20) 将O(H|S1∧S2∧…∧Sn)转换为后验概率P(H|S1∧S2∧…∧Sn)。
 将O(H|S1∧S2∧…∧Sn)转换为后验概率P(H|S1∧S2∧…∧Sn)。")
62
5. 推理举例 例8.7 设有规则if E1 then (100, 0.01) H1 (P(H1)=0.6),并已知证据E1肯定存在,求H1的后验概率P(H1| E1)。 解 由于证据E1肯定存在,因此可用公式(4)计算P(H1| E1)。于是有
 H1 (P(H1)=0.6),并已知证据E1肯定存在,求H1的后验概率P(H1| E1)。 解 由于证据E1肯定存在,因此可用公式(4)计算P(H1| E1)。于是有.")
63
例8. 8 设有规则if E1 then (100, 0. 01) H1 (P(H1)=0
例8.8 设有规则if E1 then (100, 0.01) H1 (P(H1)=0.6),并已知证据E1肯定不存在,求H1的后验概率P(H1|﹃E1)。 解 由于证据E1肯定不存在,因此可用公式(5)计算P(H1|E1)。于是有
 H1 (P(H1)=0.6),并已知证据E1肯定不存在,求H1的后验概率P(H1|﹃E1)。 解 由于证据E1肯定不存在,因此可用公式(5)计算P(H1|E1)。于是有.")
64
例3 设有规则if E1 then (100, 0. 01) H1 (P(H1)=0. 6),并已知证据E1不确定,但P(E1| S1)=0
例3 设有规则if E1 then (100, 0.01) H1 (P(H1)=0.6),并已知证据E1不确定,但P(E1| S1)=0.7,S1为影响E1的观察或条件,而E1的先验概率P(E1)=0.5,求H1的后验概率P(H1| E1)。 解 由于证据E1不确定,因此要用插值公式(6)计算P(H1|E1)。又由于 P(E1| S1)=0.7> P(E1)=0.5 所以应采用公式
 H1 (P(H1)=0.6),并已知证据E1不确定,但P(E1| S1)=0.7,S1为影响E1的观察或条件,而E1的先验概率P(E1)=0.5,求H1的后验概率P(H1| E1)。 解 由于证据E1不确定,因此要用插值公式(6)计算P(H1|E1)。又由于. P(E1| S1)=0.7> P(E1)=0.5. 所以应采用公式.")
65
即 其中P(H1 )、P(E1)已知,还需要计算E1肯定存在的情况下的P(H1| E1),我们直接采用前面例1的结果,于是有
、P(E1)已知,还需要计算E1肯定存在的情况下的P(H1| E1),我们直接采用前面例1的结果,于是有")
66
例8.10 设有规则 R1: if E1 then (200, 0.02) H R2: if E2 then (300, 1) H 已知证据E1和E2必然发生,并且P(H)=0.04,求H的后验概率P(H| E1 E2)。 解 由P(H)=0.04,有 O(H)=0.04/(1-0.04) 0.04 由R1有 O(H|E1)=LS1O(H)= =8
=0.04,有. O(H)=0.04/(1-0.04) 由R1有. O(H|E1)=LS1O(H)= =8.")
67
由R2有 O(H|E2)=LS2O(H)= =12 于是 从而
=LS2O(H)= =12 于是 从而")
68
证 据理论 1. 基本概念 1) 识别框架 识别框架就是所考察判断的事物或对象的集合,记为Ω。 例如下面的集合都是识别框架: Ω1={晴天,多云,刮风,下雨} Ω2={感冒,支气管炎,鼻炎} Ω3={红,黄,蓝} Ω4={80,90,100}

69
识别框架的子集就构成求解问题的各种解答。 这些子集也都可以表示为命题。证据理论就是通过定义在这些子集上的几种信度函数, 来计算识别框架中诸子集为真的可信度。 例如, 在医疗诊断中, 病人的所有可能的疾病集合构成识别框架, 证据理论就从该病人的种种症状出发, 计算病人患某类疾病(含多种病症并发)的可信程度。
的可信程度。")
70
2) 基本概率分配函数 定义4给定识别框架Ω,A∈2Ω,称m(A):2Ω→[0,1]是2Ω上的一个基本概率分配函数(Function of Basic Probability Assignment),若它满足 (1) m(Φ)=0;
![2) 基本概率分配函数 定义4给定识别框架Ω,A∈2Ω,称m(A):2Ω→[0,1]是2Ω上的一个基本概率分配函数(Function of Basic Probability Assignment),若它满足.](http://slidesplayer.com/slide/11305657/61/images/70/2%29+%E5%9F%BA%E6%9C%AC%E6%A6%82%E7%8E%87%E5%88%86%E9%85%8D%E5%87%BD%E6%95%B0+%E5%AE%9A%E4%B9%894%E7%BB%99%E5%AE%9A%E8%AF%86%E5%88%AB%E6%A1%86%E6%9E%B6%CE%A9%EF%BC%8CA%E2%88%882%CE%A9%EF%BC%8C%E7%A7%B0m%28A%29%EF%BC%9A2%CE%A9%E2%86%92%EF%BC%BB0%EF%BC%8C1%EF%BC%BD%E6%98%AF2%CE%A9%E4%B8%8A%E7%9A%84%E4%B8%80%E4%B8%AA%E5%9F%BA%E6%9C%AC%E6%A6%82%E7%8E%87%E5%88%86%E9%85%8D%E5%87%BD%E6%95%B0%28Function+of+Basic+Probability+Assignment%29%EF%BC%8C%E8%8B%A5%E5%AE%83%E6%BB%A1%E8%B6%B3..jpg "(1) m(Φ)=0;")
71
例8.11 设Ω={a,b,c},其基本概率分配函数为
m({a})=0.4 m({a,b})=0 m({a,c})=0.4 m({a,b,c})=0.2 m({b})=0 m({b,c})=0 m({c})=0 可以看出,基本概率分配函数之值并非概率。如 m({a})+m({b})+m({c})=0.4≠1
=0.4. m({a,b})=0. m({a,c})=0.4. m({a,b,c})=0.2. m({b})=0. m({b,c})=0. m({c})=0. 可以看出,基本概率分配函数之值并非概率。如. m({a})+m({b})+m({c})=0.4≠1.")
72
3.信任函数 定义2 给定识别框架Ω, , 称为2Ω上的信任函数(Function of Belief)。 信任函数表示对A为真的信任程度。所以,它就是证据理论的信度函数。信任函数也称为下限函数。
。 信任函数表示对A为真的信任程度。所以,它就是证据理论的信度函数。信任函数也称为下限函数。")
73
可以证明,信任函数有如下性质: (1)Bel(Φ)=0,Bel(Ω)=1,且对于2Ω中的任意元素A,有0≤Bel(A)≤1。 (2)信任函数为递增函数。即若 ,则Bel(A1)≤Bel(A2)。 (3)Bel(A)+Bel(A′)≤1 (A′为A的补集) 例8.12 由例8.11可知 Bel({a,b})=m({a})+m({b})+m({a,b})=0.4+0+0=0.4
Bel(A)+Bel(A′)≤1 (A′为A的补集) 例8.12 由例8.11可知. Bel({a,b})=m({a})+m({b})+m({a,b})=0.4+0+0=0.4.")
74
Pl({a,b})=1-Bel({a,b}′)=1-({c})=1-0=1
4)似真函数 定义3 Pl(A)=1-Bel(A′)(A∈2Ω,A′为A的补集)称为A的似真函数(Plausible function),函数值称为似真度。 似真函数又称为上限函数,它表示对A非假的信任程度。 例8.13 由例8.11、例8.12可知 Pl({a,b})=1-Bel({a,b}′)=1-({c})=1-0=1
似真函数. 定义3 Pl(A)=1-Bel(A′)(A∈2Ω,A′为A的补集)称为A的似真函数(Plausible function),函数值称为似真度。 似真函数又称为上限函数,它表示对A非假的信任程度。 例8.13 由例8.11、例8.12可知. Pl({a,b})=1-Bel({a,b}′)=1-({c})=1-0=1.")
75
[Bel(A), Pl(A)] 5) 信任区间 定义4 设Bel(A)和Pl(A)分别表示A的信任度和似真度, 称二元组
![[Bel(A), Pl(A)] 5) 信任区间 定义4 设Bel(A)和Pl(A)分别表示A的信任度和似真度, 称二元组](http://slidesplayer.com/slide/11305657/61/images/75/%EF%BC%BBBel%28A%29%2C+Pl%28A%29%EF%BC%BD+5%29+%E4%BF%A1%E4%BB%BB%E5%8C%BA%E9%97%B4%EE%80%84+%E5%AE%9A%E4%B9%894+%E8%AE%BEBel%28A%29%E5%92%8CPl%28A%29%E5%88%86%E5%88%AB%E8%A1%A8%E7%A4%BAA%E7%9A%84%E4%BF%A1%E4%BB%BB%E5%BA%A6%E5%92%8C%E4%BC%BC%E7%9C%9F%E5%BA%A6%2C+%E7%A7%B0%E4%BA%8C%E5%85%83%E7%BB%84.jpg "[Bel(A), Pl(A)] 5) 信任区间 定义4 设Bel(A)和Pl(A)分别表示A的信任度和似真度, 称二元组")
76
信任区间刻划了对A所持信任程度的上下限。 如:
(1)[1, 1]表示A为真(Bel(A)=Pl(A)=1)。 (2)[0, 0]表示A为假(Bel(A)=Pl(A)=0)。 (3)[0, 1]表示对A完全无知。因为Bel(A)=0, 说明对A不信任; 而Bel(A′) =1-Pl(A)=0, 说明对A′也不信任。 (4)[1/2, 1/2]表示A是否为真是完全不确定的。 (5)[0.25, 0.85]表示对A为真信任的程度为0.25;由Bel(A)=1-0.85=0.15表示对A′也有一定程度的信任。 由上面的讨论, Pl(A)-Bel(A)表示对A不知道的程度, 即既非对A 信任又非不信任的那部分。
[1, 1]表示A为真(Bel(A)=Pl(A)=1)。 (2)[0, 0]表示A为假(Bel(A)=Pl(A)=0)。 (3)[0, 1]表示对A完全无知。因为Bel(A)=0, 说明对A不信任; 而Bel(A′) =1-Pl(A)=0, 说明对A′也不信任。 (4)[1/2, 1/2]表示A是否为真是完全不确定的。 (5)[0.25, 0.85]表示对A为真信任的程度为0.25;由Bel(A)=1-0.85=0.15表示对A′也有一定程度的信任。 由上面的讨论, Pl(A)-Bel(A)表示对A不知道的程度, 即既非对A 信任又非不信任的那部分。")
77
似真函数Pl具有下述性质: (1) Pl(A)= ; (2) Pl(A)+Pl(A′)≥1; (3) Pl(A)≥Bel(A)。 这里, 性质(1)指出似真函数也可以由基本概率分配函数构造, 性质(2)指出A 的似真度与A′的似真度之和不小于1, 性质(3)指出A的似真度一定不小于A的信任度。
指出似真函数也可以由基本概率分配函数构造, 性质(2)指出A 的似真度与A′的似真度之和不小于1, 性质(3)指出A的似真度一定不小于A的信任度。")
78
6)Dempster 组合规则 1) 基本的组合规则。设m1(A)和m2(A)(A∈2Ω)是识别框架Ω基于不同证据的两个基本概率分配函数,则将二者可按下面的 Dempster组合规则合并: 该表达式一般称为m1与m2的正交和,并记为m=m1+m2。不难证明,组合后的m(A)满足
Dempster 组合规则 1) 基本的组合规则。设m1(A)和m2(A)(A∈2Ω)是识别框架Ω基于不同证据的两个基本概率分配函数,则将二者可按下面的 Dempster组合规则合并: 该表达式一般称为m1与m2的正交和,并记为m=m1+m2。不难证明,组合后的m(A)满足.")
79
例8.14 设识别框架Ω={a,b,c},若基于两组不同证据而导出的基本概率分配函数分别为:
m1({a})=0.4 m1({a,c})=0.4 m1({a,b,c})=0.2 m2({a})=0.6 m2({a,b,c})=0.4
=0.4. m1({a,c})=0.4. m1({a,b,c})=0.2. m2({a})=0.6. m2({a,b,c})=0.4.")
80
将m1和m2合并 =m1({a})m2({a})+m1({a})m2({a,b,c})+m1({a,c})m2({a}) +m1({a,b,c})m2({a})=0.76 m({a,c})=m1({a,c})m2({a,b,c})=0.16 m({a,b,c})=m1({a,b,c})m2({a,b,c})=0.08
=m1({a,b,c})m2({a,b,c})=0.08.")
81
2) 含冲突修正的组合规则 上述组合规则在某些情况下会有问题。考察两个不同的基本概率分配函数m1和m2,若存在集合B、C,B∩C=Φ,且m1(A)>0,m2(B)>0,这时使用 Dempster组合规则将导出 这与概率分配函数的定义冲突。这时,需将Dempster 组合规则进行如下修正:

82
其中K为规范数,且 规范数K的引入,实际上是把空集所丢弃的正交和按比例地补到非空集上,使m(A)仍然满足 如果所有交集均为空集,则出现K=∞,显然,Dempster组合规则在这种情况下将失去意义。
仍然满足 如果所有交集均为空集,则出现K=∞,显然,Dempster组合规则在这种情况下将失去意义。")
83
2. 基于证据理论的不确定性推理 基于证据理论的不确定性推理,大体可分为以下步骤: (1)建立问题的识别框架Ω; (2)给幂集2Ω定义基本概率分配函数; (3)计算所关心的子集A∈2Ω(即Ω的子集)的信任函数值Bel(A)、似真函数值Pl(A); (4)由Bel(A)、Pl(A)得出结论。
由Bel(A)、Pl(A)得出结论。")
84
例8.15 设有规则: (1)如果 流鼻涕 则 感冒但非过敏性鼻炎(0.9)或过敏性鼻炎但非感冒(0.1) (2)如果 眼发炎 则 感冒但非过敏性鼻炎(0.8)或过敏性鼻炎但非感冒(0.05)括号中的数字表示规则前提对结论的支持程度。又有事实: 小王流鼻涕(0.9) 小王眼发炎(0.4) 括号中的数字表示事实的可信程度。
 小王眼发炎(0.4) 括号中的数字表示事实的可信程度。")
85
我们用证据理论求解这一医疗诊断问题。 首先, 取识别框架 Ω={h1,h2,h3} 其中,h1表示“感冒但非过敏性鼻炎”,h2表示“过敏性鼻炎但非感冒”,h3表示“同时得了两种病”。

86
再取下面的基本概率分配函数: m1({h1})=规则前提事实可信度×规则结论可信度 =0.9×0.9=0.81 m1({h2})=0.9×0.1=0.09 m1({h1,h2,h3})=1- m1({h1})- m1({h2})= =0.1 m1(A)=0 (A为Ω的其他子集) m2({h1})=0.4×0.8=0.32m2({h2})=0.4×0.05=0.02m2({h1,h2,h3})=1-m2({h1})-m2({h2})= =0.66 m2(A)=0 (A为Ω的其他子集)
=1- m1({h1})- m1({h2})= =0.1 m1(A)=0 (A为Ω的其他子集) m2({h1})=0.4×0.8=0.32m2({h2})=0.4×0.05=0.02m2({h1,h2,h3})=1-m2({h1})-m2({h2})= =0.66. m2(A)=0 (A为Ω的其他子集)")
87
将两个概率分配函数合并 K=1/{1-[m1({h1})m2({h2})+m1({h2})m2({h1})]} =1/{1-[0.81× ×0.32]} =1/{ } =1/0.955 =1.05 m({h1})=K·[m1({h1})m2({h1})+m1({h1})m2({h1,h2,h3} +m1({h1,h2,h3})m2({h1})] =1.05×0.8258=0.87
![将两个概率分配函数合并 K=1/{1-[m1({h1})m2({h2})+m1({h2})m2({h1})]} =1/{1-[0.81× ×0.32]} =1/{ }](http://slidesplayer.com/slide/11305657/61/images/87/%E5%B0%86%E4%B8%A4%E4%B8%AA%E6%A6%82%E7%8E%87%E5%88%86%E9%85%8D%E5%87%BD%E6%95%B0%E5%90%88%E5%B9%B6+K%EF%BC%9D1%2F%7B1-%EF%BC%BBm1%28%7Bh1%7D%29m2%28%7Bh2%7D%29%EF%BC%8Bm1%28%7Bh2%7D%29m2%28%7Bh1%7D%29%EF%BC%BD%7D+%EF%BC%9D1%2F%7B1-%EF%BC%BB0.81%C3%97+%C3%970.32%EF%BC%BD%7D+%EF%BC%9D1%2F%7B+%7D.jpg "=1/ =1.05. m({h1})=K·[m1({h1})m2({h1})+m1({h1})m2({h1,h2,h3} +m1({h1,h2,h3})m2({h1})] =1.05×0.8258=0.87.")
88
m({h2})=K·[m1({h2})m2({h2})+m1({h2})m2({h1,h2,h3}
+m1({h1,h2,h3})m2({h2})] =1.05×0.0632=0.066 m({h1,h2,h3})=1-m({h1})-m({h2}) = =0.064 由信任函数求信任度 Bel({h1})=m({h1})=0.87 Bel({h2})=m({h2})=0.066
m2({h2})] =1.05×0.0632= m({h1,h2,h3})=1-m({h1})-m({h2}) = = 由信任函数求信任度. Bel({h1})=m({h1})=0.87. Bel({h2})=m({h2})=")
89
由似真函数求似真度 Pl({h1})=1-Bel({h1}′)=1-Bel({h2,h3}) =1-[m({h2}+m({h3}) =1-[0.066+0]=0.934 Pl({h2})=1-Bel({h2}′)=1-Bel({h1,h3}) =1-[m({h1})+m({h3})] =1-[0.87+0]=0.13
![由似真函数求似真度 Pl({h1})=1-Bel({h1}′)=1-Bel({h2,h3}) =1-[m({h2}+m({h3}) =1-[0.066+0]= Pl({h2})=1-Bel({h2}′)=1-Bel({h1,h3})](http://slidesplayer.com/slide/11305657/61/images/89/%E7%94%B1%E4%BC%BC%E7%9C%9F%E5%87%BD%E6%95%B0%E6%B1%82%E4%BC%BC%E7%9C%9F%E5%BA%A6+Pl%28%7Bh1%7D%29%EF%BC%9D1-Bel%28%7Bh1%7D%E2%80%B2%29%EF%BC%9D1-Bel%28%7Bh2%EF%BC%8Ch3%7D%29+%EF%BC%9D1-%EF%BC%BBm%28%7Bh2%7D%EF%BC%8Bm%28%7Bh3%7D%29+%EF%BC%9D1-%EF%BC%BB0.066%EF%BC%8B0%EF%BC%BD%EF%BC%9D+Pl%28%7Bh2%7D%29%EF%BC%9D1-Bel%28%7Bh2%7D%E2%80%B2%29%EF%BC%9D1-Bel%28%7Bh1%EF%BC%8Ch3%7D%29.jpg "=1-[m({h1})+m({h3})] =1-[0.87+0]=0.13.")
90
于是,最后得到: “感冒但非过敏性鼻炎”为真的信任度为0.87,非假的信任度为0.934; “过敏性鼻炎但非感冒”为真的信任度为0.066,非假的信任度为0.13。 所以,看来该患者是感冒了。 证据理论是被推崇的处理随机性不确定性的好方法,受到人工智能特别是专家系统领域的广泛重视,并且已为许多专家系统所采用。

91
8.3 基于贝叶斯网络的概率推理 8.3.1 什么是贝叶斯网络
贝叶斯网络是一种以随机变量为节点, 以条件概率为节点间关系强度的有向无环图(Directed Acyclic Graph, DAG)。 具体来讲就是, 贝叶斯网络的拓扑结构为一个不含回路的有向图, 图中的节点表示随机变量, 有向边描述了相关节点或变量之间的某种依赖关系, 而且每个节点附一个条件概率表(Condition Probability Table, CPT), 以刻画相关节点对该节点的影响, 条件概率可视为节点之间的关系强度。 有向边的发出端节点称为因节点(或父节点), 指向端节点称为果节点(或子节点)。
。 具体来讲就是, 贝叶斯网络的拓扑结构为一个不含回路的有向图, 图中的节点表示随机变量, 有向边描述了相关节点或变量之间的某种依赖关系, 而且每个节点附一个条件概率表(Condition Probability Table, CPT), 以刻画相关节点对该节点的影响, 条件概率可视为节点之间的关系强度。 有向边的发出端节点称为因节点(或父节点), 指向端节点称为果节点(或子节点)。")
92
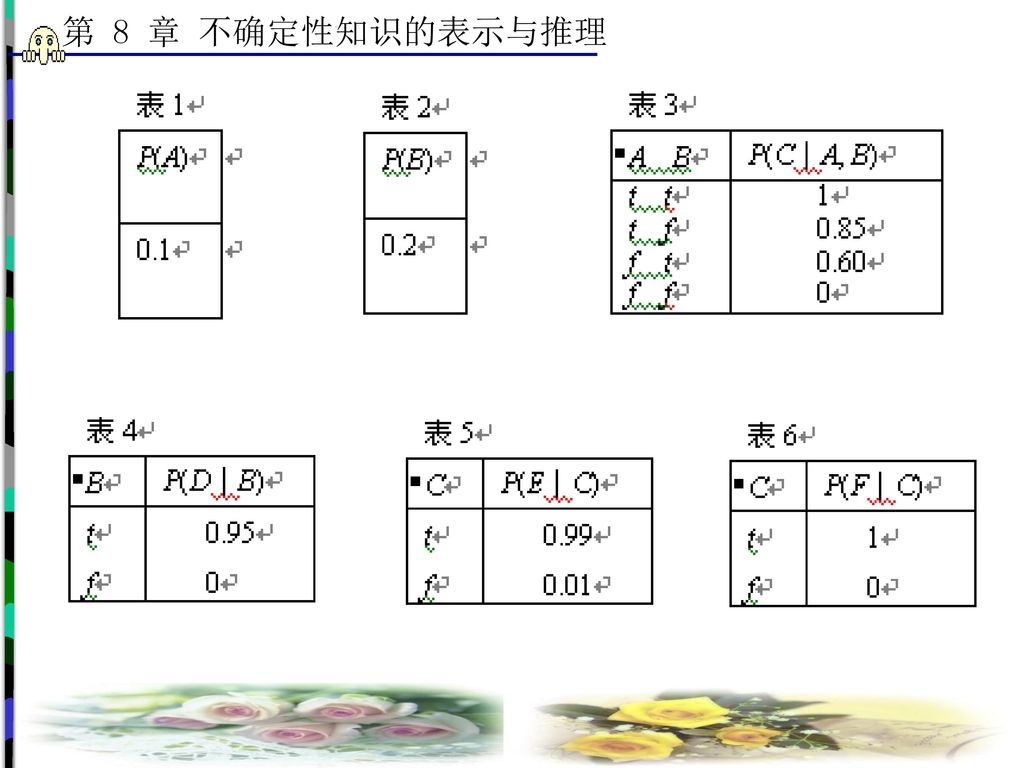
例如, 图8-3就是一个贝叶斯网络。其中A, B, C, D, E, F为随机变量; 5条有向边描述了相关节点或变量之间的关系; 每个节点的条件概率表如表1~表6所示。
图 8-3 贝叶斯网络示意图

94
贝叶斯网络中的节点一般可代表事件、对象、属性或状态; 有向边一般表示节点间的因果关系。 贝叶斯网络也称因果网络(causal network)、 信念网络(belief network)、概率网络(probability network)、 知识图(knowledge map)等。 它是描述事物之间因果关系或依赖关系的一种直观图形。所以, 贝叶斯网络可作为一种不确定性知识的表示形式和方法。
、 信念网络(belief network)、概率网络(probability network)、 知识图(knowledge map)等。 它是描述事物之间因果关系或依赖关系的一种直观图形。所以, 贝叶斯网络可作为一种不确定性知识的表示形式和方法。")
95
8.3.2 用贝叶斯网络表示不确定性知识 下面我们举例说明如何用贝叶斯网络表示不确定性知识。 医学告诉我们: 吸烟可能会患气管炎; 感冒也会引起气管发炎, 并还有发烧、头痛等症状; 气管炎又会有咳嗽或气喘等症状。我们把这些知识表示为一个贝叶斯网络(如图8 -4所示)。
。")
96
图 8-4 用贝叶斯网络表示医学知识

97
为了便于叙述, 我们将吸烟、感冒、气管炎、咳嗽、气喘分别记为: S, C, T, O, A。并将这几个变量的条件概率表用下面的概率表达式表示:
P(S)=0.4,P(¬S)=0.6; P(C)=0.8,P(¬C)=0.2; P(T | S, C)=0.35,P(T | ¬S, C)=0.25,P(T | S, ¬C)=0.011,P(T | ¬S, ¬C)=0.002; P(O | T)=0.85,P(O | ¬T)=0.15; P(A | T)=0.50,P(A | ¬T)=0.10。
=0.4,P(¬S)=0.6; P(C)=0.8,P(¬C)=0.2; P(T | S, C)=0.35,P(T | ¬S, C)=0.25,P(T | S, ¬C)=0.011,P(T | ¬S, ¬C)=0.002; P(O | T)=0.85,P(O | ¬T)=0.15; P(A | T)=0.50,P(A | ¬T)=0.10。")
98
8.3.3 基于贝叶斯网络的概率推理 根据贝叶斯网络的结构特征和语义特征, 对于网络中的一些已知节点(称为证据变量), 利用这种概率网络就可以推算出网络中另外一些节点(称为查询变量)的概率, 即实现概率推理。 具体来讲, 基于贝叶斯网络可以进行因果推理、 诊断推理、 辩解和混合推理。 这几种概率推理过程将涉及到联合概率(即乘法公式)和条件独立关系等概念。
和条件独立关系等概念。")
99
联合概率:设一个贝叶斯网络中全体变量的集合为X={x1, x2, …, xn}, 则这些变量的联合概率为
P(x1, x2,…, xn)= P(x1) P(x2|x1) P(x3|x1,x2) …P(xn|x1, x2,…, xn-1) (8-21) 条件独立: 贝叶斯网络中任一节点与它的非祖先节点和非后代节点都是条件独立的。 下面我们就以图8-4所示的贝叶斯网络为例, 介绍因果推理和诊断推理的一般方法。
= P(x1) P(x2|x1) P(x3|x1,x2) …P(xn|x1, x2,…, xn-1) (8-21) 条件独立: 贝叶斯网络中任一节点与它的非祖先节点和非后代节点都是条件独立的。 下面我们就以图8-4所示的贝叶斯网络为例, 介绍因果推理和诊断推理的一般方法。")
100
P(T | S) = P(T, C | S) + P(T, ¬C | S)
1. 因果推理 因果推理就是由原因到结果的推理, 即已知网络中的祖先节点而计算后代节点的条件概率。 这种推理是一种自上而下的推理。 以图8-4所示的贝叶斯网络为例, 假设已知某人吸烟(S), 计算他患气管炎(T)的概率P(T|S)。首先, 由于T还有另一个因节点──感冒(C), 因此我们可以对概率P(T|S)进行扩展, 得 P(T | S) = P(T, C | S) + P(T, ¬C | S) (8-22) 这是两个联合概率的和。意思是因吸烟而得气管炎的概率P(T|S)等于因吸烟而得气管炎且患感冒的概率P(T, C|S)与因吸烟而得气管炎且未患感冒的概率P(T, [C|S)之和。
, 计算他患气管炎(T)的概率P(T|S)。首先, 由于T还有另一个因节点──感冒(C), 因此我们可以对概率P(T|S)进行扩展, 得 P(T | S) = P(T, C | S) + P(T, ¬C | S) (8-22) 这是两个联合概率的和。意思是因吸烟而得气管炎的概率P(T|S)等于因吸烟而得气管炎且患感冒的概率P(T, C|S)与因吸烟而得气管炎且未患感冒的概率P(T, [C|S)之和。")
101
接着,对(8-22)式中的第一项P(T, C | S)作如下变形:
P(T, C | S)= P(T, C, S)/ P(S) (对P(T, C | S)逆向使用概率的乘法公式) = P(T | C, S)P(C, S)/ P(S) (对P(T, C, S)使用乘法公式) = P(T | C, S)P(C | S) (对P(C, S)/ P(S)使用乘法公式) = P(T | C, S)P(C) (因为C与S条件独立) 同理可得(8-22)式中的第二项 P(T, ¬C | S)= P(T | ¬C, S)P(¬C) 于是 P(T | S) = P(T | C, S)P(C)+ P(T | ¬C, S)P(¬C) (8-23)
= P(T, C, S)/ P(S) (对P(T, C | S)逆向使用概率的乘法公式) = P(T | C, S)P(C, S)/ P(S) (对P(T, C, S)使用乘法公式) = P(T | C, S)P(C | S) (对P(C, S)/ P(S)使用乘法公式) = P(T | C, S)P(C) (因为C与S条件独立) 同理可得(8-22)式中的第二项. P(T, ¬C | S)= P(T | ¬C, S)P(¬C) 于是. P(T | S) = P(T | C, S)P(C)+ P(T | ¬C, S)P(¬C) (8-23)")
102
可以看出, 这个等式右端的概率值在图8-4中的CPT中已给出, 即都为已知。 现在, 将这些概率值代入(8-23)式右端便得
P(T | S) = =0.2822 即吸烟可引起气管炎的概率为0.2822。
 = = 即吸烟可引起气管炎的概率为0.2822。")
103
由这个例子我们给出因果推理的一个种思路和方法:
(1) 首先, 对于所求的询问节点的条件概率,用所给证据节点和询问节点的所有因节点的联合概率进行重新表达。 (2) 然后, 对所得表达式进行适当变形, 直到其中的所有概率值都可以从问题贝叶斯网络的CPT中得到。 (3) 最后, 将相关概率值代入概率表达式进行计算即得所求询问节点的条件概率。
 首先, 对于所求的询问节点的条件概率,用所给证据节点和询问节点的所有因节点的联合概率进行重新表达。 (2) 然后, 对所得表达式进行适当变形, 直到其中的所有概率值都可以从问题贝叶斯网络的CPT中得到。 (3) 最后, 将相关概率值代入概率表达式进行计算即得所求询问节点的条件概率。")
104
2. 诊断推理 诊断推理就是由结果到原因的推理, 即已知网络中的后代节点而计算祖先节点的条件概率。这种推理是一种自下而上的推理。 诊断推理的一般思路和方法是,先利用贝叶斯公式将诊断推理问题转化为因果推理问题; 再用因果推理的结果, 导出诊断推理的结果。 我们仍以图8-4所示的贝叶斯网络为例, 介绍诊断推理。 假设已知某人患了气管炎(T), 计算他吸烟(S)的后验概率P(S|T)。
, 计算他吸烟(S)的后验概率P(S|T)。")
105
由贝叶斯公式, 有 由上面的因果推理知, P(T | S) = P(T, C | S) + P(T, ¬C | S) =P(T | C, S)P(C)+ P(T | ¬C, S)P(¬C) = (诸概率由图8-4的条件概率表得) =0.2822 又 P(S)= (由图8-4的条件概率表)
=0.6 (由图8-4的条件概率表)")
106
从而 同理, 由因果推理方法有 P(T | ¬S) = P(T, C | ¬S) + P(T, ¬C | ¬S) = P(T | C, ¬S)P(C)+ P(T | ¬C, ¬S)P(¬C) = (诸概率由图8-4的条件概率表得) =0.2004

107
从而 因为 P(S|T)+P(﹁S|T)=1 所以 解之得 P(T) =
+P(﹁S|T)=1 所以 解之得 P(T) =")
108
于是 即该人的气管炎是由吸烟导致的概率为 。

109
由上所述可以看出, 基于贝叶斯网络结构和条件概率, 我们不仅可以由祖先节点推算出后代节点的后验概率, 更重要的是利用贝叶斯公式还可以通过后代节点的概率反向推算出祖先节点的后验概率。 这正是称这种因果网络为贝叶斯网络的原因, 这也是贝叶斯网络的优越之处。 因为通过后代节点的概率反向推算出祖先节点的后验概率要用贝叶斯公式, 所以这种概率推理就称为基于贝叶斯网络的不确定性推理。 贝叶斯网络的建造涉及其拓扑结构和条件概率, 因此是一个比较复杂和困难的问题。一般需要知识工程师和领域专家的共同参与, 在实际中可能是反复交叉进行而不断完善的。 现在, 人们也采用机器学习的方法来解决贝叶斯网络的建造问题, 称为贝叶斯网络学习。

110
8.4 基于模糊集合与模糊逻辑的模糊推理 8.4.1 模糊集合 1. 模糊集合 定义1 设U是一个论域,U到区间[0, 1]的一个映射
8.4.1 模糊集合 1. 模糊集合 定义1 设U是一个论域,U到区间[0, 1]的一个映射 μ:U [0,1] 就确定了U的一个模糊子集A。映射μ称为A的隶属函数, 记为μA(u)。对于任意的u∈U, μA(u)∈[0, 1]称为u属于模糊子集A的程度, 简称隶属度。
![8.4 基于模糊集合与模糊逻辑的模糊推理 模糊集合 1. 模糊集合 定义1 设U是一个论域,U到区间[0, 1]的一个映射](http://slidesplayer.com/slide/11305657/61/images/110/8.4+%E5%9F%BA%E4%BA%8E%E6%A8%A1%E7%B3%8A%E9%9B%86%E5%90%88%E4%B8%8E%E6%A8%A1%E7%B3%8A%E9%80%BB%E8%BE%91%E7%9A%84%E6%A8%A1%E7%B3%8A%E6%8E%A8%E7%90%86+%E6%A8%A1%E7%B3%8A%E9%9B%86%E5%90%88%EE%80%84+1.+%E6%A8%A1%E7%B3%8A%E9%9B%86%E5%90%88%EE%80%84+%E5%AE%9A%E4%B9%891+%E8%AE%BE%EF%BC%B5%E6%98%AF%E4%B8%80%E4%B8%AA%E8%AE%BA%E5%9F%9F%2C%EF%BC%B5%E5%88%B0%E5%8C%BA%E9%97%B4%EF%BC%BB0%2C+1%EF%BC%BD%E7%9A%84%E4%B8%80%E4%B8%AA%E6%98%A0%E5%B0%84.jpg "8.4.1 模糊集合 1. 模糊集合 定义1 设U是一个论域,U到区间[0, 1]的一个映射. μ:U [0,1] 就确定了U的一个模糊子集A。映射μ称为A的隶属函数, 记为μA(u)。对于任意的u∈U, μA(u)∈[0, 1]称为u属于模糊子集A的程度, 简称隶属度。")
111
由定义, 模糊集合完全由其隶属函数确定, 即一个模糊集合与其隶属函数是等价的。
可以看出, 对于模糊集A,当U中的元素u的隶属度全为0时, 则A就是个空集;反之,当全为1时,A就是全集U;当仅取0和1时, A就是普通子集。 这就是说,模糊子集实际是普通子集的推广, 而普通子集就是模糊子集的特例。 论域U上的模糊集合A, 一般可记为

112
或 或 或 对于有限论域U, 甚至也可表示成

113
例8.16 设U={0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10}, 则 S1=0/0+0/1+0/2+0.1/3+0.2/4+0.3/5+0.5/6+0.7/7 +0.9/8+1/9+1/10 S2=1/0+1/1+1/2+0.8/3+0.7/4+0.5/5+0.4/6+0.2/7 +0/8+0/9+0/10 就是论域U的两个模糊子集, 它们可分别表示U中“大数的集合”和“小数的集合”。 可以看出, 上面“大数的集合”和“小数的集合”实际上是用外延法描述了“大”和“小”两个软概念。这就是说, 模糊集可作为软概念的数学模型。

114
例8.17 通常所说的“高个”、“矮个”、“中等个”就是三个关于身高的语言值。我们用模糊集合为它们建模。
取人类的身高范围[1.0, 3.0]为论域U, 在U上定义隶属函数μ矮(x)、μ中等(x)、μ高(x)如下(函数图像如图8-5所示)。 这三个隶属函数就确定了U上的三个模糊集合,它们也就是相应三个语言值的数学模型。
、μ中等(x)、μ高(x)如下(函数图像如图8-5所示)。 这三个隶属函数就确定了U上的三个模糊集合,它们也就是相应三个语言值的数学模型。")
116
图 8-5 身高论域上的模糊集“矮”、 “中等”、 “高”的隶属函数

117
2. 模糊关系 除了有些性质概念是模糊概念外,还存在不少模糊的关系概念。如“远大于”、“基本相同”、“好朋友”等就是一些模糊关系。模糊关系也可以用模糊集合表示。下面我们就用模糊子集定义模糊关系。 定义2 集合U1,U2,…,Un的笛卡尔积集U1×U2×…×Un的一个模糊子集 ,称为U1,U2,…,Un间的一个n元模糊关系。特别地,Un的一个模糊子集称为U上的一个n元模糊关系。

118
例8.18 设U={1,2,3,4,5},U上的“远大于”这个模糊关系可用模糊子集表示如下:
R远大于=0.1/(1,2)+0.4/(1,3)+0.7/(1,4)+1/(1,5)+0.2/(2,3)+0.4/(2,4)+0.7/(2,5)+0.1/(3,4)+0.4/(3,5)+0.1/(4,5) 就像通常的关系可用矩阵表示一样,模糊关系也可以用矩阵来表示。例如上面的“远大于”用矩阵可表示如下:
+0.4/(1,3)+0.7/(1,4)+1/(1,5)+0.2/(2,3)+0.4/(2,4)+0.7/(2,5)+0.1/(3,4)+0.4/(3,5)+0.1/(4,5) 就像通常的关系可用矩阵表示一样,模糊关系也可以用矩阵来表示。例如上面的 远大于 用矩阵可表示如下:")
119
表示模糊关系的矩阵一般称为模糊矩阵。

120
3. 模糊集合的运算 与普通集合一样, 也可定义模糊集合的交、并、补运算。 定义3 设A、B是X的模糊子集, A、B的交集A∩B、并集A∪B和补集A′, 分别由下面的隶属函数确定:

121
8.4.2 模糊逻辑 模糊逻辑是研究模糊命题的逻辑。 设n元谓词 表示一个模糊命题。定义这个模糊命题的真值为其中对象x1, x2, …, xn对模糊集合P的隶属度, 即 此式把模糊命题的真值定义为一个区间[0, 1]中的一个实数。 那么,当一个命题的真值为0时, 它就是假命题;为1时,它就是真命题;为0和1之间的某个值时, 它就是有某种程度的真(又有某种程度的假)的模糊命题。
的模糊命题。")
122
在上述真值定义的基础上, 我们再定义三种逻辑运算:
T(P∧Q)=min(T(P),T(Q)) T(P∨Q)=max(T(P),T(Q)) T(P)=1-T(P) 其中P和Q都是模糊命题。 这三种逻辑运算称为模糊逻辑运算。由这三种模糊逻辑运算所建立的逻辑系统就是所谓的模糊逻辑。 可以看出, 模糊逻辑是传统二值逻辑的一种推广。
=min(T(P),T(Q)) T(P∨Q)=max(T(P),T(Q)) T(P)=1-T(P) 其中P和Q都是模糊命题。 这三种逻辑运算称为模糊逻辑运算。由这三种模糊逻辑运算所建立的逻辑系统就是所谓的模糊逻辑。 可以看出, 模糊逻辑是传统二值逻辑的一种推广。")
123
8.4.3 模糊推理 模糊推理是基于不确切性知识(模糊规则)的一种推理。 例如 如果x小, 那么 y大。 x较小 y? 就是模糊推理所要解决的问题。 模糊推理是一种近似推理, 一般采用Zadeh提出的语言变量、 语言值、模糊集和模糊关系合成的方法进行推理。

124
1. 语言变量, 语言值 简单来讲, 语言变量就是我们通常所说的属性名, 如“年纪”就是一个语言变量。语言值是指语言变量所取的值,如“老”、“中”、“青”就是语言变量年纪的三个语言值。

125
2. 用模糊(关系)集合表示模糊规则 可以看出, 模糊命题中描述事物属性、状态和关系的语词, 就是这里的语言值。这些语言值许多都可用模糊集合表示。我们知道,一条规则实际是表达了前提中的语言值与结论中的语言值之间的对应关系(如上例中的规则就表示了语言值“小”与“大”的对应关系)。现在语言值又可用集合表示, 所以, 一条模糊规则实际就刻划了其前提中的模糊集与结论中的模糊集之间的一种对应关系。Zadeh认为, 这种对应关系是两个集合间的一种模糊关系, 因而它也可以表示为模糊集合。于是, 一条模糊规则就转换成了一个模糊集合。特别地, 对于有限集, 则就是一个模糊矩阵。
。现在语言值又可用集合表示, 所以, 一条模糊规则实际就刻划了其前提中的模糊集与结论中的模糊集之间的一种对应关系。Zadeh认为, 这种对应关系是两个集合间的一种模糊关系, 因而它也可以表示为模糊集合。于是, 一条模糊规则就转换成了一个模糊集合。特别地, 对于有限集, 则就是一个模糊矩阵。")
126
例如, 设有规则 如果x isA 那么 y isB 其中A、B是两个语言值。那么,按Zadeh的观点, A、B可表示为两个模糊集(我们仍以A、B标记);这个规则表示了A、B之间的一种模糊关系R,R也可以表示为一个模糊集。于是, 有 其中U、V分别为模糊集合A、B所属的论域,μR(ui,vj) (i, j=1, 2, …)是元素(ui, vj) 对于R的隶属度。
 (i, j=1, 2, …)是元素(ui, vj) 对于R的隶属度。")
127
现在的问题是,怎样求得隶属度μR(ui,vj) (i, j=1,2, …)呢? 对此,Zadeh给出了好多种方法, 其中具代表性的一种方法为
其中∧、 ∨分别代表取最小值和取最大值, 即min、max。 例如, 对于规则 如果 x小 那么 y大

128
令A、B分别表示“小”和“大”, 将它们表示成论域U、V上的模糊集, 设论域
定义 A=1/1+0.8/2+0.5/3+0/4+0/5 B=0/1+0/2+0.5/3+0.8/4+1/5

129
则 从而 R=0/(1, 1)+0/(1, 2)+0.5/(1, 3)+…+0.5/(2, 3)+…+1/(5, 5)
+0/(1, 2)+0.5/(1, 3)+…+0.5/(2, 3)+…+1/(5, 5)")
130
A→B=R 如果只取隶属度, 且写成矩阵形式, 则 R= 于是, 原自然语言规则就变成了一个数值集合(矩阵), 即
R= 于是, 原自然语言规则就变成了一个数值集合(矩阵), 即 A→B=R
, 即. A→B=R.")
131
3. 模糊关系合成 什么是模糊关系合成呢? 模糊关系合成也就是两个模糊关系复合为一个模糊关系。用集合的话来讲, 就是两个集合合成为一个集合。 如果是两个有限模糊集, 则其合成可以用矩阵运算来表示。下面就以有限模糊集为例,给出Zadeh的模糊关系合成法则。 设

132
则 其中 即,对R1第i行和R2第j列对应元素取最小,再对k个结果取最大, 所得结果就是R中第i行第j列处的元素。

133
例如:设 则

134
用隶属函数来表示, Zadeh的模糊关系合成法则就是下面的公式:
(8-24)
")
135
B′=A′·R 4. 基于关系合成的模糊推理 同规则一样, 证据事实也可表示成模糊矩阵(实际是向量)。 如, 把“比较小”表示为
4. 基于关系合成的模糊推理 同规则一样, 证据事实也可表示成模糊矩阵(实际是向量)。 如, 把“比较小”表示为 A′=1/1+1/2+0.5/3+0.2/4+0/5 =(1, 1, 0.5, 0.2, 0) 现在, 就可通过模糊关系的合成运算进行模糊推理了。其模式是 B′=A′·R (8-25) 其中,B′就是所推的结论。当然, 它仍是一个模糊集合。 如果需要,可再将它翻译为自然语言形式。
。 如, 把 比较小 表示为. A′=1/1+1/2+0.5/3+0.2/4+0/5. =(1, 1, 0.5, 0.2, 0) 现在, 就可通过模糊关系的合成运算进行模糊推理了。其模式是 B′=A′·R. (8-25) 其中,B′就是所推的结论。当然, 它仍是一个模糊集合。 如果需要,可再将它翻译为自然语言形式。")
136
用隶属函数表示, (8-25)式就是, 对于 y∈V (8-26)
式就是, 对于 y∈V (8-26)")
137
例8.19 现在我们就来解决本节开始提出的问题。即已知
(1) 如果x小,那么y大。 (2) x比较小。 问:y怎么样? 解 如前所述, 由(1)得
 如果x小,那么y大。 (2) x比较小。 问:y怎么样? 解 如前所述, 由(1)得.")
138
由(2)得 A′=(1, 1, 0.5, 0.2, 0) 从而 B′=A′·R=(0.5, 0.5, 0.5, 0.8, 1) 即 B′=0.5/1+0.5/2+0.5/3+0.8/4+1/5 可以解释为: y比较大。 推理模式(8-25)是肯定前件的模糊推理。 同理, 可得否定后件的模糊推理: A′=R·B′ (8-27)
是肯定前件的模糊推理。 同理, 可得否定后件的模糊推理: A′=R·B′ (8-27)")
139
可以看出, 这一模式可解决下面的问题: 设已知 (1) 如果x小, 那么 y大。 (2) y比较大。 问: x怎么样? 需说明的是,上面我们是把一条模糊规则表示为一个模糊关系(矩阵), 但实际问题中往往并非仅有一条规则,而是多条规则, 那该怎么办呢?所幸的是对于多条规则用模糊关系的合成法则仍然可化为一个模糊关系(矩阵)。
, 但实际问题中往往并非仅有一条规则,而是多条规则, 那该怎么办呢?所幸的是对于多条规则用模糊关系的合成法则仍然可化为一个模糊关系(矩阵)。")
140
5. 模糊推理的应用与发展 由上所述我们看到, 这种模糊推理实际是把推理变成了计算, 从而为不确定性推理开辟了一条新途径。特别是这种模糊推理很适合于控制。 用模糊推理原理构造的控制器称为模糊控制器。模糊控制器结构简单,可用硬件芯片实现,造价低、 体积小,现已广泛应用于控制领域。

141
事实上,自Zadeh1965年提出模糊集合的概念,特别是1974 年他又将模糊集引入推理领域开创了模糊推理技术以来, 模糊推理就成为一种重要的近似推理方法。特别是 20 世纪 90 年代初, 日本率先将模糊控制用于家用电器并取得成功, 引起了全世界的巨大反响和关注。之后, 欧美各国都竞相在这一领域展开角逐。时至今日,模糊技术已向自动化、计算机、 人工智能等领域全面推进。 模糊推理机、 模糊控制器、 模糊芯片、模糊计算机……应有尽有, 模糊逻辑、模糊语言、 模糊数据库、模糊知识库、模糊专家系统、模糊神经网络……层出不穷。可以说, 模糊技术现在已成为与面向对象、神经网络等并驾齐驱的高新技术之一。

142
如上所述的Zadeh给出的模糊推理方法, 一般称为模糊推理的CRI (Compositional Rule of Inference)法。 可以看出, CRI法的关键有两步:一步是由模糊规则导出模糊关系矩阵R, 一步是模糊关系的合成运算。在第一步中, Zadeh给出的求R的公式,其依据是把模糊规则A→B作为明晰规则A→B的推广,并且利用逻辑等价式 A→B=﹁A∨B=(﹁A∨B)∧(﹁A∨A) =A∧B∨﹁A 再运用他给出的模糊集合的交、并、补运算而得出来的。但仔细分析,不难看出, 这样做是存在问题的。因为,规则前提模糊集与结论模糊集元素之间的关系应该是函数关系,而不是逻辑关系, 但这里是用逻辑关系来处理函数关系的。
∧(﹁A∨A) =A∧B∨﹁A. 再运用他给出的模糊集合的交、并、补运算而得出来的。但仔细分析,不难看出, 这样做是存在问题的。因为,规则前提模糊集与结论模糊集元素之间的关系应该是函数关系,而不是逻辑关系, 但这里是用逻辑关系来处理函数关系的。")
143
正由于CRI方法缺乏坚实的理论依据, 所以常导致推理的失效。 为此, 包括Zadeh本人在内的许多学者, 都致力于模糊推理的理论和方法研究, 并提出了许许多多(不下数十种)的新方法。例如, Mandani推理法、TVR法、直接法、强度转移法、模糊计算逻辑推理法等等, 其中也有我国学者的重要贡献。但总的说来, 这些方法几乎还都是在逻辑框架下提出的一些隶属度变换或计算模型, 因而总存在这样或那样的问题或缺陷。因此, 模糊推理理论与技术仍然是人工智能中的重要课题。
的新方法。例如, Mandani推理法、TVR法、直接法、强度转移法、模糊计算逻辑推理法等等, 其中也有我国学者的重要贡献。但总的说来, 这些方法几乎还都是在逻辑框架下提出的一些隶属度变换或计算模型, 因而总存在这样或那样的问题或缺陷。因此, 模糊推理理论与技术仍然是人工智能中的重要课题。")
144
我们认为,一个语言值规则A→B概括了论域U中一个子域上的局部函数关系y=fAB(x), 表示了二维空间U×V中块点曲线Y=F(X)上的一个点(XA,YB),所以, 模糊推理实质是论域U上(模糊)大粒度函数的近似求值或空间U×V中(模糊)块点曲线的点坐标近似计算。
, 表示了二维空间U×V中块点曲线Y=F(X)上的一个点(XA,YB),所以, 模糊推理实质是论域U上(模糊)大粒度函数的近似求值或空间U×V中(模糊)块点曲线的点坐标近似计算。")
145
习 题 八 1. 何为不确定性? 不确定性有哪些类型? 2. 举一个随机产生式规则和一个模糊性产生式规则实例, 并用适当的度量表
1. 何为不确定性? 不确定性有哪些类型? 2. 举一个随机产生式规则和一个模糊性产生式规则实例, 并用适当的度量表 示之, 再用PROLOG语言表示之。 3. 写一个模糊框架和一个模糊语义网络, 并用PROLOG语言表示之。 4. 用模糊集表示天气的“热”, “冷”概念。 5. 什么是不精确推理?它与精确推理的区别何在? 对于不精确推理有哪些要解决的基本问题? 6. 何为不精确推理模型? 试给出你所知的不精确推理模型的名称。

146
7. 设有如下一组规则: r1: if E1 then E2(0.6) r2: if E2 and E3 then E4(0.8) r3: if E4 then H(0.7) r4: if E5 then H(0.9) 且已知 CF(E1)=0.5, CF(E3)=0.6,CF(E5)=0.4用确定性理论求CF(H)。
=0.5, CF(E3)=0.6,CF(E5)=0.4用确定性理论求CF(H)。")
147
8. 试用贝叶斯网络表示某设备(如电视机、 汽车、 计算机)的故障诊断方面的知识,并进行相应的因果推理和诊断推理。
的故障诊断方面的知识,并进行相应的因果推理和诊断推理。")
148
9. 设论域U=V={1, 2, 3, 4, 5}, “低”和“大”可分别用U, V上的两个模糊子集表示:
S低=1/1+0.8/2+0.5/3+0.2/4+0/5 S大=0/1+0.2/2+0.5/3+0.8/4+1/1 又设有模糊控制规则 “如果炉温偏低, 则就将风门开大。” 和已知事实 “炉温有些低” 若再给出定义 S有些低=1/1+1/2+0.6/3+0.3/4+0/5 请用Zadeh的CRI法进行模糊推理, 作出决策。

149
10. 一个旅行者在沙漠中行走, 想找水喝, 这时他发现路旁正好放着两瓶液体, 一个瓶子上写着“纯净水, 可信度: 0
10. 一个旅行者在沙漠中行走, 想找水喝, 这时他发现路旁正好放着两瓶液体, 一个瓶子上写着“纯净水, 可信度: 0.8”, 另一个瓶子上写着“纯净水, 隶属度: 0.7”。 问: 这位旅行者该喝哪一瓶“纯净水”? 为什么?




。本測驗共分為十個分測驗,請依照各分測 驗結果進行檢視與瞭解影響個人學習之因素。 每個分測驗依據全國高中二年級女生之常模共區分.>")





 的理解与运用 真 题 例 析 方 法 总 结 1.>")
文学理论是一门人文科学 (二)文学理论在高校教学体系中的地位 二、文学理论课程安排及重点>")




.>")





”——吉林省农村 幼儿园教师信息技术应用提升培训>")