Download presentation
1
第七章 样本分布 数理统计是研究如何有效地收集、整理和分析带有随机影响的数据,从而对所观察的现象做出推断或预测,为决策提供依据的一门学科。
第七章 样本分布 数理统计是研究如何有效地收集、整理和分析带有随机影响的数据,从而对所观察的现象做出推断或预测,为决策提供依据的一门学科。 在近一个多世纪的发展中,数理统计不同程度地渗透到人类活动的许多领域。人口调查、税收预算、测量误差、出生与死亡统计、保险业中赔款额和保险金的确定等,这些数理统计早期主要研究的问题,直到现在仍然值得认真研究。在近半个世纪以来,数理统计在理论、方法、应用上都有较大的发展。抽样调查、试验设计、回归分析与回归诊断、多元分析、时间序列分析、非参数统计、统计决策函数、统计计算、随机模拟、探索性数据分析等统计方法相继产生并在实践中普遍使用,把以描述为主的统计发展到以推断为主的统计。数理统计的内容已异常丰富,应用广泛,成为当前最活跃的学科之一。

2
§7.1 总体与样本 一、 总体与个体 总体指研究对象的某项数量指标值的全体。组成总体的每个元素称为个体。由于每个个体的出现带有随机性,即相应的数量指标值的出现带有随机性。从而可把此种数量指标看作随机变量,我们用一个随机变量及其分布来描述总体。为此常用随机变量的符号或分布的符号X,Y,Z…,F(x) …来表示总体。 例7.1研究某灯泡的使用寿命时,总体可用随机变量X来表示,或用其分布函数F(x)表示。
 …来表示总体。 例7.1研究某灯泡的使用寿命时,总体可用随机变量X来表示,或用其分布函数F(x)表示。")
3
例7.2研究某地区学龄前儿童发育情况,人们关心的是其体重X和身高Y这两个数量指标,则此总体就可用二维随机变量(X,Y)或其联合分布函数F(x,y)表示.
二、样本 为了推断总体分布及其各种特征,就必须从总体中按一定法则抽取若干个体进行观测或试验,以获得有关总体的信息.这一抽取过程称为抽样.所抽取的部分个体称为样本,样本中个体的数目称为样本容量.例如容量为n的样本可以看作是n维随机变量( ), 其观察值为( ).
, 其观察值为( ).")
4
简单随机抽样 它要求满足两点: (1)代表性. 样本中每个个体与所考虑的总体有相同的分布.即样本中每个个体与总体X具有相同的分布. (2)独立性. 样本中每个个体取什么值并不影响其它个体取什么值.即必须是相互独立的随机变量. 由简单随机抽样所得到的样本称为简单随机样本.假如总体的分布函数为F(x),则其简单随机样本的联合分布函数为
,则其简单随机样本的联合分布函数为.")
5
三、分布族 在概率论研究中,随机变量的分布总是假设给定的,但在数理统计的研究中,总体的分布是未知的,但总可以假定总体的分布是某一个分布族的成员. 例7.3 在研究某批灯泡的质量时,若关心的是其质量是否合格,若合格记为0,不合格记为1,因此该总体就可用仅取0和1的随机变量X来表示.显然,这个总体的分布就是一个参数为p的二点分布b(1,p),由于p未知,故这个总体分布也是未知的,但可以假定该总体分布是二点分布族 F={b(1,p);0<p<1}
,由于p未知,故这个总体分布也是未知的,但可以假定该总体分布是二点分布族. F={b(1,p);0<p<1}")
6
若人们关心的是灯泡的寿命。这是一个无限总体。假如人们根据过去的资料知道灯泡的寿命X服从指数分布,其密度函数为
所需确定的参数是λ>0.

7
四、从样本去认识总体 ⑴ 频数频率分布表及其图示
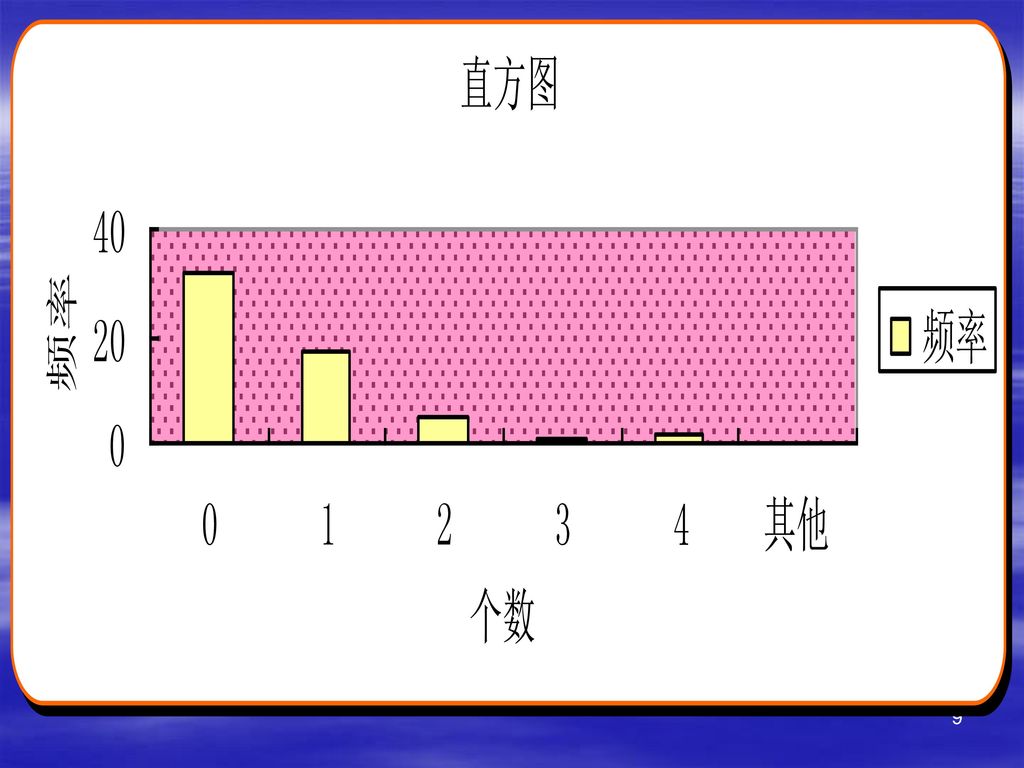
⑴ 频数频率分布表及其图示 例7.4 我们通常饮用的矿泉水有19个指标.某市技术监督局一次抽查了58批矿泉水,记录每一批矿泉水的每个指标是否合格,从中可统计出每批矿泉水不合格指标的个数X.这里X是一个离散型随机变量,其一切可能取值为0,1,…19。 58批矿泉水的指标不合格数构成了一个容量为58的样本的观察值,每个可取0,1,…,19中某个值,将它们整理后列成表1.1.1

8
表 1 58批矿泉水不合格指标数的频率、 频数分布表
表 批矿泉水不合格指标数的频率、 频数分布表

10
(2) 经验分布函数 样本直方图可以形象地去描述总体概率密度函数大致形状,经验分布函数将可以用来描述总体分布函数的大致形状.
(2) 经验分布函数 样本直方图可以形象地去描述总体概率密度函数大致形状,经验分布函数将可以用来描述总体分布函数的大致形状. 定义 设总体X的分布函数为F(x),从中获得的样本观察值为 ,将它们从小到大排列成 ,令 经验分布函数是一个等概率仅取n个值的离散型随机变量的分布函数 称 为该样本的经验分布函数.
 经验分布函数. 样本直方图可以形象地去描述总体概率密度函数大致形状,经验分布函数将可以用来描述总体分布函数的大致形状. 定义1.1.1 设总体X的分布函数为F(x),从中获得的样本观察值为 ,将它们从小到大排列成 ,令. 经验分布函数是一个等概率仅取n个值的离散型随机变量的分布函数. 称 为该样本的经验分布函数.")
11
例 写出经验分布函数 某食品厂用自动装罐机生产净重量为345克的午餐肉罐头,由于随机性,每个罐头的净重有差别,现从中随机取10个罐头,其净重如下: 344,336,345,342,340, 338,344,343,344,343, 求经验分布函数.

12
统计量及其分布 1.定义1.2.1 设 是取自某总体的一个容量为n的样本,假如样本函数
中不含任何未知参数,则称T为统计量.统计量的分布称为抽样分布. 2.常用的几个统计量 设 是来自总体X的样本 ⑴样本均值 样本均值是反映总体数学期望所在位置信息的一个统计量,是总体数学期望的一个很好的估计.

13
⑵样本方差 样本标准差 样本方差与样本标准差反映了数据取值分散与集中的程度,即反映了总体方差与标准差的信息. ⑶样本k阶(原点)矩 样本k阶中心矩 它们分别反映了总体k阶(原点)矩与k阶中心矩的信息.
矩. 样本k阶中心矩. 它们分别反映了总体k阶(原点)矩与k阶中心矩的信息.")
14
⑷样本偏度 SK反映了总体分布密度曲线的对称性信息. 当SK>0时,分布的形状是右尾长,称为正偏的;当SK<0时,分布的形状是左尾长,称为负偏的. ⑸样本峰度 KU反映了总体分布密度曲线在其峰值附近的陡峭程度的信息,当KU>0时,分布密度曲线在其峰比正态分布来得陡;当KU<0时,比正态分布来得平坦.

15
⑹次序统计量 被称为样本的第i个次序统计量,它是样本 的满足如下条件的函数: 每当样本得到一组观察值( )时,将它们从小到大排列为 ,第i个值 便是 的观察值, 称为该样本的次序统计量. 又 称为该样本的最小次序统计量, 称为该样本的最大次序统计量.

16
⑺样本极差 若样本容量为n,则样本极差 它反映了样本取值范围的大小,也反映了总体取值分散与集中的程度. 极差常在小样本(n≤30)场合使用,而在大样本场合很少在实际中使用. 这是因为极差仅使用了样本中两个极端点的信息,而把中间的信息都丢弃了,当样本容量越大时,丢弃的信息也就越多,从而留下的信息过少,其使用价值就不大了.

17
(8) 样本 p 分位数和中位数 定义 设 是来自总体 F(x) 样本, 为该样本的次序统计量. 对于 , 称
对于 , 称 为该样本的 p 分位数(或 p 分位点). 称为样本中位数, 显然有
. 称为样本中位数, 显然有.")
18
第一四分位数 第三四分位数

19
例2 设 是 F(x) 的样本, 分别为总体均值与方差, 从中任选两个分量 和 令 有 此种统计量有 个,加起来平均得:

21
几种常用的分布族 ⑴ 分布 Ⅰ定义:1.2.2 设 为相互独立的随机变量,且均服从标准正态分布N(0,1),则称随机变量
⑴ 分布 Ⅰ定义: 设 为相互独立的随机变量,且均服从标准正态分布N(0,1),则称随机变量 服从自由度为n的 分布,记作 自由度可理解为平方和中独立变量的个数. Ⅱ 分布性质 (1)设 , 则E(X)=n,D(X)=2n. (2) 可加性:设 , ,且X与Y独立,则
,则称随机变量. 服从自由度为n的 分布,记作. 自由度可理解为平方和中独立变量的个数. Ⅱ 分布性质. (1)设 , 则E(X)=n,D(X)=2n. (2) 可加性:设 , ,且X与Y独立,则.")
22
下图描绘了 分布密度函数在n=5,10,20时的图形.

23
(2) t分布 ①定义1.2.3:设X~N(0,1), ,且X与Y独立,则称随机变量 所服从的分布为t分布,记为T~t(n),称n为自由度.
 t分布 ①定义1.2.3:设X~N(0,1), ,且X与Y独立,则称随机变量 所服从的分布为t分布,记为T~t(n),称n为自由度.")
24
(3)F分布 ①定义1.2.4:设 , , 且X与Y独立,则称随机变量 服从自由度为(n,m)的F分布,记作 .
①定义1.2.4:设 , , 且X与Y独立,则称随机变量 服从自由度为(n,m)的F分布,记作 图1.2.4描绘了 的密度函数曲线
的F分布,记作 . 图1.2.4描绘了 的密度函数曲线.")
25
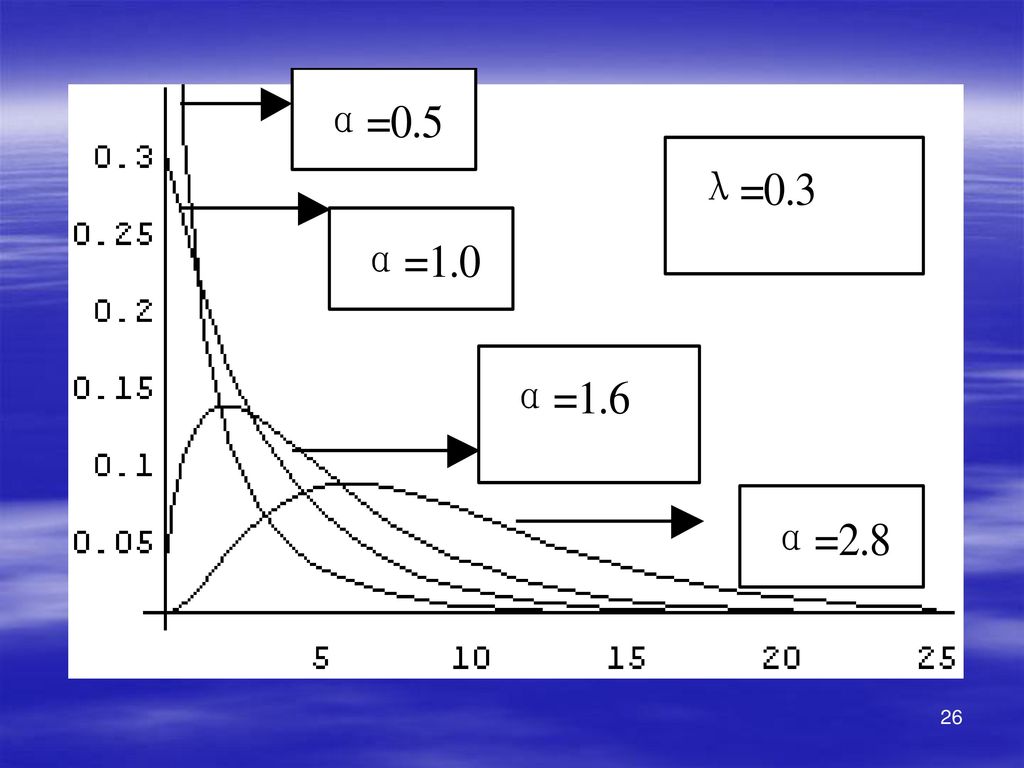
(4)Γ分布族 定义1.2.5:定义在正实数上,且用密度函数
表示的概率分布称为Γ分布,记为Γ(α,λ).其中α>0是形状参数,λ>0是尺度参数.而{Γ(α,λ);α>0,λ>0}就是Γ分布族 当α=1时的Γ分布为指数分布其密度曲线如下:
.其中α>0是形状参数,λ>0是尺度参数.而{Γ(α,λ);α>0,λ>0}就是Γ分布族. 当α=1时的Γ分布为指数分布其密度曲线如下:")
27
Γ分布族性质

28
(5)β分布族 定义1.2.6:定义在[0,1]上,且密度函数
表示的概率分布称为β分布记为β(a,b),其中a>0,b>0.而{β(a,b): a>0,b>0}为β分布族. β分布有几个重要的特例.当a=1,b=1时, β分布就是U(0,1)
![(5)β分布族 定义1.2.6:定义在[0,1]上,且密度函数](http://slidesplayer.com/slide/11334906/61/images/28/%285%29%CE%B2%E5%88%86%E5%B8%83%E6%97%8F+%E5%AE%9A%E4%B9%891.2.6%3A%E5%AE%9A%E4%B9%89%E5%9C%A8%5B0%2C1%5D%E4%B8%8A%2C%E4%B8%94%E5%AF%86%E5%BA%A6%E5%87%BD%E6%95%B0.jpg "表示的概率分布称为β分布记为β(a,b),其中a>0,b>0.而{β(a,b): a>0,b>0}为β分布族. β分布有几个重要的特例.当a=1,b=1时, β分布就是U(0,1)")
29
随机变量的分布的分位点 1、设随机变量X~F(x),给定常数:0<<1, 若存在 , 满足 ,
若存在 , 满足 , 则称 为分布F(x)的上(侧)分位点. 2、设随机变量X~N(0,1) , 给定常数:0<<1, 若存在 , 满足 , 则称 为标准正态分布的上侧分位点.
的上(侧)分位点. 2、设随机变量X~N(0,1) , 给定常数:0<<1, 若存在 , 满足 , 则称 为标准正态分布的上侧分位点.")
30
标准正态分布的分位点

31
分布分位点 设X ~ 2(n),若对于:0<<1, 满足 则称 为 分布的上分位点。
,若对于:0<<1, 满足 则称 为 分布的上分位点。")
32
t分布分位点 设T~t(n),若对:0<<1,存在t(n) , 满足P{T>t(n)}= , 则称t(n)为t(n)的上侧分位点.
,若对:0<<1,存在t(n) , 满足P{T>t(n)}= , 则称t(n)为t(n)的上侧分位点.")
33
F—分布的分位点 设F~ F(n1, n2) 对于 :0<<1,若存在F(n1, n2),满足 P{F>F(n1, n2)}= , 则称F(n1, n2)为F(n1, n2)的上侧分位点
}= , 则称F(n1, n2)为F(n1, n2)的上侧分位点.")
34
正态总体的抽样分布定理 (1)证明: 是n 个独立的正态随机变量的线性组合,故服从正态分布
证明: 是n 个独立的正态随机变量的线性组合,故服从正态分布")
35
(3)证明: 且U与 独立,根据t分布的构造
证明: 且U与 独立,根据t分布的构造")


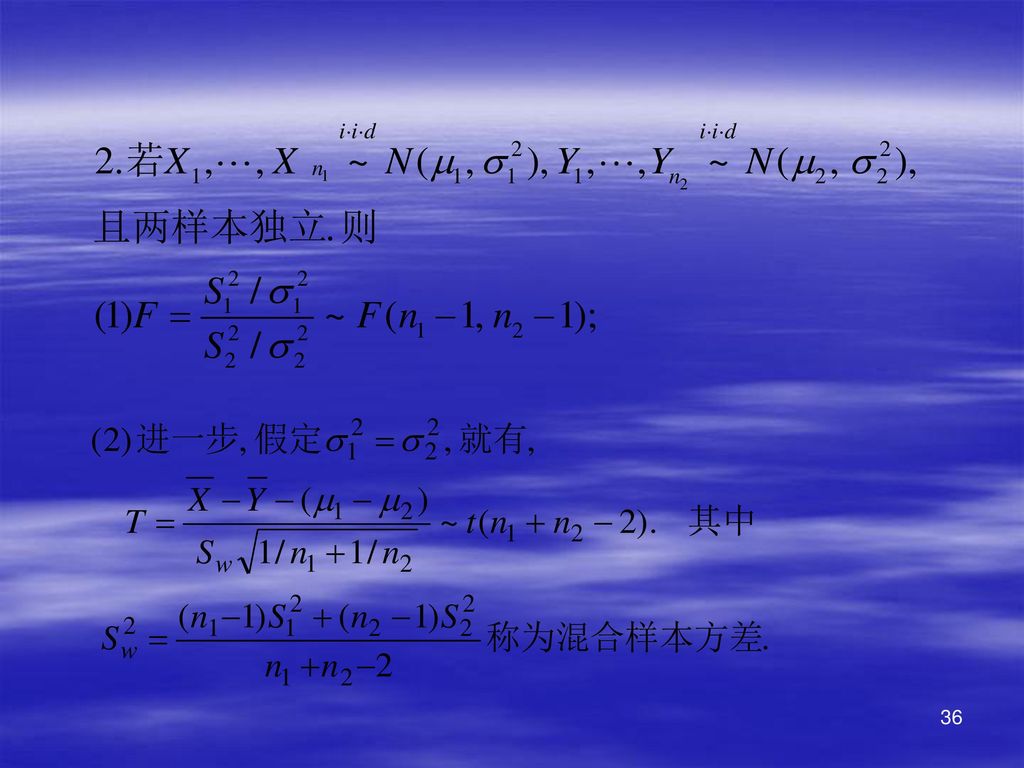
=0 变换为 x= (x), 然后建立迭代格式, 返回下一页 则称迭代格式 收敛, 否则称为发散 上一页.>")



到综合楼 205 教室集合,查看 监考安排,由考务负责人进行考务 培训。>")





 1.以大盤指數為標的之權證,和大盤指數的連動性,為什麼比和期交所期指的連動性差?>")




>")



