Download presentation
1
吴喜之 xwu@public3.bta.net.cn
本科:北京大学数学力学系 再教育:甘孜藏族自治州得荣县(6年) 统计博士:美国北卡罗来纳大学 (UNC-Chapel Hill) 教书经历: 美国加利福尼亚州大学 (UC-Davis) 美国北卡罗来纳大学 (UNC-Chapel Hill) 美国北卡罗来纳大学 (INC-Charlotte) 南开大学 北京大学 人民大学
 统计博士:美国北卡罗来纳大学 (UNC-Chapel Hill) 教书经历: 美国加利福尼亚州大学 (UC-Davis) 美国北卡罗来纳大学 (UNC-Chapel Hill) 美国北卡罗来纳大学 (INC-Charlotte) 南开大学 北京大学 人民大学.")
3
统计应用的陷阱 吴喜之

4
统计无所不在 越来越多的人意识到统计在人类生活的各个方面所起的重大作用。 几乎所有的领域都有统计的痕迹

5
统计为什么这样火爆 统计被人看重的原因是供不应求 。 一是统计的巨大市场。
另一个是统计专业所需要的包括数学、统计和计算机在内的功底,绝不是通过任何速成训练就能够达到的。 人们知道,学数学的改行学什么的都有(反之不然),但即使是学纯粹数学的,改行学统计,也不象学数学的改行力学或物理那么容易。
,但即使是学纯粹数学的,改行学统计,也不象学数学的改行力学或物理那么容易。")
6
统计应用与学科发展 统计专业的研究生毕竟有限。世界上各领域的多数统计工作都还是该领域的人士进行的。
只有统计得到充分的普及,大家都用统计,这个学科才能得到长足的发展。

7
统计应用与学科发展 而有限的专业统计工作者的主要任务,则是根据各领域的需要,发展新的统计方法和理论,建立新的模型,发展新的计算方法;
这也要求他们也参与到其他领域的统计实践中去。 统计方法(或理论)的改进和创新与统计的广泛应用是相辅相成的。
的改进和创新与统计的广泛应用是相辅相成的。")
8
统计应用与学科发展 然而,统计的广泛应用和进行统计工作的人数迅速增加,也导致人们对统计应用中可能出现的问题的忽视。
实际上,在统计应用中有许多陷阱;它们可能使统计推断的结果不可靠、不可信、甚至导致灾难性后果。

9
统计应用陷阱产生的根源 统计陷阱的产生和统计学科本身的性质及其发展的历史进程有关。包括: 统计的数学背景及其为实际服务的使命间的关系
统计教材对现实世界的理想化 统计课本的编写特点 使用统计的人对统计概念的理解 统计应用中一系列决策的任意性 统计软件的“傻瓜化”等等。

10
统计与数学的区别 统计需要大量的数学; 现代统计的基础也是数学家所奠定的 数学是一个“是非明确”的理想世界 它自我形成一个严格的封闭逻辑体系
只要逻辑正确,最多得不出结果,但不会犯错误; 这也是以演绎为主的数学魅力之所在 数学教科书也因此没有负面的内容。

11
统计与数学的区别 但以归纳为主要思维方式的统计是描述现实世界的。 应用于各领域的统计需要建立各种数学模型来近似现实世界。
统计中的数学模型本身并不形成完整封闭的逻辑体系;而且结论也绝非确定性的。 统计的非确定性恰恰说明它很适合于研究不确定的现实世界。

12
统计过程是一系列主观决策组成的 统计应用的每一环节都可能出问题。 人们按照自己的想法收集数据(信息);
人们对现实世界的认识是某些用数学语言表示的模型 或一些想象的和不易验证的假定 这些模型仅仅是对现实的某种近似 这类近似模型存在的一个必要条件是它们必须能够被人们解出来

13
统计过程是一系列主观决策组成的 模型的解可能是近似模型的精确解 也可能是近似模型的近似解 它们可能有在一定概念下的“最优性”
以数学语言描述的结论和可以适用于现实世界的结论之间还有容易被忽略但可能是致命的鸿沟; 也就是说,统计显著不一定等价于实际显著;有时差别相当大。

14
一个“简单”的例子 比如,大家最熟悉的关于比例置信区间的公式 它仅仅在大总体、大样本的情况下适用,它是二项分布的近似(近似模型的近似解)
而二项分布的“精确”置信区间(近似模型的精确解)又是对大总体时超几何分布的近似 你想过如何判断和在各种情况解决这个问题吗?
又是对大总体时超几何分布的近似. 你想过如何判断和在各种情况解决这个问题吗?")
15
显然 统计应用的每一部分都带有主观性或任意性。 从有某些“目的”地收集数据 到建立基于某些假定和猜想的模型、
从寻找解的方法到对计算机输出的解释,充满了危险和挑战

16
统计教科书把现实世界大大简化了 目前多数的数理统计教科书仍然遵循着上个世纪三四十年代遗留下来的传统。充满了与数学模型有关的定义、定理、命题、推导和证明。 但对于背后的统计思想的介绍不充分这些充满假定的数学模型都是对现实世界的简化。 有多少人真正认识到,所有统计教科书中的数学假定都是无法用数据验证的,没有任何模型是完美的?

17
统计教科书把现实世界大大简化了 经过这样的统计教育,人们(特别是缺乏实际经验的学生)有可能把一个人造的、但又并不完全虚幻的世界当成真实世界。
为了人们容易理解,教科书把本来复杂的世界进行简化,是完全必要的。 但如果已经掌握了某领域一定的知识,就有必要认识到书本和现实之间的差距。 教科书倾向于把世界过于理想化并不是大问题,但如果我们这些写书的教师或“权威”自己也这么认为, 问题就没这么简单了.

18
统计软件在不断大量生产垃圾 统计软件的发展推广和普及了统计,统计从统计学家的圈内游戏变成了大众的游戏
输入数据,做几个选项,则计算机会输出大量漂亮的结果和图表。 这种大规模产生结果的方式使得实际工作者犯错误的机会大大增加。 人们往往不能意识到计算机产生的垃圾可能大大多于有用的结果。 统计过程任何一个步骤的失误都毫无警告地包含在计算机输出之中

19
数据收集时的问题 收集数据和研究的对象有关系。也和人们心中的模型有关。
模型的选择带有主观性, 很可能把无关的变量引入了模型, 而把有关的忽略了 这样,根据变量收集的数据做出的统计推断就不可靠了。 经常一方面耗费资源收集了大量的数据,但由于其中缺乏有关变量的观测值而得不到可靠的结果。

20
抽样调查数据是典型的垃圾源 人们喜欢设计有许多问题的问卷,某全国性调查的问题数目甚至达到四百多个。
其目的肯定是为了得到更多的信息;比如想知道“一星期上网20小时的男性学生每月看三份杂志”的百分比 这个比例就涉及至少四个问题(每个问题又有若干选择):周上网时数、性别、职业、每月看杂志数。
:周上网时数、性别、职业、每月看杂志数。")
21
天文数据的垃圾 在一个四百多个问题的问卷中的所有四个问题可以产生的比例个数达到上千亿或上万亿。
一个大型问卷可以产生的理论比例总数可超过10的几十次幂的不折不扣的天文数字。 其中绝大部分比例或者不存在,或者由于(总体的有关子集的)样本量太小而导致比例没有意义。
样本量太小而导致比例没有意义。")
22
我们不便引用那个保密的全国调查资料 我们分析另外一个调查数据来说明我们的关切

23
更具体一些… 我们的例子是在浙江进行的《金融机构员工思想动态调查问卷》数据(简称“金融员工调查”数据)。
我们选了54个单选题(即每个问题从多个回答中选择一个),并且对于少数缺失数据进行了删除或填补。该数据一共有990个观测值(即有效问卷数目)。
,并且对于少数缺失数据进行了删除或填补。该数据一共有990个观测值(即有效问卷数目)。")
24
考虑两个范畴交为分母的比例 如果分母由两个范畴的交观测值数目组成,分子为其他范畴和分母的交的观测数, 那么理论上可能出现的比例将近一千五百万个,为 个。一个这样的例子为“51岁以上女性员工想跳槽的比例” 。

25
这些众多的比例中究竟有多少是合理的? 在理论上可能出现的 个比例之中,只有 (28.24%)个可以用正态近似计算置信区间 有 (8.77%)个分子和分母的范畴之交为空集, 有 (62.99%)不能用正态近似计算置信区间。 这个结果展示在下面的饼图之中。
不能用正态近似计算置信区间。 这个结果展示在下面的饼图之中。")
27
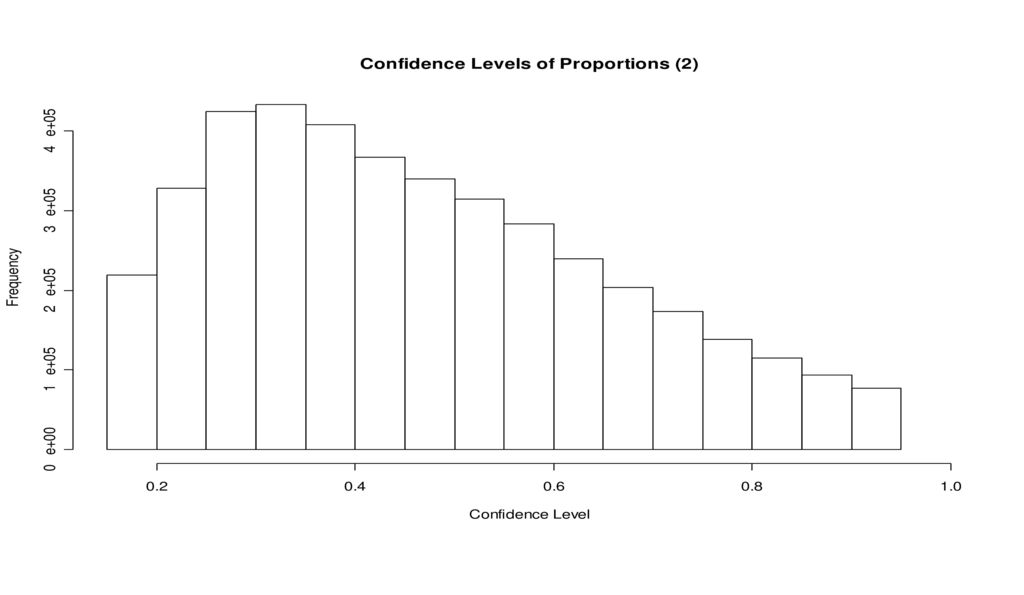
置信度 在可用的4236996个比例的误差±3%的置信度中只有79652个(1.88%)大于或等于95%。
这和近一千五百万的总数比起来简直微不足道。 绝大部分(有59.49%的比例)的置信度小于50%。这 个误差±3%的置信度由下面的直方图显示。
的置信度小于50%。这 个误差±3%的置信度由下面的直方图显示。")
29
现在可能会理解为什么调查报告中不愿提供除百分比之外的任何信息了吧!

30
拿垃圾当宝贝 但通常调查报告对这些没有意义的比例照登不误,不给出样本量、置信度、置信区间。

31
这些比例中到底有多少垃圾? 例:一个全国性的调查… 其领导小组有6名、学术顾问3名 项目办公室8人、学术委员会26人
课题组12人、调查报告主要撰稿人2人 在这57个人中没有一个是学统计的(仅仅在合作成员中有3个统计教师和8个学生) 其二百多页的调查报告(A4纸)展示了5800多个比例(百分比) 这些比例没有任何一个有样本量、置信区间和置信度 这些比例中到底有多少垃圾?
 其二百多页的调查报告(A4纸)展示了5800多个比例(百分比) 这些比例没有任何一个有样本量、置信区间和置信度. 这些比例中到底有多少垃圾?")
32
问卷的设计问题 如果不对所感兴趣的比例的分母范畴在设计抽样框时给予特别考虑,结果必然不可信。
问卷问题的多少、问题的措辞、问题的次序、问卷人的素质、抽样框的设计等等都可能严重影响调查的结果。 这也为玩弄数字(无论为了数字出官,还是什么别的目的)的人提供了机会。
的人提供了机会。")
33
把连续变量转换成分类变量或定序变量 常需要把连续变量如何转换为定序变量,比如划分东西部、贫困县等等 在确定分划点时有主观性和任意性。 一个典型例子是如何划分高收入、中等收入和低收入人群。这种任意性给制造“猫腻”创造了条件。 类似的例子还有医学统计中的病理的分期,病情的分阶段等等。

34
“等距”例子 比如,把鼻咽癌患者的淋巴结大小,按照淋巴结的实际厘米数将病例划分为四组,0,0-3,3-6,>6cm
我们似乎永远也无法确定我们自己所感兴趣的空间是什么别的空间变换的结果

35
“等间隔”和“外紧内松”的互相变换

36
“等间隔”和“外紧内松”的互相变换

37
“等间隔”和“下紧上松”的互相变换

38
? 我们究竟是在什么空间中呢

39
了解数据背景。 在对数据进行统计分析时,必须对各种数据的背景有所了解。 比如笔者曾经在一个人口数据上发现了某种可疑的“周期性”,
后来发现这是由于统计方式的不同而产生的人造周期;如果把这些人为错误放入模型,就贻笑大方了。

40
不能随意删除观测值 仅仅为了“好的拟合”而任意增补或删除观测点是不适当的。
拟合不好的根本原因是模型和数据不匹配,或者是模型的问题,或者是数据问题、或者二者都有问题。 如果数据经过核对是无误的,就必须改进模型,不能削足适履。所谓“离群点”、“奇异点”、“异常点”都是以目前的模型为参照的。

41
对统计模型和概念理解的问题 只有求得出解的模型才是可以使用的模型,但并不见得是最合理的。 如前所述,模型是对世界的近似和简化。其原因之一在于人们对真实世界认识的局限性; 这使得模型的建立成为人们的经验、知识、逻辑推理和主观猜想等的产物。

42
对统计模型和概念理解的问题 模型不合理的另一个原因是由于任何模型都是由数学语言表述的; 但并不是任何模型用已经掌握的数学工具都能够解得出来;
此外,即使数学方面不成问题,如果计算机和软件不能够在需要的时间把问题精确(对于模型而言)解答出来,就需要寻求近似解; 如近似解也得不到, 模型再好也不能用
解答出来,就需要寻求近似解; 如近似解也得不到, 模型再好也不能用.")
43
数学假定的真伪无法用数据来验证 模型的简化包括为数学推理方便而设的各种数学假定。 它们有助于得到近似模型的“精确解”
但毫无例外,统计推断中所有关于总体、数据和模型的数学假定,诸如对总体分布、对模型、对大样本的各种假定等等都无法根据数据来精确验证。 表面看来,实际工作者似乎可以不予理会这些数学问题,但这些假定的真伪很可能对统计推断的结果有决定性的影响。

44
变量的选择充满危险 模型的变量选择对结果的影响,不仅在回归分析,而且在多元统计分析的实践中特别明显。
例如因子分析或主成分分析常被用于排序,但对于变量的随意选择可以完全操纵排序的结果。 同样, 变量的选择对聚类分析, 判别分析, 典型相关分析等都会对结果产生重要影响。 因此应避免被这些分析的复杂的数学公式和漂亮的计算机输出迷惑,而忘记了变量选择这样的要害

45
能理解模型中的各种概念吗? 各种概念,如显著性水平、置信度、相合性、最大似然原理、一致最小无偏估计、渐近分布等这些名词背后的基于重复试验、总体或大样本基础上的含义,在实际应用中容易被忘记或者忽视。 此外,统计显著是不是就真的显著?“最优的”,或“渐近最优”对于计算出来的结果有什么意义?

46
头脑要清醒 这些概念绝不能仅从其表面字意或数学定义来理解;
必须要从收集数据时头脑中的模型、使用模型进行分析或者拟合时对模型和变量的选择、结论的计算、以及模型和实际问题是吻合好坏等等来分析。 要弄清楚中间有多少近似、人为的、和无法说清的成分。

47
从实际需要来评判模型。 最有发言权的还是统计模型和实际问题的相关程度(显著性水平取0.05?)
不同的检验,特别是一些非参数检验,看上去零假设是一个,但他们所给出的不同的p-值却反映了数据结构的不同方面;它们的备选假设就更不像经典统计那么容易解释; 在应用中实际显著比所谓的统计显著更重要。

48
假设检验不能得到“接受零假设”的结论 很多人把假设检验看成是证明零假设是正确的一种方法。 在教科书中常用的检验中,如H0:m=m0对Ha: m< m0一类的H0和Ha不对称的检验,根本不能证明零假设是对的。 在不能够拒绝零假设时,只能够说明证据不足,而不能说“接受零假设”。 负责任的统计学家在做出结论时应该给出该结论可能出错的概率。

49
假设检验不能得到“接受零假设”的结论 但是那些在不能拒绝零假设时声称要“接受零假设”的论述中,除了在理论上的备选假设为单点的情况下,从不提供在接受零假设时犯错误的概率(但提供体现拒绝时犯错误的概率的p值?!?!)。 但愿这仅是后果严重的无知或疏忽而已! 假设检验是统计以否定为目标的思维方式的体现。 实际上, 统计和诸如物理学等其他科学类似, 大都是在否定中发展的

50
用假设检验来“验证”各种条件是误导 在充满了定义、引理、定理及推导过程的数理统计教科书中的任何结论都有一定的条件,而这些条件在具体应用中往往或者被忽略,或者被一些如同规则条款一样的步骤来“验证”。 以回归为例,一些教科书要求“验证”正态性,“确定”没有自相关,“认定”没有共线性等等;在这些以验证为目标的步骤完成之后,就心安理得地认为回归结果是可靠的了。

51
用假设检验来“验证”各种条件是误导 其实这些以假设检验为工具的步骤都是以没有足够证据拒绝零假设而“接受零假设”作为“通过”验证的依据 这和没有见过某人犯罪就“证明”该人没有犯罪一样荒唐。 即使现存的关于回归条件的所有可能检验都无法拒绝,我们也只能够说,使用目前存在的方法没有发现问题,而永远不能说绝对没有问题了。

52
用假设检验来“验证”各种条件是误导 当然,应该鼓励利用所有可能的检验方法来试图找出问题;但永远不能证明绝对没有问题。 正像发射宇宙飞船一样,人们在发射前在用各种手段试图寻找问题;但如果没有找出问题,也绝对不能说他们已经证明不会有问题了。但至少可以说:“我们已经尽了最大努力,但未发现问题。

53
用Kormogorov-Smirnov检验。 得到下面结果:
一个简单的“接受零假设”的例子 数据:1、2、3、4、5 这个数据代表的总体是什么分布? 用Kormogorov-Smirnov检验。 得到下面结果:

54
SPSS输出(能说“接受”吗?) 零假设:Poisson分布, p-值=1.000 (“接受”零假设吗?) 零假设:正态分布,
零假设:均匀分布, p-值=0.988 (“接受”零假设吗?) 零假设:指数分布, p-值=0.806 (“接受”零假设吗?)
 零假设:指数分布, p-值=0.806 ( 接受 零假设吗 )")
55
“少数服从多数” 更加不可思议的是,有人为了达到“接受零假设”的目的,甚至搞“少数服从多数”。即对于一个假设检验,用多种检验统计量来检验,如果不能拒绝的多于可以拒绝的检验,则“接受零假设”。 实际上,如果这些检验统计量都是为这同一个检验服务的,而且条件都符合,则适当的做法是:即使仅有一个检验拒绝零假设就应该拒绝零假设,如果都不能拒绝,就不拒绝零假设(不能说接受).
.")
56
“少数服从多数” 这种搞“少数服从多数”的情况往往还把经典检验和非参数检验混起来使用;但在这时,零假设和备选假设的含义在非参数情况下意义和经典情况并不相同,不能比较。

57
关于模型的“是非” 那么,什么时候应该相信自己的结果呢。
这就回到不仅是对统计,而且是对所有科学最根本的认识:世界上所有的模型都只是对现实世界的某种近似。没有完美的模型。所有的模型都命中注定要被修正、改进以至于被替代。只要没有被新的证据所否定,任何假定的模型都可以应用,直到被更好的模型代替为止。 理想的、唯一绝对说得出是非对错的世界可能只存在于纯粹数学之中。

58
对于简单的模型: Y=c+aX1+bX2+cX3+e
它是线性的吗? 自变量需要变换吗?如何办? 自变量是相关的吗?非线性相关? 能够去掉变量吗? 对误差项你能说什么? 因变量和自变量的什么有关? 我们知道的远远不如我们不知道的! 那些书本为什么会如此自信????

59
那些把世界简单化,把世界说成只有“是”和“非” ,是无知,还是有别的原因?
是与非 那些把世界简单化,把世界说成只有“是”和“非” ,是无知,还是有别的原因? 人类世界上如此多的麻烦,有哪些不和这个有关呢?

60
危机和挑战意味着机遇 本文所讨论的统计应用中的陷阱仅仅是冰山的一角。 之所以这样强调统计应用中的问题,是由于通常的统计教科书(和其他学科的教科书一样)很少说什么不能做。 这使学生习惯于“接受”课堂授予的理想化的教条,而不习惯面对充满危机和挑战的现实世界。
很少说什么不能做。 这使学生习惯于 接受 课堂授予的理想化的教条,而不习惯面对充满危机和挑战的现实世界。")
61
危机和挑战意味着机遇 挑战其实不是坏事,所需要的是科学的态度和脚踏实地的精神。 只要敢于怀疑教条、怀疑权威、勇敢创新,那挑战就意味着机遇,意味着进步。 没有挑战就意味着没有生命。 人类文明不就是在各种挑战中发展起来的吗?

62
谢谢大家

63
按照著名统计学家C. R. Rao 在终极的分析下,一切知识都是历史 在抽象的意义下,一切科学都是数学 在理性的基础上,所有的判断都是统计学













 1 2 3 6 7 11 12 13 14 16 18 20 21 22 26 28 31 34 35 38 39 40 41 62 63 64 66 67 71 74 76 82 90 91 96 97 99 100 101 102.>")
— 鹿野苑藝文學會 吳文成會長編輯 唐代藝術家充分掌握圓 熟的寫實性技法,以豐 腴為美為特質,佛像面 容圓滿端祥,身軀雄健 飽滿,神情莊嚴而慈祥。 唐朝著名的藝術家如閻 立本、尉遲乙僧、吳道 子、周舫、楊惠之和宋 法智等,都參與佛教藝 術,是我國佛教造像的.>")

 带胶卷的照相机 光圈 胶卷 (控制光线) (感光、成像)>")






