Download presentation
1
传播学研究:理论与方法 戴元光 赵士林 邢虹文

2
第一章 引论

3
从发展轨迹来看,传播学研究从定性分析走向定量分析,从人文科学方法转向现代科学方法,从对伟人的研究转向对过程与结构的研究,从一国的研究转向对世界性传播学体系研究的发展趋势。

4
第一节 媒介与传播学研究 媒介研究四阶段(韦默与多米尼克) 第一阶段:研究媒介本身 第二阶段:研究媒介的使用 第三阶段:研究媒介的社会效果
第一节 媒介与传播学研究 媒介研究四阶段(韦默与多米尼克) 第一阶段:研究媒介本身 第二阶段:研究媒介的使用 第三阶段:研究媒介的社会效果 第四阶段:研究媒介的发展问题
 第一阶段:研究媒介本身. 第二阶段:研究媒介的使用. 第三阶段:研究媒介的社会效果. 第四阶段:研究媒介的发展问题.")
5
时间划分: 第一次世界大战期间:魔弹论 20世纪中叶:传播影响的有限性 20世纪50年代以后:使用与满足理论 20世纪80年代末:媒介争夺与竞争

6
第二节 科学方法与学科方法 在认识传播这个社会现象过程中,作为认识主体的人,必须与客体发生能动的反映关系,在这个过程中,人们不但要借助物质的手段,更要借助科学方法来讨论传播学的本质和过程,从观察、研究和试验中获得传播学的系统认识。

7
一、科学方法论的内容和意义 科学方法的内容 研究对象:研究和认识的客体 物质手段:主体在研究客体过程中使用的各种工具 理论工具:人类在科学研究过程中所使 用的理论知识的总和

8
二、科学方法的特性 1.规律性 2.实践性 3.经验性 4.解释性 5.认知性 6.多样性

9
三、科学方法与传播学研究 科学方法是所有学科通用的研究方法,对所有学科的研究都有指导作用,同时每门学科的研究又有自身的独特性。 科学方法是传播学研究的最一般的方法,是传播学研究的精神手段,其所倡导的客观态度和实事求是的精神是开展实地研究的指导原则。

10
第三节 传播学研究的交叉性 传播学是一门应用学科,涉及社会科学领域、自然科学领域及工程技术领域中的许多学科,这就决定了传播学的交叉学科性质和研究方法的跨学科性。

11
一、社会学方法 在传播学研究中,应用社会学的原理和方法,可以帮助人们把握传播与人类、传播与社会的各种联系。 理论方面:研究传播的社会结构、功能以及规律,研究社会舆论及互相影响。 经验方面:了解传播与社会的各方面联系和互动关系。 实践方面:揭示传播现象和过程的本质联系和特征,以解决传播中的实际问题。

12
二、心理学方法 心理学是研究人的心理规律的科学。 在传播学研究中,可以利用心理学关于知觉、认识、态度形成和行为效果的理论来解释态度改变、说服行为、宣传效果等问题。

13
三、语言学方法 在传播学研究中,语言学方法可以深入分析语言对传播过程、传播效果的影响,分析传播内容的结果与特点,以及语言对于传播行为的功能等。

14
四、政治学方法 政治学方法是运用辨证唯物主义和历史唯物主义方法客观地认识和分析传播对政治的影响,认识其客观性,揭示其规律性,考察其阶级性。

15
五、文化学方法 运用美学、文化社会学、文化人类学的理论研究传播学,主要是研究和评价传播在文化发展中的地位和作用,不同文化的沟通与人类文明的发展,文化的延续、继承和传播,传播对社会化的影响和作用以及媒介文化等。

16
第四节 “三论”与传播学研究 系统论、信息论和控制论以及统计数学方法的出现使传播学突破了传统方法的局限性,与哲学方法、社会心理学方法、逻辑学方法相比,它无论在形式上还是在内容上都使传播学研究更加科学化和程序化。

17
一、系统论方法 系统论方法是奥地利生物学家L·V·贝塔朗菲于20世纪上半叶创立的,是研究系统的模式、原则和规律,并对其功能进行数学描述的一门学科。 系统论的基本出发点是把生物作为一个有机体的整体来加以考察,以寻求解决整体与部分之间相互关系问题的模式、原则和方法。

18
系统论的观点 系统的观点:一切事物或有机体都是一个整体,整体不是部分的简单相加,而是有机的结合。 开放的观点:一切有机体之所以有组织地处于活动状态,是由系统与环境不断地进行物质、能量的交换。 层次的观点:每个系统都有子系统或要素,这些要素的组织形式就是系统的结构,而系统的结构是由不同层次的要素所构成的。

19
系统论与传播学 用系统论方法研究传播学,就是从系统的角度考察传播学,把传播学看成是整个社会系统中的一个子系统,是与社会进程相关联的完整过程,具有整体性、动态性、交互性与层次性。

20
二、信息论方法 信息论方法是美国物理学家C·E·香农在20世纪上半叶所创立的,主要研究的是信息的本质,并用数学的方法研究信息的计量、传递、变换和存储,可分为狭义信息论、一般信息论以及广义信息论等。

21
信息论与传播学 信息论不仅是研究传播的复杂性、系统性和整体性所不可缺少的主观手段,而且也为传播学研究的程序、思考步骤和操作方法提供了可靠的科学依据。

22
三、控制论方法 控制论是美国物理学家N·维纳于1948年所创立,是“关于动物和机器中控制和通讯的科学”,是横向联系的新学科。 控制论的基本概念是信息概念和反馈概念。任何系统通过取得、使用、保存和传递信息来保持自身的稳定和平衡,而系统的输出信息反作用于输入信息,并对信息再输出发生影响,发挥着控制和调节作用。

23
控制论与传播学 传播学运用控制论方法不仅仅运用其抽象的理论,主要是运用其具体的方法。首先是运用控制论的反馈方法,调整传播行为;其次是从信息方面研究传播的功能。此外,运用控制论方法可以了解传播与社会控制的关系以及传播的社会控制。

24
第二章 传播效果研究理论

25
效果研究不仅是传播学的主导分支,也是迄今为止最受重视、开拓最深、成果最丰的传播研究领域,而且是大众传播研究的基石。

26
第一节 传播效果研究的学术传统 一、传播效果定义
第一节 传播效果研究的学术传统 一、传播效果定义 依据传统的传者中心说,传播效果是指传者发出的讯息,通过一定的媒介渠道到达受众后,所引起受者的思想和行为的变化。

27
二、传播效果研究的学术传统 实证主义: 以“现代社会能够合理运行”为理念,主要采取社会调查、心理实验和统计分析方法,侧重于研究媒体在改变和引导人们的价值观念和思想意识及行为、传递信息、动员社会、形成舆论、改善和增强传媒之商业作用、影响社会制度和文化、传播创新和文明等方面的效果。

28
批判理论: 反对功能主义和自由多元的社会意识形态,强调现代社会的矛盾对抗性质,批判现代社会的霸权统治,揭露传媒中占统治地位的意识形态和大众商业文化之骗人虚幻的实质,鼓吹激烈的反叛行为,在激化对抗冲突中解决社会矛盾;反对以市场、统治、军事诸需要引导对传播效果的研究,批评过分注重定量分析和个体心理行为主义,主张文化研究,重视定性方法,要求扩大传播效果研究范围,尤其是要涉及文化和社会潮流,在对传媒效果的观察荚果进行阐释时,反对以过度的玫瑰色彩加以渲染,抨击传媒技术潜在的非人性倾向。

29
第二节 传播效果研究轨迹 一、超强效果论 大众传媒威力巨大,可以形成舆论、改变信念和生活习惯,并且或多或少按照大众传媒及其内容控制者之意志支配受众行为。

30
二、有限效果论 传媒并非万能,而是在多种制约因素的互动关系里产生相当有限的效果。

31
三、适度效果论 在传受双方的互动关系中,由于所处境遇不同,传受者的主动性和选择性也就千差万别,传媒的劝服效果和受众态度、思想、信仰、行为诸方面之变易程度也是各不相同的。

32
四、强大效果论 在一定的社会、历史、文化境况下,如果能够顺应事态的客观发展和公众普遍的内在需求,引导受众的感知、认识、情绪和行为,同时谨慎地筹划节目和传播运动,那么大众传媒就可能产生强大的效果 。

33
五、谈判效果论 大众传媒通过有计划、有秩序地建构关于现实的意象,并且系统地向受众传播,而受众在接受和应对大众传媒所传递的意向世界的过程中,建构自己关于现实的景象和见解。在这个双向交流中,传受双方凭借各自所处的地位,所拥有的权力以及利益和兴趣,互相应接,彼此影响。

34
第三节 传播效果研究的经典成果 一、枪弹论 媒介本身被认为是根据媒介和媒介内容的控制者的意志,以强大的力量去形成舆论和信念、改变人们的生活习惯并指导人们的行为(Bauer and Bauer,1960)。
。 .")
35
核心观点: 传播媒介拥有不可抵抗的强大力量,它们所传递的信息在受传者身上就像子弹击中躯体,药剂注入皮肤一样,可以引起直接速效的反应;它们能够左右人们的态度和意见,甚至直接支配他们的行为。

36
对第一次世界大战中宣传心理战的效果研究则进一步促成了这样一种观点:媒介是万能的,可以随心所欲地影响受众,从而产生巨大的传播效果。在两次世界大战之间的几十年内,大众传媒如报刊、电影、广播等迅速发展并普及,对人们的日常生活产生了巨大的冲击力,人们普遍认为大众传播具有惊人的强大效果,传播研究者认为大众媒介具有"魔弹式"的威力。

37
这种观点产生的理论背景是当时西方盛行的本能心理学和大众社会理论: 本能心理学认为,人的行为正如动物的遗传本能反应一样,是受"刺激—反应"机制主导的,施以某种特定的刺激就必然会引起某种特定的反应。大众社会理论是在孔德、斯宾塞的社会有机体思想和韦伯等有关工业化社会理论的基础上形成的。他们认为,大众社会中的个人,在心理上陷于孤立,对媒介的依赖性很强,因而导致媒介对社会的影响力很大。

38
局限: 有关这一理论的研究大都是建立在观察基础上的结论,并未经过严密的科学调查与验证。这种理论过分夸大了大众媒介的影响力,同时也忽视了受众对大众传播的自主权的前提。受众是具有高度自觉的主人,他们对信息不仅有所选择,而且还会自行决定取舍。此外,这一理论还忽视了影响传播效果的各种社会因素。传播效果与当时当地的社会环境、媒介环境、群体心态、政治军事经济及文化背景密切相关。不能把传播效果放到"真空"中去考察。

39
二、佩恩基金会的系列研究 佩恩基金会的系列研究主要是针对电影对青少年的影响这一主题进行,是大众传播研究史上首次规模巨大的调查研究。佩恩基金会的系列研究为科学地研究传播效果问题提出了解决方式,为日后否定“枪弹论”作了铺垫。是“意义构建论”和“塑造模式论”的开端,开拓了传播效果研究的新领域,提出了诸如:态度改变,睡眠效果,使用与满足,调查和实验的方法。

40
时代背景: 电影的产生对当时美国社会的影响日益增加,电影是否会对青少年产生不良的影响是当时美国公众关注的问题。与此同时,社会科学中的定量分析也日趋完善。这两点是佩恩基金会进行系列研究的时代背景。

41
该系列研究对后来的传播效果的研究具有重要的指导意义,但其也有一些缺陷。如社会学家布鲁默的研究就缺乏严谨的实验设计和客观的统计分析。定性分析的成分较大。而彼得森和瑟斯顿的研究虽然采用了精确的研究方法,但是其研究方法中还是具有很大的片面性。

42
三、个人差异论 个人差异论以“S-R刺激——反应”理论为基础,由霍夫兰首先提出,德弗勒作修正后形成。
观点:媒介讯息包含着特定的刺激,这些刺激与受者的个性特征有特定的相互作用,由于每个人在需要、信念、价值观、态度上不同的认知结构,世界上没有完全同样和一成不变的传播对象。相同的大众传播内容在受者之间之所以产生不同效果,是由于受众的个人条件、社会关系不同,而其中个人差异最为重要。 个人差异论最大的发现在于“选择性注意与选择性理解”。

43
实例分析: 广播剧《火星人入侵地球调查》

44
社会分类论 也叫社会类型论或社会范畴论,强调个人的社会群体差异,由赖利夫妇首先提出。 观点:受众生活在不同的社会群体中,在行动时必然受到群体规范和压力的影响,由于社会分工产生的不同行为方式,不同社会类型的成员趋向于选择不同的媒介内容,并以和其他社会类型成员不同的方式来解释同一信息,并采取不同的行动。对个人产生作用的群体是基本群体和参照群体。基本群体是长期持续的,亲密的群体,如家庭,参照群体是个人在其帮助下可以确定自己态度,价值观和行为的群体。 这一理论是对个人差异论的修正,大众媒介应考虑到不同群体对信息接收的差异。

45
二级传播论 观点:就是指人们并不会根据媒体上的意见直接做出反应或者对生活做出调整,反过来,更多地会接纳那些自己生活中“意见领袖”的意见;意见领袖就是指那些接触媒体较多,而且思维活跃,对他人较有影响力的这样的人——他们在生活中比比皆是并且时刻发挥作用;是以,媒体更多的时候是通过影响意见领袖来影响大众,发挥改变受众态度和行为的效果。 二级传播理论最大的贡献是否定了当时影响很大的枪弹论,为人们研究大众传播效果提供了理论武器。但该理论在测量方法,统计分析,抽样技术和实验方法等方面都存在明显的缺陷。而且片面的过分地夸大了人际关系在大众传播过程中的作用。

46
中介因素论 这一理论是对“个人差异论”,“社会分类论”,“二级传播论”的研究思路的总结。 观点:中介因素会是传者的预期意图不能完全按照原定的方向和强度发挥作用,在中介因素的作用下,传受双方会彼此适应。

47
四、创新和讯息扩散理论 观点:具有创新性的事物在社会传播后,受众将会采纳并扩散传播,进而导致变革。在这一过程中,创新的事物首先通过大众媒介到达受众,然后受众通过对创新事物的讨论、参与和验证,会大规模地积极采纳这一创新事物。

48
创新扩散过程包括两步: 第一步是创新事物通过大众媒介引起受众兴趣并得到认同,其中大众媒介起主导作用; 第二步是受众在参与大众传播的基础上进行再传播,是信息扩展和受众规模扩大的过程,其中人际传播起主导作用。

49
创新扩散论提出,传播过程是满足受众兴趣和需要的过程,更是受众充分参与和创造的过程,只有大众媒介与人际传播优势互补,充分调动受众的主观能动性和创造性,传播才能充分发挥其效能。

50
五、使用与满足论 使用与满足论是一种受众行为理论。 观点:受众成员是有着特定需求的个人,其媒介接触活动是基于特定的需求,从而使需求得到满足。传媒只是解决个人需求的工具,不具有决定作用。 使用与满足论为传播效果研究提供了一个全新的视角,揭示了大众传播中个人动机与需求对传播的影响,很多著名的研究都得益于该理论。该理论的缺点主要是理论缺乏深度,关键概念混乱,研究方法幼稚,忽视人类活动动机的复杂性,没有深入研究个人在接受讯息过程中所获得的满足对于自身的影响。

51
六、议题设置论 观点:大众传播只要对一些问题予以重视,集中报道,并忽视或掩盖对其他问题的报道,就能影响公众舆论。而人们则倾向于关注和思考那些大众传播媒介注意的问题,并按照大众传播媒介确定的各个问题重要性的次序分配自己的注意力,安排问题的轻重次序,从而间接达到影响舆论,左右人们的思想和观点的目的。 议程设置的功能主要在于引导受众的注意与思考,尤其是确定新出现的社会问题和不断改变人们对于不同具体问题的关心程度。但是这个理论的缺点也显而易见,它忽视了受众自身的作用,实际上,受众并不是无条件地被传媒所安排的议程所改变,他们具有判断事情真实与否的能力,反过来,受众还会影响媒体的议程设置。

52
七、文化规范论和意义建构论 观点:大众传播具有间接的长期的影响,这种效果取决于一定“语境”内传受双方螺旋循环的互动关系。具体来说,“文化规范论”认为,大众传媒具有文化规范的作用。在大众传媒构建的图景的反复影响下,人们可能在意念进而在日常行为中认同和长期模仿此种场景与行为。“意义构建论”也认为,大众传媒通过对现实世界的描述影响受众的编码解码系统,从而影响受众的思想与行为。 文化规范论和意义构建论最大的弱点在于忽视了受众的积极应对的主动性。

53
第四节 态度改变理论——学习论 卡特赖特原则
第四节 态度改变理论——学习论 卡特赖特原则 卡特赖特认为,态度是主体对客体的一种有内在结构的稳定的心理准备状态。这里的内在结构,指态度由认知因素、情感因素和行为倾向三种成分组成。改变态度就是从认知、情感、倾向的结合上进行改变。要改变人们的态度,就要讲究技巧和方法。

54
主要观点: “要影响人们,你的信息必须进入他们的器官”。这就要求信息具有一定的刺激度,方能引起人们的注意。卡特赖特认为信息到达对方的感官是劝服传播的第一步。 “信息到达对方的感官之后,必须使之被接受,成为他认知结构的一部分”。 “要一个人在群众劝服运动中采取某一行动,必须让他看到这个行动就是达到他原有某一目标的途径。” 这一原则被称为有效沟通的利益原则。

55
第五节 态度改变理论——一致论 一、海德的“平衡论”
第五节 态度改变理论——一致论 一、海德的“平衡论” P-O-X模型——认为若认知因素是平衡的,则态度相对是稳定的,若认知因素是不平衡的,则人有压力去改变态度。 P——代表认知主体 O——代表认知对象 X——与O和P有关的第三方(可以是人或者事物)
")
56
(1)平衡状态——当三者相乘为正时,则表示平衡状态,对P来说,认知体系是协调的,不需要改变态度。
海德认为,认知主体是不能长期处于不平衡状态的。

57
二、纽科姆的“均衡论” 纽科姆研究的对象是一个最简单的传播行为模式,即个体A传达信息给个体B有关某事X的信息。

58
在这个模式中,假设A对B与对X的倾向(态度)是相互独立的,那么这三者之间便组成了一个包含四个取向的系统:
A对X的倾向,包括A把X作为一个对象接近或回避的态度(以标志和强度为特征)以及对X的认知态度(信念和认知建构) A对B的倾向,与第1种情形一样。但纽科姆描述对人的倾向时,用的词是“正面的吸引”或“反面的吸引”,而描述对X的倾向用的词是“喜欢”或“不喜欢”。 B对X的倾向 B对A的倾向
以及对X的认知态度(信念和认知建构) A对B的倾向,与第1种情形一样。但纽科姆描述对人的倾向时,用的词是 正面的吸引 或 反面的吸引 ,而描述对X的倾向用的词是 喜欢 或 不喜欢 。 B对X的倾向. B对A的倾向.")
59
纽科姆进一步分析: 如果A与B对X的意见不同,那么这种“趋向对称的张力”取决于A对X的态度有多强,以及A对B的吸引力有多大。当A对B的吸引力增强时,如果同时A对X的态度也增加,那么便会有如下结果:A会竭力与B达到对X态度的对称——而这很可能会实现,并且A很可能加强对B有关X的传播。

60
三、奥斯古特和坦南鲍姆的“和谐论” 在受者、信源或传者、被传播的对象之间,受者倾向于跟后两者保持态度上的和谐关系;受者是改变自己原先态度以适合信源或传者,还是否定或改变信源或传者,则取决于受者对信源或传者和被传播的对象的喜爱程度以及受者所拥有的跟具体传播活动相关的知识。

61
四、费斯廷格的“认知不和谐论” 弗斯汀格认为,当出现认知失调时,人们会感到心理上的不舒服。因此,当出现失调时,人们会努力减少失调,其方法是,改变行为认知元素(改变自己的行动)、改变环境认知元素(改变对环境的看法或改变环境)或增加新的认知元素(用新的认知元素来加以平衡)。同时人们还会主动地避免可能增加失调的情境和信息。 对于群体可能给个体产生的心理影响,费斯汀格的“认知失调理论”做出的解释是:社会群体是个体认知失调的主要来源,也是他消除和减少可能存在的失调的主要来源。
、改变环境认知元素(改变对环境的看法或改变环境)或增加新的认知元素(用新的认知元素来加以平衡)。同时人们还会主动地避免可能增加失调的情境和信息。 对于群体可能给个体产生的心理影响,费斯汀格的 认知失调理论 做出的解释是:社会群体是个体认知失调的主要来源,也是他消除和减少可能存在的失调的主要来源。")
62
减少由群体引起的失调的方法: 改变自己的观点,使之与其它人的认知一致; 影响他人的观点,使之与自己的观点一致;
以某种方式使自己与别人不可比。例如贬损别人,认为别人是白痴等。

63
第六节 态度改变理论之深入研究 一、卡茨的功能论 1、工具性的、调节性的、实用性的功能。 2、自我防卫的功能。 3、表述价值观的功能。
4、知识功能。

64
二、麦奎尔的防疫论 主要观点: 一个面对反面宣传的接受者,就像一个正受到一种病毒或疾病侵袭的人一样:反面信息(病毒)越强,构成的危害就越大;个人的防御力量越强,就越能很好地抵制反面宣传;个人的抵抗力越弱,就越易被反面信息感染。要增强某人抵抗疾病的能力,通常有两种方法:即滋补法和接种法。
越强,构成的危害就越大;个人的防御力量越强,就越能很好地抵制反面宣传;个人的抵抗力越弱,就越易被反面信息感染。要增强某人抵抗疾病的能力,通常有两种方法:即滋补法和接种法。")
65
三、莱平格尔的五种劝服性设计 美国学者奥托·莱平格尔在《说服性传播设计》(1968)一书中总结前人成果,提出了关于说服的五种设计模式:刺激---反应设计,激发动机设计,认知性设计,社会性设计,性格性设计,从而在态度改变的有关说服理论与说服的实际问题之间,在传播的理论研究者与专业工作者之间架起了一座桥梁,使理论研究的成果适用于实际传播活动中成了可能。
一书中总结前人成果,提出了关于说服的五种设计模式:刺激---反应设计,激发动机设计,认知性设计,社会性设计,性格性设计,从而在态度改变的有关说服理论与说服的实际问题之间,在传播的理论研究者与专业工作者之间架起了一座桥梁,使理论研究的成果适用于实际传播活动中成了可能。")
66
第三章 传播学定量研究理论

67
第一节 定量研究的特点 当代科学技术的迅速发展,促使社会科学的理论和方法向高度精确方向发展,井逐步改变其传统的定性分析的性质。在社会科学领域,定量分析方法虽然起步较晚,但终于被广泛应用,并明显地表现出其优越性,这方面的成果也越来越多。

68
一、精确化地研究传播现象 传播学运用精确的数据资料作为研究依据,突破了传统定性研究的局限性,使人们对社会现象的认识更精确,而科学本身也获得了更加完备的形态。

69
二、对传播过程进行随机性定量描述 信息传播是非常复杂、变幻莫测的社会现象,存在着大量的偶然因素。定量分析的统计决定论则对社会随机过程进行定量研究,并揭示其内在规律,使自然科学中的数理统计方法应用到社会科学领域。

70
三、数字模型在传播学研究中的使用 过去仅用于自然科学的数学模型,现在已广泛用于社会科学表达客体各要素之间的函数关系上。传播学应用定量分析方法后,许多用传统方法无法描述的系统内各要素的某些关系迎刃而解。

71
四、计算机的运用 现代社会科学在收集、整理数据资料和分析数据资料方面,已摆脱了手工方式而完全用计算机来完成。

72
第二节 经验社会学与定量研究 经验社会学是社会学早期的两大流派之一,是应用社会学的原理和方法,解决实际的社会问题,改进社会的一门学科。

73
一、理论社会学 法国社会学家孔德认为,理论社会学着重从理论方面对社会进行研究,对社会起诊断作用。 19世纪30—40年代,是理论社会学的形成时期,侧重于用自然科学的方法对社会进行综合认识的总体理论研究,力求探索社会生活的一般原理和法则。

74
理论社会学发展的第二个阶段是19世纪末至20世纪20—30年代。由于资本主义社会的矛盾日益激化,社会学逐渐从对社会的总体研究转向部门研究,从对社会体制的研究转向心理、文化研究。
第二次世界大战以后是社会学迅速发展的时期,这一时期由于科学技术的发展和经济形势的发展变化,社会问题日益增多,社会学的实用性大大加强,社会学分支也日益增加。

75
二、经验社会学理论 经验社会学是侧重于研究个别社会现象,解决社会实际问题的微观社会学。 经验社会学对传播学定量分析方法的主要影响,是经验社会学所特有的一套行之有效的研究程序和方法直接被传播学借用和移植。这些研究方法主要是:调查方法,包括问卷法、抽样法、观察法、实验法和个案法等;组织方法,主要是研究过程,包括制定研究计划,搜集资料,资料加工,分析结果和作出推论。经验社会学的这些研究方法对传播学的定量研究尤其是实地调查产生过直接的示范影响。

76
第三节 定量研究中的统计数学 统计数学是现代数学的分支,主要包括概率沦与数理统计学这两个部分,前者是统计数学的基本理论,后者是统计数学的具体方法。其在传播学研究中的应用非常广泛。

77
统计学在传播学研究中的应用 1.抽样技术。抽样的要求、必要数目和怎样抽样以及可能产生的误差。 2.样本的数量、代表性及其总体可靠性的检验。 3.测量工具的准确性和有效性判别。 4.对测得(搜集)的数据进行整理、分析 5.对结果的推论和假设。

78
第四节 心理学对定量研究的渗透 传播学研究心理学的影响主要是对心理学的一套测量技术的移植和应用。

79
定量研究中的心理学方法 1.问卷调查法 2.心理测验和智力测验 3.态度量表 4.社会计量法

80
第五节 计算机在定量研究中的应用 一、计算机的发展应用 通常,我们可以将计算机分为四种类型,微型的、小型的、大型的、巨型的。
计算机无论大小,基本由两大部分组成:硬件(hardware),即计算机的可见部分;软件(software),即计算机的运行部分。但不管计算机如何进步,都由操作系统(operating system,os)控制。
,即计算机的可见部分;软件(software),即计算机的运行部分。但不管计算机如何进步,都由操作系统(operating system,os)控制。")
81
二、计算机在传播学研究中的应用 计算机在传播学研究中,主要是做统计分析(statistic analysis),因为计算机能够处理统计过程中最繁杂的计算公式。在传播学研究中,最常用的有两种统计处理软件:SPSS—X软件和SPSS—PC+软件,这是社会科学研究中最常用的软件,前者适合大型主机,后者适合个人计算机。
,因为计算机能够处理统计过程中最繁杂的计算公式。在传播学研究中,最常用的有两种统计处理软件:SPSS—X软件和SPSS—PC+软件,这是社会科学研究中最常用的软件,前者适合大型主机,后者适合个人计算机。")
82
第四章 程序与设计

83
方法是科学的结晶,方法又是科学发展的桥梁。本章所要阐述的是定量研究方法的具体内容和实施要点。

84
第一节 定量研究的基本步骤 定量研究方法的具体步骤一般说可以归纳为10个方面: (1)研究题材的选择; (2)研究目的和假说;
第一节 定量研究的基本步骤 定量研究方法的具体步骤一般说可以归纳为10个方面: (1)研究题材的选择; (2)研究目的和假说; (3)研究的理论依据; (4)研究的具体方法; (5)样本和抽样设计;
研究题材的选择; (2)研究目的和假说; (3)研究的理论依据; (4)研究的具体方法; (5)样本和抽样设计;")
85
(6)收集资料的方法; (7)工具的确定和设汁; (8)资料的登录和分类; (9)资料分析方法设计; (10)研究报告。 这10个步骤中的各个步骤之间都是相互联系、步步相依的。实际上又可归为3个阶段:即收集资料前的准备工作(1—6);收集资料(7);资料分析(8—10)。
收集资料的方法; (7)工具的确定和设汁; (8)资料的登录和分类; (9)资料分析方法设计; (10)研究报告。 这10个步骤中的各个步骤之间都是相互联系、步步相依的。实际上又可归为3个阶段:即收集资料前的准备工作(1—6);收集资料(7);资料分析(8—10)。")
86
第二节 课题选择与假设 一、传播学理论研究的领域
第二节 课题选择与假设 一、传播学理论研究的领域 传播学研究既有描述性研究,也有推断性研究,描述性研究主要通过对传播过程的研究,定量地描述传播现象。

87
二、应用研究 应用研究是解决当前传播学所关心的问题的研究,是传播所涉及的各个具体问题的研究,如传播过程的研究,传播媒介的研究,传播者和受传者的研究,传播效果的研究,反馈的研究等。

88
三、选题的论证与分析 有了初步的研究概念后,就要对所选课题进行分析,即在从大量一手资料(如学术刊物、专业性刊物、大众传播媒介、中寻找到研究题目之后,首先要对选题进行分析,以证实所选课题的价值。确定和证实选题的价值主要从以下几个主要方面着手分析。

89
—是所选课题的重要性和研究范围 二是研究的成果是否具先进性和前瞻性 三是经费的投入是否有问题 四是研究成果具普遍价值或典型价值

90
四、假设 所谓“假设”是在对选题进行分析后提出的猜想,通过研究来证实假设是否成立。这些在开展研究时提出的假设有时是对变数之间关系的描述,通过研究来证实,有时是研究者在研究前,根据过去的经验(或资料)所提出的,是一种判断或是在不能确定研究结果时所采取的方法。
所提出的,是一种判断或是在不能确定研究结果时所采取的方法。")
91
第三节 研究设计 1.确定收集资料的方法 2.确定调查队伍 3.确定工作语言 4.收集有关研究的资料

92
第四节 资料分析与解释 资料的分析和解释取决于研究目的和研究方法。不同的研究目的有不同的分析方法,有的分析只涉及一个简单的问题,有的分析则可能比较复杂。

93
第五节 工作定义 一、变量 变量一般分自变量和因变量。研究人员对自变量进行有系统的改变,对因变量加以观察,井假定其价值依赖于自变量的变化。

94
二、测量 定量研究要求对所考虑的变量进行测量,它关心的是一个变量的存在频率,能用数字准确地报告研究结果,特别是使用非常有效的数学分析方法。

95
三、离散变量与连续变量 这是大众传播中常用的两种形式的变量。 离散变量只包含有限的一系列值,不能分成子部分。 连续变量有任何值(包含分数),可以被分成有意义的子部分。
,可以被分成有意义的子部分。")
96
四、尺度与指数 尺度与指数都代表变量的合成测量手段,也就是基于好几项的测量方法。对有些复杂变量不易进行单项或单指示值测量,尺度与指数则用于此类变量。不用尺度与指数也能对有些项进行测量,如报纸的发行量。但测量其他项则需要尺度与指数,如对电视新闻的态度。

97
五、量表 量表是测量变量的组合。可以依据测量的项目不同而分为等距量表、层式量表、总加法量表、语意分析量表。

98
第五章 实地调查

99
第一节 概述 实地调查是在传播研究范围内,研究分析传播媒介和受传者之间的关系和影响。实地调查的目的不仅在于发现事实,还在于将调查经过系统设计和理论探讨,并形成假设,再利用科学方法到实地验证,形成新的推论或假说。实地调查是传播学研究中最常用最主要的方法。

100
一、实地调查的科学性和实用性 实地调查在所有研究方法中占有重要地位,也是传播学研究首选的方法。从使用面广上可充分说明其具有较高的实用性,其研究方法的严密和系统则显示出其科学性。

101
二、实地调查的分类 从社会学角度分类 : 普通调查与特殊调查 从调查的方法分类: 直接调查与间接调查 按调查性质分类: 量的调查与质的调查

102
三、实地调查的特点和问题 实地调查是在真实的环境下进行的,能较多地排除外部因素的干扰。
其次是调查途径十分合理,一般来讲,可根据经费和时间情况,采用具体的途径.如邮函调查、电话调查、面访调查、问卷调查。 实地调查范围较为广泛,可从各种社会成员中收集资料,利于调查人员或研究人员检查各种变量,使用多元统计来分析收集到的资料。

103
实地调查的不足: 研究人员不能像在实验室那样对自变量加以操纵,因果关系难以证实。 问卷上不适当的用词和问题,会使结果有所偏差。 第三个不足是被调查对象不合适。 最后一个不足是调查内容越来越复杂,特别是某些专门研究,得不到配合,如电话采访时遭到拒绝;信函调查时,问卷不能及时回收,或得不到足够的合格问卷;面访时需要赠送小礼品,而经费却捉襟见肘。

104
第二节 问题设计 一、建构出色的问题 在设计具体问题时应注意三点: 第一是所提的问题必须十分明晰,不至于引起被调查对象误解、猜想、费解。
第二节 问题设计 一、建构出色的问题 在设计具体问题时应注意三点: 第一是所提的问题必须十分明晰,不至于引起被调查对象误解、猜想、费解。 第二是表述上尽量用中性词和口语,以免引起暗示、引示、提示的作用,造成被调查对象的“顺藤摸瓜”、“见风使舵”。 第三是问题要集中,数量不要太多。

105
二、开放式和封闭式问题 一般来说,问题可分成两类,即开放式问题和封闭式问题。
开放式问题的特点是被调查对象可自由回答,轻松面对。调查对象充分表达意见,甚至可能提供调查人员预计不到的资料。 封闭式问题是研究人员预先为被调查对象提供了多项选择,不仅所提问题较为大众化,同时可以用数量表示,统计分析也比较快捷。

106
三、问题设计的一般原则 (1)问题清楚。 (2)问题短。 (3)提问题紧扣研究主题。 (4)词意准确明了。 (5)用中性词。 (6)不要提敏感和个人隐私的问题。
问题清楚。 (2)问题短。 (3)提问题紧扣研究主题。 (4)词意准确明了。 (5)用中性词。 (6)不要提敏感和个人隐私的问题。")
107
第三节 抽样设计 抽样就是从符合调查要求的社会总体中抽取—部分样本,把它当成总体的代表加以综合研究。 (1)经济可行。 (2)时效性强。
第三节 抽样设计 抽样就是从符合调查要求的社会总体中抽取—部分样本,把它当成总体的代表加以综合研究。 (1)经济可行。 (2)时效性强。 (3)可信性强。
经济可行。 (2)时效性强。 (3)可信性强。")
108
第四节 实地访问 实地访问主要是用嘴去问,用眼睛去看,用耳朵去听,是直接感知社会、获取第一手资料的方法。
第四节 实地访问 实地访问主要是用嘴去问,用眼睛去看,用耳朵去听,是直接感知社会、获取第一手资料的方法。 实地访问的最大优点是研究人员同被调查对象面对面的交流,调查访问的过程是—个互为影响、互为作用的动态过程,是一个积极的、双向的作用过程,是可以深入调查、进行高层次研究的方法。

109
一、实地访问的主要类型 实地访问可以分为结构性调查(访问)和主题性调查(访问)。 结构性调查是采用问卷的方法,这种方法对访问对象、访问的问题、访问的方法都在事先作了统一规定,制作了统一的标准化的问卷,不受当时情景的影响。 主题性调查是按照事先设计好的访问大纲进行的,访问的内容虽然已经在事前有一定的规定性,但根据调查现场情形进行调控,研究人员可根据场景及时调整访问内容、时间、顺序,只要不离开调查主题。

110
二、实地调查的准备与实施 访问的准备。设计详细的调查提纲;选择并预先了解被调查对象的情况;拟定访问计划,包括联系方式,访问的时间、地点,预测可能出现的问题;准备好访问时所需的工具,如办公文具,调查表格,调查说明书,必要的调查证明,计算器,照相机,摄像机,录音机,礼品等。 访问的实施。同被调查对象见面,尽量建立相互信任的关系;自我介绍,说明调查的内容,提出首先访问的问题。控制访问。控制现场,控制提问,控制访问的发展与深入。结束访问。访问时间不要过长,一般不超过两小时,结束时间把握在气氛较为活跃时。

111
三、实地调查的技巧 实地调查特别是主题性访问,注意技巧有利于收集到更多的资料,因此要特别强调访问的准备,而访问技巧又是很难从书本上找到的,完全是调查人员的实践与体验。

112
主要技巧 : 1.求同接近被调查对象。称呼恰当,举止随意而礼貌,从谈身边事、家常事开始。 2.友好接近被调查对象。 3.隐性接近被调查对象。

113
第五节 实地观察 一、实地观察的特点与要求 实地观察是调查人员有目的、有组织、指向明确、有计划的了解社会现象的活动,是调查人员主动采取的单向的调查研究,调查对象可能是人也可能是物,但都是在不知不觉中被观察。因此,调查人员对观察的组织是十分严密和规定性的。它要求被观察对象处于良好的被观察的环境下,同时要求调查人员有非常丰富的观察实践经验和技巧。

114
二、认真设计、严密组织实地观察 组织实地观察,要按一定的程序实施,主要是以下几项: 根据研究课题,制定观察计划,确定具体的观察内容。观察内容不外乎背景,即被调查对象存在的自然环境和社会环境。 被调查对象的行为,如果被调查对象是人,就应观察人的学习、工作、生活、社会活动、社会联系、人际关系等。 认真收集观察到的资料,包括借助物理手段。观察记录尽可能详细,并反复观察,对同步记录、事后补记录及时进行整理、补充。 撤离观察场所时,不要破坏观察环境,不要引起突然变化。

115
三、评估观察结果 1.总结观察效果,检讨观察过程。 2.寻找观察误差。 3.整理观察资料。

116
第六节 统计分析 一、描述性统计分析 描述统计分析的任务是对这些资料进行初步的整理和归类,以找出这些资料的内在规律——集中趋势和分散趋势。描述这些趋势的形式是各种数字所表示的统计量,如均数、百分比、标准差。在研究方法中,习惯地将这些形式称为单因素分析。

117
二、推断性统计分析 推断统计分析是研究样本同总体关系,它包含检验和评估两个层次。前者是以经过检验的样本为依据,推测总体的情况。

118
三、相关分析与因果分析 相关分析是探讨两个现象之间是否存在一定的关联,例如青少年的犯罪与订报、收看电视等。相关分析方法包含皮尔逊相关法、卡方分析法、等级相关法等,每种分析方法都有自己的适用范围。传播学实地调查中常用的是卡方分析。卡方分析的目的是发现观察值和期望值的差距。

119
第六章 内容分析法

120
内容分析(content analysis)是指对具体的大众传播媒介的信息所作的分析,是对传播内容的客观的、有系统的和定量的研究。传播内容不只是指大众传播媒介中的报纸、电视、书籍、杂志,凡是有记录、可以保存、具有传播价值的传播内容都在此列。 内容分析不仅是一种收集资料的方法,更重要的是一个完整的研究方法,其主要的目的是分析传播内容所产生的影响力。因此,内容分析是指对整个传播过程的分析,实际上是效果分析,是呈现大众传播媒介问题的有效方法。

121
第一节 奈斯比特的内容分析 《大趋势——改变我们生活的十个新方向》一书一出版,就赢得了成千上万的读者。人们被书中提出的独到见解所吸引,而冷静的研究学家却被书中所运用的研究方法所吸引。当然,作者奈斯比特也因此声名大震。

122
第二节 贝雷尔森和梅里尔的研究 贝雷尔森:“内容分析是一种对传播内容进行客观地、系统和定量地描述的研究方法”。
内容分析有3个方法论原则,即客观、系统、定量。 在范围上不仅分析传播内容的信息,而要分析整个传播过程。

123
美国德克萨斯大学新闻系教授梅里尔曾用内容分析法研究《时代》周刊对杜鲁门、艾森豪威尔、肯尼迪3位总统的态度。首先分析了《时代》周刊对3位总统“说了什么”。结果发现该刊明显支持艾森豪威尔(褒92次,贬1次),对肯尼迪略有好感(褒31次,贬14次)。接着梅里尔又分析了《时代》在捧和骂总统时所采用的手法(即“如何说”),其中有如“对事实有意取舍”,“把报道对象与一些声名不佳者相联系”等。
,对肯尼迪略有好感(褒31次,贬14次)。接着梅里尔又分析了《时代》在捧和骂总统时所采用的手法(即 如何说 ),其中有如 对事实有意取舍 , 把报道对象与一些声名不佳者相联系 等。")
124
第三节 内容分析的特点 一、内容分析是较为客观的研究方法
第三节 内容分析的特点 一、内容分析是较为客观的研究方法 内容分析完全是从现有文献资料出发,研究者按设计好的程序进行研究,研究人员的主观态度和偏好,不太容易影响分析研究的结论(结果),就是不同的研究者用同样的研究方法研究同样的内容,研究的结果应当是相同的。
,就是不同的研究者用同样的研究方法研究同样的内容,研究的结果应当是相同的。")
125
二、内容分析是数量化的分析 所谓数量化的分析是对分析的内容(信息)进行准确的数量描述,排除了许多的主观判断,使研究结果有可靠的信度(准确性)。由于提供了许多描述性数字,使人们看到的是用数字描述的分析对象,而不是研究人员的主观判断,有助于自己去向受众或社会解释和分析检验对象。
进行准确的数量描述,排除了许多的主观判断,使研究结果有可靠的信度(准确性)。由于提供了许多描述性数字,使人们看到的是用数字描述的分析对象,而不是研究人员的主观判断,有助于自己去向受众或社会解释和分析检验对象。")
126
三、内容分析是系统的分析 内容分析采取科学的抽样方法,按特定的程序抽取,每个单位都有接受分析的机会;分析的内容是按明确的课题设计,一致的规则来确定;分析过程是用系统的、相同的方法处理;资料的统计是按预先设计的程序,通过计算机进行的。

127
四、内容分析是比较经济的分析方法 由于内容分析是以现有文献资料为检验对象,工作量相对较小,且大部分工作在室内进行,减少了经费开支。在中国,公费订阅的媒介数量很多,研究者可以花很少的钱或不花钱使用。这无论对于商业研究还是学术研究,都是比较有利的,是可以普遍开展的研究方法。

128
第四节 内容分析的应用 一、描述传播内容 二、检验假设 三、了解大众传媒传播内容的客观性 四、评估社会个体或团体的形象

129
第五节 内容分析的步骤 一、确定研究目的、范围和假设 研究开始,首先要明确目的,选择什么样的信息材料,避免在收集资料的过程中漫无目的。
第五节 内容分析的步骤 一、确定研究目的、范围和假设 研究开始,首先要明确目的,选择什么样的信息材料,避免在收集资料的过程中漫无目的。 在确定了研究目的之后,就应该设计研究主题,设计研究步骤,提出假设的原始资料和其他媒体研究的原始资料相同。有了研究步骤,提出假设,进一步的工作是确定研究范围,就是内容分析的资料界限。

130
二、抽取样本 内容分析多实行多阶抽样方法。首先是对研究的内容的原始资料进行抽样。 抽样后,就要设计内容分析分类统计表。

131
三、分类 分类就是建立媒体内容分类的类目系统(category system),这个类目系统的构成是根据研究的内容和主题不断变化。 首先要定出分类方法或标准。按照分类标准去处理经过抽样而得到的信息资料,需要3名以上经过短期训练的评分员,分别对同一资料进行分类,然后计算一致同意的部分,并对有分歧的部分进行分类。有分歧意见的材料不列入统计结果。

132
四、量化与统计 经过分类后的信息资料,需要用数量来反映其基本趋势与内在结构。这时,常用的数量概念有绝对数、百分比、平均值等3种。 内容分析的量化主要涉及名目、等距和等比三种测量尺度。

133
第七章 控制实验

134
在传播学研究中,为了显示传播因素间直接的因果关系,常常使用实验研究方法,利用实验室的控制方式,测验传播因素之间直接影响的关系。

135
第一节 实验的目的 1.建构因果关系 2.控制变数。 3.反复进行。 4.经费投入少。 5.便于特别研究。

136
第二节 实验的特征与控制 一、实验的特征 控制实验中控制是该方法的主要特点。在复杂的传播活动中,就是靠控制寻求因变数和自变数的因果关系。

137
二、实验的控制 实验的控制,一般认为由两个方面组成。 1.相关因素的隔离 传播是异常复杂的过程,影响因素很多。要研究传播与受传者的直接因果关系,必须消除外涉影响,即把现实状态下的自变数和因变数转至实验状态。但在转移过程中,损失了现实因素的原有状态,即被测对象接受同样的测验,在现实状态下和实验状态下是有差异的。但这是任何研究方法所无法避免的,只有在实验过程中加以考虑。

138
2.实验刺激强度 把相关因素隔离在实验之外,就只剩下传播与受传者这一对关系。在受传者和信息这一对关系下,信息应视为对受传者的刺激(S),要测量的是受传者对刺激的反应(R)。研究者不断增强和减弱刺激的强度,以观察和记录R的变化情况。
,要测量的是受传者对刺激的反应(R)。研究者不断增强和减弱刺激的强度,以观察和记录R的变化情况。")
139
三、实验的确立 控制实验是以探究信息刺激与受传者反应之间的因果关系为己任。因此,实验的前提是确立一至数个命题,即对信息与受传者之间是否有因果关系作出假定,实验就是为了推论或否定、限定这个推论。美国A·坦和K·斯格罗格作过一次实验,以“社会学习论”为假说的理论依据,认为儿童的行为与价值观念是从阅读连环画的直接示范中学得的。他们的假说是“阅读暴力连环画,将引起儿童好斗行为的增加”。从这个例子我们了解到,一个假设由原因、因变量、自变量同因变量之间关系的方向这3个因素构成,因变量是研究者最为关心的问题。当然,自变量同因变量之间的关系的方向可以是正向的,也可能是反向的。

140
第三节 实验的实施 实验大多数要经过10个步骤: 一、选择实验环境 二、实验设计 三、运用变量 四、确定操纵自变量的方法 五、选择测试对象
第三节 实验的实施 实验大多数要经过10个步骤: 一、选择实验环境 二、实验设计 三、运用变量 四、确定操纵自变量的方法 五、选择测试对象 六、实验材料的制作 七、预先实验研究 八、观测工具 九、测量程度设计 十、数据分析

141
第四节 实验的设计 一、基本实验设计 1.关于预测—后测的控制组 R O1 X O2 R O1 O2 O1 表示前测 O2 表示后测
第四节 实验的设计 一、基本实验设计 1.关于预测—后测的控制组 R O1 X O2 R O O2 O1 表示前测 O2 表示后测 X 表示实验处理

142
2.关于后测的控制组 R X O1 R O2 R 表示随机抽样

143
所罗门四组设计 R O1 X O2 R O O4 R X O5 R O6

144
二、因素研究 1.多因素设计 包含两种或两种以上的自变量的分析研究称为多因素设计。 温默与多米尼克的实例:电视台了解电影系列影片的促销活动是否成功。

145
2X2多因素设计 有收音机 无收音机 有报纸 无报纸

146
2X3多因素设计 有收音机 无收音机 彩色报纸广告 黑白报纸广告 无报纸

147
2X3多因素设计 有收音机 无收音机 有电视 无电视 有电视 无电视 有报纸 无报纸

148
第八章 个案研究

149
个案研究(case study)是了解某一特定现象,在其特定范围内、特定时间内的综合情况的研究方法。个岸研究也是一种调查方法,或是调查的一种类型,是和统计调查法相对而存在的。
是了解某一特定现象,在其特定范围内、特定时间内的综合情况的研究方法。个岸研究也是一种调查方法,或是调查的一种类型,是和统计调查法相对而存在的。")
150
第一节 个案研究的意义 在传播学研究中,个案研究主要用于传播者的研究,即关于人(法人)的研究,包括编辑、记者、通讯社、报社、广播电台、编辑部等。 个案研究一般不用于实证什么,因为个案研究事先没有假设,结果也不能得出假设。但个案研究可用于调查某些行为。
的研究,包括编辑、记者、通讯社、报社、广播电台、编辑部等。 个案研究一般不用于实证什么,因为个案研究事先没有假设,结果也不能得出假设。但个案研究可用于调查某些行为。")
151
第二节 个案研究的特点 一、梅里姆的见解(Merriam,1989) 个案研究的四个特点: 1.特殊性(Particularistic)
第二节 个案研究的特点 一、梅里姆的见解(Merriam,1989) 个案研究的四个特点: 1.特殊性(Particularistic) 2.描述性(Descriptive) 3.启发性(Heuristic) 4.渐进性(Inductive)
 个案研究的四个特点: 1.特殊性(Particularistic) 2.描述性(Descriptive) 3.启发性(Heuristic) 4.渐进性(Inductive)")
152
二、温默和多米尼克的观点 个案研究能提供丰富的资料,有利于研究者发现和寻找到更多的研究线索和概念。个案研究不仅在研究的初期十分重要,而且还能用于描述性和解释性的资料研究。个案研究常常有助于研究者讨论更大范围的现象,包括文献资料、文物资料、系统的观察、直接观察和和传统的调查研究方法。

153
个案研究的缺点也很明显,主要是三个方面:
1.个案研究缺乏严谨的科学性; 2.个案研究不容易推论; 3.个案研究需要花费很多时间。

154
第三节 个案研究的实施 个案研究的实施步骤: 1.设计 2.预研究 3.实验 4.收集资料 5.资料分析 6.提出研究报告

155
第四节 撰写研究报告 一般来说,研究报告主要包括几个方面: 1.研究的主要问题、目的和范围; 2.研究方法和步骤;
第四节 撰写研究报告 一般来说,研究报告主要包括几个方面: 1.研究的主要问题、目的和范围; 2.研究方法和步骤; 3.研究的人力、经费、物资材料; 4.研究过程及碰到的主要问题; 5.研究的发现和结果; 6.进一步深入研究的设想。

156
第九章 抽样设计与实施

157
作为传播学的定量研究方法,抽样调查也当然成为本书不可或缺的一部分。事实上,抽样理论本身已经发展为一门独立学科。

158
第一节 概述 一、样本设计一般规则(Leslie Kish,1985) 1.目的明确,根据研究和调查目的而进行;
第一节 概述 一、样本设计一般规则(Leslie Kish,1985) 1.目的明确,根据研究和调查目的而进行; 2.可度量性,能从样本自身计算出有效估计值或抽样变动的近似值; 3.实用性,与实际设计的模型的配合尽量好; 4.经济性,用最少的经费完成调查目的。
 1.目的明确,根据研究和调查目的而进行; 2.可度量性,能从样本自身计算出有效估计值或抽样变动的近似值; 3.实用性,与实际设计的模型的配合尽量好; 4.经济性,用最少的经费完成调查目的。")
159
二、抽样方法的选择(Roger Wimmer和Joseph Dominick )
1.研究目的; 2.成本与价值; 3.允许误差范围; 4.进行重复测量。

160
第二节 随机和非随机抽样 一、简单随机抽样 简单随机抽样应用并不广泛,只作一般调查之用。
第二节 随机和非随机抽样 一、简单随机抽样 简单随机抽样应用并不广泛,只作一般调查之用。 简单随机抽样虽然不常使用,但常被研究者提出来研究,这是因为简单随机抽样的数学性质比较简单。 简单随机抽样的优点也非常明显:研究人员不需对研究总体作过多的调查;可以统计推断外在的效度;容易找到一组具有代表性的对象;排除了分类误差。

161
二、系统随机抽样 系统随机抽样与简单随机抽样很相似,其抽样方法是在研究总体每隔一个固定的区间便抽取一个单位。 在大众传播学的定量研究中,系统随机抽样法常被使用,因为与简单随机抽样相比,系统随机抽样省时省力,样本的代表性也比简单随机抽样好。 系统随机抽样的最大缺点是容易遇到周期性误差,就是所选的单位在排列和顺序上的偏差。

162
三、分层随机抽样 分层随机抽样抽取的样本都来自研究总体,抽取的单位来自具有相似性特征的总体,具有同质性。 以研究总体中所占比例为根据,分层随机抽样方法有两种形式,一种是比例分层抽样法,另一种是非比例分层抽样法。

163
分层随机抽样法的优点是,能够表现相关变量的代表性,可以同其他研究总体相比较,样本选自同质群体,抽样误差少;但分层随机抽样也存在一定的缺陷,选择前必须详细了解研究总体的情况,抽样成本较高,分层标准很难掌握,中选几率较低。

164
四、集体随机抽样 集体随机抽样法是将研究总体分成若干区域,然后再从若干区域中抽取一部分区域作为样本。 集体随机抽样法容易产生两种误差,一种是选定原始团体时的误差,另一种是自若干区域中取部分称作为样本的误差。为了减少这种误差,较容易的办法是将区域分得很小,降低每一区域中个体的数量,又能选取更多的区域。 在集体随机抽样法中,多段抽样法常被使用。多段抽样法就是将研究总体分成若干阶段。

165
五、非随机抽样 非随机抽样方法分为现成样本、自愿样本和立意样本等形式。 现成样本也叫便利样本,对容易得到的被调查对象进行调查,取得有用资料,但其样本的信度低。 自愿样本并非按照数学原则选出,也是一种非随机样本。

166
立意抽样是针对具有某种特性或质量的对象进行抽样,并常常被用于大众传播的广告研究。
配额抽样是同立意抽样类似的方法,按照特定和已知的比例选择对象。 偶然性抽样也是一种非随机抽样方法,它按照表面特征或某种特征要求偶然选择对象,它是研究者的主观行为和意志的研究,误差已在考虑之中。

167
第三节 样本数量、抽样误差和抽样加权 一、样本数量(Roger Wimmer和Joseph Dominick) 1.考虑所选用的研究方法;
第三节 样本数量、抽样误差和抽样加权 一、样本数量(Roger Wimmer和Joseph Dominick) 1.考虑所选用的研究方法; 2.按人口统计分类抽取样本; 3.根据时间和经费情况决定样本数量; 4.多变量研究比单一变量研究需要更多的样本; 5.抽取的样本要比实际需要样本多一些; 6.已作过研究的问题可作参考; 7.样本大比小好。
 1.考虑所选用的研究方法; 2.按人口统计分类抽取样本; 3.根据时间和经费情况决定样本数量; 4.多变量研究比单一变量研究需要更多的样本; 5.抽取的样本要比实际需要样本多一些; 6.已作过研究的问题可作参考; 7.样本大比小好。")
168
二、抽样误差 抽样误差就是测量样本得到的结果与总体实际不相符合。 只有随机样本才能评估出抽样误差,而非随机抽样是无法估计出抽样误差的。 评估抽样误差就是测量和断定样本和总体之间的差异。

169
三、抽样加权 在较科学和理想的调查中,研究者应有足够的研究对象,如较多的访问对象,较多的问卷。但在实际研究中,常常事于愿违。在既不能有较多研究对象又不能取消研究时采取的办法就是抽样加权。加权就是当样本总数未能达到需求的比例时,将得到的答案进行加倍(或加权)处理,以补不足。对单一对象的回答可乘以1.3,1.7,2.0或其他任何数字以达到事先决定的标准。
处理,以补不足。对单一对象的回答可乘以1.3,1.7,2.0或其他任何数字以达到事先决定的标准。")
170
第十章 问卷设计与可行性分析

171
问卷是在社会研究(包括传播研究)中用来收集资料的一种工具,它的形式是一份精心设计的问题表格:研究人员根据所要调查的内容和问题,编排成一种统一的表格形式,收集所有调查对象的回答,从而获得第一手资料。问卷作为一种普遍使用的测量工具,主要用来测量人们的基本状况、行为和态度。
中用来收集资料的一种工具,它的形式是一份精心设计的问题表格:研究人员根据所要调查的内容和问题,编排成一种统一的表格形式,收集所有调查对象的回答,从而获得第一手资料。问卷作为一种普遍使用的测量工具,主要用来测量人们的基本状况、行为和态度。")
172
第一节 概述 一、问卷调查的发展 问卷调查的历史最早可以追溯到公元前几千年中国和古埃及以课税和征兵为目的进行的调查。近代问卷调查则开始于1748年进行的全国规模的人口普查。 20世纪以来,问卷越来越多地被用于定量研究,与抽样调查相结合,已成为定量研究的重要方式之一。

173
二、问卷调查的特点 1、问卷调查的优点: 节省时间、精力和人力; 便于横向和纵向研究,资料收集速度快; 客观性强,可以避免资料收集的主观随意性,调查结果便于定量处理和分析; 有很好的匿名性,便于收集敏感性资料。

174
2、问卷调查的弱点: 受主客观条件的限制多; 获得的信息有限; 回收率和资料质量难以保证。

175
第二节 问卷的类型 一、按问卷填答方式分类 自填式问卷和访问式问卷:
第二节 问卷的类型 一、按问卷填答方式分类 自填式问卷和访问式问卷: 自填式问卷主要由被调查对象自己填答,匿名性好,能在较大程度上真实反映被调查对象的基本状况、态度与行为,但要受到被调查对象本人文化程度、情绪等主观因素的限制,另外,回收率也很难保证,比访问式问卷的回收率要差。

176
访问式问卷由访问员向被调查对象提出问题,填写问卷,问卷的回收率较自填式问卷要高。但同时,问卷的匿名性受到了威胁,使一些敏感性的问题难以启齿。

177
二、问卷的发放方式分类 按问卷的方法方式不同,可分为发放式问卷、访问式问卷、邮寄式问卷、报刊式问卷、电话式问卷、网络式问卷等6种。

178
发放式问卷,即由调查员将问卷直接发送到被调查对象手中,由被调查对象个别或集中填答,最后由调查员逐一收回。
访问式问卷,就是调查员按照统一设计的问卷向被调查者当面提出问题,然后再由调查员根据被调查者的口头回答来填写问卷。

179
邮寄式问卷通过邮局寄给被调查对象,被调查对象填答完后又通过邮局寄回。
报刊式问卷,就是在报刊杂志上刊登问卷,请刊物的读者填答,然后在规定的时间内将问卷邮寄回报刊杂志的编辑部。 电话式问卷,就是调查者通过电话向被调查对象提出问题,并将被调查对象的选择答案填写在问卷上。 网络式问卷是一种新出现的形式,它是随着计算机技术的发展而日益完善的。

180
三、按问卷的结构分类 结构式问卷和无结构式问卷 结构式问卷是指调查者在设计问卷的时候,将所有可能的答案全部列在问题的下面,请被调查对象在这些给定的答案中选择。 开放式问卷与封闭式问卷的形式恰恰相反。开放式问卷是指调查者只给出问题,在问题的下部留出适当的空白处让被调查对象自由填写。

181
四、半开放式(半封闭式)问卷 一般情况下,半开放式问卷的前半部分以封闭式问题、半开放式问题为主,开放式问题常常放在问卷的最后,主要是用于征询被调查对象对某件事的看法或一些意见、建议等。这种问卷在一定程度上可以弥补上述两种问卷的缺点,既易于后期的统计分析又可以使被调查对象的想法充分地表达出来。半开放式问卷是调查中较为常用的一种问卷形式。

182
第三节 问卷的结构 一、封面信 封面信是一封致被调查对象的短信,是调查者对被调查对象的自我陈述,即说明问卷调查的合理性。其主要内容是向被调查对象介绍说明调查者的身份、调查内容、调查目的、被调查对象的选取方法和调查结果的保密措施等,以取得被调查对象的合作,篇幅一般为二三百字。

183
上海市大众传播媒体舆论监督调查问卷 亲爱的朋友: 您好! 受上海市有关部门的委托,我们要调查上海市民对大众传媒舆论监督的反应,以测度舆论导向的现状和问题,论证监督导向的科学性和社会影响,从而为大众传播媒体进一步开展舆论监督提供参考意见。 按照随机抽样原则,您被选为受访者。我们衷心希望您能给予协助,回答问卷内的问题。对于您的回答,我们将根据《中华人民共和国统计法》第三章第四款之规定予以保密,仅用于科学研究的统计分析。 谢谢您的支持与合作! 上海大学影视艺术技术学院 1999年11月

184
二、问卷填答指南 卷填答指南是用来指导被调查对象填答问卷,或用来指导访问员如何正确进行访谈的各种解释与说明。 填答指南具体又可分为卷首说明与具体问题填答说明。卷首说明是对整个问卷填答的要求,具体问题填答说明则针对某特定问题的特别指示。

185
填表说明 (1)请在每一个问题后的答案中选择适合自己实际情况的选项,如果您是男同志,请在性别栏“1.男 2.女”中选择“1”选项。 (2)若无特别说明,每一个问题只能选择一个答案。 (3)填写问卷时,请不要受别人影响,独立地填写或独立回答访问员提问。
请在每一个问题后的答案中选择适合自己实际情况的选项,如果您是男同志,请在性别栏 1.男 2.女 中选择 1 选项。 (2)若无特别说明,每一个问题只能选择一个答案。 (3)填写问卷时,请不要受别人影响,独立地填写或独立回答访问员提问。")
186
9、您对报纸中的哪些内容比较感兴趣:(限选2项,将选项序号填在括号里)
[1] 政治类 [2] 经济类 [3] 文化类 [4] 体育类 [5] 社会生活类 [6] 法律类 [7] 娱乐类 [8] 教育类 [9] 国际时事类 [10] 其他_______ 1 ( ) ( )
 2 ( )")
187
三、问题与答案 问题与答案是问卷的主体,是资料收集的主要内容,也是调查所要涉及的主要内容。它是对被调查对象的主客观事实进行量度的操作性工具。

188
1.问题的形式 (1)填空式 如:您的年龄是________周岁。 (2)是否式 如:您家订阅报纸吗? 1.是 2.否 (3)多项选择式 如:请问您平时收看下列哪些类型的电视节目:(限选四项,将选项序号填在括号里)
多项选择式. 如:请问您平时收看下列哪些类型的电视节目:(限选四项,将选项序号填在括号里) .")
189
2.答案的设计 关于答案的设计,除了要与所提问题一致外,还应注意答案的穷尽性与互斥性原则。 答案的穷尽性,指现有答案中包括了所有可能的情况。 答案的互斥性,指答案之间不交叉重叠或互相包含。

190
3.相倚问题 在问卷中,经常遇到这种情况,有些问题只适用于调查样本中的一部分人。而且某个被调查对象是否应该回答这个问题,常常要根据他对前面某个问题的回答结果所定。这样的问题,我们称之为相倚问题,而前面的那个问题则称为过滤问题或筛选问题。

191
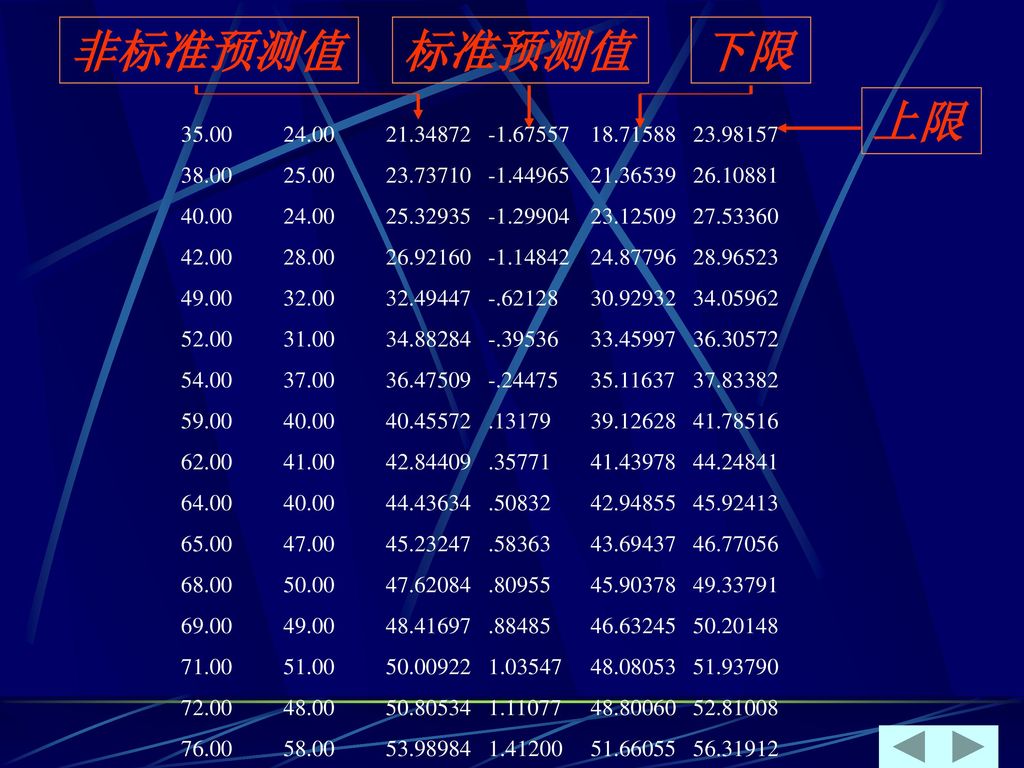
如: 你收听广播吗? (1) 否 (2) 是……………请跳过问题4到问题8 直接从问题9答起
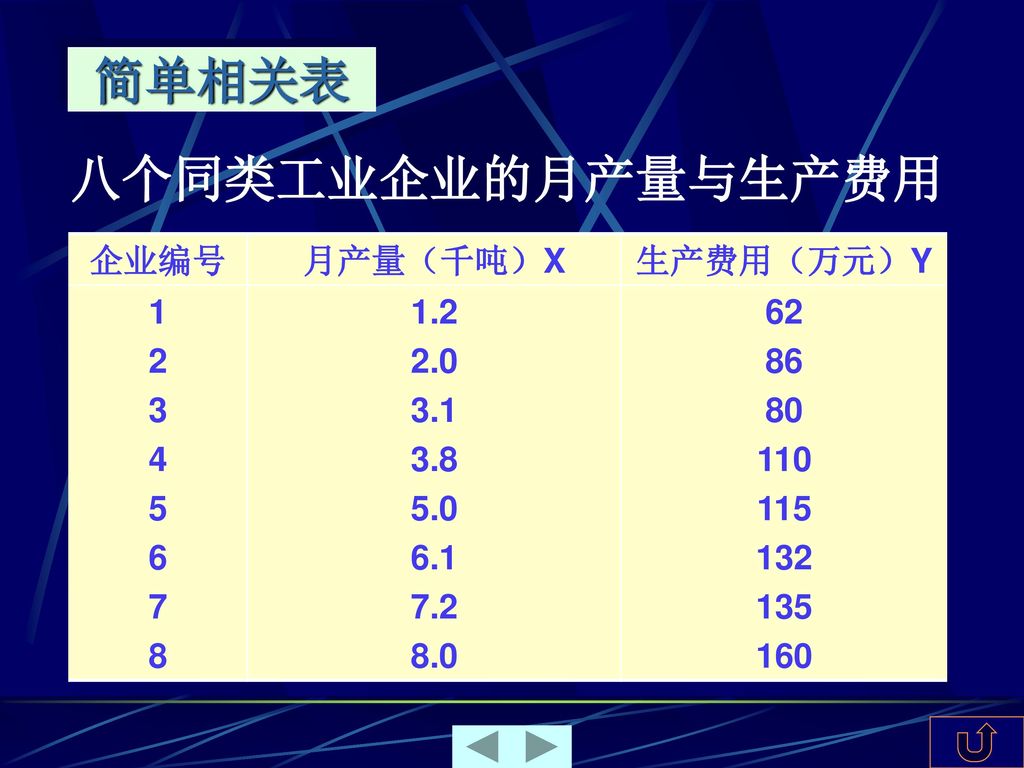
 否 (2) 是……………请跳过问题4到问题8 直接从问题9答起")
192
4.问题的数量与顺序 对于一项调查研究来说,调查问卷的容量即问题数量的多少,应视研究内容、样本的情况、分析方法、调查经费及其他因素而定。一般来说,问题不宜太多,可视研究内容的多少设计30—50个问题,被调查对象答题时间不超过半小时。

193
问卷中题目的顺序要考虑问题之间逻辑关系,要考虑从易到难,从一般到具体。
一般来说,问题的排列应按照询问的内容加以排列,同样内容的问题放在一起。一般的顺序依次为:个人基本情况,行为问题,态度问题。行为方面的问题,可以放在前面,而态度、意见、看法方面的问题可以放在行为问题之后。

194
对于每一部分的内部的具体顺序而言,一般是先问简单问题,再问复杂问题;先问回答者感兴趣的问题,再问枯燥的或敏感问题;先问回答者熟悉的问题,再问回答者感到生疏的问题。这样就使回答者即使在后面遇到难以回答的问题时,也能够顺利回答前面的绝大多数问题,从而保证问卷填答的有效性。

195
四、编码及其他资料 除了上述内容以外,问卷还包括一些相关资料,如问卷的名称、问卷发放回收时间、调查员、审核员、调查对象的地址、计算机编码等。

196
如: 上海市大众舆论监督调查问卷 问卷编号 访问日期: 年 月 日 访问地点: 上海市 区 居民区(行政村) 访问开始时间: 时 分
上海市大众舆论监督调查问卷 问卷编号 访问日期: 年 月 日 访问地点: 上海市 区 居民区(行政村) 访问开始时间: 时 分 结束时间: 时 分 访问员: 审核员:
 访问开始时间: 时 分. 结束时间: 时 分. 访问员: 审核员:")
197
第四节 问卷的制作 一、问卷设计的基本原则 1.问卷以研究目的为指导,为受众服务
第四节 问卷的制作 一、问卷设计的基本原则 1.问卷以研究目的为指导,为受众服务 首先必须考虑调查对象的具体情况,根据被调查对象的不同特点设计恰当的问卷。 其次,在设计问卷时也应考虑调查者的需要,即问题应主要围绕研究者所要研究的主要问题和所测量的主要变量来设计。

198
2.明确问卷调查的阻碍因素 主观障碍指的是被调查对象在心理上和思想上对问卷产生各种不良反应所形成的障碍。 客观障碍指由于被调查对象自身的能力、条件等方面的缺陷所形成的障碍,即被调查对象的素质难以适应问卷调查的要求。

199
3.问卷设计的具体因素分析 (1)调查目的 (2)调查内容 (3)样本的性质 (4)资料处理方式
调查目的 (2)调查内容 (3)样本的性质 (4)资料处理方式")
200
二、问卷制作过程 1.初步探索 2.设计问卷初稿 3.问卷试用 4.修改定稿

201
第五节 问卷的效度与信度 一、信度 信度即测量的可靠性程度,指的是测量工具测到所要测量内容的稳定程度。 1.再测信度 2.折半信度
第五节 问卷的效度与信度 一、信度 信度即测量的可靠性程度,指的是测量工具测到所要测量内容的稳定程度。 1.再测信度 2.折半信度 3.复本信度

202
二、效度 效度即测量的有效性程度,指的是测量工具或测量手段能够准确测出所要测量特质的程度。 1.内容效度分析法 2.准则效度分析法 3.构念效度分析法

203
三、问卷设计中常见错误分析 1.语言陈述问题 (1) 问题的语言要尽量简单易懂 (2) 问题的语言陈述应尽量简短 (3) 问题要避免带有双重或多重含义 (4) 问题不能带有倾向性 (5) 一般不能用否定方式提问 (6) 问题的设计要与答案相适应 (7) 问题设计要为调研对象考虑 (8) 关于个人隐私等 (9) 问题的提问方式要合理
 问题的设计要与答案相适应. (7) 问题设计要为调研对象考虑. (8) 关于个人隐私等. (9) 问题的提问方式要合理.")
204
2.样本偏差问题 在设计问卷之前,应该首先考察被调查对象的特点,根据不同的被调查对象,设计不同类型的问卷。

205
第十一章 描述性统计分析

206
由于计算机的普及和发展,在传播学研究中,定量研究的统计分析方法越来越受到重视,使用越来越普遍。
描述性统计(descriptive statistics)分析是运用统计数学解释所研究的对象,目的是用较少的数字来解释,使我们能够集中而清晰地看到有价值的内容。 描述性统计分析是定量研究的基础,是通过各种数据如总数、比率数、平均数、变异数、图表等来解释和表达研究的结果。
分析是运用统计数学解释所研究的对象,目的是用较少的数字来解释,使我们能够集中而清晰地看到有价值的内容。 描述性统计分析是定量研究的基础,是通过各种数据如总数、比率数、平均数、变异数、图表等来解释和表达研究的结果。")
207
第一节 概述 通过描述性统计资料我们可以做出几种趋势分析: 1.进行总体特征和趋势分析 2.进行集中趋势分析 3.进行参数趋势分析
4.进行相关分析

208
第二节 主要功能 描述性统计分析的主要形式有以下几种: 1.显示资料分布
第二节 主要功能 描述性统计分析的主要形式有以下几种: 1.显示资料分布 资料分布的方法之一是将资料在表或图中表示,每次分布都是一次数字的汇总。可以采用的方式有频率分布(frequency distribution)来表示,也可以用区间分组表示频率,除用表格来表示外,也可以用图形来表示。
来表示,也可以用区间分组表示频率,除用表格来表示外,也可以用图形来表示。")
209
2.主要指标 集中趋势统计指标: 众数,就是出现最频繁的分数,需要检验分布状况; 中位数,就是分布的中点,一半的分数在它上面,一半在它下面; 平均数,表示一组分数的平均数。

210
离散趋势测量方法 : 全距,一个分布中最高和最低分数之间的差距 ; 离散度量,提供分数偏离或不相符于平均数的程度的数学指数; 标准差,从一个分布的平均数得来的分数给定的距离。

211
第三节 常态曲线 常态曲线是描述统计分析的重要内容和工具。
第三节 常态曲线 常态曲线是描述统计分析的重要内容和工具。 该曲线是对称的,而且在它的平均数达到最高点,它的平均数也同时是它的中位数和众数。当曲线以这种方式表达时,它具有一个标准数分布的所有特征,这个特征是什么呢?就是曲线下面区域内固定的部分位于平均数和标准差的每个单位之间,曲线某一段下面的面积是落在那里的分数的频率的代表。

213
第四节 样本分析 样本分析(Sample distribution)是样本的范畴,也是其他分析单位测量出的特征分布。
第四节 样本分析 样本分析(Sample distribution)是样本的范畴,也是其他分析单位测量出的特征分布。 一旦确定抽样分布,就可能做出某一值出现的或然率(probability)。 或然率有两个重要原则。相加原则是指在一系列不相容事件中,任一事件发生的或然率也就是个别事件的或然率的总和。乘法原则是指独立事件组合体的或然率,是这些事件各不相同的或然率乘积。
是样本的范畴,也是其他分析单位测量出的特征分布。 一旦确定抽样分布,就可能做出某一值出现的或然率(probability)。 或然率有两个重要原则。相加原则是指在一系列不相容事件中,任一事件发生的或然率也就是个别事件的或然率的总和。乘法原则是指独立事件组合体的或然率,是这些事件各不相同的或然率乘积。")
214
第十二章 推断性统计分析

215
推断性统计分析是根据概率论和统计学原理,将随机抽取的样本进行统计,获得各种数值,如百分数、平均数、相关系数等,并以此为基础去推断相应的研究总体的研究方法。

216
第一节 非参数统计 一、卡方拟合优度分析 将某一现象的观测频率和期望或假设频率相比是大众传播研究人员经常采用的,目的是判断这种频率的变化是否真正有意义,即卡方统计(chi-square statistics),并通过卡方拟和优度检验实现。
,并通过卡方拟和优度检验实现。 .")
217
二、列联表分析 列联表分析法基本上就是拟合优度检验的扩展,不同点在于列联表分析法可以同时检验两个或更多变量。列联表分析法中,自由度尺度表示确定统计有效性,表示方法:(R—1)(C—1),R是行数,C是列数。
(C—1),R是行数,C是列数。")
218
三、两个样本之差的非参数分析 1.R检验 R检验(word- wolfwitz Runs Test)是通过从对两个总体中随机抽出的两个独立样本的某种趋势(平均数)和离散(离差)趋势的检验,来分析这两个总体的分布是否有差异。R检验可分为小样本R检验和大样本R检验。
是通过从对两个总体中随机抽出的两个独立样本的某种趋势(平均数)和离散(离差)趋势的检验,来分析这两个总体的分布是否有差异。R检验可分为小样本R检验和大样本R检验。 .")
219
2. U检验 U检验(Man Witney U Test)作为一种非参数分析方法,其假设条件与R检验完全相同,即两总体皆为正态连续分布的相同总体,量度层次为定序尺度。但是,U检验比R检验更容易做到,且信度高。特别是当两个总体的差异性主要表现在集中趋势程度上,并且离散不太显著的情况下,U检验比R检验更具效力。
作为一种非参数分析方法,其假设条件与R检验完全相同,即两总体皆为正态连续分布的相同总体,量度层次为定序尺度。但是,U检验比R检验更容易做到,且信度高。特别是当两个总体的差异性主要表现在集中趋势程度上,并且离散不太显著的情况下,U检验比R检验更具效力。")
220
四、参数统计 参数统计方法是处理高级数据的方法,这些方法都是假设数据呈正态分布。在大众传播学研究中最常用的参数统计方法是t检验。

221
1. t检验 t检验假设从中抽取样本的母体变量是否正常分布,还假设数据具有变异数同性,就是说数据偏离平均值程度相同。t检验的基本公式比较简单,公式的分子是样本平均与假定的总平均值之差,再除以平均值标准误差的估值(Sm)
 .")
222
2.变异数分析 变异数分析(analysis of variance)是t检验法的扩展,因为t检验法仅适用于一个变量比较,而变异数分析法可用来同时研究几个自变量,即因素(factors)。变异数分析法按研究中涉及的因素数目命名;研究一个自变量,叫单向变异数分析;研究两个自变量叫双变异数分析,依此类推。也可以用自变量的尺度对变异数命名。2*2变异数分析表示两个自变量,每个自变量有两级。
是t检验法的扩展,因为t检验法仅适用于一个变量比较,而变异数分析法可用来同时研究几个自变量,即因素(factors)。变异数分析法按研究中涉及的因素数目命名;研究一个自变量,叫单向变异数分析;研究两个自变量叫双变异数分析,依此类推。也可以用自变量的尺度对变异数命名。2*2变异数分析表示两个自变量,每个自变量有两级。")
223
3.双向变异分析 双向变异数分析是研究者在实验中同时检验第二个自变量,所用到的。在双向变异分析中,研究者收集数据,像单向变异数分析法时一样排成表,不同的是对应每一实验对象的数值填入表中每一单元。

224
4.一般相关统计 两个变量,一个变量随另一个变量改变的程度,就是相关测度(measures of correlation),也叫结合测度(measures of association)如果对同一对象进行两种不同测试,通常用变量x 表示一种测度,用变量y 表示另一种测度。
,也叫结合测度(measures of association)如果对同一对象进行两种不同测试,通常用变量x 表示一种测度,用变量y 表示另一种测度。")
225
五、部分相关 部分相关是研究人员假定一个混乱的或欺骗性的变量,会影响自变数和因变数关系时使用的方法,控制混乱变数。研究人员可用部分相关统计法测定控制变数的影响,使用这种方法能使相关值相对原先研究增加。

226
第二节 回归分析 一、简单线性回归 简单线性回归(simple linear regression)是用业检测一非独立变量(因变量)与一组独立变量(自变量)之间的关系。所有因变量与自变量的测量必须依据一定的间隔尺度进行测量,标定变量,并记录为二进制(虚拟)变量。
是用业检测一非独立变量(因变量)与一组独立变量(自变量)之间的关系。所有因变量与自变量的测量必须依据一定的间隔尺度进行测量,标定变量,并记录为二进制(虚拟)变量。 .")
227
二、复回归 复回归(multiple regression)是线性回归的扩展,它是分析两个或更多自变量和一个简单因变量的关系的参数统计法。复回归与变异数分析有相似之处,它主要使用分析自变量所得的资料来预测因变量。因此复回归的主要目的是建立一个能够对于尽可能多的变量变异进行说明的方程。
是线性回归的扩展,它是分析两个或更多自变量和一个简单因变量的关系的参数统计法。复回归与变异数分析有相似之处,它主要使用分析自变量所得的资料来预测因变量。因此复回归的主要目的是建立一个能够对于尽可能多的变量变异进行说明的方程。")
228
第十三章 SPSS系统在传播学研究中的应用

229
第一节 SPSS简介 SPSS的含义 SPSS for WINDOWS的特点 SPSS for WINDOWS的启动与退出

230
一、SPSS的含义 SPSS是软件英文名称的首字母缩写。原意为Statistical Package for the Social Sciences,即“社会科学统计软件包”。SPSS公司于2000年正式将英文全称更改为Statistical Product and Service Solutions,意为“统计产品与服务解决方案”。 我们现在讲授的主要是SPSS for Windows 11.0版。

231
二、SPSS for Windows11.0的特点 操作界面极为友好,易于学习,易于使用,是非专业统计人员的首选统计软件。
无需花费大量时间记忆大量命令、过程、选择项等。 只要粗通统计分析原理,就能得到统计分析的结果。 可以根据计算机的设备来选择安装,灵活方便。 能非常方便地与其他软件的数据进行转换。 分析方法丰富,图表功能强大,输出结果美观漂亮。

232
三、SPSS的启动与退出 SPSS的启动 使用开始菜单启动SPSS 双击SPSS图标启动SPSS SPSS的退出
使用FILE菜单中的“EXIT SPSS”菜单项退出SPSS 单击数据编辑窗右上角“x”的退出SPSS

233
进入SPSS后显示的文件对话框 使用数据库向导来创造一个新的文件选项 以浏览运行 操作指导 在数据窗口输入数据选项
打开一个已存在的数据源程序 运行一个已存在的文件选项 打开一个其它类型的文件

234
Spss11.0的界面 数据窗口 变量定义窗口

235
主界面的10个下拉菜单 ①文件(File); ②编辑(Edit) ; ③视图(View) ; ④数据(Data) ;
⑤转换(Transform) ;⑥统计分析(Analyze ) ; ⑦作图(Graphs) ;⑧工具(Utilities) ; ⑨ 窗口转换(Windows);⑩ 帮助(Help)
 ;⑥统计分析(Analyze ) ; ⑦作图(Graphs) ;⑧工具(Utilities) ; ⑨ 窗口转换(Windows);⑩ 帮助(Help)")
236
四、SPSS系统的运行方式 SPSS系统运行的三种方式: 完全窗口菜单运行管理方式 程序运行管理方式 混合运行管理方式

237
完全窗口菜单运行管理方式 完全窗口菜单运行管理方式主要在数据编辑窗口和输出观察窗口中进行操作。运行方式操作简便、直观,特别适合于初学者,也是本门课程讲授的主要方式。 缺点:对话框中包括的是基本参数和基本统计量的选择项,对于某些专业人员来说,可能不能充分满足需要。

238
程序运行管理方式 程序运行管理方式是在语句窗口(Syntax)中直接运行编写好的程序的一种方式。 分析结果仍然是显示在输出观察窗中。
主要用于习惯使用 程序的用户(SPSS最初是使用程序来进行统计分析的)。
。")
239
混合运行管理方式 混合运行方式是以上两种方法的结合方式。
操作程序:首先在数据窗中输入数据或利用主菜单中的(File)菜单项打开已经存在的数据文件,然后利用对话框选择分析过程和分析参数。选择后不马上执行,而是用Paste将选择的过程与参数变换成相应的命令语句。在语句窗口中可以进行修改,然后再将程序提交系统执行。
菜单项打开已经存在的数据文件,然后利用对话框选择分析过程和分析参数。选择后不马上执行,而是用Paste将选择的过程与参数变换成相应的命令语句。在语句窗口中可以进行修改,然后再将程序提交系统执行。")
240
五、SPSS窗口类型 数据编辑窗口(Newdata) 输出窗口(Output1) 语句窗口(Syntax) 统计图表编辑窗口(Chart)
帮助窗口(Help)
")
241
数据编辑窗口(Newdata) 数据编辑窗口是一个可扩展的二维表格,用户可在该窗口中建立或编辑数据文件。其主要功能有:定义变量属性;录入数据;修改变量属性;移动记录指针;插入记录;插入新的变量等。 在一个SPSS运行期间不能同时打开两个以上的数据编辑窗口。 File 文件操作 Edit 文件编辑 View 窗口外观控制 Data 数据文件的建立与编辑 Transform 数据转换 Statistic 统计分析 在spss10.0中为analysis Graphs 统计图表的建立与编辑 Utilities 实用程序 Window 窗口控制 Help 帮助

242
输出窗口(Output1) 输出窗口是一个文本窗口,其功能是用来显示系统处理的输出结果或系统运行过程中所发生的错误信息。
在一个SPSS运行期间可以同时打开两个或两个以上的输出窗口。其中只有一个为主输出窗口。

243
语句窗口(Syntax) 语句窗口可以用来粘贴SPSS过程的命令语句以及各选项对应的子命令语句,也可以用来手工编辑命令语句。然后将这些命令提交给系统进行运行。 在一个SPSS运行期间可以同时打开两个或两个以上的语句窗口。其中只有一个为主语句窗口。
 语句窗口可以用来粘贴SPSS过程的命令语句以及各选项对应的子命令语句,也可以用来手工编辑命令语句。然后将这些命令提交给系统进行运行。 在一个SPSS运行期间可以同时打开两个或两个以上的语句窗口。其中只有一个为主语句窗口。")
244
统计图表编辑窗口

245
帮助窗口(Help)
")
246
六、SPSS系统参数设置 系统初始状态和系统默认值的设置是通过options选择对话框完成的。具体操作是通过打开Edit菜单中的options打开系统参数设置对话框。 参数与状态的设置生效的时间不同,有的在确认后立即生效,有的要在下一次启动spss系统时才生效。

247
系统参数设置基本操作

248
Spss11.0中系统参数的设置

249
系统参数的设置的主要项目 通用参数的设置 (General) 观察窗口参数设置 (Viewer)
草稿窗口参数设置 (Draft Viewer) 标签输出设置 (Output Labels) 统计图形参数设置 (Charts) 交互图形窗口参数设置 (Interactive) 要点表参数设置 (Pivot Tables) 数据功能卡设置 (Data) 数值型变量自定义格式设置 (Currency) 稿本窗口参数设置 (Scripts)
 标签输出设置 (Output Labels) 统计图形参数设置 (Charts) 交互图形窗口参数设置 (Interactive) 要点表参数设置 (Pivot Tables) 数据功能卡设置 (Data) 数值型变量自定义格式设置 (Currency) 稿本窗口参数设置 (Scripts)")
250
通用参数的设置项目 设置日志文件 设置内存工作区的大小 启动spss 时语句窗口状态的设置 测度系统参数设置 设置显示变量表顺序的方式
文件表中文件数的设置 启动时输出窗口类型的设置 输出通告设置 临时文件路径设置

251
通用参数的设置 声音设置:无声;默认声;自选声音文件 日志文件: 在日志文件中记录 系统 执行语句 将每次运行的语句 记录 在前次运行语
变量显示方式顺序 变量标签显示在前 变量表中只显变量名 变量名按字母顺序 按数据文件中变量类 型顺序 日志文件: 在日志文件中记录 系统 执行语句 将每次运行的语句 记录 在前次运行语 句之后, 并存入日 志文件 将每次存入日志文 件时覆盖前次所存 文件表中文件数设定 系统使用过的文件数 设定文件暂存处 输出声明设置 产生新结果时屏幕显 示导航器 示新输出信息 设定内存 测度单位选择 语句窗口状态设定 启动时输出窗类型: 产生交互式要点图和统计图 输出文本格式要点图和统计图 声音设置:无声;默认声;自选声音文件

252
观察窗口参数设置 主要项目: 初始输出状态设置 输出文本的字体、字号设置 文本输出页面设置 文本输出字型、字号设置与颜色

253
观察窗口参数设置 文本标题字体和大小选择 初始输入状态设置 文本输出页面设置 文本输出字型、字号、颜色设置

254
草稿观察窗口参数设置 主要项目: Display Output Items显示输出项的设置。
Page Breaks Between分页位置设置。 在Front栏中设置使用在新的输出中的字体。 Tabular Output平面表格输出栏,控制将要点表转换成平面表,即文本输出。 Text Output文本输出栏,控制文本输出页的尺寸。

255
草稿观察窗口参数设置 字体设置 分页设置 在每个程序之间分页 在每个输出之间插入一个分割符 列表输出 指定列宽和列分割 日志中是否显示命令
符形式 使用空格为分割符. 重复占多个页面表的 标题 单元格周围显示格线 输出表时每栏均为 最大列宽和标签长度 在character栏内设定 列宽和标签最大宽度; 在cell栏指定行分割 符和列分割符. 日志中是否显示命令 显示警告 显示说明信息 显示标题 显示统计图形 显示文本输出 显示运行日志 显示表格输出 分页设置 在每个程序之间分页 在每个输出之间插入一个分割符 标准页宽,每行80字符; 132字符; 自定义字符数 标准页长,每页59行; 尽可能的页长; 自定义页长 字体设置

256
标签输出设置 主要项目: 在Outline Labeling结果标签栏中,设置输出图形时是否使用标签。
在Pivot Table Labeling要点表格标签栏中,设置输出表格时是否使用标签。

257
标签输出设置 要点表标签栏:用于设定在输出图形时是否使用标签 控制在新的要点表中的变量名和描述性的变量标签值的输出。
Labels:使用变量标签来标识每个变量。 Names使用变量名来标识每个变量。 Names and labels:使用 变量名和变量标签来标识每个变量。 用于设定在输出图形时是否使用标签 控制新的要点表中的变量名和描述性变量标签的输出。 Labels:使用变量标签来标识每个变量。 Names使用变量名来标识每个变量。 Names and labels:使用 变量名和变量标签来标识每个变量。 Labels使用变量标签值来标识每个变量。 Values使用变量值来标 识每个变量。 LabelsandValues使用 变量值和变量标签值来标识每个变量。 控制新的要点表中的数据值和描述性的变量标签值的输出。 Labels使用变量标签值来标识每个变量。 Values使用变量值来标识每个变量。 Labels and Values使用 变量值和变量标签值来标识每个变量。

258
统计图形参数设置 主要项目: 图形模板栏 Chart Template 图形的宽与高比设置参数框 Chart Aspect
图形中文字字体设置栏 Font 图形填充和线条样式栏 Fill Patterns and Line Styles 图形变框栏 Frame

259
统计图形参数设置 图形模板栏 新的图形属性采用本对话框之中设置 图形宽高设置栏: 使用一个图形模板来确定图形属性 可输入宽高比值 当前设置
字体 选择图形填充和线条样式 使用14种颜色调色板,后根据需要给颜色增加样式 使用样式来代替颜色 框架栏 为整个图形画一个框,包括标题和图例 为输出的图形部分画出边框 单元格栏 在线上标志刻度 在线上标志分类

260
交互图形窗口参数设置 主要项目: ChartLook交互图形外观样式栏
Data Saved with Chart栏,控制与交互图形同时保存的信息。 Print Resolution 栏,控制交互图形打印的精度。 Measurement System栏,设置交互图形的度量系统。 Reading Pre-8.0 Data Files 栏,读取8.0以前版本的数据文件选择项。

261
交互图形窗口参数设置 打印精度栏 测度单元栏 图形外观样式栏 图形数据存储栏 可单击Browse选择
样式目录 图形数据存储栏 当生成图表的数据文件与图表分开时,控制信息与交互图形一起保存 只保存综合数据 读取8.0前版本的数据文件栏可对数值型变量描述最小值以便将数据分类或指明刻度。 打印精度栏 测度单元栏

262
要点表参数设置 主要项目: Table Look 表格外观样式栏,可选择新表格的表格样式。
Set Table Look Directory 按钮允许改变系统默认的Table Look目录。 Adjust Column Width for 控制要点表列宽的自动调整栏。 Default Edit Mode 设置默认的编辑表格模式。

263
要点表参数设置 表格外观栏 选择系统提供的表格输出时的外观样式 样本栏 预览Table Look 中选定的样式 调整要点表列宽栏
列宽调整为标签列宽 和数据值列宽中较大的一个。 默认编辑模式栏 Edit all tables in viewer:控制在观察窗口中的要点表或一个单独窗口的激活 Edit only small tables in viewer:在观察窗口仅能编辑小的要点表 Edit small and medium tables in viewer:在观察窗口仅能编辑小的或中等的要点表 Edit all but very large in viewer:在观察窗口不能编辑非常大的要点表 Open all tables in a separate windows :在一个单独窗口打开表

264
数据功能卡设置 主要项目: Transformation and Merge Options 选择数据转换和合并栏.
Display Format for New Numeric Variables 新数值变量指定系统默认的显示宽度和小数位数。 Set Century Range for 2-Digit Years栏,对日期型数据中的年份指定用两位数字输入和显示。

265
数据功能卡设置 设置两位年表示法变动范围 自动选择 自定义 为新数值型变量指定格式栏 宽度 小数点 数据转换与合并栏
立刻执行要求的转换同时读取数据文件 在遇到命令时才执行转换和合并 设置两位年表示法变动范围 自动选择 自定义 为新数值型变量指定格式栏 宽度 小数点

266
数值型变量自定义格式的设置 主要项目: Custom Output Formats用户定义输出格式栏
All Values设置数值的首尾字符栏 Negative Value设置负数的首尾字符栏 Decimal Separator设置小数点符号栏

267
数值型变量自定义格式的设置 输出样本栏 自定义输出格式 显示变量格式的预览 设置首尾字符栏
在此框输入一个字符,此字符将成为在所有值前都显示的前缀。 在此框输入的值成为在所有值后都显示的后缀 小数点分割符设置栏 采用圆点作小数点 采用逗号作小数点 设置负数的首尾字符栏 在此框内输入在所有负值前都显示的前缀 在此框内输入的值成为在所有负值后都显示的后缀

268
稿本窗口参数设置 主要项目: Global Procedures 全局过程栏
Autoscripts 自动稿本栏,自动稿本文件是稿本子程序的组合,在每次运行建立某一输出对象类型的过程时都要自动运行这些稿本子程序。 Autoscript subroutine status矩形框中包含当前所有自动稿本文件的所有子程序。

269
稿本窗口参数设置 全局过程栏 自动脚本栏

270
第二节 SPSS数据文件的建立

271
本讲主要内容 1、进入spss前的准备工作 ——资料的审查、数据编码、资料的登录、制定分析计划等等。 2、Spss运行的基本程序与使用方法
——录入、定义、保存、分析

272
一、进入SPSS之前的准备工作 编码 资料的审查 数据资料的形式: 封闭性问卷资料与开放性问卷资料。
不同的资料形式均要求对资料进行审查,但在编码时有不同的要求。

273
资料的审查 主要考察三个方面: 资料的完整性审查 资料的统一性审查 资料的合格性审查 资料

274
资料的完整性审查 包括资料总体上的完整性和每份资料的完整性。 资料总体的完整性主要考虑问卷发放的数量、回收率等。
每份资料的完整性主要看问卷的填答情况,是否是有效问卷。

275
资料的统一性审查 1、检查所有问卷、报表填答的方法是否统一。 2、检查统一指标的数值所使用的单位是否一致。
3、审查指标的定义和分析的标准是否与自己的研究分类相一致。 4、审查指标统计的总体是否一致。

276
资料的合格性审查 审查提供资料的人的身份是否符合规定的调查对象的身份。 审查所提供的资料是否符合填答的要求。 审查所提供的资料是否正确。

277
审查资料正确性的三种方法 1、判断检验:依据已知情况来判断是否真实正确。 2、逻辑检验:从资料的逻辑关系来检验是否正确。
3、计算检验:通过各种数字的运算来检验是否正确。

278
资料的编码 问题025:您认为打工的外地人对武汉市的社会秩序是否有影响?(单选) 3□没有影响 4□不好说
根据一定的规则将研究资料转换为可进行统计分析的数码资料的过程。 问题025:您认为打工的外地人对武汉市的社会秩序是否有影响?(单选) 1□有很大影响 □有较大影响 3□没有影响 □不好说 4 答案 编码
 1□有很大影响 2□有较大影响. 3□没有影响 4□不好说. 4. 答案. 编码.")
279
编码的步骤 1、确定变量 变量:用来反映概念的量化形式。在统计中往往指最小的分析单位。编码就是对变量进行编码。变量由两个部分构成:变量名和变量值。要注意区分何为变量,何为变量值。在调查问卷中还要注意区分问题和变量。

280
问题009:您有几个儿子?几个女儿? 1□儿子_______人 2□女儿________人 2 3 问题 变量1 变量2 变量1的值
变量2的值 变量1 变量2

281
2、几种常见的编码方式 封闭性问卷的处理方法 单项选择题 多项选择题 多项排序选择题 固定选择项 不固定选择项 开放性问卷的处理方法

282
2 2

283
1 3 5 6 有6个选项,故应设6个变量,运用0-1编码方法 编码,即:1,0,1,0,1,1。
此外,多选还有另外一种编码方法,即直接编码输入法,编码为1,3,5,6,0,0。

284
问题012:您择业中考虑的主要因素有(依据重要性大小排列,限选三项)
3 1 6 1Ǝ经济收入 Ǝ专业对口 3Ǝ发展前途 Ǝ地理区位 5Ǝ个人爱好 Ǝ风险大小 7Ǝ劳动强度 Ǝ社会福利 9Ǝ社会地位 Ǝ其他 因为是依据重要性大小排列,限选三项,故应设三个变量,编码依次为3,1,6。

285
择业中考虑的主要因素(依据重要性先后排列)
1Ǝ经济收入 Ǝ专业对口 3Ǝ发展前途 Ǝ地理区位 5Ǝ个人爱好 Ǝ风险大小 7Ǝ劳动强度 Ǝ社会福利 9Ǝ其他 ,依据选择项的数目,确定可能的选项数,每一位给一个编码,第一位是处于首位的则业因素,依次类推。 因为是依据重要性排列,不限制选项,故应设九个变量,编码依次为: 3,1,6,4,7,8,5,0,0。

286
择业中考虑的主要因素(多选) 编码应为:1,0,1,1,1,0,1,1,0。 或1,3,4,5,7,8,0,0,0。
1Ǝ经济收入 Ǝ专业对口 3Ǝ发展前途 Ǝ地理区位 5Ǝ个人爱好 Ǝ风险大小 7Ǝ劳动强度 Ǝ社会福利 9Ǝ其他 编码应为:1,0,1,1,1,0,1,1,0。 或1,3,4,5,7,8,0,0,0。

287
开放性问卷的处理方法 1、对回答进行分类。一般首先随机抽取一部分问卷,了解回答的情况,依据回答对问卷进行分类,主要考虑语气强弱、观点确定等方面。 2、建立回答类别与对应的数量关系,进行编码。

288
数据登录 在大型社会调查中通常要进行数据登录,现在一般采用问卷页边编码方式,以避免转录中增加误差。 数据登录的主要作用: 输入更快捷、准确。
有利于多人分工合作、共同输入。 便于核查数据。

289
数据录入 外部式录入 内部式录入 采用DOS、WPS、CCED等软件,按ASCII码方式录入成文本文件(*.dat;*.txt)。这种录入方式的特点是,数据之间没有间隔,录完一个数码后自动后移,录入速度较快。缺点是容易错位。 采用SPSS数据编辑器(SPSS Data Editor)录入。其优点是不容易错位,缺点是不能自动后移,录入速度慢,数据错误不容易修改。
录入。其优点是不容易错位,缺点是不能自动后移,录入速度慢,数据错误不容易修改。")
290
二、SPSS运行的基本步骤 录入数据 定义数据 整理数据 统计数据 查看结果

291
录入数据 概率事件(观测量):在数据编辑器的二维表中, 每列为一个变量,每行记录 一次观测(Case) 一次观 测的值 数据编辑器 输入数据
:在数据编辑器的二维表中, 每列为一个变量,每行记录 一次观测(Case) 一次观 测的值 数据编辑器 输入数据")
292
保存数据 单击保存类型列表框,可以看到SPSS所支持的各种数据类型,有DBF、FoxPro、EXCEL、ACCESS等,这里我们仍然将其存为SPSS自己的数据格式(*.sav文件)。在文件名框内键入变量名并回车,可以看到数据管理窗口左上角由Untitled变为了现在的新变量名。
。在文件名框内键入变量名并回车,可以看到数据管理窗口左上角由Untitled变为了现在的新变量名。")
293
SPSS变量定义 Spss7.5、Spss8.0、Spss9.0的定义变量均通过Data菜单中 Define Variable子菜单的对话框中完成。 Spss10.0中变量定义只需在Data和Variable中进行转换即可进行变量定义。 Spss10.0中的变量定义。

294
Spss11.5变量定义项目 Spss11.5中变量定义的一共有10个项目:变量名(name)、变量类型(type)、变量长度(width)、小数位数(decimals)、变量标签(label)、变量值标签(values)、缺省值(missing)、变量显示宽度(columns)、变量对齐方式(align)、变量测量尺度(measure)。 注意区分变量的标签(Variable Labels)与变量值的标签(Value Labels)。
、变量类型(type)、变量长度(width)、小数位数(decimals)、变量标签(label)、变量值标签(values)、缺省值(missing)、变量显示宽度(columns)、变量对齐方式(align)、变量测量尺度(measure)。 注意区分变量的标签(Variable Labels)与变量值的标签(Value Labels)。")
295
变量的类型表 SPSS变量类型 系统默认长度 小数位数 输入方式 显示方式 范例 输入 显示 Numeric 8 2 标准格式或科学记数法
标准格式数值变量原点表示小数点的数值 38.42 Comma 带逗点的数值或科学记数法 原点做小数点,逗点做三位分割符的数值 1,343,438.1 Dot 带圆点的数值或科学记数法 逗点做小数点,原点做三位分割符的数值 34,3434E2 3.434,34 Scietific notation 科学记数法 标准格式或 457.8E4 Date 日期格式非常多 显示格式非常多 Dollar 可带$或不带$输入或科学记数法 有效数值前带$以逗点为分割符 $12343 Custom Currency String 无 一串字符串 believe

296
变量标签与变量值标签 变量标签(Variable Labels):
为进一步描述变量所表示的意义,特别是当变量名不能充分描述变量所表述的意义时。 变量值标签 (Value Labels): 为进一步说明变量的可能取值,它可以定义,也可不定义。 如,变量取值为:grade1、 grade2、 grade3、 grade4,其表示年级,则变量标签为年级,而变量值标签对应变量取值为:本科一年级、本科二年级、本科三年级、本科四年级。
: 为进一步说明变量的可能取值,它可以定义,也可不定义。 如,变量取值为:grade1、 grade2、 grade3、 grade4,其表示年级,则变量标签为年级,而变量值标签对应变量取值为:本科一年级、本科二年级、本科三年级、本科四年级。")
297
Spss11.5中变量定义的操作 定义变量宽度 单击Variable View 进入; 单击, 定义 定义对齐方式 变量 名 变量标签值
单击,定义变量类型 定义变量标签 定义测度层次 定义变量类型对话框 定义变量标签值对话框 定义变量定义缺省值对话框

298
数据的简单编辑 粘贴 剪切 复制 数据的剪切、粘贴与复制 若想恢复,打开Edit---Undo 1.插入观测量 1.插入变量
插入变量与删除变量 插入量与删除观测量 1.插入观测量 在添加处单击观测量,单击右鼠标键出现右侧对话框, 单击Insert Case 2.删除观测量 1.插入变量 在添加处单击Var,单击右鼠标键出现右侧对话框, 单击Insert Variables 2.删除变量 粘贴 剪切 复制 数据的剪切、粘贴与复制 若想恢复,打开Edit---Undo

299
Find Data in Variable SALARY对话框
数据的简单编辑 1、寻找某个观察量:单击Data---Go to Case 打开对话框: 输入要寻找观测量序号 Go To Case对话框 2、在某个变量中寻找指定数据 1)单击某变量如stock所在列的任意一单元格 2)单击Edit---Find,打开对话框 3)在Find中输入要找数据某变量 Find Data in Variable SALARY对话框
单击某变量如stock所在列的任意一单元格. 2)单击Edit---Find,打开对话框. 3)在Find中输入要找数据某变量. Find Data in Variable SALARY对话框.")
300
第三节 为分析作好准备

301
本节主要内容 数据编辑器的功能 数据文件的整理 数据文件的加权 重编码 数据的变换和计算 缺失值的处理

302
一、数据编辑器的功能 数据编辑器 标题栏 菜单栏 图标 输入数据栏 数据显示区: 变量名 观察序号 数据编辑器的构成

303
数据编辑器的功能 数据编辑器的功能主要是通过主菜单的“Edit”和“Data”两个菜单项来实现的。 其主要功能有:
1)变量和观测量的编辑功能 2)数据编辑功能
变量和观测量的编辑功能. 2)数据编辑功能.")
304
数据编辑功能表(Edit菜单) 命令 功能 Undo 删除刚输入的数据或者恢复刚修改的数据 Redo 恢复刚撤消的操作 Cut
将选定数据剪切到剪贴板 Copy 将选定数据拷贝到剪贴板 Paste 将剪贴板的数据粘贴到指定位置 Clear 清除选定的变量和观测值 Find 查找数据

305
Data菜单的各项命令 Define Variables Define Dates Templates Insert Variables
功能 对变量操作的命令 Define Variables 定义与编辑变量属性 Define Dates 定义与编辑日期变量或日期时间变量 Templates 定义与修改一个变量模板 Insert Variables 插入变量 对观测量操作的命令 Insert Case 插入观测量 Go to Case 定位到指定的观测量

306
Data菜单的各项命令 对文件操作的命令 Sort Cases 按选定的变量对观测量排序 Transpose 对数据文件的转置
Merge Files 合并数据文件 Aggregate 对数据进行分类与不分类的汇总 进行分析前的处理命令 Split File 折分数据文件 Select Cases 选择观测量 Weight Cases 加权处理观测量

307
二、数据文件的整理 主要内容: 观测量数据的排序 变量值排秩 拆分数据文件 合并数据文件

308
观测量数据的排序 首先在数据窗中建立或读入一个数据文件。
按Data Sort Cases顺序逐一单击鼠标键,打开Sort Cases观测量排序对话框。 依据需要进行选择,然后单击OK按纽即可。 在进行数据处理 过程中,有时需要按某个变量值的顺序重新排列观测量在数据文件中出现的先后顺序。

309
观测量数据的排序 在左边的源变量框中选择排序变量进入Sort by框。如果选择2个以上的变量,观测量的排序结果与排序变量在Sort by框中的顺序有关。列于首位的为第一排序变量。 在Sort Order 栏内选择排序方式——升序与降序

310
变量值排秩 运用Transform 命令实现。求得的秩在数据窗中建立一个新变量来保存。 具体操作方法:
按Transform Rank Cases顺序逐一单击鼠标键,打开Rank Cases对话框。 依据需要进行选择,然后单击OK按纽即可。新生成的秩变量的名称以原变量名称前加字母“R”的形式出现在数据文件中。 有些过程在分析 之前自动先对变量求秩序,有时需要人工事先排好秩。

311
变量值排秩

312
变量值排秩的选项说明 在Assign rank 1 to 栏中可选择秩的排列方式。
如选择一个或多个分组变量进入By栏,系统将按By变量分组排秩。 当所选择的变量具有相同值时称为Tie(结),其秩次的决定原则可以在Rank Cases:Ties对话框中指定。 在Rank Type中可以选择获得秩次的其他方法。 Display summary Tables 复选项为默认选择,表示要在输出结果窗中显示新变量的名称、标签、秩类型等总结性信息。
,其秩次的决定原则可以在Rank Cases:Ties对话框中指定。 在Rank Type中可以选择获得秩次的其他方法。 Display summary Tables 复选项为默认选择,表示要在输出结果窗中显示新变量的名称、标签、秩类型等总结性信息。")
313
拆分数据文件 在进行数据处理时经常要对数据文件中的观测量进行分组分析,如分性别的平均分数。进行分析之前必须对 数据文件进行拆分。
拆分分件并不是将一个数据文件分为两个或几个独立的数据文件,而是在同一个数据文件中按某个条件分组。这种拆分在以后的运算中一直有效直到取消或更改拆分变量。

314
拆分数据文件的具体操作 根据对数据的具体需要选择相应的选项。 按Ok完成。 读取一个数据文件。
按Data Split Files顺序逐一单击鼠标,打开Split Files对话框。 根据对数据的具体需要选择相应的选项。 按Ok完成。

315
拆分数据文件

316
合并数据文件 合并数据文件是指将外部数据中的观测量或变量合并到当前的数据文件中去。 合并数据文件包括两种方式:
从外部数据文件增加观测量到当前数据文件中——纵向合并或称追加观测量。 从外部数据文件增加变量到当前数据文件中——横向合并。

317
纵 向 合 并 首先打开一个数据文件。 按Data Merge Files Add Cases顺序逐一单击鼠标,打开:Read File对话框,依据需要选择文件,然后进入Add Cases From对话框,选择相应的选项或做适当的修改即可。

318
纵 向 合 并

319
纵 向 合 并

320
横 向 合 并 横向合并有两种方式: 从一个指定的外部数据文件中取得一个或几个变量的数据(包括变量名称)增加到 当前工作数据文件中,实际上相当于两个数据文件的横向合并。 按关键变量合并,即要求两个数据文件必须有一个共同的关键变量,而且这两个文件中的关键变量还存在一定数量的相同值的观测量。
增加到 当前工作数据文件中,实际上相当于两个数据文件的横向合并。 按关键变量合并,即要求两个数据文件必须有一个共同的关键变量,而且这两个文件中的关键变量还存在一定数量的相同值的观测量。")
321
横向合并的具体操作 首先打开一个数据文件。
按Data Merge Files Add Variables顺序逐一单击鼠标,打开Add Variables :Read File对话框,依据需要选择相应的选项或做适当的修改即可。

322
横向合并

323
三、 对观测量加权处理 在计算的过程中需要利用变量对数据进行加权处理时采用。 加权处理的具体方法:
按DataWeight Cases,打开Weight Cases对话框,依据需要进行适当的选择即可。

324
对观测量加权处理

325
对观测量加权处理 在选择加权变量时应注意: 加权变量中含有零、负数或缺省值的观测量将被排除在分析之外。 分数值有效。
一旦对数据进行了加权处理,那么在以后的分析中加权处理一直有效,直到关闭加权处理过程或选择其他的加权变量进行加权处理。

326
四、重编码 重编码的步骤及两种方式:(1)Into Same Variables ;(2) Into Different Variables.
Into Same Variables ;(2) Into Different Variables.")
327
重编码的应用 高一层次的变量,转化为低一层次的变量时,常常需要重编码。
当采用量表来进行测量,而量表中变量取值有正反两种方向的设置,需要转化为同一方向时,常常需要重编码。

328
第一种方式重编码

329
If Case 对话框 用于设置变量重编码的条件

330
Old and New Values对话框 设置旧变量转变为新变量的对应方式

331
第二种方式重编码 第二种重编码方式需要在Output Values中定义新变量的变量名与变量标签。
第二种重编码方式中 If 和 Old and New Values按钮展开的对话框形式与结构、内容是一样的。

332
五、对数据进行变换和计算 利用菜单“Transform”下的“Compute”命令实现数据的变换和计算
1、计算数值或字符型变量的值 2、创建新的变量或取代已存在的变量,对于新的变量,依然可以定义 3、可以利用已建立的函数进行变量的计算和转换

333
创建新的变量对话框

334
创建新的变量

335
六、缺失值的处理 SPSS中缺失值默认为圆点“.” DATA中设置了3种设置缺失值的方式
TRANSFORM下设置了5中不同的替代缺失值的方法。 缺失值的处理方法

336
缺失值定义方法

337
缺失值替代方法

338
缺失值处理方法 Exclude cases pariwise 成对删除含缺失值的个案
Exclude cases listwise 删除所有含有缺失值的个案 Replace with mean 用均值代替缺失值 Exclude cases analysis by analysis 统计检验时,删除含有缺失值的个案 Report values 报值

339
第四节 基本统计分析

340
一、SPSS统计分析功能概述 1、SPSS数值分析过程 2、SPSS图形分析过程

341
1、SPSS数值分析过程 Loglinear Descriptive Statistics Classify
Data reduction Scale Nonparametric tests Survival Multiple response Descriptive Statistics Compare means General linear model Correlate Regression

342
2、SPSS图形分析过程

343
二、基本统计分析功能 基本统计分析功能包括: 描述性统计分析(Descriptive Statistics)
")
344
描述性统计分析(Descriptive Statistics)
1、 Frequencies 频数分析表 2、 Descriptive 描述性统计分析过程 3、 Crosstabs 列联表分析过程

345
1、频数分析表 一、主要功能 可对数据按组进行归类整理,形成变量不同水平的频数分布表和图形,对数据的分布趋势进行初步分析。 二、频数分析
按Analyze—Descriptive Statistic—Frequencies顺序,打开Frequencies对话框如图。

346
Frequences主对话框 选择一个或多个变量右移入Variable(s)框。 显示频数分布表
按Statistics按钮,打开Statistics对话框 按Chart按钮,打开Chart 对话框 按Format按钮,打开Format 对话框

347
离差栏 分布参数栏 输出统计量对话框 在计算百分位数值和中位数时,假设数据已分组,且用各组的组中值代替各组数据 中心趋势栏
输出百分位数: 输出四分位数,显示25%、50%、75%的百分位数; 将数据平均分为所设定的相等等份,可输入2—100 的整数,如键入4则输出第25、50、75百分位数 自定义百分位数,可输入0—100 的整数。 输入值后: 按Add:输入值后按此键,可反复操作键入多个百分位数; 按Remove:删除已键入的数值 按Change:重新输入新数 中心趋势栏 离差栏 分布参数栏 输出统计量对话框

348
Chart 对话框 只有选择了条形图和圆图项才有效,决定纵轴表示的统计量 纵轴表示频数图 纵轴表示百分比 不输出任何图形,为默认
输出条形图,各条高度代表变量各分类的频数 输出圆图,圆图中各块的数值表示各分类变量的频数 输出直方图,此图仅适用于区间型数值变量。选择此项后,还可选择With normal curve,画出的直方图带有正态曲线 只有选择了条形图和圆图项才有效,决定纵轴表示的统计量 纵轴表示频数图 纵轴表示百分比 Chart 对话框

349
控制频数表输出的分类数量。默认为10 Format 对话框 设置频数表输出的格式 选择频数表中排列顺序 多变量框中可设定多变量表格输出的格式
按变量升序排列,此为默认 按变量降序排列 按变量各种取值发生的频数的升序排列 按变量各种取值发生的频数的降序排列 多变量框中可设定多变量表格输出的格式 控制频数表输出的分类数量。默认为10 Format 对话框

350
三、例题分析 对某高校100名大学生血清蛋白含量(g%)做频数分析,数据如表4—9 表4— 名大学生血清蛋白含量(%)
做频数分析,数据如表4—9 表4—9 100名大学生血清蛋白含量(%)")
351
1、具体步骤 按Analyze—Descriptive Statistic—Frequencies 顺序,打开Frequencies对话框。打开数据文件“大学生血清.sav”,挑xdh变量进入Variable框,grade变量进入Break框。选中Display frequency tables复选框,要求输出频数分布表。 单击Statistics按钮,选择要输出的统计量。 单击Chart 按钮,选择Histogram项,输出直方图,并选择With normal curve复选框,输出正态曲线。 单击Format 按钮,选Ascending项。单击“OK”完成。

352
2、 输出结果及分析结果如下 血清蛋白含量的直方图 血清蛋白含量的统计表

353
血清蛋白含量的频数分布表

354
2、描述性统计分析过程 Descriptive 对话框
一、主要功能: 调用此过程对变量进行描述性统计分析,计算均值、标准差、全距和均值标准误差等,并可将原始数据转换成Z分数。 二、描述统计量分析 按Analyze Descriptive Statistics Descriptives顺序单击,打开 Descriptives主对话框。如图 选一个或多个变量移入 如选中此框,将对Variables框中选择的变量进行标准化产生相应的Z分值,并作为新变量保存到数据窗口,其变量名在原变量名前加z。 Descriptive 对话框

355
基本统计量 分布 当Variables框中有多个变量时,此框确定其输出顺序: 按Variables框中的排列顺序输出 按各变量的字母顺序输出
按均值的升序排列 按均值的降序排列 Options 对话框

356
20个初生婴儿的体重(g) 三、例题分析 已知20个初生婴儿的体重数据如下表,对其进行描述统计。 1、操作步骤:
2770 2915 2795 2995 2860 2970 3087 3126 3125 4654 2272 3503 4218 3418 3921 2669 3707 2310 2573 3881 1、操作步骤: 打开数据文件“婴儿体重.sav”。打开 Descriptives主对话框,选定变量t进入Variable栏中。 选中Save standardized values as variables 复选框,要求计算变量的z值,并保存结果到当前数据集中。 单击Options 按钮,选中Mean、Std.Deviation、Minimum、Maximum 、Variance 项。

357
2、输出结果及分析 婴儿体重的描述统计量 这时打开原数据集,可看到多了一列zt,这是t 的z 分数,如下图所示: 保存了z 分数的数据集

358
3、列联表分析过程 主要功能: 调用列联表分析过程可进行计数资料和某些等级资料的列联表分析,一个行变量和一个列变量可组成一个二维列联表,如再加一个控制变量则可组成一个三维列联表。而多个行、列、控制变量就可组成一个复杂的多维列联表。在分析中可对二维和多维列联表资料进行统计描述和x2检验,并计算相应的百分数指标。此外,还可计算四格表确切概率(Fisher’s Exact Test),且有单双侧(One-Tail、Two-Tail)、对数拟然比检验( Likelihood Ratio)以及线性关系的Mantel-Haenszel x2检验。
,且有单双侧(One-Tail、Two-Tail)、对数拟然比检验( Likelihood Ratio)以及线性关系的Mantel-Haenszel x2检验。")
359
4、列联表分析过程 列联表分析程序 按Analyze--Descriptive Statistics--Crosstabs 顺序打开 Crosstabs 主对话框。如图:

360
Crosstabs 对话框 显示每一组中各变量的分类条形图。 只输出统计量,不输出多维列联表。
该框中的变量作为分布表中的行变量,必须是数值型或字符型等分类变量。 显示每一组中各变量的分类条形图。 该框中的变量作为控制变量,决定频数分布表中的层,可有多个控制变量,如要增加新的控制变量,按Next 键,要修改以前的变量按Previous 键 只输出统计量,不输出多维列联表。

361
Crosstabs的Statistics 对话框
进行行和列变量相互独立的假设检验,有多种检验法。(注) 进行相关系数的检验,有两项结果显示: Pearson相关系数和 Spearman相关系数 适用于定类变量的统计量: 基于卡方检验基础上对相关性的检验 用来描述相关性 当用自变量预测因变量时,此系数反映这种预测降低错误的比率。 显示不确定系数,表示用一个变量来预测其他变量时降低错误的比率 适用于定序变量: 用于检验相关性 用于检验两个评估人对同一对象的评估是否具有一致系。 检验某事件发生和某因子之间的关系 进行两个相关的二值变量的非参数检验 进行一个二值因素变量和一个二值响应变量的独立性检验。 适用于定序变量: Gamma系数反映两个有序变量间的对称相关性。 是Gamma检验的非对称推广。 对有序变量和秩变量相关性的非参数检验。 与Kendall’s tau-c相似 通常情况下显示皮尔逊卡方检验(Pearson chi-square test) 、拟然比卡方检验(Likehood ration chi-square test )、线性相关卡方检验(Linear-by-linear association chi-square test) 、费歇精确检验(Fisher’s exactly test )、耶次校正卡方检验(Yete’s corrected chi-square test)
 进行相关系数的检验,有两项结果显示: Pearson相关系数和 Spearman相关系数. 适用于定类变量的统计量: 基于卡方检验基础上对相关性的检验. 用来描述相关性. 当用自变量预测因变量时,此系数反映这种预测降低错误的比率。 显示不确定系数,表示用一个变量来预测其他变量时降低错误的比率. 适用于定序变量: 用于检验相关性. 用于检验两个评估人对同一对象的评估是否具有一致系。 检验某事件发生和某因子之间的关系. 进行两个相关的二值变量的非参数检验. 进行一个二值因素变量和一个二值响应变量的独立性检验。 适用于定序变量: Gamma系数反映两个有序变量间的对称相关性。 是Gamma检验的非对称推广。 对有序变量和秩变量相关性的非参数检验。 与Kendall’s tau-c相似. 通常情况下显示皮尔逊卡方检验(Pearson chi-square test) 、拟然比卡方检验(Likehood ration chi-square test )、线性相关卡方检验(Linear-by-linear association chi-square test) 、费歇精确检验(Fisher’s exactly test )、耶次校正卡方检验(Yete’s corrected chi-square test)")
362
Crosstabs的Cell Display 对话框
选择在列联表中输出的统计量,包括观测量数、百分比、残差 输出观测量的实际数量 如果行和列变量在统计上是独立的或不相关的,那么会在单元格中输出期望的观测值的数量。 输出单元格中观测量的数目占整行全部观测量数目的百分比 输出单元格中观测值的数目占整列全部观测量数目的百分比 输出单元格中观测量的数目占全部观测量数目的百分比 计算非标准化残差 计算标准化残差 计算调整后残差

363
Table Format 对话框 决定各行的排列顺序: 各行的排列按升序 各行的排列按降序 三、例 为了探讨吸烟与慢性支气管炎有无关系,调查了339人,情况如下: 吸烟和慢性支气管炎调查表 患慢性支气管炎 未患慢性支气管炎 吸烟 43 162 不吸烟 13 121

364
1、操作步骤 输入数据:变量h为采得的数据;变量x为是否吸烟:1为吸烟,2为不吸烟;变量n为是否患病:1为患病,2为不患病。数据文件名为“Crosstab.sav”。 在Data菜单中选Weight Cases…项,打开Weight Cases对话框。 Weight Cases by,再将变量h选入Frequence Variable 框,单击OK完成加权。 按Analyze--Descriptive Statistics--Crootabs 顺序打开 Crootabs 主对话框。将x变量 选入Row框作为行变量,将n变量 选入Column 框作为列变量。 打开Statistics对话框,选中Chi-square\Contingency coefficient和Phi and Cramer’sV复选框,单击Continue返回。 单击Cell按钮,打开Cell display对话框,选中observed和Expected 复选框,单击Continue返回;单击OK。

365
2、输出结果及分析 吸烟与患病统计摘要表 统计摘要表,列出观测量有效值个数、缺失值个数和总的个数。
输出结果如表: 吸烟与患病统计摘要表 统计摘要表,列出观测量有效值个数、缺失值个数和总的个数。 从列联表中可看出,吸烟人中患病者有43人,比期望值33.9大,不吸烟人中患病者只有13人,比期望值22.1小。

366
吸烟与患病列联表 卡方检验

367
卡方检验表,从表中可看出,Chi-Square值为7. 469,显著值为0. 006<0
卡方检验表,从表中可看出,Chi-Square值为7.469,显著值为0.006<0.05,应否定零假设,即认为吸烟与患慢性支气管炎是不独立的。由于使用卡方检验要求每个单元格频数不少于5,当条件不满足时,还可用Fisher精确检验。其双侧检验显著值为0.007。 对称性检验表,通过度量对称性来得到有效的观测个数,本例为339。 对称性检验表

368
第五节 双变量关系描述统计 ——相关分析与检验

369
双变量的关系 ——有关与无关 寻找变量间的关系是科学研究的首要目的。变量间的关系最简单的划分即:有关与无关。
在统计学上,我们通常这样判断变量之间是否有关:如果一个变量的取值发生变化,另外一个变量的取值也相应发生变化,则这两个变量有关。如果一个变量的变化不引起另一个变量的变化则二者无关。

370
性别与四级英语考试通过率的相关统计 表述:统计结果显示,当性别取值不同时,通过率变量的取值并未发生变化,因此性别与考试通过率无关。 自变量的不同取值在因变量上无差异,两变量无关。 自变量的不同取值在因变量上有差异,两变量有关。

371
表述:统计结果显示,当性别取值不同时,收入变量的取值发生了变化,因此性别与月收入有关。
因变量 自变量 表述:统计结果显示,当性别取值不同时,收入变量的取值发生了变化,因此性别与月收入有关。

372
双变量关系的统计类型

373
双变量的关系 ——关系强度测量 变量关系强度的含义:指两个变量相关程度的高低。统计学中是以准实验的思想来分析变量相关的。通常从以下的角度分析: A)两变量是否相互独立。 B)两变量是否有共变趋势。 C)一变量的变化多大程度上能由另一变量的变化来解释。
一变量的变化多大程度上能由另一变量的变化来解释。")
374
双变量关系强度测量的主要指标

375
双变量的关系 ——关系的性质 直线相关与曲线相关 正相关与负相关 完全相关与完全不相关

376
相关分析 可采用相关分析和非参数相关分析过程。可选择计算积距相关系数、Spearman秩相关系数和Kendall秩相关系数。检验的假设为相关系数为0。可选择是单尾检验还是双尾检验。

377
一、相关分析 —— Correlate菜单 相关分析用于描述两个变量间联系的密切程度,其特点是变量不分主次,被置于同等的地位。
在Analyze的下拉菜单Correlate命令项中有三个相关分析功能子命令Bivariate过程、Partial过程、 Distances过程,分别对应着相关分析、偏相关分析和相似性测度的三个spss过程。

378
简单相关分析 Bivariate过程用于进行两个或多个变量间的相关分析,如为多个变量,给出两两相关的分析结果。
Partial过程,当进行相关分析的两个变量的取值都受到其他变量的影响时,就可以利用偏相关分析对其他变量进行控制,输出控制其他变量影响后的相关系数。 Distances过程用于对同一变量各观察单位间的数值或各个不同变量间进行相似性或不相似性分析一般不单独使用,而作为因子分析等的预分析。

379
二、 Bivariate相关分析 在进行相关分析时,散点图是重要的工具,分析前应先做散点图,以初步确定两个变量间是否存在相关趋势,该趋势是否为直线趋势,以及数据中是否存在异常点。否则可能的出错误结论。 Bivariate相关分析的步骤:输入数据后,依次单击Analyze—Correlate—Bivariate,打开Bivariate Correlations对话框如图5-1

380
计算Kendall秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据。
计算积距相关系数,连续性变量才可采用。 计算Kendall秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据。 计算Spearman秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据。 图5-1 Bivariate Correlations 对话框 见图5-2 在输出结果中,相关系数的右上角上有“*”则表示显著性水平为0.05;右上角上有“**”则表示显著性水平为0.01。 不清楚变量之间是正相关还是负相关时选择此项。 清楚变量之间是正相关还是负相关时可选择此项。

381
图5-2 Optins 对话框 对每一个变量输出均值、标准差和无缺省值的观测数。 对每一个变量输出交叉距阵和协方差距阵。 计算某个统计量时,在这一对变量中排除有缺省值的观测值。 对于任何分析,有缺省值的观测值都会被排除。

382
相关分析实例 连续变量相关分析实例数据表 1、连续变量的相关分析实例 十只小鸡的体重与鸡冠的数据如表所示(数据文件:小鸡(相关).sav):
观测 号 1 2 3 4 5 6 7 8 9 10 体重 (克) 83 72 69 90 95 91 75 70 鸡冠重 (毫克) 56 42 18 84 107 68 31 48
 鸡冠重. (毫克)")
383
分析步骤 1)输入数据,依次单击Analyze—Correlate—Bivariate,打开Bivariate Correlations对话框 2)选择weight 和coronary变量进入 Variables框中。 3)在Correlation Coefficients栏内选择Pearson。 4)在Test of Significance栏选择Two-tailed。 5)选择Flag significant correlation。 6)单击Options按钮,选择Mean and standard deviations、Cross-product deviations and covariances、Exclude cases pairise选项。 7)单击OK完成。
在Correlation Coefficients栏内选择Pearson。 4)在Test of Significance栏选择Two-tailed。 5)选择Flag significant correlation。 6)单击Options按钮,选择Mean and standard deviations、Cross-product deviations and covariances、Exclude cases pairise选项。 7)单击OK完成。")
384
结果分析 描述性统计量表,如下: 从表中可看出,变量weight的均值为82.50,标准差为10.01,观测数为10;变量coronaryt的均值为60.00,标准差为27.60,观测数为10;

385
Pearson相关系数距阵 从表中可看出, Pearson相关系数为0.865,即小鸡的体重与鸡冠的相关系数为0.865,这两者之间不相关的双尾检验值为0.001。体重观测值的协方差为 ,而鸡冠重观测值的协方差为 ,体重和鸡冠重的协方差为 。 从统计结果可得到,小鸡的体重与鸡冠重之间存在正相关关系,当小鸡的体重越大时,则小鸡的鸡冠越重。并且,否定了小鸡的体重与鸡冠重之间不相关的假设。

386
2、定序变量的Spearman分析实例 权威主义和地位欲评秩
为研究集团迫使个人顺从的效应,一些研究者用F量表和为测量地位欲而设计的一种量表对12名大学生进行调查。欲知道对权威主义的评分之间相关的信息。 权威主义和地位欲评秩 学生 A B C D E F G H I J K L 权威主义 2 6 5 1 10 9 8 3 4 12 7 11 地位欲

387
分析步骤 1)输入数据,依次单击Analyze—Correlate—Bivariate,打开Bivariate Correlations对话框 2)选择power和position 变量进入 Variables框中。 3)在Correlation Coefficients栏内选择Spearman选项。 4)在Test of Significance栏选择Two-tailed。 5)选择Flag significant correlation。 6)单击Options按钮,选择Mean and standard deviations、Cross-product deviations and covariances、Exclude cases pairise选项。 7)单击OK。
在Correlation Coefficients栏内选择Spearman选项。 4)在Test of Significance栏选择Two-tailed。 5)选择Flag significant correlation。 6)单击Options按钮,选择Mean and standard deviations、Cross-product deviations and covariances、Exclude cases pairise选项。 7)单击OK。")
388
结果分析 从表中可看出,权威主义和地位欲的相关系数为0.818,这表明权威主义越高的人地位欲也越高。权威主义与地位欲不相关的假设检验值为0.001,否定假设,即权威主义与地位欲是相关的。

389
3、定序变量的Kendall分析实例 仍用前例中的数据(数据文件:权威(Spearman相关).sav) 。操作过程相同,只是在第3)步在Correlation Coefficients栏内选择Kendall’s选项。结果如下: 从表中可看出,权威主义和地位欲的相关系数为0.667,这表明权威主义越高的人地位欲也越高。权威主义与地位欲不相关的假设检验值为0.003,否定假设,即权威主义与地位欲是相关的。Kendall相关分析所得到的结果类似于Spearman分析。

390
二、偏相关

391
一、概念 当有多个变量存在时,为了研究任何两个变量之间的关系,而使与这两个变量有联系的其它变量都保持不变。即控制了其它一个或多个变量的影响下,计算两个变量的相关性。 二、偏相关系数 偏相关系数是用来衡量任何两个变量之间的关系的大小。

392
三、选择不同的方法计算相关系数 Pearson:双变量正态分布资料,连续变量 Kendall: 资料不服从双变量正态分布或 总体分布未知,等级资料。 Spearman:等级资料。

393
四、SPSS操作步骤 Analyze-----Correlation-----Partial 把分析变量选入 Variable 框
把控制变量选入 Controlling for 框 点击 Options 点击 Statistics:选择 Mean and standard deviation Zero-order correlation Continue OK

394
结 果: Variable Mean Standard Dev Cases X1( 身高 ) 152.5759 8.3622 29
结 果: Variable Mean Standard Dev Cases X1( 身高 ) Y (肺活量) X2 ( 体重 )
 Y (肺活量) X2 ( 体重 )")
395
1、身高与肺活量的简单相关系数 身高与肺活量的简单相关系数

396
2、体重与肺活量的简单相关系数

397
3、身高与体重的简单相关系数

398
4、体重为控制变量,身高与肺活量的偏相关系数
P A R T I A L C O R R E L A T I O N C O E F F I C I E N T S Controlling for.. X2 (体重) Y(肺活量) X1(身高) Y (肺活量) ( 0) ( 26) P= P= .226 X1 (身高) ( 26) ( 0) P= P= .
 Y(肺活量) X1(身高) Y (肺活量) ( 0) ( 26) P= . P= X1 (身高) ( 26) ( 0) P= .226 P= .")
399
5、身高作为控制变量,肺活量与体重的偏相关系数
P A R T I A L C O R R E L A T I O N C O E F F I C I E N T S Controlling for.. X1(身高) Y(肺活量) X2(体重) Y ( 0) ( 26) P= P= .028 X ( 26) ( 0) P= P= .
 Y(肺活量) X2(体重) Y ( 0) ( 26) P= . P= X ( 26) ( 0) P= .028 P= .")
400
应用相关注意事项 1.实际意义 进行相关回归分析要有实际意义,不可把毫无关系的两个事物或现象用来作相关回归分析。例如,有人说,孩子长,公园里的小树也在长。求孩子和小树之间的相关关系就毫无意义,用孩子的身高推测小树的高度则更加慌谬。 2.相关关系 相关关系不一定是因果关系,也可能是伴随关系,并不能证明事物间有内在联系,例如,有人发现,对于在校儿童,鞋的大小与阅读技能有很强的相关关系。然而,学会新词并不能使脚变大,而是涉及到第三个因素‑‑ 年龄。当儿童长大一些,他们的阅读能力会提高而且由于长大也穿不下原来的鞋。

401
3.利用散点图 对于性质不明确的两组数据,可先做散点图,在图上看它们有无关系、关系的密切程度、是正相关还是负相关,然后再进行相关分析。 4.变量范围 相关分析和回归方程仅适用于样本的原始数据范围之内,出了这个范围,我们不能得出两变量的相关关系和原来的回归关系。

402
第六节 线性回归

403
回归的含义 回归(Regression,或Linear Regression)和相关都用来分析两个定距变量间的关系,但回归有明确的因果关系假设。即要假设一个变量为自变量,一个为因变量,自变量对因变量的影响就用回归表示。如年龄对收入的影响。由于回归构建了变量间因果关系的数学表达,它具有统计预测功能。
和相关都用来分析两个定距变量间的关系,但回归有明确的因果关系假设。即要假设一个变量为自变量,一个为因变量,自变量对因变量的影响就用回归表示。如年龄对收入的影响。由于回归构建了变量间因果关系的数学表达,它具有统计预测功能。")
404
相关关系的概念 现象之间的相互联系,常表现为一定的因果关 系,将这些现象数量化则成为变量:其中一个 或若干个起着影响作用的变量称为自变量,通 常用X表示,它是引起另一现象变化的原因, 是可以控制、给定的值;而受自变量影响的变 量称为因变量,通常用Y表示,它是自变量变 化的结果,是不确定的值。

405
函数关系 ⒈ 出租汽车费用与行驶里程: 总费用=行驶里程 每公里单价 相关关系 ⒉ 家庭收入与恩格尔系数: 家庭收入高,则恩格尔系数低。
比较下面两种现象间的依存关系 函数关系 (确定性关系) ⒈ 出租汽车费用与行驶里程: 总费用=行驶里程 每公里单价 相关关系 (非确定性关系) ⒉ 家庭收入与恩格尔系数: 家庭收入高,则恩格尔系数低。
 ⒈ 出租汽车费用与行驶里程: 总费用=行驶里程 每公里单价. 相关关系. (非确定性关系) ⒉ 家庭收入与恩格尔系数: 家庭收入高,则恩格尔系数低。")
406
现象间的依存关系大致可以分成两种类型: 指现象间所具有的严格的确定性的依存关系 函数关系
指客观现象间确实存在关系,但数量上不是严格对应的依存关系 相关关系 函数关系与相关关系之间并无严格的界限:有函数关系的变量间,由于有测量误差及各种随机因素的干扰,可表现为相关关系;对具有相关关系的变量有深刻了解之后,相关关系有可能转化为或借助函数关系来描述。

407
回归分析与相关分析 联系: 理论和方法具有一致性; 无相关就无回归,相关程度越高,回归越好; 相关系数和回归系数方向一致,可以互相推算。

408
区别: 回归分析与相关分析 相关分析中x与y对等,回归分析中x与y要确定自变量和因变量;
相关分析中x、y均为随机变量,回归分析中只有y为随机变量; 相关分析测定相关程度和方向,回归分析用回归模型进行预测和控制。

409
回归分析的种类 一元回归 一 元线性回归 (简单回归) ⒈ 按自变量的 个数分 多元回归 (复回归) 线性回归 按回归曲线的形态分 ⒉
按自变量的 个数分 ⒈ 线性回归 非线性回归 按回归曲线的形态分 ⒉

410
其中x为自变量;y为因变量;a为截距,即常量;b为回归系数,表明自变量对因变量的影响程度。
线性回归的统计原理: 两个定距变量的回归是用函数 y= f(x) 来分析的。我们最常用的是一元回归方程 在统计学中,这一方程中的系数是靠x与y变量的大量数据拟合出来的。 其中x为自变量;y为因变量;a为截距,即常量;b为回归系数,表明自变量对因变量的影响程度。
 来分析的。我们最常用的是一元回归方程. 在统计学中,这一方程中的系数是靠x与y变量的大量数据拟合出来的。 其中x为自变量;y为因变量;a为截距,即常量;b为回归系数,表明自变量对因变量的影响程度。")
411
Y=350+20x

412
Y=a+bx Y (x,y) X
 X")
413
由图中可以看出,回归直线应该是到所有数据点最短距离的直线。该直线的求得即使用“最小二乘方法”,使:
在拟合的回归直线方程中,回归系数: 表示x每变化一个单位时,x与y共同变化的程度(共变异数)。 常数
。 常数.")
414
比如通过上学年数和工资的关系计算得出下列的回归公式:
y= x 就可知上学年数每增长1年,工资会增加14.8元; 也可推测,上学年数为15年的人,工资收入应为 *15=694元。

415
一元线性回归模型 对于经判断具有线性关系的两个变量y与x,构造一元线性回归模型为: 假定E()=0,总体一元线性回归方程:
=0,总体一元线性回归方程:")
416
一元线性回归方程的几何意义 截距 斜率 一元线性回归方程的可能形态 为正 为负 为0

417
总体一元线性 回归方程: 以样本统计量估计总体参数 (估计的回归方程) 样本一元线性回归方程: (一元线性回归方程) 截距 斜率(回归系数)
截距a 表示在没有自变量x的影响时,其它各种因素对因变量y的平均影响;回归系数b 表明自变量x每变动一个单位,因变量y平均变动b个单位。

418
X对y的线性影响而形成的系统部分,反映两变量的平均变动关系,即本质特征。
随机干扰:各种偶然因素、观察误差和其他被忽视因素的影响

419
一元线性回归方程 中参数a、b的确定: 最小平方法 基本数学要求:

420
【例】建立工业总产值对能源消耗量的线性回归方程 资料
【例】建立工业总产值对能源消耗量的线性回归方程 资料 【分析】因为工业总产值与能源消耗量之间存在高度正相关关系( ),所以可以拟合工业总产值对能源消耗量的线性回归方程。 解:设线性回归方程为
,所以可以拟合工业总产值对能源消耗量的线性回归方程。 解:设线性回归方程为.")
421
整理得到由两个关于a、b的二元一次方程组成的方程组:
进一步整理,有:

422
即线性回归方程为: 计算结果表明,在其他条件不变时,能源消耗量每增加一个单位(十万吨),工业总产值将增加0.7961个单位(亿元)。
,工业总产值将增加0.7961个单位(亿元)。")
423
回归系数b与相关系数r的关系: r> r< r=0 b> b<0 b=0

424
线性回归的操作步骤

425
SPSS线性回归的输出格式:

426
SPSS线性回归的输出格式:

427
回归方程的拟合优度与评价

428
总变差 回归变差 剩余变差 离差平方和的分解 每个因变量y的实际值与其平均数之间存在的总离差(y- )的平方和称为总离差平方和,简称总变差。
估计值 与平均数 离差的平方和,称为回归变差(可解释变差)。 剩余变差 每个观察值y与估计值 的离差平方和,称为剩余变差(未解释变差。
。 剩余变差. 每个观察值y与估计值 的离差平方和,称为剩余变差(未解释变差。")
429
剩余平方和 回归平方和 总离差平方和

430
总离差平方和 回归平方和 剩余(误差)平方和 Lyy=U+Q
平方和 Lyy=U+Q")
431
判定系数 是指因变量的总变差中可以被自变量解释部分的比例,即可解释因素的影响程度。用来说明因变量的变化有多少可通过自变量得到解释。是衡量拟合模型优劣的重要分析指标。 r2值越大,说明回归模型拟合得愈优。

432
判定系数与相关系数的关系 二者均可测定两变量的线性相关密切程度

433
判定系数与相关系数的区别: 判定系数无方向性(不能反映负相关),相关系数则有方向,其方向与样本回归系数 b 相同(可反映正相关,也可反映负相关); 判定系数说明变量值的总离差平方和中可以用回归线来解释的比例,相关系数只说明两变量间关联程度及方向。
,相关系数则有方向,其方向与样本回归系数 b 相同(可反映正相关,也可反映负相关); 判定系数说明变量值的总离差平方和中可以用回归线来解释的比例,相关系数只说明两变量间关联程度及方向。")
434
估计标准误差 是因变量各实际值与其估计值之间的平均差异程度,表明其估计值对各实际值代表性的强弱;其值越小,回归方程的代表性越强,用回归方程估计或预测的结果越准确。可从一方面反映回归模型拟合的优劣状况。

435
在大样本条件下,可用公式计算: 【例】计算前面拟合的工业总产值对能源消耗量回归方程的回归标准差 资料

436
判定系数与估计标准误差的关系: 估计标准差越小,则变量间相关程度越高,回归线对Y的解释程度越高。

437
相关系数的显著性检验(t检验法) ⒊ 根据给定的显著性水平,确定临界值 ; 步 骤 ⒋ 确定原假设的拒绝规则:
⒊ 根据给定的显著性水平,确定临界值 ; 步 骤 ⒋ 确定原假设的拒绝规则: 若 ,则接受H0 ,表示总体两变量间线性相关性不显著; 若 ,则拒绝H0 ,表示总体两变量间线性相关性显著 ⒌ 计算检验统计量并做出决策。

438
【例】检验工业总产值与能源消耗量之间的线性相关性是否显著 资料
【例】检验工业总产值与能源消耗量之间的线性相关性是否显著 资料 当 成立时,则统计量

439
估计的前提:回归方程经过检验,证明 X 和 Y 的关系在统计上是显著相关的。
回归方程的估计与预测 估计的前提:回归方程经过检验,证明 X 和 Y 的关系在统计上是显著相关的。 对于给定的 X 值,求出 Y 平均值的一个估计值或 Y 的一个个别值的预测值。 点估计 对于给定的 X 值,求出 Y 的平均值的置信区间或 Y 的一个个别值的预测区间。 区间估计

440
点估计 若 x = 80(十万吨),则:
,则:")
441
区间估计 对于给定的 x = x0 ,Y 的1-置信区间为: 自由度为n-2的 t 分布 的 水平双侧分位数

442
即: 在大样本条件下,近似有:

443
SPSS输出结果(一)
")
444
SPSS输出结果(二) 模型综述表 方差分析表
 模型综述表 方差分析表")
445
SPSS输出结果(三) 系数表
 系数表")
446
非标准预测值 标准预测值 下限 上限
447
简单相关表 八个同类工业企业的月产量与生产费用 企业编号 月产量(千吨)X 生产费用(万元)Y 1 2 3 4 5 6 7 8 1.2
2.0 3.1 3.8 5.0 6.1 7.2 8.0 62 86 80 110 115 132 135 160
448
20个同类工业企业固定资产原值与平均每昼夜产量
分组相关表 (百万元) (吨) 20个同类工业企业固定资产原值与平均每昼夜产量 平均每昼夜产量 固定资产原值 35~40 40~45 45~50 50~55 55~60 60~65 65~70 600~650 1 550~600 2 3 500~550 450~500 5 7 400~450 4 350~400 300~350 20
 (吨) 20个同类工业企业固定资产原值与平均每昼夜产量. 平均每昼夜产量. 固定资产原值. 35~40. 40~45. 45~50. 50~55. 55~60. 60~65. 65~ ~ ~ ~ ~ ~ ~ ~")
449
序号 能源消耗量(十万吨)x 工业总产值(亿元)y x2 y2 xy 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 35 38 40 42 49 52 54 59 62 64 65 68 69 71 72 76 24 25 28 32 31 37 41 47 50 51 48 58 1225 1444 1600 1764 2401 2704 2916 3481 3844 4096 4225 4624 4761 5041 5184 5776 576 625 784 1024 961 1369 1681 2209 2500 2601 2304 3364 840 950 960 1176 1568 1612 1998 2360 2542 2560 3055 3400 3381 3621 3456 4408 合计 916 55086 26175 37887

450
第十四章 定量研究个案

451
第一节 “知沟”研究 一、研究目的 1.在当前中国社会结构下,大众媒介效果中是否存在着“知沟”现象;不同的社会经济、文化环境对“知沟”形态是否产生影响; 2.从信息渠道的接触和使用、个体层面的动机、态度等因素分析“知沟”; 3.对当前中国社会的“信息富有者”和“信息贫穷者”进行总体描述,分析低SES群体在媒介信息利用上存在的问题,从多种变量看缩小“知沟”的可能性条件。

452
二、研究设计 1.调查方法 调查采用问卷、面访的方式。 2.调查内容 人口统计资料、媒介接触与使用、知识测量、个体动机与态度。 3.抽样方法 多级分层抽样 4.数据处理 SPSS10.0

453
三、概念的操作性界定及对研究设计的说明 1.新闻一体 2.知识测量 3.社会经济地位(SES)
")
454
第二节 文化传播研究 一、研究背景 由于文化教育事业的发展,大众传媒特别是电子传媒走进了寻常百姓家,人们的思维空间和活动空间开阔,精神面貌发生了变化,人民受教育机会增加,社会参与意识增强,传统道德观念受到很大冲击,产生了许多新的文化观念。这与物质生活水平、文化程度和素养、职业范围、生活环境、传媒覆盖率有关。特别是少数民族地区,交通不发达,经济落后,传播事业发展缓慢,要向该地区人民传播各种信息,进行精神文明建设和物质文明建设,就要大力发展偏远地区的文化传播事业。

455
2.研究假设 中国的改革举世瞩目,人民的精神文明和物质文明建设有了很大发展,但西北地区与沿海地区有较大的差异,发展是不平衡的; 国家对西本地区采取了一些优惠政策,这些措施产生了很大的影响,但相当一部分人的文化观念和行为认为仍局限在解决温饱的基础上; 传播媒介迅速发展,但传统的传播与交往方式仍占较大比重,价值观念变化不大; 人们的社会参与意识增强,但对于重要事件和国家大事知道的仍不多,有些虽有了解,但却不理解,需加强政策的普及和传播工作; 传播事业发达的地区,人们的文化消费较高,反之就较低,西北地区的传播事业需大力发展。

456
二、研究范围与方法 基本调查点包括甘南、临夏、庆阳、巴州、阿克苏、北疆、兰州、乌市、青海、陕西。此外,兰州军区和新疆生产建设兵团也被列为调查对象。 这次研究采取问卷和面访相结合,以问卷为主的形式。在文卷中,根据研究背景和假设的命题,设计了四个层次问题,即:背景层次,认知层次,社会参与层次,道德与信仰层次,所设计几大类问题和作为面访、座谈的问题就是围绕这四个层次展开的。

457
三、实施时间 1991年冬进行前期准备,包括对外联系,疏通渠道培训调查员,印刷问卷等; 1992年春首先在新疆试点,发现可能出现的问题; 在取得经验的基础上,在新疆全面开展。

458
四、经费 共需要经费88000元,其中资料费8000元,印刷费10000元,室外工作费20000元,差旅费30000元,统计分析10000元,坚定10000元。

459
六、研究结果 西北人的4个变化: 1.西北人在生活观念和生活方式方面已经出现游离于传统的现代倾向,表现出与过去一致性相异的多样性特征,如:选择工作时更注重收入、声望、地位和权力;业余生活多样化,在民族地区,社会成员更向往世俗教育(相对于宗教);对国家和地区发展更为重视;自主性增强,依赖性减弱。
;对国家和地区发展更为重视;自主性增强,依赖性减弱。")
460
2.西北人的人际关系中功利性倾向明显增加,如58%的人认为“关系网”很重要;社区交流、邻里交流减弱,关系淡漠,并有城市特点;代际矛盾更加明显;社会交流走向开放性和社会性;上级和下级关系不和谐。
3.择业取向分化显著,如职业评价和心理职业等级倾向于社会权力和收入,传统的职业形象发生动摇;希望职业流动说明不满现状;个人的职业选择层次多样化;强调自我价值实现和职业风险。 4.婚姻家庭观念发生很大的变化,如:对传统的价值观和文化观持肯定态度的达到30%,但对现代观念持肯定态度也在30%左右;群体意识和小农意识都浓重,集体意识淡化;妇女自身主体意识增强。

461
第三节 大众传播媒体舆论监督研究 一、研究假设 上海大众传播媒介在近两年的舆论监督中发挥了积极作用,得到社会的广泛支持和肯定。
第三节 大众传播媒体舆论监督研究 一、研究假设 上海大众传播媒介在近两年的舆论监督中发挥了积极作用,得到社会的广泛支持和肯定。 (1) 舆论监督力度较大,特别是社会关心的热点问题,敢于陈言; (2) 监督频率较高,凡对社会有害或有益或存在潜在影响的问题,都敢于提出; (3) 积极引导,以正面舆论影响社会舆论; (4) 部分社会成员仍不满意,主要是:监督表面化、形式化,深度不够。
 舆论监督力度较大,特别是社会关心的热点问题,敢于陈言; (2) 监督频率较高,凡对社会有害或有益或存在潜在影响的问题,都敢于提出; (3) 积极引导,以正面舆论影响社会舆论; (4) 部分社会成员仍不满意,主要是:监督表面化、形式化,深度不够。")
462
二、研究方法 问卷实地调查 分层抽样和随机抽样结合

463
三、研究结论 1.上海市大众传播媒体的舆论监督环境基本形成; 2.正面引导为主,展现积极的社会内容; 3.加强沟通,引导与沟通相结合,聚合了舆论; 4.市民对大众传播媒体舆论监督有较好认知;

464
5.大众传播媒体舆论监督的社会层面不断拓宽;
6.大众传播媒体舆论监督存在的问题有:大众传播媒体舆论监督定位不够,缺乏对舆论监督的深层认识,舆论监督的法理观念和伦理观念不强,缺乏对隐性舆论的反映。 7.大众传播媒体舆论监督应从反腐败抓起。

465
第四节 两岸媒体“9·11”事件报道的内容分析 研究背景和方法 一、新闻框架的形式结构:话语结构

466
1.主要事件 2.位置 3.时间 4.地点 5.消息来源 6.结果: 7.口语反应 8.评估 9.预测 10.先前片段

467
二、分析步骤 1.媒体选择 本次研究选择了《人民日报》和台湾地区《联合报》两家媒体。 2.时段界定 从2001年9月11日“9·11”事件发生,至10月10日。 3.分析单位 以所选媒体对“9·11”事件的相关报道为对象,每一条新闻为分析单位。

468
结论与启示 1.两岸主流媒体都非常重视对“9·11”事件的报道,花费了大量人力、物力,对事件的经过、舆论的反映和发展的结果都进行了详尽的报道,在本报的国际报道历史上都是前所未有的。

469
2.就海峡两岸主流媒体的比较而言,可以概括成为:中国大陆主流媒体立足于和政府立场高度一致,在报道国际事务时均离不开本国,注重报道和反映本国的国际地位和影响。 而台湾地区报纸则用更商业化的方式来操作重视信息的传播,在新闻制作方面追求“可读性”,注意捕捉精彩的戏剧性细节,反映当局的立场的同时,也反映个人在事件中的境遇。

470
3.海峡两岸主流媒体的国际报道,尤其是国际灾难性事件报道,标志着两岸不同的新闻传播体制和运作模式。中国大陆新闻媒介是党和人民的喉舌,与党和政府的立场保持高度一致。而台湾地区主流新闻媒介是在“发达传播学”的模式下运作,有不同的政治背景和政治势力支持,需要表明本集团的立场,但表面上都是民营的企业化集团,新闻报道完全是以商品形式出现,以受众市场为中心。

471
第五节 中国内地媒体SARS报道研究 一、研究背景
本次研究主要从议程设置理论出发,在总结经典理论的基础上探讨主流媒体在“非典”报道中与议程设置理论相关的问题。

472
二、研究内容和方法 1.媒体选择 本研究选择《人民日报》、《解放日报》、《云南日报》、《羊城晚报》分别代表全国性媒体、“非典”轻度发生地区媒体、无“非典”发生地区媒体、“非典”疫区媒体。

473
2.时段界定 从3月24日到6月15日,共84天。 3.分析单位 以所选纸质媒体对“非典”事件的相关报道为对象。

474
结论与启示 1.主流媒体在“非典”报道中存在议程设置; 2.主流媒体在“非典”报道中的议程设置实质上是政府行为; 3.主流媒体在“非典”报道中存在差异化倾向。


 1 SPSS 的环境与基本操作.>")














 电 话:>")



