Download presentation
Presentation is loading. Please wait.

1
第四章 概率密度函数的非参数估计 2学时

2
4.1 基本思想

3
4.1 基本思想 令R是包含样本点x的一个区域,其体积为V,设有n个训练样本,其中有k个落在区域R中,则可对概率密度作出一个估计:

4
有效性 当n固定时,V的大小对估计的效果影响很大,过大则平滑过多,不够精确;过小则可能导致在此区域内无样本点,k=0。
此方法的有效性取决于样本数量的多少,以及区域体积选择的合适。

5
收敛性 构造一系列包含x的区域R1, R2, …,对应n=1,2,…,则对p(x)有一系列的估计:
当满足下列条件时,pn(x)收敛于p (x):
收敛于p (x):")
6
区域选定的两个途径 Parzen窗法:区域体积V是样本数n的函数,如: K-近邻法:落在区域内的样本数k是总样本数n的函数,如:

7
Parzen窗法和K-近邻法

8
4.2 Parzen窗方法 定义窗函数

9
1维数据的窗函数

10
概率密度函数的估计 超立方体中的样本数: 概率密度估计:

11
窗函数的要求 上述过程是一个内插过程,样本xi距离x越近,对概率密度估计的贡献越大,越远贡献越小。 只要满足如下条件,就可以作为窗函数:

12
窗函数的形式

13
方形窗和高斯窗 方形窗函数 高斯窗函数

14
窗函数的宽度对估计的影响 hn为窗的宽度 hn=0.5 hn=1 hn=2 hn=5

15
识别方法 保存每个类别所有的训练样本; 选择窗函数的形式,根据训练样本数n选择窗函数的宽度h;
识别时,利用每个类别的训练样本计算待识别样本x的类条件概率密度: 采用Bayes判别准则进行分类。

16
Parzen窗的神经网络实现 神经元模型

17
简化神经元模型

18
Parzen窗函数的神经元表示 窗函数取Gauss函数,所有的样本归一化,令神经元的权值等于训练样本,即: 则有:

19
概率神经网络(PNN, Probabilistic Neural Network)
")
20
PNN的训练算法 begin initialize j = 0; n =训练样本数,aji=0 do j j + 1
normalize : train : wjxj if then aji1 until j = n A为模式层到类别层的连接权值

21
PNN分类算法 begin initialize k = 0; x 待识模式 do k k + 1 if aki = 1 then
until k = n return end PNN中隐含了类先验概率的信息,所以累加结果就是后验概率的估计

22
径向基函数网络(RBF, Radial Basis Function)
RBF与PNN的差异 神经元数量:PNN模式层神经元数等于训练样本数,而RBF小于等于训练样本数; 权重:PNN模式层到类别层的连接权值恒为1,而RBF的需要训练; 学习方法:PNN的训练过程简单,只需一步设置即可,而RBF一般需要反复迭代训练; 可以把RBF看作PNN的简化版本,将PNN中模式层中相近的神经元用一个代替,而向类别层连接的权值则要由原来的1变为k。

23
径向基函数网络的训练 RBF的训练的三种方法:
根据经验选择每个模式层神经元的权值wi以及映射函数的宽度σ,用最小二乘法计算模式层到类别层的权值; 用聚类的方法设置模式层每个神经元的权值wi以及映射函数的宽度σ,用最小二乘法计算模式层到类别层的权值; 通过训练样本用误差纠正算法迭代计算各层神经元的权值,以及模式层神经元的宽度σ; 最后一种方法类似于GMM,也可以采用EM算法训练。

24
4.3 近邻分类器 后验概率的估计 Parzen窗法估计的是每个类别的类条件概率密度 ,而k-近邻法是直接估计每个类别的后验概率 。
将一个体积为V的区域放到待识样本点x周围,包含k个训练样本点,其中ki个属于ωi类,总的训练样本数为n,则有: 公式解释一下

25
k-近邻分类器 k-近邻分类算法 设置参数k,输入待识别样本x; 计算x与每个训练样本的距离;
选取距离最小的前k个样本,统计其中包含各个类别的样本数ki;

26
k-近邻分类,k=13 还可以参考25叶的土

27
最近邻规则 分类规则:在训练样本集中寻找与待识别样本x距离最近的样本x',将x分类到x'所属的类别。
最近邻规则相当于k=1的k-近邻分类,其分类界面可以用Voronoi网格表示。

28
Voronoi网格

29
距离度量 距离度量应满足如下四个性质: 非负性: 自反性: 当且仅当 对称性: 三角不等式: 距离与内积的关系

30
常用的距离函数 欧几里德距离:(Eucidean Distance) 可以给出距离(范数)的定义
 可以给出距离(范数)的定义")
31
常用的距离函数 街市距离:(Manhattan Distance)
")
32
常用的距离函数 明氏距离:(Minkowski Distance) 讨论一下1范数,2范数,m范数以及无穷范数
 讨论一下1范数,2范数,m范数以及无穷范数")
33
常用的距离函数 马氏距离:(Mahalanobis Distance)
")
34
常用的距离函数 角度相似函数:(Angle Distance)
")
35
常用的距离函数 海明距离:(Hamming Distance) x和y为2值特征矢量:
D(x,y)定义为x,y中使得不等式 成立的i的个数。
定义为x,y中使得不等式 成立的i的个数。")
36
最近邻分类器的简化 最近邻分类器计算的时间复杂度和空间复杂度都为O(dn),d为特征维数,通常只有当样本数n非常大时,分类效果才会好。
简化方法可以分为三种: 部分距离法; 预分类法; 剪辑近邻法。

37
部分距离法 定义: Dr(x,y)是r的单调不减函数。令Dmin为当前搜索到的最近邻距离,当待识别样本x与某个训练样本xi的部分距离Dr(x,xi)大于 Dmin时, Dd(x,xi)一定要大于Dmin ,所以xi一定不是最近邻,不需要继续计算Dd(x,xi) 。
是r的单调不减函数。令Dmin为当前搜索到的最近邻距离,当待识别样本x与某个训练样本xi的部分距离Dr(x,xi)大于 Dmin时, Dd(x,xi)一定要大于Dmin ,所以xi一定不是最近邻,不需要继续计算Dd(x,xi) 。")
38
预分类(搜索树)
")
39
预分类(搜索树) 在特征空间中首先找到m个有代表性的样本点,用这些点代表一部分训练样本;
待识别模式x首先与这些代表点计算距离,找到一个最近邻,然后在这个最近邻代表的样本点中寻找实际的最近邻点。 这种方法是一个次优的搜索算法。

40
剪辑近邻法 最近邻剪辑算法 begin initialize j = 0;D = data set; n = number of training samples construct the full Voronoi diagram of D do j j + 1; Find the Voronoi neighbors of Xj if any neighbor is not from the same class as Xj then mark Xj until j = n Discard all points that are not marked Construct the Voronoi diagram of the remaining samples end

41
剪辑近邻法 剪辑前 剪辑后

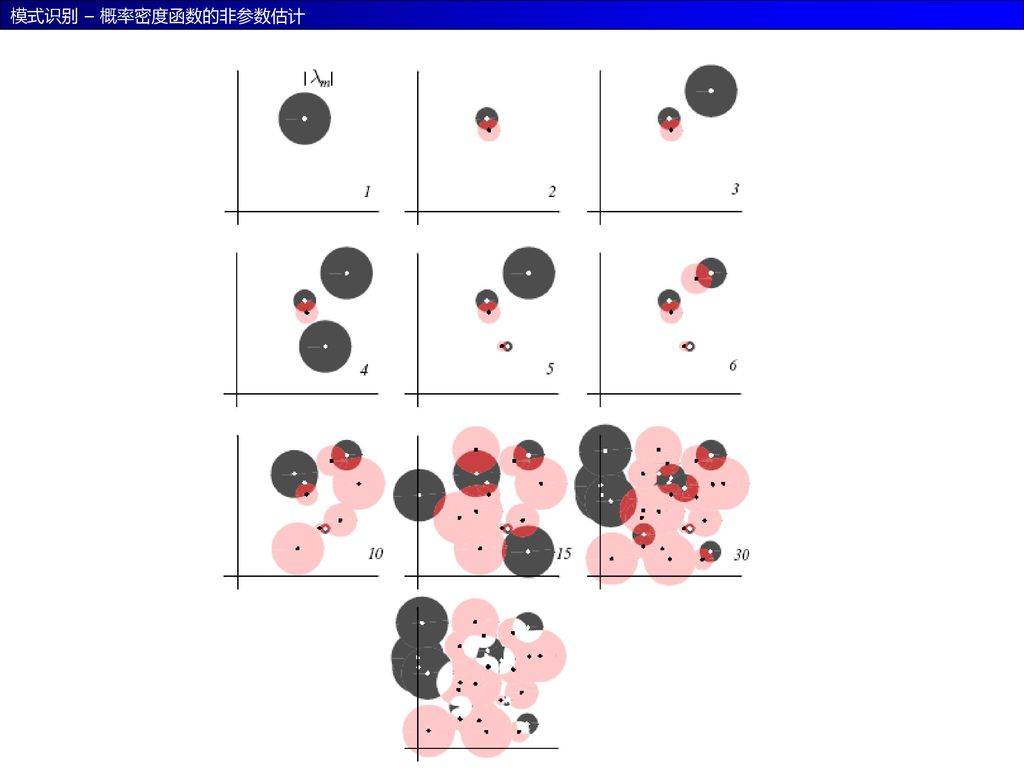
42
RCE网络

43
RCE网络的训练算法 begin initialize j=0, n=#patterns, ε=small pattern, λm=max radius,aij=0 do jj+1 train weight: wj=xj if then aji = 1 find nearest point not in ωi: set radius: until j = n

45
RCE网络的分类算法 begin initialize j=0, k=0, x, do jj+1 if then until j = n
if category of all is the same then return the label else “ambiguous” label

Similar presentations
发生 7.0 级地震。震源深度 13 公里。震中距成都约 100 公里。成都、重庆及陕西的宝鸡、汉中、安康等地均有较.>")
基本情况 工作用房面积: 18800 ㎡,其中实验室使用面积为 6500 ㎡ 中心定编 213 人,其中全额预算编制 193 人,自筹编制 20 人 现有在职职工 320 名,其中专业技术人员占 84.3% 。 人性化的办公场所实验室区域 一、海南省疾病预防控制中心概况.>")
 求积公式.>")
 ,伴咳嗽等呼 吸道感染症状,起病 5-7 天出现呼吸困难; 3 、典 型的病毒性肺炎,重症肺炎并进行性加重,部分 病例可迅速发展为急性呼吸窘迫综合症并死亡。>")
 教師手冊. 影片欣賞 -- 愛的晚霞 單純的阿霞人生第一次的愛情,卻是帶來身心嚴重 的傷害,阿霞要如何面對感染愛滋後的生活 …>")














