Download presentation
Presentation is loading. Please wait.

1
文本分类与聚类 哈工大信息检索研究室 2007

2
这一部分将讲述 文本分类及聚类的概念 文本特征的提取方法 贝叶斯分类,KNN分类及决策树分类 K均值及层次聚类的方法

3
文本分类概述

4
概述 文本分类包括普通文本分类和网页文本分类 中文网页分类技术已经成为中文信息处理领域的一项基础性工作
网页分类可以为搜索引擎用户提供目录导航服务,进而提高系统查准率 网页分类可以为个性化搜索引擎奠定基础

5
分类的概念 给定: 确定: 一个实例的描述, xX, X是实例空间 一个固定的文本分类体系: C={c1, c2,…cn}
由于类别是事先定义好的,因此分类是有指导的(或者说是有监督的) 确定: 实例x的类别 c(x)C, c(x) 是一个分类函数,定义域是 X ,值域是C
 确定: 实例x的类别 c(x)C, c(x) 是一个分类函数,定义域是 X ,值域是C.")
6
说明 分类模式 分类体系一般人工构造 2类问题,属于或不属于(binary) 多类问题,多个类别(multi-class),可拆分成2类问题
一个文本可以属于多类(multi-label) 分类体系一般人工构造 政治、体育、军事 中美关系、恐怖事件 很多分类体系: Reuters分类体系、中图分类
 分类体系一般人工构造. 政治、体育、军事. 中美关系、恐怖事件. 很多分类体系: Reuters分类体系、中图分类.")
7
中图分类法 A类 马列主义、毛泽东思想 B类 哲学 C类 社会科学总论 D类 政治、法律 E类 军事 F类 经济 G类 文化、科学、教育、体育 H类 语言、文字 I类 文学 J类 艺术 K类 历史、地理 N类 自然科学总论 O类 数理科学和化学 P类 天文学、地球科学 Q类 生物科学 R类 医药、卫生 S类 农业科学 U类 交通运输 V类 航空、航天 X类 环境科学、劳动保护科学(安全科学) TB类 一般工业技术 TD类 矿业工程 TE类 石油、天然气工业 TF类 冶金工业 TG类 金属学、金属工艺 TH类 机械、仪表工艺 TJ类 武器工业 TK类 动力工业 TL类 原子能技术 TM类 电工技术 TN类 无线电电子学、电信技术 TP类 自动化技术、计算技术 TQ类 化学工业 TS类 轻工业、手工业 TU类 建筑科学 TV类 水利工程
 TB类 一般工业技术. TD类 矿业工程. TE类 石油、天然气工业. TF类 冶金工业. TG类 金属学、金属工艺. TH类 机械、仪表工艺. TJ类 武器工业. TK类 动力工业. TL类 原子能技术. TM类 电工技术. TN类 无线电电子学、电信技术. TP类 自动化技术、计算技术. TQ类 化学工业. TS类 轻工业、手工业. TU类 建筑科学. TV类 水利工程.")
8
系统结构 标注工具 机器学习工具 模型数据 标注的样本 分类工具 类别 预处理 训练数据 新数据 文本 Modules:
- Machine learning module (neural networks, support vector machine, Bayesian belief network, decision tree, …) - Assorted data structures - Inverted index for computing TFIDF weights -
 - Assorted data structures. - Inverted index for computing TFIDF weights. -")
9
文本分类示例 测试数据 (AI) (Programming) (HCI) 类别 ML Planning Semantics
language proof intelligence” 测试数据 (AI) (Programming) (HCI) 类别 ML Planning Semantics Garb.Coll. Multimedia GUI learning intelligence algorithm reinforcement network... planning temporal reasoning plan language... programming semantics language proof... garbage collection memory optimization region... ... ... 训练数据 9
 (Programming) (HCI) 类别. ML. Planning. Semantics. Garb.Coll. Multimedia. GUI. learning. intelligence. algorithm. reinforcement. network... planning. temporal. reasoning. plan. language... programming. semantics. language. proof... garbage. collection. memory. optimization. region 训练数据. 9.")
10
分类的一般过程 收集训练集和测试集,对文本进行预处理 对文本进行特征提取 分类器训练(学习) 测试与评价 精确率、召回率、F1
宏平均,微平均

11
分类的评测 偶然事件表(Contingency Table) 对一个分类器的度量 准确率(precision) = a / (a + b)
召回率(recall) = a / (a + c) fallout = b / (b + d) 属于此类 不属于此类 判定属于此类 A B 判定不属于此类 C D
 = a / (a + c) fallout = b / (b + d) 属于此类. 不属于此类. 判定属于此类. A. B. 判定不属于此类. C. D.")
12
BEP和F测度 BEP(break-even point) F测度,取β=1 BEP和F测度的值越大,则表示分类器的性能越好。
BEP只是F1所有可能取值中的一个特定值(当p = r时),因此BEP小于或等于F1的最大值。
,因此BEP小于或等于F1的最大值。")
13
多类分类问题的评价 宏平均(macro-averaging) 微平均(micro-averaging)
先对每个分类器计算上述量度,再对所有分类器求平均 是关于类别的均值 微平均(micro-averaging) 先合并所有分类器的偶然事件表中的各元素,得到一个总的偶然事件表,再由此表计算各种量度。 是关于文本的均值
 先合并所有分类器的偶然事件表中的各元素,得到一个总的偶然事件表,再由此表计算各种量度。 是关于文本的均值.")
14
收集训练数据 TREC提供统一的训练集和测试集进行系统评测 后续增加了网页语料和中文文本 国外:CMU,BERKLEY,CORNELL
国内:中科院计算所,清华大学,复旦大学 后续增加了网页语料和中文文本 但是中文文本是新华社的新闻稿,与网页的分类体系还有差别

15
目前已有的评测语料 有指导的机器学习方法是实现中文网页自动分类的基础,因此训练集是实现分类的前提条件 已有训练语料
863评测语料(中图分类) 搜狗语料 复旦语料
 搜狗语料. 复旦语料.")
16
训练语料分类体系 中图分类体系 学科分类与代码 上述两个分类标准都不能直接用做中文网页的分类 中文网页的分类体系
处理对象是图书,不适合网页分类 学科分类与代码 1992年制定,时间过久,包括一些过时类别 上述两个分类标准都不能直接用做中文网页的分类 中文网页的分类体系

17
一种中文网页的分类体系

18
训练集的大小 通过不断增加实例的个数,考察每个类训练样本对分类器质量的影响 宏观F 微观F1

19
网页预处理 去掉网页中的导航信息 去掉HTML网页中的tag标记 去除停用词和词根还原(stemming)
(中文)分词、词性标注、短语识别、… 去除停用词和词根还原(stemming) 数据清洗:去掉不合适的噪声文档或文档内垃圾数据
分词、词性标注、短语识别、… 去除停用词和词根还原(stemming) 数据清洗:去掉不合适的噪声文档或文档内垃圾数据. ")
20
特征提取

21
特征提取(Feature Selection)
在文本分类问题中遇到的一个主要困难就是高维的特征空间 通常一份普通的文本在经过文本表示后,如果以词为特征,它的特征空间维数将达到几千,甚至几万 大多数学习算法都无法处理如此大的维数 为了能够在保证分类性能的前提下,自动降低特征空间的维数,在许多文本分类系统的实现中都引入了特征提取方法

22
举例 对每类构造k 个最有区别能力的term 例如: 计算机领域: 主机、芯片、内存、编译 … 汽车领域: 轮胎,方向盘,底盘,气缸,…

23
用文档频率选特征 文档频率 基本假设:稀少的词或者对于目录预测没有帮助,或者不会影响整体性能。
DF (Document Frequency) DFi:所有文档集合中出现特征i的文档数目 基本假设:稀少的词或者对于目录预测没有帮助,或者不会影响整体性能。 实现方法:先计算所有词的DF,然后删除所有DF小于某个阈值的词,从而降低特征空间的维数。 优缺点: 最简单的降低特征空间维数的方法 稀少的词具有更多的信息,因此不宜用DF大幅度地删除词
 DFi:所有文档集合中出现特征i的文档数目. 基本假设:稀少的词或者对于目录预测没有帮助,或者不会影响整体性能。 实现方法:先计算所有词的DF,然后删除所有DF小于某个阈值的词,从而降低特征空间的维数。 优缺点: 最简单的降低特征空间维数的方法. 稀少的词具有更多的信息,因此不宜用DF大幅度地删除词.")
24
词的熵 term的熵 该值越大,说明分布越均匀,越有可能出现在较多的类别中; 该值越小,说明分布越倾斜,词可能出现在较少的类别中
机器学习,p41

25
信息增益(Information Gain, IG)
该term为整个分类所能提供的信息量 不考虑任何特征的熵和考虑该特征后的熵的差值 信息增益计算的是已知一个词t是否出现在一份文本中对于类别预测有多少信息。 这里的定义是一个更一般的、针对多个类别的定义。 t 出现的概率 t 不出现 假定t 出现时取第i 个类别的概率 取第 i 个类别时的概率 一个属性的信息增益就是由于使用了这个属性分割样例而导致的期望熵降低(机器学习p42)
")
26
互信息(Mutual Information)
互信息(Mutual Information):MI越大t和c共现程度越大 互信息的定义与交叉熵近似,只是互信息不考虑t不出现的概率,它的定义为:
:MI越大t和c共现程度越大. 互信息的定义与交叉熵近似,只是互信息不考虑t不出现的概率,它的定义为:")
27
χ2统计量(CHI): 2统计量的定义可以从一个词t与一个类别c的偶然事件表引出(假设文本的总数为N )
度量两者(term和类别)独立性程度 χ2 越大,独立性越小,相关性越大 若AD<BC,则类和词独立, N=A+B+C+D A B C D t ~t c ~c
独立性程度. χ2 越大,独立性越小,相关性越大. 若AD<BC,则类和词独立, N=A+B+C+D. A. B. C. D. t. ~t. c. ~c.")
28
特征提取方法的性能比较(Macro-F1)
")
29
特征提取方法的性能比较(Micro-F1)
")
30
结论 可以看出CHI,IG,DF性能好于MI MI最差 CHI,IG,DF性能相当 DF具有算法简单,质量高的优点,可以替代CHI,IG

31
分类器学习 训练样本实例:<x, c(x)> 学习的过程是在给定训练样本集合D 的前提下,寻找一个分类函数h(x), 使得:
一个文本实例 xX 带有正确的类别标记 c(x) 学习的过程是在给定训练样本集合D 的前提下,寻找一个分类函数h(x), 使得:
 学习的过程是在给定训练样本集合D 的前提下,寻找一个分类函数h(x), 使得:")
32
贝叶斯分类

33
贝叶斯分类 基于概率理论的学习和分类方法 贝叶斯理论在概率学习及分类中充当重要角色 仅使用每类的先验概率不能对待分的文本提供信息
分类是根据给定样本描述的可能的类别基础上产生的后验概率分布

34
贝叶斯理论 由条件概率的定义: 得到:

35
贝叶斯分类 设各个类别的集合为 {c1, c2,…cn} 设E为实例的描述 确定E的类别 P(E) 可以根据下式确定
 可以根据下式确定")
36
贝叶斯分类(cont.) 需要知道: P(ci) 容易从数据中获得 假设样例的特征是关联的: 指数级的估计所有的 P(E | ci)
如果文档集合D中,属于ci的样例数为 ni 则有 P(ci) = ni / |D| 假设样例的特征是关联的: 指数级的估计所有的 P(E | ci)
 = ni / |D| 假设样例的特征是关联的: 指数级的估计所有的 P(E | ci)")
37
朴素的贝叶斯分类 如果假定样例的特征是独立的,可以写为: 因此,只需要知道每个特征和类别的P(ej | ci)
如果只计算单个特征的分布,大大地减少了计算量

38
文本分类 Naïve Bayes算法(训练)
设V为文档集合D所有词词表 对每个类别 ci C Di 是文档D中类别Ci的文档集合 P(ci) = |Di| / |D| 设 ni 为Di中词的总数 对每个词 wj V 令 nij 为Di中wij的数量 P(wi | ci) = (nij+ 1) / (ni + |V |)
 = |Di| / |D| 设 ni 为Di中词的总数. 对每个词 wj V. 令 nij 为Di中wij的数量. P(wi | ci) = (nij+ 1) / (ni + |V |)")
39
文本分类 Naïve Bayes算法(测试)
给定测试文档 X 设 n 为X中词的个数 返回的类别: wi是X中第i个位置的词

40
Naïve Bayes分类举例 C = {allergy, cold, well}
过敏 C = {allergy, cold, well} e1 = sneeze; e2 = cough; e3 = fever 当前实例是:E = {sneeze, cough, fever} 打喷嚏 Prob Well Cold Allergy P(ci) 0.9 0.05 P(sneeze|ci) 0.1 P(cough|ci) 0.8 0.7 P(fever|ci) 0.01 0.4
 P(sneeze|ci) 0.1. P(cough|ci) P(fever|ci)")
41
Naïve Bayes 举例 (cont.) 参数计算: 最大概率类: allergy
P(well | E) = (0.9)(0.1)(0.1)(0.99)/P(E)=0.0089/P(E) P(cold | E) = (0.05)(0.9)(0.8)(0.3)/P(E)=0.01/P(E) P(allergy | E) = (0.05)(0.9)(0.7)(0.6)/P(E)=0.019/P(E) 最大概率类: allergy P(E) = = P(well | E) = 0.23 P(cold | E) = 0.26 P(allergy | E) = 0.50
 = (0.9)(0.1)(0.1)(0.99)/P(E)=0.0089/P(E) P(cold | E) = (0.05)(0.9)(0.8)(0.3)/P(E)=0.01/P(E) P(allergy | E) = (0.05)(0.9)(0.7)(0.6)/P(E)=0.019/P(E) 最大概率类: allergy. P(E) = = P(well | E) = P(cold | E) = P(allergy | E) =")
42
Play-tennis 例子: 估算 P(xi|C)
P(p) = 9/14 P(n) = 5/14
 = 9/14. P(n) = 5/14.")
43
正例 反例 outlook P(sunny|p) = 2/9 P(sunny|n) = 3/5 P(overcast|p) = 4/9
P(overcast|n) = 0 P(rain|p) = 3/9 P(rain|n) = 2/5 temperature P(hot|p) = 2/9 P(hot|n) = 2/5 P(mild|p) = 4/9 P(mild|n) = 2/5 P(cool|p) = 3/9 P(cool|n) = 1/5 humidity P(high|p) = 3/9 P(high|n) = 4/5 P(normal|p) = 6/9 P(normal|n) = 2/5 windy P(true|p) = 3/9 P(true|n) = 3/5 P(false|p) = 6/9 P(false|n) = 2/5
 = 0. P(rain|p) = 3/9. P(rain|n) = 2/5. temperature. P(hot|p) = 2/9. P(hot|n) = 2/5. P(mild|p) = 4/9. P(mild|n) = 2/5. P(cool|p) = 3/9. P(cool|n) = 1/5. humidity. P(high|p) = 3/9. P(high|n) = 4/5. P(normal|p) = 6/9. P(normal|n) = 2/5. windy. P(true|p) = 3/9. P(true|n) = 3/5. P(false|p) = 6/9. P(false|n) = 2/5.")
44
Play-tennis例子: 分类 X 例子 X = <rain, hot, high, false>
P(X|p)·P(p) = P(rain|p)·P(hot|p)·P(high|p)·P(false|p)·P(p) = 3/9·2/9·3/9·6/9·9/14 = P(X|n)·P(n) = P(rain|n)·P(hot|n)·P(high|n)·P(false|n)·P(n) = 2/5·2/5·4/5·2/5·5/14 = 样本 X 被分到 n类,即“不适合打网球”
·P(p) = P(rain|p)·P(hot|p)·P(high|p)·P(false|p)·P(p) = 3/9·2/9·3/9·6/9·9/14 = P(X|n)·P(n) = P(rain|n)·P(hot|n)·P(high|n)·P(false|n)·P(n) = 2/5·2/5·4/5·2/5·5/14 = 样本 X 被分到 n类,即 不适合打网球")
45
举例 在Joachims(1996)的一个实验中,被应用于分类新闻组文章 20个电子新闻组,每个新闻组1000篇文章,形成2万个文档的数据集
2/3作训练集,1/3作测试集衡量性能 20 个新闻组,随机猜测的分类精确度5%,由程序获得的精确度89%

46
讨论 朴素的贝叶斯假定在一个位置上出现的词的概率独立于另外一个位置的单词,这个假定有时并不反映真实情况
虽然独立性假设很不精确,别无选择,否则计算的概率项将极为庞大 幸运的是,在实践中朴素贝叶斯学习器在许多文本分类中性能非常好,即使独立性假设不成立

47
K近邻

48
K近邻(KNN) 最近邻分类规则 对于测试样本点x,在集合中距离它最近的的x1。最近邻分类就是把x分为x1 所属的类别
 最近邻分类规则 对于测试样本点x,在集合中距离它最近的的x1。最近邻分类就是把x分为x1 所属的类别")
49
KNN算法 目标:基于训练集X的对y分类 在训练集中,寻找和y最相似的训练样本x 得到k个最相似的集合A,A为X的一个子集
设n1,n2分别为集合中属于c1,c2的个数 如果p(c1|y)>p(c2|y),判为c1,否则判为c2
>p(c2|y),判为c1,否则判为c2.")
50
kNN方法 一种基于实例的学习方法 新文本 k=1, A类 k=4,B类 k=10,B类 带权重计算,计算权重和最大的类。k常取3或者5。

51
KNN在文本分类中的应用

52
KNN 分类错误是由于: 单个的非典型样例 单个训练样本的噪音. 更鲁棒的方法是发现k个最相似的样本,返回k个样本最主要的类别

53
相似度矩阵 最近邻方法依赖于相似度矩阵(或距离). 对连续m维空间最简单的方法采用欧氏距. 对m维二值实例空间最简单的方法是海明距.
对于基于文本tf/idf权重向量的余弦相似度是经常被采用的.

54
影响KNN的因素 K的取值 K一般取15 计算距离的方法 欧式距离 兰式距离(余弦相似度)
")
55
KNN和NB比较 从表中看,KNN质量较高,NB的效率较高 从各个类别看,KNN比NB稳定,NB对类别敏感

56
决策树

57
简介 决策树方法的起源是概念学习系统CLS,然后发展到ID3方法而为高潮,最后又演化为能处理连续属性的C4.5。有名的决策树方法还有CART和Assistant 应用最广的归纳推理算法之一 一种逼近离散值目标函数的方法

58
决策树的表示法 决策树通过把实例从根节点排列到某个叶子节点来分类实例,叶子节点即为实例所属的分类。
树上的每一个节点说明了对实例的某个属性的测试,并且该节点的每一个后继分支对应于该属性的一个可能值

59
决策树表示举例

60
表达式

61
决策树学习的适用问题 实例是由属性-值对表示的 目标函数具有离散的输出值 可能需要析取的描述 训练数据可以包含错误
训练数据可以包含缺少属性值的实例

62
属性选择 构造好的决策树的关键在于如何选择好的逻辑判断或属性。 对于同样一组例子,可以有很多决策树能符合这组例子。
一般情况下或具有较大概率地说,树越小则树的预测能力越强。 要构造尽可能小的决策树,关键在于选择恰当的逻辑判断或属性。 由于构造最小的树是NP-难问题,因此只能采取用启发式策略选择好的逻辑判断或属性

63
用熵度量样例的均一性(纯度) 熵的定义 举例
 熵的定义 举例")
64
关于某布尔分类的熵函数

65
用信息增益度量期望熵最低 一个属性的信息增益就是由于使用这个属性分割样例而导致的期望熵的降低

66
举例

67
计算信息增益

68
确定最佳分类的属性 哪一个属性是最好的分类? S:[9+,5-] E=0.940 S:[9+,5-] E=0.940 Wind
Humidity normal strong weak high 6+,2- E=0.811 3+,3- E=1.000 3+,4- E=0.985 6+,1- E=0.592 Gain(S,Wind) =0.940-(8/14)0.811-(6/14)0.100 Gain(S,Humidity) =0.940-(7/14)0.985-(7/14)0.592
![确定最佳分类的属性 哪一个属性是最好的分类? S:[9+,5-] E=0.940 S:[9+,5-] E=0.940 Wind](http://slidesplayer.com/slide/11586461/62/images/68/%E7%A1%AE%E5%AE%9A%E6%9C%80%E4%BD%B3%E5%88%86%E7%B1%BB%E7%9A%84%E5%B1%9E%E6%80%A7+%E5%93%AA%E4%B8%80%E4%B8%AA%E5%B1%9E%E6%80%A7%E6%98%AF%E6%9C%80%E5%A5%BD%E7%9A%84%E5%88%86%E7%B1%BB%EF%BC%9F+S%3A%5B9%2B%2C5-%5D+E%3D0.940+S%3A%5B9%2B%2C5-%5D+E%3D0.940+Wind.jpg "Humidity. normal. strong. weak. high. 6+,2- E= ,3- E= ,4- E= ,1- E= Gain(S,Wind) =0.940-(8/14)0.811-(6/14) Gain(S,Humidity) =0.940-(7/14)0.985-(7/14)")
69
不同属性的信息增益 计算各属性的熵值 可以看到,Outlook得信息增益最大 Gain(S,Outlook)=0.246
Gain(S,Humidity)=0.151 Gain(S,Wind)=0.048 Gain(S,Temperature)=0.029 可以看到,Outlook得信息增益最大
= Gain(S,Wind)= Gain(S,Temperature)= 可以看到,Outlook得信息增益最大.")
70
Gain(Ssunny,Humidity)=0.970-(3/5)0.0-(2/5)0.0=0.970
D1,D2,…D14 9+,5- Outlook Sunny Rain Overcast D4,D5,D6,D10,D14 3+,2- D1,D2,D8,D9,D11 2+,3- D3,D7,D12,D13 4+,0- Yes ? ? 哪一个属性在这里被测试? Ssunny={D1,D2,D8,D9,D11} Gain(Ssunny,Humidity)=0.970-(3/5)0.0-(2/5)0.0=0.970 Gain(Ssunny, Temperature)=0.970-(2/5)0.0-(2/5)1.0-(1/5)0.0=0.570 Gain(Ssunny, Wind)=0.970-(2/5)1.0-(3/5)0.918=0.019
=0.970-(3/5)0.0-(2/5)0.0= Gain(Ssunny, Temperature)=0.970-(2/5)0.0-(2/5)1.0-(1/5)0.0= Gain(Ssunny, Wind)=0.970-(2/5)1.0-(3/5)0.918=")
71
ID3算法 创建树的Root结点 开始 AAttributes中分类能力最好的属性 Root的决策属性A 对于每个可能值vi
令Examplesvi为Examples中满足A属性值为vi的子集 如果Examplesvi为空 在这个新分支下加一个叶子结点,节点的lable=Examples中最普遍的目标属性值(target-attribute) 否则在这个新分支下加一个子树ID3(examplevi,target- attribute,attributes-{A}) 返回 Root
 否则在这个新分支下加一个子树ID3(examplevi,target- attribute,attributes-{A}) 返回 Root.")
72
C4.5 C4.5是对ID3的改进算法 对连续值的处理 对未知特征值的处理 对决策树进行剪枝 规则的派生

73
决策树学习的常见问题 过度拟合数据 基本的决策树构造算法没有考虑噪声,生成的决策树完全与训练例子拟合 有噪声情况下,完全拟合将导致过分拟合(overfitting),即对训练数据的完全拟合反而不具有很好的预测性能
,即对训练数据的完全拟合反而不具有很好的预测性能.")
74
解决方法 剪枝是一种克服噪声的技术,同时它也能使树得到简化而变得更容易理解。 理论上讲,向后剪枝好于向前剪枝,但计算复杂度大。
向前剪枝(forward pruning) 向后剪枝(backward pruning) 理论上讲,向后剪枝好于向前剪枝,但计算复杂度大。 剪枝过程中一般要涉及一些统计参数或阈值,如停机阈值 有人提出了一种和统计参数无关的基于最小描述长度(MDL)的有效剪枝法
 向后剪枝(backward pruning) 理论上讲,向后剪枝好于向前剪枝,但计算复杂度大。 剪枝过程中一般要涉及一些统计参数或阈值,如停机阈值. 有人提出了一种和统计参数无关的基于最小描述长度(MDL)的有效剪枝法.")
75
决策树的优点 可以生成可以理解的规则 计算量相对来说不是很大 可以处理连续和离散字段 决策树可以清晰的显示哪些字段比较重要 过程可见

76
不足之处 对连续性的字段比较难预测 当类别太多时,错误可能会增加的比较快 一般的算法分类的时候,只是根据一个属性来分类。 不是全局最优

77
文本分类的应用 新闻出版按照栏目分类 网页分类 个性化新闻 垃圾邮件过滤 类别 {spam, not-spam}
类别 {政治,体育,军事,…} 网页分类 类似于Yahoo的分类 个性化新闻 智能推荐 垃圾邮件过滤 类别 {spam, not-spam}

78
文本聚类 Text Clustering

79
聚类式搜索

80
聚类式搜索

81
聚类 将无标记的样本划分到聚类的各个子集中: 类内样本非常相似 类间样本非常不同 无监督方法发现新类别

82
聚类样例 . . .

83
fish reptile amphib. mammal worm insect crustacean
层次聚类 在无标注的样本集合中建立 树状层次分类结构 递归的标准层次聚类算法应用生成层次聚类. animal vertebrate fish reptile amphib. mammal worm insect crustacean invertebrate

84
会聚vs. 分裂聚类 会聚(bottom-up) 以每个样本独自一类开始,迭代合并到越来越大的类中
分裂 (partitional, top-down) 将所有样本不断划分到类别中
 将所有样本不断划分到类别中.")
85
会聚层次聚类 (HAC) 设定相似度函数确定任意两个实例的相似度 开始每个实例独自一类 然后重复合并最相似的类别,直到成为一类:
在当前的类别中,确定最近的两类ci 和cj 用单一的类别 ci cj取代 ci 和 cj 合并的过程成为层次结构

86
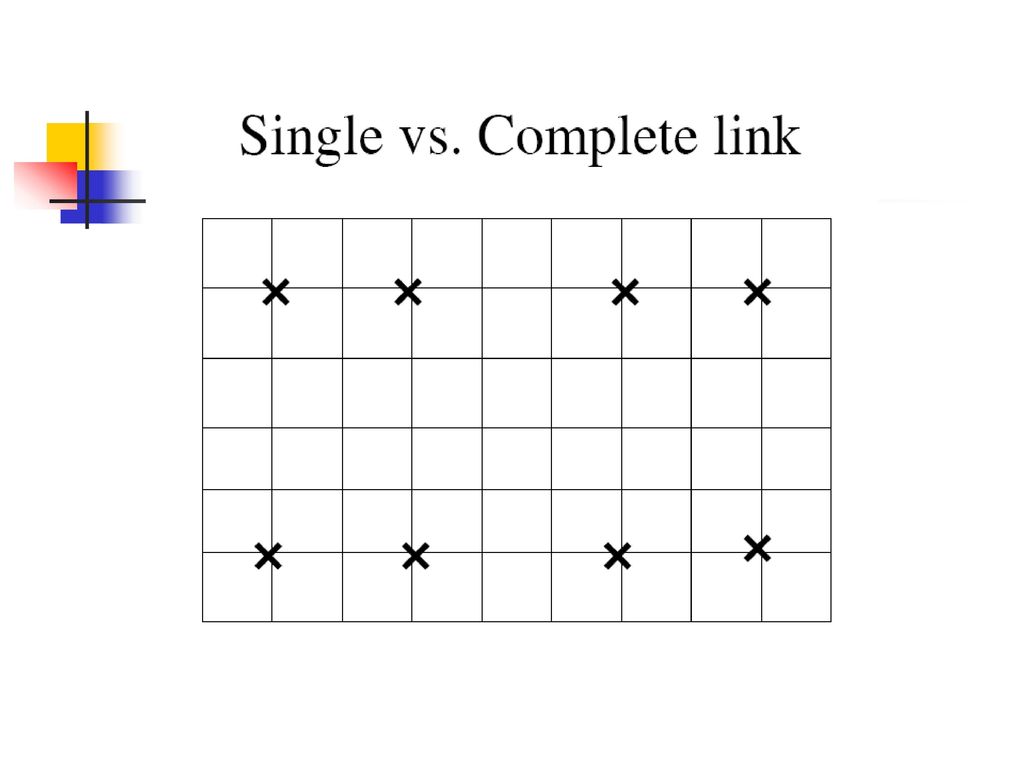
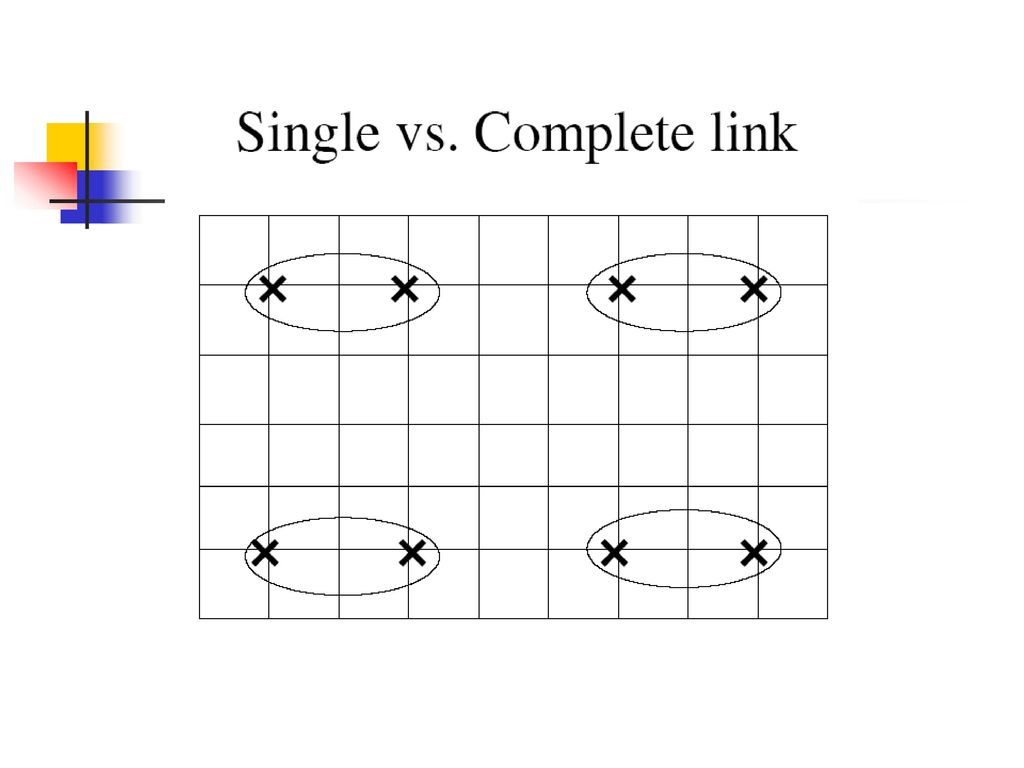
聚类相似度 设定一个相似度函数确定两个实例的相似程度 如何计算包含多个样例的两个类别的相似度? 文本向量的余弦相似度
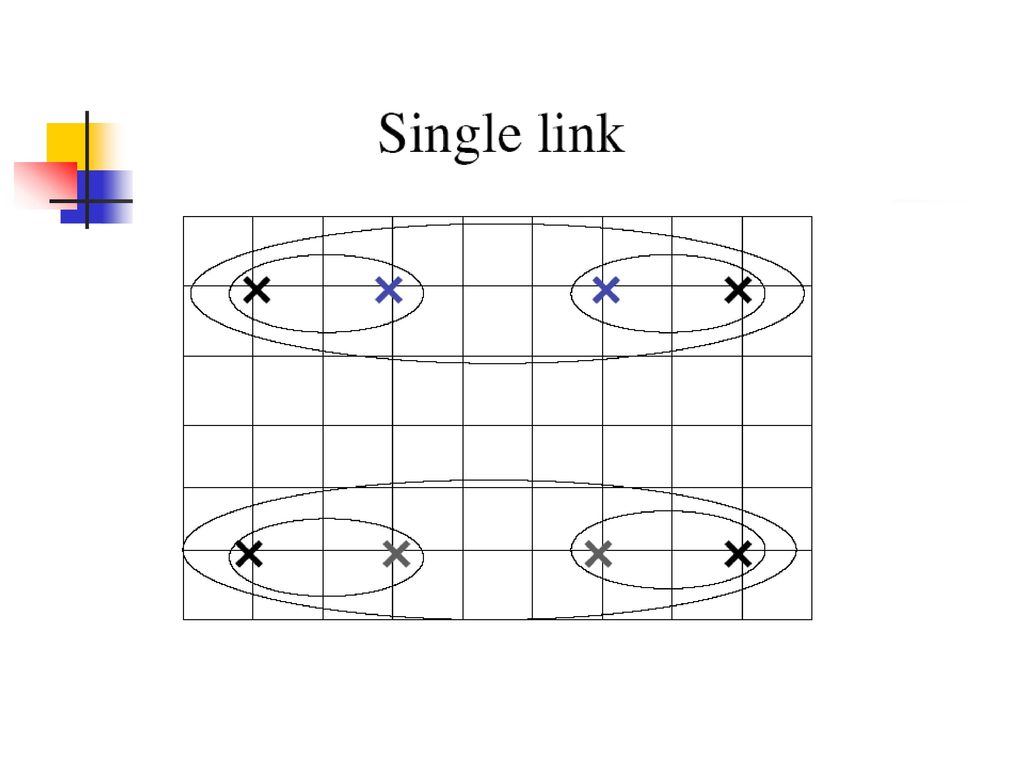
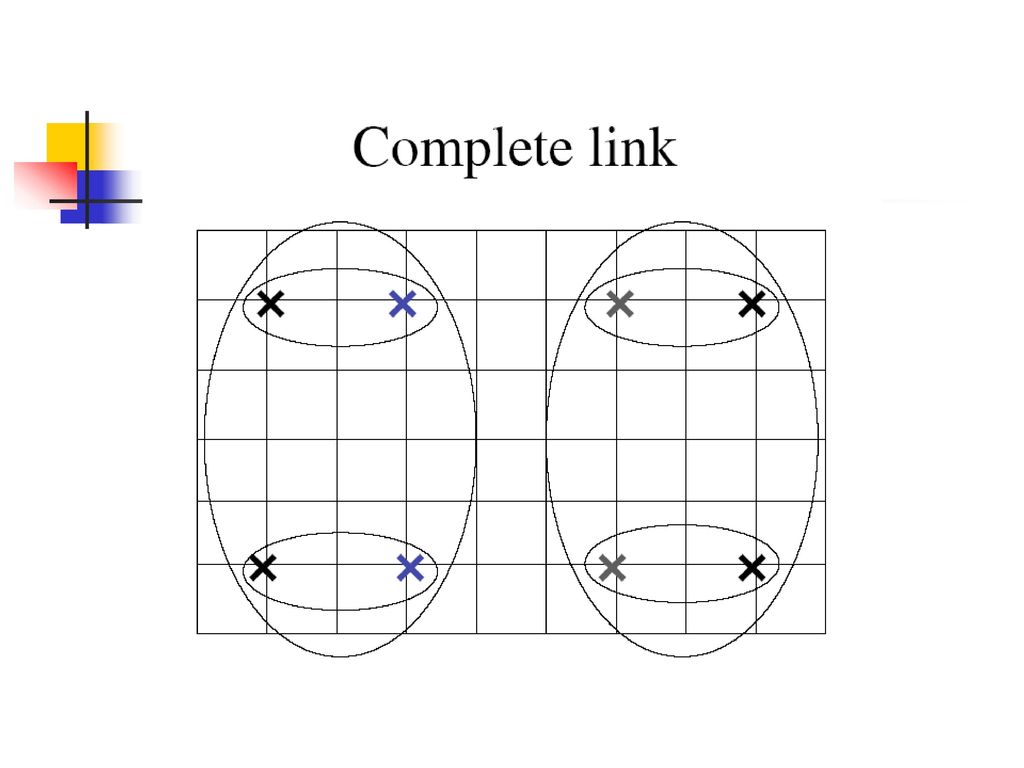
Single Link: 两个类别中最近成员的相似度 Complete Link: 两个类别中最远成员的相似度 Group Average: 成员间的平均相似度

91
计算复杂度 在第一次迭代中,HAC方法需要计算所有样例的每一对的距离 在合并迭代中,需要计算新形成的类与其他类的距离
为了维持O(n2)的性能,计算类与类之间的相似度需要常数时间
的性能,计算类与类之间的相似度需要常数时间.")
92
计算类别间相似度 合并ci,cj后,计算该类和其他类的相似度可以如下计算: Single Link: Complete Link:

93
平均连通凝聚聚类 单连通容易导致狭长聚类,全连通的算法复杂度为O(n3) 用合并后的类中所有对平均相似度度量两个类的相似度
是全连通和单连通的折中.

94
计算平均连通相似度 设定余弦相似度及单位长度归一化向量. 总是维持每个类别的向量和. 计算类别相似度在常数时间内:

95
非层次聚类 需要确定期望的类别数k 随机选择k个种子 进行初始聚类 迭代,将样例重新划分 直到样例所属的类别不再改变

96
K-Means 设定样例是一个实值向量 基于质心或类c中样本的均值聚类 根据样例与当前类别质心的相似度重新划分类别

97
距离矩阵 欧式距 (L2 norm): L1 norm: 余弦相似度 (转换成距离):
: L1 norm: 余弦相似度 (转换成距离):")
98
K-Means 算法 令 d为两个实例的距离度量. 选择 k 个随机样例{s1, s2,… sk} 作为种子. 直到聚类收敛或满足停止策略:
对每个样例 xi: 将 xi 分配到 cj , d(xi, sj) 是最小的. (Update the seeds to the centroid of each cluster) 对每个类 cj sj = (cj)
 是最小的. (Update the seeds to the centroid of each cluster) 对每个类 cj. sj = (cj)")
99
K Means 举例(K=2) Pick seeds Reassign clusters Compute centroids
x Reasssign clusters x Compute centroids Reassign clusters Converged!

100
种子的选择 聚类结果与随机种子的选择是相关的 随机选择的种子可能会导致收敛很慢或者收敛到局部最优 采用启发式方法或其他方法选择好的种子

101
Buckshot 算法 层次聚类和 K-均值 首先随机选择n1/2 大小的语料 在这些样例上运行HAC 利用HAC的结果做为K-均值的种子
该方法避免了不良种子的选取

102
文本聚类 HAC 和 K-Means可以直接应用于文本中. 典型的使用归一化、基于TF/IDF权重的向量以及余弦相似度. 应用:
在检索阶段,加入同一类别的其他文本作为初始检索结果,提高召回率. 检索结果进行聚类,可以提供给用户更好的组织形式 自动生成的层次聚类结果为用户提供方便,根据聚类结果生成文摘等

103
半监督学习 对于有监督的分类,生成标注的训练语料代价很大. Idea: 用无标记的数据帮助有监督分类.
通过用标注和未标注的语料训练EM,在半监督模式中应用. 用已标注的数据子集训练初始的模型. 用户已标注的数据在迭代过程中不再改变. 无指导的数据标注在迭代过程中被重新标注. 哦陈

104
半监督学习举例 假设“quantum” 出现在标为物理的文档中,但是 “Heisenberg”(海森堡) 没有出现在标注的数据中.
缺德

105
本章小结 介绍了文本分类和聚类的概念 介绍了几种特征提取的方法 介绍了贝叶斯,KNN及决策树分类方法 介绍了层次聚类和非层次聚类的方法

Similar presentations



 陆铭 66134922 richard.lu@shu.edu.cn mingler.ccshu.org.>")
 林卓然编著 中山大学出版社>")










 楊立偉教授 台大工管系暨商研所 2014 Fall.>")

、分類(classification)、時序相關(sequence)、預測(forecasting)、群集化(clustering)以及描述等分析作業,目前常用的資料採礦技術有決策樹、類神經網路、基因演算法以及即時線上分析(OLAP)>")

