Download presentation
Presentation is loading. Please wait.

1
数据结构 课程性质:专业基础课 授课时段:2004年下半学期 授课单位:软件学院 任课教师:李青山、徐学洲

2
任课教师:李青山、徐学洲 工作单位:软件工程研究所 工作地点:科技楼9层A座907室 联系电话:029-88202457(办)

3
课程特点 很强的理论性 本课程不是以掌握应用性知识为目的,而是以掌握基本理论,基本方法,基本技能为目的。让学生把握解决什么样的问题,用什么思想,采用什么样方法解决,以及用什么方法最优解决等一系列问题。 很强的概念性 本课程要求学生不但应该深刻理解某些概念的所有要素,要领,精神实质。同时也要求理解为什么要引入某些概念,某些概念的形成过程,引入某些概念是解决什么样的问题 。

4
课程特点(续) 很强的连贯性 本课程结构紧奏,每部分所述问题层层推进,逐步深入,逐步解决。全课程始终是以数据间的关系即“结构”为主线索展开。其中“基本数据结构”部分围饶数据结构三要素即逻辑结构、物理结构、运算特性展开,辅以一定该数据结构基本应用的讲述;而“应用数据结构部分”以基本概念、基本方法、性能分析的讲解顺序展开,使全课程大量庞杂的内容条理分明,轮廓分明 。 很多的混淆性 本课程中首先有很多容易混淆的基本概念。其次有很多算法,状态等等一系列问题都容易混淆。比如要解决某类问题,也许有很多方法和很多途径,每种方法和途径适用于什么场合,各自存在什么优缺点(例如“内部排序”这一章中各中内排方法的比较与应用),都容易产生相互混淆 。
,都容易产生相互混淆 。")
5
课程学习方法 循序渐进学习法 由于本课程很强的理论性、概念性和连贯性,所以学习过程中要从概念入手,逐段、逐节、逐章深刻理解和掌握,层层推进,从基础到应用,最后达到完全掌握该课程内容。 概括提炼学习法 每学完一节、一章内容,都要从中概括提炼出本部分内容要点、重点、非重点。一则可以达到内容总结、有效复习的目的,二则可以自检学习中存在的问题 。

6
课程学习方法(续) 归纳对比学习法 针对课程中容易混淆的概念以及课程中同类、非同类容易混淆的问题,进行归纳并加以有效的比较,从中找出它们的异同点,各自的优缺点,各自针对要解决的问题。这种方法不仅能搞清楚容易混淆的问题,而且能更深刻理解本课程的内容实质。 循环学习法 由于课程中许多基本概念和复杂算法在一次顺序学习过程中 并不能准确和透彻的理解,有些概念和方法可以应用在多种场合,他们的学习就需要循环往复,借助后续内容的信息来全面把握。

7
课程内容框架 基础数据结构 应用数据结构 数 据 结 构 线性结构 非线性结构 动 态 存 管 理 储 线 性 表 广 义 表 二 叉 树
部 排 序 外 部 排 序 队 列 数 组 栈 串 树 图 查 找 文 件 线性结构 非线性结构 基础数据结构 应用数据结构 数 据 结 构

8
教学内容---第一章 1.绪论 2.线性表 3.栈、队列和串 4.数组 5.广义表 6.树和二叉树 7.图 8.动态存储管理 9.查找
10.内部排序 11.外部排序 12.文件

9
1.1什么是数据结构 数据结构学科发展背景 应用领域从科学计算到非数值计算 起初数据结构中内容在其他课程中表述
1968年美国唐.欧.克努特开创数据结构最初体系。在《计算机程序设计技巧》第一卷《基本算法》系统阐述数据的逻辑结构、存储结构及操作 数据结构的两个发展方向:面向专门领域特殊问题的数据结构;从抽象数据类型的观点讨论数据结构

10
1.1什么是数据结构(续) 计算机解决问题的过程 具体问题 数学模型 数据结构 解答 程序 算法 抽象建模 数据结构 数据结构
算法分析与设计 解答 程序 算法 程序设计语言(范型)
")
11
1.1什么是数据结构(续) 数据结构示例(对弈) sk1 … … sqr s10 si1 … s11 … s0 sju … s1n sx1
描述非数值计 算问题的数学 模型不再是数 学方程,而是 诸如表、树和 图之类的数据 结构 … … sqr s10 si1 … s11 … s0 sju … s1n sx1 … … syv

12
1.1什么是数据结构(续) 数据结构学科的地位 综合性的专业基础课 介于数学、计算机硬件和计算机软件之间的核心课程
不仅是一般程序设计的基础,而且是设计和实现编译程序、操作系统、数据库系统及其他系统程序和大型应用程序的重要基础 本课程前继课程:离散数学、C语言 本课程后续课程:面向对象程序设计、操作系统、编译原理、数据库系统、人工智能等

13
1.1什么是数据结构 什么是数据结构 数据结构是一门研究非数值计 算的程序设计问题中计算机的操 作对象以及它们之间的关系和操 作等等的学科。

14
1.2基本概念和术语 基本概念 数据:指所有能输入到计算机中并被计算机程序加工处理的符号的总称。不仅包括数字、字符串,还包括图形、图像、声音、动画、视频等能通过编码而被加工的数据形式。 数据元素:是数据的基本单位,数据集合中的元素。 数据项:是数据的不可分割的最小单位。一个数据元素可由若干个数据项组成。 数据对象:是性质相同的数据元素的集合,是数据的一个子集。

15
1.2基本概念和术语(续) 结构的定义 内涵:数据元素之间的关系,成为“结构” 分类: *集合:松散的关系 *线性结构:一对一的关系
*树形结构:一对多的关系 *网状结构:多对多的关系

16
1.2基本概念和术语(续) 数据结构的定义 描述性定义: 相互之间存在一种或多种特定关系的数据元素的集合 形式化定义:
Data_Structure=(D,S) D={数据元素的有限集合} S={D上关系的有限集合}
 D={数据元素的有限集合} S={D上关系的有限集合}")
17
1.2基本概念和术语(续) 数据结构的分类 逻辑结构: 数据元素之间的逻辑关系(本来的关系) 存储结构:
数据结构在计算机中的映象。包括数据元素的表示和关系的表示两个方面。 分类: *顺序存储结构 *链式存储结构 描述方式: 用高级语言中的“数据类型”来描述

18
1.2基本概念和术语(续) 数据类型 内涵: 一个值的集合和定义在这个值集上的一组操作的总称。本质是封装:实现由处理器完成 分类:
*原子类型: 值不可分解,如整型、指针类型等 *结构类型: 值由若干成分按照某种结构组成,如 数组、结构(记录)等
等.")
19
1.2基本概念和术语(续) 抽象数据类型(ADT)与数据类型
ADT指一个数学模型以及定义在该模型上的一组操作。ADT的定义仅取决于它的一组逻辑特性,而与其在计算机内部如何表示和实现无关。 ADT比数据类型的范畴更广,除了具有固有数据类型的特性之外,还包括用户在设计软件系统时自己定义的数据类型。

20
1.2基本概念和术语(续) 抽象数据类型形式化定义 ADT=(D,S,P) D={数据对象} S={D上的关系集} P={对D的基本操作集}
定义形式: ADT 抽象数据类型名{ 数据对象:… 数据关系:… 基本操作:… } ADT 抽象数据类型名

21
1.2基本概念和术语(续) 抽象数据类型示例 ADT Triplet {
数据对象:D={e1,e2,e3|e1,e2,e3属于ElemSet} 数据关系:R1={<e1,e2>,<e2,e3>} 基本操作: InitTriplet(&T,v1,v2,v3) DestroyTriplet(&T) Get(T ,i,&e) Put(&T,i,e) …… } ADT Triplet 基本操作的定义格式: 基本操作名(参数表) 初始条件:<描述> 操作结果:<描述>
 DestroyTriplet(&T) Get(T ,i,&e) Put(&T,i,e) …… } ADT Triplet. 基本操作的定义格式: 基本操作名(参数表) 初始条件:<描述> 操作结果:<描述>")
22
1.2基本概念和术语(续) 抽象数据类型分类 分类标准:按照值的不同特性 *原子类型: 变量的值不可分解 *固定聚合类型:
变量的值成分的数目确定 *可变聚合类型: 变量的值成分的数目不确定 *多形数据类型: 变量的值成分不确定(成分类型可变)
")
23
1.2基本概念和术语(续) 抽象数据类型表示与实现 抽象数据类型通过固有数据类型来表示和实 抽象数据类型表示与实现
现。即利用处理器中已存在的数据类型来说明 新的结构,用已经实现的操作来组合新的操作。 类C语言的描述语法 类C语言精选了C语言的一个核心子集,也做了若干扩充,以利于描述。 如:存储结构用typedef;数据元素类型约定为ElemType;在形参表中,以&打头的参数为引用参数;等等

24
1.3算法和算法分析 算法 是对特定问题求解步骤的一种描述,是指令的有限序列,其中每一条指令表示一个或多个操作。 内涵: 特性:
*有穷形:有穷步+有穷时间/每一步 *确定性:指令的语义无二义性 *可行性:算法能用基本操作完成 *输入:零个或多个输入 *输出:一个或多个输出

25
1.3算法和算法分析(续) 算法设计的要求 正确性(Correctness) 可读性(Readablity) 健壮性(Robustness)
高时间效率与低存储量需求

26
1.3算法和算法分析(续) 算法的描述方式 自然语言 程序设计语言 流程图 类高级语言(类C语言、类Pascal语言等)
 算法的描述方式 自然语言 程序设计语言 流程图 类高级语言(类C语言、类Pascal语言等)")
27
1.3算法和算法分析(续) 算法选择时效率的考虑
虽然我们希望所选的算法占用额外空间小,运行时间短,其他性能也好,但计算机时间和空间这两大资源往往相互抵触。所以,一般算法选择的原则是: 对于反复使用的算法应选择运行时间短的算法;而使用次数少的算法可力求简明、易于编写和调试;对于数据量较大的算法可从如何节省空间的角度考虑。

28
1.3算法和算法分析(续) 算法时间效率的度量(一) 程序运行消耗时间取决于下列因素 *算法策略 *问题规模 *语言层次
*编译程序所产生的机器代码的质量 *机器执行指令的速度 算法时间效率度量 算法时间效率在软硬件环境相同的情况下取决于问题的规模,即T(n)=f(n)
=f(n)")
29
1.3算法和算法分析(续) 算法时间效率的度量(二) 算法时间效率度量的基本做法
在算法中选取一种对于所研究问题来说是基本操作的原操作,以该基本操作重复执行的次数作为算法的时间度量。 一般而言,这个基本操作是最深层循环内的语句中的原操作。 算法时间复杂度 T(n)=O (f(n)) 称为算法的渐近时间复杂度,简称时间复杂度。
=O (f(n)) 称为算法的渐近时间复杂度,简称时间复杂度。")
30
1.3算法和算法分析(续) 算法时间效率的度量(三) 算法语句频度与时间复杂度的关系
一般算法消耗的实际时间为算法中每条语句频度之和,是n的函数T(n)。当n趋于无穷大时,T(n)的同阶无穷小即是算法时间复杂度。 n+1 for (i=1; i<=n; ++i) for (j=1; j<=n; ++j){ c[i][j] = 0; for (k=1; k<=n; ++k) c[i][j] += a[i][k]*b[k][j]; } n(n+1) n2 n2 (n+1) n3 总时间消耗:T(n)=2n3+3n2+2n+1 时间复杂度:T(n)=O(n3)
。当n趋于无穷大时,T(n)的同阶无穷小即是算法时间复杂度。 n+1. for (i=1; i<=n; ++i) for (j=1; j<=n; ++j){ c[i][j] = 0; for (k=1; k<=n; ++k) c[i][j] += a[i][k]*b[k][j]; } n(n+1) n2. n2 (n+1) n3. 总时间消耗:T(n)=2n3+3n2+2n+1. 时间复杂度:T(n)=O(n3)")
31
1.3算法和算法分析(续) 算法时间效率的度量(四) 大O的运算规则 *加法准则
a)前提:T1(m)=O(f(m));T2(n)=O(g(n)) 结论:T(n)=T1+T2=O(max(f(m),g(n))) b)前提:T1(n)=O(f(n));T2(n)=O(g(n)) 结论:T(n)=T1+T2=O(f(n)+g(n)) *乘法准则 前提:T1(n)=O(f(n));T2(n)=O(g(n)) 结论:T(n)=T1*T2=O(f(n)*g(n))
前提:T1(m)=O(f(m));T2(n)=O(g(n)) 结论:T(n)=T1+T2=O(max(f(m),g(n))) b)前提:T1(n)=O(f(n));T2(n)=O(g(n)) 结论:T(n)=T1+T2=O(f(n)+g(n)) *乘法准则. 前提:T1(n)=O(f(n));T2(n)=O(g(n)) 结论:T(n)=T1*T2=O(f(n)*g(n))")
32
1.3算法和算法分析(续) 算法存储空间的度量 算法存储空间度量的基本做法
用程序执行中需要的辅助空间的消耗作为存储空间度量的依据,是问题规模n的函数。而程序执行中本身需要的工作单元不能算。 算法空间复杂度 S(n)=O (f(n)) 称为算法的空间复杂度。
=O (f(n)) 称为算法的空间复杂度。")
33
教学内容---第二章 1.绪论 2.线性表 3.栈、队列和串 4.数组 5.广义表 6.树和二叉树 7.图 8.动态存储管理 9.查找
10.内部排序 11.外部排序 12.文件

34
2.1线性表的逻辑结构 线性数据结构的特点 在数据元素的非空有限集中 存在唯一的一个被称作“第一个”的数据元素;
存在唯一的一个被称作“最后一个”的数据元素; 除第一个之外,集合中的每一个数据元素均只有一个前驱; 除最后一个之外,集合中每一个数据元素均只有一个后继。

35
2.1线性表的逻辑结构(续) 基本概念和术语 线性表:n个数据元素的有限序列(线性表中的数据元素在不同环境下具体含义可以不同,但在同一线性表中的元素性质必须相同)。 表长:线性表中元素的个数n(n>=0)。 空表:n=0时的线性表称为空表。 位序:非空表中数据元素 ai 是此表的第 i 个元 素,则称 i 为 ai 在线性表中的位序。

36
2.1线性表的逻辑结构(续) 线性表的抽象数据类型定义 ADT List {
数据对象:D={ai | ai属于ElemSet, i = 1,2, … ,n, n>=0} 数据关系:R1={< ai-1, ai >| ai-1, ai属于D, i =2,3, …, n} 基本操作: InitList(&L) DestroyList(&L) ClearList(&L) ListLength(L) GetElem(L, i ,&e) 初始条件:L存在; 1<=i<=ListLength(L) 操作结果:用e返回L中第i个 数据元素的值 } ADT List LocateElem(L,e,compare()) 初始条件:L存在; compare()是判定条件 操作结果:返回第1个与e满足关系compare()的 数据元素位序,若不存在,则返回0 ListInsert(&L, i ,e) 初始条件:L存在;1<=i<=ListLength(L)+1 操作结果:第i个位置之前插入元素e,长度加1 ListDelete(&L, i ,&e) 初始条件:L存在;非空;1<=i<=ListLength(L) 操作结果:删除第i个元素,e返回值,长度减1 查找 插入 删除
 DestroyList(&L) ClearList(&L) ListLength(L) GetElem(L, i ,&e) 初始条件:L存在; 1<=i<=ListLength(L) 操作结果:用e返回L中第i个. 数据元素的值. } ADT List. LocateElem(L,e,compare()) 初始条件:L存在; compare()是判定条件. 操作结果:返回第1个与e满足关系compare()的. 数据元素位序,若不存在,则返回0. ListInsert(&L, i ,e) 初始条件:L存在;1<=i<=ListLength(L)+1. 操作结果:第i个位置之前插入元素e,长度加1. ListDelete(&L, i ,&e) 初始条件:L存在;非空;1<=i<=ListLength(L) 操作结果:删除第i个元素,e返回值,长度减1. 查找. 插入. 删除.")
37
2.1线性表的逻辑结构(续) 示例 问题:两个集合A,B,求A = A U B 算法求解:
Void union(List &La, List Lb) { //将所有在线性表Lb中但不在La中的数据元素插入到La中 La_len = ListLength(La); Lb_len = ListLength(Lb); for (i = 1; i <= Lb_len; i++) { GetElem(Lb, i, e); if (!LocateElem(La, e, equal)) ListInsert(La, ++La_len, e); } 算法实现的复杂度取决于基本操作的复杂度以及算法的控制流程
 { //将所有在线性表Lb中但不在La中的数据元素插入到La中. La_len = ListLength(La); Lb_len = ListLength(Lb); for (i = 1; i <= Lb_len; i++) { GetElem(Lb, i, e); if (!LocateElem(La, e, equal)) ListInsert(La, ++La_len, e); } 算法实现的复杂度取决于基本操作的复杂度以及算法的控制流程.")
38
2.2线性表的顺序存储结构 顺序表---线性表的顺序存储 内涵: 线性表的顺序存储指用一组地址连续的存储
单元依次存储线性表的数据元素。这称为顺序表。 特点: * 存储单元地址连续(需要一段连续空间) * 逻辑上相邻的数据元素其物理位置也相邻 * 随机存取 * 存储密度为大(100%)
 * 逻辑上相邻的数据元素其物理位置也相邻. * 随机存取. * 存储密度为大(100%)")
39
2.2线性表的顺序存储结构(续) 顺序表的随机存取 a1 a2 … ai ai+1 an LOC(a1)
对线性表L,设每个元素占k个存储单元,则有: 递推关系: LOC(ai+1)=LOC(ai )+k 任一元素ai+1的存储位置: LOC(ai)=LOC(a1 )+(i-1)*k (其中1<= i <=ListLength(L)) LOC(ai) LOC(ai+1) LOC(an) 空闲 LOC(a1)+(maxlen-1)*k
=LOC(ai )+k. 任一元素ai+1的存储位置: LOC(ai)=LOC(a1 )+(i-1)*k. (其中1<= i <=ListLength(L)) LOC(ai) LOC(ai+1) LOC(an) 空闲. LOC(a1)+(maxlen-1)*k.")
40
2.2线性表的顺序存储结构(续) 顺序表的数据类型描述 用高级语言中的数组类型描述线性表的顺序存储
// 动态分配 #define LIST_INIT_SIZE 100 //空间初始分配量 #define LISTINCREMENT 10 //空间分配增量 typedef struct { ElemType *elem //存储空间基址 int length //当前长度 int listsize //当前分配的存储容量 } SqList Status InitList_Sq(SqList &L) L.elem=(ElemType *)malloc(LIST_INIT_SIZE * sizeof(ElemType)); if (! L.elem) exit(overflow); L.length=0; L.listsize = LIST_INIT_SIZE ; return OK; } // InitList_Sq
 L.elem=(ElemType *)malloc(LIST_INIT_SIZE * sizeof(ElemType)); if (! L.elem) exit(overflow); L.length=0; L.listsize = LIST_INIT_SIZE ; return OK; } // InitList_Sq.")
41
2.2线性表的顺序存储结构(续) 顺序表上插入运算的实现 a1 a2 … ai-1 ai an a1 a2 … ai-1 ai an e
(a1,…, ai, ai+1,…, an) 表长为n ListInsert(&L, i ,e) (a1,…, ai-1, e,ai,…, an)表长为n+1 插入 Status ListInsert_Sq(SqList &L, int i, ElemType e) { 第一步:判断参数是否合法合理,否则出错; 第二步:在物理空间中找到插入位置; 第三步:插入前的准备工作; 第四步:插入; } //ListInsert_Sq
 表长为n. ListInsert(&L, i ,e) (a1,…, ai-1, e,ai,…, an)表长为n+1. 插入. Status ListInsert_Sq(SqList &L, int i, ElemType e) { 第一步:判断参数是否合法合理,否则出错; 第二步:在物理空间中找到插入位置; 第三步:插入前的准备工作; 第四步:插入; } //ListInsert_Sq.")
42
2.2线性表的顺序存储结构(续) 顺序表上插入运算效率分析
分析:从算法流程上看,查找插入位置、插入元素的时间花费是常数级,而算法执行时间主要花在插入前元素的移动上,而移动元素的个数与插入位置i有关。

43
2.2线性表的顺序存储结构(续) 顺序表上删除运算的实现 a1 a2 … ai-1 ai an ai+1 a1 a2 … ai-1 ai+1
(a1,…, ai, ai+1,…, an) 表长为n ListDelete(&L, i ,&e) (a1,…, ai-1, ai+1,…, an) 表长为n-1 删除 Status ListDelete_Sq(SqList &L, int i, ElemType & e) { 第一步:判断参数是否合法合理,否则出错; 第二步:在物理空间中找到删除位置; 第三步:删除; 第四步:删除后的善后工作 } // ListDelete_Sq
 表长为n. ListDelete(&L, i ,&e) (a1,…, ai-1, ai+1,…, an) 表长为n-1. 删除. Status ListDelete_Sq(SqList &L, int i, ElemType & e) { 第一步:判断参数是否合法合理,否则出错; 第二步:在物理空间中找到删除位置; 第三步:删除; 第四步:删除后的善后工作. } // ListDelete_Sq.")
44
2.2线性表的顺序存储结构(续) 顺序表上删除运算效率分析
分析:从算法流程上看,查找删除位置、删除元素的时间花费是常数级,而算法执行时间主要花在删除后元素的移动上,而移动元素的个数与删除位置i有关。

45
2.3线性表的链式存储结构 顺序表优缺点分析 优点: * 不需要额外空间来存储元素之间的关系 * 可以随机存取任一元素 缺点:
* 插入和删除运算需要移动大量元素 * 需要一段连续空间 * 预先分配足够大的空间 * 表的容量难以扩充 可以通过使用动态数组数据类型来描述顺序表而改进这两个缺点

46
2.3线性表的链式存储结构(续) 链表---线性表的链式存储 内涵:
线性表的链式存储指用任意的存储单元存放线性表中的元素,每个元素与其前驱和(或)后继之间的关系用指针来存储。这称为链表。 术语: * 结点 * 数据域 * 指针域 * 头指针 * 头结点 分类: * 单链表 * 循环链表 * 双向链表 * 双向循环链表 * 静态链表
后继之间的关系用指针来存储。这称为链表。 术语: * 结点. * 数据域. * 指针域. * 头指针. * 头结点. 分类: * 单链表. * 循环链表. * 双向链表. * 双向循环链表. * 静态链表.")
47
2.3线性表的链式存储结构(续) 单链表 … ^ ^ 链表中,如果每个结点中只包含一个指针域, 称这种链表为线性链表或单链表。
单链表可由头指针唯一确定。 … L a1 a2 an ^ L ^

48
2.3线性表的链式存储结构(续) 单链表的数据类型描述 用高级语言中的指针类型描述线性表的链式存储
// 用结构指针描述 typedef struct LNode{ ElemType data //数据域 struct LNode *next //指针域 } Lnode, *LinkList

49
2.3线性表的链式存储结构(续) 单链表上插入运算的实现(一) … … ^ p ai-1 ai L ai-1 ai L e s e s
(a1,…, ai, ai+1,…, an) 表长为n ListInsert(&L, i ,e) p (a1,…, ai-1, e,ai,…, an)表长为n+1 ai-1 ai … L 插入 ai-1 ai … L s->next=p->next; p->next=s e s e ^ s S=(LinkList) malloc(sizeof(LNode))
 表长为n. ListInsert(&L, i ,e) p. (a1,…, ai-1, e,ai,…, an)表长为n+1. ai-1. ai. … L. 插入. ai-1. ai. … L. s->next=p->next; p->next=s. e. s. e. ^ s. S=(LinkList) malloc(sizeof(LNode))")
50
2.3线性表的链式存储结构(续) 单链表上插入运算的实现(二)
Status ListInsert_L(LinkList &L, int i, ElemType e) {//在带头结点的单链表L的第i个元素之前插入 第一步:判断参数是否合法合理,否则出错; 第二步:在物理空间中找到插入位置(i-1); 第三步:插入前的准备工作; 第四步:插入; } //ListInsert_L
 {//在带头结点的单链表L的第i个元素之前插入. 第一步:判断参数是否合法合理,否则出错; 第二步:在物理空间中找到插入位置(i-1); 第三步:插入前的准备工作; 第四步:插入; } //ListInsert_L.")
51
2.3线性表的链式存储结构(续) 单链表上插入运算效率分析 分析:
从算法流程上看,找到插入位置后插入元素的时间花费是常数级,而算法执行时间主要花在插入前插入位置的查找上,而查找时间与插入位置i有关。具体而言,在第i个元素之前插入需要找到指向第i-1个元素的指针。 T(n)=O(n)
=O(n)")
52
2.3线性表的链式存储结构(续) 单链表上删除运算的实现(一) … … p ai-1 ai L ai+1 ai-1 ai L ai+1 p
(a1,…, ai, ai+1,…, an) 表长为n ListDelete(&L, i ,&e) (a1,…, ai-1, ai+1,…, an) 表长为n-1 p ai-1 ai … L ai+1 ai-1 ai … L ai+1 p 删除 q free(q) p->next=p->next->next
 表长为n. ListDelete(&L, i ,&e) (a1,…, ai-1, ai+1,…, an) 表长为n-1. p. ai-1. ai. … L. ai+1. ai-1. ai. … L. ai+1. p. 删除. q. free(q) p->next=p->next->next.")
53
2.3线性表的链式存储结构(续) 单链表上插入运算的实现(二)
Status ListDelete_L(LinkList &L, int i, ElemType &e) { 第一步:判断参数是否合法合理,否则出错; 第二步:在物理空间中找到删除位置(i-1) ; 第三步:删除; 第四步:删除后的善后工作 } // ListDelete_L
 { 第一步:判断参数是否合法合理,否则出错; 第二步:在物理空间中找到删除位置(i-1) ; 第三步:删除; 第四步:删除后的善后工作. } // ListDelete_L.")
54
2.3线性表的链式存储结构(续) 单链表上删除运算效率分析 分析:
从算法流程上看,找到删除位置后删除元素的时间花费是常数级,而算法执行时间主要花在删除前删除位置的查找上,而查找时间与删除位置i有关。具体而言,删除第i个元素需要找到指向第i-1个元素的指针。 T(n)=O(n)
=O(n)")
55
2.3线性表的链式存储结构(续) 循环链表 特点: 在单链表基础上,让表中最后一个结点的指针域指向头结点,整个链表形成一个环。 作用:
从表中任一结点出发可以找到表中其他结点,从而提高整个表的平均查找效率。与单链表相比,平均可提高三分之一的时间。 操作: 与单链表基本一致

56
2.3线性表的链式存储结构(续) 双向链表 特点:
在单链表基础上,增加一个指针域,让一个指针域指向当前结点的直接前驱,一个指向当前结点的直接后继。 作用: 从映射关系上讲,元素之间的关联关系增加,从表中任一结点出发可以沿着两个方向找到表中其他结点,从而提高整个表的平均查找效率。与单链表相比,平均可提高二分之一的时间。

57
2.3线性表的链式存储结构(续) 双向链表的数据类型描述 … L ai-1 ai+1 ai
// 用结构指针描述 typedef struct DuLNode{ ElemType data //数据域 struct DuLNode *prior //前驱指针域 struct DuLNode *next //后继指针域 } DuLnode, *DuLinkList next data prior

58
2.3线性表的链式存储结构(续) 双向链表上插入运算的实现(一) … … p L ai-1 ai+1 ai L ai-1 ai e
s->next = p->next p->next->prior = s p->next = s s->prior = p (a1,…, ai, ai+1,…, an) 表长为n ListInsert(&L, i ,e) p (a1,…, ai-1, e,ai,…, an)表长为n+1 L ai-1 ai+1 … ai 插入 p L ai-1 ai … e s s=(DuLinkList) malloc(sizeof(DuLNode))
 表长为n. ListInsert(&L, i ,e) p. (a1,…, ai-1, e,ai,…, an)表长为n+1. L. ai-1. ai+1. … ai. 插入. p. L. ai-1. ai. … e. s. s=(DuLinkList) malloc(sizeof(DuLNode))")
59
2.3线性表的链式存储结构(续) 双向链表上插入运算的实现(二)
Status DuListInsert_DuL(DuLinkList &L, int i, ElemType e) {//在带头结点的双向链表L的第i个元素之前插入 第一步:判断参数是否合法合理,否则出错; 第二步:在物理空间中找到插入位置(仅仅在i-1处么?); 第三步:插入前的准备工作; 第四步:插入; } //DuListInsert_DuL
 {//在带头结点的双向链表L的第i个元素之前插入. 第一步:判断参数是否合法合理,否则出错; 第二步:在物理空间中找到插入位置(仅仅在i-1处么?); 第三步:插入前的准备工作; 第四步:插入; } //DuListInsert_DuL.")
60
2.3线性表的链式存储结构(续) 双向链表上删除运算的实现(一) … … p L ai-1 ai+1 ai L ai-1 ai+1 ai q
(a1,…, ai, ai+1,…, an) 表长为n ListDelete(&L, i ,&e) (a1,…, ai-1, ai+1,…, an) 表长为n-1 p L ai-1 ai+1 … ai 删除 L ai-1 ai+1 … ai p q p->next->next->prior=p p->next=p->next->next free(q)
 表长为n. ListDelete(&L, i ,&e) (a1,…, ai-1, ai+1,…, an) 表长为n-1. p. L. ai-1. ai+1. … ai. 删除. L. ai-1. ai+1. … ai. p. q. p->next->next->prior=p. p->next=p->next->next. free(q)")
61
2.3线性表的链式存储结构(续) 双向链表上删除运算的实现(二)
Status DuListDelete_DuL(DuLinkList &L, int i, ElemType &e) { 第一步:判断参数是否合法合理,否则出错; 第二步:在物理空间中找到删除位置(仅仅在i-1处么?) ; 第三步:删除; 第四步:删除后的善后工作 } // DuListDelete_DuL
 { 第一步:判断参数是否合法合理,否则出错; 第二步:在物理空间中找到删除位置(仅仅在i-1处么?) ; 第三步:删除; 第四步:删除后的善后工作. } // DuListDelete_DuL.")
62
2.3线性表的链式存储结构(续) 双向循环链表 特点:
在双向链表基础上,让表中最后一个结点的后继指针域指向头结点,让头结点的前驱指针域指向最后一个结点,整个链表形成一个环。 作用: 从映射关系上讲,元素之间的关联关系增加,从表中任一结点出发可以沿着两个方向找到表中其他结点,从而提高整个表的平均查找效率。与单链表相比,平均可提高三分之二的时间。

63
2.3线性表的链式存储结构(续) 静态链表 特点:
用一维数组来描述线性表,但数据元素的相邻关系仍然借助于额外的数组下标号(游标)来描述,处理手段仍然是链式存储结构的思想。 作用: 有的高级语言不支持指针类型,但有些应用需要用链式存储。
来描述,处理手段仍然是链式存储结构的思想。 作用: 有的高级语言不支持指针类型,但有些应用需要用链式存储。")
64
2.3线性表的链式存储结构(续) 静态链表的数据类型描述 a1 … ai ai+1 an (a1,…, ai, ai+1,…, an) 1
a1 k ai p i ai+1 q MAXSIZE-1 an n … i+1 (a1,…, ai, ai+1,…, an) //----线性表的静态单链表存储结构--- #define MAXSIZE 1000 typedef struct { ElemType data //数据域 int cur //游标域 } component, SLinkList[MAXSIZE]
 //----线性表的静态单链表存储结构--- #define MAXSIZE typedef struct { ElemType data //数据域. int cur //游标域. } component, SLinkList[MAXSIZE]")
65
2.3线性表的链式存储结构(续) 静态链表基本运算的实现(一) 查找:
与单链表上元素的查找过程类似,沿着游标方向不断求元素后继,从而找到待检索元素位置。 插入: 与单链表上元素的插入过程类似,需要修改游标,维护元素在物理存储上的线性关系。但申请元素时,不能用malloc,需要采用其他手段。 删除: 与单链表上元素的删除过程类似,需要修改游标。但释放被删除元素所在结点时,不能用free,需要采用其他手段。

66
2.3线性表的链式存储结构(续) 静态链表基本运算的实现(二) 申请与释放空间的做法:
将所有未被使用过以及被删除的分量用游标链成一个备用链表(仍然是静态链表),插入时申请空间从备用链表中取(相当于在备用链表中删除元素);删除时释放空间到备用链表中去(相当于在备用链表中插入元素)。 具体而言,备用链表中插入和删除的位置都在备用链表头结点后的那一个位置。
,插入时申请空间从备用链表中取(相当于在备用链表中删除元素);删除时释放空间到备用链表中去(相当于在备用链表中插入元素)。 具体而言,备用链表中插入和删除的位置都在备用链表头结点后的那一个位置。")
67
2.3线性表的链式存储结构(续) 静态链表基本运算的实现(三) … Void InitSpace_SL(SLinkList &space){
//space[0].cur为备用链表头指针,空指针表示为0 for(i=0; i<MAXSIZE-1; ++i) space[i].cur = i+1 space[MAXSIZE-1].cur = 0;}//InitSpace_SL 1 2 3 MAXSIZE-1 space …
 space[i].cur = i+1. space[MAXSIZE-1].cur = 0;}//InitSpace_SL MAXSIZE-1. space. …")
68
2.3线性表的链式存储结构(续) 静态链表基本运算的实现(四) a a … …
int Malloc_SL(SLinkList &space){ //若备用链表非空,则返回分配的结点下标,否则返回0 i=space[0].cur ; if (space[0].cur) space[0].cur = space[i].cur; return i; }//Malloc_SL j a i 1 b q k … MAXSIZE-1 p k a i 1 j … MAXSIZE-1 p Malloc_SL(space)
{ //若备用链表非空,则返回分配的结点下标,否则返回0. i=space[0].cur ; if (space[0].cur) space[0].cur = space[i].cur; return i; }//Malloc_SL. j. a. i. 1. b. q. k. … MAXSIZE-1. p. k. a. i. 1. j. … MAXSIZE-1. p. Malloc_SL(space)")
69
2.3线性表的链式存储结构(续) 静态链表基本运算的实现(五) a … a …
int Free_SL(SLinkList &space, int k){ //将下标为k的空闲结点回收到备用链表 space[k].cur = space[0].cur ; space[0].cur = k; }//Free_SL i a p 1 b q k … MAXSIZE-1 m j k a p 1 b i … MAXSIZE-1 m j Free_SL(space)
{ //将下标为k的空闲结点回收到备用链表. space[k].cur = space[0].cur ; space[0].cur = k; }//Free_SL. i. a. p. 1. b. q. k. … MAXSIZE-1. m. j. k. a. p. 1. b. i. … MAXSIZE-1. m. j. Free_SL(space)")
70
2.3线性表的链式存储结构(续) 静态链表基本运算的实现(六) 例:求(A-B)U(B-A),用S静态链表存储集合A,结果也在S中
void difference(SLinkList &space, int &S){ InitSpace_SL(space); //初始化备用空间 S = Malloc_SL(space); //生成S的头结点 r = S; //r指向S的当前最后结点 …… }// difference
{ InitSpace_SL(space); //初始化备用空间. S = Malloc_SL(space); //生成S的头结点. r = S; //r指向S的当前最后结点. …… }// difference.")
71
2.3线性表的链式存储结构(续) 静态链表基本运算的实现(七) 上例中,设 A=(c,b,e,g,f,d), B=(a,b,n,f) 8 2
2 1 f 7 6 c 3 9 11 10 b 4 d e 5 g 9 2 1 f 7 6 c 3 a 8 11 10 b 4 d e 5 g 3 2 1 f 7 6 c 4 a 8 11 10 9 d e 5 g 9 2 1 f 7 6 c 4 a 8 3 11 10 n d e 5 g 6 2 1 9 c 4 a 8 3 11 10 n d 7 e 5 g 1 S 7 r 1 S 8 r 1 S 8 r 1 S 3 r 1 S 3 r 插入a 删除b 插入n 删除f

72
2.4 线性表应用 一元多项式及相加的数学表示 对于Pn(x)=p0+p1x+p2x2+…+pnxn
可表示为:P =(p0,p1 , p2,…pn) 则另对于Qn(x)=q0+q1x+q2x2+…+qmxm亦有 Q =(q0,q1 , q2,…qm), 不妨设m<n,则Rn(x)= Pn(x)+ Qm(x)可表示为: R =(p0+q0,p1+q1 , p2+q2,…+pm+qm,pm+1 ,…, pn) 尽管这种数学模型可以抽象为以系数为元 素的线性表,但无论采用顺序表还是链表,都 存在着空间浪费严重的情况。
 则另对于Qn(x)=q0+q1x+q2x2+…+qmxm亦有. Q =(q0,q1 , q2,…qm), 不妨设m<n,则Rn(x)= Pn(x)+ Qm(x)可表示为: R =(p0+q0,p1+q1 , p2+q2,…+pm+qm,pm+1 ,…, pn) 尽管这种数学模型可以抽象为以系数为元. 素的线性表,但无论采用顺序表还是链表,都. 存在着空间浪费严重的情况。")
73
2.4 线性表应用(续) 一元多项式数据结构抽象 实际数据结构选取方案: p1于Pn(x)=p1xe1+p2xe2+…+pmxem
Pi是指数为ei的项的非零系数,且满足: 0<=e1<=e2 <=…<=ei<=em = n 则可抽象的线性表为(每个元素是一个二元组): ((p1,e1),(p1,e1),… ,(pm,em))
: ((p1,e1),(p1,e1),… ,(pm,em))")
74
2.4 线性表应用(续) 一元多项式的抽象数据结构 ADT Polynomial {
数据对象:D={ai| ai属于TermSet, i=1,2,…,m, m>=0,TermSet是一个由实数 与整数组成的二元组} 数据关系:R1={< ai-1, ai >| ai-1 , ai 属于D,且ai-1 中的指数值< ai 中的值数 值, i=1,2,…,n} 基本操作: CreatePolyn(&P,m); AddPolyn(&Pa,&Pb) // Pa = Pa + Pb MutiplyPolyn(&Pa,&Pb) // Pa = Pa* Pb …… } ADT Polynomial
; AddPolyn(&Pa,&Pb) // Pa = Pa + Pb. MutiplyPolyn(&Pa,&Pb) // Pa = Pa* Pb. …… } ADT Polynomial.")
75
2.4 线性表应用(续) 一元多项式的链式存储结构 //----------用结构指针描述------------
typedef struct Term{ float coef //系数数据域 int expn //指数数据域 struct Term *next //指针域 } Term, *LinkList

76
2.4 线性表应用(续) 一元多项式的链式表示 ^ ^ 设A17(x)=7+3x+9x8+5x17, B8(x)=8x+22x7-9x8 A
-1 1 3 8 9 ^ 17 5 7 -1 B 1 8 ^ -9 7 22

77
2.4 线性表应用(续) 一元多项式的相加 ^ 从逻辑上讲,指数相同的项对应相加,若相加后系数为0,
则删除该结点;对于指数不同的项,复抄即可,但须保证 和多项式仍然以系数递增排列。从物理实现看,本质上就 是结点的插入和删除。 A17(x)+B8(x)=7+11x+22x7+5x17 ^ 5 A -1 1 11 7 22
+B8(x)=7+11x+22x7+5x17. ^ 5. A")
78
2.4 线性表应用(续) 一元多项式链式存储的类PASCAL表示 //----------用结构指针描述------------
TYPE linktyp= ^nodetp; nodetp=RECORD coef: real; //系数数据域 exp: integer; //指数数据域 next: linktp //指针域 END; polytp=linktp;

79
2.4 线性表应用(续) 一元多项式相加的运算规则 “和多项式”中结点无需另生成,可看成是将多项式B加到 多项式A上。
运算规则:设p和q分别指向多项式A和B中某一结点,比 较结点钟的指数项,若p^.exp<q^.exp,则p结点应是“和多 项式”中的一项,令p指针向后移;若p^.exp>q^.exp,则q结 点应是“和多项式”中的一项,令q结点插入在p结点之前, 且q指针在原来的链表上后移;若p^.exp=q^.exp,则将两个 结点中的系数相加,当和不为零时修改p结点中的系数域, 释放q结点;反之,“和多项式”中没有此项,从A表中删去p 结点,同时释放p和q结点。

80
PROC add_poly(VAR pa:polyty; pb:polytp);
ENDP; {add_poly} p:=pa^.next; q:=pb^.next; pre:=pa; pc:=pa; WHILE (p!=NIL)AND (q!=NIL) DO CASE p^.exp<q^.exp: p^.exp=q^.exp: p^.exp>q^.exp: [pre:=p; p:=p^.next]; [x:=p^.coef+q^.coef; IF x!=0 THEN [ p^.coef:=x; pre:=p] ELSE [pre^.next:=p^.next;dispose(p)]; p:=pre^.next; u:=q; q:=q^.next; dispose(u)] [u:=q^.next; q^.next:=p; pre^.next:=q; pre:=q; q:=u ] IF q!= NIL THEN pre^.next:= q; dispose(pb)
AND (q!=NIL) DO. CASE. p^.exp<q^.exp: p^.exp=q^.exp: p^.exp>q^.exp: [pre:=p; p:=p^.next]; [x:=p^.coef+q^.coef; IF x!=0 THEN [ p^.coef:=x; pre:=p] ELSE [pre^.next:=p^.next;dispose(p)]; p:=pre^.next; u:=q; q:=q^.next; dispose(u)] [u:=q^.next; q^.next:=p; pre^.next:=q; pre:=q; q:=u ] IF q!= NIL THEN pre^.next:= q; dispose(pb)")
81
教学内容---第三章 1.绪论 2.线性表 3.栈、队列和串 4.数组 5.广义表 6.树和二叉树 7.图 8.动态存储管理 9.查找
10.内部排序 11.外部排序 12.文件

82
3.1 栈、队列和串的逻辑结构 栈、队列和串是特殊的线性表 栈和队列是操作受限的线性表 栈和队列的“操作受限”指操作位置受限
串的特殊性在于线性表中数据元素只能是字符 串一般以子串为操作单位 栈、队列和串具有一般线性表共性的特点 特殊的线性表反而应用面更宽

83
3.1 栈、队列和串的逻辑结构(续) 栈的基本概念和术语 栈(Stack):限定仅在表尾进行插入或删除操作的线性表。
栈顶(top) :插入或删除的表尾端。 栈底(bottom) :表头端。 空栈:空表。 栈的操作特点:后进先出(Last In First Out---LIFO)
 :插入或删除的表尾端。 栈底(bottom) :表头端。 空栈:空表。 栈的操作特点:后进先出(Last In First Out---LIFO)")
84
3.1 栈、队列和串的逻辑结构(续) 栈的抽象数据类型定义 ADT Stack {
数据对象:D={ai | ai属于ElemSet, i = 1,2, … ,n, n>=0} 数据关系:R1={< ai-1, ai >| ai-1, ai属于D, i =2,3, …, n}// a1 为栈底, an 栈顶 基本操作: InitStack(&S) DestroyStack (&S) StackEmpty(S) ClearStack (&S) StackLength(S) GetTop(S,&e) 初始条件:S存在,非空; 操作结果:用e返回S的栈顶元 素 Push(&S,e) 初始条件:S存在 操作结果:插入元素e为新的栈顶元素,长度加 Pop(&S, &e) 初始条件:S存在;非空 操作结果:删除S的栈顶元素,e返回值,长度 减1 }ADT Stack 入栈(插入) 出栈(删除)
 DestroyStack (&S) StackEmpty(S) ClearStack (&S) StackLength(S) GetTop(S,&e) 初始条件:S存在,非空; 操作结果:用e返回S的栈顶元 素. Push(&S,e) 初始条件:S存在. 操作结果:插入元素e为新的栈顶元素,长度加 1. Pop(&S, &e) 初始条件:S存在;非空. 操作结果:删除S的栈顶元素,e返回值,长度 减1. }ADT Stack. 入栈(插入) 出栈(删除)")
85
3.1 栈、队列和串的逻辑结构(续) 队列的基本概念和术语 队列(Queue):限定仅在表的一端进行插入,而另一端进行删除操作的线性表。
队尾(rear) :允许插入的一端。 队头(front):允许删除的一端。 空队:空表。 队列操作特点:先进先出(First In First Out---FIFO)
 :允许插入的一端。 队头(front):允许删除的一端。 空队:空表。 队列操作特点:先进先出(First In First Out---FIFO)")
86
3.1 栈、队列和串的逻辑结构(续) 队列的抽象数据类型定义 ADT Queue {
数据对象:D={ai | ai属于ElemSet, i = 1,2, … ,n, n>=0} 数据关系:R1={< ai-1, ai >| ai-1, ai属于D, i =2,3, …, n}// a1 为队头, an 队尾 基本操作: InitQueue(&Q) DestroyQueue(&Q) ClearQueue(&Q) QueueEmpty(Q) QueueLength(Q) GetHead(Q,&e) 初始条件:Q存在,非空; 操作结果:用e返回Q的栈顶元 素 EnQueue(&Q,e) 初始条件:Q存在 操作结果:插入元素e为新的队尾元素,长度加 DelQueue (&S, &e) 初始条件:Q存在;非空 操作结果:删除Q的对头元素,e返回值,长度 减1 }ADT Queue 入队(插入) 出队(删除)
 DestroyQueue(&Q) ClearQueue(&Q) QueueEmpty(Q) QueueLength(Q) GetHead(Q,&e) 初始条件:Q存在,非空; 操作结果:用e返回Q的栈顶元 素. EnQueue(&Q,e) 初始条件:Q存在. 操作结果:插入元素e为新的队尾元素,长度加 1. DelQueue (&S, &e) 初始条件:Q存在;非空. 操作结果:删除Q的对头元素,e返回值,长度 减1. }ADT Queue. 入队(插入) 出队(删除)")
87
3.1 栈、队列和串的逻辑结构(续) 串的基本概念和术语 串的操作特点:一般以子串整体为单位
串(String):由零个或多个字符组成的有限序列。S=‘a1a2…an’ 串名、串值 串长 空串、空格串 子串:串中任意连续的字符组成的子序列 主串: 字符在串中的位置、子串在串中的位置 串相等 串的操作特点:一般以子串整体为单位
:由零个或多个字符组成的有限序列。S=‘a1a2…an’ 串名、串值. 串长. 空串、空格串. 子串:串中任意连续的字符组成的子序列. 主串: 字符在串中的位置、子串在串中的位置. 串相等. 串的操作特点:一般以子串整体为单位.")
88
3.1 栈、队列和串的逻辑结构(续) 串的抽象数据类型定义 ADT Sring {
数据对象:D={ai | ai属于CharacterSet, i = 1,2, … ,n, n>=0} 数据关系:R1={< ai-1, ai >| ai-1, ai属于D, i =2,3, …, n} 基本操作: StrAssign(&T,chars) StrCopy (&T,S) StrEmpty (S) StrLength(S) SubString(&Sub,S,pos,len) 初始条件:S存在, 1<=pos<=StrLength(S), 0<=len<=StrLength(S)-pos+1; 操作结果: Index(S,T,pos) StrInsert(&S,pos,T) 初始条件:S存在,1<=pos<=StrLength(S)+1 操作结果:在串S的第pos个字符之前插入串T StrDelete(&S,pos,len) 初始条件:S存在,1<=pos<=StrLength(S)-len+1 操作结果:从串S中删除第pos个字符起长度为 len 的子串 }ADT String 查找 插入 删除
 StrCopy (&T,S) StrEmpty (S) StrLength(S) SubString(&Sub,S,pos,len) 初始条件:S存在, 1<=pos<=StrLength(S), 0<=len<=StrLength(S)-pos+1; 操作结果: Index(S,T,pos) StrInsert(&S,pos,T) 初始条件:S存在,1<=pos<=StrLength(S)+1. 操作结果:在串S的第pos个字符之前插入串T. StrDelete(&S,pos,len) 初始条件:S存在,1<=pos<=StrLength(S)-len+1. 操作结果:从串S中删除第pos个字符起长度为. len 的子串. }ADT String. 查找. 插入. 删除.")
89
3.2 栈、队列和串的存储结构 栈的顺序存储 … ai a2 a1 //----------动态分配------------
#define STACK_INIT_SIZE //空间初始分配量 #define STACKINCREMENT 10 //空间分配增量 typedef struct { sElemType *base sElemType *top int stacksize //当前分配的存储容量 } SqStack a1 … ai a2 top base

90
3.2 栈、队列和串的存储结构(续) 顺序栈上的入栈 … e ai a2 a1
Status Push(SqStack &S,SElemType e) if(S.top – S.base>= S.stacksize) { S.base = (SElemTupe *) realloc ( S.base,(S.stacksize +STACKINCERMENT) * sizeof (Selemtype)); if (!S.base) exit (OVERFLOW); // 存储分配失败 S.top = S.base + S.stacksize; S.stacksize =+ STACKINCERMENT;} *S.top++ = e; return OK; } // Push 入栈 a1 … ai a2 base top e
 if(S.top – S.base>= S.stacksize) { S.base = (SElemTupe *) realloc ( S.base,(S.stacksize. +STACKINCERMENT) * sizeof (Selemtype)); if (!S.base) exit (OVERFLOW); // 存储分配失败. S.top = S.base + S.stacksize; S.stacksize =+ STACKINCERMENT;} *S.top++ = e; return OK; } // Push. 入栈. a1. … ai. a2. base. top. e.")
91
3.2 栈、队列和串的存储结构(续) 顺序栈上的出栈 a1 ai ai-1 … a2 a1 … ai-1 a2
Status Pop(SqStack &S,SElemType &e) if(S.top = S.base) return error; e = * --S.top; return OK; } // Pop a1 ai ai-1 … a2 a1 … ai-1 a2 top top 出栈 base base
 if(S.top = S.base) return error; e = * --S.top; return OK; } // Pop. a1. ai. ai-1. … a2. a1. … ai-1. a2. top. top. 出栈. base. base.")
92
3.2 栈、队列和串的存储结构(续) 栈的链式存储---链栈 … ^ an-1 a1 an typedef struct {
ElemType data struct Lnode *next } Lnode,* StackPtr typedef struct { StackPtr top StackPtr base } LinkStack an-1 a1 ^ an … base top

93
3.2 栈、队列和串的存储结构(续) 链栈上的入栈与出栈 链栈上的入栈与出栈与单链表上元素插入删除操作类似
插入删除位置都在栈顶处,不花费查找时间 栈空的判断 与顺序栈相比,时间效率高

94
3.2 栈、队列和串的存储结构(续) 队列的顺序存储---循环队列(一) … ai a2 a1 一般顺序存储的队列特点:
队空条件:front = rear 队满条件:rear = MAXSIZE 队满条件下的队满为假满(假溢出) (真满时:rear = MAXSIZE, front = 0) a1 … ai a2 rear front
 (真满时:rear = MAXSIZE, front = 0) a1. … ai. a2. rear. front.")
95
3.2 栈、队列和串的存储结构(续) 队列的顺序存储---循环队列(二) //----------动态分配------------
#define MAXSIZE //最大队列长度 typedef struct { QElemType *base int front //指向队头元素当前位置 int rear // 指向队尾元素下一个位置 } SqQueue

96
3.2 栈、队列和串的存储结构(续) 队列的顺序存储---循环队列(三) 循环队列特点: 队空条件: *front = rear(方式一)
队满条件: *(rear+1) % MAXSIZE = front (方式一) 队满条件下的队满为真满
 % MAXSIZE = front (方式一) 队满条件下的队满为真满.")
97
3.2 栈、队列和串的存储结构(续) 队列的顺序存储---循环队列(四) Status InitQueue(SqQueue &Q) {
Q.base=(QElemType *)malloc(MAXSIZE * sizeof(QElemType)); if (! Q.base) exit(overflow); Q.front = Q.rear = 0 ; return OK; } // InitQueue Status DeQueue(SqQueue &Q,QElemType &e){ if(Q.rear= = Q.front) return ERROR; e = Q.base[Q.front]; Q.front = (Q.front +1) % MAXSIZE; return OK; } // DeQueue Status EnQueue(SqQueue &Q,QElemType e) if((Q.rear+1) % MAXSIZE = = Q.front) return ERROR; Q.base[Q.rear] = e; Q.rear = (Q.rear +1) % MAXSIZE; return OK; } // EnQueue
malloc(MAXSIZE * sizeof(QElemType)); if (! Q.base) exit(overflow); Q.front = Q.rear = 0 ; return OK; } // InitQueue. Status DeQueue(SqQueue &Q,QElemType &e){ if(Q.rear= = Q.front) return ERROR; e = Q.base[Q.front]; Q.front = (Q.front +1) % MAXSIZE; return OK; } // DeQueue. Status EnQueue(SqQueue &Q,QElemType e) if((Q.rear+1) % MAXSIZE = = Q.front) return ERROR; Q.base[Q.rear] = e; Q.rear = (Q.rear +1) % MAXSIZE; return OK; } // EnQueue.")
98
3.2 栈、队列和串的存储结构(续) 队列的链式存储---链队列(一) … ^ a2 an a1 typedef struct {
QElemType data struct QNode *next } QNode,* QueuePtr typedef struct { QueuePtr rear QueuePtr front } LinkQueue a2 an ^ a1 … q.rear .front

99
3.2 栈、队列和串的存储结构(续) 队列的链式存储---链队列(二) Status InitQueue(LinkQueue &Q) {
Q.front = Q.rear = (QueuePtr)malloc(sizeof(QNode)); if (! Q.front) exit(overflow); Q.front->next = NULL ; return OK; } // InitQueue Status DeQueue(LinkQueue &Q,QElemType &e) { if(Q.rear= = Q.front) return ERROR; p = Q.front->next; e = p->data; Q.front->next = p->next; if (Q.rear = =p) Q.rear = Q.front; free(p); return OK; } // DeQueue Status EnQueue(LinkQueue &Q,QElemType e) p = (QueuePtr) malloc (sizeof (Qnode)); if (!p) exit(overflow); p->data = e; p->next = NULL; Q.rear->next = p; Q.rear = p; return OK; } // EnQueue
malloc(sizeof(QNode)); if (! Q.front) exit(overflow); Q.front->next = NULL ; return OK; } // InitQueue. Status DeQueue(LinkQueue &Q,QElemType &e) { if(Q.rear= = Q.front) return ERROR; p = Q.front->next; e = p->data; Q.front->next = p->next; if (Q.rear = =p) Q.rear = Q.front; free(p); return OK; } // DeQueue. Status EnQueue(LinkQueue &Q,QElemType e) p = (QueuePtr) malloc (sizeof (Qnode)); if (!p) exit(overflow); p->data = e; p->next = NULL; Q.rear->next = p; Q.rear = p; return OK; } // EnQueue.")
100
3.2 栈、队列和串的存储结构(续) 串的顺序存储(一) 串顺序存储的特点: 连续存储单元静态分配 串操作中的原操作一般为“字符序列的复制”
// 串的定长顺序存储表示 #define MAXSTRLEN //最大串长度 typedef unsigned char SString[MAXSTRLEN+1] //0号单元存放串的长度 串顺序存储的特点: 连续存储单元静态分配 串操作中的原操作一般为“字符序列的复制” 截尾法处理串值序列的上越界

101
3.2 栈、队列和串的存储结构(续) 串的顺序存储(二)
Status SubString(SString &Sub,SString S, int pos, int len){ if(pos <1 || pos>S[0] || len<0 || len> S[0] – pos +1) return ERROR; Sub[1..len] = S[pos..pos+len-1]; Sub[0] =len; return OK; } // SubString Status Concat(SString &T,SString S1, SString S2){ … } // Concat
{ if(pos <1 || pos>S[0] || len<0 || len> S[0] – pos +1) return ERROR; Sub[1..len] = S[pos..pos+len-1]; Sub[0] =len; return OK; } // SubString. Status Concat(SString &T,SString S1, SString S2){ … } // Concat.")
102
3.2 栈、队列和串的存储结构(续) 串的堆分配存储(一) 串堆存储的特点: 连续存储单元动态分配 串操作中的原操作一般为“字符序列的复制”
// 串的堆存储表示 typedef struct{ char *ch; //按照串长动态分配存储区 int length; //串长 }HString //0号单元存放串的长度 串堆存储的特点: 连续存储单元动态分配 串操作中的原操作一般为“字符序列的复制” 一般不会越界

103
3.2 栈、队列和串的存储结构(续) 串的堆分配存储(二)
Status SubString(HString &Sub,HString S, int pos, int len){ if(pos <1 || pos>S.length || len<0 || len> S.length – pos +1) return ERROR; if (Sub.ch) free (Sub.ch); //释放旧空间 if (!len) {Sub.ch = NULL; Sub.length = 0;} //空子串 else{ //完整子串 Sub.ch = (char *) malloc (len*sizeof(char)); Sub.ch[0..len-1] = S[pos-1..pos+len-2]; Sub.length = len; } return OK; } // SubString
{ if(pos <1 || pos>S.length || len<0 || len> S.length – pos +1) return ERROR; if (Sub.ch) free (Sub.ch); //释放旧空间. if (!len) {Sub.ch = NULL; Sub.length = 0;} //空子串. else{ //完整子串. Sub.ch = (char *) malloc (len*sizeof(char)); Sub.ch[0..len-1] = S[pos-1..pos+len-2]; Sub.length = len; } return OK; } // SubString.")
104
3.2 栈、队列和串的存储结构(续) 串的块链存储 串块链存储的特点: 可以动态分配块,但块内仍然顺序 存储密度小,因为有指针
#define CHUNKSIZE //块大小 typedef struct Chunk{ char ch[CHUNKSIZE ] struct Chunk *next } Chunk; typedef struct { Chunk *head, *tail; int curlen; //当前长度 } LString 串块链存储的特点: 可以动态分配块,但块内仍然顺序 存储密度小,因为有指针 串一般操作复杂,要访问到块内

105
3.3 串的模式匹配算法 一般算法 int Index(SString S,SString T, int pos) { //返回子串T在主串S中第pos个 i = pos; j = 1; //字符之后的位置。若不存在, while (i<= s[0] && j<= T[0]) { //函数值位0 if (S[i] = = T[j]) { ++i; ++j; } else {i = i-j+2; j =1; } } if (j > T[0]) return i – T[0]; else return 0; } // Index 算法时间复杂度:T(n) = O(n*m) 逻辑函数为 Index(S,T,pos) S = ‘a1a2…ai…an’ T = ‘t1t2…tj…tm ’ 一般而言,m<<n 算法思路: 从主串S的第pos个字符起和模式的第一个字符比较之,若相等,继续逐个比较后续字符,否则从主串的下一个字符起再重新和模式的字符比较之。
 { //函数值位0. if (S[i] = = T[j]) { ++i; ++j; } else {i = i-j+2; j =1; } } if (j > T[0]) return i – T[0]; else return 0; } // Index. 算法时间复杂度:T(n) = O(n*m) 逻辑函数为 Index(S,T,pos) S = ‘a1a2…ai…an’ T = ‘t1t2…tj…tm ’ 一般而言,m<<n. 算法思路: 从主串S的第pos个字符起和模式的第一个字符比较之,若相等,继续逐个比较后续字符,否则从主串的下一个字符起再重新和模式的字符比较之。")
106
3.3 串的模式匹配算法(续) 模式串T= ‘abcac’ 第一趟 主串: a b a b c a b c a c b a b //i =3
模式串: a b c //j =3 第二趟 主串: a b a b c a b c a c b a b //i =2 模式串: a /j =1 第三趟 主串: a b a b c a b c a c b a b //i =7 模式串: a b c a c //j =5 第四趟 主串: a b a b c a b c a c b a b //i =4 模式串: a //j =1 第五趟 主串: a b a b c a b c a c b a b //i =5 模式串: a //j =1 第六趟 主串: a b a b c a b c a c b a b //i =11 模式串: a b c a c //j =6

107
3.3 串的模式匹配算法(续) 改进算法---思路 如何理解“部分匹配”? KMP算法思路:
主串: a c a b a a c a a b c a c 模式串: a c a a b KMP算法思路: 从主串S的第pos个字符起和模式的第一个字符比较之,若相等,继续逐个比较后续字符。当一趟匹配过程中出现字符比较不等时,不回朔i指针,而是利用已经得到的“部分匹配”的结果将模式串向右“滑动”尽可能远的一段距离后,继续进行比较。 优点: 在匹配过程中,主串的跟踪指针不回朔 时间效率达到T(n) = O(n+m)
 = O(n+m)")
108
3.3 串的模式匹配算法(续) 改进算法---原理 设主串S=‘s1s2…si…sn’, 模式串T= ‘t1t2…tj…tm’
在匹配过程中,当主串中第i个字符与模式串中第j个字符“失配”时(si不等于tj),将模式串“向右滑动”,让模式串中第k(k<j)个字符与si对齐继续比较。这时有: ‘t1t2…tk-1’ = ‘si-k+1si-k+2…si-1’ (1) 而由部分匹配成功的结果可知: ‘t1t2…tj-1’ = ‘si-j+1si-j+2…si-1’ -----(2) 由(2)式可以推知: ‘tj-k+1tj-k+2…tj-1’ = ‘si-k+1si-k+2…si-1’ -----(3) 由(1)式与(3)式可以推知: ‘t1t2…tk-1’ = ‘tj-k+1tj-k+2…tj-1’ (4)
,将模式串 向右滑动 ,让模式串中第k(k<j)个字符与si对齐继续比较。这时有: ‘t1t2…tk-1’ = ‘si-k+1si-k+2…si-1’ -----(1) 而由部分匹配成功的结果可知: ‘t1t2…tj-1’ = ‘si-j+1si-j+2…si-1’ -----(2) 由(2)式可以推知: ‘tj-k+1tj-k+2…tj-1’ = ‘si-k+1si-k+2…si-1’ -----(3) 由(1)式与(3)式可以推知: ‘t1t2…tk-1’ = ‘tj-k+1tj-k+2…tj-1’ -----(4)")
109
3.3 串的模式匹配算法(续) 改进算法---Next函数定义 设主串S=‘s1s2…si…sn’, 模式串T= ‘t1t2…tj…tm’
令next[j] = k,表示当模式串中第j个字符与主串中相应字符“失配”时,在模式中需重新和主串中该字符进行比较的字符的位置。根据其语义,定义如下: 0 当j = 1时 //相当于主串中i指针推进一个位置 Next[j] = Max {k | 1<k<j 且 ‘t1t2…tk-1’ = ‘tj-k+1tj-k+2…tj-1’ } // 1 其他情况 保证得到第一个“配串” Next函数值仅取决于模式串本身的结构而与相匹配的主串无关 j 模式串 a b a a b c a c next[j] j 模式串 a b a a b c a c next[j]

110
3.3 串的模式匹配算法(续) 改进算法---匹配过程 j 1 2 3 4 5 6 7 8 模式串 a b a a b c a c
next[j] 改进算法---匹配过程 第一趟 主串: a c a b a a b a a b c a c a a b c //i =2 模式串: a b //j =2, next[2]=1 第二趟 主串: a c a b a a b a a b c a c a a b c //i =2 模式串: a //j =1, next[1]=0 第三趟 主串: a c a b a a b a a b c a c a a b c //i =8 模式串: a b a a b c //j =6, next[6]=3 第四趟 主串: a c a b a a b a a b c a c a a b c //i =14 模式串: (a b) a a b c a c //j =9
 a a b c a c //j =9.")
111
3.3 串的模式匹配算法(续) 改进算法---KMP算法
int Index_KMP(SString S,SString T, int pos) { //返回子串T在主串S中第pos个字符之后的位置。若不存在,函数值为0 i = pos; j = 1; while (i<= s[0] && j<= T[0]) { if ( j = = 0 | S[i] = = T[j]) { ++i; ++j; } else j =next[j]; } if (j > T[0]) return i – T[0]; else return 0; } // Index_KMP 算法时间复杂度:T(n) = O(n+m)
 { //返回子串T在主串S中第pos个字符之后的位置。若不存在,函数值为0. i = pos; j = 1; while (i<= s[0] && j<= T[0]) { if ( j = = 0 | S[i] = = T[j]) { ++i; ++j; } else j =next[j]; } if (j > T[0]) return i – T[0]; else return 0; } // Index_KMP. 算法时间复杂度:T(n) = O(n+m)")
112
3.3 串的模式匹配算法(续) 改进算法---Next函数算法 递归法: j 1 2 3 4 5 6 7 8
设next[j] = k,则有: ‘t1t2…tk-1’ = ‘tj-k+1tj-k+2…tj-1’ (2) 则考察next[j+1]: * 若tk = tj ,有: ‘t1t2…tk-1 tk’ = ‘tj-k+1tj-k+2…tj’ (3) 即 next[j+1] = k+1=next[j] (4) * 若tk != tj ,表明:‘t1t2…tk-1 tk’ != ‘tj-k+1tj-k+2…tj’,又是一个模式匹配问题。这时由于tk != tj ,设next[k] = k’,则又是两种情况: tk’= tj以及tk’ != tj。对于tk’= tj,有:‘t1t2…tk’’ = ‘tj-k’+1tj-k’+2…tj-1 tj’ (1<k’<k<j ) -----(5) 即 next[j+1] = k’+1=next[k] (6) 对于tk’ != tj,依次类推,直至tj和模式串中某个字符匹配成功或者不存在任何k’满足(5)式,则next[j+1] = (7) 改进算法---Next函数算法 j 模式串 a b a a b c a c next[j] 已知前6个字符的next函数值,依次求next[7]和next[8] 对于求next[7],即j+1=7,j=6。已知next[6]=3,即k=3。 因为t6 != t3 ,而next[3]=1,即k’ =1,考察而知,又有 t6 != t1, 所以,不存在k’ 满足匹配式,则next[j+1]=1,即next[7]=1 对于求next[8],即j+1=8,j=7。已知next[7]=1,即k=1。 考察而知t7 = t1 ,而next[3]=1,即k’ =1考察而知,又有 t6 != t1, 所以,next[8]=next[7+1]=next[7]+1=1+1=2
 则考察next[j+1]: * 若tk = tj ,有: ‘t1t2…tk-1 tk’ = ‘tj-k+1tj-k+2…tj’ -----(3) 即 next[j+1] = k+1=next[j] (4) * 若tk != tj ,表明:‘t1t2…tk-1 tk’ != ‘tj-k+1tj-k+2…tj’,又是一个模式匹配问题。这时由于tk != tj ,设next[k] = k’,则又是两种情况: tk’= tj以及tk’ != tj。对于tk’= tj,有:‘t1t2…tk’’ = ‘tj-k’+1tj-k’+2…tj-1 tj’ (1<k’<k<j ) -----(5) 即 next[j+1] = k’+1=next[k] (6) 对于tk’ != tj,依次类推,直至tj和模式串中某个字符匹配成功或者不存在任何k’满足(5)式,则next[j+1] = (7) 改进算法---Next函数算法. j 模式串 a b a a b c a c. next[j] 已知前6个字符的next函数值,依次求next[7]和next[8] 对于求next[7],即j+1=7,j=6。已知next[6]=3,即k=3。 因为t6 != t3 ,而next[3]=1,即k’ =1,考察而知,又有 t6 != t1, 所以,不存在k’ 满足匹配式,则next[j+1]=1,即next[7]=1. 对于求next[8],即j+1=8,j=7。已知next[7]=1,即k=1。 考察而知t7 = t1 ,而next[3]=1,即k’ =1考察而知,又有 t6 != t1, 所以,next[8]=next[7+1]=next[7]+1=1+1=2.")
113
3.3 串的模式匹配算法(续) 改进算法---Next函数算法
void get_next(SString T, int &next[ ]) { //求模式串T的next函数值并存入数组next j = 1; next[1] = 0; k = 0; //初始化 while (j <= T[0]) { //求出每个字符的next值 if (k = = 0 || T[j] = = T[k]) { ++j; ++k; next[j] = k;} else k =next[k]; } } // get_next 算法时间复杂度:O(m) 对初值情况的处理 对tk = tj 情况的处理 对tk != tj 情况的处理 考察下一个字符
 { //求模式串T的next函数值并存入数组next. j = 1; next[1] = 0; k = 0; //初始化. while (j <= T[0]) { //求出每个字符的next值. if (k = = 0 || T[j] = = T[k]) { ++j; ++k; next[j] = k;} else k =next[k]; } } // get_next. 算法时间复杂度:O(m) 对初值情况的处理. 对tk = tj 情况的处理. 对tk != tj 情况的处理. 考察下一个字符.")
114
3.3 串的模式匹配算法(续) 改进算法---改进的Next函数
void get_nextval(SString T, int &nextval[ ]) { j = 1; nextval[1] = 0; k= 0; while (j <= T[0]) { if (k = = 0 || T[j] = = T[k]) { ++j; ++k; if (T[j] != T[k]) nextval[j] = k; else nextval[j] = nextval[k];// 改进之处 } else k =nextval[k]; } // get_nextval j 模式串 a a a a b next[j] j 模式串 a a a a b next[j] Nextval[j] 以避免不必要的多一次比较
 { j = 1; nextval[1] = 0; k= 0; while (j <= T[0]) { if (k = = 0 || T[j] = = T[k]) { ++j; ++k; if (T[j] != T[k]) nextval[j] = k; else nextval[j] = nextval[k];// 改进之处. } else k =nextval[k]; } // get_nextval. j 模式串 a a a a b. next[j] j 模式串 a a a a b. next[j] Nextval[j] 以避免不必要的多一次比较.")
115
3.4 栈、队列和串的应用 栈的应用领域 操作以“后进先出”为特征 数值转换、括号匹配检验、行编辑程序、迷宫求解、表达式求值等
数值转换中主要利用栈实现按照从高位到低位输出转换后的数值。 操作以“后进先出”为特征 数值转换、括号匹配检验、行编辑程序、迷宫求解、表达式求值等 栈在程序调用中的作用 栈与递归 括号匹配检验中利用栈来检验括号间是否以合法的嵌套层次成对出现。 迷宫求解中,利用栈保存从入口到当前位置的路径,当一趟“试探”失败后可以回退到当前位置(本质是在树中寻找合理路径)。 行编辑程序中利用栈回退刚刚输入到缓冲区中的字符或者字符串。
。 行编辑程序中利用栈回退刚刚输入到缓冲区中的字符或者字符串。")
116
3.4 栈、队列和串的应用(续) 函数调用中栈的应用 调用函数和被调用函数之间的链接和信息交换通过栈来进行 调用之前的三项工作:
*将实参、返回地址等信息传递给被调用函数保存; *为被调用函数的局部变量分配存储区; *将控制转移到被调函数入口。 调用之后的三项工作: *保存被调用函数的执计算结果; *释放被调函数的数据区; *依照返回地址将控制转移到调用函数。 当多个函数构成嵌套调用时,函数之间的信息传递和控制转移必须通过“栈”来实现,因为存在“后调用、先返回”的规则。 具体做法:系统对整个程序运行时所需的数据空间用栈进行管理。当存在函数调用时,就为它在栈顶分配一个存储区,放置着当前调用过程中的控制转移信息和数据信息;当函数运行完成,就释放这段存储区。当前正在运行的函数的数据区在栈顶。

117
3.4 栈、队列和串的应用(续) … 2, i,x,y 1, m,n,i … m,n top top top top top
int first(int s, int t); int second(int d); int main(){ int m, n; … first(m,n); 1: … } int first(int s, int t){ int i; second(i); 2: … } int second(int d){ int x,y; … } … … m,n top top 2, i,x,y top top 1, m,n,i top
; int second(int d); int main(){ int m, n; … first(m,n); 1: … } int first(int s, int t){ int i; second(i); 2: … } int second(int d){ int x,y; … } … … m,n. top. top. 2, i,x,y. top. top. 1, m,n,i. top.")
118
3.4 栈、队列和串的应用(续) 递归中栈的应用 类似于函数嵌套调用,调用函数与被调函数是同一个函数。调用关系用“层次”来表达。设调用递归函数的主函数为第0层,则第一次调用进入第1层,依次,第i层递归调用本函数进入第i+1层。返回时,按照“后调用、先返回”的原则。 具体做法:系统设立一个“递归工作栈”作为递归函数运行期间使用的数据存储区;每一层递归所需要的控制转移信息和数据信息构成一个“工作记录”,包括:实参、局部变量以及上一层的返回地址。当前正在运行层的工作记录在栈顶,称为“活动记录”,指示活动记录的栈顶指针为“当前环境指针”。

119
3.4 栈、队列和串的应用(续) 队列的应用---离散事件模拟 串的应用---文本编辑和建立词索引表
 队列的应用---离散事件模拟 串的应用---文本编辑和建立词索引表")
120
教学内容---第四章 1.绪论 2.线性表 3.栈、队列和串 4.数组 5.广义表 6.树和二叉树 7.图 8.动态存储管理 9.查找
10.内部排序 11.外部排序 12.文件

121
4.1数组的逻辑结构 数组的抽象数据类型定义 查找 ADT Array {
数据对象:ji = 0,…,bi – 1, i = 1,2,…,n D={a j1 j2 … jn | a j1 j2 … jn属于ElemSet, n(>0)为数组维数, ji 为数组元素的第i维下标, bi为第i维的长度 } 数据关系:R = {R1,R2,…,Rn} Ri={< a j1 … ji… jn , a j1 … ji+1… jn >| 0<= jk <= bk –1, 1<=k<=n, 且 k != i, 0<= ji <= bi –2, a j1 … ji… jn , a j1 … ji+1… jn属于D, i =2,3, …, n} 基本操作: InitArray(&A,n,bound1,…,boundn) DestroyArray(&A) Value(A,&e,index1,…indexn) Assign(&A,e,index1,…) }ADT Array 查找
为数组维数, ji 为数组元素的第i维下标, bi为第i维的长度 } 数据关系:R = {R1,R2,…,Rn} Ri={< a j1 … ji… jn , a j1 … ji+1… jn >| 0<= jk <= bk –1, 1<=k<=n, 且 k != i, 0<= ji <= bi –2, a j1 … ji… jn , a j1 … ji+1… jn属于D, i =2,3, …, n} 基本操作: InitArray(&A,n,bound1,…,boundn) DestroyArray(&A) Value(A,&e,index1,…indexn) Assign(&A,e,index1,…) }ADT Array. 查找.")
122
4.2数组的存储结构 数组的顺序存储 内涵: 数组的顺序存储指用一组地址连续的存储 单元按照某种规则存放数组中的数据元素。 特点:
* 存储单元地址连续(需要一段连续空间) * 存储规则(以行(列)为主序)决定元素 实际存储位置 * 随机存取 * 存储密度为大(100%)
 * 存储规则(以行(列)为主序)决定元素 实际存储位置. * 随机存取. * 存储密度为大(100%)")
123
4.2数组的存储结构(续) 随机存取 BASIC、PL/1、COBOL、PASCAL、C语言都采用以行序为主序;而FORTRAN语言采用以列序为主序。(以后不做说明,均采用以行序为主序。) 对于二维数组A[b1,b2],设每个元素占L个存储单元,则有: A中任一元素ai,j的存储位置: LOC(i,j)=LOC(0,0)+(b2*i+j)*L 对于n维数组A[b1,b2,…,bn],设每个元素占L个存储单元,则有: A中任一元素a j1 j2 … jn的存储位置: LOC(j1, j2 ,… , jn)=LOC(0,0,…0)+(b2*…*bn* j1 +b3*…*bn* j2 +…+ bn* jn-1 + jn)*L 上式称为n维数组的映象函数。位置是下标的函数,所以随机存取。
![4.2数组的存储结构(续) 随机存取. BASIC、PL/1、COBOL、PASCAL、C语言都采用以行序为主序;而FORTRAN语言采用以列序为主序。(以后不做说明,均采用以行序为主序。) 对于二维数组A[b1,b2],设每个元素占L个存储单元,则有:](http://slidesplayer.com/slide/11606863/62/images/123/4.2%E6%95%B0%E7%BB%84%E7%9A%84%E5%AD%98%E5%82%A8%E7%BB%93%E6%9E%84%EF%BC%88%E7%BB%AD%EF%BC%89+%E9%9A%8F%E6%9C%BA%E5%AD%98%E5%8F%96.+BASIC%E3%80%81PL%2F1%E3%80%81COBOL%E3%80%81PASCAL%E3%80%81C%E8%AF%AD%E8%A8%80%E9%83%BD%E9%87%87%E7%94%A8%E4%BB%A5%E8%A1%8C%E5%BA%8F%E4%B8%BA%E4%B8%BB%E5%BA%8F%EF%BC%9B%E8%80%8CFORTRAN%E8%AF%AD%E8%A8%80%E9%87%87%E7%94%A8%E4%BB%A5%E5%88%97%E5%BA%8F%E4%B8%BA%E4%B8%BB%E5%BA%8F%E3%80%82%EF%BC%88%E4%BB%A5%E5%90%8E%E4%B8%8D%E5%81%9A%E8%AF%B4%E6%98%8E%EF%BC%8C%E5%9D%87%E9%87%87%E7%94%A8%E4%BB%A5%E8%A1%8C%E5%BA%8F%E4%B8%BA%E4%B8%BB%E5%BA%8F%E3%80%82%EF%BC%89+%E5%AF%B9%E4%BA%8E%E4%BA%8C%E7%BB%B4%E6%95%B0%E7%BB%84A%5Bb1%2Cb2%5D%EF%BC%8C%E8%AE%BE%E6%AF%8F%E4%B8%AA%E5%85%83%E7%B4%A0%E5%8D%A0L%E4%B8%AA%E5%AD%98%E5%82%A8%E5%8D%95%E5%85%83%EF%BC%8C%E5%88%99%E6%9C%89%EF%BC%9A.jpg "A中任一元素ai,j的存储位置: LOC(i,j)=LOC(0,0)+(b2*i+j)*L. 对于n维数组A[b1,b2,…,bn],设每个元素占L个存储单元,则有: A中任一元素a j1 j2 … jn的存储位置: LOC(j1, j2 ,… , jn)=LOC(0,0,…0)+(b2*…*bn* j1 +b3*…*bn* j2 +…+ bn* jn-1 + jn)*L. 上式称为n维数组的映象函数。位置是下标的函数,所以随机存取。")
124
4.2数组的存储结构(续) 数组顺序存储的数据类型描述 //----------数组的顺序存储表示------------
typedef struct { ElemType *base //存储空间基址 int dim //数组维数 int *bounds //数组维界基址 int *constants //数组映象函数常量基址 } Array

125
4.3矩阵的压缩结构 基本概念和术语 压缩存储:为多个值相同的元只分配一个存储空间;对零元不分配空间。
特殊矩阵:值相同的元或零元在矩阵中的分布有一定的规律,则这类矩阵为特殊矩阵。 稀疏因子:假设在m*n矩阵中非零元个数为t,则称t/(m*n)为稀疏因子。 稀疏矩阵:值相同的元或零元在矩阵中的分布没有一定的规律且稀疏因子小于等于0.05时,称这类矩阵为稀疏矩阵。 特殊矩阵和稀疏矩阵都需要压缩存储。
为稀疏因子。 稀疏矩阵:值相同的元或零元在矩阵中的分布没有一定的规律且稀疏因子小于等于0.05时,称这类矩阵为稀疏矩阵。 特殊矩阵和稀疏矩阵都需要压缩存储。")
126
4.3矩阵的压缩结构(续) 特殊矩阵 n阶对称矩阵A[n,n]:
aij = aji 1<=i,j<=n,用sa[n(n+1)/2]压缩存储。设sa[k]中存放着元素aij ,则有:k=i(i-1)/2+j-1 (当i>=j); k=j(j-1)/2+i-1 (当i<j)。 a11 a12 … a1n a21 a22 a23 … a2n …… ai,i … ain … an … an,n an,n n阶三角矩阵A[n,n]: *下三角矩阵:aij = c , i<j; *上三角矩阵:aij = c , i>j; 用sa[n(n+1)/2+1]压缩存储。对下三角矩阵设,sa[k]中存放着元素aij ,则有:k=i(i-1)/2+j-1 (i>=j);k= n(n+1)/2+1(i<j)。
![4.3矩阵的压缩结构(续) 特殊矩阵 n阶对称矩阵A[n,n]:](http://slidesplayer.com/slide/11606863/62/images/126/4.3%E7%9F%A9%E9%98%B5%E7%9A%84%E5%8E%8B%E7%BC%A9%E7%BB%93%E6%9E%84%EF%BC%88%E7%BB%AD%EF%BC%89+%E7%89%B9%E6%AE%8A%E7%9F%A9%E9%98%B5+n%E9%98%B6%E5%AF%B9%E7%A7%B0%E7%9F%A9%E9%98%B5A%5Bn%2Cn%5D%3A.jpg "aij = aji 1<=i,j<=n,用sa[n(n+1)/2]压缩存储。设sa[k]中存放着元素aij ,则有:k=i(i-1)/2+j-1 (当i>=j); k=j(j-1)/2+i-1 (当i<j)。 a11 a12 … a1n. a21 a22 a23 … a2n. …… ai,i … ain. … an1 … an,n-1 an,n. n阶三角矩阵A[n,n]: *下三角矩阵:aij = c , i<j; *上三角矩阵:aij = c , i>j; 用sa[n(n+1)/2+1]压缩存储。对下三角矩阵设,sa[k]中存放着元素aij ,则有:k=i(i-1)/2+j-1 (i>=j);k= n(n+1)/2+1(i<j)。")
127
4.3矩阵的压缩结构(续) a11 a12 0 … a21 a22 a23 0 … 0 …… ai,j 0 … 0 … an-1,n
0 …… ai,j … 0 … an-1,n 0 … an,n an,n n阶对角矩阵A[n,n],如三对角矩阵:除主对角线和两条副对角线之外,其他元素都为零。用线性空间sa[0..3n-1]压缩存储。设sa[k]中存放着元素aij ,则有: k=3(i-1)-1+j-(i-1)=2i+j-3 (|i-j|<=1) i = (k+1)/3 + 1 (0<=k<=3n-1); j = k-2i+3= k- 2((k+1)/3)+1
-1+j-(i-1)=2i+j-3 (|i-j|<=1) i = (k+1)/3 + 1 (0<=k<=3n-1); j = k-2i+3= k- 2((k+1)/3)+1.")
128
4.3矩阵的压缩结构(续) 稀疏矩阵的逻辑结构抽象---三元组表 矩阵中的元素一般可由一个三元组(i,j, aij ) 唯一确定。
稀疏矩阵可由表示非零元的三元组及其行列数唯一确定。 例:矩阵M对应的数据结构 为如下线性表(以行序为主 序排列): ((1,2,12),(1,3,9),(3,1,-3),(3,6,14), (4,3,24),(5,2,18),(6,1,15),(6,4,-7)) 行数为6;列数为7 M =
: ((1,2,12),(1,3,9),(3,1,-3),(3,6,14), (4,3,24),(5,2,18),(6,1,15),(6,4,-7)) 行数为6;列数为 M =")
129
4.3矩阵的压缩结构(续) 三元组顺序表 //----------稀疏矩阵的三元组顺序表存储表示------------
#define MAXSIZE //非零元最大个数 typedef struct { int i,j; //非零元的行、列下标 ElemType e; }Triple; typedef struct{ Triple data[MAXSIZE+1 ] //data[0]未用,行序为主序 int mu,nu,tu; //矩阵的行、列和非零元数 }TSMatrix;

130
4.3矩阵的压缩结构(续) 三元组顺序表上矩阵转置运算 0 12 9 0 0 0 0 0 0 0 0 0 0 0
M6X7= 三元组顺序表上矩阵转置运算 三元组表描述的稀疏矩阵转置基本步骤: *将矩阵的行列值相互交换; *将每个三元组中的i和j相互调换; *重排三元组之间的次序(保证转 置后的矩阵的三元组顺序表仍然 以行序为主序存储) T7X6=
 T7X6=")
131
4.3矩阵的压缩结构(续) 三元组顺序表上矩阵转置运算 1 2 12 3 9 -3 6 14 24 18 15 -7 1 3 -3 6 15
M.data 1 3 -3 2 6 15 12 4 5 18 9 24 7 -7 8 14 T.data

132
4.3矩阵的压缩结构(续) 三元组顺序表上矩阵转置运算 “重排三元组之间的次序”有两种处理手法,对应着两种处理算法。 第一种:
按照T.data中三元组的次序依次在M.data中找到相应的三元组进行转置。 按照矩阵M的列序来进行转置,为了找到M的每一列中所有非零元素,须对三元组表M.data从第一行起整个扫描一遍,由于M.data是以M的行序为主序来存放每个非零元,由此得到的恰是T.data应有的顺序。

133
4.3矩阵的压缩结构(续) M.data M.mu=6 M.nu=7 M.tu=8 T.data T.mu=7 T.nu=6 T.tu=8 1 2 12 3 9 -3 4 6 14 5 24 18 7 15 8 -7 1 3 -3 2 6 15 2 3 1 12 4 5 18 3 5 1 9 6 4 24 4 7 6 -7 6 8 3 14

134
4.3矩阵的压缩结构(续) Status TransposeSMatrix(TSMatrix M,TSMatrix &T) {
T.mu = M.nu; T.nu =M.mu; T.tu = M.tu; if(T.tu) { q =1; for (col =1; col <=M.nu; ++col) for (p =1;p<=M.tu; ++p) if (M.data[p].j = = col){ T.data[q].i = M.data[p].j; T.data[q].j = M.data[p].i; T.data[q].e = M.data[p].e; ++q; } } return OK; } // 算法时间复杂度:O(nu*tu),适合tu<<mu*nu的情况 对M中每一列,扫描一遍所有非零元
 { q =1; for (col =1; col <=M.nu; ++col) for (p =1;p<=M.tu; ++p) if (M.data[p].j = = col){ T.data[q].i = M.data[p].j; T.data[q].j = M.data[p].i; T.data[q].e = M.data[p].e; ++q; } } return OK; } // 算法时间复杂度:O(nu*tu),适合tu<<mu*nu的情况. 对M中每一列,扫描一遍所有非零元.")
135
4.3矩阵的压缩结构(续) 三元组顺序表上矩阵转置运算 1 2 12 3 9 -3 6 14 24 18 15 -7 4 5 7 8
M.data T.data

136
4.3矩阵的压缩结构(续) 第二种: 按照M.data中三元组的次序进行转置,并将转置后的三元组置入T.data中恰当的位置。
预先确定矩阵M中每一列的第一个非零元在T.data中应有的位置,然后在对M.data中的三元组依次做转置时,便可直接放到T.data中恰当的位置上。 转置前,先求得M的每一列中非零元的个数,进而求得每一列第一个非零元在T.data中应有的位置。 具体做法:num[col]放置矩阵M第col列中非零元的个数;cpot[col]指示T中第col列的第一个非零元在T.data中的恰当位置。有: cpot[1] = 1; cpot[col] = cpot[col-1] + num[col-1] 2<=col<=M.nu

137
2 num 1 3 4 7 5 6 1 cpot 3 5 7 8 9 2 3 5 4 6 7 8 9 M.data M.mu=6 M.nu=7 M.tu=8 1 2 3 4 5 6 7 8 T.data T.mu=7 T.nu=6 T.tu=8 1 2 12 3 9 -3 4 6 14 5 24 18 7 15 8 -7 1 3 -3 1 2 6 15 2 3 1 12 2 4 5 18 3 5 1 9 3 6 4 24 4 7 6 -7 6 8 3 14

138
4.3矩阵的压缩结构(续) Status FastTransposeSMatrix(TSMatrix M,TSMatrix &T) {
T.mu = M.nu; T.nu =M.mu; T.tu = M.tu; if(T.tu) { for(col =1;col<=M.nu; ++col) num[col] =0; for(t =1; t<=M.tu; ++t) ++num[M.data[t].j]; cpot[1]=1; for (col =2;col<=M.nu;++col) cpot[col]=copt[col-1]+num[col-1]; for (p =1;p<=M.tu; ++p) { col=M.data[p].j; q=cpot[col]; T.data[q].i = M.data[p].j; T.data[q].j = M.data[p].i; T.data[q].e = M.data[p].e; ++cpot[col]; } } return OK; } // 算法时间复杂度:O(nu+tu) 统计M中每一列的非零元个数 初始化M中每一列第一个非零元应该在T中的位置 M中col列上下一个非零元应该在T中的位置
 { for(col =1;col<=M.nu; ++col) num[col] =0; for(t =1; t<=M.tu; ++t) ++num[M.data[t].j]; cpot[1]=1; for (col =2;col<=M.nu;++col) cpot[col]=copt[col-1]+num[col-1]; for (p =1;p<=M.tu; ++p) { col=M.data[p].j; q=cpot[col]; T.data[q].i = M.data[p].j; T.data[q].j = M.data[p].i; T.data[q].e = M.data[p].e; ++cpot[col]; } } return OK; } // 算法时间复杂度:O(nu+tu) 统计M中每一列的非零元个数. 初始化M中每一列第一个非零元应该在T中的位置. M中col列上下一个非零元应该在T中的位置.")
139
4.3矩阵的压缩结构(续) 三元组十字链表 //----------稀疏矩阵的三元组十字链表存储表示------------
typedef struct OLNode{ int i,j; //非零元的行、列下标 ElemType e; struct OLNode *right, *down //行表与列表的后继指针 } OLNode *OLink; typedef struct { OLink *rhead, *chead //行列链表头指针向量基址 int mu,nu,tu; //矩阵的行、列和非零元数 }CrossList;

140
4.3矩阵的压缩结构(续) 三元组十字链表 3 0 0 5 M= 0 -1 0 0 2 0 0 0 M.rhead 3 1 2 ^ -1 4
M= 三元组十字链表 M.rhead 3 1 2 ^ -1 4 5 M.chead

141
教学内容---第五章 1.绪论 2.线性表 3.栈、队列和串 4.数组 5.广义表 6.树和二叉树 7.图 8.动态存储管理 9.查找
10.内部排序 11.外部排序 12.文件

142
5.1广义表的逻辑结构 基本概念和术语 广义表:n个数据元素的有限序列,数据元素可以是单个元素,也可以是广义表。
LS =(a1,…, ai, ai+1,…, an) 表长为n 广义表:n个数据元素的有限序列,数据元素可以是单个元素,也可以是广义表。 表长:广义表中最高层次上元素的个数n(n>=0)。 深度:广义表中嵌套的层次数,称为表的深度。 空表:n=0时的广义表称为空表,记为:LS = ( )。 原子:广义表中是单个元素的数据元素。 子表:广义表中是广义表的数据元素。 表头:非空广义表的第一个元素为表头(Head)。 表尾:非空广义表中除第一个元素之外的其他元素组成的表称为表尾(Tail)。
 表长为n. 广义表:n个数据元素的有限序列,数据元素可以是单个元素,也可以是广义表。 表长:广义表中最高层次上元素的个数n(n>=0)。 深度:广义表中嵌套的层次数,称为表的深度。 空表:n=0时的广义表称为空表,记为:LS = ( )。 原子:广义表中是单个元素的数据元素。 子表:广义表中是广义表的数据元素。 表头:非空广义表的第一个元素为表头(Head)。 表尾:非空广义表中除第一个元素之外的其他元素组成的表称为表尾(Tail)。")
143
5.1广义表的逻辑结构(续) 广义表的三大特性 A = ( ) B = (a,( ),(e),(a,(b,c,d))) C = (c,C)
表长:4; 深度:3; 表头:Head(B) = a; 表尾:Tail(B) = (( ),(e),(a,(b,c,d)) ) 原子:a; 子表: ( ),(e),(a,(b,c,d)) A为空表 A = ( ) B = (a,( ),(e),(a,(b,c,d))) C = (c,C) 表长:2; 深度:无穷; 表头:Head(C) = c; 表尾:Tail(C) = (C) 原子:c; 子表: C 层次性 共享性 递归性
 = a; 表尾:Tail(B) = (( ),(e),(a,(b,c,d)) ) 原子:a; 子表: ( ),(e),(a,(b,c,d)) A为空表. A = ( ) B = (a,( ),(e),(a,(b,c,d))) C = (c,C) 表长:2; 深度:无穷; 表头:Head(C) = c; 表尾:Tail(C) = (C) 原子:c; 子表: C. 层次性. 共享性. 递归性.")
144
5.1广义表的逻辑结构(续) 广义表的抽象数据类型定义 ADT GList {
数据对象:D={ai | ai属于AtomSet 或者属于GList, i = 1,2, … ,n, n>=0} 数据关系:R1={< ai-1, ai >| ai-1, ai属于D, i =2,3, …, n} 基本操作: InitGList(&L) DestroyGList(&L) ClearGList(&L,S) GListLength(L) GListDepth(L) GetHead(L) GetTail(L) …… }ADT GList 表头 表尾
 DestroyGList(&L) ClearGList(&L,S) GListLength(L) GListDepth(L) GetHead(L) GetTail(L) …… }ADT GList. 表头. 表尾.")
145
5.2广义表的存储结构 广义表的链式存储---头尾链表 tag = 1 hp tp tag = 0 atom 表结点 原子结点
// 广义表的头尾链表存储表示 typedef enum {ATOM,LIST} ElemTag; //ATOM = = 0,//LIST = = 1 typedef struct GLNode{ ElemTag tag; //公共部分,区分原子结点与表结点 union { AtomType atom;; //AtomType由用户定义 struct { struct GLNode *hp, *tp;}ptr; //ptr.hp、ptr.tp指头与尾} *GList;

146
5.2广义表的存储结构(续) 头尾链表示例 对广义表:E = (a,(b,c,d)),其头尾链表为: E 1 1 ^ a 1 1 1 ^ b
a 1 1 1 ^ b c d

147
5.2广义表的存储结构(续) 广义表的链式存储---扩展线性链表 tag = 1 hp tp 表结点 原子结点 tag = 0 atom
// 广义表的扩展线性链表存储表示 typedef enum {ATOM,LIST} ElemTag; //ATOM = = 0,//LIST = = 1 typedef struct GLNode{ ElemTag tag; //公共部分,区分原子结点与表结点 union { AtomType atom;; //AtomType由用户定义 struct GLNode *hp; } //hp为表结点的表头指针\ struct GLNode *tp; //指向同层次的下一个元素结点} *GList;

148
5.2广义表的存储结构(续) 扩展线性链表示例 对广义表:E = (a,(b,c,d)),其扩展线性链表为: E 1 ^ a 1 ^ b c
a 1 ^ b c d ^

149
教学内容---第六章 1.绪论 2.线性表 3.栈、队列和串 4.数组 5.广义表 6.树和二叉树 7.图 8.动态存储管理 9.查找
10.内部排序 11.外部排序 12.文件

150
6.1树的逻辑结构 基本概念和术语 树:树T是n个结点的有限集。非空树中: (1)有且只有一个特定的称为根(Root)的结点;
(2)当n>1时,其余结点可分为m(m>0)各互不相交 的有限集T1,T2,…,Tm,其中每一个集合本身又是 一棵树,并且称为根的子树(SubTree)。 树的结点:一个数据元素和指向其子树的分支。 结点的度:结点拥有的子树数。 终端结点(或叶子):度为0的结点。 非终端结点(或分支结点、或内部结点) :度不为0的结点。 树的度:树内各结点的度的最大值。 (结点的)孩子:结点的子树的根。
当n>1时,其余结点可分为m(m>0)各互不相交 的有限集T1,T2,…,Tm,其中每一个集合本身又是 一棵树,并且称为根的子树(SubTree)。 树的结点:一个数据元素和指向其子树的分支。 结点的度:结点拥有的子树数。 终端结点(或叶子):度为0的结点。 非终端结点(或分支结点、或内部结点) :度不为0的结点。 树的度:树内各结点的度的最大值。 (结点的)孩子:结点的子树的根。")
151
6.1树的逻辑结构(续) 基本概念和术语 (结点的)双亲:其孩子为该结点的结点。 兄弟:同一个双亲的孩子之间互称双亲。
(结点的)祖先:从根到该结点所经分支上的所有结点。 (结点的)子孙:以该结点为根的子树中的任一结点。 (结点的)层次:从根开始定义,根为第一层,根的孩子为第二层。若某结点在第L层,则其子树的根在第L+1层。 堂兄弟:其双亲在同一层的结点互为堂兄弟。 树的深度(或高度):树中结点的最大层次。 有序树:树中结点的各子树从左至右有次序。 无序树:树中结点的各子树无左右次序。 森林(Forest):m棵互不相交的树的集合。
祖先:从根到该结点所经分支上的所有结点。 (结点的)子孙:以该结点为根的子树中的任一结点。 (结点的)层次:从根开始定义,根为第一层,根的孩子为第二层。若某结点在第L层,则其子树的根在第L+1层。 堂兄弟:其双亲在同一层的结点互为堂兄弟。 树的深度(或高度):树中结点的最大层次。 有序树:树中结点的各子树从左至右有次序。 无序树:树中结点的各子树无左右次序。 森林(Forest):m棵互不相交的树的集合。")
152
6.1树的逻辑结构(续) 树的性质及树的表示 树的性质: 递归性 层次性 树的表示形式: 树形表示 集合嵌套表示 广义表形式表示 凹入表示
 树的性质及树的表示 树的性质: 递归性 层次性 树的表示形式: 树形表示 集合嵌套表示 广义表形式表示 凹入表示")
153
6.1树的逻辑结构(续) 树的抽象数据类型 ADT Tree {
数据对象:D={ai | ai属于ElemSet, i = 1,2, … ,n, n>=0} 数据关系:R: 若D为空集,则称为空树; 若D仅含有一个数据元素,则R为空集,否则R={H},H为二元关系: (1)在D中存在唯一的称为根的数据元素root,它在关系H下无前驱; (2)若D-{root}不为空,则存在D-{root}的一个划分D1,D2,…,Dm (m>0),对任意j != k(1<=j,k<=m)有Dj与Dk交集为空,且对任意的 i(1<=i<=m),唯一存在数据元素Xi属于Di,有<root,xi>属于H; (3)对应于D-{root}的划分,H – {<root,x1>,…, <root,xm>}有唯一的一 个划分H1,H2,…,Hm(m>0),对任意j != k(1<=j,k<=m)有Hj与Hk交集 为空,且对任意的 i(1<=i<=m), Hi 是Di上的二元关系,(Di,{Hi }) 是一棵符合本定义的树,称为根root的子树。 基本操作:P: InitTree(&T); DestroyTree(&T); …; TraverseTree(T,Visit()) }ADT Tree
在D中存在唯一的称为根的数据元素root,它在关系H下无前驱; (2)若D-{root}不为空,则存在D-{root}的一个划分D1,D2,…,Dm. (m>0),对任意j != k(1<=j,k<=m)有Dj与Dk交集为空,且对任意的. i(1<=i<=m),唯一存在数据元素Xi属于Di,有<root,xi>属于H; (3)对应于D-{root}的划分,H – {<root,x1>,…, <root,xm>}有唯一的一. 个划分H1,H2,…,Hm(m>0),对任意j != k(1<=j,k<=m)有Hj与Hk交集 为空,且对任意的 i(1<=i<=m), Hi 是Di上的二元关系,(Di,{Hi }) 是一棵符合本定义的树,称为根root的子树。 基本操作:P: InitTree(&T); DestroyTree(&T); …; TraverseTree(T,Visit()) }ADT Tree.")
154
6.2树的存储结构 多叉链表法 多叉链表存储的、度为k的、结点数为n的树中,空指针域个数为: n*k-(n-1) = n(k-1)+1
data link1 link2 结点 … Linkk // 用结构指针描述 typedef struct MultiLNode{ ElemType data //数据域 struct MultiLNode *link1 //第1个指针域 struct MultiLNode *link2 //第2个指针域 ……. struct MultiLNode *linkk //第k个指针域 } MultiLNode, *MultiLinkTree

155
6.2树的存储结构(续) 双亲表示法 //----------树的双亲存储表示------------
#define MAX_TREE_SIZE 100 typedef struct PTNode{ TElemType data; //树结点数据域 int parent //双亲位置域 } PTNode; typedef struct { PTNode nodes[MAX_TREE_SIZE ]; int n; //结点数 }PTree; 树的双亲存储法易于实现对上层结点的操作;不易于访问底层结点。

156
6.2树的存储结构(续) 孩子表示法 便于涉及孩子操作的实现 typedef struct CTNode{
int child; //孩子位置域 struct CTNode *next } *ChildPtr; typedef struct { TElemType data; //树结点数据域 ChildPtr firstchild; //孩子链表头指针 } CTBox; CTBox nodes[MAX_TREE_SIZE ]; int n,r; //结点数和根的位置 }PTree;

157
6.2树的存储结构(续) 孩子双亲表示法 typedef struct CTNode{ int child; //孩子位置域
struct CTNode *next } *ChildPtr; typedef struct { int parent //双亲位置域 TElemType data; //树结点数据域 ChildPtr firstchild; //孩子链表头指针 } CTBox; CTBox nodes[MAX_TREE_SIZE ]; int n,r; //结点数和根的位置 }PTree;

158
6.2树的存储结构(续) 孩子兄弟表示法(二叉链表) data firstchild nextsibling 结点
// 树的二叉链表(孩子-兄弟)存储表示 typedef struct CSNode{ ElemType data; //树结点数据域 struct CSNode *firstchild, *nextsibling; } CSNode, *CSTree;
存储表示 typedef struct CSNode{ ElemType data; //树结点数据域. struct CSNode *firstchild, *nextsibling; } CSNode, *CSTree;")
159
6.2树的存储结构(续) 三叉链表 data firstchild nextsibling 结点 parent
// 树的三叉链表(双亲-孩子-兄弟)存储表示------ typedef struct PCSNode{ ElemType data; //树结点数据域 struct PCSNode *firstchild, *nextsibling,*parent; } PCSNode, *PCSTree;
存储表示 typedef struct PCSNode{ ElemType data; //树结点数据域. struct PCSNode *firstchild, *nextsibling,*parent; } PCSNode, *PCSTree;")
160
6.3二叉树的逻辑结构 二叉树的描述性定义及其基本形态
二叉树:二叉树BT是n个结点的有限集。非空二叉树中:(1)有且只有一个特定的称为根(Root)的结点; (2)当n>1时,其余结点可分为2个互不相交 的有限集BTL,BTR, BTL,BTR分别又是一棵二叉树, BTL称为根的左子树; BTR称为根的右子树。 二叉树的基本形态: 五种:空二叉树;仅有根结点的二叉树;右子树为空的二叉树;左、右子树均不为空的二叉树;左子树为空的二叉树。
有且只有一个特定的称为根(Root)的结点; (2)当n>1时,其余结点可分为2个互不相交. 的有限集BTL,BTR, BTL,BTR分别又是一棵二叉树, BTL称为根的左子树; BTR称为根的右子树。 二叉树的基本形态: 五种:空二叉树;仅有根结点的二叉树;右子树为空的二叉树;左、右子树均不为空的二叉树;左子树为空的二叉树。")
161
6.3二叉树的逻辑结构(续) ADT BinaryTree {
数据对象:D={ai | ai属于ElemSet, i = 1,2, … ,n, n>=0} 数据关系:R: 若D为空集,则R为空集,称为空二叉树; 若D不为空集,R={H},H为二元关系: (1)在D中存在唯一的称为根的数据元素root,它在关系H下无前驱; (2)若D-{root}不为空,则存在D-{root}={DL,DR} ,且DL与DR交集为空; (3)若DL不为空,则DL 中存在唯一的元素xL, <root,xL>属于H,且存在 DL上的关系HL 包含在H中;若DR不为空,则DR中存在唯一的元素 xR, <root,xR>属于H,且存在DR上的关系HR 包含在H中; H={<root,xL>, <root,xR >, HL , HR }; (4)(DL , {HL})是一棵符合本定义的二叉树,称为根的左子树; (DR , {HR})是一棵符合本定义的二叉树,称为根的右子树。 基本操作: InitBiTree(&T); DestroyBiTree(&T); …;InsertChild (T,p,LR,c); PreOrderTraverse (T,Visit()); InOrderTraverse (T,Visit()); PostOrderTraverse (T,Visit()); LevelOrderTraverse (T,Visit()) }ADT BinaryTree
在D中存在唯一的称为根的数据元素root,它在关系H下无前驱; (2)若D-{root}不为空,则存在D-{root}={DL,DR} ,且DL与DR交集为空; (3)若DL不为空,则DL 中存在唯一的元素xL, <root,xL>属于H,且存在 DL上的关系HL 包含在H中;若DR不为空,则DR中存在唯一的元素. xR, <root,xR>属于H,且存在DR上的关系HR 包含在H中; H={<root,xL>, <root,xR >, HL , HR }; (4)(DL , {HL})是一棵符合本定义的二叉树,称为根的左子树; (DR , {HR})是一棵符合本定义的二叉树,称为根的右子树。 基本操作: InitBiTree(&T); DestroyBiTree(&T); …;InsertChild (T,p,LR,c); PreOrderTraverse (T,Visit()); InOrderTraverse (T,Visit()); PostOrderTraverse (T,Visit()); LevelOrderTraverse (T,Visit()) }ADT BinaryTree.")
162
6.3二叉树的逻辑结构(续) 二叉树的数学性质 性质1:在二叉树的第i层上至多右2i-1个结点(i>=1);
性质2:深度为k的二叉树至多有2k –1个结点(k>=1); 性质3:二叉树T,若叶子结点数为n0,度为2的结点数为n2,则有n0 = n2 +1; 性质4:具有n个结点的完全二叉树的深度为:以2为底的n的对数值取下整+1; 性质5:n个结点的完全二叉树结点按照层序编号,则对任一结点i(1<=i<=n),有:(1)如果i=1,则结点i是二叉树的根;如果i>1,则其双亲是结点(i/2)取下整;(2)如果2i>n,则结点i无左孩子(结点i为叶子结点);否则其左孩子是结点 2i;(3)如果如果2i+1>n,则结点i无右孩子;否则其右孩子是结点 2i+1。 满二叉树:深度为k且有2k –1个结点的二叉树; 完全二叉树:深度为k,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应时,称之为完全二叉树。 性质1: [证明] i=1时,显然有2i-1 = 20 =1; 假设对于所有的j,1<=j<i,第j层上至多有2j-1 个结点,则当j=i时,由假设知2i-1 层上至多右2i-2 ,而二叉树的每个结点的度至多为2,故在第i层上 最大结点数为i-1层上最大结点数的2倍,即2* 2i-2 = 2i-1 。 [证毕] 性质3: [证明] n = n0 + n1 + n2 n = B+1 B = n1 + 2n2 所以: n0 = n [证毕] 性质4: [证明] 假设深度为k,由性质2以及完全二叉树定义有: 2k-1 –1< n <=2k –1 推出 2k-1 <= n < 2k k –1 <= 以2为底的n的对数 < k 由于k是整数,所以结论成立。 [证毕]
; 性质3:二叉树T,若叶子结点数为n0,度为2的结点数为n2,则有n0 = n2 +1; 性质4:具有n个结点的完全二叉树的深度为:以2为底的n的对数值取下整+1; 性质5:n个结点的完全二叉树结点按照层序编号,则对任一结点i(1<=i<=n),有:(1)如果i=1,则结点i是二叉树的根;如果i>1,则其双亲是结点(i/2)取下整;(2)如果2i>n,则结点i无左孩子(结点i为叶子结点);否则其左孩子是结点 2i;(3)如果如果2i+1>n,则结点i无右孩子;否则其右孩子是结点 2i+1。 满二叉树:深度为k且有2k –1个结点的二叉树; 完全二叉树:深度为k,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应时,称之为完全二叉树。 性质1: [证明] i=1时,显然有2i-1 = 20 =1; 假设对于所有的j,1<=j<i,第j层上至多有2j-1 个结点,则当j=i时,由假设知2i-1 层上至多右2i-2 ,而二叉树的每个结点的度至多为2,故在第i层上 最大结点数为i-1层上最大结点数的2倍,即2* 2i-2 = 2i-1 。 [证毕] 性质3: [证明] n = n0 + n1 + n2. n = B+1. B = n1 + 2n2. 所以: n0 = n2 + 1 [证毕] 性质4: [证明] 假设深度为k,由性质2以及完全二叉树定义有: 2k-1 –1< n <=2k –1 推出 2k-1 <= n < 2k. k –1 <= 以2为底的n的对数 < k 由于k是整数,所以结论成立。 [证毕]")
163
6.4二叉树的存储结构 顺序存储 具体做法: 利用完全二叉树的性质,元素之间的关系隐含在元素的编号中,所以采用顺序存储后,完全二叉树中结点的存储位置为其编号所在的位置。对于一般二叉树,若采用顺序存储,须先增加虚结点以补成虚完全二叉树,对此虚完全二叉树的存储对应该二叉树的顺序存储。 // 二叉树的顺序存储表示 #define MAX_TREE_SIZE 100 typedef TElemType SqBiTree[MAX_TREE_SIZE ]; //0号单元存放根结点 SqBiTree bt;

164
6.4二叉树的存储结构(续) 顺序存储 E A B D I J K A B C D I J
 顺序存储 E A B D I J K A B C D I J")
165
6.4二叉树的存储结构(续) 二叉链表存储 data lchild rchild 结点
// 二叉树的二叉链表存储表示 typedef struct BiTNode{ TElemType data; //数据域 struct BiTNode *lchild, *rchild; } BiTNode, *BiTree;

166
6.4二叉树的存储结构(续) 三叉链表存储 data lchild rchild 结点 parent
// 二叉树的三叉链表存储表示 typedef struct BiTNode{ TElemType data; //数据域 struct BiTNode *lchild, *rchild,*parent; } BiTNode, *BiTree;

167
6.4二叉树的存储结构(续) (二叉)线索链表存储 data lchild 结点 ltag rtag rchild
// 二叉树的二叉线索链表存储表示 typedef enum {Link,Thread} PointerTag; //Link = =0; Thread = = 1 typedef struct BiThrNode{ TElemType data; //数据域 struct BiThrNode *lchild, *rchild; //左、右孩子指针 PointerTag LTag,Rtag; //左、右标志 } BiThrNode, *BiThrTree;

168
6.4二叉树的存储结构(续) (二叉)线索链表存储 E A B C D F I J H G K
 (二叉)线索链表存储 E A B C D F I J H G K")
169
6.5二叉树的遍历及线索化 遍历二叉树 遍历(Traversing):按照某条路径访问每个结点,使
得每个结点均被访问一次,而且仅被访问一次。 在二叉树中查找具有某种特征的结点 需要对结点进行访问(处理、输出等)操作 二叉树上许多复杂操作的基础是对其遍历 遍历本质:结点之间非线性关系线性化的过程 两种思路: *只要保证每个结点都被访问到一次; *遍历过程中易于实现关于结点的复杂操作 层次遍历法 递归遍历法: 先序、中序、后序
操作. 二叉树上许多复杂操作的基础是对其遍历. 遍历本质:结点之间非线性关系线性化的过程. 两种思路: *只要保证每个结点都被访问到一次; *遍历过程中易于实现关于结点的复杂操作. 层次遍历法. 递归遍历法: 先序、中序、后序.")
170
6.5二叉树的遍历及线索化(续) 遍历二叉树的方法 层次遍历(LevelOrderTraverse):从上到下,自左至右按照层次遍历。
先序遍历(PreOrderTraverse):DLR; 若二叉树为空,则空操作(递归基础);否则:访问根结点;先序遍历左子树;先序遍历右子树。 中序遍历(InOrderTraverse):LDR; 若二叉树为空,则空操作(递归基础);否则:中序遍历左子树;访问根结点;中序遍历右子树。 后序遍历(PostOrderTraverse):LRD; 若二叉树为空,则空操作(递归基础);否则:后序遍历左子树;中序遍历右子树;访问根结点。
:DLR; 若二叉树为空,则空操作(递归基础);否则:访问根结点;先序遍历左子树;先序遍历右子树。 中序遍历(InOrderTraverse):LDR; 若二叉树为空,则空操作(递归基础);否则:中序遍历左子树;访问根结点;中序遍历右子树。 后序遍历(PostOrderTraverse):LRD; 若二叉树为空,则空操作(递归基础);否则:后序遍历左子树;中序遍历右子树;访问根结点。")
171
E A B C D F I J H G K 层次遍历:A,B,I,C,D,J,K,E,F,G,H 先序遍历:A,B,C,D,E,F,G,H,I,J,K 中序遍历:C,B,E,D,G,F,H,A,J,I,K 后序遍历:C,E,G,H F,D,B,J,K,I,A

172
6.5二叉树的遍历及线索化(续) 中序遍历的算法
Status InOrderTraverse1(BiTree T, Status (* Visit) (TElemType e)) { //中序遍历二叉树T的非递归算法,对每个数据元素调用函数Visit InitStack(S); Push(S,T); //根指针入栈 While (!StackEmpty(S)) { while (GetTop(S,p) &&p) Push (S,p->lchild); //向左走到尽头 Pop(S,p) //空指针退栈 if (! StackEmpty(S)) { //访问结点,向右一步 Pop(S,p); if (!Visit(p->data)) return ERROR //访问出错 Push(S,p->rchild); } //if } //while return OK; } InOrderTraverse // 算法时间复杂度:O(n) Status InOrderTraverse2(BiTree T, Status (* Visit) (TElemType e)) { //中序遍历二叉树T的非递归算法,对每个数据元素调用函数Visit InitStack(S); p = T; While ( p || !StackEmpty(S)) { if (p) { Push (S,p); p = p->lchild; } //根指针入栈,遍历左子树 else { //根指针退栈,访问根结点,遍历右子树 Pop(S,p); if (!Visit(p->data)) return ERROR //访问出错 p = p->rchild); } //else } //while return OK; } InOrderTraverse // 算法时间复杂度:O(n) Status InOrderTraverse(BiTree T, Status (* Visit) (TElemType e)) { //中序遍历二叉树T的递归算法,对每个数据元素调用函数Visit if(T) { if(InOrderTraverse(T->lchild,Visit)) if(Visit(T->data)){ if(InOrderTraverse(T->rchild,Visit)) return OK; } else return ERROR; //当访问失败时,出错 } else return OK; //一次递归访问终止 } InOrderTraverse // 算法时间复杂度:O(n)
 (TElemType e)) { //中序遍历二叉树T的非递归算法,对每个数据元素调用函数Visit. InitStack(S); Push(S,T); //根指针入栈. While (!StackEmpty(S)) { while (GetTop(S,p) &&p) Push (S,p->lchild); //向左走到尽头. Pop(S,p) //空指针退栈. if (! StackEmpty(S)) { //访问结点,向右一步. Pop(S,p); if (!Visit(p->data)) return ERROR //访问出错. Push(S,p->rchild); } //if. } //while. return OK; } InOrderTraverse // 算法时间复杂度:O(n) Status InOrderTraverse2(BiTree T, Status (* Visit) (TElemType e)) { //中序遍历二叉树T的非递归算法,对每个数据元素调用函数Visit. InitStack(S); p = T; While ( p || !StackEmpty(S)) { if (p) { Push (S,p); p = p->lchild; } //根指针入栈,遍历左子树. else { //根指针退栈,访问根结点,遍历右子树. Pop(S,p); if (!Visit(p->data)) return ERROR //访问出错. p = p->rchild); } //else. } //while. return OK; } InOrderTraverse // 算法时间复杂度:O(n) Status InOrderTraverse(BiTree T, Status (* Visit) (TElemType e)) { //中序遍历二叉树T的递归算法,对每个数据元素调用函数Visit. if(T) { if(InOrderTraverse(T->lchild,Visit)) if(Visit(T->data)){ if(InOrderTraverse(T->rchild,Visit)) return OK; } else return ERROR; //当访问失败时,出错. } else return OK; //一次递归访问终止. } InOrderTraverse // 算法时间复杂度:O(n)")
173
6.5二叉树的遍历及线索化(续) 二叉树遍历的典型应用 b - + a * / e d c f a+b*(c-d)-e/f
二叉树表示表达式的递归定义: 若表达式为数或简单变量,则相应二叉树中仅有一个根结点,其数据域存放该表达式信息。 若表达式=(第一操作数)(运算符)(第二操作数),则相应的二叉树中以左子树表示第一操作数;右子树表示第二操作数;根结点的数据域存放运算符(若为一元运算符,则左子树为空)。操作数本身又为表达式。 前缀表示(波兰式) -+a*b-cd/ef 中缀表示 a+b*c-d-e/f 后缀表示(逆波兰式) abcd-*+ef/-
(运算符)(第二操作数),则相应的二叉树中以左子树表示第一操作数;右子树表示第二操作数;根结点的数据域存放运算符(若为一元运算符,则左子树为空)。操作数本身又为表达式。 前缀表示(波兰式) -+a*b-cd/ef. 中缀表示. a+b*c-d-e/f. 后缀表示(逆波兰式) abcd-*+ef/-")
174
6.5二叉树的遍历及线索化(续) 二叉树遍历的典型应用 E A B C D F I J H G K
Step1:判定根,由PostOrder知根为A; 已知二叉树的前序遍历序列和中序遍历序列,或者已知二叉树的后序遍历序列和中序遍历序列,可以唯一确定这棵二叉树。 E A B C D F I J H G K Step2:判定左子树元素集合,由InOrder知为{C B E D G F H } Step3:判定右子树元素集合,由InOrder知为{J I K} InOrder: C B E D G F H A J I K PostOrder: C E G H F D B J K I A Step4:分别对左、右子树元素集合按照中序和后序序列递归进行Step1---Step3,直到元素集合为空。

175
6.5二叉树的遍历及线索化(续) 线索二叉树 线索二叉树上遍历的过程,就是根据线索和遍历规则不断找当前结点后继结点的过程。
遍历本质是结点之间非线性关系线性化的过程 遍历后的元素之间的某种线性关系一般隐藏在遍历规则下 需要多次对同一棵树遍历时,如何提高效率? 在二叉链表结构中增加线索域,显式描述遍历后的线索关系 节省线索域空间,充分利用二叉链表中空的n+1个指针域 线索链表:二叉树的存储结构,结点结构定义见前面。 线索:指向结点前驱和后继的指针,叫做线索。 线索二叉树:加上线索的二叉树。 线索化:对二叉树以某种次序遍历使其变为线索二叉树的过程。 线索二叉树上遍历的过程,就是根据线索和遍历规则不断找当前结点后继结点的过程。

176
6.5二叉树的遍历及线索化(续) 线索二叉树上的中序遍历 E A B C D F I J H G K
设当前结点指针为p,其前驱结点为q,后继结点指针为s,则有: InOrder: C B E D G F H A J I K E A B C D F I J H G K 求结点p的后继: 1.若 p->rtag = 1 则 s = p->rchild; 2.若p->rtag = 0 s为p的右子树的中序遍历序列的第一个结点,即右子树最左下结点 求结点p的前驱: 1.若 p->ltag = 1 则 q = p->lchild; 2.若p->rtag = 0 q为p的左子树的中序遍历序列的第一个结点,即左子树最右下结点

177
6.5二叉树的遍历及线索化(续) 线索二叉树上的后序遍历 E A B C D F I J H G K
设当前结点指针为p,其父结点指针为f,其前驱结点为q,后继结点指针为s,则有: PostOrder: C E G H F D B J K I A 求结点p的后继: 1.若 p->rtag = 1, 则 s = p->rchild; 2.若p->rtag = 0 *如果p为其父结点的右儿子,则:s=f; *如果p为其父结点的左儿子,且其父结点没有右子树,则:s=f *如果p为其父结点的左儿子,且其父结点有右子树,则s为其父结点的右子树后序序列的第一个结点,即其左最下的结点。 求结点p的前驱: 1.若 p->ltag = 1 则 q = p->lchild; 2.若 p->ltag = 0 则 *若p有右儿子,q = p->rchild *否则,q = p->lchild

178
6.5二叉树的遍历及线索化(续) 线索二叉树上的前序遍历 E A B C D F I J H G K
设当前结点指针为p,其父结点指针为f,其前驱结点为q,后继结点指针为s,则有: PreOrder: A B C D E F G H I J K 求结点p的前驱: 1.若 p->ltag = 1, 则 s = p->lchild; 2.若p->ltag = 0 *如果p为其父结点的左儿子,则:s=f; *如果p为其父结点的右儿子,且其父结点没有左子树,则:s=f *如果p为其父结点的右儿子,且其父结点有左子树,则s为其父结点的左子树前序序列的最后一个结点,即其右最下的结点。 求结点p的后继: 1.若 p->rtag = 1 则 q = p->rchild; 2.若p->rtag = 0则 *若p有左儿子,则q=p->lchild; *否则,q = p->rchild

179
6.6树和森林的遍历 森林与树相互递归定义 森林:m棵互不相交的树的集合。
树:树是一个二元组Tree = (root,F),root是根,F是m(m>0)棵树的森林,F ={T1,T2,…,Tm}其中Ti = (ri,Fi) 称为根的第i棵子树;当m != 0时,在树根和其子树森林之间存在下列关系:RF = {< root,ri> | i = 1,2,…,m, m>0}
,root是根,F是m(m>0)棵树的森林,F ={T1,T2,…,Tm}其中Ti = (ri,Fi) 称为根的第i棵子树;当m != 0时,在树根和其子树森林之间存在下列关系:RF = {< root,ri> | i = 1,2,…,m, m>0}")
180
6.6树和森林的遍历(续) 树与二叉树的转换 目的:利用二叉树运算来简化树和森林上的运算; 依据:树与二叉树具有相同的二叉链表存储结构 ;
E A B C D F I A B C D I E F

181
6.6树和森林的遍历(续) 森林与二叉树的转换 根据森林与树的相互定义关系以及树与二叉树之间转换规则 森林转换成二叉树: 二叉树转换成森林:
如果F ={T1,T2,…,Tm}是森林,则可按照如下规则转换成一棵二叉树B = (root,LB,RB)。 (1)若F为空,则B为空树; (2)若F非空,则B的根root为森林中第一棵树T1的根;B的左子树LB是从T1 中根结点的子树森林F1 ={T11,T12,…,T1m1}转换而成的二叉树;其右子树RB是从森林F’ = {T2,…,Tm}转换而成的二叉树。 二叉树转换成森林: 二叉树B = (root,LB,RB)可按照如下规则转换成一棵森林F ={T1,T2,…,Tm} 。 (1)若B为空,则F为空树; (2)若B非空,则森林中第一棵树T1的根为B的根root; 是从T1 中根结点的子树森林F1 是由B的左子树LB转换而成的;F中除T1之外的F’ = {T2,…,Tm}是由右子树RB转换而成的。
。 (1)若F为空,则B为空树; (2)若F非空,则B的根root为森林中第一棵树T1的根;B的左子树LB是从T1 中根结点的子树森林F1 ={T11,T12,…,T1m1}转换而成的二叉树;其右子树RB是从森林F’ = {T2,…,Tm}转换而成的二叉树。 二叉树转换成森林: 二叉树B = (root,LB,RB)可按照如下规则转换成一棵森林F ={T1,T2,…,Tm} 。 (1)若B为空,则F为空树; (2)若B非空,则森林中第一棵树T1的根为B的根root; 是从T1 中根结点的子树森林F1 是由B的左子树LB转换而成的;F中除T1之外的F’ = {T2,…,Tm}是由右子树RB转换而成的。")
182
6.6树和森林的遍历(续) A B D E C I F E A B C D F I J H G K K J G H
 A B D E C I F E A B C D F I J H G K K J G H")
183
6.6树和森林的遍历(续) E A B C D F I J H G K E A B C D I J F H G K
 E A B C D F I J H G K E A B C D I J F H G K")
184
6.6树和森林的遍历(续) 遍历树 策略: *按照某种规则直接对树进行遍历; *利用二叉树遍历来实现树上的遍历。 先序遍历:
先访问树的根结点,然后依次先根遍历根的每棵子树;(对应等价的二叉树的先序遍历) 后根遍历: 先依次后根遍历根的每棵子树,然后访问树的根结点; (对应等价的二叉树的中序遍历)
 后根遍历: 先依次后根遍历根的每棵子树,然后访问树的根结点; (对应等价的二叉树的中序遍历)")
185
6.6树和森林的遍历(续) E A B C D F I 先根遍历:A,B,C,D,E,F,I 后根遍历:B,E,F,D,C,I,A
 E A B C D F I 先根遍历:A,B,C,D,E,F,I 后根遍历:B,E,F,D,C,I,A")
186
6.6树和森林的遍历(续) 遍历森林 策略: *按照某种规则直接对森林进行遍历; *利用二叉树遍历来实现森林上的遍历。 先序遍历:
(1)访问森林中第一棵树的根结点; (2)先序遍历第一棵树中根结点的子树森林; (3)先序遍历除去第一棵树之后剩余的树构成的森林 (对应等价的二叉树的先序遍历) 中序遍历: (1)中序遍历第一棵树中根结点的子树森林; (2)访问森林中第一棵树的根结点; (3)中序遍历除去第一棵树之后剩余的树构成的森林 (对应等价的二叉树的中序遍历)
访问森林中第一棵树的根结点; (2)先序遍历第一棵树中根结点的子树森林; (3)先序遍历除去第一棵树之后剩余的树构成的森林. (对应等价的二叉树的先序遍历) 中序遍历: (1)中序遍历第一棵树中根结点的子树森林; (2)访问森林中第一棵树的根结点; (3)中序遍历除去第一棵树之后剩余的树构成的森林. (对应等价的二叉树的中序遍历)")
187
6.7二叉树的应用 哈夫曼树(Huffman Tree)
结点之间路径长度:树中两个结点之间的分支构成这两个结点的路径,路径上的分支数目为路径长度。 树的路径长度:树根到每个结点的路径长度之和。 结点的带权路径长度:该结点到树根之间的路径长度与结点上权的乘积。 树的带权路径长度:树中所有叶子结点的带权路径长度之和,记为:WPL = w1k1 + w2k2 +…+ wiki + wnkn。 最优二叉树(哈夫曼树):设n个权值{w1, w2,…, wn },构造一棵有n个叶子结点的二叉树,每个叶子结点带权wi,则其中带权路径长度WPL最小的二叉树称为最优二叉树(哈夫曼树) 。
:设n个权值{w1, w2,…, wn },构造一棵有n个叶子结点的二叉树,每个叶子结点带权wi,则其中带权路径长度WPL最小的二叉树称为最优二叉树(哈夫曼树) 。")
188
6.7二叉树的应用(续) 哈夫曼算法(Huffman Algorithmic) 输入: n个权值{w1, w2,…, wn } ;
输出:一棵哈夫曼树 算法: 步骤一: 根据给定的n个权值{w1, w2,…, wn } 构成n棵二叉树的集合F ={T1, T2 …, Tn },其中每棵二叉树Ti 中只有一个带权为wi 的根结点,其左右子树均为空。 步骤二:在F中选取两棵根结点的权值最小的树作为左、右子树构造一棵新的二叉树,且置新的二叉树的根结点的权值为其左、右子树上根结点的权值之和。 步骤三:在F中删除这两棵树,同时将新得到的二叉树加入F中。 步骤四:重复步骤二与三,直到F只含有一棵树为止。

189
6.7二叉树的应用(续) 哈夫曼算法(Huffman Algorithmic) 82 49 33 29 20 16 17 14 15 11
给定权的集合: {15,3,14,2,6,9,16,17} 82 {15,3,14,2,6,9,16,17} 49 33 {15,5,14,6,9,16,17} {15,11,14,9,16,17} 29 20 16 17 {15,14,20,16,17} 14 15 11 9 {29,20,16,17} {29,20,33} 5 6 {49,33} 3 2 {82} WPL =(2+3)*5+6*4+( )*3+(16+17)*2 = 229
*5+6*4+( )*3+(16+17)*2 = 229.")
190
6.7二叉树的应用(续) 哈夫曼编码(Huffman Code) 等长编码:每个被编码对象的码长相等。 优点:码长等长,易于解码;
缺点:被编码信息总码长较大,尤其是当存在 许多不常用的被编码对象时 前缀编码:任一个被编码对象的编码都不是另一个 被编码对象的编码的前缀。 优点:当存在被编码对象使用概率不同时,被 编码信息总码长可以减小; 缺点:码长不等长,不易于解码

191
6.7二叉树的应用(续) 哈夫曼编码(Huffman Code)---前缀编码 b a e d c f 利用二叉树来设计二进制的前缀编码:
被编码对象出现在二叉树的叶子结点。约定左分支表示字符“0”,右分支表示字符“1”,则可以从根结点到叶子结点的路径上分支字符组成的字符串作为该叶子结点对应对象的编码。 b a e d c f 1 a(00) b(010) c(0110) d(0111) e(10) f(11) 这种编码的译码过程从根开始。沿着某条分支走到叶子结点时,走过的二进制字符串即译为该叶子结点对应的对象。然后循环扫描总编码后的字符串。
 b(010) c(0110) d(0111) e(10) f(11) 这种编码的译码过程从根开始。沿着某条分支走到叶子结点时,走过的二进制字符串即译为该叶子结点对应的对象。然后循环扫描总编码后的字符串。")
192
6.7二叉树的应用(续) 哈夫曼编码与译码 利用哈夫曼算法可以得到总码长最短的二进制前缀编码,即为哈夫曼编码。 设某次编码应用中不同被编码对象有n种,以此n种被编码对象出现的频率作权,构造出的哈夫曼树即为这n种对象的编码树,由此可得到其二进制的前缀编码。 Set = {c,a,s,t} W ={2,7,4,5} 5 18 7 11 6 4 2 1 c s a t c(110) a(0) s(111) t(10) 假定用于通讯的电文如下,现在要对其编码,采用哈夫曼编码。写出编码后的二进制串。 电文:castcatssatatatasa 电文编码:
 a(0) s(111) t(10) 假定用于通讯的电文如下,现在要对其编码,采用哈夫曼编码。写出编码后的二进制串。 电文:castcatssatatatasa. 电文编码:")
193
教学内容---第七章 1.绪论 2.线性表 3.栈、队列和串 4.数组 5.广义表 6.树和二叉树 7.图 8.动态存储管理 9.查找
10.内部排序 11.外部排序 12.文件

194
7.1图的逻辑结构 图的抽象数据类型 ADT Graph { 数据对象:V={具有相同性质的数据元素} 数据关系:R: R={VR}
VR = {<v,w> | v,w属于V且P(v,w), <v,w> 是从v到w的一 条弧,谓词P(v,w)定义了弧<v,w> 的意义或信息 } 基本操作:P: CreateGraph(&G,V,VR); DFSTraverseGraph(G,v,Visit()); …; BFSTraverseGraph(G,v,Visit()) }ADT Graph
, <v,w> 是从v到w的一 条弧,谓词P(v,w)定义了弧<v,w> 的意义或信息 } 基本操作:P: CreateGraph(&G,V,VR); DFSTraverseGraph(G,v,Visit()); …; BFSTraverseGraph(G,v,Visit()) }ADT Graph.")
195
7.1图的逻辑结构(续) 基本概念和术语 顶点(Vertex):图中数据元素。
弧(Arc): v,w属于V , <v,w> 属于VR,则<v,w> 是从v到w的一条弧。v为弧尾(Tail)或初始点(Initial node), w为弧头(Head)或终端点(Terminal node) 有向图(Digraph):由顶点与弧构成的图。 边(Edge): v,w属于V ,有 <v,w> 属于VR则必有<w,v> 属于VR,称<v,w>以及<w,v>是一条边,记作(v,w)。 无向图(Undigraph):由顶点与边构成的图。 完全图(Completed graph):设图的顶点数为n,有n(n-1)/2条边的无向图为完全图。 有向完全图:设图的顶点数为n,有n(n-1)条弧的有向图为有向完全图。
: v,w属于V , <v,w> 属于VR,则<v,w> 是从v到w的一条弧。v为弧尾(Tail)或初始点(Initial node), w为弧头(Head)或终端点(Terminal node) 有向图(Digraph):由顶点与弧构成的图。 边(Edge): v,w属于V ,有 <v,w> 属于VR则必有<w,v> 属于VR,称<v,w>以及<w,v>是一条边,记作(v,w)。 无向图(Undigraph):由顶点与边构成的图。 完全图(Completed graph):设图的顶点数为n,有n(n-1)/2条边的无向图为完全图。 有向完全图:设图的顶点数为n,有n(n-1)条弧的有向图为有向完全图。")
196
7.1图的逻辑结构(续) 基本概念和术语 稀疏图(Sparse graph):有很少条边或弧(e<n*以2为底n的对数)的图。反之,称为稠密图(Dense graph)。 权(Weight):与图的边或弧相关的数叫做权。 网(Network):带权的图称为网。 子图(Subgraph):设有两个图G=(V,{E})和G’=(V’,{E’}),如果V’包含在V中且E’包含在E中,则称G’为G的子图。 邻接点(Adjacent):对于无向图G=(V,{E}) ,如果边(v,v’)属于E,则称顶点v与v’互为邻接点;或边(v,v’) 依附(Incident)于顶点v和v’;或者边(v,v’) 和顶点v和v’相关联 。对于有向图G=(V,{A}),如果弧<v,v’>属于A,则称顶点v邻接到顶点v’;顶点v’邻接自顶点v;弧(v,v’) 和顶点v和v’相关联 。 (顶点的)度(Degree):和该顶点v相关联的顶点的数目。记为:TD(v)。以顶点v为头的弧的数目称为顶点v的入度(
:带权的图称为网。 子图(Subgraph):设有两个图G=(V,{E})和G’=(V’,{E’}),如果V’包含在V中且E’包含在E中,则称G’为G的子图。 邻接点(Adjacent):对于无向图G=(V,{E}) ,如果边(v,v’)属于E,则称顶点v与v’互为邻接点;或边(v,v’) 依附(Incident)于顶点v和v’;或者边(v,v’) 和顶点v和v’相关联 。对于有向图G=(V,{A}),如果弧<v,v’>属于A,则称顶点v邻接到顶点v’;顶点v’邻接自顶点v;弧(v,v’) 和顶点v和v’相关联 。 (顶点的)度(Degree):和该顶点v相关联的顶点的数目。记为:TD(v)。以顶点v为头的弧的数目称为顶点v的入度(")
197
7.1图的逻辑结构(续) 基本概念和术语 (顶点的)入度(InDegree):以顶点v为头的弧的数目称为顶点v的入度。记为:ID(v)。
(顶点的)出度(OutDegree):以顶点v为尾的弧的数目称为顶点v的出度。记为:OD(v)。 (顶点之间)路径(Path):对无向图G=(V,{E}) ,从顶点 v到顶点v’的路径是一个顶点序列( v =vi,0, vi,1,…, vi,m =v’),其中( vi,j-1, vi,j)属于E,1<=j<=m ;对有向图G ,则路径也是有向的,顶点序列应该满足<vi,j-1, vi,j>属于A。 (顶点之间)路径长度:路径上边或弧的数目。 回路或环(Cycle):第一个顶点与最后一个顶点相同的路径 。 简单路径:序列中不重复出现的路径。 简单回路(简单环):除第一个和最后一个顶点外,其余顶点不重复出现的回路。
出度(OutDegree):以顶点v为尾的弧的数目称为顶点v的出度。记为:OD(v)。 (顶点之间)路径(Path):对无向图G=(V,{E}) ,从顶点 v到顶点v’的路径是一个顶点序列( v =vi,0, vi,1,…, vi,m =v’),其中( vi,j-1, vi,j)属于E,1<=j<=m ;对有向图G ,则路径也是有向的,顶点序列应该满足<vi,j-1, vi,j>属于A。 (顶点之间)路径长度:路径上边或弧的数目。 回路或环(Cycle):第一个顶点与最后一个顶点相同的路径 。 简单路径:序列中不重复出现的路径。 简单回路(简单环):除第一个和最后一个顶点外,其余顶点不重复出现的回路。")
198
7.1图的逻辑结构(续) 基本概念和术语 (顶点之间)连通:无向图中,如果顶点v到顶点v’有路径,则称v和v’是连通的。
连通图(Connected Graph):如果对于无向图G中任意两个顶点vi 、 vj属于V, vi和vj 都是连通的,则称G是连通图。 连通分量(Connected Component):无向图中的极大连通子图 强连通图:如果对于有向图G中任意两个顶点vi 、 vj属于V, vi!=vj ,从vi 到vj 和从vj 到vi 都存在路径 ,则称G是强连通图。 强连通分量:有向图中的极大强连通子图。 (连通图的)生成树:一个极小连通子图,它含有图中全部顶点,但只有足以构成一棵树的n-1条边。(对无向图) (有向图的)生成森林:由若干棵有向树(恰有一个顶点入度为0,其余顶点入度为1的有向图)组成,含有图中全部顶点,但只有足以构成若干棵不相交的有向树的弧。
:如果对于无向图G中任意两个顶点vi 、 vj属于V, vi和vj 都是连通的,则称G是连通图。 连通分量(Connected Component):无向图中的极大连通子图. 强连通图:如果对于有向图G中任意两个顶点vi 、 vj属于V, vi!=vj ,从vi 到vj 和从vj 到vi 都存在路径 ,则称G是强连通图。 强连通分量:有向图中的极大强连通子图。 (连通图的)生成树:一个极小连通子图,它含有图中全部顶点,但只有足以构成一棵树的n-1条边。(对无向图) (有向图的)生成森林:由若干棵有向树(恰有一个顶点入度为0,其余顶点入度为1的有向图)组成,含有图中全部顶点,但只有足以构成若干棵不相交的有向树的弧。")
199
7.2图的存储结构 图的多重链表 data link1 link2 结点 … Linkk
// 用结构指针描述 typedef struct MultiLNode{ ElemType data //数据域 struct MultiLNode *link1 //第1个指针域 struct MultiLNode *link2 //第2个指针域 ……. struct MultiLNode *linkk //第k个指针域 } MultiLNode, *MultiLinkGraph

200
7.2树的存储结构(续) 数组表示法 用两个数组分别存储数据元素(顶点)的信息和数据元素之间关系(边或弧)的信息。
// 图的数组(邻接矩阵)存储表示 #define MAX_VERTEX_NUM 20 //最大顶点数 #define enum {DG,DN,AG,AN} GraphKind; //{有向图,有向网,无向图,无向网} typedef struct ArcCell{ VRType adj; //VRType是顶点关系类型。对无权图,用1或0表示相 邻否;对带权图,则为权值类型。 InfoType *info //该弧相关信息的指针 } ArcCell,AdjMatrix[MAX_VERTEX_NUM][MAX_VERTEX_NUM]; typedef struct { VertexType vexs [MAX_VERTEX_NUM]; //顶点向量 AdjMatrix arcs; //邻接矩阵 GraphKind kind; //图的种类标志 }MGraph;
存储表示 #define MAX_VERTEX_NUM 20 //最大顶点数. #define enum {DG,DN,AG,AN} GraphKind; //{有向图,有向网,无向图,无向网} typedef struct ArcCell{ VRType adj; //VRType是顶点关系类型。对无权图,用1或0表示相 邻否;对带权图,则为权值类型。 InfoType *info //该弧相关信息的指针. } ArcCell,AdjMatrix[MAX_VERTEX_NUM][MAX_VERTEX_NUM]; typedef struct { VertexType vexs [MAX_VERTEX_NUM]; //顶点向量. AdjMatrix arcs; //邻接矩阵. GraphKind kind; //图的种类标志 }MGraph;")
201
7.2树的存储结构(续) 数组表示法 V3 V1 V2 V5 V4 V1 V2 V4 V3 0 1 0 1 0 1 0 1 0 1
G1.arcs = V3 V1 V2 V5 V4 G1 V1 V2 V4 V3 G2 G2.arcs =

202
7.2树的存储结构(续) 数组表示法 邻接矩阵的优点: 容易判定任意两个顶点之间是否有边(或弧)相连; 容易求得各个顶点的度;
*对无向图,TD(vi) = A[i][0]+A[i][1]+…+A[i][n-1] *对有向图,OD(vi) = A[i][0]+A[i][1]+…+A[i][n-1] ID(vi) = A[0][i]+A[1][i]+…+A[n-1][i] 容易求得当前顶点的第一个邻接点、下一个邻接点。
 = A[i][0]+A[i][1]+…+A[i][n-1] *对有向图,OD(vi) = A[i][0]+A[i][1]+…+A[i][n-1] ID(vi) = A[0][i]+A[1][i]+…+A[n-1][i] 容易求得当前顶点的第一个邻接点、下一个邻接点。")
203
7.2图的存储结构(续) 邻接表---图的链式存储 基本思路:
对图中每个顶点建立一个单链表,第i个单链表中的结点表示依附于顶点vi的边(对有向图是以顶点vi为尾的弧)。每个表结点由三个域组成:邻接点域(adjvex)指示与顶点vi邻接的点在图中的位置;链域(nextarc)指示下一条边或弧的结点;数据域(info)存储和边或弧相关的信息。头结点由两个域组成:链域(firstarc)指向链表中第一个结点;数据域(data)存储顶点vi信息。 头结点以顺序结构形式存取,以便随机访问任一顶点的链表。 Adjvex nextarc info data firstarc 表结点 头结点
。每个表结点由三个域组成:邻接点域(adjvex)指示与顶点vi邻接的点在图中的位置;链域(nextarc)指示下一条边或弧的结点;数据域(info)存储和边或弧相关的信息。头结点由两个域组成:链域(firstarc)指向链表中第一个结点;数据域(data)存储顶点vi信息。 头结点以顺序结构形式存取,以便随机访问任一顶点的链表。 Adjvex. nextarc. info. data. firstarc. 表结点. 头结点.")
204
7.2图的存储结构(续) 邻接表---图的链式存储 #define MAX_VERTEX_NUM 20 //最大顶点数
typedef struct ArcNode{ int adjvex; //该弧所指向的顶点的位置 struct ArcNode *nextarc } //指向下一条弧的指针 InfoType *info; //该弧相关信息的指针; }ArcNode; typedef struct VNode{ VertexType data; //顶点信息 ArcNode *firstarc; //指向第一条依附该顶点的弧的指针 }VNode, AdjList[MAX_VERTEX_NUM]; typedef struct { AdjList vertices; int vexnum,arcnum; //图的当前顶点数和弧数 int kind; //图的种类标志 }ALGraph;

205
7.2图的存储结构(续) ^ ^ ^ V1 V2 V3 V4 V5 V3 V1 V2 V5 V4 V1 V2 V4 V3 V1 V3 V2
V2 1 V3 2 V4 3 V5 4 ^ V3 V1 V2 V5 V4 G1 V1 V2 V4 V3 G2 V1 V3 2 V2 1 V4 3 ^ V1 V2 ^ 1 V3 2 V4 3

206
7.2图的存储结构(续) 邻接表---图的链式存储 邻接表的优点: 边(或弧)稀疏时,节省空间; 和边(或弧)相关的信息较多时,节省空间;
容易求得当前顶点的第一个邻接点、下一个邻接点。 对有向图,也可建立逆向邻接表,即对每个顶点建立一个链接以该顶点为头的弧的表。

207
7.2图的存储结构(续) (有向图)十字链表 基本思路:
将有向图的邻接表和逆邻接表结合在一起得到的链表。在十字链表中,对应于有向图每一条弧的结点称为弧结点;对应于每个顶点的结点为顶点结点。每个弧结点由五个域组成:尾域(tailvex)和头域(headvex)分别指示弧尾和弧头两个顶点在图中的位置;链域hlink 指向弧头相同的下一条弧;链域tlink 指向弧尾相同的下一条弧;数据域(info)存储和弧相关的信息。顶点结点由三个域组成:链域firstin与firstout分别指向以该顶点为弧头或弧尾的第一个弧结点指向链表中第一个结点;数据域(data)存储顶点vi信息。 顶点结点以顺序结构形式存取,以便随机访问任一顶点的链表。 将有向图邻接矩阵看作稀疏矩阵时,则可将有向图十字链表看作邻接矩阵十字链表存储。 弧结点 tailvex headvex info tlink hlink 顶点结点 data firstin firstout
和头域(headvex)分别指示弧尾和弧头两个顶点在图中的位置;链域hlink 指向弧头相同的下一条弧;链域tlink 指向弧尾相同的下一条弧;数据域(info)存储和弧相关的信息。顶点结点由三个域组成:链域firstin与firstout分别指向以该顶点为弧头或弧尾的第一个弧结点指向链表中第一个结点;数据域(data)存储顶点vi信息。 顶点结点以顺序结构形式存取,以便随机访问任一顶点的链表。 将有向图邻接矩阵看作稀疏矩阵时,则可将有向图十字链表看作邻接矩阵十字链表存储。 弧结点. tailvex. headvex. info. tlink. hlink. 顶点结点. data. firstin. firstout.")
208
7.2图的存储结构(续) (有向图)十字链表 #define MAX_VERTEX_NUM 20 //最大顶点数
typedef struct ArcBox{ int tailvex, headvex; //该弧的尾和头顶点的位置 struct ArcBox *hlink, *tlink InfoType *info; //该弧相关信息的指针; }ArcBox; typedef struct VexNode{ VertexType data; //顶点信息 ArcBox *firstin, firstout; //分别指向第一条入弧和出弧 }VexNode; typedef struct { VexNode xList[MAX_VERTEX_NUM]; //表头向量 int vexnum,arcnum; //图的当前顶点数和弧数 }OLGraph;

209
7.2图的存储结构(续) V1 V2 V4 V3 G2 (有向图)十字链表 V1 V2 ^ V3 V4 2 3 1
 V1 V2 V4 V3 G2 (有向图)十字链表 V1 V2 ^ V3 V")
210
7.2图的存储结构(续) (无向图)邻接多重表 基本思路:
无向图的邻接表中任何一条边在两个链表中,不便于图的某些操作。在邻接多重表中,对应于无向图每一条边的结点称为边结点;对应于每个顶点的结点为顶点结点。每个边结点由六个域组成:mark是标志域,标记该条边是否被搜索过;ivex和头域jvex该边依附的两个顶点在图中的位置;ilink 指向下一条依附于顶点ivex的边; jlink 指向下一条依附于顶点jvex的边;数据域(info)存储和边相关的信息。顶点结点由两个域组成:数据域(data)存储顶点vi信息; firstedge指向第一条依附于该顶点的边。 顶点结点以顺序结构形式存取,以便随机访问任一顶点的链表。 所需存储量与邻接表相同。 边结点 顶点结点 data firstedge ivex jvex info jlink ilink mark
存储和边相关的信息。顶点结点由两个域组成:数据域(data)存储顶点vi信息; firstedge指向第一条依附于该顶点的边。 顶点结点以顺序结构形式存取,以便随机访问任一顶点的链表。 所需存储量与邻接表相同。 边结点. 顶点结点. data. firstedge. ivex. jvex. info. jlink. ilink. mark.")
211
7.2图的存储结构(续) (无向图)邻接多重表 #define MAX_VERTEX_NUM 20 //最大顶点数
Typedef enum {unvisited,visited} VisitIf; typedef struct EBox{ VisitIf mark; //访问标记 int ivex, jvex; //该边依附的两个顶点的位置 struct EBox *ilink, *jlink InfoType *info; //该弧相关信息的指针; }EBox; typedef struct VexBox{ VertexType data; //顶点信息 EBox *firstedge; }VexBox; typedef struct { VexBox adjmuList[MAX_VERTEX_NUM]; //表头向量 int vexnum,arcnum; //图的当前顶点数和弧数 }AMLGraph;

212
7.2图的存储结构(续) (无向图)邻接多重表 1 2 ^ 4 3 V1 V3 V2 V4 V5 V3 V1 V2 V5 V4 G1
 (无向图)邻接多重表 1 2 ^ 4 3 V1 V3 V2 V4 V5 V3 V1 V2 V5 V4 G1")
213
7.3图的遍历 遍历图 图的遍历(Traversing Graph):从图的某一个顶点出发,按照某条路径访问每个结点,使得每个结点均被访问一次,而且仅被访问一次。 在图中查找具有某种特征的结点 需要对结点进行访问(处理、输出等)操作 图的遍历算法是求解图的连通性问题、拓扑排序和求关键路径等算法的基础 遍历本质:结点之间非线性关系线性化的过程 遍历思路: *深度优先:类似于树的先根遍历; *广度优先:类似于树的层次遍历。
操作. 图的遍历算法是求解图的连通性问题、拓扑排序和求关键路径等算法的基础. 遍历本质:结点之间非线性关系线性化的过程. 遍历思路: *深度优先:类似于树的先根遍历; *广度优先:类似于树的层次遍历。")
214
7.3图的遍历(续) 深度优先搜索 Boolean visited[MAX]; //访问标志数组
Status (*VisitFunc) (int v); //函数变量 Void DFSTraverse(Graph G,Status (*Visit)(int v)){ VisitFunc = Visit; //使用全局变量VisitFunc,使DFS不必设函数指针参数 for (v =0; v<G.vexnum; ++v) visited[v] = FALSE; //标志数组初始化 for (v =0; v<G.vexnum; ++v) if (!visited[v]) DFS(G,v); } Status DFS (Graph G, int v){ //从第v个顶点出发递归地深度优先遍历图G,对每个元素调用函数Visit visited[v] = TRUE; VisitFunc(v); //访问第v个顶点 for ( w =FirstAdjVex(G,v); w; w =NextAdjVex(G,v,w)) if (!visited[w]) DFS(G,w); } // 算法时间复杂度与存储结构相关 深度优先搜索 邻接矩阵存储:T(n)=O(n2); 邻接表存储:T(n)=O(n+e) 遍历思路: 从图的某个顶点v出发,访问此顶点,然后依次从v的未被访问的邻接点出发深度优先遍历图,直至图中所有和v有路径相通的顶点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作为始点,重复上述过程,直至图中所有顶点都被访问到为止。 这是一个递归算法,遍历过程中,当某个顶点的所有邻接点都被访问到后,需要“回朔”,即沿着调用的逆方向回退到上一层顶点,继续考察该顶点的下一个邻接点。
![7.3图的遍历(续) 深度优先搜索 Boolean visited[MAX]; //访问标志数组](http://slidesplayer.com/slide/11606863/62/images/214/7.3%E5%9B%BE%E7%9A%84%E9%81%8D%E5%8E%86%EF%BC%88%E7%BB%AD%EF%BC%89+%E6%B7%B1%E5%BA%A6%E4%BC%98%E5%85%88%E6%90%9C%E7%B4%A2+Boolean+visited%5BMAX%5D%3B+%2F%2F%E8%AE%BF%E9%97%AE%E6%A0%87%E5%BF%97%E6%95%B0%E7%BB%84.jpg "Status (*VisitFunc) (int v); //函数变量. Void DFSTraverse(Graph G,Status (*Visit)(int v)){ VisitFunc = Visit; //使用全局变量VisitFunc,使DFS不必设函数指针参数. for (v =0; v<G.vexnum; ++v) visited[v] = FALSE; //标志数组初始化. for (v =0; v<G.vexnum; ++v) if (!visited[v]) DFS(G,v); } Status DFS (Graph G, int v){ //从第v个顶点出发递归地深度优先遍历图G,对每个元素调用函数Visit. visited[v] = TRUE; VisitFunc(v); //访问第v个顶点. for ( w =FirstAdjVex(G,v); w; w =NextAdjVex(G,v,w)) if (!visited[w]) DFS(G,w); } // 算法时间复杂度与存储结构相关. 深度优先搜索. 邻接矩阵存储:T(n)=O(n2); 邻接表存储:T(n)=O(n+e) 遍历思路: 从图的某个顶点v出发,访问此顶点,然后依次从v的未被访问的邻接点出发深度优先遍历图,直至图中所有和v有路径相通的顶点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作为始点,重复上述过程,直至图中所有顶点都被访问到为止。 这是一个递归算法,遍历过程中,当某个顶点的所有邻接点都被访问到后,需要 回朔 ,即沿着调用的逆方向回退到上一层顶点,继续考察该顶点的下一个邻接点。")
215
7.3图的遍历(续) 深度优先搜索 V12 V9 V10 V11 V1 V3 V6 V2 V8 V5 V4 V7 G3
一种DFS遍历序列: V1 , V2 , V4 , V8 , V5 , V3 , V6 , V7 , V9 , V10 , V12 , V11 当存储结构和算法确定后,遍历序列唯一。

216
7.3图的遍历(续) 广度优先搜索 Boolean visited[MAX]; //访问标志数组
Void BFSTraverse(Graph G,Status (*Visit)(int v)){ for (v =0; v<G.vexnum; ++v) visited[v] = FALSE; //标志数组初始化 InitQueue(Q); //置空的辅助队列 for (v =0; v<G.vexnum; ++v) if (!visited[v]) { visited[v] = TRUE; Visit (v); EnQueue(Q,u); While(!QueueEmpty(Q)) { DeQueue(Q,u); for ( w =FirstAdjVex(G,u); w; w =NextAdjVex(G,u,w)) if (!visited[w]) {Visited[w] =TRUE; Visit(w); Enqueue(Q,w); } } //while }if } // 算法时间复杂度与存储结构相关 邻接矩阵存储:T(n)=O(n2); 邻接表存储:T(n)=O(n+e) 广度优先搜索 遍历思路: 从图的某个顶点v出发,访问此顶点,然后依次访问v的未被访问的邻接点,然后从这些邻接点出发依次访问它们的邻接点,并使“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问,直至图中所有已被访问的顶点的邻接点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作为始点,重复上述过程,直至图中所有顶点都被访问到为止。 一层层遍历。如何保证上层次序先于下层次序?保证“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问?可以通过队列来控制实现。
![7.3图的遍历(续) 广度优先搜索 Boolean visited[MAX]; //访问标志数组](http://slidesplayer.com/slide/11606863/62/images/216/7.3%E5%9B%BE%E7%9A%84%E9%81%8D%E5%8E%86%EF%BC%88%E7%BB%AD%EF%BC%89+%E5%B9%BF%E5%BA%A6%E4%BC%98%E5%85%88%E6%90%9C%E7%B4%A2+Boolean+visited%5BMAX%5D%3B+%2F%2F%E8%AE%BF%E9%97%AE%E6%A0%87%E5%BF%97%E6%95%B0%E7%BB%84.jpg "Void BFSTraverse(Graph G,Status (*Visit)(int v)){ for (v =0; v<G.vexnum; ++v) visited[v] = FALSE; //标志数组初始化. InitQueue(Q); //置空的辅助队列. for (v =0; v<G.vexnum; ++v) if (!visited[v]) { visited[v] = TRUE; Visit (v); EnQueue(Q,u); While(!QueueEmpty(Q)) { DeQueue(Q,u); for ( w =FirstAdjVex(G,u); w; w =NextAdjVex(G,u,w)) if (!visited[w]) {Visited[w] =TRUE; Visit(w); Enqueue(Q,w); } } //while }if } // 算法时间复杂度与存储结构相关. 邻接矩阵存储:T(n)=O(n2); 邻接表存储:T(n)=O(n+e) 广度优先搜索. 遍历思路: 从图的某个顶点v出发,访问此顶点,然后依次访问v的未被访问的邻接点,然后从这些邻接点出发依次访问它们的邻接点,并使 先被访问的顶点的邻接点 先于 后被访问的顶点的邻接点 被访问,直至图中所有已被访问的顶点的邻接点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作为始点,重复上述过程,直至图中所有顶点都被访问到为止。 一层层遍历。如何保证上层次序先于下层次序?保证 先被访问的顶点的邻接点 先于 后被访问的顶点的邻接点 被访问?可以通过队列来控制实现。")
217
7.3图的遍历(续) 广度优先搜索 V12 V9 V10 V11 V1 V3 V6 V2 V8 V5 V4 V7 G3
一种BFS遍历序列: V1 , V2 , V3 , V4 , V5 , V6 , V7 , V8 , V9 , V10 , V12 , V11 当存储结构和算法确定后,遍历序列唯一。

218
7.4图的应用 典型应用 无向图的连通分量 无向图的生成树 连通网的最小生成树 有向无环图的拓扑排序 有向无环图的关键路径 有向网的最短路径

219
7.4图的应用(续) 无向图的连通分量 思路:利用遍历图的算法求解无向图的连通性。
方法:利用图的遍历(DFS与BFS均可)算法,对连通图,从任一定点出发遍历,可访问到所有顶点;对非连通图,需从多个顶点出发进行遍历,每一次从一个新的起始点出发遍历得到的顶点序列恰为其各个连通分量中的顶点集。最终求得一个无向图的所有连通分量。
算法,对连通图,从任一定点出发遍历,可访问到所有顶点;对非连通图,需从多个顶点出发进行遍历,每一次从一个新的起始点出发遍历得到的顶点序列恰为其各个连通分量中的顶点集。最终求得一个无向图的所有连通分量。")
220
7.4图的应用(续) 无向图的生成树 V12 V9 V10 V11 V1 V3 V6 V2 V8 V5 V4 V7 思路:
G3 V3 V6 V2 V8 V5 V4 V7 思路: 利用遍历图的算法求解无向连通图的生成树和无向非连通图的生成森林。 方法: 对连通图G,设E(G)为连通图G中所有边的集合,则从图中任一顶点出发遍历图时,必将E(G)分为两个集合T(G)和B(G),其中T(G)是遍历图过程中历经边的集合;B(G)是剩余边的集合。T(G)和图G中所有顶点一起构成连通图G的极小连通子图,它是连通图的一棵生成树。根据遍历方法,生成树分为DFS生成树和BFS生成树。 对无向非连通图,每个连通分量对应一个生成树,形成生成森林。
为连通图G中所有边的集合,则从图中任一顶点出发遍历图时,必将E(G)分为两个集合T(G)和B(G),其中T(G)是遍历图过程中历经边的集合;B(G)是剩余边的集合。T(G)和图G中所有顶点一起构成连通图G的极小连通子图,它是连通图的一棵生成树。根据遍历方法,生成树分为DFS生成树和BFS生成树。 对无向非连通图,每个连通分量对应一个生成树,形成生成森林。")
221
7.4图的应用(续) 无向图的生成树 V12 V9 V10 V11 V1 G3 V3 V6 V2 V8 V5 V4 V7
 无向图的生成树 V12 V9 V10 V11 V1 G3 V3 V6 V2 V8 V5 V4 V7")
222
7.4图的应用(续) 连通网的最小生成树 问题: 用连通网表示的网络上如何构造代价最小的通信网。
对于n个顶点的连通网可以建立许多不同的生成树,每一棵生成树都是一个通信网。一个生成树的代价就是树上各边的代价之和,表示着通信网上总通信耗费量。使通信网上总通信耗费量最小的问题就是求解最小生成树的问题,即如何构造连通网的最小代价生成树 思路: 利用最小生成树的MST性质。 方法: *普里姆(prim)算法; *克鲁斯卡尔(kruskal)算法。 最小生成树的MST性质: 假设N = (V,{E})是一个连通网,U是顶点集V的一个非空子集。若(u,v)是一条具有最小权值(代价)的边,其中u属于U,v属于V-U,则必存在一棵包含边(u,v)的最小生成树。 证明: (反证法) 假设N = (V,{E})的任何一棵最小生成树都不含边(u,v) 。设T是连通网上的一棵最小树,当将边(u,v) 加入到T中时,由生成树的定义,T中必存在一条包含(u,v) 的回路。另一方面,由于T是生成树,则在T上必存在另一条边(u’,v’) ,其中u’属于U,v’属于V-U,且u和u’,v和v’之间均有路径相通。删去边(u’,v’),便可消除上述回路,同时得到另一棵生成树T’。因为(u,v)的代价不高于(u’,v’),则T’的代价亦不高于T,T’是一棵包含(u,v)的最小生成树。矛盾!
算法; *克鲁斯卡尔(kruskal)算法。 最小生成树的MST性质: 假设N = (V,{E})是一个连通网,U是顶点集V的一个非空子集。若(u,v)是一条具有最小权值(代价)的边,其中u属于U,v属于V-U,则必存在一棵包含边(u,v)的最小生成树。 证明: (反证法) 假设N = (V,{E})的任何一棵最小生成树都不含边(u,v) 。设T是连通网上的一棵最小树,当将边(u,v) 加入到T中时,由生成树的定义,T中必存在一条包含(u,v) 的回路。另一方面,由于T是生成树,则在T上必存在另一条边(u’,v’) ,其中u’属于U,v’属于V-U,且u和u’,v和v’之间均有路径相通。删去边(u’,v’),便可消除上述回路,同时得到另一棵生成树T’。因为(u,v)的代价不高于(u’,v’),则T’的代价亦不高于T,T’是一棵包含(u,v)的最小生成树。矛盾!")
223
7.4图的应用(续) 连通网的最小生成树---prim算法 输入:连通网N = (V, {E}),最小生成树边的集合TE =空集
输出:一棵最小生成树T = (V, {TE}) 步骤: step1.初始:U ={u0}(u0属于V),TE = {}; step2.在所有u属于U,v属于V – U的边(u,v)中找一条代价最小的 边(u0, v0 )并入集合TE,同时v0 并入U; step3.重复step2,直至 U = V为止 最后TE中有n-1条边, T = (V, {TE})即为N的一棵最小生成树。 效率: T(n) = O(n2),与e无关(其中n为网中结点个数, e为边的个数)
 步骤: step1.初始:U ={u0}(u0属于V),TE = {}; step2.在所有u属于U,v属于V – U的边(u,v)中找一条代价最小的. 边(u0, v0 )并入集合TE,同时v0 并入U; step3.重复step2,直至 U = V为止. 最后TE中有n-1条边, T = (V, {TE})即为N的一棵最小生成树。 效率: T(n) = O(n2),与e无关(其中n为网中结点个数, e为边的个数)")
224
7.4图的应用(续) 连通网的最小生成树---prim算法 V1 V4 V6 V2 V5 V3
U ={v1} , V-U={v2, v3, v4, v5, v6}, TE= { } V1 6 V4 V6 V2 V5 V3 3 5 1 4 2 U ={v1, v3} , V-U={v2, v4, v5, v6}, TE= { (v1, v3)} U ={v1, v3 ,v6} , V-U={v2, v4, v5}, TE= { (v1, v3 ), (v3, v6 ) } U ={v1, v3 ,v6 , v4} , V-U={v2, v5}, TE= { (v1, v3 ), (v3, v6 ) , (v4, v6 ) } U ={v1, v3 ,v6 , v4 , v2} , V-U={v5}, TE= { (v1, v3 ), (v3, v6 ) , (v4, v6 ) , (v2, v3 ) } U ={v1, v3 ,v6 , v4 , v2 , v5} , V-U={}, TE ={ (v1, v3 ),(v3, v6 ),(v4, v6 ),(v2, v3 ),(v2, v5 ) }
} U ={v1, v3 ,v6} , V-U={v2, v4, v5}, TE= { (v1, v3 ), (v3, v6 ) } U ={v1, v3 ,v6 , v4} , V-U={v2, v5}, TE= { (v1, v3 ), (v3, v6 ) , (v4, v6 ) } U ={v1, v3 ,v6 , v4 , v2} , V-U={v5}, TE= { (v1, v3 ), (v3, v6 ) , (v4, v6 ) , (v2, v3 ) } U ={v1, v3 ,v6 , v4 , v2 , v5} , V-U={}, TE ={ (v1, v3 ),(v3, v6 ),(v4, v6 ),(v2, v3 ),(v2, v5 ) }")
225
7.4图的应用(续) 连通网的最小生成树---kruskal算法 输入:连通网N = (V, {E}),最小生成树边的集合TE =空集
输出:一棵最小生成树T = (V, {TE}) 步骤: step1.初始:只有n个顶点而无边的非连通图T = (V,TE={}); step2.在E中选择代价最小的边,若该边依附的顶点落在T中不同 的连通分量上,则将此边加入到T的TE集合中,否则舍去此 边而选择下一条代价最小的边; step3.重复step2,直至 T中所有顶点都在同一个连通分量上为止 效率: T(n) = O(eloge),与n无关(其中n为网中结点个数, e为边的个数)
 步骤: step1.初始:只有n个顶点而无边的非连通图T = (V,TE={}); step2.在E中选择代价最小的边,若该边依附的顶点落在T中不同. 的连通分量上,则将此边加入到T的TE集合中,否则舍去此. 边而选择下一条代价最小的边; step3.重复step2,直至 T中所有顶点都在同一个连通分量上为止. 效率: T(n) = O(eloge),与n无关(其中n为网中结点个数, e为边的个数)")
226
7.4图的应用(续) 连通网的最小生成树---kruskal算法 V1 V4 V6 V2 V5 V3
V ={v1,v2, v3, v4, v5, v6}, TE= { } V1 6 V4 V6 V2 V5 V3 3 5 1 4 2 V ={v1,v2, v3, v4, v5, v6}, TE= { (v1, v3)} V ={v1,v2, v3, v4, v5, v6}, TE= { (v1, v3 ), (v4, v6 ) } V ={v1,v2, v3, v4, v5, v6}, TE= { (v1, v3 ), (v4, v6 ) , (v2, v5 ) } V ={v1,v2, v3, v4, v5, v6}, TE= { (v1, v3 ), (v4, v6 ) , (v2, v5 ) , (v3, v6 ) } V ={v1,v2, v3, v4, v5, v6}, TE ={ (v1, v3 ),(v3, v6 ),(v4, v6 ),(v2, v3 ),(v2, v5 ) }
} V ={v1,v2, v3, v4, v5, v6}, TE= { (v1, v3 ), (v4, v6 ) } V ={v1,v2, v3, v4, v5, v6}, TE= { (v1, v3 ), (v4, v6 ) , (v2, v5 ) } V ={v1,v2, v3, v4, v5, v6}, TE= { (v1, v3 ), (v4, v6 ) , (v2, v5 ) , (v3, v6 ) } V ={v1,v2, v3, v4, v5, v6}, TE ={ (v1, v3 ),(v3, v6 ),(v4, v6 ),(v2, v3 ),(v2, v5 ) }")
227
7.4图的应用(续) 有向无环图中基本概念 有向无环图(DAG):一个无环的有向图。其作用: *描述含有公共子式的表达式
*描述一项工程或系统的进行过程 #工程能否顺利进行; #工程完成所必需的最短时间 拓扑排序(Topological Sort) :由某个集合上的一个偏序得到该集合上的一个全序的操作。这个全序称为拓扑有序(Topological Order)。 AOV-网:用顶点表示活动,用弧表示活动间的优先关系的有向图称为顶点表示活动的图(Activity On Vertex Network)。 AOE-网:顶点表示事件,弧表示活动,权表示活动持续时间的带权有向无环图称为边表示活动的网(Activity On Edge )
 :由某个集合上的一个偏序得到该集合上的一个全序的操作。这个全序称为拓扑有序(Topological Order)。 AOV-网:用顶点表示活动,用弧表示活动间的优先关系的有向图称为顶点表示活动的图(Activity On Vertex Network)。 AOE-网:顶点表示事件,弧表示活动,权表示活动持续时间的带权有向无环图称为边表示活动的网(Activity On Edge )")
228
7.4图的应用(续) 有向无环图的拓扑排序 为了工程能进行,其对应的AOV-网中不应该存在环。检测的办法有:
*DFS遍历:从有向图某个顶点v出发,在遍历结束之前如果出现从顶点u到顶点v的回边,由于u在生成树上是v的子孙,则有向图中必定存在包含顶点v和u的环。 *拓扑排序:对有向图构造其顶点的拓扑有序序列,若网中所有顶点都在它的拓扑有序序列中,则该AOV-网中必定不存在环。

229
7.4图的应用(续) Status TopologicalSort(ALGraph G){ //有向图G采用邻接表存储结构 FindInDegree(G,indegree); //对各顶点求入度Indegree[0..vexnum-1]--O(e) InitStack; //用栈存放所有入度为零的顶点 for (i =0;i<G.vexnum;++i) if(!indegree[i]) Push(S,i); //入度为0进栈--O(n) count = 0 //输出顶点计数 while (!StackEmpty(S)) { pop(S,i);printf(i,G.vertices[i].data); ++count; for (p =G.vertices[i].firstarc; p; p =p->nextarc) { k = p->adjvex; //对i号顶点的每个邻接点的入度减1 if (!(--indegree[k])) Push(S,k); } //for O(e) if(count<G.vexnum) return ERROR; else return OK; } // 算法时间复杂度T(n) = O(n +e) 有向无环图的拓扑排序算法 输入:AOV-网 输出:包含全部顶点的一个拓扑序列或者部分顶点的序列(存在环) 步骤: step1.在图中选取一个没有前驱的顶点且输出之; step2.在图中删除该顶点和所有以它为尾的弧; step3.重复step1、step2,直至 全部顶点均已输出,或者当前图中不存在无前驱的顶点为止(存在环)。 逻辑上:拓扑序列不唯一; 物理上:拓扑序列唯一
![7.4图的应用(续) Status TopologicalSort(ALGraph G){ //有向图G采用邻接表存储结构. FindInDegree(G,indegree); //对各顶点求入度Indegree[0..vexnum-1]--O(e)](http://slidesplayer.com/slide/11606863/62/images/229/7.4%E5%9B%BE%E7%9A%84%E5%BA%94%E7%94%A8%EF%BC%88%E7%BB%AD%EF%BC%89+Status+TopologicalSort%28ALGraph+G%29%7B+%2F%2F%E6%9C%89%E5%90%91%E5%9B%BEG%E9%87%87%E7%94%A8%E9%82%BB%E6%8E%A5%E8%A1%A8%E5%AD%98%E5%82%A8%E7%BB%93%E6%9E%84.+FindInDegree%28G%2Cindegree%29%3B+%2F%2F%E5%AF%B9%E5%90%84%E9%A1%B6%E7%82%B9%E6%B1%82%E5%85%A5%E5%BA%A6Indegree%5B0..vexnum-1%5D--O%28e%29.jpg "InitStack; //用栈存放所有入度为零的顶点. for (i =0;i<G.vexnum;++i) if(!indegree[i]) Push(S,i); //入度为0进栈--O(n) count = 0 //输出顶点计数. while (!StackEmpty(S)) { pop(S,i);printf(i,G.vertices[i].data); ++count; for (p =G.vertices[i].firstarc; p; p =p->nextarc) { k = p->adjvex; //对i号顶点的每个邻接点的入度减1. if (!(--indegree[k])) Push(S,k); } //for --O(e) if(count<G.vexnum) return ERROR; else return OK; } // 算法时间复杂度T(n) = O(n +e) 有向无环图的拓扑排序算法. 输入:AOV-网. 输出:包含全部顶点的一个拓扑序列或者部分顶点的序列(存在环) 步骤: step1.在图中选取一个没有前驱的顶点且输出之; step2.在图中删除该顶点和所有以它为尾的弧; step3.重复step1、step2,直至 全部顶点均已输出,或者当前图中不存在无前驱的顶点为止(存在环)。 逻辑上:拓扑序列不唯一; 物理上:拓扑序列唯一.")
230
7.4图的应用(续) 有向无环图的拓扑排序算法 ^ V1 V3 V2 V4 4 V5 V6 V1 V2 V3 V4 V5 V6 V1 V2
V3 2 V2 ^ 1 V4 3 4 V5 V6 5 V1 V2 V3 V4 V5 V6 V1 V2 V3 V4 V5 V3 V4 V5 V2 V3 V5 V2 V2 V5 1 2 1 4 3 5 1 1 2 V2

231
7.4图的应用(续) 有向无环图的关键路径 AOE-网描述工程,有两个问题需要解决: *完成整项工程至少需要多少时间?
*那些活动是影响工程进度的关键? V1 V2 V3 V4 V5 V6 a4=3 a1=3 a8=1 a3=2 a2=2 a5=4 a6=3 a7=2 8个活动、6个事件的AOE-网, v1 表示整个工程开始, v6 表示整个工程结束。事件v4 表示活动a3 和a5 已经完成, 活动a7 可以开始

232
7.4图的应用(续) 源点:唯一的一个入度为零的点 汇点:唯一的一个出度为零的点
关键路径:路径长度(路径上各活动持续时间之和)最长的路径。这也是完成工程所需要的最短时间。 事件vi 最早发生时间ve(i):从源点到vi的最长路径长度。 活动ai的最早开始时间e(i) :为活动ai (< vj, vk >)弧的弧尾事件ve(j) 事件vi 最迟发生时间vl(i):不推迟整个工程完成的前提下事件vi必须开始的时间。 活动ai的最迟开始时间l(i) :不推迟整个工程完成的前提下活动ai必须进行的时间。 关键活动: l(i) = e(i) 的活动称为关键活动。关键路径上的所有活动都是关键活动。要求工程最少需要完成时间、要加快工程进度,只能考察和改进关键活动,它们是影响工程进度的关键。
最长的路径。这也是完成工程所需要的最短时间。 事件vi 最早发生时间ve(i):从源点到vi的最长路径长度。 活动ai的最早开始时间e(i) :为活动ai (< vj, vk >)弧的弧尾事件ve(j) 事件vi 最迟发生时间vl(i):不推迟整个工程完成的前提下事件vi必须开始的时间。 活动ai的最迟开始时间l(i) :不推迟整个工程完成的前提下活动ai必须进行的时间。 关键活动: l(i) = e(i) 的活动称为关键活动。关键路径上的所有活动都是关键活动。要求工程最少需要完成时间、要加快工程进度,只能考察和改进关键活动,它们是影响工程进度的关键。")
233
7.4图的应用(续) 有向无环图的关键路径算法 思路:
1.求出AOE-网中的关键活动,即求出l(i) = e(i) 的活动ai (< vj, vk >) 。 2.对活动ai (< vj, vk >),其持续时间为dut(<j,k>),则有: (1)e(i) = ve(j); (2)l(i) = vl(k) – dut(<j,k>) 3. (1)从ve(0) =0开始向前递推:ve(j) = Max(i) {ve(i) + dut(<i,j>) <i,j>属于T, j =1,2,…,n-1;T是所有以第j个顶点为头的弧的集合 (2)从vl(n-1) = ve(n-1) 开始向后递推:vl(i) = Min(j) {vl(j) - dut(<i,j>) <i,j>属于S, i =n-2,…,0;S是所有以第i个顶点为尾的弧的集合 输入:AOE-网 输出:求出所有关键活动,进而求出所有关键路径 步骤: step1.输入e条弧<j,k>,建立AOE-网的存储结构; step2.从源点v0 出发,令ve[0]=0,按拓扑有序求其余各顶点的最早发生时间ve[i](1<=i<=n)。如果得到拓扑有序序列中顶点个数小于网中顶点数n,则说明网中存在环,算法终止;否则执行step3; step3.从汇点vn 出发,令vl[n-1]=ve[n-1],按拓扑有序求其余各顶点的最迟发生时间vl[i](n-2>=i>=2); step4.根据各顶点的ve和vl值,求每条弧s的最早开始时间e(s)和最迟开始时间l(s)。若某条弧满足e(s)=l(s),则为关键活动。
 = e(i) 的活动ai (< vj, vk >) 。 2.对活动ai (< vj, vk >),其持续时间为dut(<j,k>),则有: (1)e(i) = ve(j); (2)l(i) = vl(k) – dut(<j,k>) 3. (1)从ve(0) =0开始向前递推:ve(j) = Max(i) {ve(i) + dut(<i,j>) <i,j>属于T, j =1,2,…,n-1;T是所有以第j个顶点为头的弧的集合. (2)从vl(n-1) = ve(n-1) 开始向后递推:vl(i) = Min(j) {vl(j) - dut(<i,j>) <i,j>属于S, i =n-2,…,0;S是所有以第i个顶点为尾的弧的集合. 输入:AOE-网. 输出:求出所有关键活动,进而求出所有关键路径. 步骤: step1.输入e条弧<j,k>,建立AOE-网的存储结构; step2.从源点v0 出发,令ve[0]=0,按拓扑有序求其余各顶点的最早发生时间ve[i](1<=i<=n)。如果得到拓扑有序序列中顶点个数小于网中顶点数n,则说明网中存在环,算法终止;否则执行step3; step3.从汇点vn 出发,令vl[n-1]=ve[n-1],按拓扑有序求其余各顶点的最迟发生时间vl[i](n-2>=i>=2); step4.根据各顶点的ve和vl值,求每条弧s的最早开始时间e(s)和最迟开始时间l(s)。若某条弧满足e(s)=l(s),则为关键活动。")
234
7.4图的应用(续) 有向无环图的关键路径示例 V1 V2 V3 V4 V5 V6 V1 V3 V4 V6 顶点 ve vl v1 v2 3
v2 3 4 v3 2 v4 6 v5 7 v6 8 活动 e l l-e a1 1 a2 a3 3 4 a4 a5 2 a6 5 a7 6 a8 7 V1 V2 V3 V4 V5 V6 a4=3 a1=3 a8=1 a3=2 a2=2 a5=4 a6=3 a7=2 *关键活动的改进可以改进工程进度; *关键活动速度提高要有限度,前提是不能改变关键路径 *若网中有多条关键路径,要改进工程进度,必须同时 提高几条关键路径上的关键活动的速度。 V1 V3 V4 V6 a2=2 a5=4 a7=2

235
7.4图的应用(续) 带权有向图的最短路径 源点:路径上的第一个顶点 汇点:路径上的最后一个顶点 最短路径:
*从源点到终点所含边的数目最少的路径。(用BFS边历方法可以求得) *从源点到终点路径上边的权值之和最小的路径。(用Dijkstra算法和Floyd算法可以求得) 从某个源点到其余各顶点的最短路径(设源点为v0,终点可以是v1 ,v2 ,…, vn ,则可以求得n条最短路径) 每一对顶点之间的最短路径(源点可以为v1 ,v2 ,…, vn ,终点也可以是v1 ,v2 ,…, vn ,源点与终点不能相等,可以求得n(n-1)条最短路径)
 *从源点到终点路径上边的权值之和最小的路径。(用Dijkstra算法和Floyd算法可以求得) 从某个源点到其余各顶点的最短路径(设源点为v0,终点可以是v1 ,v2 ,…, vn ,则可以求得n条最短路径) 每一对顶点之间的最短路径(源点可以为v1 ,v2 ,…, vn ,终点也可以是v1 ,v2 ,…, vn ,源点与终点不能相等,可以求得n(n-1)条最短路径)")
236
7.4图的应用(续) 某个源点到其余各顶点的最短路径 V1 V5 V2 V3 V0 V4 10 100 5 30 20 50 60 源点
终点 最短路径 路径长度 v0 v1 无 v2 (v0 , v2 ) 10 v3 (v0 , v4 , v3 ) 50 v4 (v0 , v4 ) 30 v5 (v0 , v4 , v3 , v5 ) 60
 10. v3. (v0 , v4 , v3 ) 50. v4. (v0 , v4 ) 30. v5. (v0 , v4 , v3 , v5 ) 60.")
237
7.4图的应用(续) 最短路径算法 输入:带权有向图 输出:n条最短路径 步骤:
step1.从源点v出发到图上其余各顶点(终点)vi 可能达到的最短路径长度的初值为:若从v到vi 有弧,D[i]为弧上权值;否则为无穷大; step2.选择vj ,使得D[j] = Min(i){D[i] | vi 属于V-S}, vj 就是当前求得的一条从v出发的最短路径的终点。令S = S U {j} ; step3.修改从v出发到集合V-S上任一顶点vk可达的最短路径长度。如果D[j] +arcs[j][k]<D[k],则修改D[k] =D[j] +arcs[j][k]; step4.重复操作step2、step3共n-1次。由此求得从v到图上其余各顶点的最短路径是依路径长度递增的序列。 思路: 1.Dijkstra: 按路径长度递增的次序产生最短路径 。 2.用向量D[i]表示当前所找到的从源点v到每个终点vi 的最短路径的长度。它的初态为:若从v到vi 有弧,则D[i]为弧上权值;否则为无穷大。这时,长度为D[j] = Min(i){D[i] | vi 属于V}的路径就是从v出发的长度最短的一条最短路径。设为(v, vj)。 3. 设S为已求得最短路径的终点的集合,则下一条最短路径(设其终点为x)或者是弧(v, x ),或者是中间只经过S中的顶点而最后到达顶点x的路径。即下一条长度次短的最短路径的长度为D[j] = Min(i){D[i] | vi 属于V-S},其中,D[i]或者是弧(v, vi ) 上的权值,或者是D[k] (vi 属于S)和弧(vi, vk )上的权值之和。
vi 可能达到的最短路径长度的初值为:若从v到vi 有弧,D[i]为弧上权值;否则为无穷大; step2.选择vj ,使得D[j] = Min(i){D[i] | vi 属于V-S}, vj 就是当前求得的一条从v出发的最短路径的终点。令S = S U {j} ; step3.修改从v出发到集合V-S上任一顶点vk可达的最短路径长度。如果D[j] +arcs[j][k]<D[k],则修改D[k] =D[j] +arcs[j][k]; step4.重复操作step2、step3共n-1次。由此求得从v到图上其余各顶点的最短路径是依路径长度递增的序列。 思路: 1.Dijkstra: 按路径长度递增的次序产生最短路径 。 2.用向量D[i]表示当前所找到的从源点v到每个终点vi 的最短路径的长度。它的初态为:若从v到vi 有弧,则D[i]为弧上权值;否则为无穷大。这时,长度为D[j] = Min(i){D[i] | vi 属于V}的路径就是从v出发的长度最短的一条最短路径。设为(v, vj)。 3. 设S为已求得最短路径的终点的集合,则下一条最短路径(设其终点为x)或者是弧(v, x ),或者是中间只经过S中的顶点而最后到达顶点x的路径。即下一条长度次短的最短路径的长度为D[j] = Min(i){D[i] | vi 属于V-S},其中,D[i]或者是弧(v, vi ) 上的权值,或者是D[k] (vi 属于S)和弧(vi, vk )上的权值之和。")
238
V1 V5 V2 V3 V0 V4 10 100 5 30 20 50 60 7.4图的应用(续) 终点 从v0 到各终点的D值和最短路径的求解过程 i=1 i=2 i=3 i=4 i=5 v1 无穷大 无穷大(无) v2 10 (v0 , v2 ) v3 60 (v0 , v2 , v3 ) 50 (v0 , v4 , v3 ) v4 30 (v0 , v4 ) v5 100 (v0 , v5 ) 90 (v0 , v4 , v5 ) 60(v0 , v4 , v3 , v5) vj S {v0 , v2 } {v0 , v2 , v4 } {v0 , v2 , v3 , v4 } {v0 , v2 , v3 , v4 , v5} 10 (v0 , v2 ) 50 (v0 , v4 , v3 ) 30 (v0 , v4 ) 60(v0 , v4 , v3 , v5)
 v2. 10 (v0 , v2 ) v3. 60 (v0 , v2 , v3 ) 50 (v0 , v4 , v3 ) v4. 30 (v0 , v4 ) v (v0 , v5 ) 90 (v0 , v4 , v5 ) 60(v0 , v4 , v3 , v5) vj. S. {v0 , v2 } {v0 , v2 , v4 } {v0 , v2 , v3 , v4 } {v0 , v2 , v3 , v4 , v5} 10 (v0 , v2 ) 50 (v0 , v4 , v3 ) 30 (v0 , v4 ) 60(v0 , v4 , v3 , v5)")
239
7.4图的应用(续) 每一对顶点之间的最短路径 两种方法: *每次以一个顶点为源点,重复执行Dijkstra算法n次,便
可求得每一对顶点之间最短路径。T(n) = O(n3) *Floyd算法。 T(n) = O(n3)
 = O(n3) *Floyd算法。 T(n) = O(n3)")
240
教学内容---第八章 1.绪论 2.线性表 3.栈、队列和串 4.数组 5.广义表 6.树和二叉树 7.图 8.动态存储管理 9.查找
10.内部排序 11.外部排序 12.文件

241
8.1概述 动态存储管理的基本问题: *系统如何应用户提出的“请求”分配内存;
*系统如何回收那些用户不再使用而“释放”的内存,以备新的 “请求”产生 时重新进行分配 占用块:系统已分配给用户使用的地址连续的内存区 可利用空间块(空闲块):未曾分配的地址连续的内存区 系统运行初期,整个内存基本上分隔成两部分:低地址区包含若干占用块;高地址区(分配后剩余部分)是一个“空闲块”. 多次“请求---分配---释放”后,内存区呈现出占用块和空闲块犬牙交错状态.当有新“请求”时,系统有两种策略: *系统继续从高地址空闲块中进行分配,直到剩余空闲不能满足分配请求 而分配无法进行时,系统才回收所有不再使用的空闲块,重新组织内存, 将所有空闲区域连接一起成为大的空闲块; *用户一旦运行结束,便将它所占内存区释放成空闲块,当有新“请求”时,系 统巡视整个内存区中所有空闲块,从中找出一个“合适”空闲块“分配之.
:未曾分配的地址连续的内存区. 系统运行初期,整个内存基本上分隔成两部分:低地址区包含若干占用块;高地址区(分配后剩余部分)是一个 空闲块 . 多次 请求---分配---释放 后,内存区呈现出占用块和空闲块犬牙交错状态.当有新 请求 时,系统有两种策略: *系统继续从高地址空闲块中进行分配,直到剩余空闲不能满足分配请求. 而分配无法进行时,系统才回收所有不再使用的空闲块,重新组织内存, 将所有空闲区域连接一起成为大的空闲块; *用户一旦运行结束,便将它所占内存区释放成空闲块,当有新 请求 时,系. 统巡视整个内存区中所有空闲块,从中找出一个 合适 空闲块 分配之.")
242
8.1概述(续) 对于第二种策略,系统需要建立一张记录所有空闲块的“可利用空间表”.此表的结构有两种:目录表和链表 目录表 链表
10,000 25,000 31,000 39,000 59,000 99,999 目录表 起始地址 内存块大小 使用情况 10,000 15,000 空闲 31,000 8,000 59,000 41,000 链表 8,000 41,000 ^ 15,000

243
8.2可利用空间表及分配回收方法 只讨论链表形式存储的可利用空间表组织及分配方法
分配与释放基本思路:用户请求时,系统从链表中删除一个结点分配之;用户释放时,系统回收该空间并将它插入到链表中 这种可利用空间表可以看作“存储池”,有三种结构形式: *系统运行期间所有用户请求分配的存储量大小相同。以“链 栈”形式组织,即分配和释放空间只对链表表头结点操作. *用户请求分配的存储量有若干种大小的规格。建立若干个 可利用空间表,同一链表中结点大小相同.每个链表仍然以 “链栈”形式组织,但当请求空间所对应链表为空时,需查询结 点较大的链表,从中取一个结点,将其中一部分内存分配给用 户,将剩余部分插入到相应大小的链表中 *系统运行期间分配给用户的内存块大小不固定。初始状况 下,链表中只有一个结点,随着分配和回收的进行,可利 用空间表中结点大小和个数也随之变化。有三种分配策略

244
8.2可利用空间表及分配回收方法(续) 设用户需大小为n的内存,当可利用表中有多个不小于n的空闲块时,实际分配那一块由分配策略决定。
8,000 41,000 ^ 15,000 用户申请7K的内存 8,000 41,000 ^

245
8.2可利用空间表及分配回收方法(续) 最佳拟合法:将可利用空间表中一个不小于n且最接近n的空闲块的一部分分配给用户。为此,分配前系统必须先找到满足要求的空闲块的位置。所以,有时候为了查找方便,可以预先设定可利用空间表的结构按空间块大小自小至大有序。回收时,将释放的空闲块插入到链表中合适的位置上去(仍然保证有序) 8,000 41,000 ^ 15,000 用户申请7K的内存 1,000 41,000 ^ 15,000
 8, ,000. ^ 15,000. 用户申请7K的内存. 1, ,000. ^ 15,000.")
246
8.2可利用空间表及分配回收方法(续) 最差拟合法:将可利用空间表中一个不小于n且链表中最大的空闲块的一部分分配给用户。为此,分配前系统必须先找到满足要求的空闲块的位置。所以,有时候为了查找方便,可以预先设定可利用空间表的结构按空间块大小自大至小有序。回收时,将释放的空闲块插入到链表中合适的位置上去(仍然保证有序) 8,000 41,000 ^ 15,000 用户申请7K的内存 8,000 34,000 ^ 15,000
 8, ,000. ^ 15,000. 用户申请7K的内存. 8, ,000. ^ 15,000.")
247
8.2可利用空间表及分配回收方法(续) 最佳拟合法适用于请求分配的内存大小范围较广的系统。可以保留很大内存块以备响应后面将发生的内存量特大的请求 最差拟合法适用于请求分配的内存大小范围较窄的系统。 首次拟合法适用于系统事先不掌握运行期间可能出现的请求分配和释放的信息的情况。 选择那种方法要综合考虑下列因素:用户的逻辑要求;请求分配量的大小分布;分配和释放的效率等 回收空闲块时要考虑“结点合并”,否则会出现大量碎片,以致后来出现的大容量的请求分配无法进行。一般在回收过程中进行空闲块合并,有多种策略。 下面具体介绍两种实际使用的存储管理方法: *边界标识法 *伙伴系统

248
8.2可利用空间表及分配回收方法(续) 边界标识法 一种适用于系统运行期间分配给用户的内存块大小不固定情况下的存储管理方法。
操作系统的一种实际的存储空间分配、释放管理的方法。 可利用空间表是一个双重循环链表;每个结点头部和底部两个边界上分别设有标识该区域为占用块或空闲块的标志域。 分配可以采用首次拟合法或者最佳拟合法。 回收用户释放空闲块时,通过分别判定其相邻结点头部和底部标志域来确定是否要合并结点,从而将所有地址连续的空闲存储区组合成一个尽可能大的空闲块。

249
8.2可利用空间表及分配回收方法(续) 边界标识法中结点结构 结点结构由三部分组成: *space为一块连续存储单元;
*head为头部,包括指向前驱结点域 llink、标志域tag、space大小size、指 向后继结点域rlink *foot为底部,包括指向本结点域 uplink (空闲块首地址)、 标志域tag space size tag uplink rlink llink head foot 15,000 8,000 41,000
、 标志域tag. space. size. tag. uplink. rlink. llink. head. foot. 15,000. 8, ,000.")
250
8.2可利用空间表及分配回收方法(续) 边界标识法中分配算法 可以采用多种分配方法,具体过程与方法有关。假设采用首
次拟合法。设请求分配存储量为n。边界标识法作了两点规定: 找到合适空闲块为m,分配容量n后:若剩余的m-n<=e,就将m的空闲块整块都分配给用户;反之,只分配n,其余待用。 每次分配后,从不同结点开始进行查找,使分配后剩余的小块均匀分布在链表中。一般,令头指针指向刚进行过分配的结点的后继结点。 8,000 41,000

251
8.2可利用空间表及分配回收方法(续) 边界标识法中回收算法 一旦用户释放占用块,系统需立即回收以备再分配
检查刚释放占用块的左、右紧邻是否为空闲块,然后分情况采取合理策略合并相邻空闲块以形成最大地址连续空闲区域 *释放块的左、右邻区均为占用块。插入新空闲块到链表中 *释放块的左邻区为空闲块,右邻区为占用块。改变左邻空闲 块的结点:增加结点的size域的值且重新设置结点的底部, 头部不变,不需要改变指针 *释放块的右邻区为空闲块,左邻区为占用块。改变右邻空闲 块的结点:增加结点的size域的值且重新设置结点的头部, 这时指针也要变 *释放块的左、右邻区均为空闲块。改变左邻空闲块的结点: 增加结点的size域的值且重新设置结点的底部;删除右邻块

252
8.2可利用空间表及分配回收方法(续) 伙伴系统 操作系统的另一种实际的存储空间分配、释放管理的方法。
请求时分配,回收时释放,必要时合并连续空间。 占用块或空闲块大小均为2的k次幂(k为某个正整数)。 用户申请n个单元的内存区时,分配的占用块大小为2k个单元(2k-1 <n<=2k)。 若总的可利用内存容量为2m个单元,则空闲块的大小只可能是20、21 、…、2m 。 可利用空间表 = 向量+双向链表。 *大小相同的空闲块组成一个双向链表,共有m+1个链表; *这m+1个双向链表的表头指针形成一个向量
。 用户申请n个单元的内存区时,分配的占用块大小为2k个单元(2k-1 <n<=2k)。 若总的可利用内存容量为2m个单元,则空闲块的大小只可能是20、21 、…、2m 。 可利用空间表 = 向量+双向链表。 *大小相同的空闲块组成一个双向链表,共有m+1个链表; *这m+1个双向链表的表头指针形成一个向量.")
253
8.2可利用空间表及分配回收方法(续) 伙伴系统结点结构 双向链表结点结构由两部分组成: *head为头部,包括指向前驱结点域
llink、标志域tag、2的幂次k的值域 kval、指向后继结点域rlink *space为一块大小为2k -1连续存储单元 表头向量每个分量由两个域组成: *指向链表起始位置的指针域 *表示该链表中空闲块大小的nodesize域 space kval rlink link tag head 2k 2k -1 … 20 2m K

254
8.2可利用空间表及分配回收方法(续) 伙伴系统分配算法
当用户提出大小为n的内存请求时,首先在可利用表上寻找结点大小与n相匹配的子表,若此子表非空,则将子表中任意一个结点分配之即可;若此子表为空,则需从结点更大的非空子表中去查找,直至找到一个空闲块,则将空间的一半分配给用户,而将剩余一半插入相应的子表中 两个由同一大块分裂出来的小块称为“互为伙伴”。它们地址空间相连。

255
8.2可利用空间表及分配回收方法(续) 伙伴系统回收算法
释放空间后系统要回收空闲块到可利用空间表中去。同时,也要对地址相邻的空闲块进行合并。 伙伴系统回收空闲块时,只当其伙伴为空闲块时才归并成大块。其他情况下,即使空闲块相邻,也不合并 回收时,首先判断其伙伴是否为空闲块,若否,只要简单插入到相应子表中即可;若是,则需在相应子表中找到其伙伴并删除之,然后在判别合并后的空闲块的伙伴是否是空闲块。依次重复,直至归并所得空闲块的伙伴不是空闲块时,再插入到相应子表中去。

256
8.3无用单元收集 当用户明确提出“分配”和“回收”空间时,可以采用前述方法和策略来进行存储管理
由于用户疏漏或结构本身原因致使系统没有进行回收或恰当回收而产生“无用单元”或“悬挂访问” “无用单元”是指那些用户不再使用而系统没有回收的结构和变量 “悬挂访问”是指回收后的单元可以被用户访问到而导致不可预期的结果(当单元被共享时,往往出现这种情况) 两条途径可以解决上述问题:访问计数器;收集无用单元. 收集无用单元:在程序运行过程中,直到整个可利用空间表为空时,才回收结点.这时,将所有当前不被使用的结点链接在一起成为一个新的可利用空间表,而后程序继续运行 无用单元收集效率与当前无用结点个数有关,个数越少,效率越低. 一般系统确定一个系数k,当收集到的无用单元个数小于等于k时,系统就不再运行下去
 两条途径可以解决上述问题:访问计数器;收集无用单元. 收集无用单元:在程序运行过程中,直到整个可利用空间表为空时,才回收结点.这时,将所有当前不被使用的结点链接在一起成为一个新的可利用空间表,而后程序继续运行. 无用单元收集效率与当前无用结点个数有关,个数越少,效率越低. 一般系统确定一个系数k,当收集到的无用单元个数小于等于k时,系统就不再运行下去.")
257
8.4存储紧缩 用“堆”来提供可利用空间 堆是一块地址连续的存储区 用“存储映象表”来存储堆中的各个用户占用空间的情况
“分配”时从堆中划出一块.一般从“堆指针”开始划出n个连续单元,然后重新修改堆指针 “回收”时必须将所释放的空闲块合并到整个堆上去才能重新使用.这就是“存储紧缩”的任务 存储紧缩有两种做法: *一旦用户释放存储块即进行回收紧缩.同时修改存储映象; *程序执行过程中不回收用户随时释放的存储块,直到可利 用空间不够分配或堆指针指向最高地址时才进行存储紧缩, 将堆中所有的空闲块连成一片,堆指针指向该空闲块起始位 置.这时再修改整个存储映象表.

258
教学内容---第九章 1.绪论 2.线性表 3.栈、队列和串 4.数组 5.广义表 6.树和二叉树 7.图 8.动态存储管理 9.查找
10.内部排序 11.外部排序 12.文件

259
9.1查找的概念和思路 基本概念和术语 查找表(Search Table):同一类型的数据元素组成的集合。
静态查找表(Static Search Table): 若对查找表只作“查找”操作(查询某个“特定的”数据元素是否在表中并检查该数据元素各种属性),则称此类查找表为静态查找表。 动态查找表(Dynamic Search Table): 若对查找表不仅作“查找”操作,而且在查找过程中同时插入查找表中不存在的数据元素,或者从查找表中删除已经存在的某个数据元素,则称此类查找表为动态查找表。 查找(Searching): 在一个含有众多数据元素的查找表中找出某个“特定的”数据元素。(以关键字为依据) 关键字(Key): 数据元素中某个数据项的值,用它可以标识一个数据元素。 主关键字(Primary Key): 若关键字可以唯一标识一个数据元素,则称此关键字为主关键字。 次关键字(Secondary Key): 用以标识若干数据元素的关键字
: 若对查找表只作 查找 操作(查询某个 特定的 数据元素是否在表中并检查该数据元素各种属性),则称此类查找表为静态查找表。 动态查找表(Dynamic Search Table): 若对查找表不仅作 查找 操作,而且在查找过程中同时插入查找表中不存在的数据元素,或者从查找表中删除已经存在的某个数据元素,则称此类查找表为动态查找表。 查找(Searching): 在一个含有众多数据元素的查找表中找出某个 特定的 数据元素。(以关键字为依据) 关键字(Key): 数据元素中某个数据项的值,用它可以标识一个数据元素。 主关键字(Primary Key): 若关键字可以唯一标识一个数据元素,则称此关键字为主关键字。 次关键字(Secondary Key): 用以标识若干数据元素的关键字.")
260
9.1查找的概念和思路(续) 基本概念和术语 查找成功(Searching Success): 根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素。若表中存在这样的一个元素,则称查找成功,查找结果为整个元素信息或者指示该元素在查找表中的位置。 查找不成功(Searching Failed): 一次查找过程中,若查找表中不存在关键字等于给定值的元素,则称查找不成功,查找结果为一个空元素或者一个空指针。 查找成功时平均查找长度: 为确定元素在查找表中的位置,需和给定值进行比较的关键字个数的期望值称为查找算法在查找成功时平均查找长度。 查找不成功平均查找长度: 查找不成功时和给定值进行比较的关键字个数的期望值称为在查找不成功时平均查找长度。 平均查找长度(Average Search Length):查找算法在查找成功时平均查找长度和查找不成功时平均查找长度之和。
: 一次查找过程中,若查找表中不存在关键字等于给定值的元素,则称查找不成功,查找结果为一个空元素或者一个空指针。 查找成功时平均查找长度: 为确定元素在查找表中的位置,需和给定值进行比较的关键字个数的期望值称为查找算法在查找成功时平均查找长度。 查找不成功平均查找长度: 查找不成功时和给定值进行比较的关键字个数的期望值称为在查找不成功时平均查找长度。 平均查找长度(Average Search Length):查找算法在查找成功时平均查找长度和查找不成功时平均查找长度之和。")
261
9.1查找的概念和思路(续) 基本思路 查找表中元素关系松散,直接在原始查找表中查找的效率很低。
查找一般思路:向查找表上依附其他数据结构,使查找表中数据元素之间关系约束增加,从而利于查找过程的进行。 根据依附的数据结构不同,可以有不同的查找过程、查找特点和查找性能。 依附数据结构的选择取决于问题域特点和查找表本身特性。

262
9.2静态查找表 抽象数据类型定义 ADT StaticSearchTable {
数据对象:V={具有相同性质的数据元素,各个数据元素均含有类型相同,可唯一标识数据元素的关键字} 数据关系:R: 集合关系 基本操作:P: Create(&ST,n); Destroy(&ST); Search(ST,key); Traverse(ST,Visit()) }ADT StaticSearchTable
; Destroy(&ST); Search(ST,key); Traverse(ST,Visit()) }ADT StaticSearchTable.")
263
线性链表查找=查找表+线性表+链式存储;
9.2静态查找表(续) 顺序表的查找 顺序表查找=查找表+线性表+顺序存储 顺序查找 // 静态查找表存储表示 typedef struct { ElemType *elem; //0号单元留空 int length; }SSTable; 线性链表查找=查找表+线性表+链式存储;
 顺序表的查找. 顺序表查找=查找表+线性表+顺序存储. 顺序查找. // 静态查找表存储表示 typedef struct { ElemType *elem; //0号单元留空. int length; }SSTable; 线性链表查找=查找表+线性表+链式存储;")
264
9.2静态查找表(续) 顺序表的查找 顺序查找(Sequential Search)过程:
int Search_Seq(SSTable ST, KeyType key ){ //若找到,含数值为该元素在表中的位置,否则为0 ST.elem[0].key = key; // “哨兵” for (i =ST.length; !EQ(ST.elem[i].key, key); --i ); //从后往前找 return i ; //找不到,i为0(这也是哨兵的作用所在) } Search_Seq 顺序查找(Sequential Search)过程: 从表中最后一个元素开始,逐个进行元素的关键字和给定值的比较,若某个元素的关键字和给定值相等,则查找成功,找到所查元素;反之,若直至第一个记录,其关键字和给定值比较都不等,则表明表中没有所查元素,查找不成功 。 顺序查找的优点: *算法简单、适用面广; *对线性关系没有其他要求; *对存储结构没有要求 性能分析: n = ST.length; Pi = 1/n, qi = 1/n (假设的前提) ASLss成功 = nP1+(n-1)P2+…+2Pn-1+Pn =(n+1)/2 ASLss不成功 = (n+1)(q1+q2+…+qn-1+qn )=n+1 顺序查找的缺点: *平均查找长度大;
{ //若找到,含数值为该元素在表中的位置,否则为0. ST.elem[0].key = key; // 哨兵 for (i =ST.length; !EQ(ST.elem[i].key, key); --i ); //从后往前找. return i ; //找不到,i为0(这也是哨兵的作用所在) } Search_Seq. 顺序查找(Sequential Search)过程: 从表中最后一个元素开始,逐个进行元素的关键字和给定值的比较,若某个元素的关键字和给定值相等,则查找成功,找到所查元素;反之,若直至第一个记录,其关键字和给定值比较都不等,则表明表中没有所查元素,查找不成功 。 顺序查找的优点: *算法简单、适用面广; *对线性关系没有其他要求; *对存储结构没有要求. 性能分析: n = ST.length; Pi = 1/n, qi = 1/n (假设的前提) ASLss成功 = nP1+(n-1)P2+…+2Pn-1+Pn =(n+1)/2. ASLss不成功 = (n+1)(q1+q2+…+qn-1+qn )=n+1. 顺序查找的缺点: *平均查找长度大;")
265
有序表查找=查找表+线性表+有序性+顺序存储
9.2静态查找表(续) 有序表的查找 有序表查找=查找表+线性表+有序性+顺序存储 // 静态查找表存储表示 typedef struct { ElemType *elem; //0号单元留空 int length; }SSTable; 四种查找方法: *折半查找 *顺序查找 *斐波那契查找 *插值查找
 有序表的查找. 有序表查找=查找表+线性表+有序性+顺序存储. // 静态查找表存储表示 typedef struct { ElemType *elem; //0号单元留空. int length; }SSTable; 四种查找方法: *折半查找 *顺序查找. *斐波那契查找 *插值查找.")
266
9.2静态查找表(续) 有序表的折半查找 折半查找(Binary Search)过程:
int Search_Bin(SSTable ST, KeyType key ){ //若找到,含数值为该元素在表中的位置,否则为0 low =1; high = ST.length; //置区间初值 while (low < high) { mid = (low+high)/2; if EQ(key, ST.elem[mid].key) return mid; //查找成功,返回位置 else if LT(key, ST.elem[mid].key) high = mid – 1; //继续在前半区间 else low = mid +1; //继续在后半区间查找 } return 0; //查找失败 } Search_Bin 折半查找(Binary Search)过程: 先确定待查元素所在范围(区间),然后逐步缩小范围直到找到或找不到该元素为止 。具体而言,折半查找是以处于区间中间位置记录的关键字和给定值比较,若相等,则查找成功,若不等,则缩小范围,直至新的区间中间位置记录的关键字等于给定值或者查找区间的大小小于零时(表明查找不成功)为止。
{ //若找到,含数值为该元素在表中的位置,否则为0. low =1; high = ST.length; //置区间初值. while (low < high) { mid = (low+high)/2; if EQ(key, ST.elem[mid].key) return mid; //查找成功,返回位置. else if LT(key, ST.elem[mid].key) high = mid – 1; //继续在前半区间. else low = mid +1; //继续在后半区间查找. } return 0; //查找失败 } Search_Bin. 折半查找(Binary Search)过程: 先确定待查元素所在范围(区间),然后逐步缩小范围直到找到或找不到该元素为止 。具体而言,折半查找是以处于区间中间位置记录的关键字和给定值比较,若相等,则查找成功,若不等,则缩小范围,直至新的区间中间位置记录的关键字等于给定值或者查找区间的大小小于零时(表明查找不成功)为止。")
267
9.2静态查找表(续) 有序表的折半查找 设给定值key = 21,则查找过程为:
low high mid low high mid low high mid

268
9.2静态查找表(续) 有序表的折半查找 一个位置查找成功或者失败与查找表中元素值无关,只与元素位置有关。 2 6 3 1 4 5 9 7
2 6 3 1 4 5 9 7 11 8 10 设给定值key = 21,则查找路径为: 设给定值key = 85,则查找路径为:

269
9.2静态查找表(续) 折半查找过程中,找到有序表中任何一个元素的过程就是走了一条根结点到与该元素相应的结点的路径,和给定值比较的关键字个数恰为该结点在判定树上的层次数。 性能分析: 假定有序表长度n = 2h-1, Pi = 1/n ASLbs成功 = (1/n)*(1*1+2*2+…+h*(2h-1)) =((n+1)/n)*log2(n+1)-1 当n=11时: ASLbs成功 =(1*1+2*2+3*4+4*4)/11 =3 2 6 3 1 4 5 9 7 11 8 10
*(1*1+2*2+…+h*(2h-1)) =((n+1)/n)*log2(n+1)-1. 当n=11时: ASLbs成功 =(1*1+2*2+3*4+4*4)/11. =")
270
9.2静态查找表(续) 2 6 3 1 4 5 9 7 11 8 10 如下图:方形结点为构造的判定树的外部结点。
折半查找查找不成功的过程就是走了一条根结点到外部结点的路径,和给定值进行比较的关键字个数等于该路径上内部结点的个数。 当n=11时: ASLbs不成功 =(3*4+4*8)/12 =11/3 折半查找的优点: *效率高; 2 6 3 1 4 5 9 7 11 8 10 10-11 9-10 11- 6-7 7-8 8-9 3-4 -1 5-6 4-5 2-3 1-2 折半查找的缺点: *只适用于有序 表 *限于顺序存储
/12 =11/3. 折半查找的优点: *效率高; 折半查找的缺点: *只适用于有序. 表. *限于顺序存储.")
271
9.2静态查找表(续) 有序表的顺序查找 有序表顺序查找过程:
从表中第一个元素开始,逐个进行元素的关键字和给定值的比较,若某个元素的关键字和给定值相等,则查找成功,找到所查元素;反之,由于查找表中元素本来有序(设为从小到大有序),如给定值比某个元素关键字小,则表明表中没有所查元素,查找不成功 。 性能分析: n = ST.length; Pi = 1/n, qi = 1/(n+1) (假设的前提) ASLss成功 = nP1+(n-1)P2+…+2Pn-1+Pn =(n+1)/2 ASLss不成功 = 1q1+2q2+…+(n-1)qn-1+nqn +(n+1)qn+1 =(n+2)/2
,如给定值比某个元素关键字小,则表明表中没有所查元素,查找不成功 。 性能分析: n = ST.length; Pi = 1/n, qi = 1/(n+1) (假设的前提) ASLss成功 = nP1+(n-1)P2+…+2Pn-1+Pn =(n+1)/2. ASLss不成功 = 1q1+2q2+…+(n-1)qn-1+nqn +(n+1)qn+1 =(n+2)/2.")
272
9.2静态查找表(续) 有序表的斐波那契查找 斐波那契序列:F0 =0, F1 =1, Fi = Fi-1 + Fi-2 ,i>=2
斐波那契查找过程: 根据斐波那契序列对表进行分割。假设开始时表中元素个数比某个斐波那契数小1,即n = Fu –1,然后将给定值key和ST.elem[Fu-1].key进行比较,若相等,则查找成功;若key< ST.elem[Fu-1].key,则继续在自ST.elem[1]至ST.elem[Fu-1 -1]的子表中进行查找,否则继续在自ST.elem[Fu-1 +1]至 ST.elem[Fu -1]的子表中进行查找,后一子表的长度为Fu-2 –1。 平均性能比折半查找好,但最坏情况下性能比折半查找差。

273
9.2静态查找表(续) 有序表的插值查找 查找查找思想:
根据给定值key来确定进行比较的关键字ST.elem[i].key。令i= (key-ST.elem[L].key)(h-L+1)/(ST.elem[h].key-ST.elem[L].key),其中ST.elem[L]和ST.elem[h]分别为有序表中具有最小关键字和最大关键字的元素。 适用于关键字均匀分布的表;表长较大时,平均性能比折半查找好。
(h-L+1)/(ST.elem[h].key-ST.elem[L].key),其中ST.elem[L]和ST.elem[h]分别为有序表中具有最小关键字和最大关键字的元素。 适用于关键字均匀分布的表;表长较大时,平均性能比折半查找好。")
274
索引顺序查找=查找表+线性表+分块有序性
9.2静态查找表(续) 索引顺序表的查找 索引顺序查找=查找表+线性表+分块有序性 索引顺序表特征: 索引顺序表包括顺序表和索引表两部分。顺序表分成若干子表(块),每个子表对应索引表中一个索引项。每个索引项包括两部分:关键字项(其值为该子表内的最大关键字)和指针项(指示该子表的第一个元素在表中位置)。索引表按关键字有序,顺序表分块有序(第i个子表中所有元素关键字均大于第i-1个子表中最大关键字,i从2至b(b为子表个数))。 分块查找过程分两步 :第一步确定待查元素所在块,第二步在块中顺序查找。
 索引顺序表的查找. 索引顺序查找=查找表+线性表+分块有序性. 索引顺序表特征: 索引顺序表包括顺序表和索引表两部分。顺序表分成若干子表(块),每个子表对应索引表中一个索引项。每个索引项包括两部分:关键字项(其值为该子表内的最大关键字)和指针项(指示该子表的第一个元素在表中位置)。索引表按关键字有序,顺序表分块有序(第i个子表中所有元素关键字均大于第i-1个子表中最大关键字,i从2至b(b为子表个数))。 分块查找过程分两步 :第一步确定待查元素所在块,第二步在块中顺序查找。")
275
9.2静态查找表(续) 索引顺序表的查找 性能分析: (将长度为n的表均匀分为b块,每块s个元素) ASLbs = Lb+Lw
块中查找元素的平均查找长度。 若用顺序查找确定所在块,则有 ASLbs = Lb+Lw=(b+1)/2+(s+1)/2=(n/s+s)/ 当(n/s)=s,即s= n开根号时, ASLbs最小=(n开根号+1) 若用折半查找确定所在块,则有 ASLbs = Lb+Lw 约等于 log2(n/s+1)+s/2
/2+(s+1)/2=(n/s+s)/2+1 当(n/s)=s,即s= n开根号时, ASLbs最小=(n开根号+1) 若用折半查找确定所在块,则有. ASLbs = Lb+Lw 约等于 log2(n/s+1)+s/2.")
276
9.3动态查找表 抽象数据类型定义 ADT DynamicSearchTable {
数据对象:V={具有相同性质的数据元素,各个数据元素均含有类型相同,可唯一标识数据元素的关键字} 数据关系:R: 集合关系 基本操作:P: InitDSTable(&DT); DestroyDSTable(&DT); SearchDSTable(DT,key); InsertDSTable(&DT,e); TraverseDSTable(DT,Visit()) }ADT DynamicSearchTable
; DestroyDSTable(&DT); SearchDSTable(DT,key); InsertDSTable(&DT,e); TraverseDSTable(DT,Visit()) }ADT DynamicSearchTable.")
277
二叉排序树查找=查找表+二叉树+BST性质
9.3动态查找表(续) 二叉排序树的查找 二叉排序树查找=查找表+二叉树+BST性质 二叉排序树(Binary Sort Tree):或者是一棵空树;或者具有BST性质:(1)若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; (2)若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; (3) 它的左、右子树也分别为二叉排序树(BST树)。BST树也称为二叉查找树。 平衡二叉树(Balanced Binary Tree或Height-Balanced Tree):或者是一棵空树;或者具有AVL性质:它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1 。平衡二叉树也称为AVL树。 平衡因子(Balance Factor):该结点的左子树的深度减去它的右子树的深度。
 二叉排序树的查找. 二叉排序树查找=查找表+二叉树+BST性质. 二叉排序树(Binary Sort Tree):或者是一棵空树;或者具有BST性质:(1)若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; (2)若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; (3) 它的左、右子树也分别为二叉排序树(BST树)。BST树也称为二叉查找树。 平衡二叉树(Balanced Binary Tree或Height-Balanced Tree):或者是一棵空树;或者具有AVL性质:它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1 。平衡二叉树也称为AVL树。 平衡因子(Balance Factor):该结点的左子树的深度减去它的右子树的深度。")
278
9.3动态查找表(续) 二叉排序树查找过程 Status SearchBST(BiTree T, KeyType key,BiTree f,BiTree &p ){ //从根指针T所指二叉排序树中递归地查找某关键字等于key的数据元素若查 //找成功,则指针p指向该数据元素结点,并返回TRUE,否则p指向查找路径 //上访问的最后一个结点并返回FALSE,f是T的双亲,初值为NULL if(!T) { p =f; return FALSE;} //查找不成功 else if EQ(key,T->data.key) {p =T; return TRUE; } //查找成功 else if LT(key,T->data.key) SearchBST(T->lchild, key, T, p); //在左子树查找 else SearchBST(T->rchild, key, T, p); //在右子树中继续查找 } //SearchBST 8 20 10 5 30 23 40 35 设给定值key = 5,则查找路径为: 设给定值key = 38,则查找路径为: BST树上的查找为动态查找,在查找失败时,要在失败的位置插入关键字为待查关键字的数据元素。 查找失败的位置在叶子处,插入位置也在叶子位置,当采用二叉链表存储BST树时,插入新元素时不需要移动其他元素,仅需修改指针即可。 38
 { p =f; return FALSE;} //查找不成功. else if EQ(key,T->data.key) {p =T; return TRUE; } //查找成功. else if LT(key,T->data.key) SearchBST(T->lchild, key, T, p); //在左子树查找. else SearchBST(T->rchild, key, T, p); //在右子树中继续查找. } //SearchBST 设给定值key = 5,则查找路径为: 设给定值key = 38,则查找路径为: BST树上的查找为动态查找,在查找失败时,要在失败的位置插入关键字为待查关键字的数据元素。 查找失败的位置在叶子处,插入位置也在叶子位置,当采用二叉链表存储BST树时,插入新元素时不需要移动其他元素,仅需修改指针即可。 38.")
279
9.3动态查找表(续) BST树上建树的过程,就是查找失败时元素不断插入的过程。 初始序列中元素的次序直接决定了BST树的结构。 初始序列: 空树 35 8 20 10 5 30 23 5 23 30 20 10 20 20 10 30 20 10 8 20 10 5 30 23 40 35 8 20 10 5 30 23 23 30 20 10

280
9.3动态查找表(续) 二叉排序树上结点删除 S F C CL PR SL S F C P Q CL PR QL SL PL CL F C
… 二叉排序树上结点删除 S F C P Q CL PR QL SL … 设BST树上被删除结点指针为p,其左、右子树分别表示为PL和PR,其双亲结点指针为f,不失一般性,设*p为*f的左孩子。则有: PL 1.若*p为叶子结点,直接删除; 2.若*p只有左子树PL或者只有右子树PR,删除*p后令PL或PR直接成为其双亲结点*f的左子树即可; 3.若*p左子树PL和右子树PR均不为空。有两种做法:其一是令*p的左子树为*f的左子树,而*p的右子树为*p中序序列直接前驱*s的右子树;其二是令*p中序序列直接前驱*s替代*p,然后令*s的左子树为*s的双亲*q的右子树。 CL F C S Q PR QL SL …

281
9.3动态查找表(续) 二叉排序树查找性能分析 8 20 10 5 30 23 40 35 BST查找过程中,找到中任何一个元素的过程就是走了一条根结点到与该元素相应的结点的路径,和给定值比较的关键字个数恰为该结点在BST树上的层次数。查找不成功的过程就是走了一条根结点到外部结点的路径,和给定值进行比较的关键字个数等于该路径上内部结点的个数。 30-35 10-20 5-8 8-10 <5 23-30 20-23 35-40 >40 BST树上查找成功和查找不成功的ASL与BST树的结构有关,而树的结构与初始序列构造有关。即含有n个结点的二叉排序树不唯一。效率最高的情况为BST为一棵平衡二叉树的时候。 ASLbst成功 =(1*1+2*2+3*3+4*2)/8=11/4 ASLbst不成功 =(1*2+3*4+4*4)/9=10/3
/8=11/4. ASLbst不成功 =(1*2+3*4+4*4)/9=10/3.")
282
9.3动态查找表(续) BST树平衡化过程 由初始序列建立BST树的过程中若因为插入一个结点而导致了当前树不平衡,则应该调整其平衡。这个过程即是BST树初始平衡化过程。在查找过程中,如查找失败,当在失败位置处插入失败元素而引起树的不平衡,也应该调整其平衡。这就是BST平衡化。 假设由于在二叉排序树上插入结点而失去平衡的最小子树根结点的指针为a(即a是离插入结点最近,且平衡因子绝对值超过1的祖先结点),则失去平衡后进行调整有四中情况: 1.单向右旋转(LL):由于在*a的左子树根结点的左子树上插入结点而导致以*a为根的子树失去平衡,则需进行向右一次顺时针旋转操作; 2.单向左旋转(RR):由于在*a的右子树根结点的右子树上插入结点而导致以*a为根的子树失去平衡,则需进行向左一次逆时针旋转操作; 3.双向先左后右旋转(LR):由于在*a的左子树根结点的右子树上插入结点而导致以*a为根的子树失去平衡,则需进行先左旋转后右旋转两次操作; 4.双向先右后左旋转(RL):由于在*a的右子树根结点的左子树上插入结点而导致以*a为根的子树失去平衡,则需进行先右旋转后左旋转两次操作。
,则失去平衡后进行调整有四中情况: 1.单向右旋转(LL):由于在*a的左子树根结点的左子树上插入结点而导致以*a为根的子树失去平衡,则需进行向右一次顺时针旋转操作; 2.单向左旋转(RR):由于在*a的右子树根结点的右子树上插入结点而导致以*a为根的子树失去平衡,则需进行向左一次逆时针旋转操作; 3.双向先左后右旋转(LR):由于在*a的左子树根结点的右子树上插入结点而导致以*a为根的子树失去平衡,则需进行先左旋转后右旋转两次操作; 4.双向先右后左旋转(RL):由于在*a的右子树根结点的左子树上插入结点而导致以*a为根的子树失去平衡,则需进行先右旋转后左旋转两次操作。")
283
初始序列: a a 6 6 2 5 1 4 2 6 1 a 2 LL型 LR型 1 4 3 5 2 1 6 5 3 4 5 2 1 7 6 3 4 a RL型 RR型 7

284
9.3动态查找表(续) 平衡树查找性能分析 性能分析: 查找过程中和给定值进行比较的关键字个数不超过树的深度。
含有n个关键字的平衡树的最大深度为 (见p334参考书目[1]) : Log (1+ 5开根号)/2(5开根号*(n+1)) 平衡树上进行查找的时间复杂度T(n) = O(log2n)。
 : Log (1+ 5开根号)/2(5开根号*(n+1)) 平衡树上进行查找的时间复杂度T(n) = O(log2n)。")
285
B-树查找=查找表+多路平衡树+B-树性质
9.3动态查找表(续) B-树的查找 B-树查找=查找表+多路平衡树+B-树性质 B-树(B- Tree):或者是一棵空树;或者为满足下列特性的m叉树: (1)树中每个结点至多有m棵子树; (2)若根结点不是叶子结点,则至少有两棵子树; (3) 除根之外的所有非终端结点至少有[m/2]棵子树; (4)所有非终端结点中包含下列信息数据(n,A0,K1,A1,K2,A2,…,Kn,An),其中: Ki(i=1,…,n)为关键字,且Ki < Ki+1 (i=1,…,n-1) ; Ai为指向子树根结点的指针,且指针Ai-1所指子树中所有结点的关键字均小于Ki(i=1,…,n) , An所指子树中所有结点的关键字均大于Kn ,n([m/2]-1<=n<=m-1)为关键字个数(n+1为当前结点子树个数) (5)所有叶子结点都出现在同一层次上,并且不带信息。 1 11 2 43 78 47 53 64 3 99 27 39 18 35 F
 B-树的查找. B-树查找=查找表+多路平衡树+B-树性质. B-树(B- Tree):或者是一棵空树;或者为满足下列特性的m叉树: (1)树中每个结点至多有m棵子树; (2)若根结点不是叶子结点,则至少有两棵子树; (3) 除根之外的所有非终端结点至少有[m/2]棵子树; (4)所有非终端结点中包含下列信息数据(n,A0,K1,A1,K2,A2,…,Kn,An),其中: Ki(i=1,…,n)为关键字,且Ki < Ki+1 (i=1,…,n-1) ; Ai为指向子树根结点的指针,且指针Ai-1所指子树中所有结点的关键字均小于Ki(i=1,…,n) , An所指子树中所有结点的关键字均大于Kn ,n([m/2]-1<=n<=m-1)为关键字个数(n+1为当前结点子树个数) (5)所有叶子结点都出现在同一层次上,并且不带信息。 F.")
286
9.3动态查找表(续) #define m 3 //B-树的阶 typedef struct BTNode{
int keynum; //结点中关键字个数 struct BTNode *parent //指向双亲结点 KeyType key[m+1]; //关键字向量,0号单元未用 struct BTNode *ptr[m+1] //子树指针向量 struct BTNode *dataptr[m+1] //元素指针向量, 0号单元未用 }BTNode, *Btree; typedef struct { BTNode *pt; //指向找到的结点 int i; //1..m在结点中的关键字序号 int tag //1:查找成功;0:查找失败 }Result; //B-树的查找结果类型

287
9.3动态查找表(续) Result SearchBTree(Btree T, KeyType K ) { //在m阶B树T上查找关键字K,返回结过(pt,i,tag)。若查找成功,则特征值 //tag=1,指针pt所指结点中第i个关键字等于K;否则特征值tag=0,等于K的关 //键字应插入在指针pt所指结点中第i个和第i+1个关键字之间 p = T; q = NULL; found = FALSE; i = 0; //初始化,p指向待查结点,q指向p双亲 while (p && !found) { n = p->keynum; i = Search(p,K); //在p->key[1..keynum]中查找, //i使得:p->key[i]<=K<=p->key[i+1] if (i>0 && p->key[i] = =K) found = TRUE; //查找待查关键字 else {q =p; p = p->ptr[i]; } }//while if (found) return (p,i,1); //查找成功 else return (q,i,0); //查找不成功,返回K的插入位置信息 } //SearchBTree B-树的查找 B-树上进行查找的过程是一个顺指针查找结点和在结点的关键字中进行查找交叉进行的过程。若某个元素的关键字和给定值相等,则查找成功,找到所查元素; 当查找到某个叶子结点处,查找失败,此时在失败的位置插入关键字为待查关键字的数据元素。插入新元素时不需要移动其他元素,仅需修改指针即可。
 { n = p->keynum; i = Search(p,K); //在p->key[1..keynum]中查找, //i使得:p->key[i]<=K<=p->key[i+1] if (i>0 && p->key[i] = =K) found = TRUE; //查找待查关键字. else {q =p; p = p->ptr[i]; } }//while. if (found) return (p,i,1); //查找成功. else return (q,i,0); //查找不成功,返回K的插入位置信息. } //SearchBTree. B-树的查找. B-树上进行查找的过程是一个顺指针查找结点和在结点的关键字中进行查找交叉进行的过程。若某个元素的关键字和给定值相等,则查找成功,找到所查元素; 当查找到某个叶子结点处,查找失败,此时在失败的位置插入关键字为待查关键字的数据元素。插入新元素时不需要移动其他元素,仅需修改指针即可。")
288
9.3动态查找表(续) B-树查找性能分析 性能分析:
B-树上进行查找包含两步:在B-树中找结点;在结点中找关键字。前一操作在磁盘上进行,后一操作在内存中进行。在磁盘上进行一次查找比在内存中进行一次查找耗费时间多得多,因此,在磁盘上进行查找的次数、即待查关键字所在结点在B-树上的层次数,是决定B-树查找效率的首要因素。 含 n个关键字的m阶B-树的最大深度为: Log m/2取上整 ((n+1)/2) + 1。
/2) + 1。")
289
9.3动态查找表(续) B-树插入 由于B-树结点中的关键字个数必须大于等于m/2取上整-1,小于等于m-1,因此,(查找失败时)每次插入一个关键字时,首先在最低层的某个非终端结点中添加一个关键字,若超过m-1,则产生结点要“分裂”。 分裂方法: 假设*p结点中已有m-1个关键字,当插入一个关键字后,结点中含有信息为:m,A0,(K1,A1),…,(Km,Am),且其中Ki<Ki+1,(1<=i<m),此时可将*p结点分裂为*p和*p’两个结点,其中*p结点中含有信息为: m/2取上整-1, A0,(K1,A1),…,(K m/2取上整-1,A m/2取上整-1); *p’结点中信息为: m-m/2取上整, Am/2取上整,(K m/2取上整+1,Am/2取上整+1),…,(Km,Am) ;而关键字 K m/2取上整和指针*p’一起插入到*p的双亲结点中
,…,(Km,Am),且其中Ki<Ki+1,(1<=i<m),此时可将*p结点分裂为*p和*p’两个结点,其中*p结点中含有信息为: m/2取上整-1, A0,(K1,A1),…,(K m/2取上整-1,A m/2取上整-1); *p’结点中信息为: m-m/2取上整, Am/2取上整,(K m/2取上整+1,Am/2取上整+1),…,(Km,Am) ;而关键字 K m/2取上整和指针*p’一起插入到*p的双亲结点中.")
290
依次插入关键字:30, 26, 85, 7 45 24 3 12 53 90 37 50 61 70 100 b e c d f g h a 插入30 插入26 30 37 45 53 90 50 61 70 100 e f g h a 24 30 3 12 26 37 b c d d’ 分裂结点 插入85

291
9.3动态查找表(续) 分裂结点 45 50 61 100 e f g h a 24 30 3 12 26 37 b c d d’ 85 g’ 再分裂结点 53 45 70 90 50 61 100 e’ f g h a 24 30 3 12 26 37 b c d d’ 85 g’ e

292
9.3动态查找表(续) 53 45 70 90 50 61 100 e’ f g h a 24 30 3 12 26 37 b c d d’ 85 g’ e 插入7 53 45 70 90 50 61 100 e’ f g h a 12 26 37 b c’ d d’ 85 g’ e 3 c 分裂结点

293
9.3动态查找表(续) 再分裂结点 53 24 45 70 90 50 61 100 e’ f g h a 30 12 26 37 b’
c’ d d’ 85 g’ e 3 c 7 b 9.3动态查找表(续) 三次分裂结点 53 45 90 50 61 100 e’ f g h m 30 12 26 37 b’ c’ d d’ 85 g’ e 3 c 7 b 24 70 a a’
 三次分裂结点 e’ f. g. h. m b’ c’ d. d’ 85. g’ e. 3. c. 7. b a. a’")
294
9.3动态查找表(续) B-树删除 B-树中元素的删除分两种情况: *被删除元素Ki所在结点不是最下层的非终端结点。这时将Ki与Ai指
针所指向子树中最小关键字Y交换,然后在相应结点中删除Y; *被删除元素Ki所在结点是最下层的非终端结点。若该结点中关键字 数目不少于m/2取上整,则直接删除即可;否则要进行“合并”结点 的操作。 这两种情况都可以归结到删除最下层非终端结点中关键字的情形。有三种可能性。

295
9.3动态查找表(续) 45 24 3 12 53 90 37 50 61 70 100 b e c d f g h a 被删除元素Ki所在结点不是最下层的非终端结点。这时将Ki与Ai指针所指向子树中最小关键字Y交换,然后在相应结点中删除Y 45 50 45 24 3 12 53 90 37 50 61 70 100 b e c d f g h a 删除12 (1)被删除关键字所在结点中关键字数目不少于m/2取上整,则只需从该结点中删去关键字Ki和相应指针Ai ,树的其余部分不变 3
被删除关键字所在结点中关键字数目不少于m/2取上整,则只需从该结点中删去关键字Ki和相应指针Ai ,树的其余部分不变. 3.")
296
9.3动态查找表(续) 45 24 3 53 90 37 50 61 70 100 b e c d f g h a 删除50 (2)被删除关键字所在结点中关键字数目等于m/2取上整-1,而与该结点相邻的右兄弟(或左兄弟)结点中的关键字数目大于m/2取上整-1,则需将其兄弟结点中的最小(或最大)关键字上移至双亲结点中,而将双亲结点中小于(或大于)且紧靠该上移关键字的关键字下移至被删关键字所在结点中。 53 61 90 70
被删除关键字所在结点中关键字数目等于m/2取上整-1,而与该结点相邻的右兄弟(或左兄弟)结点中的关键字数目大于m/2取上整-1,则需将其兄弟结点中的最小(或最大)关键字上移至双亲结点中,而将双亲结点中小于(或大于)且紧靠该上移关键字的关键字下移至被删关键字所在结点中。")
297
9.3动态查找表(续) 45 24 3 61 90 37 53 70 100 b e c d f g h a 删除53 (3)被删除关键字所在结点中关键字数目和与该结点相邻的右兄弟(或左兄弟)结点中的关键字数目均等于m/2取上整-1。设该结点有右兄弟,且其右兄弟结点地址由双亲结点中的指针Ai所指,则在删去关键字之后,它所在结点中剩余的关键字和指针,加上双亲结点中的关键字Ki一起,合并到Ai 所指兄弟结点中(若没有右兄弟,则合并到左兄弟结点中) 45 24 3 90 37 61 70 100 b e c d g h a 删除后
被删除关键字所在结点中关键字数目和与该结点相邻的右兄弟(或左兄弟)结点中的关键字数目均等于m/2取上整-1。设该结点有右兄弟,且其右兄弟结点地址由双亲结点中的指针Ai所指,则在删去关键字之后,它所在结点中剩余的关键字和指针,加上双亲结点中的关键字Ki一起,合并到Ai 所指兄弟结点中(若没有右兄弟,则合并到左兄弟结点中) b. e. c. d. g. h. a. 删除后.")
298
B+树查找=查找表+多路平衡树+B+树性质
9.3动态查找表(续) B+树 B+树查找=查找表+多路平衡树+B+树性质 B+树(B+ Tree):是B-树的变型树。一棵m阶B+树与m阶B-树差异: (1)有n棵子树的结点中含有n个关键字; (2)所有的叶子结点中包含了全部关键字信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接; (3) 所有的非终端结点可以看成是索引部分,结点中仅含有其子树(根结点)中的最大(或最小)关键字 B+树上查找运算有两种:一种是从最小关键字起顺序查找,另一种是从根结点开始,进行随机查找。从根结点开始进行随机查找的过程是一个顺指针寻找索引和在叶子结点的关键字中进行查找交叉进行的过程。若非终端结点关键字和给定值相等,并不终止,而是继续向下直到叶子结点。因此,在B+树,不管查找成功与否,每次查找都走了一条从根到叶子结点的路径。
 B+树. B+树查找=查找表+多路平衡树+B+树性质. B+树(B+ Tree):是B-树的变型树。一棵m阶B+树与m阶B-树差异: (1)有n棵子树的结点中含有n个关键字; (2)所有的叶子结点中包含了全部关键字信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接; (3) 所有的非终端结点可以看成是索引部分,结点中仅含有其子树(根结点)中的最大(或最小)关键字. B+树上查找运算有两种:一种是从最小关键字起顺序查找,另一种是从根结点开始,进行随机查找。从根结点开始进行随机查找的过程是一个顺指针寻找索引和在叶子结点的关键字中进行查找交叉进行的过程。若非终端结点关键字和给定值相等,并不终止,而是继续向下直到叶子结点。因此,在B+树,不管查找成功与否,每次查找都走了一条从根到叶子结点的路径。")
299
哈希表查找=查找表+顺序表+Hash规则
9.3动态查找表(续) 哈希表查找 哈希表查找=查找表+顺序表+Hash规则 基本思想: 在线性表和树结构中,元素在结构中的相对位置是随机的,和元素的关键字之间不存在确定的关系,在这些结构作用下的查找表中查找时需要进行一系列的和关键字的比较(包括“相等”、“不相等”、“大于”、“小于”、“等于”比较)。 哈希表查找的思路是希望不通过比较,一次存取便能得到所查元素。显然,前提是每个关键字和结构中一个唯一的存储位置相对应。这种对应关系为查找提供依据和线索。
 哈希表查找. 哈希表查找=查找表+顺序表+Hash规则. 基本思想: 在线性表和树结构中,元素在结构中的相对位置是随机的,和元素的关键字之间不存在确定的关系,在这些结构作用下的查找表中查找时需要进行一系列的和关键字的比较(包括 相等 、 不相等 、 大于 、 小于 、 等于 比较)。 哈希表查找的思路是希望不通过比较,一次存取便能得到所查元素。显然,前提是每个关键字和结构中一个唯一的存储位置相对应。这种对应关系为查找提供依据和线索。")
300
9.3动态查找表(续) 哈希表中基本概念和术语 哈希函数(Hash Function):由关键字到元素存储位置之间的对应关系H称为哈希表函数。它是一个映象,设置灵活,只要使得关键字由此所得的哈希函数值都落在表长允许范围内即可。H: Key ---> Address;key的哈希函数值记H(key)。 冲突(collision):对不同关键字可能得到同一哈希地址的现象,即key1 != key2,而H(key1)=H(key2)。具有相同函数值的关键字对该哈希函数来说称作同义词(synonym)。 哈希表(Hash Table):根据设定的哈希函数H(key)和处理冲突的方法将一组关键字映象到一个有限的连续的地址集(区间)上并以关键字在地址集中的“象”作为元素在表中的存储位置,这种表称为哈希表。这种映象过程称为哈希造表或散列,所得存储位置称为哈希地址或散列地址。
:由关键字到元素存储位置之间的对应关系H称为哈希表函数。它是一个映象,设置灵活,只要使得关键字由此所得的哈希函数值都落在表长允许范围内即可。H: Key ---> Address;key的哈希函数值记H(key)。 冲突(collision):对不同关键字可能得到同一哈希地址的现象,即key1 != key2,而H(key1)=H(key2)。具有相同函数值的关键字对该哈希函数来说称作同义词(synonym)。 哈希表(Hash Table):根据设定的哈希函数H(key)和处理冲突的方法将一组关键字映象到一个有限的连续的地址集(区间)上并以关键字在地址集中的 象 作为元素在表中的存储位置,这种表称为哈希表。这种映象过程称为哈希造表或散列,所得存储位置称为哈希地址或散列地址。")
301
9.3动态查找表(续) 哈希函数构造方法 构造和选取哈希函数的原则:均匀性(Uniform)。 若对于关键字集合中的任一个关键字,经哈希函数映象到地址集合中任何一个地址的概率是相等的,则称此类哈希函数为均匀的哈希函数。这种均匀性可以使一组关键字的哈希地址均匀分布在整个地址区间中,从而减少冲突。 实际中选取哈希函数要考虑的因素包括: *计算哈希函数所需要时间; *关键字长度; *哈系表大小; *关键字分布情况 *记录的查找频率 直接定址法:取关键字或关键字的某个线性函数值为哈希地址。即:H(key) = key 或H(key) = a*key+b (a,b为常数)。基于这种哈系函数的哈系表中不会发生冲突。但太理想化。 数字分析法:假设关键字是以r为基的数(如:以10为基的十进制数),并且哈系表中可能出现的关键字都是事先直到的,则可取关键字的若干数位组成哈希地址。当然,所取数位应该能比较均匀地区分这些关键字。 平方取中法:取关键字平方后的中间几位为哈希地址。因为一个数平方后的中间几位数和数的每一位都相关,由此使随机分布的关键字得到的哈希地址也是随机的。 折叠法:将关键字分割成位数相同的几部分,然后取这几部分的叠加和(舍去进位)作为哈希地址。关键字位数很多,而且关键字中每一位上数字分布大致均匀时,可以采用折叠法 随机数法:选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key)=random(key)。关键字长度不等时采用该方法构造哈希函数较恰当。
 = key 或H(key) = a*key+b (a,b为常数)。基于这种哈系函数的哈系表中不会发生冲突。但太理想化。 数字分析法:假设关键字是以r为基的数(如:以10为基的十进制数),并且哈系表中可能出现的关键字都是事先直到的,则可取关键字的若干数位组成哈希地址。当然,所取数位应该能比较均匀地区分这些关键字。 平方取中法:取关键字平方后的中间几位为哈希地址。因为一个数平方后的中间几位数和数的每一位都相关,由此使随机分布的关键字得到的哈希地址也是随机的。 折叠法:将关键字分割成位数相同的几部分,然后取这几部分的叠加和(舍去进位)作为哈希地址。关键字位数很多,而且关键字中每一位上数字分布大致均匀时,可以采用折叠法. 随机数法:选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key)=random(key)。关键字长度不等时采用该方法构造哈希函数较恰当。")
302
9.3动态查找表(续) 哈希表构造方法 除留余数法:取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址。即:
H(key) = key MOD p p<=m 可以对关键字直接取模,也可以在折叠、平方取中等运算后取模。 一般情况下,p取质数或不包含小于20的质因素的合数。
 = key MOD p p<=m. 可以对关键字直接取模,也可以在折叠、平方取中等运算后取模。 一般情况下,p取质数或不包含小于20的质因素的合数。")
303
9.3动态查找表(续) 处理冲突的方法 假设哈希表地址集为:0~(m-1),冲突是指由关键字得到的哈希地址为j(0<=j<=m-1)的位置上已存有记录,则“处理冲突”就是为该关键字的元素找到另一个“空”的哈希地址。在处理冲突的过程中可能得到一个地址序列Hi, i= 1,2,…,k (Hi属于[0..m-1])。在处理冲突过程中,若H1发生冲突,则求H2 ;若H2发生冲突,求H3 ,依次类推,直到Hk不发生冲突为止。 Hk 为元素在表中的地址。
,冲突是指由关键字得到的哈希地址为j(0<=j<=m-1)的位置上已存有记录,则 处理冲突 就是为该关键字的元素找到另一个 空 的哈希地址。在处理冲突的过程中可能得到一个地址序列Hi, i= 1,2,…,k (Hi属于[0..m-1])。在处理冲突过程中,若H1发生冲突,则求H2 ;若H2发生冲突,求H3 ,依次类推,直到Hk不发生冲突为止。 Hk 为元素在表中的地址。")
304
9.3动态查找表(续) 开放定址法: Hi =(H(key) + di ) MOD m i=1,2,…,k(k<=m-1)其中:H(key)为哈希函数;m为哈希表表长; di 为增量序列.若:(1)di=1,2,3,…,m-1,称线性探测再散列; (2)di=12, -12, 22, 22,…, +k2 , -k2,称二次探测再散列; (3)di=伪随机数序列,称伪随机探测再散列。 1 2 3 4 5 6 7 8 9 10 H(key) = key MOD 11,表中已有关键字17, 60, 29,现哈希关键字为38的元素. 60 17 29 38 d3=3 38 H(38) 38 d1=1 38 d2=2 线性探测: 避免“二次聚集” 线性探测:空间足够 时,可以最终完成 二次探测:当m=4j+3的素数时才能完成 1 2 3 4 5 6 7 8 9 10 38 d2=2 60 17 29 38 H(38) 38 d1=1 二次探测:
di=12, -12, 22, 22,…, +k2 , -k2,称二次探测再散列; (3)di=伪随机数序列,称伪随机探测再散列。 H(key) = key MOD 11,表中已有关键字17, 60, 29,现哈希关键字为38的元素 d3= H(38) 38. d1= d2=2. 线性探测: 避免 二次聚集 线性探测:空间足够. 时,可以最终完成. 二次探测:当m=4j+3的素数时才能完成 d2= H(38) 38. d1=1. 二次探测:")
305
9.3动态查找表(续) 再哈希法: Hi =RHi (key) i=1,2,…,k
这种方法不容易产生“聚集”,但增加了计算时间 公共溢出区法: 设向量HachTable[0..m-1]为基本表,每个分量存放一个元素,另设向量OverTable[0..v]为溢出表。所有关键字和基本表中关键字为同义词的元素,不管它们由哈希函数得到的哈希地址是什么,一旦发生冲突,都填入溢出表。 链地址法: 将所有关键字为同义词的元素存储在同一线性链表中。 用一个指针向量来表示:ChainHash[m],凡是哈希地址为i的元素都插入到头指针为ChainHash[i]的链表中。

306
9.3动态查找表(续) 关键字集合:{19,14,23,01,68,20,84,27,55,11,10,79}, H(key)= key MOD 13 ^ 1 2 3 4 6 5 7 8 9 10 11 12 27 79 01 14 55 68 19 84 20 23
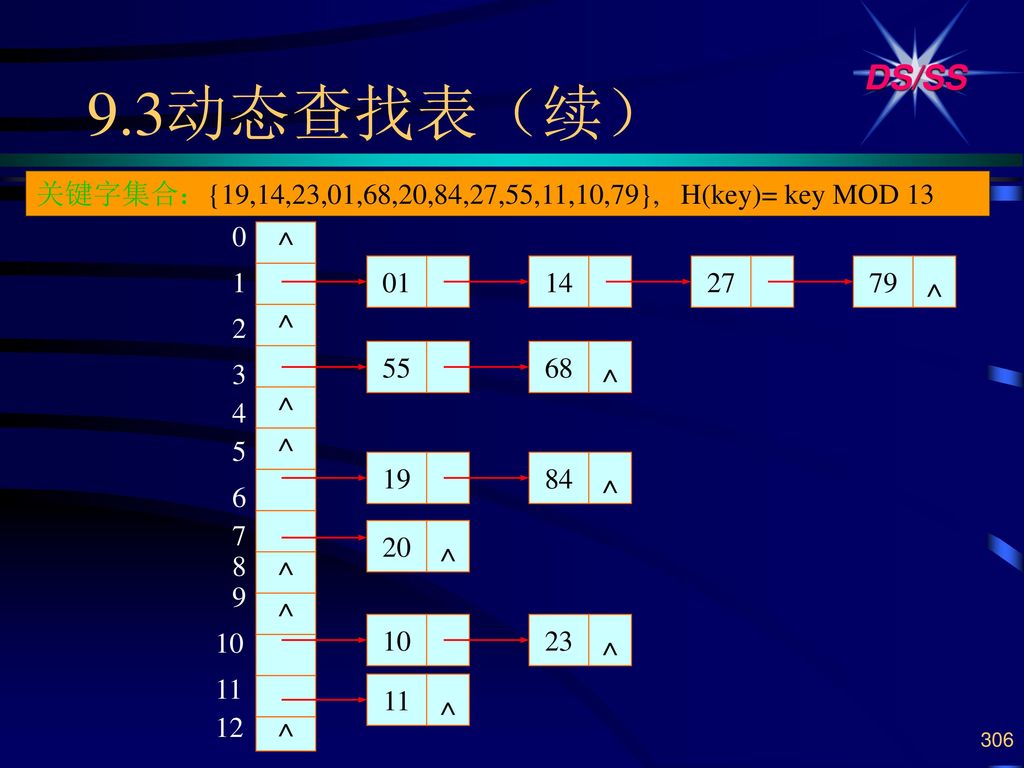
307
9.3动态查找表(续) 哈希表上的查找及性能 哈希表查找过程:
由于哈希表为动态查找表,哈希造表的过程就是查找失败时元素插入的过程(在失败位置)。同样,根据哈希查找特征,哈希表上元素查找过程也类同于哈希造表过程。给定K值,根据造表时设定的哈希函数求得哈希地址,若表中此位置上没有元素,则查找不成功;否则比较关键字,若和给定值相等,则查找成功;否则根据造表时设定的处理冲突的方法找“下一地址”,直至哈希表某个位置为“空”或者表中所填元素的关键字等于给定值时为止。 哈希表查找性能取决于三个因素: *哈希函数 *处理冲突的方法 *装填因子(表中填入元素个数/哈希表表长)
。同样,根据哈希查找特征,哈希表上元素查找过程也类同于哈希造表过程。给定K值,根据造表时设定的哈希函数求得哈希地址,若表中此位置上没有元素,则查找不成功;否则比较关键字,若和给定值相等,则查找成功;否则根据造表时设定的处理冲突的方法找 下一地址 ,直至哈希表某个位置为 空 或者表中所填元素的关键字等于给定值时为止。 哈希表查找性能取决于三个因素: *哈希函数. *处理冲突的方法. *装填因子(表中填入元素个数/哈希表表长)")
308
9.3动态查找表(续) 性能分析: 关键字集合:{19,14,23,01,68,20,84,27,55,11,10,79}
M=16; H(key) = key MOD 13,线性探测处理冲突 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 14 1 01 2 68 1 27 4 55 3 19 1 20 1 84 3 79 9 23 1 11 1 10 3 性能分析: n = 12; m=16, p=13 ASL成功 = (1*6+2+3*3+4+9)/12=2.5 ASL不成功 = ( )/13=7
 = key MOD 13,线性探测处理冲突 性能分析: n = 12; m=16, p=13. ASL成功 = (1*6+2+3*3+4+9)/12=2.5. ASL不成功 = ( )/13=7.")
309
关键字集合:{19,14,23,01,68,20,84,27,55,11,10,79} M=16; H(key) = key MOD 13,链地址法处理冲突 ^ 1 2 3 4 6 5 7 8 9 10 11 12 27 79 01 14 55 68 19 84 20 23 性能分析: n = 12; m=16, p=13 ASL成功 = (1*6+2*4+3+4)/12=1.75 ASL不成功 =
/12=1.75. ASL不成功 =")
310
教学内容---第十章 1.绪论 2.线性表 3.栈、队列和串 4.数组 5.广义表 6.树和二叉树 7.图 8.动态存储管理 9.查找
10.内部排序 11.外部排序 12.文件

311
10.1排序基本概念 排序(Sorting):将一个数据元素的任意序列重新排成一个按照关键字有序的序列的操作。即:
假设n个元素的序列 {R1,R2,…, Rn},相应关键字序列为 {K1,K2,…, Kn}。确定1,2,…,n的一种排列p1,p2,…, pn,使其相应关键字满足非递减(或非递增)关系K p1<=K p2<=…<= Kpn , 从而得到一个按关键字有序序列 {Rp1,R p2,…, R pn},这样一个操作过程,就是排序。 (排序方法)稳定: Ki 是次关键字。设待排元素序列中, 若Ki=Kj (1<=i<=n,1<=j<=n, i != j),且排序前Ri 领先于Rj(即i<j),经过该方法排序后序列中Ri 仍然领先于Rj ,则该方法稳定。 (排序方法)不稳定: Ki 是次关键字。设待排元素序列中, 若Ki=Kj (1<=i<=n,1<=j<=n, i != j),且排序前Ri 领先于Rj(即i<j),经过该方法排序后若可能出现序列中Rj 领先于Ri ,则该方法不稳定。 内部排序: 待排序元素存放在内存中进行的排序过程。 外部排序: 待排序元素个数多,内存中一次不能容纳下,在排序过程中需要对外存进行访问的排序过程。
关系K p1<=K p2<=…<= Kpn , 从而得到一个按关键字有序序列 {Rp1,R p2,…, R pn},这样一个操作过程,就是排序。 (排序方法)稳定: Ki 是次关键字。设待排元素序列中, 若Ki=Kj (1<=i<=n,1<=j<=n, i != j),且排序前Ri 领先于Rj(即i<j),经过该方法排序后序列中Ri 仍然领先于Rj ,则该方法稳定。 (排序方法)不稳定: Ki 是次关键字。设待排元素序列中, 若Ki=Kj (1<=i<=n,1<=j<=n, i != j),且排序前Ri 领先于Rj(即i<j),经过该方法排序后若可能出现序列中Rj 领先于Ri ,则该方法不稳定。 内部排序: 待排序元素存放在内存中进行的排序过程。 外部排序: 待排序元素个数多,内存中一次不能容纳下,在排序过程中需要对外存进行访问的排序过程。")
312
10.1排序基本概念(续) 插入排序 交换排序 选择排序 归并排序 基数排序 内部排序 简单排序 排序 先进排序 外部排序 基数排序
按排序依据的不同原则 外部排序 内部排序 按排序所需的工作量 简单排序 先进排序 基数排序 排序

313
10.1排序基本概念(续) 待排序元素有三种存储方式: *顺序排序:元素之间的次序关系由存储位置决定,实
现排序必须同时进行关键字比较和元素移动两类操作。 *链表排序:元素之间的次序关系由指针指定,排序中只 进行关键字比较,仅仅修改指针,不进行元素移动。 (为了节省空间,一般用静态链表即可) *地址排序:待排元素在连续单元内,同时另设一个指示 各个元素存储位置的地址向量,排序过程中只进行关键 字比较,不进行实际数据元素移动,而移动地址向量中 这些数据元素的“地址”,形成关键字有序序列 //一般用顺序排序,存储表示如下 #define MAXSIZE 20 typedef int KeyType; //定义关键字类型为整型 typedef struct { KeyType key //关键字项 infoType otherinfo //元素其他数据项 }ElemType; //元素类型 ElemType r[MAXSIZE+1] //r[0]用作“监视哨” int length //顺序表长度 }sqList; //顺序表类型
 *地址排序:待排元素在连续单元内,同时另设一个指示. 各个元素存储位置的地址向量,排序过程中只进行关键. 字比较,不进行实际数据元素移动,而移动地址向量中. 这些数据元素的 地址 ,形成关键字有序序列. //一般用顺序排序,存储表示如下. #define MAXSIZE 20. typedef int KeyType; //定义关键字类型为整型. typedef struct { KeyType key //关键字项. infoType otherinfo //元素其他数据项. }ElemType; //元素类型. ElemType r[MAXSIZE+1] //r[0]用作 监视哨 int length //顺序表长度. }sqList; //顺序表类型.")
314
10.2插入排序 直接插入排序 算法思想: 直接插入排序(Straight Insertion Sort)的基本操作是将一个元素插入到已排好序的有序表中,从而得到一个新的、元素数增1的有序表。 第i趟排序过程:在含有i-1个元素的有序子序列r[1..i-1]中插入一个元素r[i]后,变成含有i个元素的有序子序列r[1..i]。 整个排序过程共进行n-1趟(即i从2变化到n):先将序列中的第1个元素看成是一个有序的子序列,然后从第2个元素起逐个进行插入,直至整个序列变成按关键字非递减有序序列为止。
:先将序列中的第1个元素看成是一个有序的子序列,然后从第2个元素起逐个进行插入,直至整个序列变成按关键字非递减有序序列为止。")
315
49 1 2 3 4 5 6 7 8 38 65 97 76 13 27 49* 初始关键字 直接插入排序 38 49 65 97 76 13 27 49* i=2 i=3 65 38 49 97 76 13 27 49* i=4 97 38 49 65 76 13 27 49* i=5 76 38 49 65 97 13 27 49* i=6 13 38 49 65 76 97 27 49* i=7 27 13 38 49 65 76 97 49* i=8 49* 13 27 38 49 65 76 97

316
10.2插入排序(续) 直接插入排序 Void InsertSort(SqList &L ){
for (i=2; i<=L.length; ++i) if LT(L.r[i].key,L.r[i-1].key) { L.r[0] = L.r[i]; //监视哨为当前插入元素 for (j = i-1; LT(L.r[0].key,L.r[j].key); --j) L.r[j+1] = L.r[j]; //元素后移 L.[j+1] = L.r[0]; 插入到正确位置 } } //InsertSort
 if LT(L.r[i].key,L.r[i-1].key) { L.r[0] = L.r[i]; //监视哨为当前插入元素. for (j = i-1; LT(L.r[0].key,L.r[j].key); --j) L.r[j+1] = L.r[j]; //元素后移. L.[j+1] = L.r[0]; 插入到正确位置. } } //InsertSort.")
317
10.2插入排序(续) 性能分析: 时间复杂度T(n)=O(n2) 正序: 比较次数:n-1; 元素不移动 空间复杂度S(n)=O(1)
稳定性: 直接插入排序方法是稳定的排序方法 适用情况: *元素初始序列基本有序; *元素个数少

318
10.2插入排序(续) 希尔排序 算法思想: 希尔排序(Shell’s Sort)称为“缩小增量排序”,它是从两点出发对直接插入排序进行改进而得到的一种插入排序排序。第一点,元素基本有序时,直接插入排序时间复杂度接近O(n);第二点,元素个数n很小时,直接插入排序效率也比较高。 希尔排序的基本思想:先将整个待排元素序列分割成若干子序列分别进行直接插入排序(这些子序列要么元素个数少、要么基本有序,从而直接插入排序效率高),待整个序列中的元素“基本有序”时,再对全体元素进行一次直接插入排序。 子序列的构成不是简单地“逐段分割”,而是将相隔某个“增量”的元素组成一个子序列。这样便于每一趟排序都均匀展开。 排序的趟数就是增量序列的长度。
,待整个序列中的元素 基本有序 时,再对全体元素进行一次直接插入排序。 子序列的构成不是简单地 逐段分割 ,而是将相隔某个 增量 的元素组成一个子序列。这样便于每一趟排序都均匀展开。 排序的趟数就是增量序列的长度。")
319
希尔排序(增量序列为:5、3、1) 初始关键字 1 2 3 4 5 6 7 8 9 10 49 38 65 97 76 13 27 49*
1 2 3 4 5 6 7 8 9 10 49 38 65 97 76 13 27 49* 55 04 一趟排序结果 13 27 49* 55 04 49 38 65 97 76 二趟排序结果 13 04 49* 38 27 49 55 65 97 76 三趟排序结果 04 13 27 38 49* 49 55 65 76 97

320
10.2插入排序(续) Void ShellInsert(SqList &L ,int dk){ //一趟希尔排序,前后元素位置增量为dk
for (i=dk+1; i<=L.length; ++i) if LT(L.r[i].key,L.r[i-dk].key) { //将L.r[i]插入有序增量子表 L.r[0] = L.r[i]; //L.r[0]为暂存单元 for (j = i-dk; j>0&<(L.r[0].key,L.r[j].key); j-=dk) L.r[j+dk] = L.r[j]; //元素后移 L.[j+dk] = L.r[0]; 插入到正确位置 } } //ShellInsert Void ShellSort(SqList &L ,int dlta[], int t){ //按增量序列dlta[0..t-1]作希尔排序 for (k=0; k<t; ++k) ShellInsert(L,dlta[k]); } //ShellSort
 if LT(L.r[i].key,L.r[i-dk].key) { //将L.r[i]插入有序增量子表. L.r[0] = L.r[i]; //L.r[0]为暂存单元. for (j = i-dk; j>0&<(L.r[0].key,L.r[j].key); j-=dk) L.r[j+dk] = L.r[j]; //元素后移. L.[j+dk] = L.r[0]; 插入到正确位置. } } //ShellInsert. Void ShellSort(SqList &L ,int dlta[], int t){ //按增量序列dlta[0..t-1]作希尔排序. for (k=0; k<t; ++k) ShellInsert(L,dlta[k]); } //ShellSort.")
321
10.2插入排序(续) 性能分析: 时间复杂度T(n) = O(n1.5):增量序列dlta[k]=2t-k+1-1
空间复杂度S(n)=O(1) O(n1.5):增量序列dlta[k]=2t-k+1-1 O(n(log2n)2):n趋于无穷大时 O(n1.3):平均情况 稳定性: 希尔排序方法是不稳定的排序方法 增量序列选择: *增量序列中的值没有除1之外的公因子; *最后一个增量值必须等于1
![10.2插入排序(续) 性能分析: 时间复杂度T(n) = O(n1.5):增量序列dlta[k]=2t-k+1-1](http://slidesplayer.com/slide/11606863/62/images/321/10.2%E6%8F%92%E5%85%A5%E6%8E%92%E5%BA%8F%EF%BC%88%E7%BB%AD%EF%BC%89+%E6%80%A7%E8%83%BD%E5%88%86%E6%9E%90%3A+%E6%97%B6%E9%97%B4%E5%A4%8D%E6%9D%82%E5%BA%A6T%28n%29+%3D+O%28n1.5%29%EF%BC%9A%E5%A2%9E%E9%87%8F%E5%BA%8F%E5%88%97dlta%5Bk%5D%3D2t-k%2B1-1.jpg "空间复杂度S(n)=O(1) O(n1.5):增量序列dlta[k]=2t-k+1-1. O(n(log2n)2):n趋于无穷大时. O(n1.3):平均情况. 稳定性: 希尔排序方法是不稳定的排序方法. 增量序列选择: *增量序列中的值没有除1之外的公因子; *最后一个增量值必须等于1.")
322
10.3交换排序 冒泡排序 算法思想: 冒泡排序(Bubble Sort)的基本操作是将两个相邻元素关键字比较,若为逆序,则交换两个元素。
第i趟排序过程:从L.r[1]到L.r[n-i+1]依次比较相邻两个元素关键字,并在逆序时交换相邻元素,结果是这n-i+1个元素中关键字最大的元素被交换到第n-i+1的位置上。 整个排序过程共进行k趟(1<=k<n),判别冒泡排序结束的条件是“在一趟排序过程中没有进行国交换元素的操作”。
,判别冒泡排序结束的条件是 在一趟排序过程中没有进行国交换元素的操作 。")
323
49 1 2 3 4 5 6 7 8 38 65 97 76 13 27 49* 初始关键字 冒泡排序 38 49 65 76 13 27 49* 97 第一趟结果 第二趟结果 38 49 65 13 27 49* 76 97 第三趟结果 38 49 13 27 49* 65 76 97 第四趟结果 38 13 27 49 49* 65 76 97 第五趟结果 13 27 38 49 49* 65 76 97 第六趟结果 13 27 38 49 49* 65 76 97

324
10.3交换排序(续) 性能分析: 时间复杂度T(n)=O(n2) 正序: 比较次数:n-1; 元素不移动 空间复杂度S(n)=O(1)
稳定性: 冒泡排序方法是稳定的排序方法 适用情况: *元素初始序列基本有序; *元素个数较少

325
10.3交换排序(续) 快速排序 算法思想: 快速排序(Quick Sort)的基本基本思想是,通过一趟排序将待排元素分割成独立的两部分,其中一部分元素的关键字均比另一部分元素的关键字小,则可分别对这两部分元素继续进行排序,以达到整个序列有序。 一趟排序(划分)过程:对待排序列{L.r[s],L.r[s+1],…,L.r[t]},任意选取一个元素作为枢轴(pivot),将所有关键字较它小的元素都安置在它的位置之前,将所有关键字较它大的元素都安置在它的位置之后。最后,以该“枢轴”元素最后所落位置作分界线,将序列分割成两个子序列。 整个排序过程共进行的趟数与每一趟排序过程中枢轴元素的选取有关,如果每一趟划分“均匀”,则总趟数可以减到最小。
过程:对待排序列{L.r[s],L.r[s+1],…,L.r[t]},任意选取一个元素作为枢轴(pivot),将所有关键字较它小的元素都安置在它的位置之前,将所有关键字较它大的元素都安置在它的位置之后。最后,以该 枢轴 元素最后所落位置作分界线,将序列分割成两个子序列。 整个排序过程共进行的趟数与每一趟排序过程中枢轴元素的选取有关,如果每一趟划分 均匀 ,则总趟数可以减到最小。")
326
快速排序 low 初始关键字 1 2 3 4 5 6 7 8 49 38 65 97 76 13 27 49* high 一趟排序结果 49
1 2 3 4 5 6 7 8 49 38 65 97 76 13 27 49* high 一趟排序结果 49 27 38 13 76 97 65 49* low high 27 38 13 49 76 97 65 49* low high 76 27 38 13 49 97 65 49* 二趟排序结果 49 49* 65 76 97 13 27 38 49 low high 76 13 27 38 49* 65 76 97 四趟排序结果 49* 65 76 97 13 27 38 49

327
int Partition(SqList &L ,int low, int high){ //一趟快速排序
pivotkey = L.r[low].key //用子表的第一个元素作枢轴元素 L.r[0] = L.r[low].key; //将枢轴元素暂存在r[0]位置处 while (low<high){ //从表的两端交替地向中间扫描 while (low<high && L.r[high].key >= pivotkey) --high; L.r[low] = L.r[high]; while (low<high && L.r[low].key <= pivotkey) ++low; L.r[high] = L.r[low]; } L.r[low] = L.r[0]; //枢轴元素到位(此时low=high) retun low; } // Partition Void QSort(SqList &L ,int low, int high){ //完成一次完整的快速排序 if (low<high) { pivotloc = partition(L, low,high); //将L.r[low..high]一分为二 Qsort(L,low,pivotloc-1); Qsort(L, pivotloc+1, high); } } //QSort
{ //从表的两端交替地向中间扫描. while (low<high && L.r[high].key >= pivotkey) --high; L.r[low] = L.r[high]; while (low<high && L.r[low].key <= pivotkey) ++low; L.r[high] = L.r[low]; } L.r[low] = L.r[0]; //枢轴元素到位(此时low=high) retun low; } // Partition. Void QSort(SqList &L ,int low, int high){ //完成一次完整的快速排序. if (low<high) { pivotloc = partition(L, low,high); //将L.r[low..high]一分为二. Qsort(L,low,pivotloc-1); Qsort(L, pivotloc+1, high); } } //QSort.")
328
10.3交换排序(续) 性能分析: 平均时间复杂度T(n)=O(knlnn) ,k为常数。
*就平均时间而言,快速排序是目前最好的一种内部排序方法 *若初始序列基本有序,快速排序就蜕变为冒泡排序 *一般选枢轴元素采取“三者取中”法则 一般情况下空间复杂度S(n)=O(log2n),最坏情况下达到O(n)(若改进算法,在一趟排序之后比较分割所得两部分长度,且先对长度短的子序列元素进行快速排序,则栈最大深度可降为O(log2n) 稳定性: 快速排序方法是不稳定的排序方法 适用情况: *元素初始序列不是基本有序;
=O(log2n),最坏情况下达到O(n)(若改进算法,在一趟排序之后比较分割所得两部分长度,且先对长度短的子序列元素进行快速排序,则栈最大深度可降为O(log2n) 稳定性: 快速排序方法是不稳定的排序方法. 适用情况: *元素初始序列不是基本有序;")
329
10.4选择排序 简单选择排序 算法思想: 简单选择排序(Simple Selection Sort)的基本操作是通过n-i次关键字的比较,从n-i+1个元素中选出关键字最小的元素,并和第i(1<=i<=n)个元素交换之。 整个排序过程共进行n-1趟(i从1变化至n-1)选择。 Void SelectSort(SqList &L){ //完成一次完整的简单选择排序 for (i=1; i<L.length; ++i) { //选择第i小的元素,并交换到位 j = SelectMinKey(L,i); //在L.r[i .. L.length]中选择key最小的元素 if (i != j) L.r[i] 与L.r[j]交换; //与第i个元素交换 } } //SelectSort
选择。 Void SelectSort(SqList &L){ //完成一次完整的简单选择排序. for (i=1; i<L.length; ++i) { //选择第i小的元素,并交换到位. j = SelectMinKey(L,i); //在L.r[i .. L.length]中选择key最小的元素. if (i != j) L.r[i] 与L.r[j]交换; //与第i个元素交换. } } //SelectSort.")
330
49 1 2 3 4 5 6 7 8 38 65 97 76 13 27 49* 初始关键字 简单选择排序 13 38 65 97 76 49 27 49* i=1 i=2 13 27 65 97 76 49 38 49* i=3 13 27 38 97 76 49 65 49* i=4 13 27 38 49 76 97 65 49* i=5 13 27 38 49 49* 97 65 76 i=6 13 27 38 49 49* 65 97 76 i=7 13 27 38 49 49* 65 76 97

331
10.4选择排序(续) 性能分析: 时间复杂度T(n)=O(n2) 正序: 比较次数:n(n-1)/2; 元素不移动
空间复杂度S(n)=O(1) 正序: 比较次数:n(n-1)/2; 元素不移动 逆序: 比较次数:n(n-1)/2; 移动次数:3(n-1) 稳定性: 简单选择排序方法是不稳定的排序方法 适用情况: *元素个数较少
=O(1) 正序: 比较次数:n(n-1)/2; 元素不移动. 逆序: 比较次数:n(n-1)/2; 移动次数:3(n-1) 稳定性: 简单选择排序方法是不稳定的排序方法. 适用情况: *元素个数较少.")
332
10.4选择排序(续) 堆排序 堆(Heap):n个元素的序列{k1, k2,…, kn},当且仅当满足以下关系时,称之为堆。
ki<= k2i且ki<= k2i+1 或 ki>= k2i且ki>= k2i+1. 满足前一约束的堆称之为小顶堆,满足后一约束的堆称之为大顶堆。 小顶堆的第一个元素为序列中最小者;大顶堆的第一个元素为序列中最大者。 堆可以用完全二叉树来描述(堆的本质仍然是一个序列) 。
 。")
333
10.4选择排序(续) 小顶堆:{13, 38, 27, 49*, 76, 65, 49, 97} 顺序存储的堆 1 2 3 4 5 6 7
1 2 3 4 5 6 7 8 13 38 27 49* 76 65 49 97 97 13 38 49* 76 27 65 49

334
10.4选择排序(续) 堆排序 算法思想: 堆排序(Heap Sort)的思路是:下一趟选择排序时尽可能利用上一趟排序过程中已有的比较结果信息,从而提高排序效率。 堆排序完整过程:首先对初始序列建堆;然后,在输出堆顶的最小值之后,使得剩余n-1个元素的序列重新又建成一个堆,则得到n个元素中的次小值。如此反复进行,通过n-1趟,便能得到一个有序序列。 堆排序实现的两个问题: *如何由初始序列建成一个堆; *如何在输出堆顶元素之后,调整剩余元素成为一个新的堆 这两个问题的解决都归结到一个实现:筛选(自堆顶至叶子的调整过程)
")
335
筛选(自堆顶至叶子的调整过程): 输出堆顶元素后,以堆中最后一个元素替代。这时破坏了整个树描述的堆,但其左、右子树仍然是堆,则仅需自上而下进行调整。 首先以堆顶元素和其左、右子树根结点值小者交换 ,若破坏了子树的堆,则进行类似的调整,直至叶子结点。此时堆顶为n-1个元素的最小者。这就是一次调整过程。 1 2 3 4 5 6 7 8 13 38 27 49* 76 65 49 97 13 97 97 27 49 97 13 27 38 49* 76 97 65 49 97 13 97 13 38 49* 76 27 65 49 1 2 97 49 3 4

336
… 建堆: 从一个无序序列建堆的过程就是一个反复“筛选”的过程。
将此序列用完全二叉树描述,则最后一个非终端结点是“第(n/2)取下整”个元素,由此,筛选只需从“第(n/2)取下整”个元素开始。 共进行“第(n/2)取下整”次筛选就完成初始建堆过程。 1 2 3 4 5 6 7 8 49 38 65 97 76 13 27 49* {49, 38, 65, 97, 76, 13, 27, 49*} 49 13 27 49 13 65 49* 97 49* 49 38 97 76 65 13 27 97 49 38 49* 76 65 13 27 97 49 38 49* 76 13 65 27 97 49 38 49* 76 13 65 27 49 13 65 27 … 13 49 49 27
取下整 个元素,由此,筛选只需从 第(n/2)取下整 个元素开始。 共进行 第(n/2)取下整 次筛选就完成初始建堆过程。 * {49, 38, 65, 97, 76, 13, 27, 49*} * * * * * …")
337
typedef SqList HeapType; //堆采用顺序表存储表示
void HeapAdjust(HeapType &H ,int s, int hm){ //一次调整 rc = H.r[s]; for (j =2*s; j<=m; j *=2) { //沿key较大的孩子结点向下筛选 if (j<m &<(H.r[j].key, H.r[j+1].key)) ++j; //j为key较大的元素的下标 if ( !LT(rc.key, H.r[j].key)) break; //rc应插入在位置s上 H.r[s] = H.r[j]; s = j; } H.r[s] = rc; //插入 } // HeapAdjust 已知H.r[s..m]中元素的关键字除H.r[s].key之外均满足堆的定义,本函数调整H.r[s]的关键字,使H.r[s..m]成为一个大顶堆 Void HeapSort(HeapType &H){ //完成一次完整的堆排序 for (i=H.length/2; i>0; --i) HeapAdjust (H, i, H.length); for (i=H.length; i>0; --i) { H.r[1] 与H.r[i]交换; //将堆顶元素和H.r[1..i]中最后一个元素相互交换 HeapAdjust (H, 1, i-1); //将H.r[1..i-1]重新调整成大顶堆} } //HeapSort t
{ //一次调整. rc = H.r[s]; for (j =2*s; j<=m; j *=2) { //沿key较大的孩子结点向下筛选. if (j<m &<(H.r[j].key, H.r[j+1].key)) ++j; //j为key较大的元素的下标. if ( !LT(rc.key, H.r[j].key)) break; //rc应插入在位置s上. H.r[s] = H.r[j]; s = j; } H.r[s] = rc; //插入 } // HeapAdjust. 已知H.r[s..m]中元素的关键字除H.r[s].key之外均满足堆的定义,本函数调整H.r[s]的关键字,使H.r[s..m]成为一个大顶堆. Void HeapSort(HeapType &H){ //完成一次完整的堆排序. for (i=H.length/2; i>0; --i) HeapAdjust (H, i, H.length); for (i=H.length; i>0; --i) { H.r[1] 与H.r[i]交换; //将堆顶元素和H.r[1..i]中最后一个元素相互交换. HeapAdjust (H, 1, i-1); //将H.r[1..i-1]重新调整成大顶堆} } //HeapSort t.")
338
10.4选择排序(续) 性能分析: 时间复杂度T(n)= O(nlog2n) (最坏情况下)
*建立n个元素、深度为h的堆,关键字比较总次数不超过4n; *调整新堆时调用HeapAdjust共n-1次,总共进行的比较次数不 超过2nlog2n次。 空间复杂度S(n)=O(1) (元素交换时用) 稳定性: 堆排序方法是不稳定的排序方法 适用情况: *元素个数较多(时间主要耗费在初始建堆和调整新堆时进行的反复筛选上)
=O(1) (元素交换时用) 稳定性: 堆排序方法是不稳定的排序方法. 适用情况: *元素个数较多(时间主要耗费在初始建堆和调整新堆时进行的反复筛选上)")
339
10.5归并排序 2-路归并排序 算法思想: 归并排序(Merging Sort)的基本操作是“归并”:将两个或两个以上的有序表组合成一个新的有序表。 2-路归并过程:假设初始序列含n个元素,看成n个子序列,两两归并,得到“n/2取上整”个长度为2或为1的有序子序列;再两两归并,如此重复,直至得到一个长度为n的有序序列为止。 整个排序过程共进行log2n趟。每一趟归并调用“(n/(2h))取上整”次核心归并算法,将SR[1..n]中前后相邻长度为h的有序段进行两两归并,得到前后相邻、长度为2h的有序段,并存放在TR[1..n]中。交替进行。
)取上整 次核心归并算法,将SR[1..n]中前后相邻长度为h的有序段进行两两归并,得到前后相邻、长度为2h的有序段,并存放在TR[1..n]中。交替进行。")
340
10.5归并排序(续) void Merge(RcdType SR[] , RcdType TR[] , int i, int m, int n){ //核心归并算法 //将有序的SR[i..m]和SR[m+1..n]归并为有序的TR[i..n] for (j =m+1, k =i; i<=m&& j<=n; ++k) { //将SR中元素由小到大地并入TR if LQ(SR[i].key,SR{j].key) TR[k] = SR[i++]; else TR[k] = SR[j++]; } if(j<=m) TR[k..n] = SR[i..m]; //将剩余的SR[i..m]复制到TR if(j<=n) TR[k..n] = SR[j..n]; //将剩余的SR[j..n]复制到TR } // Merge
![10.5归并排序(续) void Merge(RcdType SR[] , RcdType TR[] , int i, int m, int n){ //核心归并算法. //将有序的SR[i..m]和SR[m+1..n]归并为有序的TR[i..n]](http://slidesplayer.com/slide/11606863/62/images/340/10.5%E5%BD%92%E5%B9%B6%E6%8E%92%E5%BA%8F%EF%BC%88%E7%BB%AD%EF%BC%89+void+Merge%28RcdType+SR%5B%5D+%2C+RcdType+TR%5B%5D+%2C+int+i%2C+int+m%2C+int+n%29%7B+%2F%2F%E6%A0%B8%E5%BF%83%E5%BD%92%E5%B9%B6%E7%AE%97%E6%B3%95.+%2F%2F%E5%B0%86%E6%9C%89%E5%BA%8F%E7%9A%84SR%5Bi..m%5D%E5%92%8CSR%5Bm%2B1..n%5D%E5%BD%92%E5%B9%B6%E4%B8%BA%E6%9C%89%E5%BA%8F%E7%9A%84TR%5Bi..n%5D.jpg "for (j =m+1, k =i; i<=m&& j<=n; ++k) { //将SR中元素由小到大地并入TR. if LQ(SR[i].key,SR{j].key) TR[k] = SR[i++]; else TR[k] = SR[j++]; } if(j<=m) TR[k..n] = SR[i..m]; //将剩余的SR[i..m]复制到TR. if(j<=n) TR[k..n] = SR[j..n]; //将剩余的SR[j..n]复制到TR. } // Merge.")
341
10.5归并排序(续) 2-路归并排序 性能分析: 时间复杂度T(n)= O(nlog2n)
空间复杂度S(n)=O(n) (每一趟交替进行) 稳定性: 归并排序方法是稳定的排序方法 适用情况: *元素个数较多(辅助外排序情况下常用) *n较大时,归并排序所需时间较堆排序省,但辅助空间多
=O(n) (每一趟交替进行) 稳定性: 归并排序方法是稳定的排序方法. 适用情况: *元素个数较多(辅助外排序情况下常用) *n较大时,归并排序所需时间较堆排序省,但辅助空间多.")
342
10.6基数排序 基数排序(Radix Sorting):借助多关键字排序的思想对单逻辑关键字进行排序的方法。
多关键字排序: n个元素的序列 {R1,R2,…, Rn},每个元素Ri有d个关键字(K0i, K1i,…, Kd-1i),则称序列对关键字(K0, K1,…, Kd-1)有序: 对于任意两个元素Ri和Rj都满足下列有序关系: (K0i, K1i,…, Kd-1i)< (K0j, K1j,…, Kd-1j)。其中K0称为最主位关键字, Kd-1称为最次位关键字。 最高位优先(Most Significant Digit first):先对最主位关键字K0 进行排序,将序列分成若干子序列,每个子序列中的元素都具有相同的K0 值,然后分别就每个子序列对关键字K1进行排序,按K1值不同再分成若干更小的子序列,依次重复,直至对Kd-2进行排序之后得到的每一子序列中的元素都具有相同的关键字(K0, K1,…, Kd-2) ,而后分别每个子序列对Kd-1进行排序,最后将所有子序列依次联接在一起称为一个有序序列。 最低位优先(Least Significant Digit first):从最次位关键字Kd-1起进行排序。然后再对高一位的关键字Kd-2进行排序,依次重复,直至对K0进行排序后便成为一个有序序列。
,则称序列对关键字(K0, K1,…, Kd-1)有序: 对于任意两个元素Ri和Rj都满足下列有序关系: (K0i, K1i,…, Kd-1i)< (K0j, K1j,…, Kd-1j)。其中K0称为最主位关键字, Kd-1称为最次位关键字。 最高位优先(Most Significant Digit first):先对最主位关键字K0 进行排序,将序列分成若干子序列,每个子序列中的元素都具有相同的K0 值,然后分别就每个子序列对关键字K1进行排序,按K1值不同再分成若干更小的子序列,依次重复,直至对Kd-2进行排序之后得到的每一子序列中的元素都具有相同的关键字(K0, K1,…, Kd-2) ,而后分别每个子序列对Kd-1进行排序,最后将所有子序列依次联接在一起称为一个有序序列。 最低位优先(Least Significant Digit first):从最次位关键字Kd-1起进行排序。然后再对高一位的关键字Kd-2进行排序,依次重复,直至对K0进行排序后便成为一个有序序列。")
343
10.6基数排序(续) 链式基数排序 算法思想: 借助“分配”和“收集”两种操作对单逻辑关键字进行排序。
有的单逻辑关键字可以看成由若干个关键字复合而成。比如数值,设0<=K<=999,则K可以看作三个关键字(K0, K1, K2)组成(d=3),其中是K0 是百位数, K1是十位数, K2是个位数,且0<= Ki<=9(RADIX=10)。由于每个关键字范围都相同,则按LSD进行排序更方便,即从最低位关键字字起,按关键字的不同值将序列中元素“分配”到RADIX个队列中后再“收集”之,如此重复d次,即可实现基数排序。 具体而言,第一趟分配对最低位关键字(个位数)进行,将初始序列中元素分配到RADIX个队列中去,每个队列中的元素关键字的个位数相等。f[i]和e[i]分别为第i个队列的头指针和尾指针;第一趟收集是改变所有非空队列的队尾元素的指针域,令其指向下一个非空队列的对头元素,重新将RADIX个队列中的元素链接成一个链表。第二趟分配,第二趟收集及第三趟分配,第三趟收集分别对十位数和百位数进行的,过程相同。 链式基数排序
组成(d=3),其中是K0 是百位数, K1是十位数, K2是个位数,且0<= Ki<=9(RADIX=10)。由于每个关键字范围都相同,则按LSD进行排序更方便,即从最低位关键字字起,按关键字的不同值将序列中元素 分配 到RADIX个队列中后再 收集 之,如此重复d次,即可实现基数排序。 具体而言,第一趟分配对最低位关键字(个位数)进行,将初始序列中元素分配到RADIX个队列中去,每个队列中的元素关键字的个位数相等。f[i]和e[i]分别为第i个队列的头指针和尾指针;第一趟收集是改变所有非空队列的队尾元素的指针域,令其指向下一个非空队列的对头元素,重新将RADIX个队列中的元素链接成一个链表。第二趟分配,第二趟收集及第三趟分配,第三趟收集分别对十位数和百位数进行的,过程相同。 链式基数排序.")
344
10.6基数排序(续) 109 063 930 589 184 505 269 008 083 278 e[0] e[1] e[2] e[3] e[4] e[5] e[6] e[7] e[8] e[9] f[0] f[1] f[2] f[3] f[4] f[5] f[6] f[7] f[8] f[9] 分配 269 008 589 083 930 063 184 505 278 109 063 083 184 505 278 008 109 589 269 930 收集
![10.6基数排序(续) e[0] e[1] e[2] e[3] e[4]](http://slidesplayer.com/slide/11606863/62/images/344/10.6%E5%9F%BA%E6%95%B0%E6%8E%92%E5%BA%8F%EF%BC%88%E7%BB%AD%EF%BC%89+e%5B0%5D+e%5B1%5D+e%5B2%5D+e%5B3%5D+e%5B4%5D.jpg "e[5] e[6] e[7] e[8] e[9] f[0] f[1] f[2] f[3] f[4] f[5] f[6] f[7] f[8] f[9] 分配 收集.")
345
10.6基数排序(续) 063 083 184 505 278 008 109 589 269 930 e[0] e[1] e[2] e[3] e[4] e[5] e[6] e[7] e[8] e[9] f[0] f[1] f[2] f[3] f[4] f[5] f[6] f[7] f[8] f[9] 分配 109 589 008 184 269 505 930 063 278 083 008 109 930 063 269 278 083 184 589 505 收集
![10.6基数排序(续) e[0] e[1] e[2] e[3] e[4]](http://slidesplayer.com/slide/11606863/62/images/345/10.6%E5%9F%BA%E6%95%B0%E6%8E%92%E5%BA%8F%EF%BC%88%E7%BB%AD%EF%BC%89+e%5B0%5D+e%5B1%5D+e%5B2%5D+e%5B3%5D+e%5B4%5D.jpg "e[5] e[6] e[7] e[8] e[9] f[0] f[1] f[2] f[3] f[4] f[5] f[6] f[7] f[8] f[9] 分配 收集.")
346
10.6基数排序(续) 008 109 930 063 269 278 083 184 589 505 e[0] e[1] e[2] e[3] e[4] e[5] e[6] e[7] e[8] e[9] f[0] f[1] f[2] f[3] f[4] f[5] f[6] f[7] f[8] f[9] 分配 083 063 184 278 589 008 109 269 505 930 063 083 109 184 269 278 505 589 930 008 收集
![10.6基数排序(续) e[0] e[1] e[2] e[3] e[4]](http://slidesplayer.com/slide/11606863/62/images/346/10.6%E5%9F%BA%E6%95%B0%E6%8E%92%E5%BA%8F%EF%BC%88%E7%BB%AD%EF%BC%89+e%5B0%5D+e%5B1%5D+e%5B2%5D+e%5B3%5D+e%5B4%5D.jpg "e[5] e[6] e[7] e[8] e[9] f[0] f[1] f[2] f[3] f[4] f[5] f[6] f[7] f[8] f[9] 分配 收集.")
347
10.6基数排序(续) 性能分析: 时间复杂度T(n)= O(d(n+rd)) (rd为每个关键字基数) 每一趟:分配时间复杂度O(n)
每一趟:收集时间复杂度O(rd) 供d趟: d(n+rd) 空间复杂度S(n)=O(rd) (2rd个队列指针) 稳定性: 基数排序方法是稳定的排序方法 适用情况: *元素个数n很大且关键字较小
 供d趟: d(n+rd) 空间复杂度S(n)=O(rd) (2rd个队列指针) 稳定性: 基数排序方法是稳定的排序方法. 适用情况: *元素个数n很大且关键字较小.")
348
10.7内部排序方法比较 排序方法 时间性能 空间性能 稳定性 适用情况 直接插入排序 O(n2) O(1) 稳定 n小;初始序列基本有序
希尔排序 O(n1.3) 不稳定 冒泡排序 快速排序 O(nlog2n) O(log2n) 初始序列无序 简单选择排序 堆排序 n大;只求前几位 2-路归并排序 O(n) n很大 链式基数排序 O(d(n+rd)) O(rd) n大;关键字值小
 不稳定. 冒泡排序. 快速排序. O(nlog2n) O(log2n) 初始序列无序. 简单选择排序. 堆排序. n大;只求前几位. 2-路归并排序. O(n) n很大. 链式基数排序. O(d(n+rd)) O(rd) n大;关键字值小.")
349
教学内容---第十一章 1.绪论 2.线性表 3.栈、队列和串 4.数组 5.广义表 6.树和二叉树 7.图 8.动态存储管理 9.查找
10.内部排序 11.外部排序 12.文件

350
11.1外存信息的存取 磁带信息存取 磁带为一种顺序存取设备 磁带上信息成块组织,一块为一次存取单位
磁带上读取一块信息所需时间TI/O=ta + n*tw * ta 为延迟时间,读/写头到达传输信息所在物理块起始位 置所需时间; * tw为传输一个字符的时间 检索和修改信息不方便(有时需要倒转) 顺序存取设备主要用于处理变化少、只进行顺序存取的大量数据
 顺序存取设备主要用于处理变化少、只进行顺序存取的大量数据.")
351
11.1外存信息的存取(续) 磁盘信息存取 磁盘为一种直接存取设备 磁盘上信息以扇段(块)为单位组织,一扇段为一次存取单位
磁盘上读取一块信息所需时间TI/O=tseek + tla + n*twm * tseek 为寻查时间,即读/写头定位时间(确定信息所在柱 面; (磁盘读写信息时间主要花在寻查时间上) * tla 为等待时间(latency time),即等待信息块的初始位置 转到读写头下的时间; * twm为传输时间 尽量将相关信息放在同一柱面上或临近柱面上,以提高寻查效率
 * tla 为等待时间(latency time),即等待信息块的初始位置. 转到读写头下的时间; * twm为传输时间. 尽量将相关信息放在同一柱面上或临近柱面上,以提高寻查效率.")
352
11.2外部排序的方法 外部排序 由两个阶段组成: 产生初始归并段。按可用内存大小,将外存上含n个记录的文件分成若干长度为L的段(segment),依次读入内存并利用内排方法对它们进行排序,并将排序后得到的有序段(归并段或顺串)重新写入外存 归并。对这些初始归并段进行逐趟归并,使归并段逐渐由小到大,直至得到整个有序文件。 归并效率是影响外部排序效率的关键 归并本身花费时间并不多,主要时间花费在内外存间元素的交换上

353
11.2外部排序的方法(续) 外部排序所需总时间= 内部排序(产生初始归并段)所需时间 m*tIS +外存信息读写时间 d*tIO
+内部归并所需时间 s*utmg 其中: tIS是为得到一个初始归并段进行内部排序所需时间的均值; tIO是进行一次外存读/写时间的均值;utmg 是对u个记录进行内部归并所需时间;m为经过内部排序之后得到的初始归并段的个数;s为归并的趟数;d为总的读/写次数。 一般而言,tIO取决于所用的外存设备, 且tIO >> tmg 。因此,提高外排效率应主要着眼于减少外存信息读写的次数d。

354
11.2外部排序的方法(续) s=logkm取下整;增加k或减少m便能减少s
例:假设含10,000个记录的文件,分成10个初始归并段其中每一 段都含1000个记录。设外存每个物理块容纳200个记录。 每一趟归并需进行50次“读”和50次“写”。 *若进行2-路归并: m=10; s=4;d=500(四趟归并加上内部排序时所需进行 的读/写次数)(d是影响外排效率的关键) *若进行5-路归并: m=10; s=2;d=300(两趟归并加上内部排序时所需进行 的读/写次数) *若进行k-路归并: s=logkm取下整;增加k或减少m便能减少s 可采用置换-选择排序,让各个初始归并段长度不等,从而减少m K的选择并非越大越好,要综合考虑
(d是影响外排效率的关键) *若进行5-路归并: m=10; s=2;d=300(两趟归并加上内部排序时所需进行. 的读/写次数) *若进行k-路归并: s=logkm取下整;增加k或减少m便能减少s. 可采用置换-选择排序,让各个初始归并段长度不等,从而减少m. K的选择并非越大越好,要综合考虑.")
355
11.3最佳归并树 初始归并段长度互不相等时,多路平衡归并效率与归并方案有关 归并过程用归并树描述时,树中叶子结点权值为初始归并段长度。
树的带权路径长度之和对应归并所需对外存进行的读/写次数。 要使归并效率最好,m个初始归并段归并过程应该是树的带权路径长度之和为最小的归并树描述的归并过程。即求m个结点的多叉哈夫曼树的过程。

356
11.3最佳归并树(续) 对k-路归并而言,如果初始归并段个数m不是k的倍数,则附加长度为零的“虚段”。然后按照哈夫曼树构造原则,权为零的叶子应离树根最远。 附加虚段的数目: 若(m-1) MOD (k-1) =0,则不需要附加虚段;否则附加k-(m-1) MOD (k-1) –1个虚段。 例如,当k=3时,三叉树中只有度为3和0的结点,必有n3=(n0-1)/2,由于n3为整数,则(n0-1) MOD 2 =0。对3-路归并,只有当m为偶数时,才需增加一个虚段。
/2,由于n3为整数,则(n0-1) MOD 2 =0。对3-路归并,只有当m为偶数时,才需增加一个虚段。")
357
11.3最佳归并树(续) 8个初始归并段:{9, 12, 18, 3, 17, 2, 6, 24} 补虚段后的集合: {0, 9, 12, 18, 3, 17, 2, 6, 24} 24 91 {0, 9, 12, 18, 3, 17, 2, 6, 24} 9 6 20 18 17 12 47 {5, 9, 12, 18, 17, 6, 24} {20, 12, 18, 17, 24} 3 2 5 {20, 47, 24} {91} WPL =(2+3)*3+ ( )*2+24*1 = 163
*3+ ( )*2+24*1 = 163.")
358
教学内容---第十二章 1.绪论 2.线性表 3.栈、队列和串 4.数组 5.广义表 6.树和二叉树 7.图 8.动态存储管理 9.查找
10.内部排序 11.外部排序 12.文件

359
12.1有关文件的基本概念 操作系统文件 数据库文件 单关键字文件 多关键字文件 文件 存在外存储器上的大量性质相同的记录的集合
按记录的类型不同 单关键字文件 多关键字文件 文件 存在外存储器上的大量性质相同的记录的集合 按记录是否 等长 定长记录文件 不定长记录文件

360
12.1有关文件的基本概念(续) (记录的)逻辑结构:记录在用户或应用程序员面前呈现的方式,是用户对数据的表示和存取方式.(用户读/写的单位) (记录的)物理结构:记录在物理存储器上存储的方式,是数据的物理表示和组织.(操作系统操作的单位) 物理记录与逻辑记录的对应关系: *一个物理记录存放一个逻辑记录 *一个物理记录包含多个逻辑记录 *多个物理记录表示一个逻辑记录 文件的操作包括两类:检索和修改 *检索方式包括:顺序存取;直接存取;按关键字存取 *修改包括:插入;更新;删除 (文件的)物理结构:文件在存储介质上的组织方式.基本方式包括:顺序组织、随机组织、链组织。常见文件形式有:顺序文件、索引文件、散列文件。 一个文件选取何种物理结构要考虑多种因素:存储介质类型、记录类型、记录大小、关键字数目、对文件做何操作等。
物理结构:文件在存储介质上的组织方式.基本方式包括:顺序组织、随机组织、链组织。常见文件形式有:顺序文件、索引文件、散列文件。 一个文件选取何种物理结构要考虑多种因素:存储介质类型、记录类型、记录大小、关键字数目、对文件做何操作等。")
361
12.2文件存储结构 顺序文件 顺序文件:记录按其在文件中的逻辑顺序依次进入存储介质,即顺序文件中物理记录和顺序和逻辑记录的顺序是一致的.
连续文件:若次序相邻的两个物理记录在存储介质上的存储位置是相邻的,则称这种顺序文件为连续文件. 串联文件:若物理记录之间的次序由指针相链表示,则称这种顺序文件为串联文件. 磁带介质和磁盘介质中都可以用顺序文件

362
12.2文件存储结构(续) 顺序文件特点: *存取第i个记录,必须先搜索在它之前的i-1个记录; *插入新的记录时只能加在文件的末尾;
*若要更新文件中某个记录,则必须将整个文件进行复制 顺序文件优点: *连续存取速度块(只适用于 顺序存取、批量修改)
")
363
12.2文件存储结构(续) 索引文件 索引文件:包括文件数据区和索引表两大部分的文件.数据区为文件本身,索引表是一张指示逻辑记录和物理记录之间一一对应关系的表。索引表中索引项(索引表中每一项)总是按关键字(或逻辑记录号)顺序排列。 索引顺序文件:数据区中记录也按关键字顺序排列的索引文件 索引非顺序文件:数据区中记录不按关键字顺序排列的索引文件 多级索引:索引表很大时,可以为索引表建立索引,形成“查找表”。(一般最高可以有四级索引:索引表---查找表---第二查找表---第三查找表) 索引文件只能适用于磁盘存储介质
 索引文件只能适用于磁盘存储介质.")
364
12.2文件存储结构(续) 索引文件的检索: *索引表长度比记录小得多,一般可一次读入在内存中,
*一级索引文件中检索最多只访问外存两次: 一次读索 引,一次读记录;多级索引文件中检索文件时,先查找 查找表,再查索引表,然后读取记录 *索引表有序,在索引表中查找可以用高效方法 索引文件的修改: *删除一个记录时,仅需删去相应的索引项; *插入一个记录时,应将记录置于数据区的末尾,同时 在索引表中插入索引项; *更新记录时,应将更新后的记录置于数据区的末尾, 同时修改索引表中相应的索引项

365
12.2文件存储结构(续) ISAM文件和VSAM文件都是索引顺序文件。
索引顺序存取方法ISAM(Indexed Sequential Access Method):专为磁盘存取设计的文件组织形式。对磁盘上的数据文件建立盘组、柱面和磁道三级索引。 虚拟存储存取方法VSAM(Virtual Storage Access Method):利用操作系统的虚拟存储器。对用户来说,文件只有控制区间和控制区域等逻辑存储单位,与外存器中具体存储单位没有必然联系。VSAM文件由三部分组成:索引集、顺序集和数据集。文件的记录在数据集中。顺序集和索引集一起构成一棵B+树,为文件的索引部分。
:专为磁盘存取设计的文件组织形式。对磁盘上的数据文件建立盘组、柱面和磁道三级索引。 虚拟存储存取方法VSAM(Virtual Storage Access Method):利用操作系统的虚拟存储器。对用户来说,文件只有控制区间和控制区域等逻辑存储单位,与外存器中具体存储单位没有必然联系。VSAM文件由三部分组成:索引集、顺序集和数据集。文件的记录在数据集中。顺序集和索引集一起构成一棵B+树,为文件的索引部分。")
366
12.2文件存储结构(续) 直接存取文件(散列文件)
直接存取文件(散列文件):利用杂凑(Hash)法进行组织的文件。根据哈希函数和处理冲突的方法将记录散列到存储设备上。 思路类似于哈希表,但磁盘上文件成组存放,多个记录组成一个存储单位(桶bucket)。若一个桶能放m个记录,则m个同义词的记录可以存放在同一地址的桶中,而当m+1个同义词出现时才发生“溢出”,这时才处理冲突。 常用链地址法处理冲突
:利用杂凑(Hash)法进行组织的文件。根据哈希函数和处理冲突的方法将记录散列到存储设备上。 思路类似于哈希表,但磁盘上文件成组存放,多个记录组成一个存储单位(桶bucket)。若一个桶能放m个记录,则m个同义词的记录可以存放在同一地址的桶中,而当m+1个同义词出现时才发生 溢出 ,这时才处理冲突。 常用链地址法处理冲突.")
367
12.2文件存储结构(续) 直接存取文件(散列文件)优点: *文件随机存放,记录不需要进行排序; *插入、删除方便; *存取速度快;
*不需要索引区,节省存储空间 直接存取文件(散列文件)缺点: *不能进行顺序存取,只能按关键字随机存取; *多次插入、删除后可能导致文件结构不合理,可能需 要重组文件;
缺点: *不能进行顺序存取,只能按关键字随机存取; *多次插入、删除后可能导致文件结构不合理,可能需. 要重组文件;")
Similar presentations







>")
和二叉树 5.1 树的基本概念 5.2 二叉树 5.3 遍历二叉树和线索二叉树 5.4 树和森林>")










