Download presentation
Presentation is loading. Please wait.

1
第 二 章 關聯式資料庫

2
本章學習目標 1.瞭解何謂關聯式資料庫(Relational Database)及其定義。 2.瞭解關聯式資料庫的各種專有名詞及
三種關聯模型。 3.瞭解關聯式資料完整性中的三種整合 性法則。 開始: 本章學習目標 有二項:

3
本章內容 2-1 關聯式資料庫(Relation Database) 2-2 鍵值屬性 2-3 關聯式資料庫的種類 2-4 關聯式資料完整性
2-2 鍵值屬性 2-3 關聯式資料庫的種類 2-4 關聯式資料完整性 1-1 認識資料與資訊的關係: 其中,「資料」轉換成「資訊」必須要經過一連串處理過程,而這一連串的處理過程就是透過「程式」來處理。 1-2 何謂資料結構? 「資料結構」(Data Structures)主要是探討如何將資料更有組織地存放到電腦記憶體中,以提昇程式之執行效率的一 門學問。 1-3 何謂演算法?演算法就是「解決問題的方法」 1-4 程式設計概念: 步驟1. 分析所要解決的問題 步驟2. 設計解題的步驟 步驟3. 編寫程式 步驟4. 上機測試、偵測錯誤 步驟5. 編寫程 式說明書 1-5 結構化程式設計 利用「由上而下」的技巧,將程式分解成許多個獨立功能的模組。並且每一個模組都是由三種結構所組成。分別為循序結構、選擇結構及重複結構。 1-6 演算法的效率評估 指用來計算某些演算法所撰寫的程式,在經過編譯之後,實際執行所需要的時間。
主要是探討如何將資料更有組織地存放到電腦記憶體中,以提昇程式之執行效率的一. 門學問。 1-3 何謂演算法 演算法就是「解決問題的方法」 1-4 程式設計概念: 步驟1. 分析所要解決的問題 步驟2. 設計解題的步驟 步驟3. 編寫程式 步驟4. 上機測試、偵測錯誤 步驟5. 編寫程. 式說明書. 1-5 結構化程式設計. 利用「由上而下」的技巧,將程式分解成許多個獨立功能的模組。並且每一個模組都是由三種結構所組成。分別為循序結構、選擇結構及重複結構。 1-6 演算法的效率評估. 指用來計算某些演算法所撰寫的程式,在經過編譯之後,實際執行所需要的時間。")
4
2.1 關聯式資料庫(Relation Database)
1.是由一群相互關係的正規化關聯(表格)所組成。 2.關聯(表格)之間是透過相同的欄位值(即外鍵FK ;Foreign Key)來連繫。 3.關聯(表格)中的所有屬性內含值都是基元值(Atomic Value) 。
所組成。 2.關聯(表格)之間是透過相同的欄位值(即外鍵FK ;Foreign. Key)來連繫。 3.關聯(表格)中的所有屬性內含值都是基元值(Atomic Value) 。")
6
2-1 關聯式資料庫(Relation Database)
假設學校行政系統中有一個尚未分割的「學籍資料表」,如下表所示: 由上表中,我們可以清楚看出多筆資料重複現象,如果有某一筆資料打錯, 將會導致資料不一致現象。例如:在上表中的第5筆記錄的系主任,應該是「李碩安」卻打成「李安」。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

7
因此,我們就必須要將原始的「學籍資料表」分割成數個不重複的資料表,再利用「關聯式資料庫」的方法來進行資料表的關聯。
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

8
因此,我們就必須要將原始的「學籍資料表」分割成數個不重複的資料表,再利用「關聯式資料庫」的方法來進行資料表的關聯。
何謂「關聯式資料庫」呢?它是由兩個或兩個以上的資料表組合而成。其目的: 1.節省重複輸入的時間與儲存空間。 2.確保異動資料(新增、修改、刪除)時的一致性及完整性。 因此,我們必須將各種資料依照性質的不同(如:學籍資料、選課資料,課程資料,學習歷程資料等…‥),分別存放在幾個不同的表格中,表格與表格之間的關係,則以共同的欄位值(如:「學號」欄位…)相互連結,以這種方式來存放資料的資料庫,在電腦術語中,稱為「關聯式資料庫(Relational Database)」。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
時的一致性及完整性。 因此,我們必須將各種資料依照性質的不同(如:學籍資料、選課資料,課程資料,學習歷程資料等…‥),分別存放在幾個不同的表格中,表格與表格之間的關係,則以共同的欄位值(如:「學號」欄位…)相互連結,以這種方式來存放資料的資料庫,在電腦術語中,稱為「關聯式資料庫(Relational Database)」。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
9
1.是由一群相互關係的正規化關聯(表格)所組成。 2.關聯(表格)之間是透過相同的欄位值(即外鍵參考主鍵)來連繫。
【定義】 1.是由一群相互關係的正規化關聯(表格)所組成。 2.關聯(表格)之間是透過相同的欄位值(即外鍵參考主鍵)來連繫。 3.關聯(表格)中的所有屬性內含值都是基元值(Atomic Value)。 因此,我們可以將上表中的「學籍資料表」分割為「學生資料表」與「科系代碼表」,如何產生關聯式資料庫呢?它是透過兩個資料表的相同欄位值(即系碼)來進行連結。如下所示: 註:「主鍵」與「外鍵」專有名詞會有後面章節中詳細介紹。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
所組成。 2.關聯(表格)之間是透過相同的欄位值(即外鍵參考主鍵)來連繫。 3.關聯(表格)中的所有屬性內含值都是基元值(Atomic Value)。 因此,我們可以將上表中的「學籍資料表」分割為「學生資料表」與「科系代碼表」,如何產生關聯式資料庫呢?它是透過兩個資料表的相同欄位值(即系碼)來進行連結。如下所示: 註:「主鍵」與「外鍵」專有名詞會有後面章節中詳細介紹。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
10
因為資料不須再重複輸入,故可以節省行政人員的輸入時間。 3.達成資料的一致性 因為資料不須再重複輸入,故可以減少多次輸入產生人為的錯誤。
【優點】 1.節省記憶體空間 相同的資料記錄不須要再重複輸入。 2.提高行政效率 因為資料不須再重複輸入,故可以節省行政人員的輸入時間。 3.達成資料的一致性 因為資料不須再重複輸入,故可以減少多次輸入產生人為的錯誤。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

11
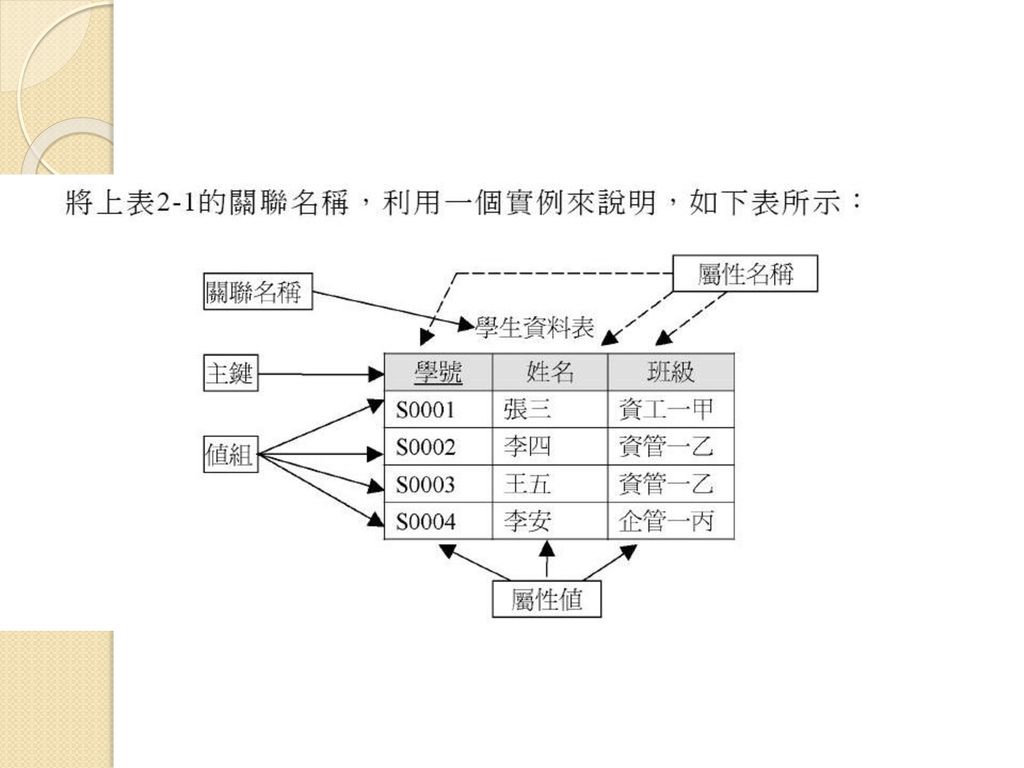
【關聯名詞】 關聯式資料庫模型的相關術語通常是用來說明資料庫系統的相關理論,而SQL Server或Access等資料庫管理系統所使用的資料庫相關名詞是利用另成一套術語,不過這些名詞或術語都代表相同意義,如表2-1所示: 表2-1 關聯名詞比較表 關聯式資料模型 SQL Server或Access 關聯(Relation) 表格(Table) 值組(Tuple) 橫列(Row)或記錄(Record) 屬性(Attribute) 直欄(Column)或欄位(Filed) 基數(Cardinality) 記錄個數(number of Record) 主鍵(Primary Key) 唯一識別(unique identifier) 定義域(Domain) 合法值群(pool legal values) 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
 表格(Table) 值組(Tuple) 橫列(Row)或記錄(Record) 屬性(Attribute) 直欄(Column)或欄位(Filed) 基數(Cardinality) 記錄個數(number of Record) 主鍵(Primary Key) 唯一識別(unique identifier) 定義域(Domain) 合法值群(pool legal values) 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
12
例如:上表中的第一筆記錄。#1 S0001,一心,D001。
圖示說明: 【重要專有名詞】 1.資料表(Table):又稱為表格,它是真正儲存資料的地方。它可視為特 定主題的資料集合。並且它是由「資料行」與「資料列」的二維表格 組合而成。 例如:上表中的「學生資料表」。 2.資料行(Column):是指資料表中的某些「欄位」,它是以「垂直」方 式來呈現。 例如:上表中的「學號」、「姓名」等。 3.資料列(Row) :是指資料表中某些「記錄」,它是以「水平」方式來呈現。 例如:上表中的第一筆記錄。#1 S0001,一心,D001。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
:又稱為表格,它是真正儲存資料的地方。它可視為特. 定主題的資料集合。並且它是由「資料行」與「資料列」的二維表格. 組合而成。 例如:上表中的「學生資料表」。 2.資料行(Column):是指資料表中的某些「欄位」,它是以「垂直」方. 式來呈現。 例如:上表中的「學號」、「姓名」等。 3.資料列(Row) :是指資料表中某些「記錄」,它是以「水平」方式來呈現。 例如:上表中的第一筆記錄。#1 S0001,一心,D001。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
13
圖示說明: 【重要專有名詞】 4.主鍵( Primary Key; PK):是指用來識別記錄的唯一性,它不可以重複及 空值(Null)。
例如:上表中的學生資料表中的「學號」及科系代碼表中的「系碼」 5.外鍵( Foreign Key; FK):是指用來建立資料表之間的關係,其外鍵內含值 必須要與另一個資料表的主鍵相同。 例如:上表中的學生資料表中的「系碼」。 6.關聯性(Relationship):在資料表之間,透過外鍵來參考另一個資料 表的主鍵,如果具有相同欄位值就可以進行關聯。 例如:上表中的學生資料表中的「系碼」與科系代碼表中的「系碼」都具有 相同欄位值,因此,就可以進行關聯。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
:是指用來建立資料表之間的關係,其外鍵內含值. 必須要與另一個資料表的主鍵相同。 例如:上表中的學生資料表中的「系碼」。 6.關聯性(Relationship):在資料表之間,透過外鍵來參考另一個資料. 表的主鍵,如果具有相同欄位值就可以進行關聯。 例如:上表中的學生資料表中的「系碼」與科系代碼表中的「系碼」都具有. 相同欄位值,因此,就可以進行關聯。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
14
2-2 鍵值屬性 在關聯式資料庫中,每一個關聯(表格)會有許多不同的鍵值屬性(Key Attribute),因此,我們可以分成兩個部份來探討: 一、屬性(Attribute):是指一般屬性或欄位。如下圖所示。 二、鍵值屬性(Key Attribute):是指由一個或一個以上的屬性所組成, 並且在一個關聯中,必須要具有「唯一性」的屬性來當作「鍵(Key)」。 例如:在關聯式資料庫中,常見的鍵(Key)可分為:超鍵、候選鍵、主 鍵及交替鍵,其各鍵的關係,如下圖所示。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
:是指由一個或一個以上的屬性所組成, 並且在一個關聯中,必須要具有「唯一性」的屬性來當作「鍵(Key)」。 例如:在關聯式資料庫中,常見的鍵(Key)可分為:超鍵、候選鍵、主. 鍵及交替鍵,其各鍵的關係,如下圖所示。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
15
2-2.1 屬性(Attribute) 【定義】用來描述實體的性質(Property)。 【例如】
學號、姓名、「性別」都是用來描述學生實體的性質,並且每一個屬 性一定要有一個定義域(Domain)(亦即資料類型、範圍大小等)。其中, 「性別」屬性的內含值,必須是「男生」或「女生」,而不能超出定 義域(Domain)的合法值群。 【分類】 1.簡單屬性(Simple Attribute) 2.複合屬性(Composite Attribute) 3.衍生屬性(Derived Attribute) 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
(亦即資料類型、範圍大小等)。其中, 「性別」屬性的內含值,必須是「男生」或「女生」,而不能超出定. 義域(Domain)的合法值群。 【分類】 1.簡單屬性(Simple Attribute) 2.複合屬性(Composite Attribute) 3.衍生屬性(Derived Attribute) 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
16
1.簡單屬性(Simple Attribute)
【定義】已經無法再繼續切割成其他有意義的單位,亦即該屬性為 基元值(Atomic Value)。 【例如】「學號」屬性便是「簡單屬性」。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
。 【例如】「學號」屬性便是「簡單屬性」。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
17
2.複合屬性(Composite Attribute)
【定義】由兩個或兩個以上的其他屬性的值所組成。 【例如】 「地址」屬性是由區域號碼、縣市、鄉鎮、路、巷、弄、號等 各個屬性所組成。 【適用時機】戶政事務查詢,房屋仲介網站… 那些屬性是屬於「複合屬性」呢?必須要視需求而定。一般使用者在設定客戶資料表或學生資料表時, 「地址」屬性是視為「簡單屬性」。 【優點】大量查詢時,較快速。 where 地址 Like ‘*苓雅區*’速度較慢 where 區域=‘苓雅區’ 速度較快 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

18
3.衍生屬性(Derived Attribute)
【定義】 指可以經由某種方式的計算或推論而獲得的。 【例如1】 「年齡」屬性便屬於「衍生屬性」。 以實際的年齡為例,可以由「目前的系統時間」減去「生日」屬性的 值,便可換算出「年齡」屬性的值。 年齡=目前的系統時間─生日 SELECT DATEDIFF(YY,'1971/10/9',getdate()); 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法 Dim Age As Integer Age = Year(Now()) - Val(TextBox1.Text) Label3.Text = "您今年 " & Age & " 歲” 程式名稱: ch2\ch2-2\ch2-2.sln
); 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法. Dim Age As Integer. Age = Year(Now()) - Val(TextBox1.Text) Label3.Text = 您今年 & Age & 歲 程式名稱: ch2\ch2-2\ch2-2.sln.")
19
【例如2】 「性別」屬性也可以當作「衍生屬性」。
假設使用者輸入介面中有「身分證字號」欄位時,則我們可以判斷使用者的性別是「男生」或「女生」。 【作法】輸入ID,判斷第二位數字,如果是’1’代表「男生」 如果是’2’代表「女生」 Dim ID As String Dim Sex_word As String ID = TextBox1.Text Sex_word = Mid(ID, 2, 1) If Sex_word = "1" Then Label3.Text = "您是男生" Else Label3.Text = "您是女生" End If 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
 If Sex_word = 1 Then. Label3.Text = 您是男生 Else. Label3.Text = 您是女生 End If. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
20
超鍵(Super Key) 基本上,我們會在每一個資料表中,選出一個具有唯一性的欄位來當作「主鍵」,但是,在一個資料表中,如果找不到具有唯一性的欄位時,我們也可以選出兩個或兩個以上的欄位組合起來,以作為唯一識別資料的欄位。 【定義】 是指在一個資料表中,選出兩個或兩個以上的欄位組合起來,以作為唯一識別資料的欄位,因此,我們可以稱這種組合出來的欄位,就是「超鍵」。在一個關聯(表格)中至少有一個「超鍵」,就是所有屬性的集合。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
中至少有一個「超鍵」,就是所有屬性的集合。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
21
【例如】 以「學生資料表」為例,若是全班的學生姓名中,若有人同名同姓時(重複),則我們可以搭配學生的學號,讓「學生的學號」與「學生的姓名」兩欄位結合起來(亦即「學號+姓名」)來產生新的鍵。所以,{姓名,學號}是一個超鍵。因為不可能有兩個學生的姓名與學號皆相同。{身份證字號}也是一個超鍵。 同名同姓 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法 設定{姓名,學號}為超鍵

22
{姓名,學號,身份證字號,年齡,系別},{姓名,學號,身份證字號,年齡}也都是超鍵。因為它可以造成唯一性的限制。
【同理】 {姓名,學號,身份證字號,年齡,系別},{姓名,學號,身份證字號,年齡}也都是超鍵。因為它可以造成唯一性的限制。 【分析】 1.{年齡}或{姓名}都不是「超鍵」 。 2.最大的「超鍵」是所有屬性的集合; 最小的「超鍵」則是關聯的主鍵。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

23
主鍵(Primary Key) 在關聯式資料庫模型中,將每一個資料表視為一個「實體」,而每一個實體利用「屬性」描述之,而這些屬性就稱為「鍵值」。其中用來識別資料表中記錄的唯一值的鍵值,稱為「主鍵」。 【定義】 1.從候選鍵中選擇一個用來唯一識別值組(記錄)的鍵,稱為主鍵。 2.在關聯綱要裡,我們會在主鍵的屬性名稱加一個底線。 3.在一個關聯中,只有一個主鍵,若候選鍵未被選為主鍵時,則稱為 「交替鍵(Alternate Key)」。 4.主鍵之鍵值不可為虛值(Null Value) 。 5.在建立資料表時一般都是以「P.K.」來代表主鍵。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
的鍵,稱為主鍵。 2.在關聯綱要裡,我們會在主鍵的屬性名稱加一個底線。 3.在一個關聯中,只有一個主鍵,若候選鍵未被選為主鍵時,則稱為. 「交替鍵(Alternate Key)」。 4.主鍵之鍵值不可為虛值(Null Value) 。 5.在建立資料表時一般都是以「P.K.」來代表主鍵。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
24
【舉例】學生資料表(學號,姓名,生日,身分證字號,科系) (1)候選鍵:(學號)或(身分證字號) (2)主鍵:學號 (3)交替鍵:身分證字號
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

25
基本上,我們要從多個鍵值中挑選「主鍵」時,會依循以下三個原則: 1.固定不會再變更的值
【如何挑選主鍵?】 基本上,我們要從多個鍵值中挑選「主鍵」時,會依循以下三個原則: 1.固定不會再變更的值 在挑選「主鍵」時,必須要找永遠不會被變更的欄位,否則會增加爾 後的管理和維護資料的困難度與複雜性。 例如:「學號」與「身份證字號」在決定之後,幾乎不會再改變。 2.單一的屬性 在一個資料表中,最好只選取「單一屬性」的候選鍵作為主鍵,因為 可以節省記憶體空間及提高執行效率。 例如:{姓名+學號}與{學號},雖然二者都具有唯一性,但是後者 {學號}是單一屬性。 3.不可以為空值或重覆 依照「關聯式資料完整性規則」,主鍵的鍵值不可以重覆,也不可以 為空值(NULL)。 例如:{姓名}欄位就不適合當作主鍵欄位。因為可能會重複。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
。 例如:{姓名}欄位就不適合當作主鍵欄位。因為可能會重複。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
26
【SQL Server 上機實作】 以圖2-1關聯式資料庫為例: 步驟一:先建立一個「學生資料表」,並且包括「學號」、「姓名」及「系碼」
三個欄位名稱,如下圖所示: 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

27
步驟二:將滑鼠移到欲設定「主鍵」欄位名稱的最左邊,再按功能表中 的「設定主索引鍵」圖示即可。
設定後的結果如下圖示: 說明:「學號」欄位名稱的最左邊就會自動出現一支黃色的鑰匙,即代表 「學號」設定為「主鍵」。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

28
步驟三:請在學生資料表中先輸入五筆記錄如下圖示:
再新增第六筆記錄,其學號為S0001的李安,系碼為D001的學生。 以證明主鍵是具有唯一性,不可以重複的。 因此,SQL Server就會馬上出現錯誤的畫面,即代表第六筆無法新增。如下圖所示: 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法 第六筆無法新增

29
2-2.4 複合鍵(Composite Key) 【定義】是指資料表中的主鍵,是由兩個或兩個欄位以上所組成,這種
【使用時機】 當表格中某一欄位的值無法區分資料記錄時,可以使用這種方法。 【例如】 在表2-2a中「縣市」的欄位值有重複,無法區分出每一筆記錄,所以「縣市」欄位不能當作主鍵欄位。因此,必須要把「縣市」與「區域」兩個欄位組合在一起,當作主鍵欄位。如表2-2b所示。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法 重複 重複

30
【SQL Server 上機實作】 以上面的例子為例: 步驟一:先建立一個「城市區域資料表」,並且包括「縣市」及「區域」兩個
欄位名稱,並輸入四筆記錄。如下圖所示: 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

31
說明:「縣市」及「區域」兩個欄位名稱的最左邊就會各出現一支黃色的鑰匙, 即代表「縣市」及「區域」設定為「複合鍵」。
步驟二:將滑鼠移到欲設定「主鍵」欄位名稱的最左邊,按住滑鼠左鍵往下選取「縣市」及「區域」兩個欄位名稱,再按功能表中的「設定主索引鍵」圖示即可。 設定後的結果如下圖示: 說明:「縣市」及「區域」兩個欄位名稱的最左邊就會各出現一支黃色的鑰匙, 即代表「縣市」及「區域」設定為「複合鍵」。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

32
2-2.5 候選鍵(Candidate Key) 【定義】候選鍵就是主鍵的候選人,並且也是關聯表的屬性子集所組成。 【條件】
一個屬性(欄位)是要成為候選鍵,則必須同時要符合下列兩項條件: 1.具有唯一性 是指在一個關聯表中,用來唯一識別資料記錄的欄位。 例如:超鍵(Super Key)。但可以是由多個欄位組合{縣市+區域}而成。 2.具有最小性 是指除了符合「唯一性」的條件之外,還必須要在該「屬性子集」中 移除任一個屬性之後,不再符合唯一性。亦即鍵值欄位個數為最小。 例如: {縣市+區域}組合成來符合「唯一性」的條件。並且在移除任 一個屬性{區域}之後, {縣市}不再符合唯一性。因此, {縣市 +區域}就是候選鍵。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
是要成為候選鍵,則必須同時要符合下列兩項條件: 1.具有唯一性. 是指在一個關聯表中,用來唯一識別資料記錄的欄位。 例如:超鍵(Super Key)。但可以是由多個欄位組合{縣市+區域}而成。 2.具有最小性. 是指除了符合「唯一性」的條件之外,還必須要在該「屬性子集」中. 移除任一個屬性之後,不再符合唯一性。亦即鍵值欄位個數為最小。 例如: {縣市+區域}組合成來符合「唯一性」的條件。並且在移除任. 一個屬性{區域}之後, {縣市}不再符合唯一性。因此, {縣市. +區域}就是候選鍵。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
33
1.候選鍵可以唯一識別值組(記錄),大部份關聯都只有一個候選鍵。 2.若候選鍵只包含一個屬性時,稱為簡單(simple)候選鍵。
【特性】 1.候選鍵可以唯一識別值組(記錄),大部份關聯都只有一個候選鍵。 2.若候選鍵只包含一個屬性時,稱為簡單(simple)候選鍵。 例如: {學號} 若包含兩個或兩個以上屬性時,稱為複合(composite)候選鍵。 例如: {縣市+區域} 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
,大部份關聯都只有一個候選鍵。 2.若候選鍵只包含一個屬性時,稱為簡單(simple)候選鍵。 例如: {學號} 若包含兩個或兩個以上屬性時,稱為複合(composite)候選鍵。 例如: {縣市+區域} 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
34
【舉例1】假設現在有一個「學生資料表」,其相關的欄位如下所示: 學生資料表(學號,姓名,生日,身分證字號,科系)
請找出此資料表中的兩個「候選鍵」。 【解答】第一個候選鍵 (1)找出「具有唯一性」的欄位 {學號+姓名}共同組成時,滿足唯一性。 (2)檢查是否「具有最小性」 但是{學號+姓名} 不滿足最小性,因為在移去「姓名」屬性之後, 「學號」仍然具有唯一性。 因此,我們必須要縮減為最小欄位為{學號},所以找到第一個候選鍵。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
找出「具有唯一性」的欄位. {學號+姓名}共同組成時,滿足唯一性。 (2)檢查是否「具有最小性」 但是{學號+姓名} 不滿足最小性,因為在移去「姓名」屬性之後, 「學號」仍然具有唯一性。 因此,我們必須要縮減為最小欄位為{學號},所以找到第一個候選鍵。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
35
所以,{學號}或{身分證字號}皆為「候選鍵」
學生資料表(學號,姓名,生日,身分證字號,科系) 【解答】第二個候選鍵 (1)找出「具有唯一性」的欄位 {身分證字號+科系}共同組成時,滿足唯一性。 (2)檢查是否「具有最小性」 但是{身分證字號+科系} 不滿足最小性,因為在移去「科系」屬性 之後,「身分證字號」仍然具有唯一性。 因此,我們必須要縮減為最小欄位為{身分證字號}, 所以找到第二個候選鍵。 所以,{學號}或{身分證字號}皆為「候選鍵」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
 【解答】第二個候選鍵. (1)找出「具有唯一性」的欄位. {身分證字號+科系}共同組成時,滿足唯一性。 (2)檢查是否「具有最小性」 但是{身分證字號+科系} 不滿足最小性,因為在移去「科系」屬性. 之後,「身分證字號」仍然具有唯一性。 因此,我們必須要縮減為最小欄位為{身分證字號}, 所以找到第二個候選鍵。 所以,{學號}或{身分證字號}皆為「候選鍵」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
36
所以, {姓名+生日}為「複合式候選鍵」 【舉例2】假設現在有一個「通訊錄資料表」,其相關的欄位如下所示:
通訊錄資料表(姓名,生日,電話,地址) 請找出此資料表中的一個「候選鍵」。 【解答】 (1)找出「具有唯一性」的欄位 {姓名+生日}共同組成時,滿足唯一性。 (2)檢查是否「具有最小性」 並且{姓名+生日} 也滿足最小性,因為在移去「生日」屬性之後, 「姓名」就不具有唯一性。 因此, {姓名+生日} 兩個欄位組合,缺一不可,所以這種候選鍵又稱 為「複合式候選鍵」。 所以, {姓名+生日}為「複合式候選鍵」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
 請找出此資料表中的一個「候選鍵」。 【解答】 (1)找出「具有唯一性」的欄位. {姓名+生日}共同組成時,滿足唯一性。 (2)檢查是否「具有最小性」 並且{姓名+生日} 也滿足最小性,因為在移去「生日」屬性之後, 「姓名」就不具有唯一性。 因此, {姓名+生日} 兩個欄位組合,缺一不可,所以這種候選鍵又稱. 為「複合式候選鍵」。 所以, {姓名+生日}為「複合式候選鍵」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
37
問題 ?

38
外來鍵(Foreign Key) 在關聯式資料庫中,任兩個資料表要進行關聯(對應)時,必須要透過「外來鍵」參考「主鍵」才能建立,其中「主鍵」值的所在資料表稱為「父關聯」,而「外來鍵」值的所在資料表稱為「子關聯」。 【定義】 外來鍵是指「父關聯嵌入的鍵」,並且外來鍵在父關聯中扮演「主鍵」的角色。因此,外來鍵一定會存放另一個資料表的主鍵,主要目的是用來確定資料的參考完整性。所以,當父關聯的「主鍵」值不存在時,則「子關聯」的「外來鍵」值也不可能存在。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法 子關聯 父關聯

39
1. 「子關聯」的外鍵必須對應「父關聯」的主鍵。 2. 外鍵是用來建立「子關聯」與「父關聯」的連結關係。
【外來鍵的特性】 1. 「子關聯」的外鍵必須對應「父關聯」的主鍵。 2. 外鍵是用來建立「子關聯」與「父關聯」的連結關係。 例如:張三同學可以找到對應的系主任。 說明:在SQL語言中,通常是「主鍵值=外來鍵值」當作條件式 例如:在SELECT之WHERE子句中撰寫如下: 說明:以上SQL指令是用來聯結「學生資料表」 和「科系代碼表」兩個資料表。 參考 嵌入 子關聯 父關聯 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法 學生資料表.系碼=科系代碼表.系碼

40
3.外來鍵和「父關聯」的主鍵欄位必須要具有相同定義域,亦即相同的 資料型態和欄位長度,但名稱則可以不相同。
【外來鍵的特性】<續> 3.外來鍵和「父關聯」的主鍵欄位必須要具有相同定義域,亦即相同的 資料型態和欄位長度,但名稱則可以不相同。 【舉例1】相同的資料型態和欄位長度 假設現在有一個關聯圖如下: 其中,「科系代碼表」的「系碼」欄位的資料類型為「nvarchar(4)」,現在欲改為「nchar(10)」的資料類型,則會出現以下的錯誤產生: 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
」,現在欲改為「nchar(10)」的資料類型,則會出現以下的錯誤產生: 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
41
【舉例2】外來鍵和「父關聯」的主鍵欄位名稱則可以不相同 假設現在有一個關聯圖如下:
其中,「科系代碼表」的「系碼」欄位名稱,現在欲改為「科系代碼」欄位名稱,則是可以的。如下圖所示: 註:因此,我們可以清楚得知,「子關聯」的外來鍵參考「父關聯」 的主鍵時,是透過「相同的欄位值」。而「非相同的欄位名稱」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

42
4.外來鍵的欄位值可以是重覆值或空值(NULL) 。 (1)「重覆值」的例子
【外來鍵的特性】<續> 4.外來鍵的欄位值可以是重覆值或空值(NULL) 。 (1)「重覆值」的例子 說明:在上表中,代表張三與李四都是就讀「資工系」 參考 重覆值 子關聯 父關聯 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
 。 (1)「重覆值」的例子. 說明:在上表中,代表張三與李四都是就讀「資工系」 參考. 重覆值. 子關聯. 父關聯. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
43
4.外來鍵的欄位值可以是重覆值或空值(NULL) 。 (2)空值(NULL)的例子
【外來鍵的特性】<續> 4.外來鍵的欄位值可以是重覆值或空值(NULL) 。 (2)空值(NULL)的例子 說明:在上表中,代表王五尚未決定要就讀那一個科系 參考 空值 子關聯 父關聯 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
 。 (2)空值(NULL)的例子. 說明:在上表中,代表王五尚未決定要就讀那一個科系. 參考. 空值. 子關聯. 父關聯. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
44
【歸納主鍵與外鍵的關係】 1.父關聯表中的「主鍵」值,一定不能為空(Null),也不能有重複現象。
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

45
【SQL Server 上機實作】 以上面的例子為例: 步驟一:先建立一個「學生資料表」與「科系代碼表」,如下圖所示: 學生資料表
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

46
步驟二:在「ch2_DB」資料庫中的「資料庫圖表」上,按下「右鍵」之後,再點選「新增資料庫圖表」,如下圖所示:
按「右鍵」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

47
步驟三:在「加入資料表」對話方塊中,滑鼠先移到「科系代碼表」上,按住「Ctrl」鍵,再點選「學生資料表」之後,再按「加入」鈕,最後再按「關閉」鈕即可。
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

48
步驟四:顯示兩個資料表準備作關聯圖,而在每一個資料表中都有一個比較粗體的欄位名稱,即所謂「主鍵」,也就是具有唯一性的欄位。
步驟五:在上圖中,請將滑鼠移到「科系代碼表」內的「系碼」欄位上(即主鍵),按住滑鼠左鍵拖曳到「學生資料表」內的「系碼」欄位上(即外鍵),此時便會出現一條長條形的方塊之後,放掉滑鼠左鍵,此時, 馬上出現一個「資料表和資料行」之編輯關聯對話方塊。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
,按住滑鼠左鍵拖曳到「學生資料表」內的「系碼」欄位上(即外鍵),此時便會出現一條長條形的方塊之後,放掉滑鼠左鍵,此時, 馬上出現一個「資料表和資料行」之編輯關聯對話方塊。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
49
在按「確定」鈕之後,即可建立「學生資料表」與「科系代碼表」的資料庫關聯圖了。如下圖所示:
主鍵 外鍵 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

50
步驟六:儲存資料庫關聯圖名稱。 在建立完成資料庫關聯圖之後,再按工具列上的「儲存」鈕之後,會出現「選擇名稱」的對話方塊,此時,請輸入「學生科系資料庫關聯圖」後,再按「確定」鈕即可。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

51
2-3 關聯式資料庫的種類 假設現在有甲與乙兩個資料表,其「關聯式資料庫」中資料表的關聯種類可以分為下列三種: 1.一對一的關聯(1:1):
2-3 關聯式資料庫的種類 假設現在有甲與乙兩個資料表,其「關聯式資料庫」中資料表的關聯種類可以分為下列三種: 1.一對一的關聯(1:1): 甲資料表中的一筆記錄,只能對應到乙資料表中的一筆記錄,並且乙資料表中的一筆記錄,只能對應到甲資料表中的一筆記錄。 2.一對多的關聯(1:M): 甲資料表中的一筆記錄,可以對應到乙資料表中的多筆記錄,但是乙資料表中的一筆記錄,卻只能對應到甲資料表中的一筆記錄。 3.多對多的關聯(M:N): 甲資料表中的一筆記錄,能夠對應到乙資料表中的多筆記錄,並且乙資料表中的一筆記錄,也能夠對應到甲資料表中的多筆記錄。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
: 甲資料表中的一筆記錄,只能對應到乙資料表中的一筆記錄,並且乙資料表中的一筆記錄,只能對應到甲資料表中的一筆記錄。 2.一對多的關聯(1:M): 甲資料表中的一筆記錄,可以對應到乙資料表中的多筆記錄,但是乙資料表中的一筆記錄,卻只能對應到甲資料表中的一筆記錄。 3.多對多的關聯(M:N): 甲資料表中的一筆記錄,能夠對應到乙資料表中的多筆記錄,並且乙資料表中的一筆記錄,也能夠對應到甲資料表中的多筆記錄。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
52
2-3.1 一對一關聯(1:1) 【定義】 假設現在有甲與乙兩個資料表,在一對一關聯中,甲資料表中的一筆記錄,只能對應到乙資料表中的一筆記錄,並且乙資料表中的一筆記錄,只能對應到甲資料表中的一筆記錄。 【舉例】 以「成績處理系統」為例,當兩個資料表之間做一對一的關聯時,表示「學生資料表」中的每一筆記錄,只能對應到「成績資料表」的一筆記錄,而且「成績資料表」的每一筆記錄,也只能對應到「學生資料表」的一筆記錄 ,這就是所謂的1對1關聯。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

53
【一對一的關聯圖】 在下圖中,「學生資料表」與「成績資料表」是一對一的關係。因此, 「學生資料表」的主鍵必須對應「成績資料表」的主鍵,才能設定為1:1的關聯圖。 在實務上,我們也可以將這兩個資料表合併成一個資料表,其合併結果如下圖所示。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

54
【一對一的實例】 欲將「學生資料表」與「成績資料表」的這兩個資料表合併成一個資料表時,必須要先完成以下兩個條件,否則就無法進行「合併」:
1.先檢查「學生資料表」中「學號」欄位值是否與「成績資料表」中「學號」 欄位值完全相同。 2.再建立「1:1的資料庫關聯圖」 ,下圖所示: 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

55
【SQL Server建立一對一資料庫關聯圖】
步驟一:在「ch2_hwDB」資料庫中的「資料庫圖表」上,按下「右鍵」之後,再點選「新增資料庫圖表」,如下圖所示: 按「右鍵」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法 資料庫名稱:ch2_hwDB.mdf

56
步驟二:在「加入資料表」對話方塊中,滑鼠先移到「成績表」上,按住「Ctrl」鍵,再點選「學生表」之後,再按「加入」鈕,最後再按「關閉」鈕即可。
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

57
步驟三:顯示兩個資料表準備作關聯圖,而在每一個資料表中都有一個「主鍵」 (左邊有一支黃色鑰匙),也就是具有唯一性的欄位。
例如:成績表中的「學號」與學生表中的「學號」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

58
步驟四:在上圖中,請將滑鼠移到「學生表」內的「學號」欄位上,按住滑鼠左鍵拖曳到「成績表」內的「學號」欄位上,此時便會出現一個「+」號的方塊,放掉滑鼠左鍵,此時,馬上出現一個「編輯關聯」對話方塊。
<注意>如果先從「學生表」的「學號」拖曳時,則「學生表」內的記錄可以先輸入,但是如果先從「成績表」的「學號」拖曳時,則「成績表」內的記錄先輸入。亦即先拖曳的資料表稱為「主表」而另一個資料表稱為「副表」,因為有主從關係。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法 主鍵 主鍵

59
在按「確定」鈕之後,即可建立「學生表」與「成績表」的資料庫關聯圖了。如下圖所示:
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法 一對一關係

60
步驟五:儲存資料庫關聯圖名稱。 在建立完成資料庫關聯圖之後,再按工具列上的「儲存」鈕之後,會出現「選擇名稱」的對話方塊,此時,請輸入「學生成績資料庫關聯圖」後,並按「確定」鈕,最後再按「是」即可。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

61
◎注意: 在一般的資料庫中,使用「一對一」關聯來設計是非常少人在使用。因為在二個資料表中,都必須要有一個主鍵,且第一個資料表的每一筆記錄,都必須一對一的關聯到第二個資料表的記錄。這種設計方法大大的降低資料庫的能力。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

62
一對多關聯(1:M) 【定義】 假設現在有甲與乙兩個資料表,在一對多關聯中,甲資料表中的一筆記錄,可以對應到乙資料表中的多筆記錄,但是乙資料表中的一筆記錄,卻只能對應到甲資料表中的一筆記錄。 【舉例】 以「數位學習系統」為例,當兩個資料表之間做一對多的關聯時,表示「老師資料表」中的每一筆記錄,可以對應到「課程資料表」中的多筆記錄,但「課程資料表」的每一筆記錄,只能對應到「老師資料表」中的一筆記錄,這就是所謂的一對多關聯,這種方式是最常被使用。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

63
【一對多的關聯圖】 在下圖中,「老師資料表」與「課程資料表」是一對多的關係。因此, 「老師資料表」的主鍵必須對應「課程資料表」的外來鍵,才能設定為1:M的關聯圖。 註:「*」代表該欄位為主鍵,「#」代表該欄位為外來鍵。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

64
【一對多的實例】 我們建立兩個資料表,分別為「老師資料表」與「課程資料表」,此時,我們可以了解「老師資料表」中的一筆記錄(T0001),可以對應到「課程資料表」中的多筆記錄(C001,C002,C003),但是「課程資料表」中的一筆記錄,卻只能對應到「老師資料表」中的一筆記錄。如下圖所示。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

65
【SQL Server建立一對多資料庫關聯圖】
步驟一:在「ch2_hwDB」資料庫中的「資料庫圖表」上,按下「右鍵」之後,再點選「新增資料庫圖表」,如下圖所示: 按「右鍵」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法 資料庫名稱:ch2_hwDB.mdf

66
步驟二:在「加入資料表」對話方塊中,滑鼠先移到「老師資料表」上,按住「Ctrl」鍵,再點選「課程資料表」之後,再按「加入」鈕,最後再按「關閉」鈕即可。
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

67
步驟三:顯示兩個資料表準備作關聯圖,而在每一個資料表中都有一個「主鍵」 (左邊有一支黃色鑰匙),也就是具有唯一性的欄位。
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

68
步驟四:在上圖中,請將滑鼠移到「老師資料表」中的主鍵「老師編號」欄位上,按住滑鼠左鍵拖曳到「課程資料表」中的外來鍵「老師編號」欄位上,此時便會出現一個「+」號的方塊,放掉滑鼠左鍵,此時,馬上出現一個「資料表和資料行」之編輯關聯對話方塊。 主鍵 外來鍵 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

69
在按「確定」鈕之後,即可建立「老師資料表」與「課程資料表」的資料庫關聯圖了。如下圖所示:
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法 一對多關係

70
步驟五:儲存資料庫關聯圖名稱。 在建立完成資料庫關聯圖之後,再按工具列上的「儲存」鈕之後,會出現「選擇名稱」的對話方塊,此時,請輸入「老師課程資料庫關聯圖」後,再按「確定」鈕即可。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

71
多對多關聯(M:N) 【定義】 假設現在有甲與乙兩個資料表,在多對多關聯中,甲資料表中的一筆記錄,能夠對應到乙資料表中的多筆記錄,並且乙資料表中的一筆記錄,也能夠對應到甲資料表中的多筆記錄。 【舉例】 以「選課系統」為例,當兩個資料表之間做多對多的關聯時,表示「學生資料表」中的每一筆記錄,可以對應到「課程資料表」中的多筆記錄,並且「課程資料表」中的每一筆記錄,也能夠對應到「學生資料表」中的多筆記錄,這就是所謂的多對多關聯。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

72
【多對多的關聯圖】 【兩個資料表多對多關聯之問題】
雖然,一對多關聯是最常先的一種關聯性,但是在實務上,「多對多關聯」的情況也不少,也就是說由兩個資料表(實體)呈現多對多的關聯。 例如:「學生資料表」與「課程資料表」。如下圖所示。 在上圖中表示:每一位學生可以選修多門課程,並且每一門課程也可以被多位 學生來選修。 【兩個資料表多對多關聯之問題】 在實務上多對多關聯如果只有兩個資料表來建置,難度較高,並且容易出問題。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
呈現多對多的關聯。 例如:「學生資料表」與「課程資料表」。如下圖所示。 在上圖中表示:每一位學生可以選修多門課程,並且每一門課程也可以被多位. 學生來選修。 【兩個資料表多對多關聯之問題】 在實務上多對多關聯如果只有兩個資料表來建置,難度較高,並且容易出問題。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
73
【解決方法】 利用「三個資料表」來建置「多對多關聯」,也就是說,在原來的兩個資料表之間再加入一個「聯合資料表(Junction Table)」,使他們可以順利處理多對多的關聯。其中,聯合資料表(Junction Table)中的主索引鍵(複合主鍵)是由資料表A(學生資料表)和資料表B(課程資料表)兩者的主鍵所組成。 例如:在「學生資料表」與「課程資料表」之間再加入第三個資料表 「選課資料表」,如下圖所示。 聯合資料表 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
」,使他們可以順利處理多對多的關聯。其中,聯合資料表(Junction Table)中的主索引鍵(複合主鍵)是由資料表A(學生資料表)和資料表B(課程資料表)兩者的主鍵所組成。 例如:在「學生資料表」與「課程資料表」之間再加入第三個資料表. 「選課資料表」,如下圖所示。 聯合資料表. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
74
1. 在「學生資料表」與「選課資料表」的關係是以一對多。 2. 在「課程資料表」與「選課資料表」的關係是以一對多。
聯合資料表 說明: 1. 在「學生資料表」與「選課資料表」的關係是以一對多。 2. 在「課程資料表」與「選課資料表」的關係是以一對多。 3. 藉由「選課資料表」的使用,使「學生資料表」與「課程資料表」 關係變成多對多的關聯式,亦即每一位學生可以選修一門以上的課程 並且每一門課程也可以被多位同學的選修。 4.以資料表(Table)之方式組成關聯,將這些關聯組合起來,即形成一個 關聯式資料庫。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
之方式組成關聯,將這些關聯組合起來,即形成一個. 關聯式資料庫。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
75
【多對多的實例】 我們建立三個資料表,分別為「學生資料表」、「選課資料表」及「課程資料表」 ,此時,我們可以了解「學生資料表」中的一筆記錄(S0001),可以對應到「選課資料表」中的多筆記錄(#1,#4,#5;亦即選了C001,C002,C003三門課程),並且「課程資料表」中的一筆記錄(C002),也能夠對應到「選課資料表」中的多筆記錄(#3,#4;亦即每一門課程可以被S0001,SC003兩位同學來選) 。如下圖所示。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
,可以對應到「選課資料表」中的多筆記錄(#1,#4,#5;亦即選了C001,C002,C003三門課程),並且「課程資料表」中的一筆記錄(C002),也能夠對應到「選課資料表」中的多筆記錄(#3,#4;亦即每一門課程可以被S0001,SC003兩位同學來選) 。如下圖所示。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
76
2-4 資料庫之完整性規則 完整性規則(Integrity Rules)是用來確保資料的一致性與完整性,以避免資料在經過新增、修改及刪除等運算之後,而產生的異常現象。亦即避免使用者將錯誤或不合法的資料值存入資料庫中。如下圖所示: 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

77
【三種完整性規則】 關聯式資料模式的「完整性規則」,有下列三種:如下圖所示。
1.實體完整性規則(Entity Integrity Rule) 2.參考完整性規則(Referential Integrity Rule) 3.值域完整性規則(Domain Integrity Rule) 學生資料表(子關聯) 科系代碼表(父關聯) 註:在關聯式資料庫中,任兩個資料表要進行關聯(參考)時,必須透過「主鍵」對應 「外來鍵」才能建立,其中「主鍵」值的所在資料表稱為「父關聯」,而「外來 鍵」值的所在資料表稱為「子關聯」。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
 2.參考完整性規則(Referential Integrity Rule) 3.值域完整性規則(Domain Integrity Rule) 學生資料表(子關聯) 科系代碼表(父關聯) 註:在關聯式資料庫中,任兩個資料表要進行關聯(參考)時,必須透過「主鍵」對應. 「外來鍵」才能建立,其中「主鍵」值的所在資料表稱為「父關聯」,而「外來. 鍵」值的所在資料表稱為「子關聯」。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
78
綜合上述,為了確保資料的完整性、一致性及正確性,基本上,使用者在異動(即新增、修改及刪除)資料時,都會先檢查使用者的「異動操作」是否符合資料庫管理師(DBA)所設定的限制條件,如果違反限制條件時,則無法進行異動(亦即異動失敗),否則,就可以對資料庫中的資料表進行各種異動處理。如下圖所示: 在上圖中,所謂的「限制條件」是指資料庫管理師(DBA)在定義資料庫的資料表結構時,可以設定主鍵(Primary Key)、外鍵(Foreign Key)、唯一鍵(Unique Key)、條件約束檢查(Check)及不能空值(Not Null)等五種不同的限制條件。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
在定義資料庫的資料表結構時,可以設定主鍵(Primary Key)、外鍵(Foreign Key)、唯一鍵(Unique Key)、條件約束檢查(Check)及不能空值(Not Null)等五種不同的限制條件。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
79
【完整性的綜合分析】 我們已經學會一對一、一對多及多對多的資料庫關聯圖了,但是,你是否有注意到,當我們拖曳「外鍵」來參考「主鍵」時,除了自動彈出一個「資料表和資料行」之編輯關聯對話方塊之外,並且在按下「確定」鈕之後,也會隨即自動再彈出「外部索引鍵關聯性」的對話方塊,如下圖所示: 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法 主鍵 外來鍵

80
【完整性的綜合分析】<續> 在下圖中的「外部索引鍵關聯性」的對話方塊,主要是用來檢查「參考完整性規則」,也就是在兩個資料表中,次要資料表的外鍵(FK)的資料欄位值,一定要存在於主要資料表的主鍵(PK)中的資料欄位值,否則,會出現錯誤訊息。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

81
【參考完整性】 以下圖的「學生資料表」與「科系代碼表」為例: 「科系代碼表」內的「系碼」欄位為主鍵,而「學生資料表」內的「系碼」為外來鍵。
因此,「參考完整性」有勾選時,則DBMS會限制使用者輸入資料是否有違反參考完整性。 何謂「參考完整性」?是指用來確保相關資料表間的資料一致性,避免因一個資料表的記錄改變時,造成另一個資料表的內容變成無效的值。 如下圖所示。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

82
2-4.1 實體完整性規則…針對主鍵 【定義】 每一個關聯表中的值組都必須是可以識別的,因此,主鍵必須要具有唯一性,並且主鍵不可重複或為空值(NULL)。否則,就無法唯一識別某一記錄(值組)。 【特性】 1.實體必須是可區別的(Distinguishable)。 2.主鍵值未知代表是一個不確定的實體,不能存放在資料關聯中。 如下圖所示: 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
。 2.主鍵值未知代表是一個不確定的實體,不能存放在資料關聯中。 如下圖所示: 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
83
3.實體完整性規則只適用於基本關聯(Base Relation),不考慮視界 (View)。 (1)基本關聯(Base Relation)
真正存放資料的具名關聯,是透過SQL的Create Table敘述來建立。 基本關聯對應於ANSI/SPARC的「概念層」。 (2)視界(View) 是一種具名的衍生關聯、虛擬關聯,定義在某些基本關聯上,本身不含任 何資料。視界相對應於ANSI/SPARC的「外部層」。 4.在建立資料表時可以設定某欄位為主鍵,以確保實體完整性和唯一性。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
視界(View) 是一種具名的衍生關聯、虛擬關聯,定義在某些基本關聯上,本身不含任. 何資料。視界相對應於ANSI/SPARC的「外部層」。 4.在建立資料表時可以設定某欄位為主鍵,以確保實體完整性和唯一性。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
84
5.複合主鍵(學號與課號)中的任何屬性值皆不可以是空值(Null)。 如下圖所示:
說明:主鍵是由多個欄位連結而成的組合鍵,因此,每一個欄位值都 不可為空值(Null)。 <實作>在下一頁 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
。 <實作>在下一頁. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
85
【SQL Server 上機實作】 步驟一:將「選課資料表」中的「學號」與「課號」設定為複合主鍵。 如下圖所示:
資料庫名稱: ch2_DB.mdf 步驟一:將「選課資料表」中的「學號」與「課號」設定為複合主鍵。 如下圖所示: 步驟二:學號S0004同學尚未選課,故無法新增到「選課資料表」中。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

86
2-4.2 參考完整性規則…針對外鍵 在完成建立資料庫及資料表之後,如果沒有把它們整合起來,則「學生資料表」中的外鍵(系碼)就無法與「科系代碼表」的主鍵(系碼)之間來進行關聯了,這將會導致資料庫不一致的問題。也就是違反了資料庫之「參考完整性規則」。 【定義】 是指用來確保兩個資料表之間的資料一致性,避免因一個資料表的記錄改變時,造成另一個資料表的內容變成無效的值。因此,子關聯的外來鍵(FK)的資料欄位值,一定要存在於父關聯的主鍵(PK)中的資料欄位值。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
的資料欄位值,一定要存在於父關聯的主鍵(PK)中的資料欄位值。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
87
學生資料表(子關聯) 的系碼(外鍵;F.K.) 一定要存在於系別代碼表(父關聯)的系碼(主鍵;P.K.)中。 如下圖所示:
【例如】 學生資料表(子關聯) 的系碼(外鍵;F.K.) 一定要存在於系別代碼表(父關聯)的系碼(主鍵;P.K.)中。 如下圖所示: 存在於 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法 學生資料表(子關聯) 系別代碼表(父關聯)
 的系碼(外鍵;F.K.) 一定要存在於系別代碼表(父關聯)的系碼(主鍵;P.K.)中。 如下圖所示: 存在於. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法. 學生資料表(子關聯) 系別代碼表(父關聯)")
88
【例如】 「強制使用外部索引鍵條件約束」使用預設值為「是」的情況
假設現有二個資料表,分別為「學生資料表」與「科系代碼表」,其中有一位「五福」同學欲從資工系(D001)轉為資管系(D002),並且,在轉系的過程中,學校的校務行政系統中的「學生資料表」與「系別資料表」之間有建立「強制使用外部索引鍵條件約束」,如下圖所示: 因此,行政人員假設在填入「系碼」欄位,誤填為「D003」時,DBMS就無法檢查出來,此時,將會使得系碼「D003」內容變成無效的值,以致於產生資料不一致現象。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
轉為資管系(D002),並且,在轉系的過程中,學校的校務行政系統中的「學生資料表」與「系別資料表」之間有建立「強制使用外部索引鍵條件約束」,如下圖所示: 因此,行政人員假設在填入「系碼」欄位,誤填為「D003」時,DBMS就無法檢查出來,此時,將會使得系碼「D003」內容變成無效的值,以致於產生資料不一致現象。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
89
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

90
【例如】 「強制使用外部索引鍵條件約束」設定為「否」的情況
假設現有二個資料表,分別為「學生資料表」與「科系代碼表」,其中有一位「五福」同學欲從資工系(D001)轉為資管系(D002),但是,在轉系的過程中,學校的校務行政系統中的「學生資料表」與「科系代碼表」之間尚未建立「強制使用外部索引鍵條件約束」,如下圖所示: 因此,行政人員假設在填入「系碼」欄位, 誤填為「D003」時,DBMS就可以檢查出 來,此時,系碼「D003」就無法修改,因此 ,不會產生資料不一致現象。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
轉為資管系(D002),但是,在轉系的過程中,學校的校務行政系統中的「學生資料表」與「科系代碼表」之間尚未建立「強制使用外部索引鍵條件約束」,如下圖所示: 因此,行政人員假設在填入「系碼」欄位, 誤填為「D003」時,DBMS就可以檢查出. 來,此時,系碼「D003」就無法修改,因此. ,不會產生資料不一致現象。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
91
1.至少要有兩個或兩個以上的資料表才能執行「參考完整性規則」。
【參考完整性規則的特性】 1.至少要有兩個或兩個以上的資料表才能執行「參考完整性規則」。 2.由父關聯表的「主鍵」與子關聯表的「外來鍵」的關係來建立兩資料表間資 料的關聯性。 3.建立「參考完整性」之後,就可以即時有效檢查使用者的輸入值, 以避免無效的值發生。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

92
【SQL Server 上機實作】 步驟一:建立「學生資料表」與「科系代碼表」 步驟二:建立資料庫關聯圖 圖:
接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

93
步驟三:將「學生資料表」中的五福同學的系碼改為「D003」, 如下所示:
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

94
2-4.3 值域完整性規則 【定義】 是指在「單一資料表」中,對於所有屬性(Attributes)的內含值,必須來自值域(Domain)的合法值群中。亦即是指在「單一資料表」中,同一資料行中的資料屬性必須要相同。亦即同一行的欄位之資料類型要相同。 【例如】 「性別」屬性的內含值,必須是「男生」或「女生」,而不能超出定義域(Domain)的合法值群。 【特性】 1.作用在「單一資料表」中 2. 「同一資料行」中的「資料屬性」必須要「相同」 3.建立資料表可以「設定條件」來查檢值域是否為合法值群 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
的合法值群。 【特性】 1.作用在「單一資料表」中. 2. 「同一資料行」中的「資料屬性」必須要「相同」 3.建立資料表可以「設定條件」來查檢值域是否為合法值群. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
95
【實例】 【例1】學生資料表中的系碼僅能存放文字型態的資料,並且一定只 有四個字元,不可以超過四個字元或其他的日期格式等型態。
【例2】學生成績資料表中的成績資料行僅能存放數值型態的資料, 不可以有文字或日期等格式。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

96
當要新增學生的成績時,其成績的屬性內含值,必須要來自定義域,其範圍為0~100分,如果成績超出範圍,則無法新增。
【例3】 當要新增學生的成績時,其成績的屬性內含值,必須要來自定義域,其範圍為0~100分,如果成績超出範圍,則無法新增。 如下圖所示。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

97
【SQL Server 上機實作1】 步驟一:選擇欲修改的欄位名稱「成績」欄位 圖:
接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

98
【SQL Server 上機實作1】<續>
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

99
【 SQL Server 上機實作1】<續>
步驟二:填入「條件約束之運算式」及「描述」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

100
【SQL Server 上機實作2】 檢查「性別」欄位 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」
當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

101
{constant column_name function (subquery)} [{operator AND OR NOT} {constant column_name function (subquery)}]
![{constant column_name function (subquery)} [{operator AND OR NOT} {constant column_name function (subquery)}]](http://slidesplayer.com/slide/11613059/62/images/101/%7Bconstant+column_name+function+%28subquery%29%7D+%5B%7Boperator+AND+OR+NOT%7D+%7Bconstant+column_name+function+%28subquery%29%7D%5D.jpg "{constant column_name function (subquery)} [{operator AND OR NOT} {constant column_name function (subquery)}]")
102
【 SQL Server 上機實作3】 檢查「性別」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」
當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

103
2-4.4 空值(NULL Values) 【定義】 1.空值是一種特殊記號,用以記錄目前不詳的資料值。
2.空值不是指「空白格」或「零值」。 3.空值可分為以下三種: (1)可應用的空值(Application Null Value):一般指目前不知道的值, 但此值確實存在。 例如:張三已婚,但其配偶欄的姓名尚未填入。 (2)不可應用的空值(Inapplicable Null Value):目前完全沒有存在這 個值。 例如:張三未婚,其配偶欄的值為空值。 (3)完全未知的空值(Totally Unknown):完全不知道這個值是否存在。 例如:陌生人張三<不知已婚或未婚>,其配偶欄的值。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
可應用的空值(Application Null Value):一般指目前不知道的值, 但此值確實存在。 例如:張三已婚,但其配偶欄的姓名尚未填入。 (2)不可應用的空值(Inapplicable Null Value):目前完全沒有存在這. 個值。 例如:張三未婚,其配偶欄的值為空值。 (3)完全未知的空值(Totally Unknown):完全不知道這個值是否存在。 例如:陌生人張三<不知已婚或未婚>,其配偶欄的值。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
104
2-4.5 非空值(NOT NULL) 【定義】資料行必須有正確的資料值,不可為虛值。 【例如】
在「學生資料表」中的「學號」和「姓名」兩欄位值必須確定, 不可為虛值。因此,在建立資料表時就必須宣告為NOT NULL 。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

105
2-4.6 外鍵使用法則 在「關聯式資料庫」中,若進行刪除(Delete)或更新(Update)運算時,發現違反『參考完整性規則』,則常見有以下四種策略: 1.刪除(Delete)運算時的四種方式 (1)沒有動作(No Action),又稱為限制作法(Restricted) <預設作法> (2)重疊顯示:又稱為連帶作法(Cascades) :表示自動刪除 (3)設定Null:又稱為空值化(Set Null) (4)設定為預設值: 2.更新(Update)運算的四種方法 (2)重疊顯示:又稱為連帶作法(Cascades) :表示自動更改 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
沒有動作(No Action),又稱為限制作法(Restricted) <預設作法> (2)重疊顯示:又稱為連帶作法(Cascades) :表示自動刪除. (3)設定Null:又稱為空值化(Set Null) (4)設定為預設值: 2.更新(Update)運算的四種方法. (2)重疊顯示:又稱為連帶作法(Cascades) :表示自動更改. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
106
一、刪除(Delete)運算: 1. 沒有動作(No Action) :又稱為限制作法(Restricted)
【定義】在刪除「父關聯表」的一個記錄時,如果該記錄的主鍵,沒有被「子關聯表」的外鍵參考時,則允許被刪除,反之,則不允許。亦即被參考的記錄是拒絕被刪除。 【例如】 當刪除「科系代碼表」的第三筆記錄(D003,軟工系,葉主任),是可以的(∵沒有被參考到),但是欲刪除第一、二筆時,不允許(∵有被參考到)。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
,是可以的(∵沒有被參考到),但是欲刪除第一、二筆時,不允許(∵有被參考到)。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
107
在建立資料庫關聯圖時,必須要同時勾選以下的選項,才會具有此功能。
【實作】 在建立資料庫關聯圖時,必須要同時勾選以下的選項,才會具有此功能。 注意:此種規則為預設作法,亦即「被參考的記錄是拒絕被刪除」! 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

108
【定義】在刪除「父關聯表」的一個記錄時,也會同時刪除「子關聯
2.重疊顯示:又稱為連帶作法(Cascades) 【定義】在刪除「父關聯表」的一個記錄時,也會同時刪除「子關聯 表」 中擁有相同外鍵值記錄。 【例如】 在前例中,欲刪除「科系代碼表」中的第一筆記錄(D001,資工系, 李春雄),也必須同時刪除「學生資料表」中的第1,2,5筆記錄。 子關聯表 父關聯表 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
 【定義】在刪除「父關聯表」的一個記錄時,也會同時刪除「子關聯. 表」 中擁有相同外鍵值記錄。 【例如】 在前例中,欲刪除「科系代碼表」中的第一筆記錄(D001,資工系, 李春雄),也必須同時刪除「學生資料表」中的第1,2,5筆記錄。 子關聯表. 父關聯表. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
109
在建立資料庫關聯圖時,必須選取「重疊顯示」。如下圖所示:
【作法】 在建立資料庫關聯圖時,必須選取「重疊顯示」。如下圖所示: 注意:您如果沒有「選取」時,則是「沒有動作」! 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

110
在下表中,欲刪除「科系代碼表」中的第二筆記錄(D002,資 管系,李碩安),也必須同時刪除「學生資料表」中的第3筆與 第4筆記錄。
【例如】 在下表中,欲刪除「科系代碼表」中的第二筆記錄(D002,資 管系,李碩安),也必須同時刪除「學生資料表」中的第3筆與 第4筆記錄。 子關聯表 父關聯表 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
,也必須同時刪除「學生資料表」中的第3筆與. 第4筆記錄。 子關聯表. 父關聯表. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
111
步驟一:建立「學生資料表」與「科系代碼表」
【利用SQL Server 實作】 步驟一:建立「學生資料表」與「科系代碼表」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

112
步驟二:建立資料庫關聯圖表 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」
當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

113
刪除「科系代碼表」中的第二筆記錄(D002,資管系,李碩安),並檢查「學生資料表」中的第3,4,5筆記錄一併同時被刪除。
步驟三: 刪除「科系代碼表」中的第二筆記錄(D002,資管系,李碩安),並檢查「學生資料表」中的第3,4,5筆記錄一併同時被刪除。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
,並檢查「學生資料表」中的第3,4,5筆記錄一併同時被刪除。 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
114
【定義】在刪除「父關聯」的一個記錄時,也會同時將「子關聯」 中擁有相同外鍵予以空值化。
3.空值化(Set Null) 【定義】在刪除「父關聯」的一個記錄時,也會同時將「子關聯」 中擁有相同外鍵予以空值化。 【例如】 在前例中,欲刪除「科系代碼表」中的第二筆記錄(D002,資管系,李碩安),也必須同時將「學生資料表」中系碼屬性有”D002”的第三與第四筆值空值化。 子關聯 父關聯 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
 【定義】在刪除「父關聯」的一個記錄時,也會同時將「子關聯」 中擁有相同外鍵予以空值化。 【例如】 在前例中,欲刪除「科系代碼表」中的第二筆記錄(D002,資管系,李碩安),也必須同時將「學生資料表」中系碼屬性有 D002 的第三與第四筆值空值化。 子關聯. 父關聯. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
115
【作法】在建立資料庫關聯圖時,必須選取「設定Null」。如下圖所示:
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

116
步驟一:建立「學生資料表」與「科系代碼表」
【利用SQL Server 實作】 步驟一:建立「學生資料表」與「科系代碼表」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

117
步驟二:建立資料庫關聯圖 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」
當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

118
刪除「科系代碼表」中的第二筆記錄(D002,資管系,李碩安),並檢查「學生資料表」中的第3,4,5筆記錄同時被設定為「空值化」
步驟三: 刪除「科系代碼表」中的第二筆記錄(D002,資管系,李碩安),並檢查「學生資料表」中的第3,4,5筆記錄同時被設定為「空值化」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
,並檢查「學生資料表」中的第3,4,5筆記錄同時被設定為「空值化」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
119
【定義】在刪除「父關聯表」的一個記錄時,也會同時將「子關聯表」 中擁有相同外鍵設定為預設值。
4.設定為預設值 【定義】在刪除「父關聯表」的一個記錄時,也會同時將「子關聯表」 中擁有相同外鍵設定為預設值。 【例如】 在前例中,欲刪除「科系代碼表」中的第二筆記錄(D002,資管系,李碩安),也必須同時將「學生資料表」中系碼屬性有”D002”的第三與第四筆值設定為預設值。 子關聯表 父關聯表 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
,也必須同時將「學生資料表」中系碼屬性有 D002 的第三與第四筆值設定為預設值。 子關聯表. 父關聯表. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
120
【作法】在建立資料庫關聯圖時,必須選取「預設值或繫結」。如下圖所示:
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

121
步驟一:建立「學生資料表」與「科系代碼表」
【利用SQL Server實作】 步驟一:建立「學生資料表」與「科系代碼表」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

122
步驟二:建立資料庫關聯圖,必須選取「設為預設值」。如下圖所示:
圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

123
刪除「科系代碼表」中的第二筆記錄(D002,資管系,李碩安),並檢查「學生資料表」中的第3,4,5筆記錄同時被設定為「Null」
步驟三: 刪除「科系代碼表」中的第二筆記錄(D002,資管系,李碩安),並檢查「學生資料表」中的第3,4,5筆記錄同時被設定為「Null」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
,並檢查「學生資料表」中的第3,4,5筆記錄同時被設定為「Null」 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
124
二、更新(Update)運算: 1.沒有動作(No Action):又稱為限制作法(Restricted)
【定義】在更新「父關聯表」的一個記錄時,如果該記錄的主鍵,沒有被「子關聯表」的外鍵參考時,則允許被更新,反之,則不允許。亦即被參考的記錄是拒絕被更新。 ◎說明:當更新「科系代碼表」中的D001為A001時,不允許;當更新 「系別資料表」中D003為A003時,允許。 子關聯表 父關聯表 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

125
注意:此種規則為預設作法,亦即「被參考的記錄是拒絕被更新」!
【實作】 注意:此種規則為預設作法,亦即「被參考的記錄是拒絕被更新」! 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

126
【定義】在更新「父關聯表」的一個記錄時,也會同時更新「子關聯表」 中擁有相同外鍵值記錄。
2.重疊顯示:又稱為連帶作法(Cascades) 【定義】在更新「父關聯表」的一個記錄時,也會同時更新「子關聯表」 中擁有相同外鍵值記錄。 【例如】 在前例中,欲更新「科系代碼表」中的「D001」為「A001」,也必須同時將「學生資料表」中的第1,2,5三筆記錄的「D001」修改為「A001」。 子關聯表 父關聯表 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
 【定義】在更新「父關聯表」的一個記錄時,也會同時更新「子關聯表」 中擁有相同外鍵值記錄。 【例如】 在前例中,欲更新「科系代碼表」中的「D001」為「A001」,也必須同時將「學生資料表」中的第1,2,5三筆記錄的「D001」修改為「A001」。 子關聯表. 父關聯表. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
127
在建立資料庫關聯圖時,必須選取「重疊顯示」。如下圖所示:
【作法】 在建立資料庫關聯圖時,必須選取「重疊顯示」。如下圖所示: 注意:您如果沒有「選取」時,則是「沒有動作」! 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法

128
【定義】在更新「父關聯表」的一個記錄時,也會同時將「子關聯表」 中擁有相同外鍵予以空值化。
3.空值化(Set Null) 【定義】在更新「父關聯表」的一個記錄時,也會同時將「子關聯表」 中擁有相同外鍵予以空值化。 【例如】 在前例中,欲更新「科系代碼表」中的第二筆記錄(D002)為「A002」時,也必須同時將「學生資料表」中的第三與第四筆記錄的「D002」修改為空值(Null)。 子關聯 父關聯 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
 【定義】在更新「父關聯表」的一個記錄時,也會同時將「子關聯表」 中擁有相同外鍵予以空值化。 【例如】 在前例中,欲更新「科系代碼表」中的第二筆記錄(D002)為「A002」時,也必須同時將「學生資料表」中的第三與第四筆記錄的「D002」修改為空值(Null)。 子關聯. 父關聯. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
129
【定義】在更新「父關聯表」的一個記錄時,也會同時將「子關聯表」 中擁有相同外鍵予以空值化。
4.設定為預設值 【定義】在更新「父關聯表」的一個記錄時,也會同時將「子關聯表」 中擁有相同外鍵予以空值化。 【例如】 在前例中,欲更新「科系代碼表」中的第二筆記錄(D002)為「A002」時,也必須同時將「學生資料表」中的第三與第四筆記錄的「D002」修改為空值(Null)。 子關聯 父關聯 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法
為「A002」時,也必須同時將「學生資料表」中的第三與第四筆記錄的「D002」修改為空值(Null)。 子關聯. 父關聯. 圖: 接下來,我們可以從圖1-1來說明「資料與資訊的關係」 當我們「輸入原始成績」之後,如何輸出一張成績單呢?那就必須要透過「程式」來進行處理, 而在資料結構中,程式=資料結構+演算法.")
Similar presentations




 課程名稱:數位學習 授課老師:李春雄 博士>")




 課程名稱:系統分析與設計 各位同學大家好,我是李春雄老師,本學期所開設的課程名稱為「資料結構」,>")









