Download presentation
Presentation is loading. Please wait.

1
主讲:李晓军 E-mail:lixj111@tom.com
统计学实践 主讲:李晓军

2
第1章 数据分析概述与软件入门 1.1 SPSS软件概述 1.1.1 SPSS简介
SPSS(Statistics Package for Social Science )for Windows是一种运行在Windows系统下的社会科学统计软件软件包。 SPSS的基本功能包括数据管理、统计分析、图表分析、输出管理等,具体内容包括描述统计、列联分析,总体的均值比较、相关分析、回归模型分析、聚类分析、主成份分析、时间序列分析、非参数检验等多个大类,每个类中还有多个专项统计方法。
for Windows是一种运行在Windows系统下的社会科学统计软件软件包。 SPSS的基本功能包括数据管理、统计分析、图表分析、输出管理等,具体内容包括描述统计、列联分析,总体的均值比较、相关分析、回归模型分析、聚类分析、主成份分析、时间序列分析、非参数检验等多个大类,每个类中还有多个专项统计方法。")
3
一、功能强大 (1)囊括了各种成熟的统计方法与模型,为统计分析用户提供了全方位的统计学算法,为各种研究提供了相应的统计学方法。
(2)提供了各种数据准备与数据整理技术。 (3)自由灵活的表格功能。 (4)各种常用的统计学图形。
提供了各种数据准备与数据整理技术。 (3)自由灵活的表格功能。 (4)各种常用的统计学图形。")
4
二、SPSS的实验环境要求 三、SPSS的主要界面 四、SPSS的帮助系统
(1)系统运行环境 SPSS10.0以上版本软件包可以工作在两种模式下,单机模式和作为网络系统的用户界面模式。 (2)辅助软件环境 三、SPSS的主要界面 SPSS的主要界面有数据编辑窗口和结果输出窗口。 四、SPSS的帮助系统 SPSS对一些基本模块中的统计提供了帮助,可以通过单击Help菜单中的Statistics Coach命令,选择所需要的统计指导。
系统运行环境. SPSS10.0以上版本软件包可以工作在两种模式下,单机模式和作为网络系统的用户界面模式。 (2)辅助软件环境. 三、SPSS的主要界面. SPSS的主要界面有数据编辑窗口和结果输出窗口。 四、SPSS的帮助系统. SPSS对一些基本模块中的统计提供了帮助,可以通过单击Help菜单中的Statistics Coach命令,选择所需要的统计指导。")
5
SPSS附加模块 功能 SPSS Advanced 一般线性模型、混合线性模型、对数线性模型、生存分析等 SPSS Categories 对应分析、感知图、Proxscal等 SPSS Complex Sample 多阶段复杂抽样技术等 SPSS Conjoint 正交设计、联合分析等,适用于市场研究 SPSS Exact Test 精确P值计算、随机抽样P值计算等 SPSS Maps 在地图上展示数据等 SPSS Missing Value Analysis 缺失数据的报告与填补等 SPSS Regression Logistic回归、非线性回归、Probit回归等 SPSS Tables 交互式创建各种表格(如堆积表、嵌套表、分层表等) SPSS Trends Arima模型、指数平滑、自回归等
 SPSS Trends. Arima模型、指数平滑、自回归等.")
6
五、SPSS的运行方式 SPSS提供了3种基本运行方式:完全窗口菜单方式,程序运行方式、混合运行方式。程序运行方式和混合运行方式是使用者从特殊的分析需要出发,编写自己的SPSS命令程序,通过语句直接运行。 SPSS中使用的对话框主要有两类,一类是文件操作对话框,文件操作对话窗口操作与Windows应用软件操作风格一致。另一类是统计分析对话框,统计分析对话框可以分为主窗口和下级窗口,在该类对话框中,选择参与分析的各类变量及统计方法是对话框的主要任务。

7
spss的安装 一、启动Windows 后,把SPSS 系统安装软盘(或光盘)插入软驱(或光驱),并找到SPSS的安装程序的可执行文件Setup.exe。 二、双击 Setup.exe 文件,安装程序向导将给出每一步操作的提示。在出现[Welcome(欢迎)]窗口后,选择[Next]进入下一步。 三、安装程序显示[Software License Agreement]对话框时,选择[Yes]接受显示的协议条款。
]窗口后,选择[Next]进入下一步。 三、安装程序显示[Software License Agreement]对话框时,选择[Yes]接受显示的协议条款。")
8
1.2 spss操作入门 1.2.1 spss软件的启动与退出
单击Windows 的[开始]按钮,在[程序]菜单项[SPSS for Windows]中找到[SPSS 10.0 for Windows]并单击。

9
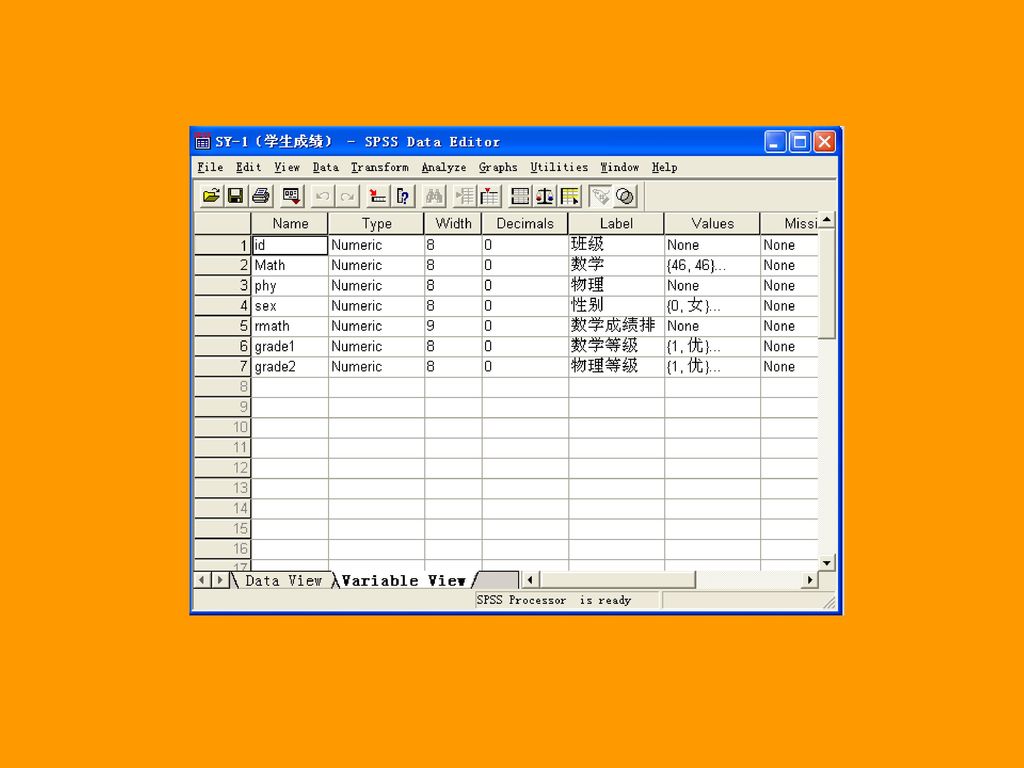
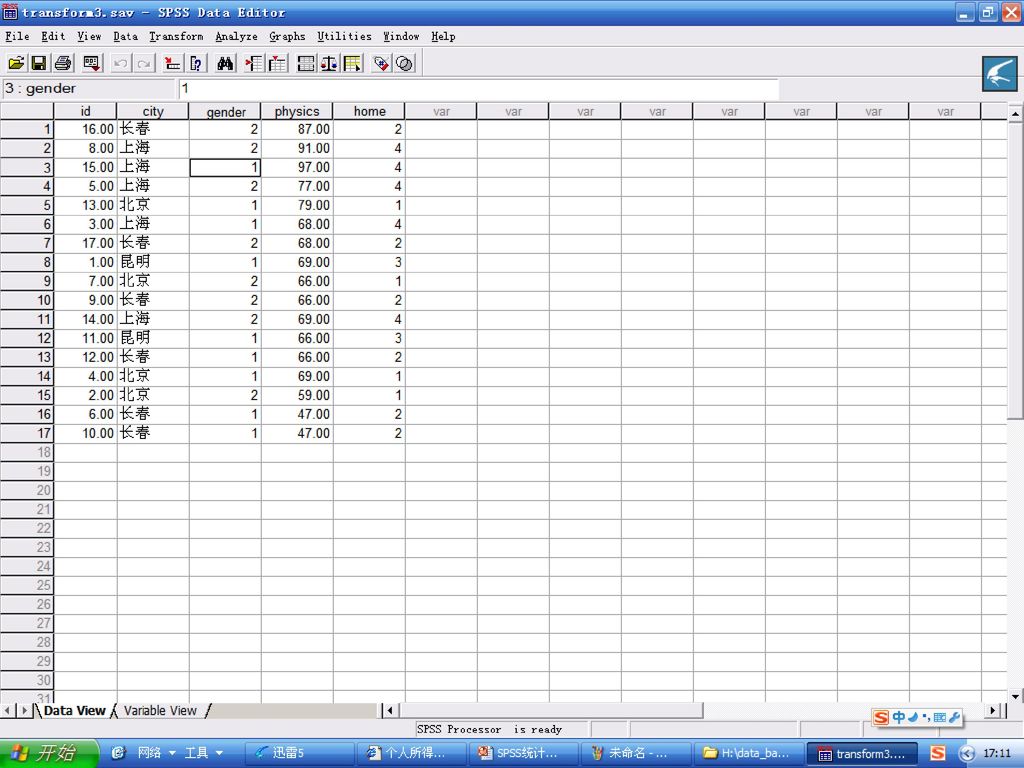
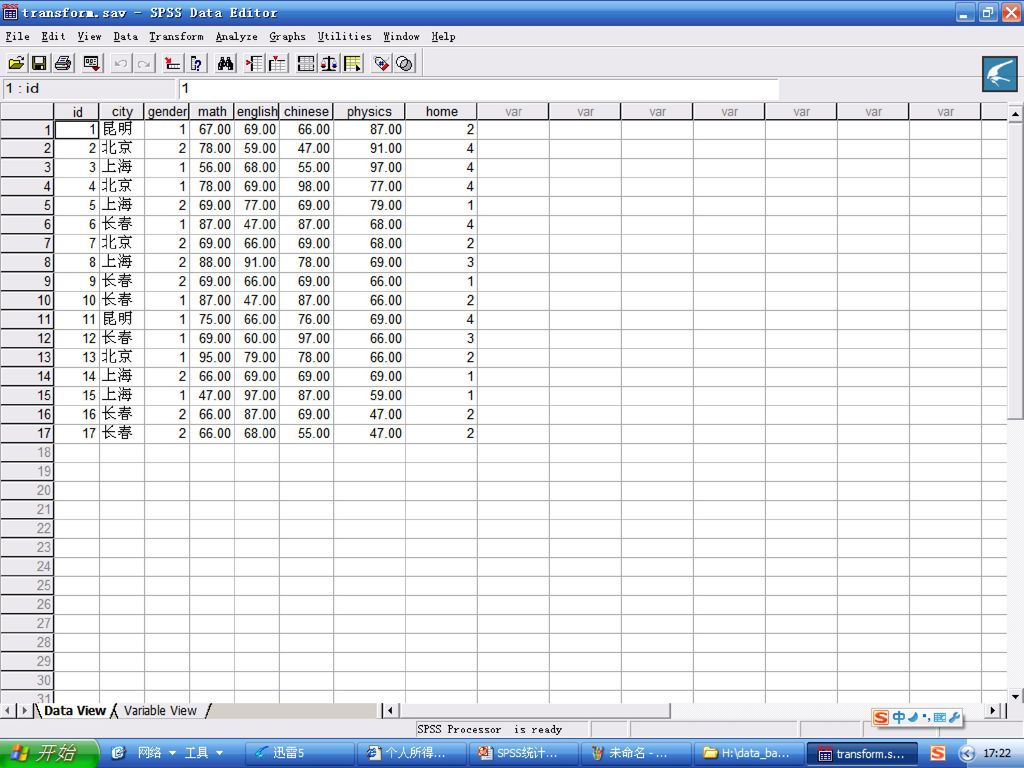
1.2.2 SPSS的5个窗口 (1)数据编辑窗口(SPSS Data Editor) Spss处理数据的工作全在此窗口进行。
数据编辑窗口(SPSS Data Editor) Spss处理数据的工作全在此窗口进行。")
11
(2)结果管理窗口(SPSS Output viewer)
此窗口用于存放分析结果。左边是目录区,右边是内容区。

12
(3)草稿结果窗口(SPSS Draft Viewer)
草稿结果是结果的一种简化文本格式。实际上就是WORD所兼容的rtf超文本格式,因此可以在没有安装SPSS的PC机上使用文字编辑软件打开。

13
(4)语法编辑窗口(SPSS Syntax Editor)
语法编辑窗口(SPSS Syntax Editor)")
14
(5)脚本窗口(SPSS Script Editor)
脚本窗口(SPSS Script Editor)")
15
1.2.3 SPSS的四种运行方式 一、菜单对话方式 首先打开SPSS软件,然后选择菜单File Open file。
然后,利用菜单Analyze Descriptive Statistics Frequencies,

17
二、程序方式 在Syntax编辑窗口中键入以下程序:
Get file=‘c:\program files\spss\employee data.sav’. Frequencies variables = jobcat/order = analysis。 只需要选择菜单Run All,运行该程序也一样会出现相同的分析结果。

18
三、Include命令方式 当编写Syntax程序时,如果发现将要编写的程序语句正好是另一个Syntax文件的内容;或者发现所需要的程序语句其实是几个Syntax文件的总和是,除了可以通过“Copy”、“Paste”的方法利用资源,生产一个新的Syntax文件外,还可以利用Include命令。 Include ‘c:\sytaxsample.sps’.

19
四、spss Production Faccility 方式
在Windows的程序菜单中,spss菜单组除了有“spss for windows”项之外,还有一个“spss production facility”。

20
(1)单击Syntax框下的“Add”按钮,到C盘根目录下打开“syntaxsample”。
(2)单击Syntax框下的“Edit”按钮,对程序进行编辑。 (3)单击右下角的“uesr prompts”按钮,添加对程序的交互分析界面。 (4)单击“Browse”按钮制定结果保存路径,单击“export options”按钮还可以制定结果保存格式。
单击Syntax框下的 Edit 按钮,对程序进行编辑。 (3)单击右下角的 uesr prompts 按钮,添加对程序的交互分析界面。 (4)单击 Browse 按钮制定结果保存路径,单击 export options 按钮还可以制定结果保存格式。")
21
1.2.4 spss的四种输出结果 1、表格格式 2、文本格式 3、标准图与交互图 4、结果的保存和导出

23
第2章 数据录入与数据获取 本章主要解决两个问题: 第一个问题,根据问题类型的不同,将会从开放题、单选题和多选题的录入方式为例进行介绍。
第2章 数据录入与数据获取 本章主要解决两个问题: 第一个问题,根据问题类型的不同,将会从开放题、单选题和多选题的录入方式为例进行介绍。 第二个问题,重点介绍如何用SPSS直接读取Excel类型和文本格式的数据,以及如何用ODBC接口读取数据库文件。

24
2.1 数据格式概述 2.1.1 统计软件中数据的录入格式 (1)不同观测对象的数据不能在同一记录中出现,即同一观测数据应当独占一行。 (2)每一个观测量指标或影响因素只能占据一列的位置,即同一指标的数量观测值都应当录入到同一个变量中去。 即:一个观测占一行,一个变量占一列

25
2.1.2 变量属性介绍 在录入数据时,归纳为以下三步: 第一步:定义变量名; 第一步:指定每个变量的各种属性; 第一步:录入数据。 变量名不能与spss保留字相同,spss的保留字有ALL、END、BY、EQ、GE、GT、LE、LT、NE、NOT、OR、TO、WITH。

26
一、变量的储存类型 SPSS中,变量有三种的基本类型:数值型、字符型和日期型。
数值型:数值型的数据是0-9的阿拉伯数字和其他符号,如美元符号、逗号或圆点组成的。 标准 数值型 逗号 数值型 圆点 数值型 科学技术法 数值型 美元 数值型 用户自 定义型

27
注意:在输入数据时不应输入引号,否则双引号将会作为字符型数据的一部分。
字符型:字符型数据的默认显示宽度为8个字符位,系统不区分变量名中的大小写字母,并且不能进行数学运算。 注意:在输入数据时不应输入引号,否则双引号将会作为字符型数据的一部分。 日期型:日期型数据是用来表示日期或时间的。日期型数据的显示格式有很多,SPSS以菜单方式列出日期型数据的显示格式以供用户选择。事实上,SPSS存储中的日期型变量是该实践与1582年10月14日零点相差的秒数。

28
关于日期型格式的几点说明: “m”在年与日(字母y与d)之间表示月份;在时与秒(字母h与s)之间表示“分”钟。
“mmm”表示要求书写英文月份单词的前三个字母组成的缩写。 “ddd”三个字母d表示要求用从元月一日算起的日数表示日期。 指定了日期变量的格式,不一定在输入时就使用指定的格式。可以输入用“/”或“—”作分隔符的具体日期,回车后,系统将自动将输入的格式转化为指定的格式,显示在单元各种。

29
二、变量的测量尺度 在SPSS中使用Measure属性对变量的测量尺度进行定义。
(1)定类尺度(Nominal Measurement):定类尺度是对事物的类别或属性的一种测度,按照事物的某种属性对其进行分类或分组。 特点:其值仅代表了事物的类别和属性,即能测度类别差异,不能比较各类之间的大小,所以各类之间没有顺序和等级。对定类尺度的变量只能计算频数和频率。 在spss中,能适用定类尺度的数据可以是数值型,也可以是字符型变量。使用定类变量对事物进行分类时,必须符合穷尽原则和互斥原则。
定类尺度(Nominal Measurement):定类尺度是对事物的类别或属性的一种测度,按照事物的某种属性对其进行分类或分组。 特点:其值仅代表了事物的类别和属性,即能测度类别差异,不能比较各类之间的大小,所以各类之间没有顺序和等级。对定类尺度的变量只能计算频数和频率。 在spss中,能适用定类尺度的数据可以是数值型,也可以是字符型变量。使用定类变量对事物进行分类时,必须符合穷尽原则和互斥原则。")
30
(2)定序尺度(Ordinal Measurement):定序尺度是对事物之间的等级或顺序差别的一种测度,可比较优劣或排序。
特点:由于定序变量只能侧度类别之间的顺序,无法测出类别之间的准确差值,即测量数值不代表绝对的数量大小,所以其测量结果只能排序,不能进行运算。 (3)定矩尺度(Interval Measurement):定矩尺度是对事物类别或次序之间间距的测度。 特点:不仅能将事物区分为不同类型并进行排序,而且可能准确指出类别之间的差距是多少;定居变量通常以自然或物理单位为计量尺度,因此测量结果往往表现为数值,所以计量结果可以进行加减运算。
定矩尺度(Interval Measurement):定矩尺度是对事物类别或次序之间间距的测度。 特点:不仅能将事物区分为不同类型并进行排序,而且可能准确指出类别之间的差距是多少;定居变量通常以自然或物理单位为计量尺度,因此测量结果往往表现为数值,所以计量结果可以进行加减运算。")
31
(4)定比尺度(Scale Measurement):定比尺度是能够测算两个测度值之间比值的一种计量尺度,它的测量结果同定距变量一样表现为数值。
特点:定必变量是测量尺度的最高水平,它除了具有其他三种测量尺度的全部特点外,还具有可计算两个侧度至之间笔直的特点,因此它可以进行加、减、乘、除运算,而定居变量值可进行加减运算。

32
三、变量名与变量标签值 Label:定义变量名标签 Value:定义变量值标签

33
四、缺失值 Spss中缺失值有用户自定义缺失值和系统缺失值两大类。

34
2.2 数据的直接录入 2.1.1 操作界面说明 标尺栏 菜单栏 工具栏 数据输入区 数据编辑区 窗口标签 标题栏 状态栏 当前数据栏 显示区滚动条 Data View表可以直接输入观测数据值或存放数据,表的左端列边框显示观测个体的序号,最上端行边框显示变量名。

35
Variable View表用来定义和修改变量的名称、类型及其他属性,如图所示。
如果输入变量名后回车,将给出变量的默认属性。如果不定义变量的属性,直接输入数据,系统将默认变量Var00001,Var00002等。

36
在Variable View表中,每一行描述一个变量,依次是:
Type:变量类型。变量类型有8 种,最常用的是Numeric数值型变量。其它常用的类型有:String字符型,Date日期型,Comma逗号型(隔3位数加一个逗号)等。 Width:变量所占的宽度。 Decimals:小数点后位数。 Label:变量标签。关于变量涵义的详细说明。 Values:变量值标签。关于变量各个取值的涵义说明。 Missing:缺失值的处理方式。 Columns:变量在Date View 中所显示的列宽(默认列宽为8)。 Align:数据对齐格式(默认为右对齐)。 Measure:数据的测度方式。系统给出名义尺度、定序尺度和等间距尺度三种(默认为等间距尺度)。
等。 Width:变量所占的宽度。 Decimals:小数点后位数。 Label:变量标签。关于变量涵义的详细说明。 Values:变量值标签。关于变量各个取值的涵义说明。 Missing:缺失值的处理方式。 Columns:变量在Date View 中所显示的列宽(默认列宽为8)。 Align:数据对齐格式(默认为右对齐)。 Measure:数据的测度方式。系统给出名义尺度、定序尺度和等间距尺度三种(默认为等间距尺度)。")
37
为了在统计分析过程中能有效的利用其它软件产生的数据,SPSS软件编辑窗口除可以使用
为了在统计分析过程中能有效的利用其它软件产生的数据,SPSS软件编辑窗口除可以使用*.sav扩展名数据文件,还可以直接打开和保存下述类型的文件: SPSS DOS版本产生的数据文件*.sys; Excel 报表程序产生的数据文件*.xls; DBASE 数据库格式文件*.dbf; SAS统计软件产生的数据文件。

38
2.2.2 开放题和简单单选题的录入 一、在spss中定义变量 录入数据的第一步是定义变量属性,随后才能进行数据录入。 二、开放题的录入

39
三、单选题的录入 单选题的录入可以采用字符直接录入、字符代码+值标签、数值代码+值标签三种方式。

40
2.2.3多选题的录入 一、多重二分法(Multiple Dichotomy Method)
所谓多重二分法,是在编码的时候,对应每一个选项都要定义一个变量,有几个选项就有几个变量,这些变量均为二分类,他们各自代表对一个选项的选择结果。 二、多重分类法(Multiple Category Method) 多重分类法,也是利用多个变量对一个多选题的答案进行定义,应该用多少个变量,由被访者实际可能给出的最多答案数而定。
 多重分类法,也是利用多个变量对一个多选题的答案进行定义,应该用多少个变量,由被访者实际可能给出的最多答案数而定。")
41
三、多选题录入在spss中的实现

42
2.3 外部数据的获取 SPSS读入非SPSS类型的文件数据,有三种主要方式:直接打开,利用文本导向读入文本数据以及利用数据库OBDC接口读入数据。 2.3.1 电子表格数据如何导入spss中 SPSS中可以直接读入许多常用格式的数据文件,选择菜单File Open Data或直接单击快捷键工具栏上的 快捷按钮,系统就会弹出Open File 对话框,单击“文件类型”列表框,在里面能够看到可以直接打开的数据文件格式。

43
2.3.2 文本数据如何导入spss中 第一步:首先,在Open File 文件框中选中文件,单击“打开”,系统会自动启动文本倒入向导对话框。 第二步:选择“NO”并单击“下一步”按钮。

44
用某种字符区分 固定宽度 第三步:分别选择“Delimited”和“yes”,然后单击“下一步”按钮。

45
第四步

46
第五步

47
第六步

48
第七步

49
2.4 数据的保存 2.4.1 存为spss格式 2.4.2 存为其他数据格式

50
第3章 数据管理 3.1 变量级别的数据管理 对变量进行操作的内容主要集中于Transform菜单中,包括新变量的生成、记录的排序、对变量进行计数等。 ◇计算新变量:就是用Compute过程。 ◇变量转换:包括Recode、Visual Bander、Count、Rank Case、Automatic Recode这五个过程。 ◇专用过程:包括建立时间序列、缺失值代替和设定随机种子三个过程。 ◇Run Pending Transforming:用于执行编程中被挂起的数据整理操作。

51
计算产生新变量 连续变量进行分段 变量值重新编码 创建计数变量 创建时间序列变量 观测量排秩 创建代替缺失值变量 变量值自动编码 设定随机数种子 运行其它转换程序

52
3.1.1 计算新变量 计算新变量的功能就是在原有spss数据文件的基础上,根据用户的要求,使用spss算术表达式及函数,对所有记录或满足SPSS条件表达式的记录,计算出一个新结果,并将结果存入一个用户指定的变量中。 一、常用基本概念 (1)spss算术表达式 spss算术表达式是由常量、spss变量名、spss的算术运算符、圆括号等组成的式子。 (2)spss函数 spss提供了多达70多种函数,分为八大类:算术函数、统计函数、分布函数、逻辑函数、字符串函数、日期时间函数、缺失值函数和其它函数。 (3)spss条件表达式 通过spss的算术表达式和函数可以对所有记录计算一个结果,如果仅希望对部分记录进行计算,则应当利用spss的条件表达式指定对那些记录进行计算。
spss算术表达式 spss算术表达式是由常量、spss变量名、spss的算术运算符、圆括号等组成的式子。 (2)spss函数 spss提供了多达70多种函数,分为八大类:算术函数、统计函数、分布函数、逻辑函数、字符串函数、日期时间函数、缺失值函数和其它函数。 (3)spss条件表达式 通过spss的算术表达式和函数可以对所有记录计算一个结果,如果仅希望对部分记录进行计算,则应当利用spss的条件表达式指定对那些记录进行计算。")
53
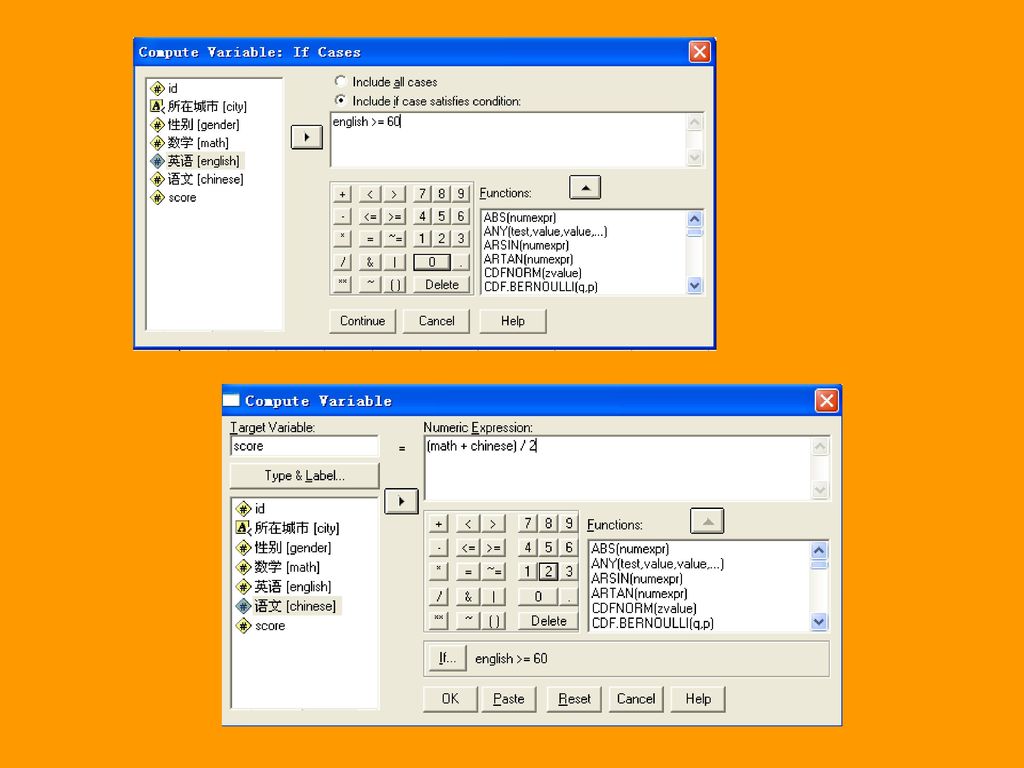
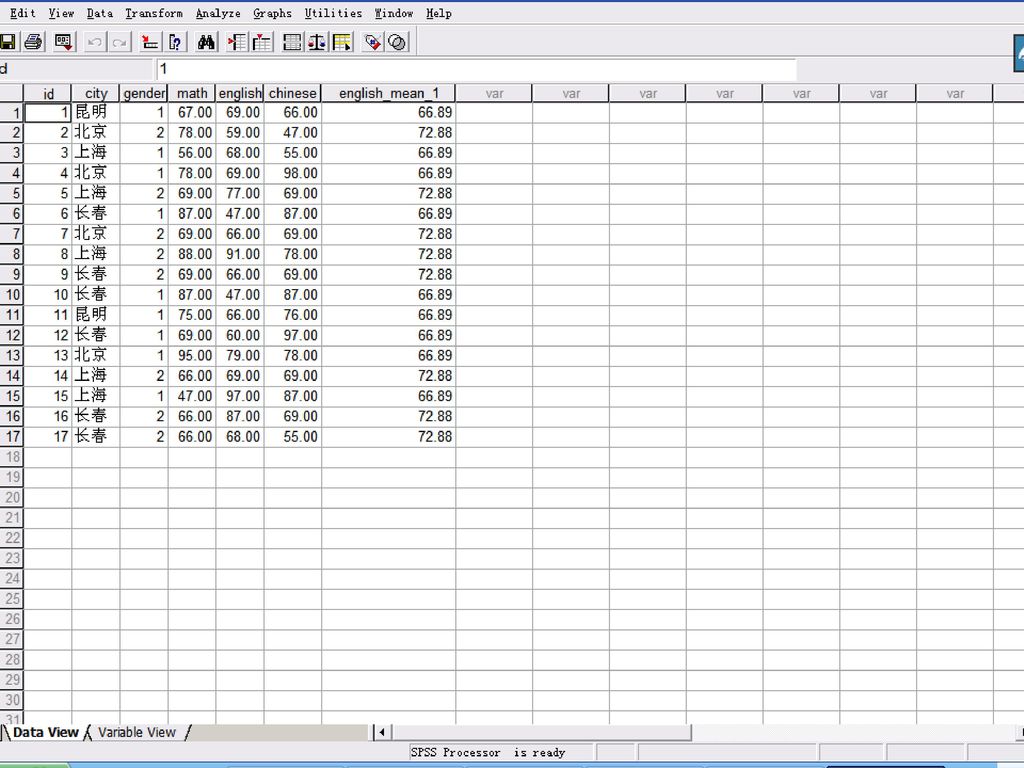
二、compute过程的分析实例 例3.1 统计英语成绩在60分以上的学生的数学和语文的平均成绩。

55
例3.2 计算工人工资的所得税。 学生自己练习。

56
3.1.2 对变量值进行分组合并 一、对连续变量进行分组
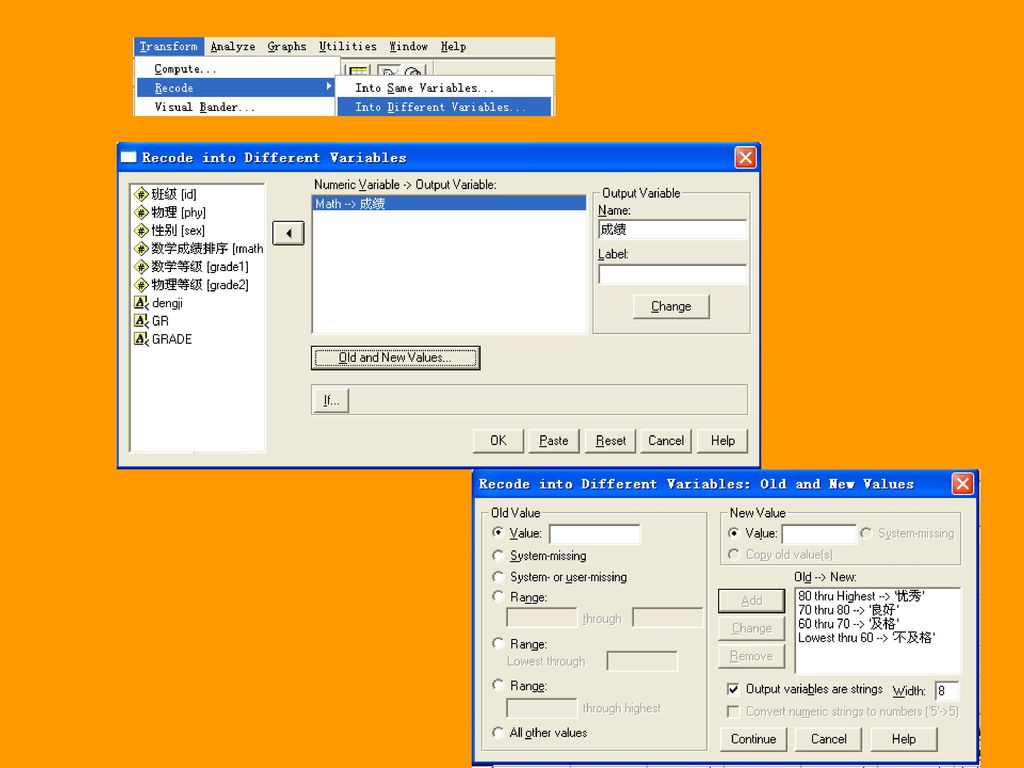
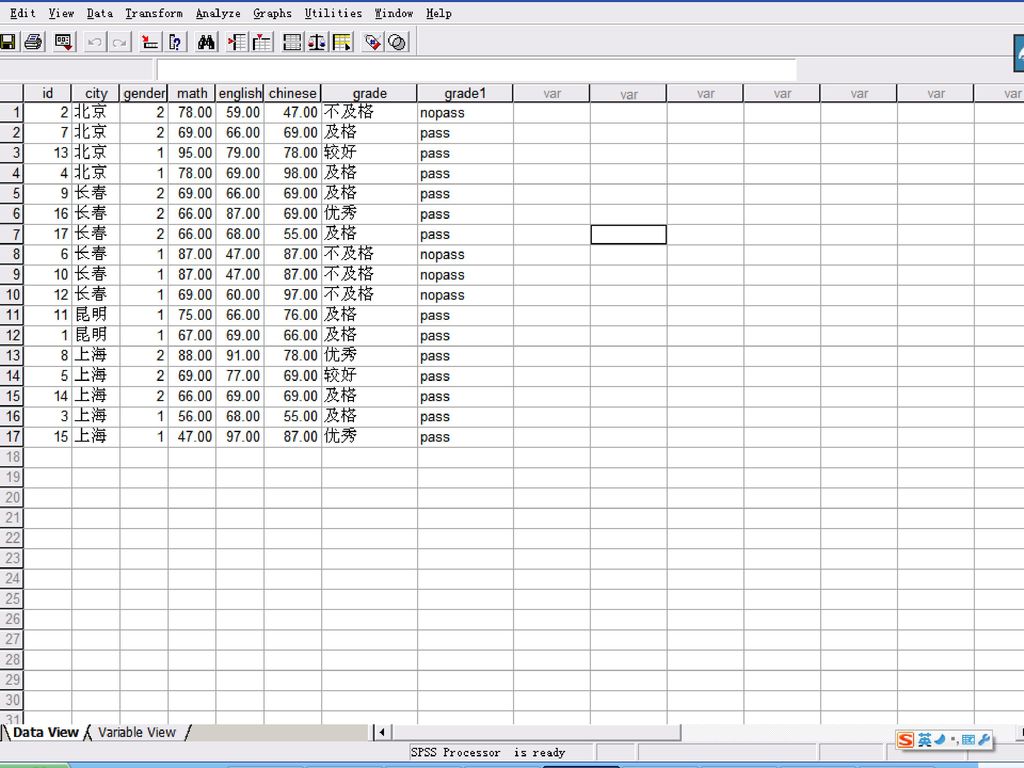
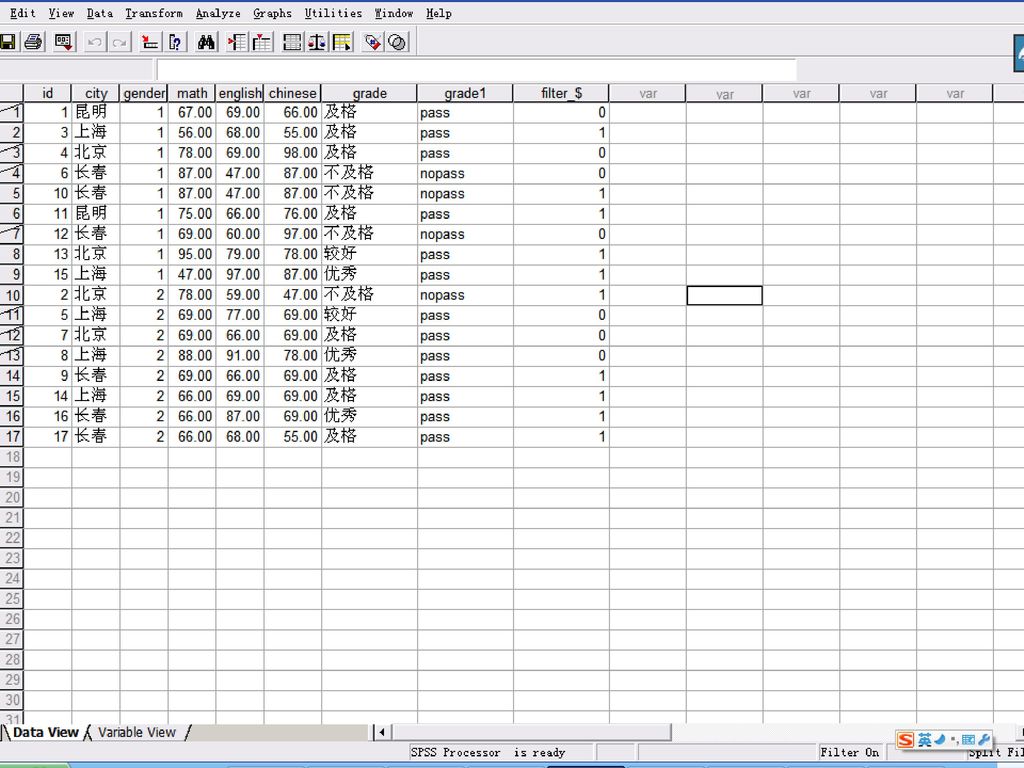
在SPSS中可以将连续变量转换为离散(等级或定序)变量,按照某种一一对应的关系生成新变量值,可以将新值赋给原变量。Recode过程和Visual Bander过程都可以完成这一任务,但前者给为简单和常用。 例3.3 当学生英语成绩小于60时取值为“不及格”,大于等于60且小于70为“及格”,大于等于70且小于80为“较好”,大于等于80为“优秀”。
变量,按照某种一一对应的关系生成新变量值,可以将新值赋给原变量。Recode过程和Visual Bander过程都可以完成这一任务,但前者给为简单和常用。 例3.3 当学生英语成绩小于60时取值为 不及格 ,大于等于60且小于70为 及格 ,大于等于70且小于80为 较好 ,大于等于80为 优秀 。")
58
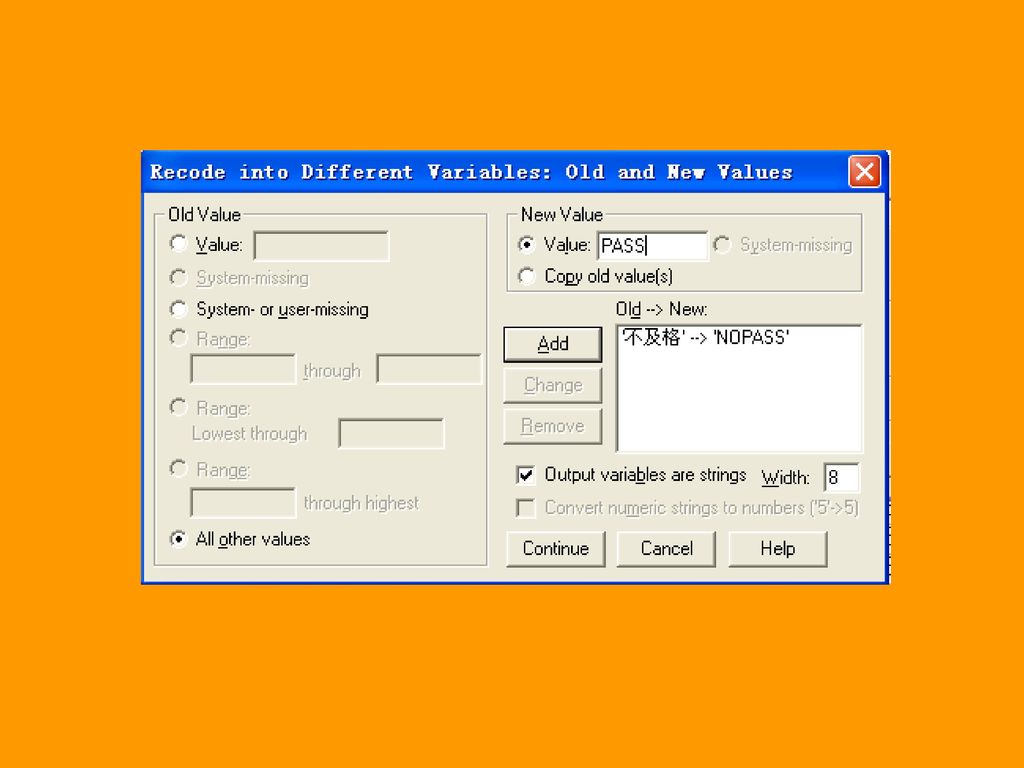
二、分类变量类别的合并 Recode过程也常用于合并某个分类变量的几个水平为一个水平。
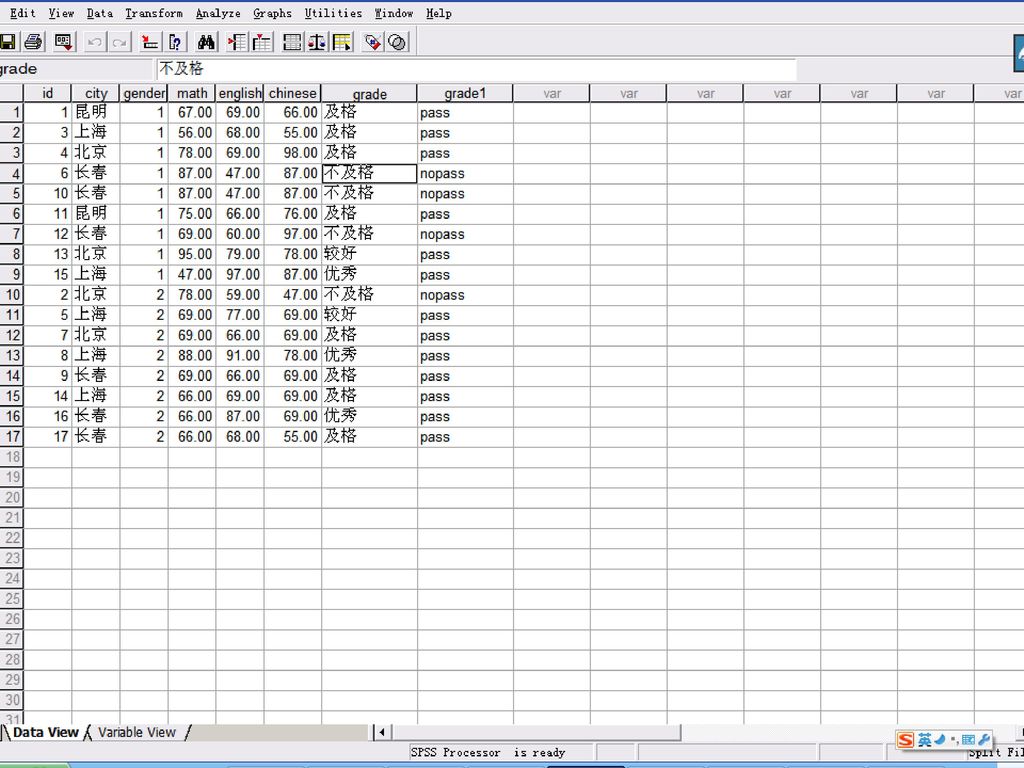
将上例grade中优秀、良好和及格三个等级合并为一个等级“PASS”,将grade的等级“不及格”转换为“NOPASS”。

60
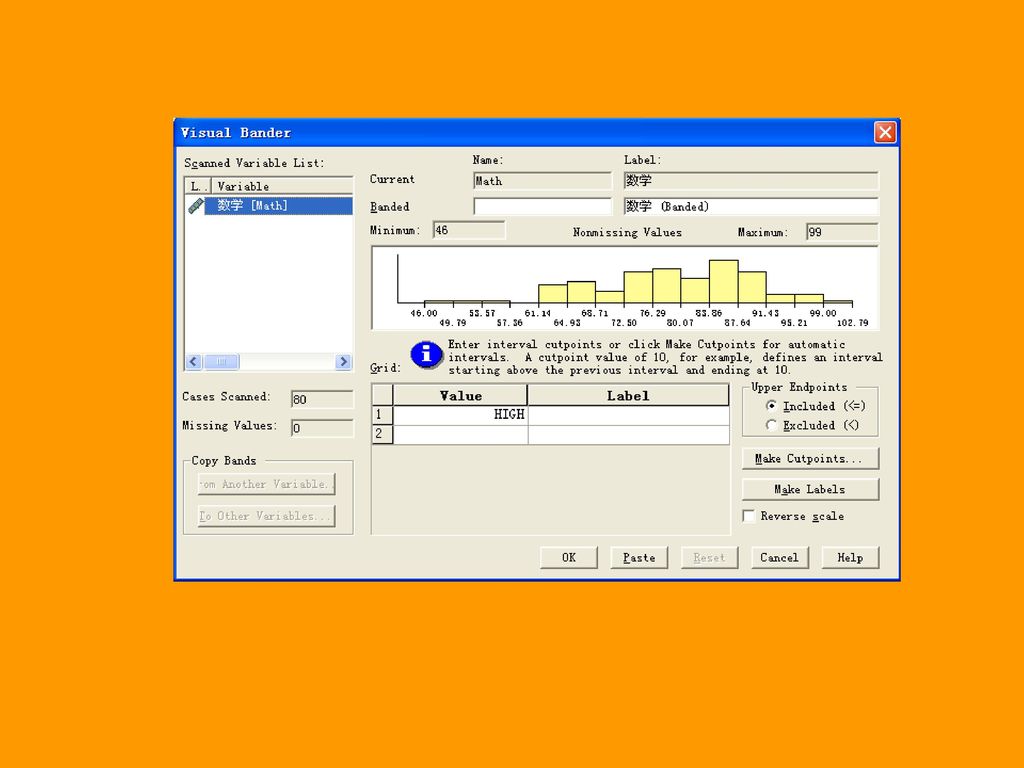
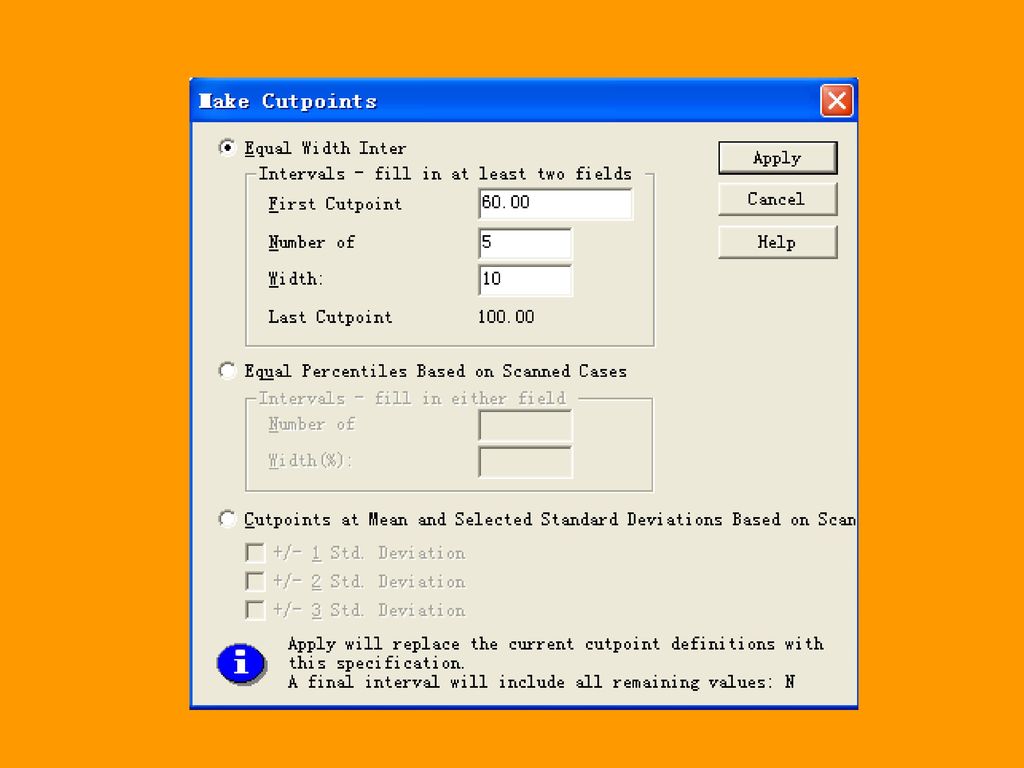
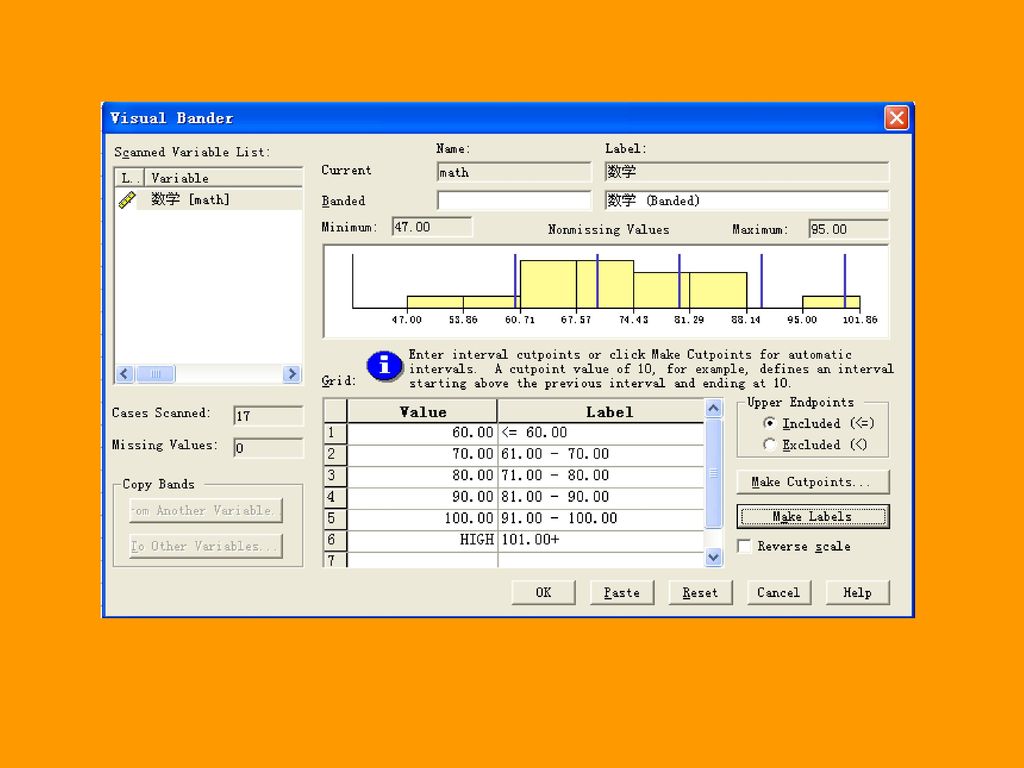
3.1.3 连续变量的可视化分段 VISUAL Bander 用于将连续变量进行分段,该过程使用百分位数、标准差范围或者等间距方式将连续变量划分为若干组段,并采用图形化操作的方式。 例3.4 对数学成绩进行分段,假设现在希望按变量math将学生分为5组,60分 以下为第一组,60分以上的按照等间距的方式分为4组。

64
3.1.4 将字符变量转换为数值变量 用automatic recode将字符变量转换为数值变量。

65
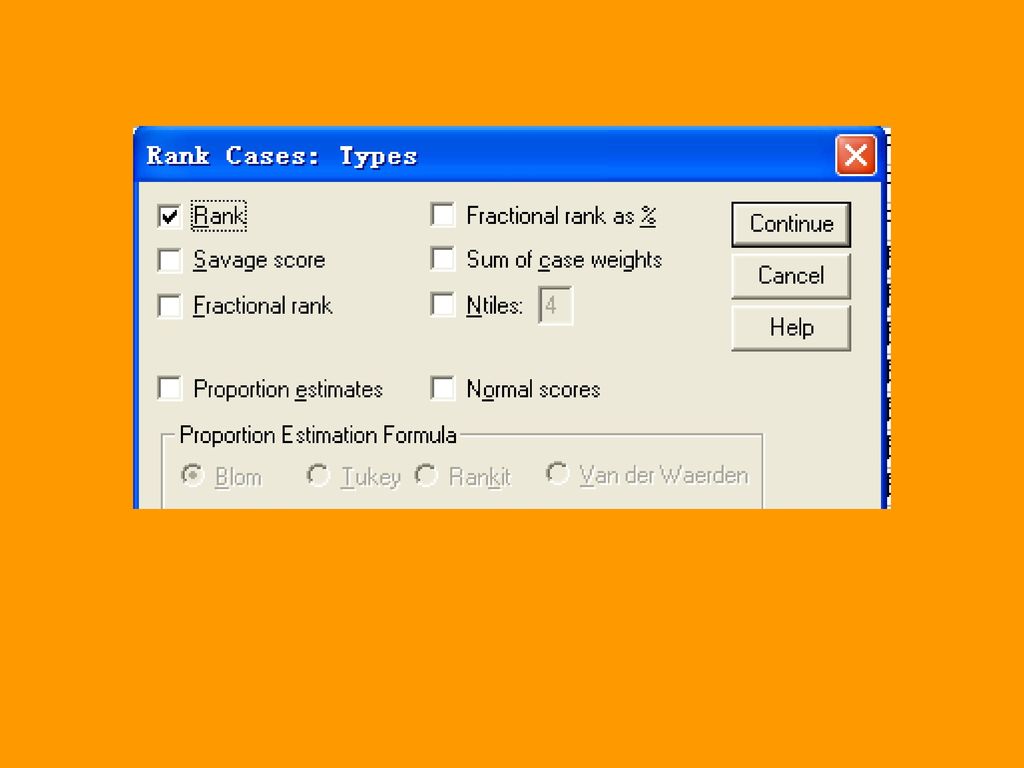
3.1.5 变量的编秩 所谓编秩,就是对记录按照某个变量值大小来排序。Rank case过程就是用来排序的一个专用过程。
例:根据性别分组计算数学成绩的秩次。

67
3.1.6 Transform菜单中的其它功能 (1)count过程 如果用户需要对满足某项条件的数据进行计数,可以使用Count命令。
先在Target Variable中指定一个变量(可以是已经存在的变量或新变量),并定义变量标签,然后指定要统计的变量加到Numeric Variables框中,再单击Define Values按纽,打开Value to Count对话框。
,并定义变量标签,然后指定要统计的变量加到Numeric Variables框中,再单击Define Values按纽,打开Value to Count对话框。")
68
Value:输入某个值为清点对象; System-missing:以系统的缺失值为清点对象; System-or user missing:以系统或用户指定的缺失值为清点对象; Range:指定数值的计数区域:其中包括: ( )through( )在框内指定下限和上限 lowest through( ): 在框内只指定上限; ( )highest through: 在框内只指定下限。
through( )在框内指定下限和上限. lowest through( ): 在框内只指定上限; ( )highest through: 在框内只指定下限。")
69
(2)random Number Seed过程: 用于设定伪随机函数的随机种子。
random Number Seed过程: 用于设定伪随机函数的随机种子。")
70
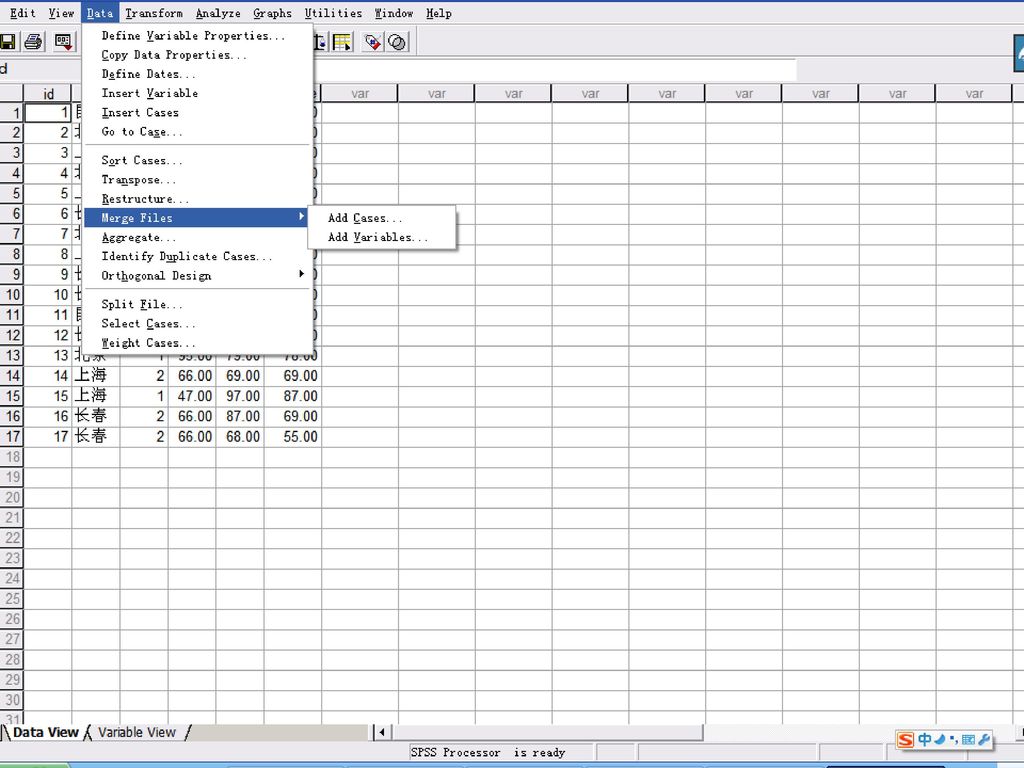
3.2 文件级别的数据管理(一) 数据编辑窗口的Data菜单为用户创建和定义数据提供了方便的功能。这个菜单是SPSS统计软件数据整理的特有功能菜单。它的功能包括:对变量、观测量的编辑处理;对变量数据的变换;对观察量数据整理。 (1)简单命令:包括插入变量、插入记录和到达某条记录,他们的功能实际上都可以用鼠标在数据表界面上直接完成,很少会使用菜单来调用。 (2)常用的简单过程:包括排序、拆分文件、选择记录和加权记录。 (3)变量与数据文件属性导向:用于定义数据字典,或者将于定义的数据字典直接引入当前数据文件。
简单命令:包括插入变量、插入记录和到达某条记录,他们的功能实际上都可以用鼠标在数据表界面上直接完成,很少会使用菜单来调用。 (2)常用的简单过程:包括排序、拆分文件、选择记录和加权记录。 (3)变量与数据文件属性导向:用于定义数据字典,或者将于定义的数据字典直接引入当前数据文件。")
71
(4)数重构过导向:用于进行数据转置,或者对重复测量数据表进行长型、宽型记录间的转换。
(5)文件合并过程:将几个数据文件合并为一个大的spss数据文件,含横向合并和纵向合并两种情况。 (6)正交设计过程:实际上是联合分析模块的一部分,用于生成实施联合分析所需要的设计。 (7)其他过程:包括定义日期变量过程、数据汇总过程和查找重复记录导向。
文件合并过程:将几个数据文件合并为一个大的spss数据文件,含横向合并和纵向合并两种情况。 (6)正交设计过程:实际上是联合分析模块的一部分,用于生成实施联合分析所需要的设计。 (7)其他过程:包括定义日期变量过程、数据汇总过程和查找重复记录导向。")
72
定义变量属性 拷贝数据属性 插入一个变量 定义变量日期 定位观测量 插入观测量 数据文件转置 观测量排序 合并数据文件 重构数据结构 标识重复观测量 分类或不分类汇总 拆分数据文件 正交设计 观测量加权 选择观测量

73
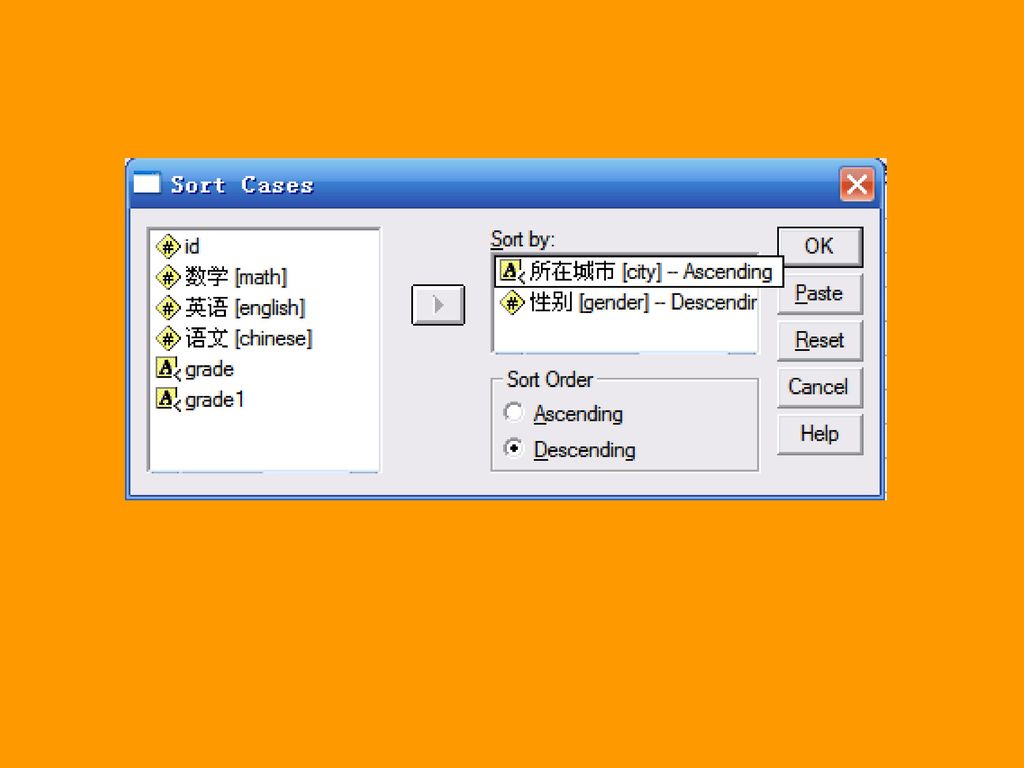
3.2.1 记录排序 一、排序的两种方法: (1)在数据表格的变量名处单击右键,弹出的右键菜单最后两项就是“sort Ascending”和“Sort Descending”。 (2)对于多变量排序,则需要使用Sort Cases过程来进行。 二、多变量排序需要注意的三点: (1)在多重排序中,制定排序变量名是很关键的,先指定的变量在排序时必然优先于后制订的变量。 (2)可以指定按某变量值升序排序的同时按另一变量值降序排序,或相反。 (3)排序以后,原来记录数据的排列次序将被打乱。
在多重排序中,制定排序变量名是很关键的,先指定的变量在排序时必然优先于后制订的变量。 (2)可以指定按某变量值升序排序的同时按另一变量值降序排序,或相反。 (3)排序以后,原来记录数据的排列次序将被打乱。")
76
3.2.2 记录拆分 Split File 分割文件的功能是把当前工作分割成两个或两个以上的组,随后的分析将对每个组进行。

78
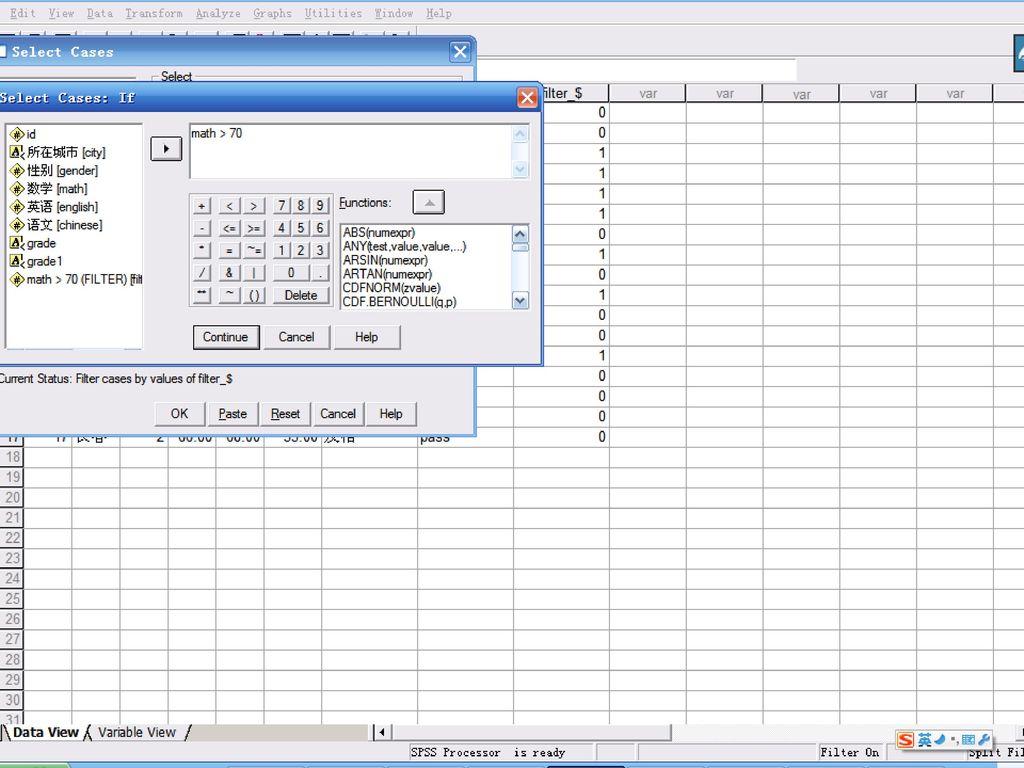
3.2.3 记录筛选 Select Cases:当用户不需要分析全部的数据,而是按要求分析其中的一部分,使用该选择。
All case:选择所有数据; If condition is satisfied: 按指定条件选择数据。

79
Random Sample of cases:对观察值进行随机抽样。

83
Based on time or case range:顺序抽样。单击Range按纽,打开Select Case: Range对话框,用户自行定义从第几个观察值开始抽到第几个观察值结束。
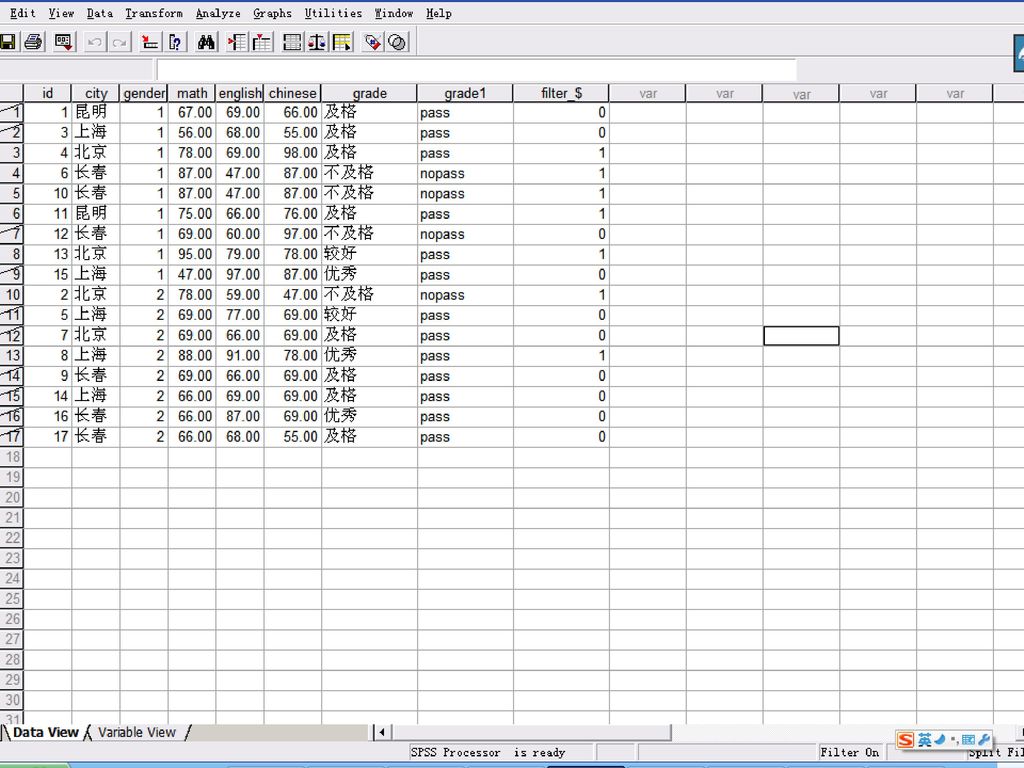
Use filter variable:用指定变量作过滤。先选择一个变量,系统自动在数据管理器中将该变量值为0的观测单位标上删除记号,系统对标有删除记号的观测单位不作分析。

85
3.2.4 加权记录 Weight Cases:设定某变量为频数变量。

86
3.2.5 数据汇总 一、汇总的概念 二、进行分类汇总的方法
所谓分类汇总就是按指定的分类变量对观测值进行分组,对每组记录的各变量求指定的描述统计量,结果可以存入新数据文件,也可以替换当前数据文件。 二、进行分类汇总的方法 1、打开“data”菜单,选择“Aggregate”,展开aggregate data”对话框。

87
2、在左侧的源变量框中选择一个或多个变量作为分类变量进入分类变量(Break Variable[s])框中。
3、在左侧的源变量框中选择一个或多个变量作为要求汇总的变量进入汇总变量(Aggregate Variable[s])框中,即要求这些变量的值进行分类汇总。 4、“name& label” (名称与标签):单击此按钮可以修改组合后所生成新变量名称以及标签:可以在name后面的矩形框中输入新变量名。在Label后面的矩形框中输入新变量标签。单击“continue”按钮继续。
![2、在左侧的源变量框中选择一个或多个变量作为分类变量进入分类变量(Break Variable[s])框中。](http://slidesplayer.com/slide/11173131/60/images/87/2%E3%80%81%E5%9C%A8%E5%B7%A6%E4%BE%A7%E7%9A%84%E6%BA%90%E5%8F%98%E9%87%8F%E6%A1%86%E4%B8%AD%E9%80%89%E6%8B%A9%E4%B8%80%E4%B8%AA%E6%88%96%E5%A4%9A%E4%B8%AA%E5%8F%98%E9%87%8F%E4%BD%9C%E4%B8%BA%E5%88%86%E7%B1%BB%E5%8F%98%E9%87%8F%E8%BF%9B%E5%85%A5%E5%88%86%E7%B1%BB%E5%8F%98%E9%87%8F%EF%BC%88Break+Variable%5Bs%5D%EF%BC%89%E6%A1%86%E4%B8%AD%E3%80%82.jpg "3、在左侧的源变量框中选择一个或多个变量作为要求汇总的变量进入汇总变量(Aggregate Variable[s])框中,即要求这些变量的值进行分类汇总。 4、 name& label (名称与标签):单击此按钮可以修改组合后所生成新变量名称以及标签:可以在name后面的矩形框中输入新变量名。在Label后面的矩形框中输入新变量标签。单击 continue 按钮继续。")
88
5、“Function”(函数) 选择此项可以确定汇总变量的描述内容;系统默认函数为平均数。
 选择此项可以确定汇总变量的描述内容;系统默认函数为平均数。")
90
3.3文件级别的数据管理(二) 3.3.1 数据字典的定义与应用
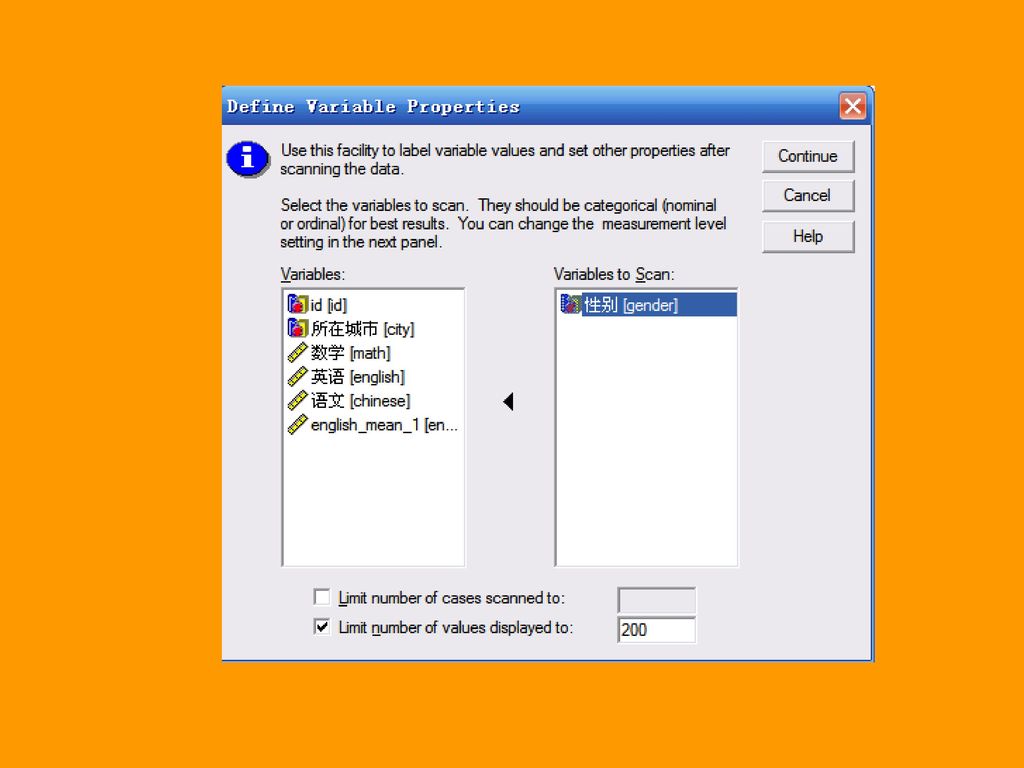
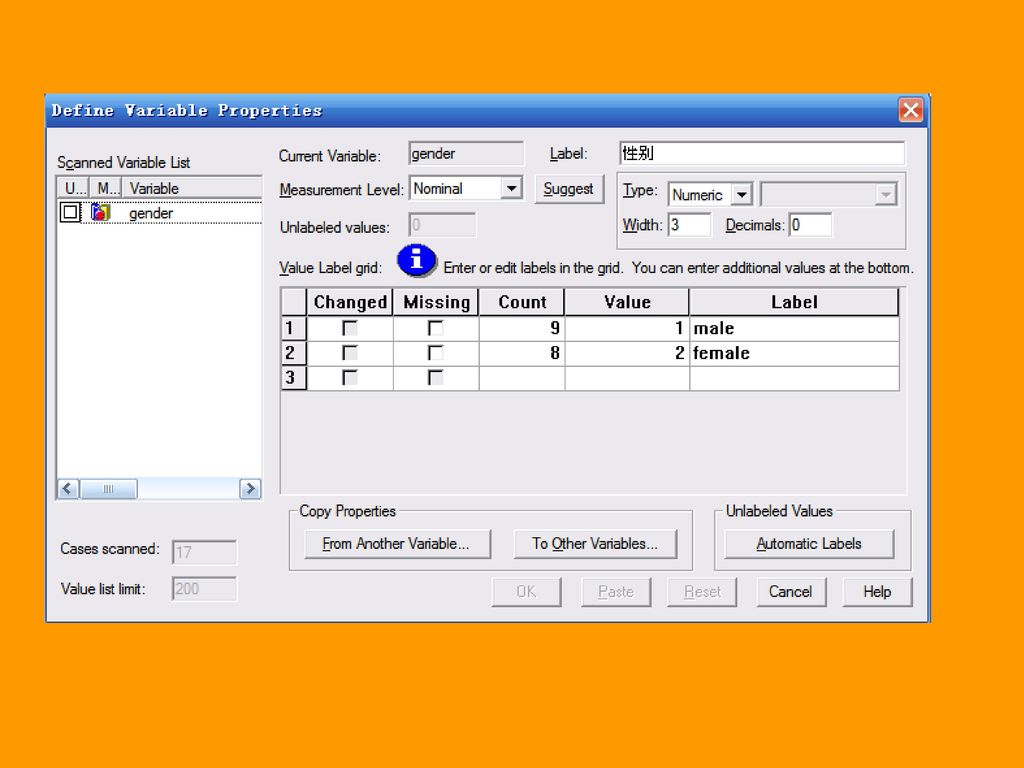
在大型的数据分析项目中,数据管理是非常重要的一个环节,为了保证工作质量,数据处理人员往往会事先定义好一个非常详细的数据格式,包括变量格式、变量标签、标签值、缺失值定义等,这被称为数据字典。 一、变量属性定义导向:Define Variable Properties 具体说来,可以列出所选变量的所有值;分辨没有值标签的值,并且提供自动给出值标签的功能;可以将另一个变量的属性拷贝到所选变量,也可以将所选变量的属性拷贝到其他变量。

93
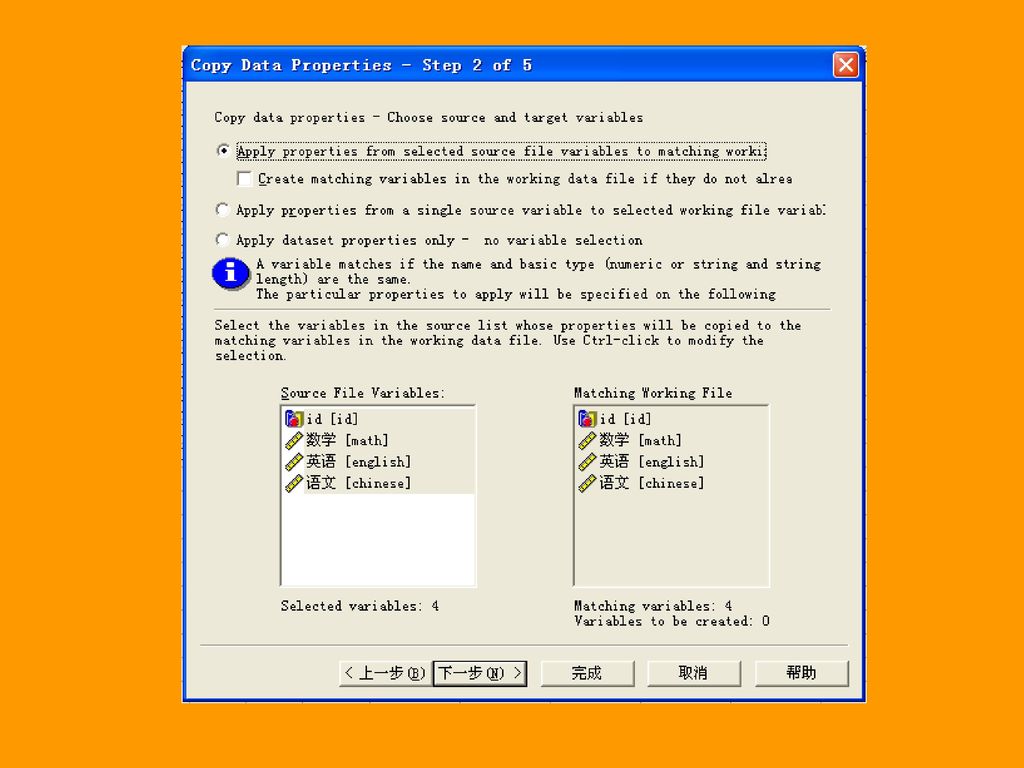
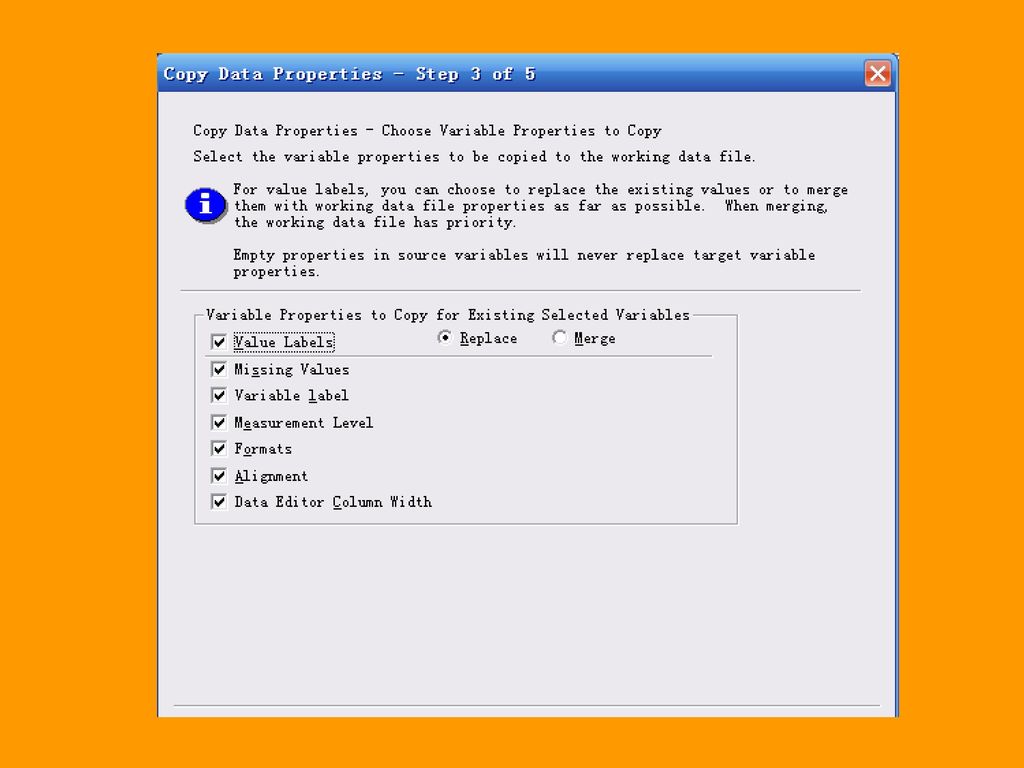
二、复制数据文件属性导向 Copy Data Properties 过程用于将定义好的数据字典直接应用到当前文件中。
操作时不仅可以将一个外部数据文件相关属性拷贝到当前数据文件中,还可以进行自行定义,只选择某些变量,或者某些属性进行拷贝,这无疑大大提高了连续性项目对原有资源的利用程度。

96
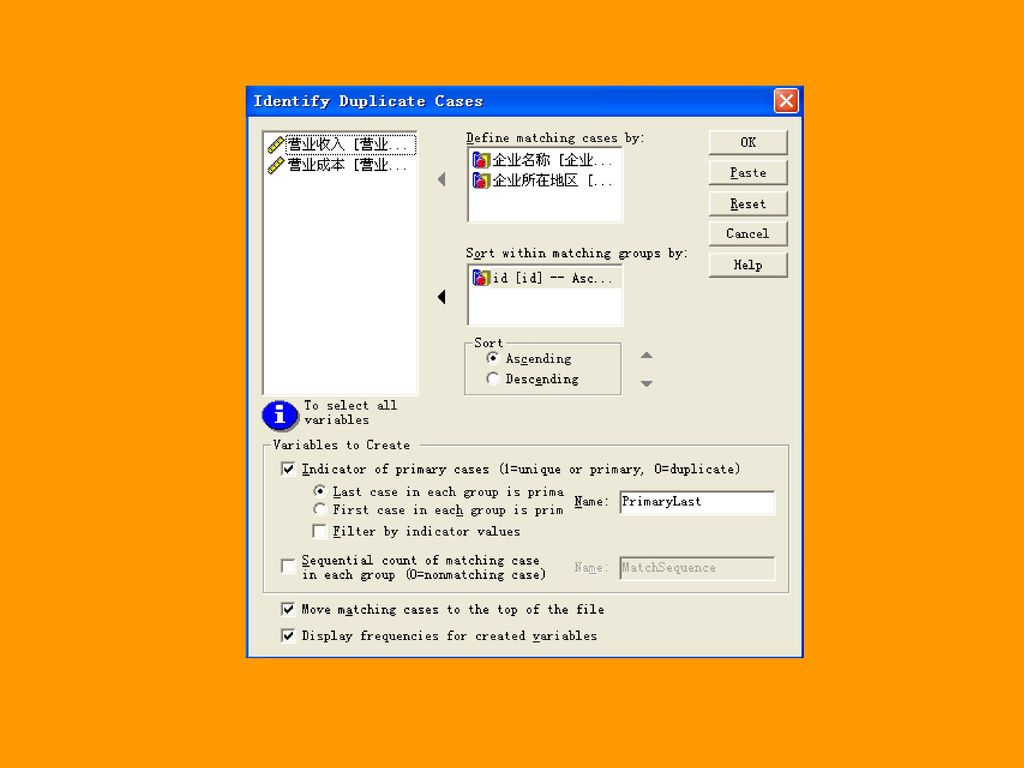
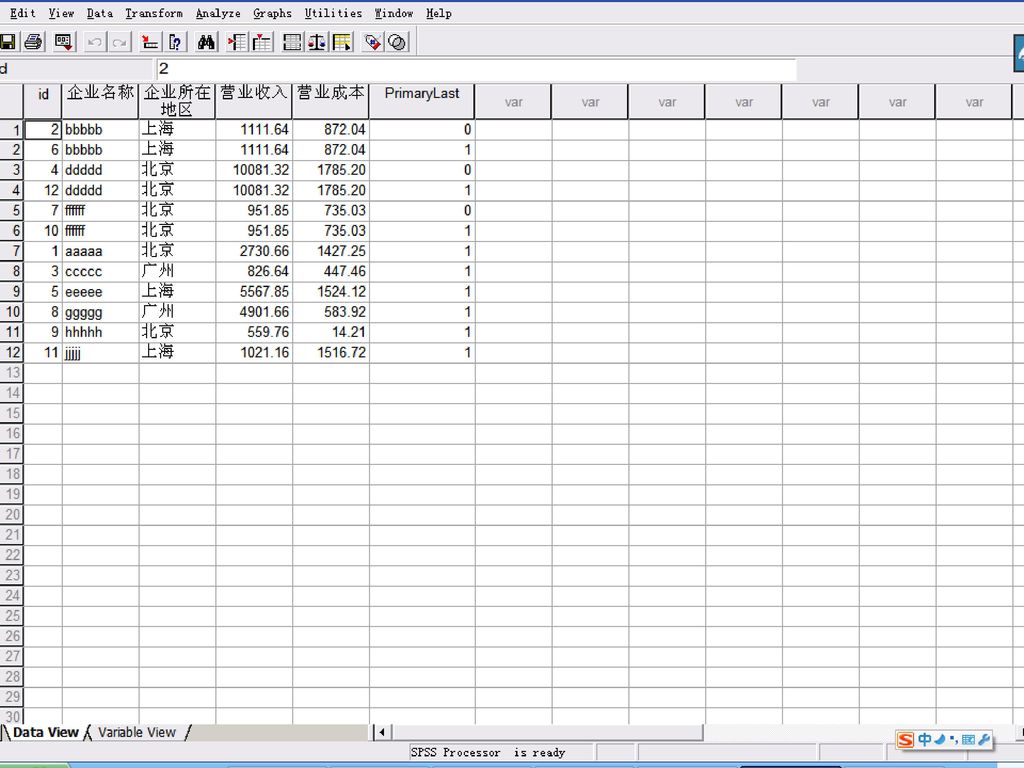
3.3.2 查找重复记录 Identifying Duplicate Cases:用于查找重复记录。

100
运行结束后,结果窗口会给出本次操作的信息汇总:

101
3.3.3 数据文件的重新排列与转置 一、数据的长型与宽型格式: 长型格式和宽型格式指的是重复测量数据的两种不同的排列方式。
由于重复测量模型可以使用不同的统计模型加以分析,因此根据模型的要求进行长型格式和宽型格式之间的互转换是数据分析中经常要遇到的问题。

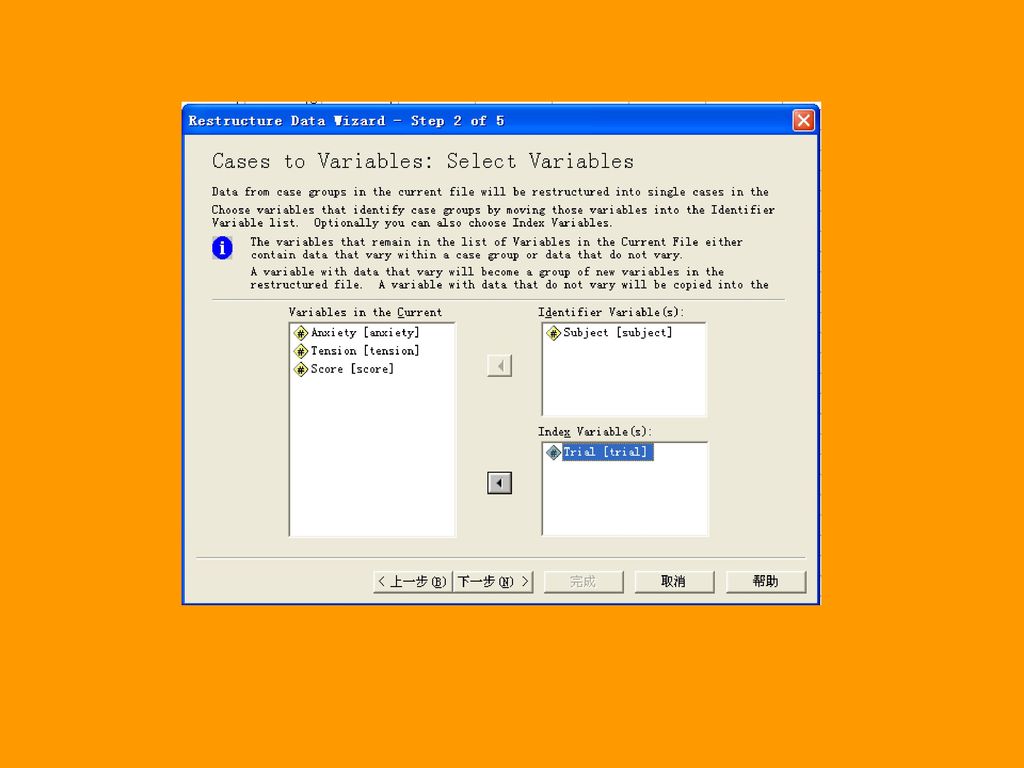
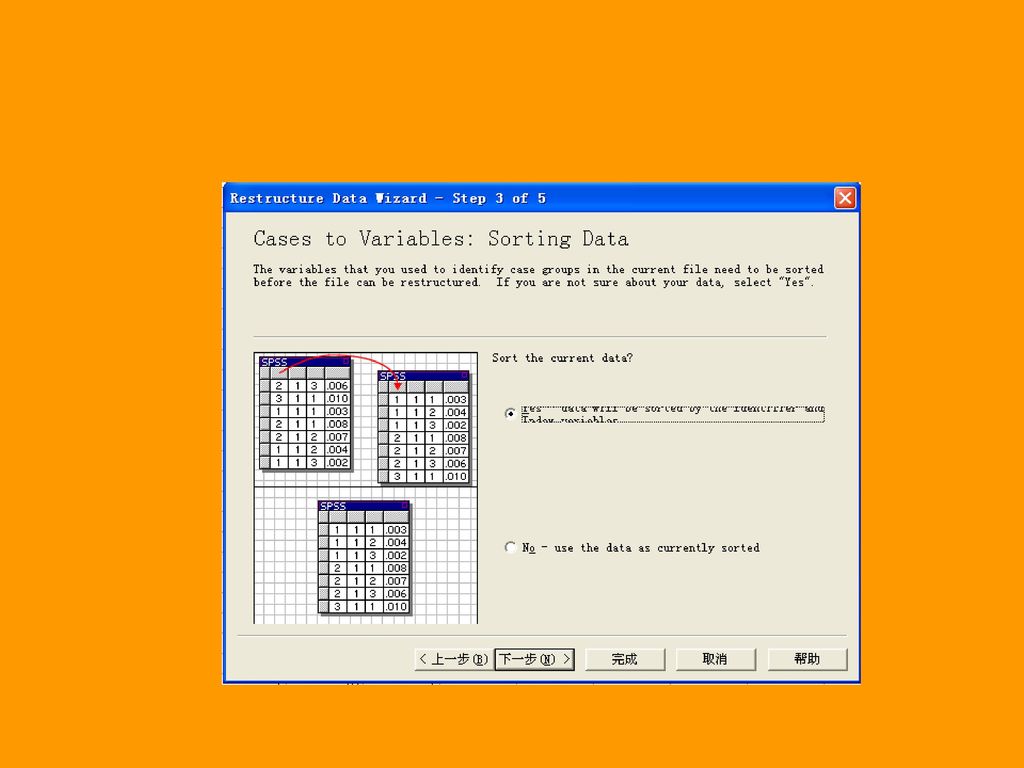
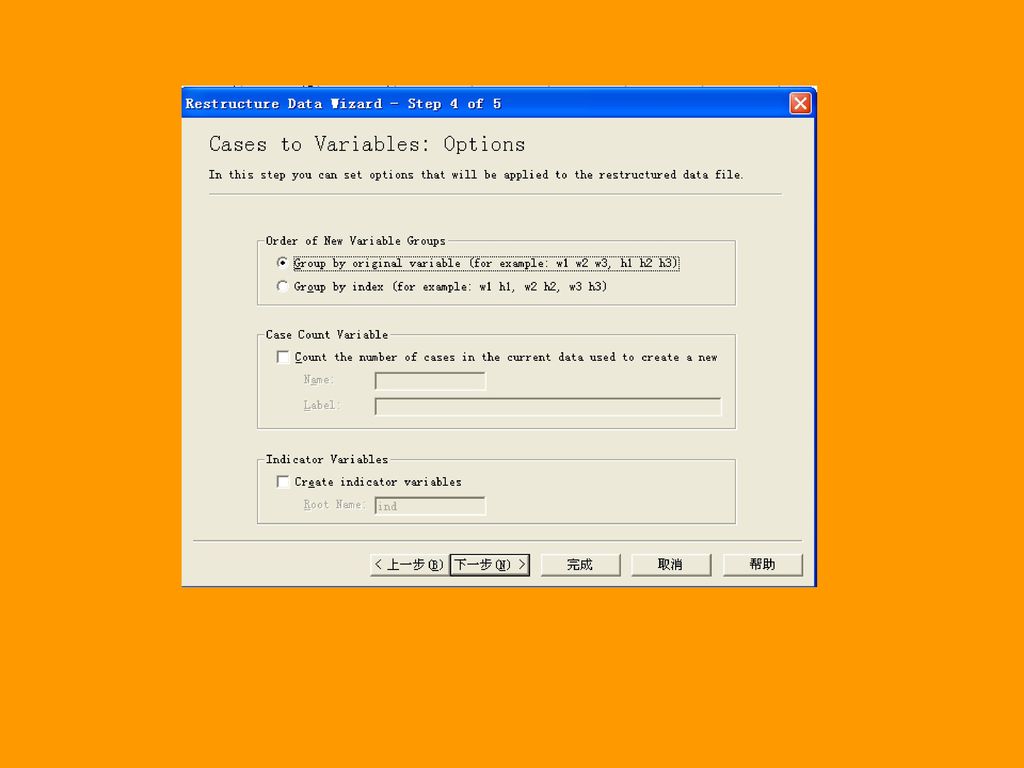
104
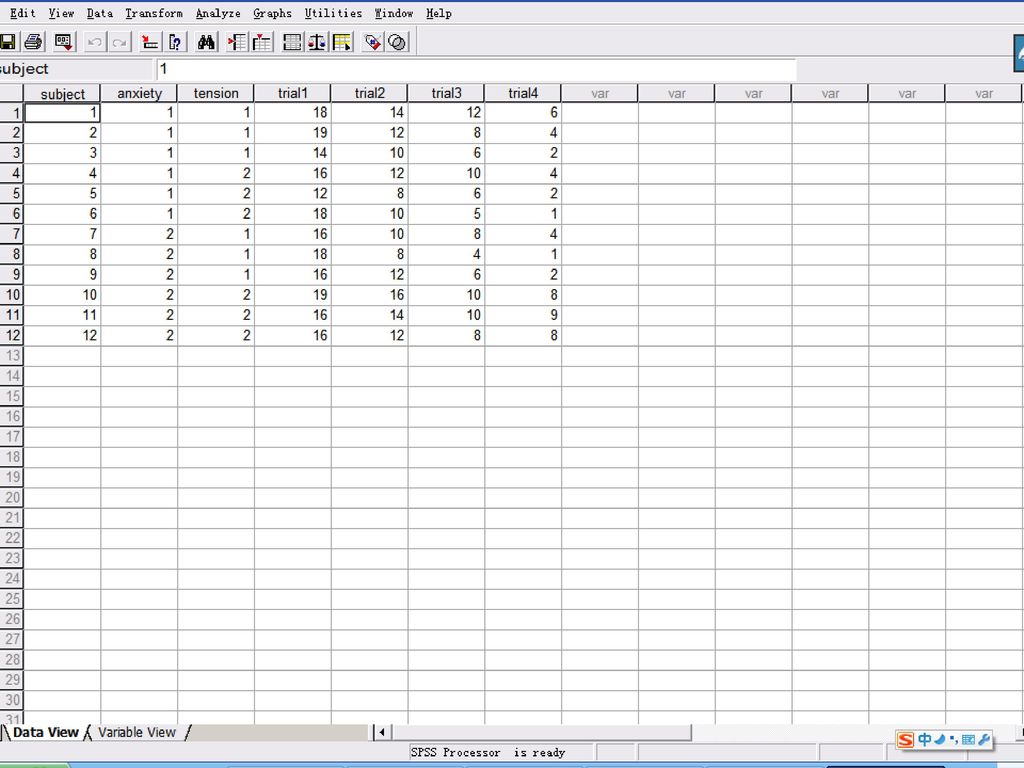
二、长型格式转换为宽型格式:Restructure。
选择Data Restructure,系统就会弹出下图导向。

109
三、数据转置 Transpose:用于对数进行行列转置,数据文件的转置就是将数据编辑窗口中数据的行列互换,即将记录转为变量,将变量转为记录后,重新显示在数据编辑窗口中。

110
Variable(s):放入将要行列转置的变量名。在数据文件中,未放入栏中的变量会遗失。字符串变量不能转换,如强迫转换,变量值转变为系统缺失值。
Name variable:变量命名栏,在左侧源变量栏中选择一个变量,放入name variable栏,技改变量的数据作为转置后的变量名。

111
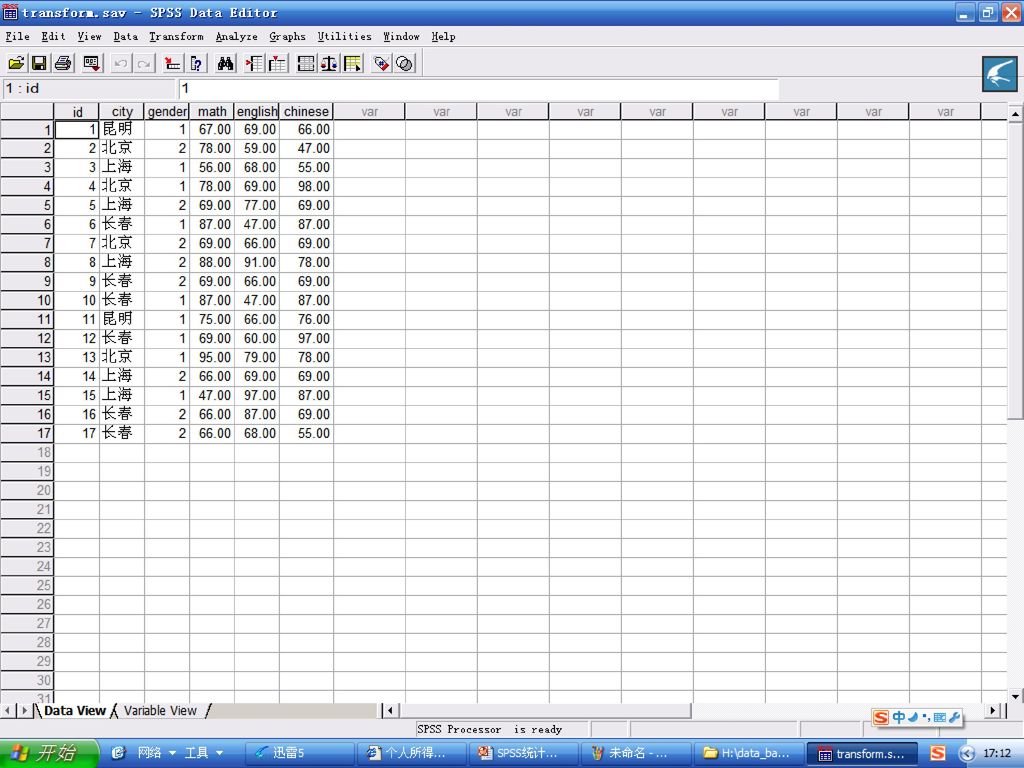
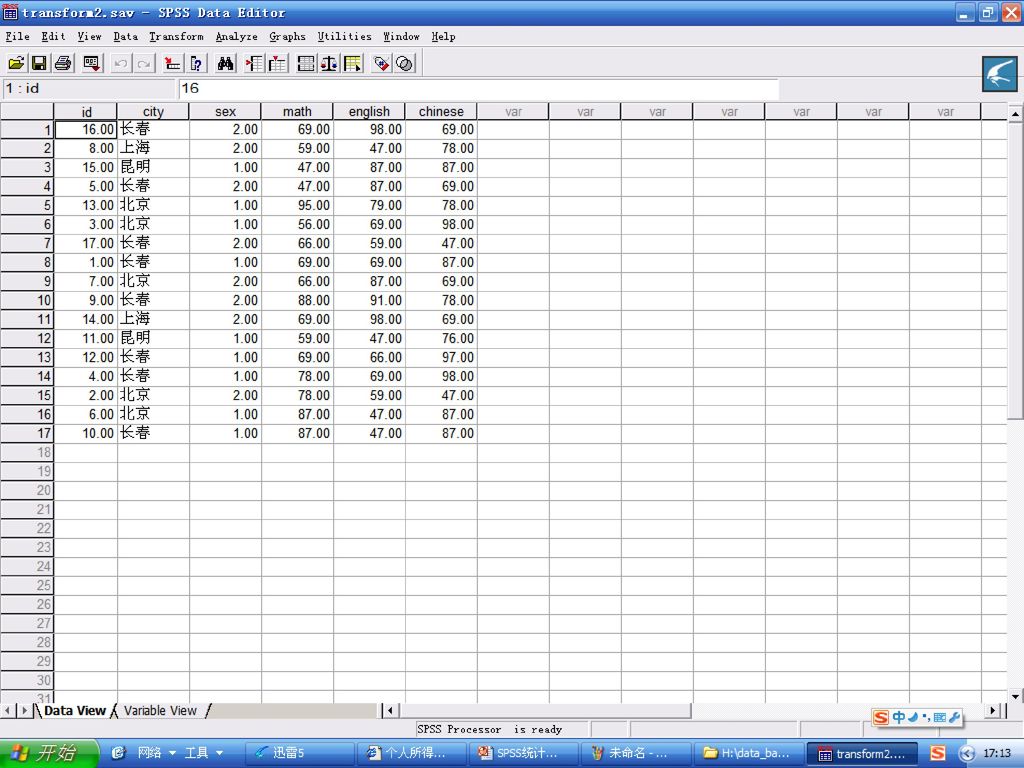
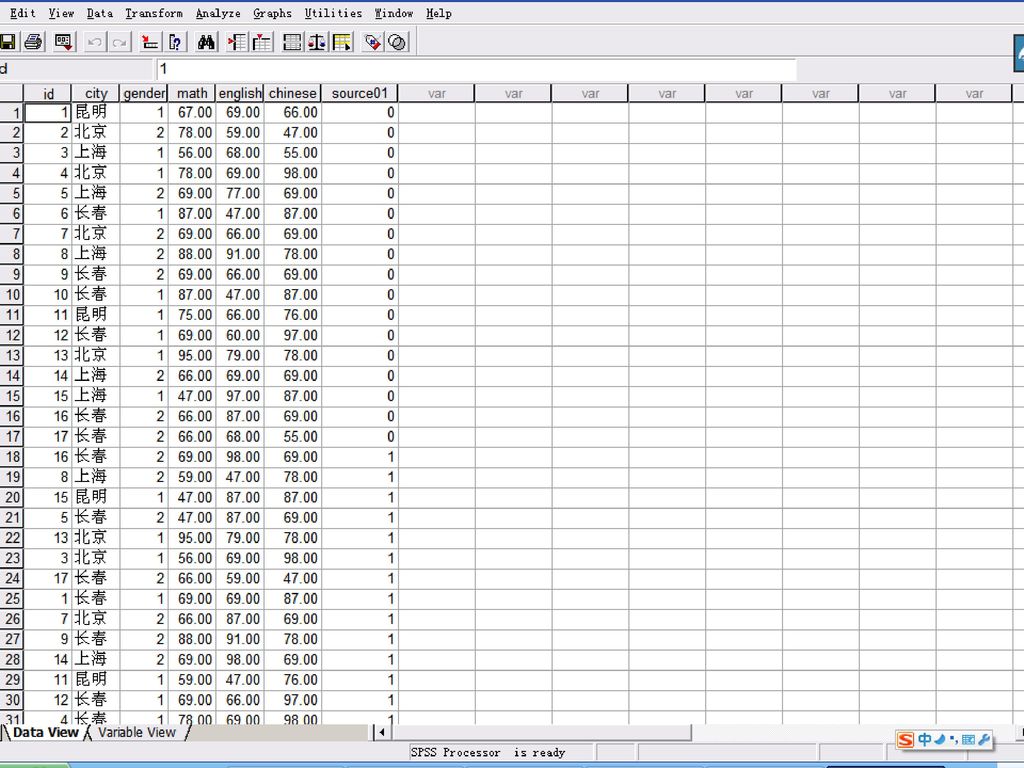
3.3.4 多个数据文件的合并 一、数据文件的纵向连接
纵向连接:几个数据集中的数据相加,组成一个新的数据集,新数据集中的记录是原来几个数据集中记录数的总和。 横向连接:指的是按照记录的次序,或者某个关键变量的数值,将不同数据集中的不同变量合并为一个数据集,新数据集中的变量数是所有原数据集中不重名变量的总和。 一、数据文件的纵向连接 纵向合并实质就是将两个数据文件的变量列,按照各个变量名的含义,一一对应的进行首尾相接。 纵向合并必须遵循两个条件: 第一,两个合并的spss数据文件,其内容合并是有实际意义的。 第二,为方便spss数据文件的合并,在不同的数据文件中,最好起相同的名字,变量类型和变量长度也要尽量相同。

115
Unpaired variable:不匹配变量栏。指变量名相同而变量定义不同的变量,或变量名不同的变量。
Variable in new working data:新工作数据变量栏。 Indicate case source as variable:指示记录来源的变量选项/

117
二、数据文件的横向合并 横向合并的实质是将两个数据文件的记录,按照记录对应,一一进行左右对接。 横向合并遵循三个条件:
第一,如果不是按照记录号对应的规律进行合并,则两个数据文件必须至少有一个变量名相同的公共变量,这个变量是两个数据文件横向合并的依据,成为关键变量。 第二,如果是使用关键变量进行合并的对应,则两个数据文件都必须事先按关键变量进行升序排列。 第三,为方便SPSS文件的合并,在不同的数据文件中,数据含义不相同的列,变量名不应取相同的名称。

119
Excluded Variables:拒绝变量名。外部文件与当前数据的同变量,拒绝加到新工作区中。
New Working Data:新工作数据变量栏。 Match Case on Key Variable in sort:排序文件中按关键变量匹配记录选项。 Both files provide case:由外部文件和当前数据量两者提供记录。 External file is keyed table:外部文件为关键表,以当前数据为基准,外部文件匹配当前数据的关键变量值,如匹配成功,外部文件的新变量值加入到当前数据的新变量中,匹配不成功则不加入。 Working Data File is keyed table:当前数据为关键表。 Key Variables:关键变量栏,在拒绝变量选择某变量作为关键变量。 Indicate case source as variable:指示记录来源的变量选项。

121
第4章 连续性变量的统计描述与参数估计 4.1 连续变量的统计描述概述 4.1.1 统计描述中的可用工具 (1)各种初步汇总描述方法
频数、百分位数。 (2)各种统计描述指标 均值、标准差、四分位数间距。 (3)统计表 (4)统计图
各种统计描述指标. 均值、标准差、四分位数间距。 (3)统计表. (4)统计图.")
122
4.1.2 连续变量的统计描述指标体系 (1)集中趋势 (Central Trend): 均数(Mean) 中位数(Median)
众数(Mode) 总合(Sum)
 总合(Sum)")
123
(2)离散趋势(Dispersion Trend)
标准差(Std. Deviation)、方差(Variance)、全距(Range)、最小值(Minimum)、最大值(Maximum)、标准误(S.E. Mean) (3)分布特征(Distribution Tendency) 偏度系数(Skewness)和峰度系数(Kurtosis) (4)其他趋势 百分位数指标(Percentile)、M统计量(M-Estimators)、极端值(Outlier)。
、方差(Variance)、全距(Range)、最小值(Minimum)、最大值(Maximum)、标准误(S.E. Mean) (3)分布特征(Distribution Tendency) 偏度系数(Skewness)和峰度系数(Kurtosis) (4)其他趋势. 百分位数指标(Percentile)、M统计量(M-Estimators)、极端值(Outlier)。")
125
4.1.3 spss中的相应功能 1、Spss的用于连续变量统计描述的过程,均集中在Descriptive Statistics子菜单中。
(1)Frequencies:产生原始数据的频数表,并能计算各种百分位数。
Frequencies:产生原始数据的频数表,并能计算各种百分位数。")
126
控制频数表输出范围类型的最大数目

127
(2)Descriptive过程 该过程用于一般性的统计描述,相对于Frequencies过程而言,它不能绘制统计图。
Descriptive过程 该过程用于一般性的统计描述,相对于Frequencies过程而言,它不能绘制统计图。")
128
(3)Explore 过程 该过程用于对连续性资料分布状况不清楚时的探索性分析,它可以计算许多描述统计量,给出各种统计图,并进行简单的参数估计。
Explore 过程 该过程用于对连续性资料分布状况不清楚时的探索性分析,它可以计算许多描述统计量,给出各种统计图,并进行简单的参数估计。")
130
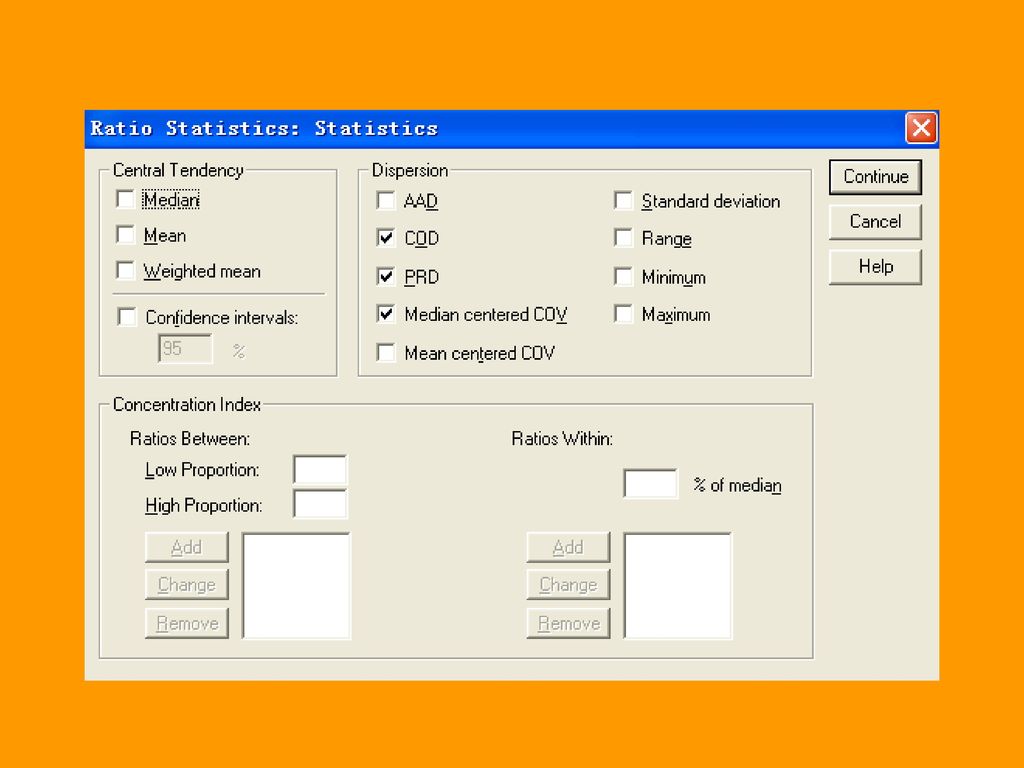
(4)Ratio 过程 用于对两个连续性变量计算相对比指标。
Ratio 过程 用于对两个连续性变量计算相对比指标。")
132
2、Compares means 均值比较

133
means过程:means过程的优势在于各组的描述指标被放在一起便于相互比较,并且如果需要,可以直接输出结果,无须再次调用其它过程。

134
4.2集中趋势的的描述指标 4.2.1 算术平均 算术平均(Arithmetic Mean)是最常用的描述输送距分布的集中趋势的统计良。总体均数(Population Mean)用希腊字母 表示,样本均数常用 表示。 一、算术平均数的定义和性质

135
二、均数的意义 三、均数的适用范围 任何一个平均数值首先是同类现象的平均数。任何一个平均数总是一个平衡点。
但平均数在高度概括观测数据从而使问题简化的同时,却丢失了某些有用的信息,一方面它把各个观测数据之间的差异性掩盖了起来,另一方面由于平均数对于个别极端值反应比较灵敏,因而平均数在某些情况下可能具有一定的欺骗性。 三、均数的适用范围 严格的讲平均数指示用于定距变量。但有时对于定序变量,求平均等级也可以使用平均数。

136
4.2.2 中位数 一、中位数的定义 二、中位数的适用范围
中位数(Median)是将总体各单位的标志值按大小顺序排列,处于中间位置的那个标志。 一、中位数的定义 对于未分组的原始资料,首先必须将标志值按大小顺序。设排序结果为: 则中位数就可以按下列方式确定: 二、中位数的适用范围
是将总体各单位的标志值按大小顺序排列,处于中间位置的那个标志。 一、中位数的定义. 对于未分组的原始资料,首先必须将标志值按大小顺序。设排序结果为: 则中位数就可以按下列方式确定: 二、中位数的适用范围.")
137
4.2.3其他集中趋势指标 一、截尾均数 由于均数较易受极端之的影响,因此可以考虑将数据排序后,按照一定的比例去掉最两端的数据,只是用中部的数据来求均数。如果截尾均数河源均数相差不大,则说明数据不存在极端值,或者两侧极端值的影响正好抵消;反之,则说明数据中有极端值,此时截为均数更好地反映数据的集中趋势。 常用的截尾均数有5%截尾均数,即两端各去掉5%的数据。

138
二、几何均数 几何均数适用于原始数据分布不对称,但经过对数转换后称对称分布的资料。
几何均数世纪上就是对数转换后的数据lgX的算术平均数的反对数。

139
三、众数(Mode) 四、调和均数 众数指的是样本数据中出现频次最多的那个数。 它实际上是观察值X倒数之均数的倒数。
众数适用于任何层次的变量,特别适用于单峰对称的情况,是比较两个分布是否接近首先要考虑的参数。 在SPSS中,众数可以在Report子菜单和Tables子菜单的全部报表过程和制表过程中计算出来。 四、调和均数 它实际上是观察值X倒数之均数的倒数。 在SPSS中,调和均数可以在Report子菜单的4个报表过程过程中计算出来。

140
4.3 离散趋势的描述指标 4.3.1全距(Range) 又称为极差,是一组数据中最大值(Maximun)与最小值(Minimum)之差。
极差反映的是变量分布的差异范围或离散程度,在总体中,任何两个标志值之差都不可能超过极差。 极差存在两点不足: 一是它仅仅取决于两个极端之的水平,不能反映其间的变量分布情况,提供的信息太少。 二是它容易受个别极端值的影响,不符合稳健型的要求。

141
4.3.2 方差和标准差 一、方差(Variance)和标准差(Standard Deviation)的定义
方差和标准差 一、方差(Variance)和标准差(Standard Deviation)的定义 将离均差平方和(Sum of Squares of Deviation from Mean,SS)除以观察例数N,就得到方差: 方差越大,数据分布离散程度越大。 对于样本数据而言,方差的计算公式为: 将方差开方,就得到标准差。对于同性质的数据来说,标准差越小,表明数据的变异程度越小,即数据越整齐,数据的分布范围越集中;标准差越大,表明数据的变异程度越大,即数据越参差不齐,分布越分散。 二、方差和标准差的适用范围: 方差和标准差的适用范围应当是正态分布。
和标准差(Standard Deviation)的定义. 将离均差平方和(Sum of Squares of Deviation from Mean,SS)除以观察例数N,就得到方差: 方差越大,数据分布离散程度越大。 对于样本数据而言,方差的计算公式为: 将方差开方,就得到标准差。对于同性质的数据来说,标准差越小,表明数据的变异程度越小,即数据越整齐,数据的分布范围越集中;标准差越大,表明数据的变异程度越大,即数据越参差不齐,分布越分散。 二、方差和标准差的适用范围: 方差和标准差的适用范围应当是正态分布。")
142
4.3.3 百分位数、四分位数与四分位数间距 分位差是对极差指标的一种改进,是从变量数列中剔除了一部分极端值后重新计算的类似于极差的指标。常用的分位差有四分位差、十分位差、百分位差。 一、分位数 分位数:是一种位置指标,用PX表示。一个百分位数PX将一组观测之分为两部分,理论上有x%的观测值比它小,(100-x)%的观测值比它大。 四分位数(quartile)、十分位数(decile)、百分位数(percentile),他们分别是用3个点、9个点、99个点将数据4等分、10等分和100等分后各分位点上的值。
%的观测值比它大。 四分位数(quartile)、十分位数(decile)、百分位数(percentile),他们分别是用3个点、9个点、99个点将数据4等分、10等分和100等分后各分位点上的值。")
143
二、四分位数 四分位数:实际上是三个数值的总称,分别是P25、P50、P75分位数。 很显然,中间的分位数是中位数,因此通常所说的四分位数是指 第一个四分位数(下四分位数)和第三个四分位数(上四分位数)。 上下四分位数的差值称为四分位数间距: QR=Q3-Q1

144
4.3.4 变异系数 当需要比较两组数据离散程度大小的时候,往往直接使用标准差来进行比较并不合适。这可以被分为两种情况:
(1)测量尺度相差太大; (2)数据量纲不同。 在以上情形中,就应当消除测量尺度和量纲的影响,而变异系数(Coefficient of Variance),它是标准差和其平均数的比率。
测量尺度相差太大; (2)数据量纲不同。 在以上情形中,就应当消除测量尺度和量纲的影响,而变异系数(Coefficient of Variance),它是标准差和其平均数的比率。")
145
4.4 连续变量统计描述实例 4.4.1 数据背景介绍 4.4.2 使用Explore过程进行分析
探索分析是对数据进行初步的观察分析,主要的分析项目有: 观察数据的分布特征:可通过绘制箱图和茎叶图等图形直观地反映数据的分布形式和数据的一些规律性,包括考察数据中是否存在异常值等。 正态分布检验:检验数据是否服从正态分布。 方差齐性的检验:用Levene检验比较各组的方差是否相等。

146
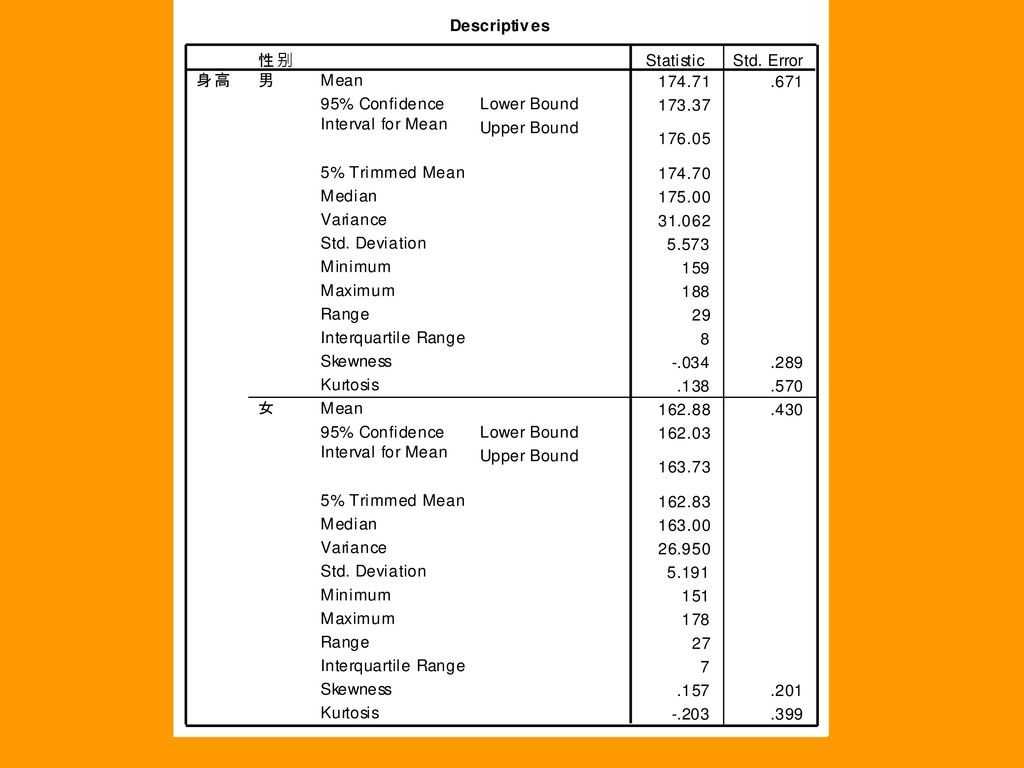
一、分析操作 1、单击Analyze->Descriptive statistics->Explore,打开Explore主对话框: (1)从左侧的变量列表中选出变量”身高”,送入Dependent List栏。 (2)选择”性别”作为因子变量,送入Factor List栏。有了因子变量,SPSS会把所有的观测个体按照因子变量的取值分成若干各组,再分组考察Dependent List中的各个变量,如果不选择因子变量,SPSS会对全部观测来做探索分析。 (3)在Display栏中选择输出项,依次是Both选择项,输出图形与描述统计量(系统默认),只输出描述统计量和只输出图形。本例中选择默认项。
选择 性别 作为因子变量,送入Factor List栏。有了因子变量,SPSS会把所有的观测个体按照因子变量的取值分成若干各组,再分组考察Dependent List中的各个变量,如果不选择因子变量,SPSS会对全部观测来做探索分析。 (3)在Display栏中选择输出项,依次是Both选择项,输出图形与描述统计量(系统默认),只输出描述统计量和只输出图形。本例中选择默认项。")
147
(1)Descriptives基本统计描述。同时指定均值的置信区间的置信度,系统默认为95%。
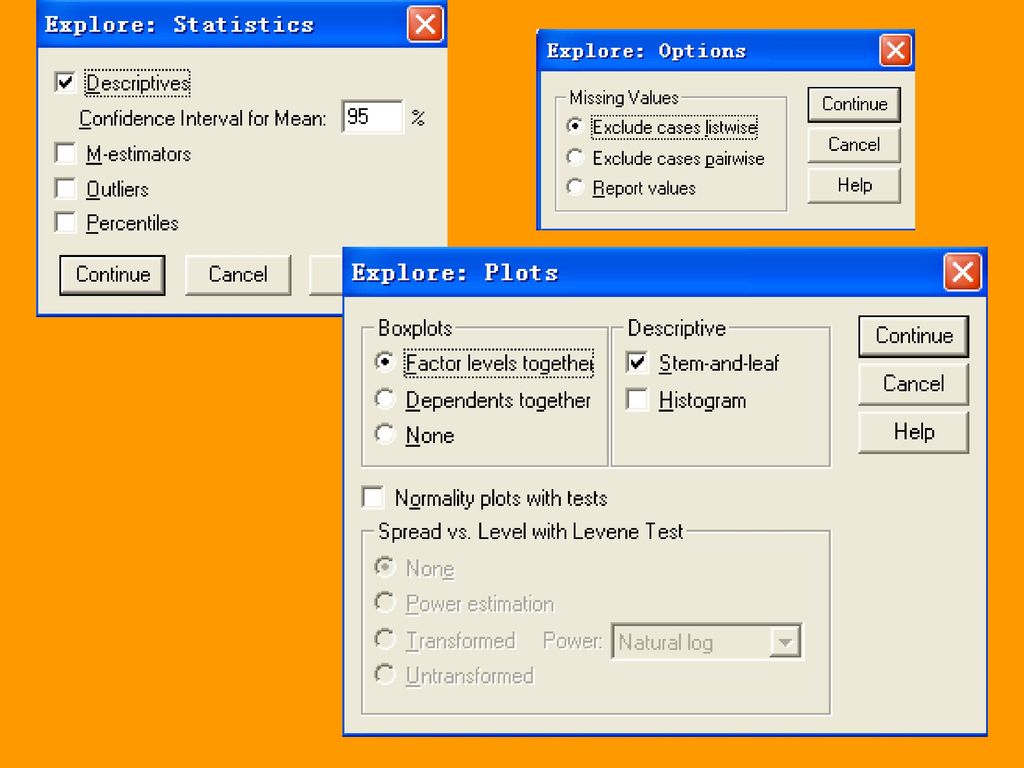
2、单击Statistics统计量按钮,打开Statistics对话框,选择统计输出量。 (1)Descriptives基本统计描述。同时指定均值的置信区间的置信度,系统默认为95%。 (2)M-估计(M估计在计算时对所有观测量赋予权重,随观测量距分布中心的远近而变化)。 (3)Outliers输出分析数据中五个最大值和五个最小值。 (4)Percentiles输出百分数。
Descriptives基本统计描述。同时指定均值的置信区间的置信度,系统默认为95%。 (2)M-估计(M估计在计算时对所有观测量赋予权重,随观测量距分布中心的远近而变化)。 (3)Outliers输出分析数据中五个最大值和五个最小值。 (4)Percentiles输出百分数。")
148
3、单击Plots 图形按钮,打开Plots对话框。
(1)Boxplot 箱图选择栏 Factor levels together因变量按因素水平分组(系统默认); Dependents together 所有因变量生成一个并列箱图(本例中选择项);None不显示箱图。 (2)Descriptive 描述图形栏 Stem-and-leaf 茎叶图Histogram 直方图 (3)Normality plots with test(复选项),正态分布检验并输出Q-Q图。 (4)Spread vs level with Levene Test栏,对所有的散布—层次图,同时输出回归直线的斜率以及方差齐性的Levenes检验。 None:不产生回归直线的斜率和方差齐性检验; Power Estimation转换幂值估计(对每组数据产生一个中位数自然对数及四个分位数的自然对数的散点图)选项; Transformed 变换原始数据选择项; Untransformed不变换变换原始数据选择项。
Boxplot 箱图选择栏. Factor levels together因变量按因素水平分组(系统默认); Dependents together 所有因变量生成一个并列箱图(本例中选择项);None不显示箱图。 (2)Descriptive 描述图形栏. Stem-and-leaf 茎叶图Histogram 直方图. (3)Normality plots with test(复选项),正态分布检验并输出Q-Q图。 (4)Spread vs level with Levene Test栏,对所有的散布—层次图,同时输出回归直线的斜率以及方差齐性的Levenes检验。 None:不产生回归直线的斜率和方差齐性检验; Power Estimation转换幂值估计(对每组数据产生一个中位数自然对数及四个分位数的自然对数的散点图)选项; Transformed 变换原始数据选择项; Untransformed不变换变换原始数据选择项。")
149
4、单击Option按纽,打开Option对话框如图所示。可选择缺失值的处理方式,SPSS提供三种处理方式:
(1)Exclude cases listwies 剔除带缺失值的观测量(系统默认)。 (2)Exclude cases pairwise 剔除带缺失值的观测量时还一并剔除与缺失值有成对关系的观测量。 (3)Report values 输出频数表时同时输出缺失值。 5、单击OK,得到相应的输出结果如表所示。
Exclude cases listwies 剔除带缺失值的观测量(系统默认)。 (2)Exclude cases pairwise 剔除带缺失值的观测量时还一并剔除与缺失值有成对关系的观测量。 (3)Report values 输出频数表时同时输出缺失值。 5、单击OK,得到相应的输出结果如表所示。")
150
二、基本的分析结果

152
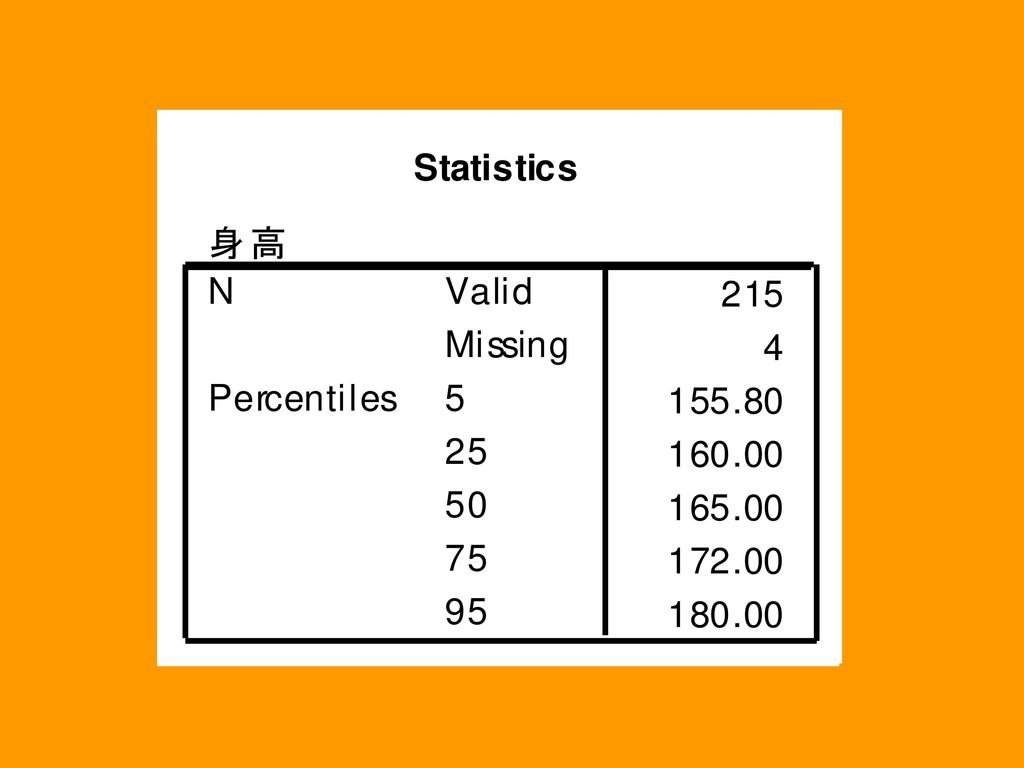
三、输出百分位数和极端值列表

154
身高 Stem-and-Leaf Plot for
sex= 男 Frequency Stem & Leaf Stem width: Each leaf: case(s)
")
155
箱图中,最底部的水平线段是数据的最小值(奇异点除外),顶部的水平线段是数据的最大值(奇异点除外),中间矩形箱子的底所在位置是数据的第一个四分位数(即25%分位数),箱子顶部所在位置是数据的第三个四分位数据(即75%分位数)。箱子中间的水平线段刻画的是数据的中位数(即50%分位数)。
,顶部的水平线段是数据的最大值(奇异点除外),中间矩形箱子的底所在位置是数据的第一个四分位数(即25%分位数),箱子顶部所在位置是数据的第三个四分位数据(即75%分位数)。箱子中间的水平线段刻画的是数据的中位数(即50%分位数)。")
156
4.4.3使用其他过程过程进行分析 一、Descriptive过程的结果 二、Frequencies过程的结果

158
4.5 连续性变量的参数估计 根据样本数据对总体的客观规律性作出合理估计的过程被称为统计推断(Statistical Inference),它可以被分为参数估计和假设检验两大类。 4.5.1 正态分布 一、正态分布的定义 若连续性随即变量X的概率分布密度函数为 则称随机变量X服从正态分布(Normal Distribution)
")
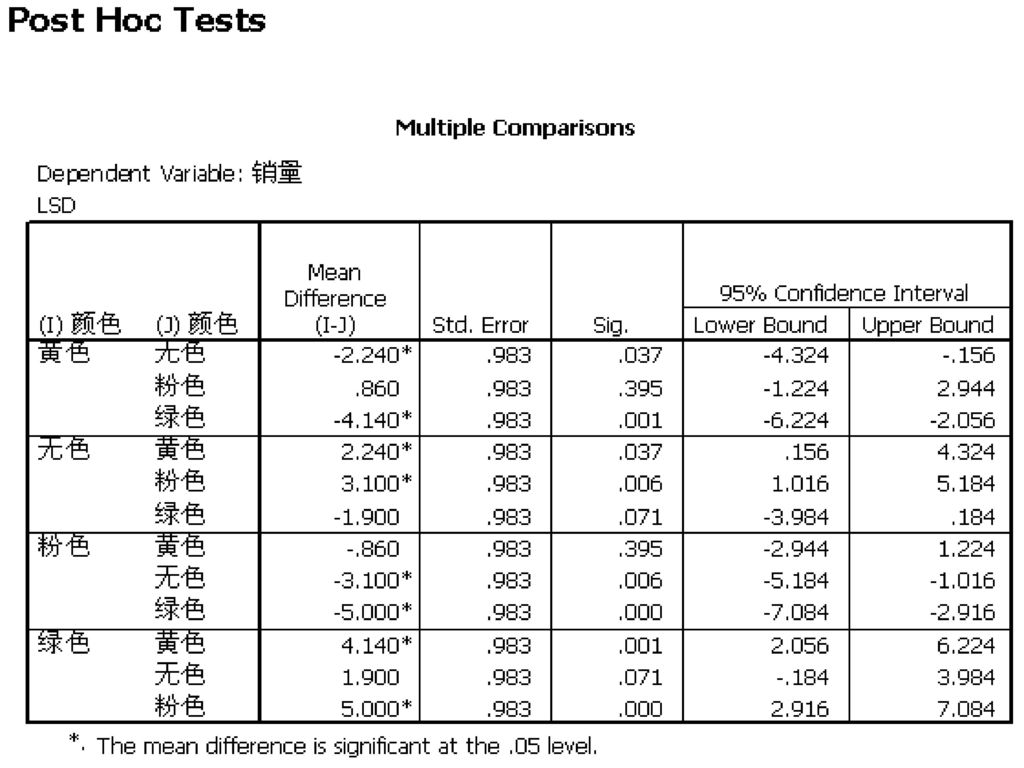
159
二、正态分布的特征 (1)正态分布是一条对称曲线,关于均数对称,因此均数被称为正态分布的位置参数。 (2)曲线是单峰,在均值出达到最高点。
(3)正态分布曲线的尖削与标准差有关。因此标准差被称为正态分布曲线的尺度参数。 (4)曲线无论向左或向右延伸,都越来越接近横轴,但不会与横轴相交,以横轴为渐近线。 (5)约68%的个体的取值与平均数在距离一个标准差之内。 (6)约95%的个体取值与平均数的距离在1.96个标准差之内。 (7)99%个体的取值与平均数的距离在2.58个标准差。
正态分布曲线的尖削与标准差有关。因此标准差被称为正态分布曲线的尺度参数。 (4)曲线无论向左或向右延伸,都越来越接近横轴,但不会与横轴相交,以横轴为渐近线。 (5)约68%的个体的取值与平均数在距离一个标准差之内。 (6)约95%的个体取值与平均数的距离在1.96个标准差之内。 (7)99%个体的取值与平均数的距离在2.58个标准差。")
160
三、标准正态分布(Standard Normal Distribution)
将原来的正态分布转换为标准正态分布。 在SPSS中的Descriptive过程可以将原变量转换为标准正态分布的得分,只需要选中主对话框左下角的Save standardized values as variables 复选框即可。

161
四、偏度和峰度 (1)偏度(Skewness):偏度是用来描述变量取值分布形态的统计量,只分布不对称的方向和程度。样本偏度系数:
偏态的方向指的应当是长尾的方向,而不是高峰的位置。

162
(2)峰度(Kurtosis):峰度用来描述变量取值分布形态陡缓的统计量,是指分布图形的的尖削程度或峰凸程度。样本的峰度系数:
峰度(Kurtosis):峰度用来描述变量取值分布形态陡缓的统计量,是指分布图形的的尖削程度或峰凸程度。样本的峰度系数:")
163
4.5.2 参数的点估计 参数的点估计就是选定一个适当的样本统计量作为参数的估计量,并计算出估计值。
对于所选统计量是否适于作参数估计量,有无偏性、一致性和有效性三个评选标准。 无偏性是指虽然估计量的值不全等于参数,但应在真实值附近摆动。 一致性是指样本容量越大,估计值离真实值的差异应当越小。 有效性是指如果两个统计量都符合上述要求,则应当选取误差更小的一个作为估计值。 一、矩法 在许多种情况下,样本统计量本身往往就是相应的总体参数的最佳估计,此时就可以直接取相应的样本统计量作为总体参数的点估计。

164
二、极大似然估计法 该方法的原理是在已知总体的分布,但未知其参数值时,在待估参数的可能取值范围内进行搜索,使似然函数值最大的那个数值为极大似然估计值。 三、稳健估计值 稳健估计值的是该统计量具有稳健性,当数据存在异常值时受影响较小,而且对大部分的分布而言都很好。

165
文件估计有M估计、R估计等不同方法。 SPSS中数出的M估计量有4种,它们分别是Huber、Andrews、Hampel和Tukey所提出的,实际上就是所用的函数不同。一般而言,Huber适用于数据接近正态分布的情况,另外三种则适用于数据中许多异常值的情况。如果M估计量里平均数和中位数较远,则数据中可能存在异常值。此时,应该用M估计量替代平均数以反映集中趋势。。

166
4.5.3 参数的区间估计 一、标准误 标准误就是用来描述参数估计值可能离真实值究竟有多远的统计量。 二、区间估计的计算
结合样本统计量和标准误可以确定一个具有较大的可信度包含总体参数的区间,该区间称为总体参数的1-a可信区间或置信区间(Confidence Interval)。 对于任意可信度的区间情况,总体均值在100(1-a)%可信区间为:
。 对于任意可信度的区间情况,总体均值在100(1-a)%可信区间为:")
168
第5章 分类变量的统计描述与参数估计 5.1分类变量的统计描述概述 5.1.1分类变量的统计描述指标体系 一、频数分布情况描述
根据类别的有序性,分类变量可以分为有序分类变量(Ordinal Variable)和无序分类变量(Nominal Variable)。 5.1分类变量的统计描述概述 5.1.1分类变量的统计描述指标体系 一、频数分布情况描述 各个类别的样本数和所占比例分别称为频数(绝对频数)和百分比(构成比)。 累计频数是指本类别及较低类别出现的次数之和,累计百分比则是指本类别及较低类别出现的次数之和占总次数的百分比。
和无序分类变量(Nominal Variable)。 5.1分类变量的统计描述概述 分类变量的统计描述指标体系. 一、频数分布情况描述. 各个类别的样本数和所占比例分别称为频数(绝对频数)和百分比(构成比)。 累计频数是指本类别及较低类别出现的次数之和,累计百分比则是指本类别及较低类别出现的次数之和占总次数的百分比。")
169
二、集中趋势的描述 三、使用相对数进行深入描述 当集中趋势显著时,用众数(Mode)作为总体的代表值。
所谓众数,使之出现次数最多的那个数。如果只有一个众数称为单众数,多于一个的称为复众数。 三、使用相对数进行深入描述 (1)比(Ratio):比指的是两个有关指标之比A/B,用于反映两个指标在数量/频数上的大小关系。
比(Ratio):比指的是两个有关指标之比A/B,用于反映两个指标在数量/频数上的大小关系。")
170
(2)构成比(Proportion) 分观察对象为K部分(A1、A2、……Ak),其中某一个/多个部分的例数占总例的比例未构成比,它描述某个事物内部各构成部分所占的比重。 (3)率(Rate) 率是一个时间概念,或者说具有速度、强度含义的指标,用于说明某个时间发生的频率或强度。
构成比(Proportion) 分观察对象为K部分(A1、A2、……Ak),其中某一个/多个部分的例数占总例的比例未构成比,它描述某个事物内部各构成部分所占的比重。 (3)率(Rate) 率是一个时间概念,或者说具有速度、强度含义的指标,用于说明某个时间发生的频率或强度。")
171
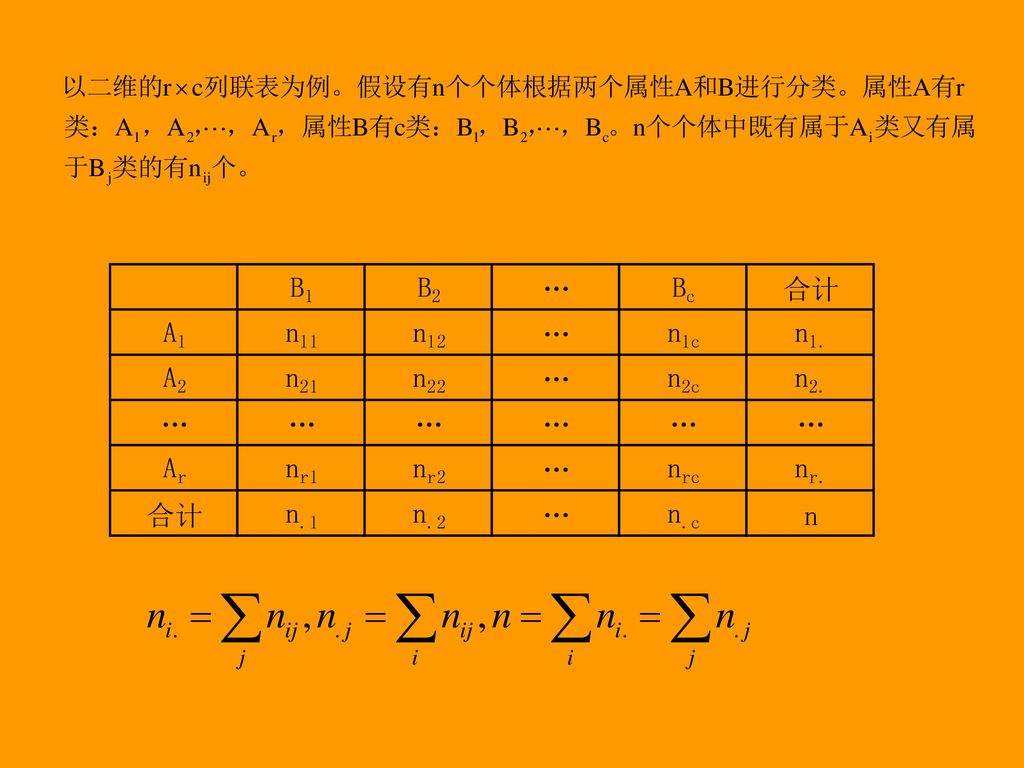
5.1.2 分类变量的联合描述 当一共有两个分类变量时,这汇总因分类变量的各类别交叉而成的复合频数表被称为行*列表,也称列联表。
当观察的现象与两个因素有关时,如某种服装的销量受价格和居民收入影响;某种产品的生产成本受原材料价格和产量的影响等等,交叉列联表分析可以比较好的反映出两个因素之间有无关联性,两因素与现象之间的相关关系。因此,数据交叉列联表分析主要包括两个基本任务: 1、根据收集的样本数据,产生二维或多维交叉列联表; 2、在交叉列联表的基础上,对两两变量间是否存在关联性进行检验。

173
5.2分类变量的统计描述实例 5.2.1使用Frequencies过程输出频数表 具体操作:
Analysis Descriptive Statistics Frequencies

175
1、打开数据,单击AnalyzeDescriptive Statistics Crosstabs对话框。
2、如果是二维列联表分析,可以将行变量选择进入Row(s)中,将列变量选择进入Column(s)框中。如进行三维以上的列联表,可以将其它变量作为控制变量选到Layer框中。多控制变量可以是同层次的也可以是逐层叠加的。
中,将列变量选择进入Column(s)框中。如进行三维以上的列联表,可以将其它变量作为控制变量选到Layer框中。多控制变量可以是同层次的也可以是逐层叠加的。")
176
3、Display clustered bar chart选择项,可以指定绘制各变量交叉频数分布柱形图。Suppress table表示不输出列联表,只有在分析行列变量间关系时选择此项。此例中不选择这一项。 4、单击Cell按纽,打开Crosstabs:Cell Display对话框,如图所示。从对话框中指定列联表单元格中的输出内容。在Counts框中选择Observed 观察值(系统默认)或Expected期望频数。在Percentages框内选择Row行百分比、Column列百分比及Total总百分比。在Residuals框中选择输出残差。其中Standardize为标准化残差。 Adj. standardize 为修正的标准化残差。
或Expected期望频数。在Percentages框内选择Row行百分比、Column列百分比及Total总百分比。在Residuals框中选择输出残差。其中Standardize为标准化残差。 Adj. standardize 为修正的标准化残差。")
178
5.3 多选题的统计描述 5.3.1 多选题的描述指标体系 在多选题分析中比较特别的描述指标有: (1)应答人数:是指选择了本项人数。
(2)应答人数百分比(Percent of Cases):选择该项的人占总人数的比例。 (3)应答人次:选择本选项的人次。 (4)应答次数百分比(Percent of Responses):在作出的选择中,选择该项的人数占总次数的比例。
应答人数百分比(Percent of Cases):选择该项的人占总人数的比例。 (3)应答人次:选择本选项的人次。 (4)应答次数百分比(Percent of Responses):在作出的选择中,选择该项的人数占总次数的比例。")
179
5.3.2 分析实例 操作步骤:Analyze Multiple Response Frequencies 1、Define Sets过程
该过程指定变量组成一个多重响应或多重两分数集,并应用于频数表和交叉列表。 2、Frequencies过程 该过程对定义的多重响应或多重两分数提供一个频数表。 3、Crosstabs过程 该过程提供带有另一种变量的,已定义的多重或多重两分数据集交叉表。

180
5.4 分类变量的参数估计 5.4.1 二项分布的参数估计 一、二项分布
二项分布又称为贝努里(Bernoulli)分布,是一种具有广泛应用的离散型随机变量的概率分布。二项分布研究的是试验仅有两种结果的分布(这种试验称为贝努里试验),如某产品质量合格与不合格等。其定义为:设有n 次试验,各次试验是相互独立的,每次试验某事件出现的概率都是p,某事件不出现的概率都是1-p,记为q,则对于某事件出现k(k=0,1,2,⋯,n)次的概率分布为:
分布,是一种具有广泛应用的离散型随机变量的概率分布。二项分布研究的是试验仅有两种结果的分布(这种试验称为贝努里试验),如某产品质量合格与不合格等。其定义为:设有n 次试验,各次试验是相互独立的,每次试验某事件出现的概率都是p,某事件不出现的概率都是1-p,记为q,则对于某事件出现k(k=0,1,2,⋯,n)次的概率分布为:")
181
当研究对象属于二项总体时,可以用二项分布来检验假设,判断所抽取的样本是否来自具有既定值的总体。其检验步骤如下:
二、二项分布检验(Binomial Test) 当研究对象属于二项总体时,可以用二项分布来检验假设,判断所抽取的样本是否来自具有既定值的总体。其检验步骤如下: 1、提出假设 2、计算统计量值和p 值 3、根据p 值作出统计判断。 [例]掷一枚球类比赛用的挑边器40 次,出现A 面和B 面在上的次数。如表所示,试问这枚挑边器是否均匀?
 当研究对象属于二项总体时,可以用二项分布来检验假设,判断所抽取的样本是否来自具有既定值的总体。其检验步骤如下: 1、提出假设. 2、计算统计量值和p 值. 3、根据p 值作出统计判断。 [例]掷一枚球类比赛用的挑边器40 次,出现A 面和B 面在上的次数。如表所示,试问这枚挑边器是否均匀?")
182
解:(1)在SPSS 中输入表中的数据(变量名为Y)。
选择主菜单的[Analyze]=> [Nonparametric Tests]=> [Binomial Test]。 (2)显示如图所示的[Binomial Test(二项检验)]主对话框,把Y选入[Test Variable],其它选项采用默认值。 (3)单击主对话框中的[OK]按钮,输出结果如下: 从结果可以看出,p=0.017<α=0.05,认为该挑边器不是均匀的。
显示如图所示的[Binomial Test(二项检验)]主对话框,把Y选入[Test Variable],其它选项采用默认值。 (3)单击主对话框中的[OK]按钮,输出结果如下: 从结果可以看出,p=0.017<α=0.05,认为该挑边器不是均匀的。")
183
第6章 数据报表的呈现 6.1 spss报表概述 6.1.1 spss中的报表功能 1、base模块 2、original模块
3、Custom Tables模块 6.1.2 报表的基本绘制步骤

184
6.2表格入门 6.2.1 表格基本框架 行(Row)指的是形成表格的横行元素;列(Column)指的是形成表格纵列的元素;行、列元素相交就会形成一个最简单的二维表,行、列元素不同取值的组合就确定了一个单元格(Cell)。层(Layer)指的是表格中的第三个维度。
指的是形成表格的横行元素;列(Column)指的是形成表格纵列的元素;行、列元素相交就会形成一个最简单的二维表,行、列元素不同取值的组合就确定了一个单元格(Cell)。层(Layer)指的是表格中的第三个维度。 .")
186
6.2.3单元格的数据类型 1、分类变量. 包括了名义型和有序尺度两大类。 2、连续变量 包括间距尺度和比率尺度两大类。
(1)集中趋势指标:均数、中位数、众数、最大值、最小值。 (2)离散趋势指标:全距、标准误、标准差、方差。 (3)百分位数:第5、25、75、95、99百分位数其任一指定的百分位数。 (4)百分比:按相应合计方向当前变量的行、列、层、表格合计百分比。 (5)其他:例数、有效例数、综合等。 3、汇总项
集中趋势指标:均数、中位数、众数、最大值、最小值。 (2)离散趋势指标:全距、标准误、标准差、方差。 (3)百分位数:第5、25、75、95、99百分位数其任一指定的百分位数。 (4)百分比:按相应合计方向当前变量的行、列、层、表格合计百分比。 (5)其他:例数、有效例数、综合等。 3、汇总项.")
187
6.2.4 集中基本表格类型 1、叠加表(Stacking)
叠加表指的是在同一张表格中对两个变量进行描述,或者说表格中有一个维度的元素是由两个以上的变量构成。 2、交叉表(Crosstabulation) 它的两个维度都是由两个分类变量的各类别构成。 3、嵌套表(Nesting) 两个变量被放置在同一个表格维度中,即该维度是由两个变量的各种类别组合而成。 4、多层表(Layers) 如果制定了层元素,表格就由二维扩展到三维,即多层表。 5、复合表格
 它的两个维度都是由两个分类变量的各类别构成。 3、嵌套表(Nesting) 两个变量被放置在同一个表格维度中,即该维度是由两个变量的各种类别组合而成。 4、多层表(Layers) 如果制定了层元素,表格就由二维扩展到三维,即多层表。 5、复合表格.")
188
6.3 用Original Tables模块制表 6.3.1 功能简介 (1)Multiple Response Sets
(2)Basic Tables (3)General Tables (4)Multiple Response Tables (5)Tables of Frequencies
Basic Tables. (3)General Tables. (4)Multiple Response Tables. (5)Tables of Frequencies.")
189
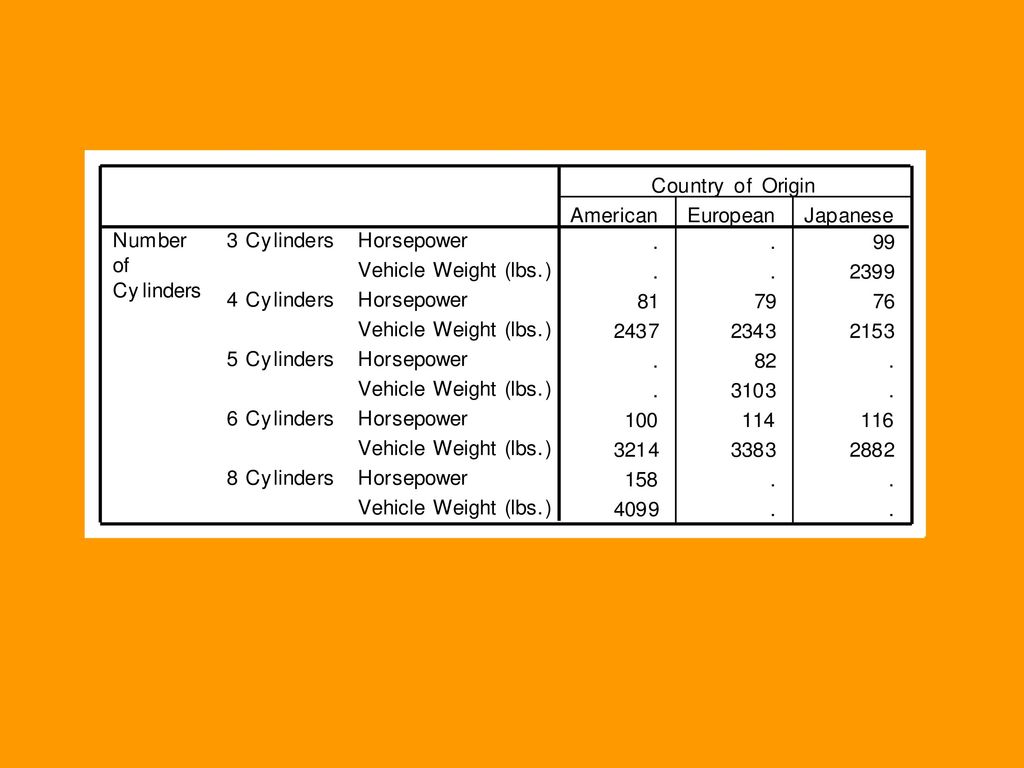
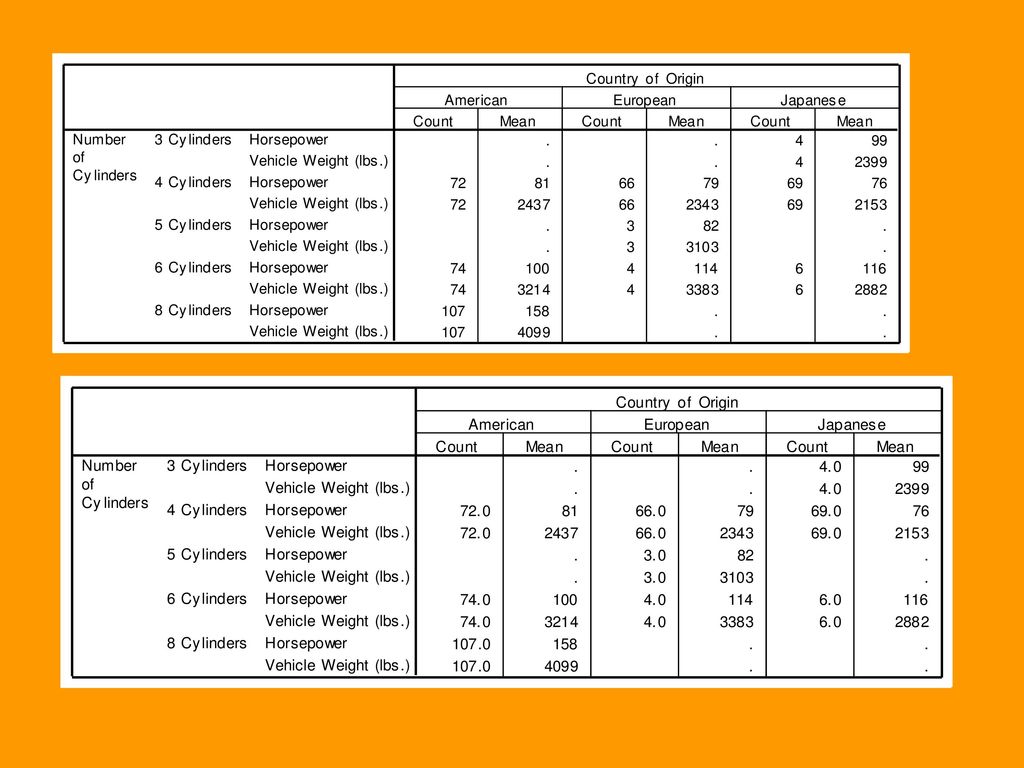
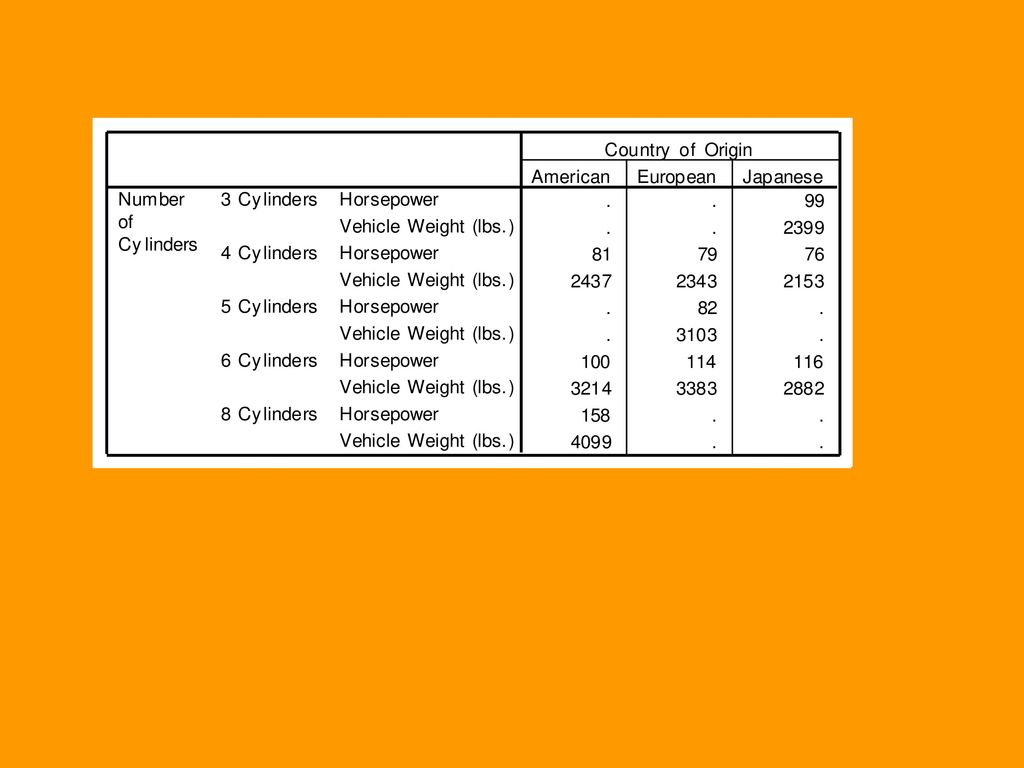
6.3.2 Basic Tables过程 例2:请将数据文件Cars.sav中的汽车数据分为不同的产地和气缸数计算其引擎功率、引擎重量的频数和均数,用适当的报表形式给出,并要求给出类别合计。

190
1、表格框架的设定

192
2、统计量的添加与格式的设置

194
3、添加汇总项

195
4、空单元格的设置

196
5、添加标题与说明文字

197
6、标签排列格式的调整

198
7、最终完成表格绘制

199
General Tables 过程 1、表格框架的设定

201
2、添加汇总项

202
6.4用Custom Tables模块自由制作 6.4.1操作主界面

203
6.4.2 简单实例分析 1、表格框架的绘制:选中左侧列表中变量的图标,按下左键不放,移动鼠标,此时鼠标携带着变量图标一起移动。将其拖入画布内,当鼠标接近行/列边框时,相应地边框会变红,表明该变量已经找到位置。

204
2、连续变量统计量的设置 (1)选中画布上的Horsepower图标,此时界面左下方Define框组中的Summary Statistics 浮动钮已经可以用,单击该钮后即弹出连续变量汇总统计量设定的对话框图。 (2)如果计算某一个统计量,使用连接两框的统计按钮将其移入右侧。例如如果希望先计算频数,则在用最右侧的上下移动钮将其移动到均数上方即可。
如果计算某一个统计量,使用连接两框的统计按钮将其移入右侧。例如如果希望先计算频数,则在用最右侧的上下移动钮将其移动到均数上方即可。")
205
3、分类变量汇总项的设置 选择分类变量Cylinder,则Define框组中的该浮动按钮可用,单击后弹出如下界面:

206
Totals and Subtotals Appear框组:用于设定汇总和子项汇总的标签是在左上部显示还是在右下部显示。
Show框组:用于设定某项是否显示,Ttotal选项用于要求计算汇总栏,Missing选项要求将用户定义的的缺失值按缺失值处理方式处理,该选择不影响系统缺失。Empty选项用于控制是否在表格中输出无案例的类别。而最右侧的Other选项则控制是否显示未提供值标签的类别。 Exclude框:用于指定部显示某些类别。 Display框组:直观的显示该分类变量各类的显示方式、顺序、汇总等。

207
4、显示标签的调整 将表格画布切换为正常视图,然后在Cylingder的变量名标签出单击右键,则弹出相应的右键菜单。

208
6.4.3 其他选项卡功能 1、Test Statistics功能

209
2、Titles 选项卡

210
3、Options选项卡

211
6.5 表格的编辑 6.5.1 基本编辑操作 1、两种不同的编辑窗口 (1)嵌套窗口编辑模式
选中相应表格使用右键菜单上的SPSS Pivot table Object Edit,或者双击鼠标左键。 (2)单独窗口编辑模式 选中相应表格使用右键菜单上的SPSS Pivot table Object Ope。,
单独窗口编辑模式. 选中相应表格使用右键菜单上的SPSS Pivot table Object Ope。,")
212
2、表格元素的选择方式

213
3、单元格内容编辑

214
6.5.2主要编辑菜单功能介绍 1、Edit菜单

215
2、format菜单 对单元格的字体、阴影、颜色等属性修改 对单元格的字体、阴影、颜色等属性修改 对表格进行各个选项的精细设置
选用新的表格模版 表格的行、列自动按内容多少调整为最小。 将列标题纵向显示

216
3、View菜单和Insert菜单

217
4、Pivot菜单

218
6.5.3 表格属性的详细设置 单击菜单Format到Table Properties即可弹出表格属性对话框。 (1)general选项卡
general选项卡")
219
(2)Footnotes选项卡
Footnotes选项卡")
220
(3)Cell Formats选项卡
Cell Formats选项卡")
221
(4)Borders选项卡
Borders选项卡")
222
6.6参数估计

223
6.6 .1参数估计的一般问题 一、估计量与估计值 所谓参数估计(Parameter estimation)就是用样本统计量去估计总体的参数。 如果我们将总体参数笼统地用一个符号 来表示,参数估计也就是如何用样本统计量来估计总体参数 。 用于估计 的样本统计量用符号 表示,我们把 称为统计量(estimator)。 估计值(estimated value)就是用来估计总体参数时计算出来的估计量的具体数值。
。 估计值(estimated value)就是用来估计总体参数时计算出来的估计量的具体数值。")
224
二、点估计与区间估计 所谓点估计就是由样本x1,x2,…xn确定一个统计量
参数的估计方法有点估计(point estimate)和区间估计(interval estimate)两种。 (一)点估计 所谓点估计就是由样本x1,x2,…xn确定一个统计量 用它来估计总体的未知参数,称为总体参数的估计量。当具体的样本抽出后,可求出样本统计量的值。用它作为总体参数的估计值,称作总体参数的点估计。
和区间估计(interval estimate)两种。 (一)点估计. 所谓点估计就是由样本x1,x2,…xn确定一个统计量. 用它来估计总体的未知参数,称为总体参数的估计量。当具体的样本抽出后,可求出样本统计量的值。用它作为总体参数的估计值,称作总体参数的点估计。")
225
某连续生产线上生产的灯泡的使用寿命X服从正态分布N(μ,δ2),其中μ和δ2是未知总体参数。从中随机抽取5只灯泡,测得使用寿命分别为1529小时、1513小时、1600小时、1527小时、1111小时。试估计μ和δ2。 从总体中抽取一个样本,构造适当的统计量 ,来估计对应的总体参数 。

226
无偏性是指估计量的抽样分布的数学期望等于被估计的总体参数。
评价点估计量优劣的标准 : 1、无偏性(unbiasedness) 无偏性是指估计量的抽样分布的数学期望等于被估计的总体参数。 偏差 参数θ等于抽样分布的均值 参数θ不等于抽样分布的均值 (无偏估计量) (有偏估计量)
 无偏性是指估计量的抽样分布的数学期望等于被估计的总体参数。 偏差. 参数θ等于抽样分布的均值. 参数θ不等于抽样分布的均值. (无偏估计量) (有偏估计量)")
227
2、有效性(Efficiency)
")
228
的抽样分布 的抽样分布 参数

230
自正态总体抽样时,总体均值与总体中位数相同,而中位数的标准误差大约比均值的标准误差大25%。因此,样本均值更有效。
的抽样分布 的抽样分布

231
3、一致性(consistency) 两个不同容量样本的点估计量的抽样分布
 两个不同容量样本的点估计量的抽样分布")
232
(二)区间估计 区间估计是在点估计的基础上,给出总体参数估计的一个区间范围,该区间通常是由样本统计量加减抽样误差得到的。 的样本 置信度1-α 使得
区间估计 区间估计是在点估计的基础上,给出总体参数估计的一个区间范围,该区间通常是由样本统计量加减抽样误差得到的。 的样本 置信度1-α 使得")
233
6.6.2 一个总体参数的区间估计 一、总体均值的区间估计 (一)总体方差已知时总体均值的区间估计
当总体服从正态分布且方差已知时,或者总体不是正态分布但大样本时,样本均值的抽样分布均为正态分布,期数学期望为总体均值,方差为 。而样本均值经过标准化以后的随机变量则服从标准正态分布。

234
显著性水平 置信度 显著性水平α下,μ在1- α置信水平下的置信区间:

235
例题: 一批零件的长度服从正态分布,从中随机抽取9件,测得其平均长度为21. 4毫米。已知该批零件长度的标准差为0
例题: 一批零件的长度服从正态分布,从中随机抽取9件,测得其平均长度为21.4毫米。已知该批零件长度的标准差为0.15毫米,试以95%的把握程度,估计该批零件平均长度的存在区间。

236
例题: 某大学从该校学生中随机抽取100人,调查到他们平均每天参加体育锻炼为26分钟。试以95%的置信水平估计该大学全体学生平均每天参加体育锻炼的时间(已知总体方差为36)。
。")
237
例题:一家保险公司收集到36个投保人组成的随机样本,得到每个投保人的年龄如表:
23 35 39 27 36 44 42 46 43 31 33 53 45 54 47 24 34 28 40 49 38 48 50 32 试建立投保人年龄的90%置信区间。

238
(二)总体方差未知时总体均值的区间估计 如果总体服从正态分布,则无论样本容量如何,样本均值的抽样分布都服从正态分布。这时,只要总体方差已知,即使在小样本的情况下,也可以建立总体均值的置信区间。但是,如果总体方差未知,而且是在小样本的情况下,则需要用样本方差替代总体方差,这时样本均值经过标准化以后的随机变量则服从自由度为(n-1)的t分布。
的t分布。")
239
显著性水平α下,μ的1- α置信区间: -3 -2 -1 1 2 3 0.0 0.1 0.2 0.3 0.4 标准正态分布 自由度为20的t-分布 自由度为10的t-分布

240
例题:已知某灯泡的寿命副总正态分布,现从一批灯泡中随机抽取16只,测得其寿命如下:
1510 1450 1480 1460 1520 1490 1530 1470 1500 试建立该批灯泡使用寿命95%的置信区间。

241
总体均值区间估计程序 是否为大样本 n≥30 是 否 σ值是否已知 总体是否近 似正态分布 是 否 是 否 σ值是否已知 是 否 用样本标准差s 估计δ 用样本标准差s 估计δ 将样本容量 增加到n≥30 以便进行区间 估计

242
二、总体比例的区间估计

243
显著性水平α下,P在1- α置信水平下的置信区间:

244
某企业在一项关于职工流动原因的研究中,从企业前职工的总体中随机抽选了200人组成一个样本。在对其进行访问时,有140说他们离开该企业是由于同管理人员不能融洽相处。试对由于这种原因而离开企业的人员的真正比率构造95%的置信区间。

245
三、总体方差的区间估计 自由度为5 自由度为2 自由度为10 显著性水平α下,σ2 的置信区间

246
对某种金属的10个样品所组成的一个随机样本作抗拉强度试验。从试验数据算出的方差为4,试求σ2 的95%值信区间。
0.025 0.025 =2.7044 = 自由度为9的χ2分布

247
四、样本容量的确定 允许误差(permissible)
一家广告公司想估计某类商店去年所花的平均广告费有多少。经验表明,总体方差为 。如置信度取95%,并要使估计值处在总体平均值附近500元的范围内,这家广告公司应取多大的样本? 用历史数据代替。若有若干个历史数据,应以较大者代替。 一家市场调研公司想估计某地区有彩色电视机的家庭所占的比率。该公司希望对 P 的估计误差不超过0.05,要求可靠程度为 95%,应取多大容量的样本? 总体方差最大值为0.5×0.5=0.25

248
关键术语 无放回抽样(sampling without replacement)一个元素一旦选入样本,就从总体中剔除,不能再次被选入 放回抽抽样(sampling with replacement)一个元素一旦被选入样本,仍被放回总体中。先前被选入的元素可能再次被抽到,并且在本样中可能出现多次 抽样分布(sampling distribution)样本统计量所有可能值构成的概率分布 点估计(point estimate)用做总体参数估计量的值。它是点估计量的具体的取值 点估计量(point estimator)提供总体参数点估计的样本统计量 标准误差(standard error)点估计量的标准差 中心极限定理(central limit theorem)当样本容量大的时候,用正态分布近似样本均值的分布和样本比率的抽样分布 区间估计(interval estimate)总体参数估计值的一个范围,确信该范围包括参数的值在内 抽样误差(sample error)无偏估计值(如样本均值)与所估计的总体值(如总体均值)之差的绝对值 置信水平(confidence level)与区间估计相联系的置信度 边际误差(margin error)置信区间中从点估计值中所加上或减去的值 t分布(t distribution) 概率分布的一族,当总体是正态或者近似正态概率分布,并且总体标准差未知情况下,对总体均值进行区间估计时常用到该分布 自由度(degrees of freedom)t 分布的参数,计算总体均值的区间估计中所用的t 分布的自由度为n-1,其中n是简单单随机样本的样本容量
样本统计量所有可能值构成的概率分布. 点估计(point estimate)用做总体参数估计量的值。它是点估计量的具体的取值. 点估计量(point estimator)提供总体参数点估计的样本统计量. 标准误差(standard error)点估计量的标准差. 中心极限定理(central limit theorem)当样本容量大的时候,用正态分布近似样本均值的分布和样本比率的抽样分布. 区间估计(interval estimate)总体参数估计值的一个范围,确信该范围包括参数的值在内. 抽样误差(sample error)无偏估计值(如样本均值)与所估计的总体值(如总体均值)之差的绝对值. 置信水平(confidence level)与区间估计相联系的置信度. 边际误差(margin error)置信区间中从点估计值中所加上或减去的值. t分布(t distribution) 概率分布的一族,当总体是正态或者近似正态概率分布,并且总体标准差未知情况下,对总体均值进行区间估计时常用到该分布. 自由度(degrees of freedom)t 分布的参数,计算总体均值的区间估计中所用的t 分布的自由度为n-1,其中n是简单单随机样本的样本容量.")
249
第7章 均值比较与方差检验 本章主要内容: 1、单个总体均值的 t 检验(One-Sample T Test);
2、两个独立总体样本均值的 t 检验(Independent-Sample T Test); 3、两个有联系总体均值均值的 t 检验(Paired-Sample T Test); 4、单因素方差分析(One-Way ANOVA); 5、双因素方差分析(General Linear ModelUnivariate)。 假设条件:研究的数据服从正态分布或近似地服从正态分布。 在Analyze菜单中,均值比较检验可以从菜单Compare Means,和General Linear Model得出。
; 3、两个有联系总体均值均值的 t 检验(Paired-Sample T Test); 4、单因素方差分析(One-Way ANOVA); 5、双因素方差分析(General Linear ModelUnivariate)。 假设条件:研究的数据服从正态分布或近似地服从正态分布。 在Analyze菜单中,均值比较检验可以从菜单Compare Means,和General Linear Model得出。")
250
7.1假设检验的基本问题 一、假设检验的基本思想 假设检验是除参数估计之外的另一类重要的统计推断问题。它的基本思想可以用小概率原理来解释。
所谓小概率原理,就是认为小概率事件在一次试验中几乎不可能发生。也就是说,如果对总体的某个假设是真实的,那么不利于或不能支持这一假设的小概率事件A在一次试验中是几乎不可能发生的;要是在一次试验中事件A竟然发生了,我们就有理由怀疑这一假设的真实性,拒绝这一假设。

251
拒绝 原假设 小概率 事件发生 接受 原假设 大概率 事件发生
假设检验的基本思想 拒绝 原假设 小概率 事件发生 前提: 承认 原假设 进行一次实验 接受 原假设 大概率 事件发生

252
根据样本观测值来判断一个有关总体的假设是否成立的问题,就是假设检验问题(hypothesis testing)。
某厂生产一种供出口的罐头,经验表明罐头的净重服从正态分布。标准规格是每罐净重250克,标准差是3克。现从生产线上随机抽取100罐进行检查,称得其平均净重251克。问这批罐头是否合乎规格净重? 250 250 假设总体服从均值为250,标准差3的正态分布 则样本均值服从均值为250,标准差0.3的正态分布

253
0.9545 249.4 250 250.6 251 样本均值服从均值为250,标准差0.3的正态分布

254
-2.00 2.00 3.33 样本均值服从均值为250,标准差0.3的正态分布

255
拒绝域 接受域 拒绝域 Z统计量 显著性水平 临界值 临界值 假设检验是对我们所关心的却又是未知的总体参数先作出假设,然后抽取样本,利用样本提供的信息,根据小概率原理对假设的正确性进行判断的一种统计推断方法。

256
二、假设的表达式 例:由统计资料得知,1989年某地新生儿的平均体重3190千克,现从1990年的新生儿中随机抽取100个,测得其平均体重为3210千克,问1990年的新生儿与1989年相比,体重有无显著差异。 原假设(null hypothesis)采用等式的方式,即 如果原假设不成立,就要拒绝原假设。在需要的另一个假设中做出选择,这个假设称为备择假设(alternative hypothesis)。备择假设表达式为:
采用等式的方式,即. 如果原假设不成立,就要拒绝原假设。在需要的另一个假设中做出选择,这个假设称为备择假设(alternative hypothesis)。备择假设表达式为:")
257
假设基本形式 H0:原假设,H1:备择假设 假设检验:运用统计理论对上述假设进行检验,在原假设与备择假设中选择其一。

258
显著性水平α对应犯拒真错误的概率,通常取α=0.05或α=0.01或α=0.0455 计算检验统计量的值
提出原假设和备择假设 作出统计决策 拒绝原假设,即这批罐头不符合规格净重。 确定检验统计量 某厂生产一种供出口的罐头,经验表明罐头的净重服从正态分布。标准规格是每罐净重250克,标准差是3克。现从生产线上随机抽取100罐进行检查,称得其平均净重251克。问这批罐头是否合乎规格净重? 规定显著性水平α 显著性水平α对应犯拒真错误的概率,通常取α=0.05或α=0.01或α=0.0455 计算检验统计量的值

259
p-值是一个概率值,它是用于确定是否拒绝H0的另一种方法。如果假定原假设为真,则p-值是所获得的样本结果至少与实测结果不同的概率值。

260
例题: 某商品标签上标明其重量至少为3公斤以上,现抽取36瓶该产品组成的一个简单随机样本,得其样本均值2.92公斤,已知总体标准差为0.18时,在显著性水平α=0.01的情况下检验其商品标签所标内容是否真实?

261
求解过程: (1)原假设H0:μ≥3,备择假设H1:μ<3 (2)检验统计量为: 代入数据得:
原假设H0:μ≥3,备择假设H1:μ<3 (2)检验统计量为: 代入数据得:")
262
(3)z=-2.67所对应的p值为0.0038 (4)0.0038<0.010,所以拒绝H0。
z=-2.67所对应的p值为 (4)0.0038<0.010,所以拒绝H0。")
263
接受或拒绝H0,都可能犯错误 三、假设检验的两类错误 I类错误——弃真错误,发生的概率为α( αerror)
II类错误——取伪错误,发生的概率为β( β error)
")
264
7.2 正态总体参数的假设检验 正态总体参数假设检验的步骤 第一步:建立原假设H0和备择假设H1。原假设应该是希望犯第Ι类错误概率小的假设。
7.2 正态总体参数的假设检验 正态总体参数假设检验的步骤 第一步:建立原假设H0和备择假设H1。原假设应该是希望犯第Ι类错误概率小的假设。 常用的假设形式 :

265
第二步:选择检验用的统计量。 z 检验 t 检验 常用 统计量 F检验

266
第三步:确定显著水平α的值,查相应的分布表得其临界值以及拒绝域。
第四步:进行显著性判别。

267
7.2.1一个正态总体的参数检验 在一个正态总体的参数检验中,用到的检验统计量主要有三个:Z统计量,t统计量, 统计量。Z统计量和t统计量常用于均值和比例的检验, 统计量则用于方差检验。 选择什么统计量进行检验需要考虑一些因素,这些因素主要有:总体的标准差是否已知,样本量的大小。

268
(一)总体标准差是否已知 总体 方差 检 验 统计量 μ=μ0 时检验 统计量的分布 假 设 拒绝域 σ2 已知 未知
总体标准差是否已知 总体 方差 检 验 统计量 μ=μ0 时检验 统计量的分布 假 设 拒绝域 σ2 已知 未知")
269
(二)样本量 总体标准差 已知 未知 Z统计量 样本容量 大 小 Z统计量 t统计量
样本量 总体标准差 已知 未知 Z统计量 样本容量 大 小 Z统计量 t统计量")
270
二、总体均值的检验 例题: 某厂加工一种零件,根据经验知道,该厂加工的零件的椭圆度渐近服从正态分布,其总体均值为0.081mm,总体标准差为0.025mm。今另换一种新机床进行加工,取200个零件进行检验,得到椭圆度均值为0.076mm。问新机床加工零件的椭圆度总体均值与以前有无显著差别。(α=0.05)
")
271
拒绝域 接受域 拒绝域

272
例题: 某批发商欲从厂家购进一批灯泡,根据合同规定,灯泡的使用寿命平均不能低于1000小时。已知灯泡使用寿命服从正态分布,标准差为20小时。在总体中随机抽取了100个灯泡,得其均值为960小时,批发商是否应该购进这批灯泡。

273
解一: 接受域 拒绝域

274
解二: 接受域 拒绝域

275
例题:电视机显像管批量生产的质量标准为平均使用寿命1200小时,标准差为300小时。某电视机厂宣称其生产的显像管质量大大超过规定标准。为了进行验证,随机抽取100件为样本,测得平均使用寿命为1245小时。能否说该厂的显像管质量显著地高于规定标准。

276
解一: 接受域 拒绝域

277
解二: 拒绝域 接受域

278
某机器制造出的肥皂的标准厚度为5cm,今欲了解机器性能是否良好,随机抽取10块肥皂为样本,测得平均厚度为5. 3cm,标准差为0
某机器制造出的肥皂的标准厚度为5cm,今欲了解机器性能是否良好,随机抽取10块肥皂为样本,测得平均厚度为5.3cm,标准差为0.3cm,试以0.01的显著性水平检验机器性能良好的假设。 接受域 拒绝域

279
一个汽车轮胎制造商声称,某一等级轮胎的平均寿命在一定的汽车重量和正常行驶条件下大于40000km,对一个由120个轮胎组成的随机样本作了试验,测得平均值和标准差分别为41000km和5000km。已知轮胎寿命的公里数近似服从正态分布。能否根据这些数据作出该制造商的产品同他所说的标准相符的结论。 接受域 拒绝域

280
三、总体比例的检验 例题: 某高尔夫球场在过去几个月里高尔夫运动者有20%是女性,为增加女性运动者比率,球场以特价方式吸引女性运动者,一周以后,一个400名运动者所组成的样本中,300名为男性,100名为女性。能否得出结论认为球场的女性运动者比率上升了(α=0.05)。
。")
281
接受域 拒绝域

282
7.2.2 两个总体参数的检验 一、两个总体参数之差的抽样分布

283
大样本(n1≥30且n2≥30)情形下, 近似服从正态分布,即:
σ1 和σ2已知 式中:σ1──总体1的标准差 σ2──总体2的标准差 n1──来自总体1简单随机样本的的样本容量 n2──来自总体2简单随机样本的的样本容量

284
大样本(n1≥30且n2≥30)情形下, 近似服从正态分布,即:
σ1 和σ2未知 式中:s1──来自总体1的样本标准差 s2──来自总体2的样本标准差 n1──来自总体1简单随机样本的的样本容量 n2──来自总体2简单随机样本的的样本容量

285
小样本情形下,存在自由度为n1+n2-2的t分布,即:
σ1 和σ2未知, 但已知σ1 =σ2 式中:s1──来自总体1的样本标准差 s2──来自总体2的样本标准差 n1──来自总体1简单随机样本的的样本容量 n2──来自总体2简单随机样本的的样本容量

286
有两种方法可用于制造某种以抗拉强度为重要特征的产品。根据以往的资料得知,第一种方法生产出的产品其抗拉强度的标准差为8kg,第二种方法的标准差为10kg。从两种方法生产的产品中各抽一个随机样本,样本的容量分别为n1=32,n2=40,测得 =50kg, =44kg。问两种方法生产出来的产品平均抗拉强度是否有显著差别(α=0.05)。
。")
287
一个车间研究用两种不同的工艺组装某种产品所用的时间是否相同。让一个组的10工人用第一种工艺组装该种产品,平均所需时间为26
一个车间研究用两种不同的工艺组装某种产品所用的时间是否相同。让一个组的10工人用第一种工艺组装该种产品,平均所需时间为26.1分钟,样本标准差为12分钟。另一组8名工人用第二种工艺组装,平均所需时间为17.6分钟,标准差为10.5分钟。已知用两种工艺组装产品所用时间服从正态分布,且σ1=σ2,试问能否认为用第二种方法组装比第一种方法要好。

288
某制造公司有两种方法可供员工执行某生产任务。为使产出最大化,公司试图确认哪种方法有最短完成时间。
抽取样本有两个可供选择的方案 2、匹配样本方案:抽取工人的一个简单随机样本,每个工人选用一种方法,后用另一种方法,两种方法的次序是随机排列的;每个工人提供一对数据,一个是方法1的,另一个是方法2的。 1、独立样本方案:抽取工人的一个简单随机样本,其中每个工人使用方法1;抽取工人的另一个简单随机样本,其中每个工人使用方法2。均值差的检验可采用前述独立样本条件下的检验方法。

289
匹配样本数据 工人 方法1的完成时间(分钟) 方法2的完成时间(分钟) 完成时间的差值(di) 1 2 3 4 5 6 6.0 5.0 7.0 6.2 6.4 5.4 5.2 6.5 5.9 5.8 0.6 -0.2 0.5 0.3 0.0 匹配样本方案中,两种生产方法是在相似的条件下被检验的(即由同一个工人执行),所以该方案往往比独立样本方案有更小的抽样误差。这主要是由于匹配样本方案中作为抽样误差来源之一的工人个体间的差异被去掉了。 差值(di)的样本均值与样本标准差 假设差值(di)服从正态分布,则检验统计量 对α=0.05,自由度为n-1=5的t分布(t0.025=2.571),双侧检验的拒绝法则为:如果t<-2.571或t>2.571,则拒绝H0。 检验的统计量的值为: 样本数据没有提供足够的证据拒绝H0。
,所以该方案往往比独立样本方案有更小的抽样误差。这主要是由于匹配样本方案中作为抽样误差来源之一的工人个体间的差异被去掉了。 差值(di)的样本均值与样本标准差. 假设差值(di)服从正态分布,则检验统计量. 对α=0.05,自由度为n-1=5的t分布(t0.025=2.571),双侧检验的拒绝法则为:如果t<-2.571或t>2.571,则拒绝H0。 检验的统计量的值为: 样本数据没有提供足够的证据拒绝H0。")
290
二、两个总体比率之差的检验 大样本情形下,p1-p2近似服从正态分布,即: p1-p2抽样分布

291
对两个大型企业青年工人参加技术培训的情况进行调查,调查结果如下:甲厂:调查60人,18人参加技术培训。乙厂:调查查40人,14人参加技术培训。能否根据以上调查结果认为乙厂工人参加技术培训的人数比例高于甲厂(α=0.05)。
。")
292
7.3 .1单个总体的 t 检验 (One-Sample T Test)分析
例1:根据2002年我国不同行业的工资水平,检验国有企业的职工平均年工资收入是否等于10000元,假设数据近似地服从正态分布。 首先建立假设: H0:国有企业工资为10000元; H1:国有企业职工工资不等于10000元 检验过程的操作按照下列步骤:

293
1、单击Analyze Compare Means One-Sample T Test,打开One-Sample T Test 主对话框,如图所示。
2、从左边框中选中需要检验的变量(国有单位)进入检验框中。 3、在Test Value框中键入原假设的均值数10000。
进入检验框中。 3、在Test Value框中键入原假设的均值数10000。")
294
4、单击Options按钮,得到Options对话框,选项分别是置信度(默认项是95%)和缺失值的处理方式。选择后默认值后返回主对话框。
5、单击OK,得输出结果。如表所示。 从上面检验结果表(1)可以得出国有单位职工工资的平均值、标准差和均值的标准误等反映数据特征的数据。从表(2)中可知检验的结果。即相应的检验统计量t值为4.121,自由度为30,假设检验的P值(sig)小于0.05,故原假设不成立,检验结论是拒绝原假设H0,接受假设H1。即认为国有企业职工的平均工资与10000元的假设差异显著。
可以得出国有单位职工工资的平均值、标准差和均值的标准误等反映数据特征的数据。从表(2)中可知检验的结果。即相应的检验统计量t值为4.121,自由度为30,假设检验的P值(sig)小于0.05,故原假设不成立,检验结论是拒绝原假设H0,接受假设H1。即认为国有企业职工的平均工资与10000元的假设差异显著。")
295
例题: 为确认某市12—15岁青少年是否达到160. 0厘米的标准身高 ,对该市同年龄段的青少年作了一次抽样调查 ,获样本数据如下 。试以0
例题: 为确认某市12—15岁青少年是否达到160.0厘米的标准身高 ,对该市同年龄段的青少年作了一次抽样调查 ,获样本数据如下 。试以0.05的显著性水平作出统计推断。

296
三十名学生的身高与体重数据 序号 性别 年龄 身高 体重 11 12 13 14 15 男 女 156.0 155.0 144.6 161.5 161.3 158.0 161.0 162.0 164.3 144.0 157.9 176.1 168.0 164.5 153.0 47.5 37.8 38.6 41.6 43.3 47.3 47.1 47.0 33.8 49.2 54.5 50.0 44.0 58.0 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 164.7 160.5 147.0 153.2 166.0 169.0 170.0 165.1 172.0 159.4 158.6 44.1 53.0 36.4 30.1 40.4 57.0 58.5 51.0 55.0 44.7 45.4 44.3 42.8 51.1
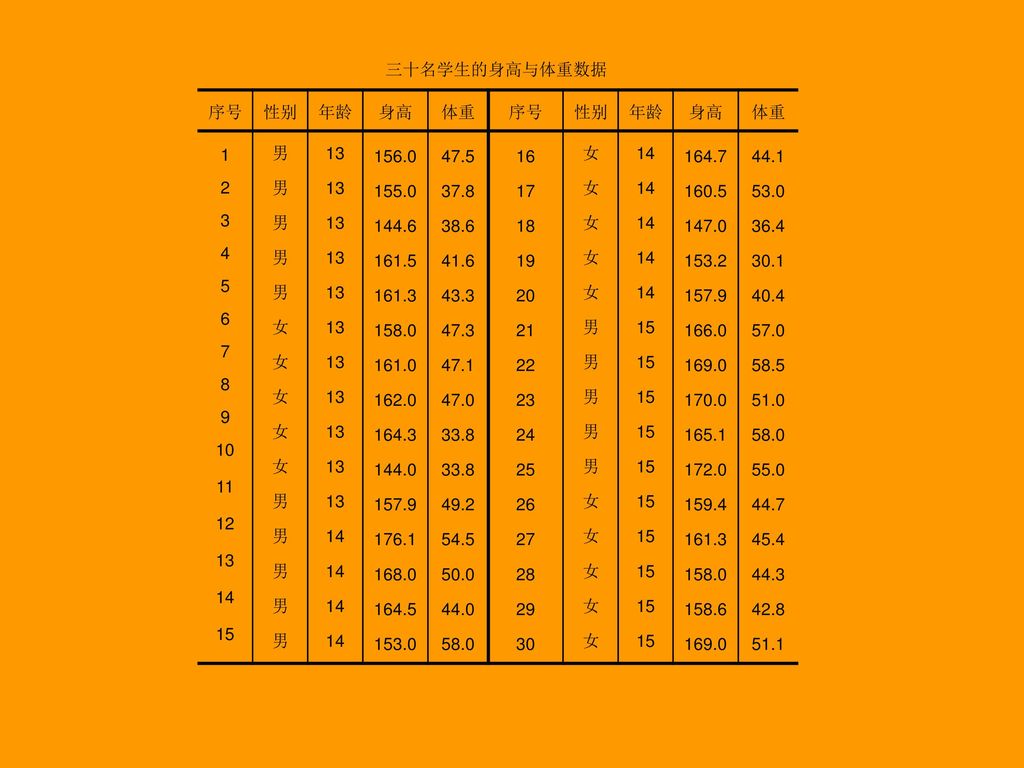
297
7.3.2 两个总体的 t 检验 7.2.1 两个独立样本的t检验(Independent-samples T Test)
Independent-sample T Test是检验两个没有联系的总体样本均值间是否存在显著的差异,两个没有联系的总体样本也称独立样本。 例2.某医药研究所考察一种药品对男性和女性的治疗效果是否有显著差异,调查了10名男性服用者及7名女性服用者,对他们服药后的各项指标进行综合评分,服用的效果越好,分值就越高,每人所得的总分见下表,试根据表中的数据检验这种药品对男性和女性的治疗效果是否存在显著差异。

298
解:由于药品对男性或女性的影响是无联系的,因此这两个样本是相互独立的。可以应用两独立样本的假设检验。
首先,建立假设 H0:该药品对男性和女性的治疗效果没有显著差异; H1:该药品对男性和女性的治疗效果有显著差异。 具体操作步骤: 1、单击Analyze Compare Means Independent-sample T Test,打开Independent-sample T Test 主对话框如图。 2、选择要检验的变量“综合得分”进入检验框中。

299
3、选择分组变量“性别”进入分组框中,然后单击Define Group按纽,打开分组对话框如图所示,确定分组值后返回主对话框,如果没有分组,可以选择Cut point单选项,并在激活的框内输入一个值作为分组界限值。 4、由Option选择按纽确定置信度值和缺失值的处理方式。 5、点击OK可得输出结果。

300
第三列和第四列是检验两样本数据的方差是否相等,从检验结果得知两样本的方差没有显著差异。从第五列开始是对两个样本的均值的是否相等进行检验。从假设检验的P值看出,它大于显著性水平0.05,所以说男女之间的机械能力之间并无显著差异,因此接受原假设H0。而第八列之后分别是均值差、均值差标准误、均值差的置信区间。

301
三十名学生的身高与体重数据 序号 性别 年龄 身高 体重 11 12 13 14 15 男 女 156.0 155.0 144.6 161.5 161.3 158.0 161.0 162.0 164.3 144.0 157.9 176.1 168.0 164.5 153.0 47.5 37.8 38.6 41.6 43.3 47.3 47.1 47.0 33.8 49.2 54.5 50.0 44.0 58.0 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 164.7 160.5 147.0 153.2 166.0 169.0 170.0 165.1 172.0 159.4 158.6 44.1 53.0 36.4 30.1 40.4 57.0 58.5 51.0 55.0 44.7 45.4 44.3 42.8 51.1 试以0.10的显著性水平,对该市男女青少年的身高进行比较。

302
7.3.3 两个有联系总体间的均值比较 (Paired-Sample T Test)
Paired-Sample T Test是检验两个有联系正态总体的均值是否存在显著的差异。又称配对样本的 t 检验。 例3:某企业对生产线上的工人进行某种专业技术培训,要对培训效果进行检验,从参加培训的工人中抽取30人,将他们培训前后的数据每加工500个零件的不合格品数进行对比,得到数据表见表。试根据表中数据检验培训前后工人的平均操作技术水平是否有显著提高,也就是检验培训效果是否显著。

303
解:这显然是配对样本均值的假设检验的问题。所以要建立假设:
H0:培训前后工人的技术水平没有显著差异; H1:培训前后工人的技术水平有显著差异; 根据中心极限定理,在大样本的情况下,样本均值近似地服从正态分布。所以可以利用正态参数的检验方法进行均值的检验。其检验过程的具体操作步骤为: 1、单击Analyze Compare Means Paired-Sample T Test,打开Paired-Sample T Test主对话框如图

304
2、选择要检验的两变量进入检验框中,注意,一定要选择两个变量进入检验框内,否则将无法得到检验结果。
3、由Option选择按纽确定置信度值95%和缺失值的处理方式。 4、点击OK得输出结果。 5、根据输出结果作出结论如表所示。 上表的检验结果知,假设检验的P值小于0.05,因此可以得出培训前后的差异是显著的,故拒绝假设H0,接受假设H1,认为培训的效果是显著的。

305
为分析不同促销形式对商品销售额是否产生显著影响,分别搜集了7 种商品在不同促销形式下的销售额数据。试对两种促销效果作出统计推断。
促销形式1 促销形式2 1 2 3 4 5 6 7 65 73 30 56 34 36 37 26 43 60

306
方差分析

307
方差分析的基本问题 一、方差分析的内容 1、定义:方差分析就是对多个总体均值是否相等这一假设进行检验。

308
方差分析的基本原理 某饮料企业生产一种新型饮料。饮料的颜色分为黄色、无色、粉色和绿色四种。为确定饮料的颜色是否对饮料的销售量有显著影响,从5个超市中搜集了该种饮料的样本数据如下表所示。管理者想用这些样本数据来检验假设:颜色对销售量没有显著影响。 总体1 总体2 总体3 总体4 四种颜色饮料销售量样本数据 超市 黄色 无色 粉色 绿色 1 2 3 4 5 27.9 25.1 28.5 24.2 26.5 28.7 29.1 27.2 31.2 28.3 30.8 29.6 32.4 31.7 32.8 样本均值 样本方差 =26.44 =3.298 =27.32 =2.672 =29.56 =2.143 =31.46 =1.658 总均值 =28.695 水平1 水平2 水平3 水平4 自变量或称因素 处理1 处理2 处理3 处理4 因变量或称响应变量 样本1 样本2 样本3 样本4 方差分析是对多个总体均值是否相等这一假设进行检验。

309
方差分析的基本原理 方差分析的假定条件 1.对每个总体,响应变量服从正态分布: 2.对每个总体,响应变量的方差相同: 3.观察值是独立的 于是:各个水平下的观测值可视为相应总体的随机样本。方差分析的问题就变为:检验所有数据是否可以看作来自同一总体的样本。 总体1 总体2 总体3 总体4 不尽相等

310
方差分析的基本原理 不尽相等 原假设为真时,样本均值来自同一个抽样分布。 1 m 不尽相等 原假设为假时,样本均值来自不同的抽样分布。

311
二、方差分析的原理 (一)数据差异的来源 1、因素的水平不同(系统性差异); 2、随机因素(随机性差异)。 (二)、数据差异的度量 1、水平之间的方差(组间方差)——系统性因素和随机因素的共同作用。 2、水平内部的方差(组内方差)——随机性因素的作用。 (三)、方差分析的基本思想: 如果因素对结果没有影响,那么水平间的方差就只含随机性差异而没有系统性差异,其值与水平内部方差就应该很接近,两个方差的比值就会接近于1;反之,水平间方差就同时包含系统性差异和随机性差异,两个方差的比值就会明显大于1,当这个比值大到某个程度(比如说大于某个临界值)就可以作结论:不同水平间存在显著差异。
——随机性因素的作用。 (三)、方差分析的基本思想: 如果因素对结果没有影响,那么水平间的方差就只含随机性差异而没有系统性差异,其值与水平内部方差就应该很接近,两个方差的比值就会接近于1;反之,水平间方差就同时包含系统性差异和随机性差异,两个方差的比值就会明显大于1,当这个比值大到某个程度(比如说大于某个临界值)就可以作结论:不同水平间存在显著差异。")
312
三、检验统计量 1、方差分析的统计假设: 2、检验的统计量: 组间均方差与组内均方差之比 至少两个总体的均值不等 ;
Distribution)。 是一个统计量,服从 分布(
。 是一个统计量,服从. 分布(")
313
7.4.2单因素方差分析 观测值 因素(i) (j) A1 A2 … Ak 1 x11 x21 xk1 2 x12 x22 xk2 n
x1n x2n xkn

314
一、单因素方差分析的步骤 (一)计算水平均值和总体均值
计算水平均值和总体均值")
322
二、关系强度的测量

323
7.4.3 双因素方差分析 一、双因素方差分析及其类型
例:有四个品牌的彩电在五个地区销售,为分析彩电的品牌和销售地区对销售量是否影响,对每个品牌在各地区的销售量取得以下数据。试分析品牌和销售地区对彩电的销售量是否有影响。 不同品牌的彩电在各地区的销售量数据

324
二、无交互作用的双因素方差分析 (一)数据结构
数据结构")
326
(二)分析步骤
分析步骤")
327
多因素方差分析 调用此过程可完成多因素方差分析。操作过程中涉及广义线性模型的内容,故在此从略。

328
7.4.1 单因素方差分析-spss 单因变量的单因素方差分析主要解决多于两个总体样本或变量间均值的比较问题。是一种对多个(大于两个)总体样本的均值是否存在显著差异的检验方法。其目的也是对不同的总体的数据的均值之间的差异是否显著进行检验。 单因素方差分析的应用条件:在不同的水平(因素变量取不同值)下,各总体应当服从方差相等的正态分布。 例4,某企业需要一种零件,现有三个不同的地区的企业生产的同种零件可供选择 ,为了比较这三个零件的强度是否相同,每个地区的企业抽出6件产品进行强度测 试,其值如表所示。假设每个企业零件的强度值服从正态分布,试检验这三个地区 企业的零件强度是否存在显著差异。 解:首先建立假设 H0:三个地区的零件强度无显著差异; H1:三个地区的零件强度有显著差异。 具体操作过程如下:
下,各总体应当服从方差相等的正态分布。 例4,某企业需要一种零件,现有三个不同的地区的企业生产的同种零件可供选择. ,为了比较这三个零件的强度是否相同,每个地区的企业抽出6件产品进行强度测. 试,其值如表所示。假设每个企业零件的强度值服从正态分布,试检验这三个地区. 企业的零件强度是否存在显著差异。 解:首先建立假设. H0:三个地区的零件强度无显著差异; H1:三个地区的零件强度有显著差异。 具体操作过程如下:")
329
1、单击Analyze Compare Means One-Way ANOVA,打开 One-Way ANOVA对话框。
2、从左框中选择因变量”零件强度”进入Dependent list框内,选择因素变量”地区”进入Factor框内。点击OK就可以得到方差分析下表。 由于F统计量值的P值明显小于显著性水平0.05,故拒绝假设H0,认为这三个地区的零件强度有显著差异。 如果需要对各地区间的零件强度进行进一步的比较和分析,可以通过按钮Option选项,contrast对照比较,Post Hoc多重比较去实现。

330
3、单击Option按纽,打开Option对话框如图所示:在Option选项中选择输出项。主要有不同水平下样本方差的齐性检验,缺失值的处理方式及均值的图形。
本例中选择Homogeneity of variance test 进行不同水平间方差齐性的检验以及Descriptive 基本统计描述。在Missing Value栏中选择系统默认项。

331
完成所有选择后返回主对话框,然后单击OK,就可以得到三个地区零件强度分析表 。
4、Contrasts按钮可以用来进一步分析随着控制变量水平的变化,观测值变化的总体趋势以及进一步比较任意指定水平间的均值差异是否显著。 单击Contrasts按钮,打开One-Way ANOVA:Contrasts对话框,见图 。

332
如果要对组间平方和进行趋势成分检验,选中Polynomial多项式复选项,选中后激活Degree参数框,在Degree框中选择趋势检验多项式的阶数,有最高次数可达5 次。系统将给出指定阶数和低于指定阶次各阶次的自由度、F值和F检验的概率值。 在Contrast栏,指定需要对照比较两个水平的均值。 在Coefficients 框中输入一个系数,单击Add按纽,系数就进入到Coefficients 框中。重复上述,依次输入各组均值的系数。注意系数的和应当等于0。如;图就是指第一个水平与第三个水平的均值差比较。

333
5、如果需要将水平间两两比较,可以单击Post Hoc 按纽,打开多重比较对话框。
在该对话框中列出了二十种多重比较检验,涉及到许多的数理统计方法,在实际中只选用其中常用的方法即可。 对话框下部的Significance level表示显著性水平,默认值是0.05,也可以根据需要重新输入其它值。 如果满足在水平间方差相等的条件,常用LSD(least-significant difference最小显著性差异法),表示用 t 检验完成各组均值间的配对比较。 当方差不等的情况下,可以选择Tamhanes T2, 用t检验进行各组均值间的配对比较。
,表示用 t 检验完成各组均值间的配对比较。 当方差不等的情况下,可以选择Tamhanes T2, 用t检验进行各组均值间的配对比较。")
334
从表可以看出,地区2与地区3之间的差异是非常显著的,它们均值差的检验的尾概率为0.005,明显小于显著性水平0.05。

335
单因素方差分析 四种颜色饮料销售量样本数据 [数据集12] 超市 黄色 无色 粉色 绿色 1 2 3 4 5 27.9 25.1 28.5 24.2 26.5 28.7 29.1 27.2 31.2 28.3 30.8 29.6 32.4 31.7 32.8 =2 =3 =4 color =1 sale 定义 变量
![单因素方差分析 四种颜色饮料销售量样本数据. [数据集12] 超市. 黄色. 无色. 粉色. 绿色](http://slidesplayer.com/slide/11173131/60/images/335/%E5%8D%95%E5%9B%A0%E7%B4%A0%E6%96%B9%E5%B7%AE%E5%88%86%E6%9E%90+%E5%9B%9B%E7%A7%8D%E9%A2%9C%E8%89%B2%E9%A5%AE%E6%96%99%E9%94%80%E5%94%AE%E9%87%8F%E6%A0%B7%E6%9C%AC%E6%95%B0%E6%8D%AE.+%5B%E6%95%B0%E6%8D%AE%E9%9B%8612%5D+%E8%B6%85%E5%B8%82.+%E9%BB%84%E8%89%B2.+%E6%97%A0%E8%89%B2.+%E7%B2%89%E8%89%B2.+%E7%BB%BF%E8%89%B2.jpg "=2. =3. =4. color. =1. sale. 定义. 变量.")
336
单因素方差分析 调用此过程可完成单因素方差分析

337
单因素方差分析的基本过程可采纳系统的默认方式。
多重比较 各种 选项

338
单因素方差分析 F统计量=10.544的P值 =0.000 <0.05。故拒绝原假设,接受备择假设,即不同颜色的饮料的销售量有显著差异。

339
对四种颜色下各总体的均值进行多重比较。

340
最小显著性差异法

342
由于方差分析的前提是各水平下的总体服从方差相等的正态分布,因此须对方差分析的前提进行检验。

343
输出不同水平下的描述性统计量 输出方差相等性的检验结果 输出各水平下均值的折线图。 计算中涉及的变量含有缺失值时暂时剔除观测 剔除所有含有缺失值的观测

344
单因素方差分析 检验统计量=0.255相伴P值=0.856 > 0.05故可以认为4种水平下各总体的方差无显著差异,满足单因素方差分析中的方差相等性要求。

345
单因素方差分析 样本数据所显示的四种颜色饮料销售量的差异。

346
7.4 双因素方差(Univariate)分析过程
单因变量的双因素方差分析是对观察的现象(因变量)受两个因素或变量的影响进行分析,检验不同水平组合之间对因变量的影响是否显著。 双因素方差分析应用条件:因变量和协变量必须是数值型变量,且因变量来自或近似来自正态总体。因素变量是分类变量,变量可以是数值型或字符型的。各水平下的总体假设服从正态分布,而且假设各水平下的方差是相等的。 双因素方差分析过程可以分析出每一个因素的作用;各因素之间的交互作用;检验各总体间方差是否相等;还能够对因素的各水平间均值差异进行比较等。 例5:右表是某商品S在不同地区和不同时期的销售量表。已知数据服从正态分布,则要检验地区因素及时间因素对销售量的影响是否显著。
受两个因素或变量的影响进行分析,检验不同水平组合之间对因变量的影响是否显著。 双因素方差分析应用条件:因变量和协变量必须是数值型变量,且因变量来自或近似来自正态总体。因素变量是分类变量,变量可以是数值型或字符型的。各水平下的总体假设服从正态分布,而且假设各水平下的方差是相等的。 双因素方差分析过程可以分析出每一个因素的作用;各因素之间的交互作用;检验各总体间方差是否相等;还能够对因素的各水平间均值差异进行比较等。 例5:右表是某商品S在不同地区和不同时期的销售量表。已知数据服从正态分布,则要检验地区因素及时间因素对销售量的影响是否显著。")
347
由于销售量受地区和时间两个因素的影响,这是一个双因素方差分析的问题。
1、单击Analyze General linear Model Univariate,打开Univariate主对话框。 2、选择要分析的变量”销售量”进入Dependent Variable 框中,选择因素变量”地区”和”时期”进入Fixed Factor框中。 3、单击Model按纽选择分析模型,得到Model对话框。如图所示:在Specify框中,指定模型类型。

348
Custom选项为自定义模型,本例选择此项并激活下面的各项操作。
先从左边框中选择因素变量进入Model框中,然后选择效应类型。一般不考虑交互作用时,选择主效应Main,考虑交互作用时,选择交互作用Interaction。可以通过单击Build Term下面的小菜单完成,本例中选择主效应。最后在Sum of Square 中选择分解平方和的方法后返回在主对话框。一般选取默认项TypeⅢ。单击OK就可以得到相应的双因素方差分析表 。

349
从表中数据可以看出,F值对应概率P值都小于显著性水平0.05,这说明地区和时期对销售量的影响都是显著的。
4、如果需要进行特定的两水平间的均值比较,可单击Contrast比较按纽,打开Contrast对话框如图。在Factor框中显示所有在主对话框中选择的因素变量,括号中显示的是当前的比较方法,点击选中因素变量,可以改变均值的比较方法。

350
5、如果需要进行图形展示,可单击Plots按纽,打开图形对话框如图所示。选择作均值轮廓图(Profile)的参数。
(1)在Factor框中选择因素变量进入横坐标Horizontal Axis框内,然后单击add按纽,可以得到该因素不同水平的因变量均值的分布。 (2)如果要了解两个因素变量的交互作用,将一个因素变量送入横坐标后,将另一个因素变量送入Separate Lines分线框中,然后单击add按纽。就可以输出反映两个因素变量的交互图。本例中选择因素A为横坐标。
在Factor框中选择因素变量进入横坐标Horizontal Axis框内,然后单击add按纽,可以得到该因素不同水平的因变量均值的分布。 (2)如果要了解两个因素变量的交互作用,将一个因素变量送入横坐标后,将另一个因素变量送入Separate Lines分线框中,然后单击add按纽。就可以输出反映两个因素变量的交互图。本例中选择因素A为横坐标。")
351
6、如需要将因素A各水平间均值进行两两比较,单击Post Hoc按纽,打开Post Hoc Multiple多重比较对话框如图所示。从Factor框中选择因素变量进入Post Hoc Test for框中,然后选择多重比较方法。本例中各组方差相等,选择LSD方法。 7、单击Save 按纽,打开保存对话框,如图所示。选择需要保存的变量。

352
8、单击Options按纽,打开Univariate:Options对话框,从中选择需要输出的显著性水平,默认值为0
8、单击Options按纽,打开Univariate:Options对话框,从中选择需要输出的显著性水平,默认值为0.05。 在进行所有的选择后,单击OK,就可以得到输出结果。由多重比较LSD表中得到不同地区销售量的比较表。

353
两个因素变量地区和时期的折线之间无交叉,因此两个因素之间基本上没有交互作用。

354
第8章 相关分析与回归模型的建立与分析 相关分析和回归分析是统计分析方法中最重要内容之一,是多元统计分析方法的基础。相关分析和回归分析主要用于研究和分析变量之间的相关关系,在变量之间寻求合适的函数关系式,特别是线性表达式。 本章主要内容: 对变量之间的相关关系进行分析(Correlate)。其中包括简单相关分析(Bivariate)和偏相关分析(Partial)。 建立因变量和自变量之间回归模型(Regression),其中包括线性回归分析(Linear)和曲线估计(Curve Estimation)。 数据条件:参与分析的变量数据是数值型变量或有序变量。
。其中包括简单相关分析(Bivariate)和偏相关分析(Partial)。 建立因变量和自变量之间回归模型(Regression),其中包括线性回归分析(Linear)和曲线估计(Curve Estimation)。 数据条件:参与分析的变量数据是数值型变量或有序变量。")
355
8.1 相关分析 在SPSS中,可以通过Analyze菜单进行相关分析(Correlate),Correlate菜单如图所示。
,Correlate菜单如图所示。")
356
简单相关分析 两个变量之间的相关关系称简单相关关系。有两种方法可以反映简单相关关系。一是通过散点图直观地显示变量之间关系,二是通过相关系数准确地反映两变量的关系程度。 散点图 SPSS软件的绘图命令集中在Graphs菜单。下面通过例题来介绍具体操作方法。 例1:数据库中的变量X表示山东省人均国内生产总值,Y表示山东省城镇居民的消费额(资料来源:山东省2003年统计年鉴),现画出散点图来观察两个变量的关联程度。 单击Graphs Scatter,打开Scatter plot散点图对话框,如图3.2所示。然后选择需要的散点图,图中的四个选项依次是: Simple 简单散点图 Matrix 矩阵散点图 Overlay 重叠散点图 3-D 三维散点图
,现画出散点图来观察两个变量的关联程度。 单击Graphs Scatter,打开Scatter plot散点图对话框,如图3.2所示。然后选择需要的散点图,图中的四个选项依次是: Simple 简单散点图. Matrix 矩阵散点图. Overlay 重叠散点图. 3-D 三维散点图.")
357
如果只考虑两个变量,可选择简单的散点图Simple,然后点击Define,打开Simple Scatterplot对话框,如图所示。

358
简单相关分析操作 简单相关分析是指两个变量之间的相关分析,主要是指对两变量之间的线性相关程度作出定量分析。仍然上题为例,说明居民收入与某商品的销售量两变量的相关分析过程,具体操作如下: 1、打开数据库后,单击Analyze Correlate Bivariate 打开Bivariate对话框,见图所示。

359
2、从左边的变量框中选择需要考察的两个变量进入 Variables 框内,从Correlation Coefficients 栏内选择相关系数的种类,有Pearson相关系数,Kendall′s一致性系数和Spearman等级相关系数。从检验栏内选择检验方式,有双尾检验和单尾检验两种。 3、单击Options按纽,选择输出项和缺失值的处理方式。本例中选择输出基本统计描述。

360
4、单击OK,可以得到相关分析的结果。

361
偏相关分析 简单相关关系只反映两个变量之间的关系,但如果因变量受到多个因素的影响时,因变量与某一自变量之间的简单相关关系显然受到其它相关因素的影响,不能真实地反映二者之间的关系,所以需要考察在其它因素的影响剔除后二者之间的相关程度,即偏相关分析。 例2:为了考察火柴销售量的影响因素,选择煤气户数、卷烟销量、蚊香销量、打火石销量作为影响因素,得数据表。试求火柴销售量与煤气户数的偏相关系数.

362
解:根据数据表建立数据文件,求解火柴销售量与煤气户数的偏相关系数具体操作如下:
1、首先打开数据文件,单击Analyze Correlate Partial,打开Partial Correlations对话框,见图所示。 2、从左边框内选择要考察的两个变量进入Variables框内,其它客观存在的变量作为控制变量进入Controlling for 框内,如本例中考察煤气户数与火柴销量的偏相关系数进入Variables框内,其它相关变量(除年份外)进入Controlling for 框内。
进入Controlling for 框内。")
363
3、单击Options按纽,打开Options 对话框如图所示。从 Statistics 栏中选择输出项,有平均值及标准差,Zero-order correlations 表示在输出偏相关系数的同时输出变量间的简单相关系数。另外还有缺失值的处理方式。本例中选择简单相关系数。 4、选择结束后,单击OK得输出结果

364
表中的上半部分是简单相关系数,下半部分是偏相关系数。从表中可以看出,火柴销量与煤气户数的简单相关系数为0
表中的上半部分是简单相关系数,下半部分是偏相关系数。从表中可以看出,火柴销量与煤气户数的简单相关系数为0.8260,自由度为13,检验的P值为0.000;而偏相关系数为0.6046,自由度为10,检验的P值为0.037,表示煤气户数对火柴销量的真实影响是显著的。

365
8.2 线性回归分析 线性回归是统计分析方法中最常用的方法之一。如果所研究的现象有若干个影响因素,且这些因素对现象的综合影响是线性的,则可以使用线性回归的方法建立现象 (因变量)与影响因素(自变量)之间的线性函数关系式。由于多元线性回归的计算量比较大,所以有必要应用统计分析软件实现。这一节将专门介绍SPSS软件的线性回归分析的操作方法,包括求回归系数,给出回归模型的各项检验统计量值及相应的概率,对输出结果的分析等相关内容。
与影响因素(自变量)之间的线性函数关系式。由于多元线性回归的计算量比较大,所以有必要应用统计分析软件实现。这一节将专门介绍SPSS软件的线性回归分析的操作方法,包括求回归系数,给出回归模型的各项检验统计量值及相应的概率,对输出结果的分析等相关内容。")
366
线性回归模型假设条件与模型的各种检验 1、线性回归的假设理论 (1)正态性假设:即所研究的变量均服从正态分布; (2)等方差假设:即各变量总体的方差是相等的; (3)独立性假设, 即各变量之间是相互独立的; (4)残差项无自相关性,即误差项之间互不相关,Cov(i,j)= 0
残差项无自相关性,即误差项之间互不相关,Cov(i,j)= 0.")
367
2、线性回归模型的检验项目 (1)回归系数的检验(t检验)。 (2)回归方程的检验(F检验)。 (3)拟合程度判定(可决系数R2)。 (4)D.W检验(残差项是否自相关)。 (5)共线性检验(多元线性回归)。 (6)残差图示分析(判断异方差性和残差序列自相关)。
残差图示分析(判断异方差性和残差序列自相关)。")
368
8.2.2 线性回归分析的具体步骤 SPSS软件中进行线性回归分析的选择项为Analyze→Regression→Linear。

369
例3. 仍然用例2的数据,考察火柴销售量与各影响因素之间的相关关系,建立火柴销售量对于相关因素煤气户数、卷烟销量、蚊香销量、打火石销量的线性回归模型,通过对模型的分析,找出合适的线性回归方程。
解:建立线性回归模型的具体操作步骤如下: 1、打开数据文件,单击Analyze Regression Linear打开Linear 对话框如图所示。 2、从左边框中选择因变量Y进入Dependent 框内,选择一个或多个自变量进入Independent框内。从Method 框内下拉式菜单中选择回归分析方法,有强行进入法(Enter),消去法(Remove),向前选择法(Forward),向后剔除法(Backward)及逐步回归法(Stepwise)五种。本例中选择逐步回归法(Stepwise)。
,消去法(Remove),向前选择法(Forward),向后剔除法(Backward)及逐步回归法(Stepwise)五种。本例中选择逐步回归法(Stepwise)。")
370
3、单击Statistics,打开Linear Regression: Statistics对话框,可以选择输出的统计量如图所示。
Regression Coefficients栏,回归系数选项栏。 Estimates (系统默认): 输出回归系数的相关统计量:包括回归系数,回归系数标准误、标准化回归系数、回归系数检验统计量(t值)及相应的检验统计量概率的P值(sig)。本例中只选择此项。 Confidence intervals:输出每一个非标准化回归系数95%的置信区间。 Covariance matrix: 输出协方差矩阵。 与模型拟合及拟合效果有关的选择项。
: 输出回归系数的相关统计量:包括回归系数,回归系数标准误、标准化回归系数、回归系数检验统计量(t值)及相应的检验统计量概率的P值(sig)。本例中只选择此项。 Confidence intervals:输出每一个非标准化回归系数95%的置信区间。 Covariance matrix: 输出协方差矩阵。 与模型拟合及拟合效果有关的选择项。")
371
Model fit是默认项。能够输出复相关系数R、R2及R2修正值,估计值的标准误,方差分析表。
R squared change: 引入或剔除一个变量时,R2的变化。 Descriptives: 基本统计描述。 Part and Partial correlations:相关系数及偏相关系数。 Collinearity diagnostics:共线性诊断。主要对于多元回归模型,分析各自变量的之间的共线性的统计量:包括容忍度和方差膨胀因子、特征值,条件指数等。 本例中选择上面所有的统计项。 Residuals 残差栏 Durbin-Watson:D.W检验. Casewise diagnostics: 奇异值诊断,有两个选项: Outliers outside( )standard deviations:奇异值判据,默认项标准差≥3。 All case 输出所有观测量的残差值。 本例中选择D.W检验及奇异值诊断,选择标准差为2,即置信度约为95%。
standard deviations:奇异值判据,默认项标准差≥3。 All case 输出所有观测量的残差值。 本例中选择D.W检验及奇异值诊断,选择标准差为2,即置信度约为95%。")
372
4、如果需要观察图形,可单击Plots按纽,打开Linear Regression:Plots对话框如图所示。在此对话框中可以选择所需要的图形。
在左上角的源变量框中,选择Dependent 进入X(或Y)轴变量框,选择其它变量进入Y(或X)轴变量框,除因变量外,其客观存在变量依次是:ZPRED:标准化预测值,ZRESID:标准化残差,DRESID:剔除残差,ADJPRED:修正后预测值,SRESID学生化残差,SDRESID:学生化剔除残差。
轴变量框,选择其它变量进入Y(或X)轴变量框,除因变量外,其客观存在变量依次是:ZPRED:标准化预测值,ZRESID:标准化残差,DRESID:剔除残差,ADJPRED:修正后预测值,SRESID学生化残差,SDRESID:学生化剔除残差。")
373
Standardized Residual Plots栏,标准化残差图类型,有选择项: Histogram: 标准化残差直方图 Normal probability plot 标准化残差序列的正态分布概率图. Produce all partial plots 依次绘制因变量和所有自变量的散布图 本例中选择因变量Dependent与标准化残差ZRESID的残差图。 5、单击Options按纽,打开Linear Regression:Options对话框,如图所示。可以从中选择模型拟合判断准则Stepping Method Criteria 及缺失值的处理方式。 Stepping Method Criteria 栏,设置变量引入或剔除模型的判别标准。 Use probability of F:采用F检验的概率为判别依据。 Use F value: 采用F值作为检验标准。 Include constant in equation 回归方程中包括常数项。 Missing Values 缺失值的处理方式。本例中选择系统默认项。

374
6、如果要保存预测值等数据,可单击Save按纽打开Linear Regression:Save对话框。选择需要保存的数据种类作为新变量存在数据编辑窗口。其中有预测值、残差,预测区间等。本例中不做选择。 7、当所有选择完成后,单击OK得到分析结果。主要的分析结果见表。 表模型综合分析中有模型的复相关系数R,样本决定系数R2,修正的可决系数 ,估计标准误,模型变化导致的可决系数及F值的变化,D.W检验值等。由上表中知模型3的修正的可决系数为0.993,其模型的拟合程度最好, DW值为2.066,显然通过DW检验,说明残差项不存在一阶自相关。

375
模型1是先将卷烟销量作为自变量进入模型,模型2将卷烟销量与打火石销量两个自变量进入模型,模型3是将卷烟、打火石和煤气户数三个自变量进入模型。第四个自变量蚊香销量没有通过检验自动剔除。

377
残差统计表表示了预测值、残差、标准化预测值和标准化残差的特征值。其中包括预测值及残差项的最小值和最大值、均值、标准误和样本容量。
共线性诊断表中第二列是特征值,第三列是条件指数,最后一列是方差比。最大的条件指数小于20,说明自变量之间不存在比较强烈的共线性。

378
奇异值表中依次是序号,标准化残差值,实际观测值、预测值及残差值。表中给出的两个个体数据的标准化残差(数据号为12和14)超出了2。
超出了2。")
379
由图中可以看出,残差图中的点分布是随机的,没有出现趋势性,所以回归模型是有效的。
最终得回归模型为:

380
8.3 曲线估计 上节介绍了线性回归模型的分析和检验方法。如果某对变量数据的散点图不是直线,而是某种曲线的形式时,可以利用曲线估计的方法为数据寻求一条合适的曲线,也可用变量代换的方法将曲线方程变为直线方程,用线性回归模型进行分析和预测。SPSS提供了多种曲线方程。

381
函数名称 方程形式 相应的线性回归方程 Linear线性函数 Quadratic二次多项式 Compound复合模型 Growth生长曲线 Logarithmic对数函数 Cubic三次多项式 S S曲线 Exponential指数函数 Inverse逆函数 Power幂函数 Logistic逻辑曲线

382
例4:下表表示的是全国1990年至2002年人均消费支出与教育支出的统计数据,试以人均消费性支出为解释变量,教育支出作为被解释变量,拟合用一条合适的函数曲线。

383
解:首先根据上表建立数据,作出人均消费支出与教育支出的散点图
由右面图形可以看出,两个变量的散点图为增长的曲线形式,故选择合适的函数进行曲线估计。具体操作如下: 1、单击Analyze Regression Curve Estimation打开Curve Estimation对话框。 2、选择估计曲线:SPSS有多条曲线形式供选择。根据散点图,本例中选择Quadratic, Power ,和Compound曲线进行对比分析。

384
3、单击Save按钮,打开Save对话框。选择需要保存到数据表中的项目。在Save Variables栏中,复选项依次是:Predicted Values预测值、Residuals残差、Prediction intervals预测区间,可以在下方框中选择置信度,默认值为95%。本例中不作选择。

385
4、所有选择完成后,单击OK,得到输出结果 。
Independent: X 决定系数 自由度 F值 P值 回归系数 Dependent Mth Rsq d.f. F Sigf b b b Y QUA E Y COM Y POW E

386
Analysis of Variance: 方差分析表
从表中可以看出,可决系数接近1的模型是 Com复合函数,同时也可通过图形验证这三个模型对观察值的拟合程度。下面对以上三个模型进一步分析。在主对话框的下方选择输出方差分析表Display AMOVA table, 可得到方差分析表的详细分析结果如表所示: 曲线估计及方差分析表 Dependent variable.. Y Method.. QUADRATI二次多项式 复相关指数Multiple R 可决系数R Square 修正的可决系数Adjusted R Square 标准误Standard Error Analysis of Variance: 方差分析表 自由度 平方和 均方 DF Sum of Squares Mean Square Regression Residuals F(检验统计量) = Signif F(假设检验P值) =
 = Signif F(假设检验P值) =")
387
Dependent variable.. Y Method.. COMPOUND复合函数
Listwise Deletion of Missing Data Multiple R R Square Adjusted R Square Standard Error Analysis of Variance: DF Sum of Squares Mean Square Regression Residuals F = Signif F = Variables in the Equation Variable B SE B Beta T Sig T X E (Constant) 从上面的输出结果可以看出,比较各种估计模型的样本决定系数,标准误,F值,拟合程度最好的复合函数曲线,并且其模型的回归系数的检验也通过。故可以选择复合函数曲线作为拟合曲线,其回归方程为:
 从上面的输出结果可以看出,比较各种估计模型的样本决定系数,标准误,F值,拟合程度最好的复合函数曲线,并且其模型的回归系数的检验也通过。故可以选择复合函数曲线作为拟合曲线,其回归方程为:")
388
第9章 时间序列分析 由于反映社会经济现象的大多数数据是按照时间顺序记录的,所以时间序列分析是研究社会经济现象的指标随时间变化的统计规律性的统计方法。.为了研究事物在不同时间的发展状况,就要分析其随时间的推移的发展趋势,预测事物在未来时间的数量变化。因此学习时间序列分析方法是非常必要的。 本章主要内容: 1. 时间序列的线图,自相关图和偏自关系图; 2. SPSS 软件的时间序列的分析方法 季节变动分析。

389
9.1 实验准备工作 根据时间数据定义时间序列 对于一组示定义时间的时间序列数据,可以通过数据窗口的Date菜单操作,得到相应时间的时间序列。定义时间序列的具体操作方法是: 将数据按时间顺序排列,然后单击Date Define Dates打开Define Dates对话框,如图所示。从左框中选择合适的时间表示方法,并且在右边时间框内定义起始点后点击OK,可以在数据库中增加时间数列。

390
9.1.2 绘制时间序列线图和自相关图 一、线图 线图用来反映时间序列随时间的推移的变化趋势和变化规律。下面通过例题说明线图的制作。
绘制时间序列线图和自相关图 一、线图 线图用来反映时间序列随时间的推移的变化趋势和变化规律。下面通过例题说明线图的制作。 例题1:表中显示的是某地1979至1982年度的汗衫背心的零售量数据。试根据这些的数据对汗衫背心零售量进行季节分析。

391
解:根据表的数据,建立数据文件,并对数据定义相应的时间值,使数据成为时间序列。为了分析时间序列,需要先绘制线图直观地反映时间序列的变化趋势和变化规律。具体操作如下:
1. 在数据编辑窗口单击GraphsLine,打开Line Charts对话框如图。从中选择Simple单线图,从Date in Chart Are 栏中选择Values of individual cases,即输出的线图中横坐标显示变量中按照时间顺序排列的个体序列号,纵坐标显示时间序列的变量数据。

392
2. 单击Define,打开对话框如图所示。选择分析变量进入Line Represents,在Category Labels 类别标签(横坐标)中选择Case number数据个数(或变量Variable),单击Title按纽可以添加标题。
中选择Case number数据个数(或变量Variable),单击Title按纽可以添加标题。.")
393
二、自相关图 多数经济现象具有滞后性的特点,而自相关图能够刻画经济的滞后现象,对经济问题的分析和预测起到重要的作用。下面介绍自相关图的具体操作方法。 1. 在数据编辑窗口单击Gragh→Time Series →Autocorrelation对话框。 2. 在左边框内选择要显示的变量进入右边Variables对话框;如果需要对时间序列进行变换,则要从Transform栏中选择对变量的的变换方式:其中分别是Natural log transform自然对数变换,Differfence差分(确定差分阶数),Seasonally difference季节差分(确定差分阶数);从Display栏中选择自相关图(Autocorrelations)和偏自相关图(Partial autocorrelations)。
,Seasonally difference季节差分(确定差分阶数);从Display栏中选择自相关图(Autocorrelations)和偏自相关图(Partial autocorrelations)。")
394
3. 单击Options对话框,在Maximum Number of Lags参数框中选择最大滞后数值,默认值是16。选择默认值后点击OK,可在输出窗口观察到自相关图和偏相关图。
从上面的图中都可以看出,这个时间序列具有很强的季节性。偏相关反映出这个时间序列不是平稳的时间序列,有一定的趋势性。通过时间序列的线图和自相关图后,可以根据时间序列的变动趋势和季节性的特点进行季节分解,分析季节因素的影响程度。

395
9.2 季节变动分析 时间序列分析的基本方法,是进行季节变动分析。季节变动分析的可以通过分析菜单上Time Series实现。即在数据窗口单击AnalyzeTime Series。从Time Series小菜单中可以得到时间序列分析的四种选择分别是: Exponential Smoothing… 指数平滑法 Autoregression… 自回归模型 ARMA… 自回归移动平均模型 Seasonal Decomposition… 季节分解。

396
季节分析方法 季节变动分析是分析时间序列的指标值受时间因素的周期影响程度,通过季节分解,可以得出每个月指标的季节指数,根据季节指数进行季节调整,为制定相应的计划提供可靠的依据。下面通过前面的例1说明季节指数的求解方法。 打开数据文件。根据前面的线形图,看出数据有明显的季节波动,需要进行季节分解,求出季节指数。具体操作如下: 1、单击Analyze Time Series Seasonal Decomposition 打开Seasonal Decomposition对话框,如图所示。

397
2、从左边框中选择待分解处理的变量进入Variable框内, 并在Model栏中选择模型类型。有乘法模型(Multiplicative)和加法模型(Additive)两种。本例中选择乘法模型。
3、在Moving Average Weight 栏中,选择移动平均处理方法,一般当时距n为奇数时选择All points equal; 当n为偶数时选择Endpoints weighted by .5。 4、如果选择左下方的Display casewise listing,可以在输出窗口观察计算过程,其中包括移动平均的结果,季节指数的生成过程,序列成分分解过程。否则只输出简单的季节指数。 5、单击Save按纽,打开Save对话框,选择是否创建新的变量。 新创建的时间序列有:季节指数、调整后的序列值、平滑值及不规则变动。

398
Results of SEASON procedure for variable 零售量变量季节分析结果
6、单击OK得到输出结果如表所示。 简单的输出结果只显示季节指数。 Results of SEASON procedure for variable 零售量变量季节分析结果 Multiplicative Model. Centered MA method. Period = 12 乘法模型 Seasonal index 季节指数% 时期Period (* 100) 从上面的季节指数可以看出,背心的销售量在4月份至8月份的季节指数明显的高于其它月份的季节指数,其中5月、6月和7月份的季节指数超过了200%,说明了这个阶段的零售量非常大,已经达到月平均值的两倍以上。
 从上面的季节指数可以看出,背心的销售量在4月份至8月份的季节指数明显的高于其它月份的季节指数,其中5月、6月和7月份的季节指数超过了200%,说明了这个阶段的零售量非常大,已经达到月平均值的两倍以上。")
399
进行季节调整 季节分解的目的是根据季节指数进行季节调整,消除季节因素的影响,并通过调整前后的指标数据的比较,确定季节因素的影响程度,为预测决策提供科学依据。所以在进行季节分解的同时,在Seasonal Decomposition对话框中选择Display casewise listing复选项,可以得到详细的分解过程和季节调整值。表中给出了季节分解和调整过程的部分数据。

400
序号 变量 移动平均 比率 季节指数 季节调整值 平滑值 不规则变动 Seasonal Seasonally Smoothed
序号 变量 移动平均 比率 季节指数 季节调整值 平滑值 不规则变动 Seasonal Seasonally Smoothed Case Moving Ratios factors adjusted trend- Irregular number 零售量 averages (* 100) (* 100) series cycle component (1) (2) (3)=(1)/(2) (4) (5)=(1)/(4) (6) (7)=(5)/(6)
 (* 100) series cycle component. (1) (2) (3)=(1)/(2) (4) (5)=(1)/(4) (6) (7)=(5)/(6)")
401
第10章 非参数检验 前面进行的假设检验和方差分析,大都是在数据服从正态分布或近似地服从正态分布的条件下进行的。但是如果总体的分布未知,如何进行总体参数的检验,或者如何检验总体服从一个指定的分布,都可以归结为非参数检验方法。非参数检验包括下列内容: 本章主要内容: 1、总体分布的假设检验; 2、两种以上的现象之间的关联性检验(见列联分析); 3、总体分布未知时,关于单个总体均值的检验;两个总体均值或分布的差异是否显著的检验,以及多个未知总体的单因素方差分析。 4、某种现象的出现的随机性检验; 在SPSS分析软件中,非参数检验在菜单Analyze ®Nonparametric Test 中显示,共有8种检验方法。
; 3、总体分布未知时,关于单个总体均值的检验;两个总体均值或分布的差异是否显著的检验,以及多个未知总体的单因素方差分析。 4、某种现象的出现的随机性检验; 在SPSS分析软件中,非参数检验在菜单Analyze ®Nonparametric Test 中显示,共有8种检验方法。")
402
这8种检验方法依次是: Chi-square卡方检验 Binomial二项分布检验 Runs游程检验
1-Sample K-S 单个样本柯尔莫哥洛夫-斯米诺夫检验 2 Independent sample 两个独立样本检验 K Independent sample K个独立样本检验 2 Related Independent sample两个相关样本检验 K Related Independent sample K个相关样本检验

403
10.1 Chi-Square Test 卡方检验 卡方检验是一种常用的检验总体分布是否服从指定的分布的一种非参数检验方法。其检验思想是:将总体的取值范围分成有限个互不相容的子集,从总体中抽取一个样本,考察样本观察值落到每个子集中的实际频数,并按假设的总体分布计算每个子集的理论频数,最后根据实际频数和理论频数的差构造卡方统计量,当原假设成立时,统计量服从卡方分布。以此来检验假设总体的分布是否成立。下面通过例题来说明具体的检验方法。 例10.1 掷一个骰子300次,每个面出现的次数(取变量名为Shi)见表,用数字1,2,3,4,5,6分别表示六个面的点数,试在显著性水平0.05下检验颗骰子是否是均匀的?
见表,用数字1,2,3,4,5,6分别表示六个面的点数,试在显著性水平0.05下检验颗骰子是否是均匀的?")
404
解:如果这个骰子是均匀的,则每次试验出现六个点数的可能性是相等的。
建立原假设H0:每个点出现的概率等于1/6; 备择假设H1:每个点出现的概率不等于1/6。 具体操作步骤: 1、首先建立数据文件,注意变量Shi的变量值是300次试验的所有结果。然后单击Analyze Nonparametric Test Chi-Square Test ,Chi-Square Test打开对话框如图所示。 2、指定检验统计量,本例中选择变量Shi进入检验框中。 3、在Expect Values栏内指定期望分布的频数值,有两个选择项 。

405
4、在Expect Range 栏中指定检验值的范围。
系统默认从数据中得到的最小值和最大值作为取值范围,也可选择自定义取值范围。本例中选择系统默认项。 5、单击Option按钮,打开对话框如下图所示,对话框中有两个选择栏: Statistics栏, 选择输出的统计量: 有统计描述和四分位数两个选项,基本统计描述输出变量的均值、标准差、最大值和最小值,缺失值数量等。 Missing Value栏,选择处理缺失值的方式。 本例中选择系统默认项,将剔除参与对比的缺失值

406
7、单击OK,系统运行,输出结果如表所示。

407
10.2 一个样本的K-S检验 Chi-Square Test 卡方检验在进行均匀分布时的检验比较方便,但在进行其它总体分布的检验时需要预先计算出理论分布期望值并输入到计算机中。这样操作起来比较麻烦,下面介绍一种K-S检验方法,可以非常方便快捷地检验常用的四种总体分布形式,使检验过程更加简单。 一个样本的K-S检验又称单个样本柯尔莫哥洛夫-斯米诺夫检验,这种检验可以检验样本数据是否服从Normal正态分布、Poisson泊松分布、Uniform均匀分布及Exponential指数分布等四种分布形式。但一般要求在大样本条件下进行检验。下面通过例题介绍这种检验方法。

408
例5.2:某棉织厂质量检验部门抽检验了50匹布,每匹布上的疵点数如下:
试检验布匹上的疵点是否服从的泊松分布。(α=0.05 解:如果只检验疵点数的分布,可以用一个样本的K-S检验。即检验假设: H0:布匹上的疵点服从泊松分布, H1:布匹上的疵点不服从泊松分布。 具体检验的操作过程如下: 1、根据原始数据建立数据文件,在其数据编辑窗口单击Analyze Nonparametric Test 1-sample K-S,打开对话框。

409
2、选择检验变量“疵点”进入检验框; 3、在Test Distribution栏中选择检验数据的分布假设,系统默认正态分布,根据本例中的要求,选择泊松分布。 4、在Options对话框中选择输出结果形式及缺失值处理方式。 5、单击OK。 从上面的检验结果可以看出,样本平均值为1.68,由样本计算的统计量为0.569,假设检验的P值为0.902,远远大于0.05,所以可以认定疵点数服从泊松分布,故接受假设H0。

410
如果将要检验布匹上的疵点是否服从λ=1.5.的泊松分布。则要通过Chi-square检验。即检验假设
设λ=1.5,通过泊松分布的分布计算出X取每一值概率并得出理论频数如表。 具体检验步骤如下: 1、打开数据文件,在数据编辑窗口单击Analyze Nonparametric Test Chi-Square Test ,打开Chi-Square Test对话框。 2、指定检验统计量 本例中选择变量疵点进入检验框中。 3、在Expect Values栏内指定理论值,选择Values , 依次输入各组由给定分布所计算的理论值,每输入一个值,点击Add,直到输入全部理论值为止。 4、单击OK,系统运行。

411
从上面的结果可以看出,由样本计算的统计量值为12. 671,P值小于0. 05,故接受H1,认为每匹布的疵点数不是服从λ=1
注意,在这次检验中频数小于5 的值太多,按照卡方检验法的条件,应当适当合并小于5的组,将疵点数大于等于4的观察值合并成一组,再进行检验,在合并时注意定义一个新的变量,给变量值重新编码,主要将变量值大于等于4(有4,5,6三个值)的值赋予同一个码值,即相当于一个组,与之相应的观测频数和理论频数合并相加后,再进行卡方检验,就可以得到最终结果。
的值赋予同一个码值,即相当于一个组,与之相应的观测频数和理论频数合并相加后,再进行卡方检验,就可以得到最终结果。")
412
10.3 两个独立样本的检验(Test for Two Independent Sample)
如果两个无联系总体的分布是未知的,则检验两个总体的均值或分布是否有显著差异的方法是一种非参数检验方法,或者称为两个独立样本的检验。检验是通过两个总体中分别抽取的随机样本数据进行的。下面通过例题解释具体操作过程。 例3:为了调查甲、乙两地的土壤对种植的同一种西瓜有无影响,从这两个产地分别随机抽取同种的8只和7只西瓜,重量(市斤)如下: 试根据样本数据检验两地的土壤对种植西瓜在重量上是否有显著差异。 解:建立假设 H0:甲乙两地的西瓜重量没有显著差异; H1:甲乙两地的西瓜重量有没有显著差异。 然后根据上面给出的数据建立数据文件,注意数据文件中有一个表示重量数据的变量和一个表示地区分组的变量。
如下: 试根据样本数据检验两地的土壤对种植西瓜在重量上是否有显著差异。 解:建立假设 H0:甲乙两地的西瓜重量没有显著差异; H1:甲乙两地的西瓜重量有没有显著差异。 然后根据上面给出的数据建立数据文件,注意数据文件中有一个表示重量数据的变量和一个表示地区分组的变量。")
413
最后在数据编辑窗口进行检验。检验的具体操作过程如下:
1、单击Analyze Nonparametric Test 2 Independent Sample ,打开Two-Independent-Sample对话框如图所示。 2、选择检验的变量进入检验框中,选择分组变量进入Grouping Variable框中,单击Define Group键,打开Define Group对话框。

414
3、在Test Type栏中,确定检验方法。
SPSS中提供了四种检验方式:这四种方式分别是: Mann-Whitney U 曼—惠特尼检验,同时适用于小样本和大样本的情况。 Kolmogorov-Smirnov Z K-S检验,适用于大样本的情况。 Mases Extreme Reactions 极端反应检验,适用于小样本的情况。 Wald-Wolfowitz runs 游程检验,适用于大样本的情况。 这四种检验方法的侧重点有所不同,但都是先将两样本数据混合排序,再从不同的角度分析并检验两个独立总体的分布是否有显著的差异。有时这几种检验结果可能不一样,所以要结合数据的探索分析考察数据的分布状况作出结论。常用的检验方法是 Mann-Whitney U方法,该方法同时适用于大样本和小样本的情况。本例中就选择Mann-Whitney 和Kolmogorov-Smirnov方法。 4、选择输出的结果形式及缺失值处理方式; 5、单击OK,得输出结果。

415
上表中显示的是Mann-Whitney U 曼—惠特尼检验的秩和表,右表中有适用于大小两种样本的统计量,由于例题是小样本的情况,所以选择小样本 U 统计量和精确概率的计算结果,从检验结果知两个地区的西瓜重量上无显著差异。

416
上表显示的是频数表,下表中显示检验结果,从表中看到检验统计量值Z为0.414,P值接近1,故两地种植的西瓜的重量没有显著差异。
因此,上面的两种检验的结论是一致的。即两地种植的同一种西瓜地的重量没有显著差异。

417
10.4 两个有联系样本检验 (Test for Two related samples)
两个有联系的样本检验一般用于比较一个现象在采取了某项措施前后的变化是否显著,或者说采取的措施是否有效。也可以检验同一个测试对象上的两种测试方法是否一致。取n个测试对象作为样本,则样本数据是成对出现的。也可以检验这样两个样本是否服从相同的分布等。这种检验在实际中应用范围很广,如对于一种药品效果比较检验,农业上对于一种新的粮食品种与原有品种的比较检验,工业中新工艺方法、新材料与原方法和材料的比较检验等等。下面通过一个例题说明两个有联系样本的检验方法。 例5.4:一车间为了提高工作效率,对某种零件的加工过程进行改进,为了比较加工时间是否明显减少,抽取15名工人对比他们改革前后零件的加工时间,得到相应的数据如下:试根据数据检验改进后零件的加工时间是否明显减少(α=0.05)? 改进前(m):70,76,56,63,63,56,58,60,65,65,75,66,56,59,70 改进后(m):48,54,60,64,48,55,54,45,51,48,56,48,64,50,54
? 改进前(m):70,76,56,63,63,56,58,60,65,65,75,66,56,59,70. 改进后(m):48,54,60,64,48,55,54,45,51,48,56,48,64,50,54.")
418
解:根据上面的数据建立数据文件SY-15,这显然是两个有联系的样本,故采用两个有联系的样本检验方法。具体操作如下:
建立假设H0:改进前后的零件加工时间没有显著差异; H1:改进前后的零件加工时间明显减少。 1、单击Analyze Nonparametric Test 2 Related Sample ,打开Two Related Sample对话框如图所示。 2、选择检验的两个变量进入检验框中。 3、在Test Type栏中选择检验方式。SPSS中给出了三种检验方法,分别是: Wilcoxon :威尔克科森秩和检验,只给出大样本近似检验概率。 Sign:符号检验,给出精确检验概率。 McNemar:适用于二值变量的检验 本例中选择Wilcoxon和Sign检验。

419
4、在Options框内选择输出结果形式和缺失值处理方式。 5、单击OK,输出结果如表。
Wilcoxon Signed Ranks Test 威尔克科森秩和检验 Sign Test符号检验 威尔克科森秩和检验,检验统计量Z的值为-2.870,假设检验的P值为0.004,小于0.05;而符号检验的频数表和检验表,同样,假设检验的P值为0.035,也小于0.05,故拒绝原假设,认为改进前后的差异是显著的。

420
10.6 多个样本的非参数检验 (K Samples Test)
一、多个独立样本的单因素方差分析 (Test for Saveral Independent Samples) 在总体分布未知的情况下,多个独立样本的检验是检验多个独立总体的平均值是否存在显著的差异。由于总体分布未知,所以检验过程是建立秩的基础上。下面通过例题来说明具体的检验方法。 例 5.6 仍以2002年全国职工平均工资表为例,如果定义一个分组变量,将我国东部、中部和西部各省标上1,2,3作为分组值,下面来考察东部、中部和西部的职工平均工资是否存在显著差异(α=0.05)? 解:建立假设 H0:各地区的职工平均工资没有显著差异; H1:各地区的职工平均工资有显著差异; 可以从分组中得到三个独立的样本数据,显然可以用多个独立样本的检验。 具体操作步骤如下:
 在总体分布未知的情况下,多个独立样本的检验是检验多个独立总体的平均值是否存在显著的差异。由于总体分布未知,所以检验过程是建立秩的基础上。下面通过例题来说明具体的检验方法。 例 5.6 仍以2002年全国职工平均工资表为例,如果定义一个分组变量,将我国东部、中部和西部各省标上1,2,3作为分组值,下面来考察东部、中部和西部的职工平均工资是否存在显著差异(α=0.05)? 解:建立假设. H0:各地区的职工平均工资没有显著差异; H1:各地区的职工平均工资有显著差异; 可以从分组中得到三个独立的样本数据,显然可以用多个独立样本的检验。 具体操作步骤如下:")
421
1.打开数据,在数据窗口单击Analyze Nonparametric Test K Independent Sample ,打开K-Independent-Sample对话框如图所示。
2.选择检验的变量进入检验框中。本例中选择国有单位,城镇集体和港澳台商进入Test Variable List框内。 3.在Test Type栏中选择检验方式。SPSS软件给出两种检验方式,Kruskal-Wallis H检验,利用秩平均建立检验统计量,检验多个独立总体的分布是否存在显著差异。Median中位数检验,利用卡方统计量检验多组样本的中位数差异是否显著。本例中选择Kruskal-Wallis 统计量。 4.在Options对话框内选择输出结果形式和缺失值处理方式。 5.单击OK,输出结果如表。

422
Ranks 秩和表 Test Statistics(a,b) 检验统计表 Ranks 秩和表中给出每个变量各组的秩平均。 Test Statistics(a,b) 检验统计表中给出检验结果,其结果显示:卡方统计量结果显示:国有企业、城镇集体及港澳台商企业这三个变量的职工平均工资在中国的东部、中部和西部地区的的差异都是显著的。
 检验统计表中给出检验结果,其结果显示:卡方统计量结果显示:国有企业、城镇集体及港澳台商企业这三个变量的职工平均工资在中国的东部、中部和西部地区的的差异都是显著的。")
423
二、多个有联系样本的方差分析 (K Related Samples Test)
多个有联系样本的方差分析,又称多个配对样本的检验,是在总体分布未知的情况下,用于比较多个有联系的总体分布的差异性。可以归纳为: 多个有联系的总体是否存在显著差异; 多个评判结果是否存在显著差异(一致性检验); 由于总体分布未知,所以检验都是建立秩和的基础上。下面通过例题来说明具体的检验方法。 例7 对于五个企业生产的同一类型产品,由四个使用单位分别对这些企业生产的产品进行评价,以打分的形式表示评价结果,满分是10 分,得出评价结果如表所示。试检验使用单位的判断标准是否一致(α=0.05)。
; 由于总体分布未知,所以检验都是建立秩和的基础上。下面通过例题来说明具体的检验方法。 例7 对于五个企业生产的同一类型产品,由四个使用单位分别对这些企业生产的产品进行评价,以打分的形式表示评价结果,满分是10 分,得出评价结果如表所示。试检验使用单位的判断标准是否一致(α=0.05)。")
424
解:建立假设H0:使用单位的判断标准没有显著差异;
根据评分表建立数据文件,多个有联系样本检验的具体操作步骤如下 1. 打开数据,在数据窗口单击Analyze Nonparametric Test K Related Samples ,打开K-Related-Samples对话框如图所示。 2.选择检验的变量进入检验框中。本例中选择企业的产品A、B、C、D、E 进 入Test Variable List框内。 3.在Test Type栏中选择检验方式。SPSS软件给出三种检验方式: Friendman检验,适用于等间距变量数据,利用秩平均建立Friendman检验统计量,检验多个有联系的总体的分布是否存在显著差异。原假设是无显著差异。 Kendall′s W 一致性检验,适用于分析评判者的判别标准是否一致。通过Kendall一致性系数W值越接近1,说明评判者的评价标准一致性越好。 Cochran′s Q 检验,适用于二值变量数据,原假设是无显著差异。

425
4. 在Statistics对话框内选择输出结果形式和缺失值处理方式。 5. 单击OK,输出 Kendall's W Test 检验表如表。
Ranks秩 Test Statistics检验统计表 Ranks秩表示每个企业产品的秩平均值, Test Statistics检验统计表输出统计检验的结果可以看出,Kendall一致性系数W比较小,即四个使用单位的评价结果明显是不一致的。

426
例8 某企业为了比较该企业的产品在顾客中的满意程度,同时调查了包括自己企业在内的四种畅销品牌的顾客满意程度,得到数据如表所示:
例8 某企业为了比较该企业的产品在顾客中的满意程度,同时调查了包括自己企业在内的四种畅销品牌的顾客满意程度,得到数据如表所示: 试根据上面调查结果分析,四种品牌之间的差异是否显著(α=0.05)? 解:根据题意建立数据文件.检验假设: H0:四种品牌之间的差异不显著 H1:四种品牌之间的差异显著 检验步骤如下: 1. 打开数据,在数据窗口单击Analyze Nonparametric Test K Related Samples ,打开K-Related-Samples对话框如图所示。 2.选择检验的变量进入检验框中。本例中选择所有变量进入Test Variable List框内。
? 解:根据题意建立数据文件.检验假设: H0:四种品牌之间的差异不显著. H1:四种品牌之间的差异显著. 检验步骤如下: 1. 打开数据,在数据窗口单击Analyze Nonparametric Test K Related Samples ,打开K-Related-Samples对话框如图所示。 2.选择检验的变量进入检验框中。本例中选择所有变量进入Test Variable List框内。")
427
3.在Test Type栏中选择检验方式。本例中的数据是二值变量,故选择Cochran′s Q 检验。
4. 在Statistics对话框内选择输出结果形式和缺失值处理方式。本例中取默认项。 5. 单击OK,输出 Cochran′s Q 检验表如表。 Frequencies频数表 Test Statistics检验表 从检验表中看出,Cochran′s Q统计量值为29.809,假设检验的P值远远地小于0.05,故拒绝H0,认为该企业的产品与其它品牌的差异是显著的。 如果需要,企业还可以与其它品牌进行两两比较分析,读者可以自行做出两个有联系的样本检验。

428
10.6 游程检验(Runs Test) 游程检验可以检验下面两种情况: 单样本变量的取值是否是随机的。 两独立总体的分布是否存在显著差异。
例5:为了鉴别两种操作方法对劳动效率的影响,随机抽取12人用第一种操作方法。10 人用第二种操作方法,每人的日产量见表,试问这两种操作方法有无显著差异? 解:如果两种操作方法差异不显著,则有这两组工人的日产量排列是随机的,故根据表中数据建立数据文件,将两组工人的日产量数据进行统一排序,观察排序后工人所在组的标志值的排列是否是随机的。 建立原假设H0:两种操作方法没有显著差异; 备择假设H1:两种操作方法的差异是显著的。

429
1、单击Analyze Nonparametric TestRuns ,打开Runs Test 对话框如图所示。
2、选择检验的变量:将变量“组别”进入检验框中。 3、在Cut point栏中选择划分二类的检验分类点,系统默认中位数。本例中选择1.5作为检验分类点。 4、在在Options框内选择输出结果形式和缺失值处理方式。 5、单击OK,输出结果见表。

430
由表给出的检验结果知,按照产量排序后,组别标志值的游程为2,由样本计算的检验统计量Z为-4. 417,P值为0. 017,小于0
由表给出的检验结果知,按照产量排序后,组别标志值的游程为2,由样本计算的检验统计量Z为-4.417,P值为0.017,小于0.05,拒绝原假设H0,即认为两种操作方法的差异显著。

Similar presentations

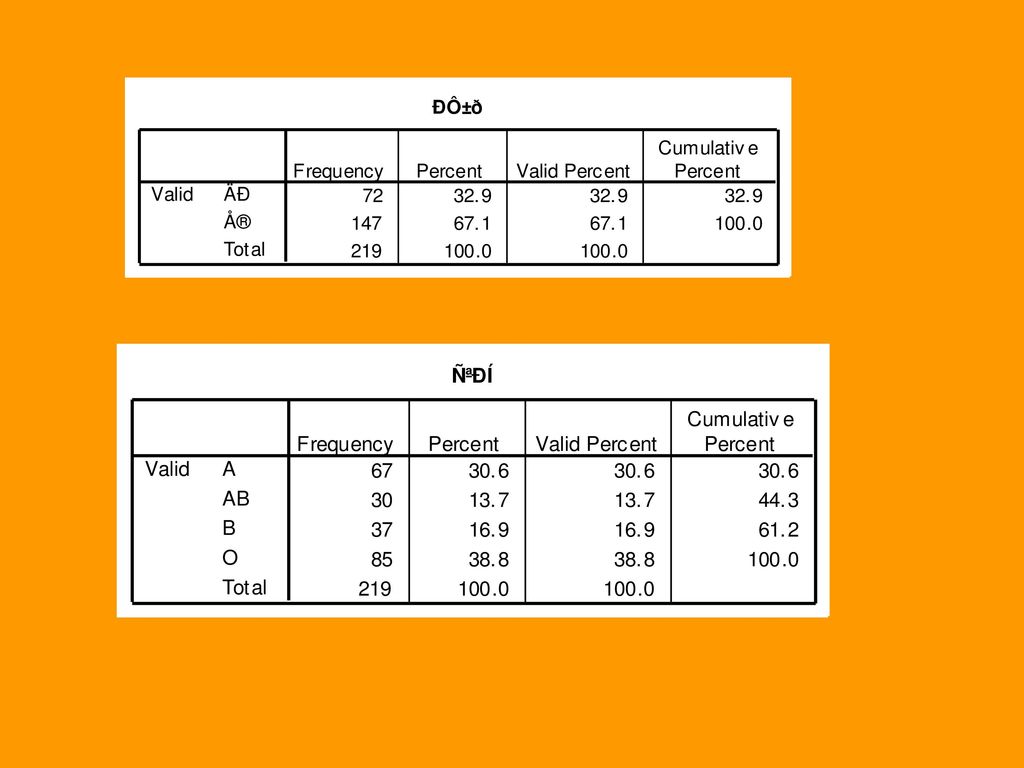
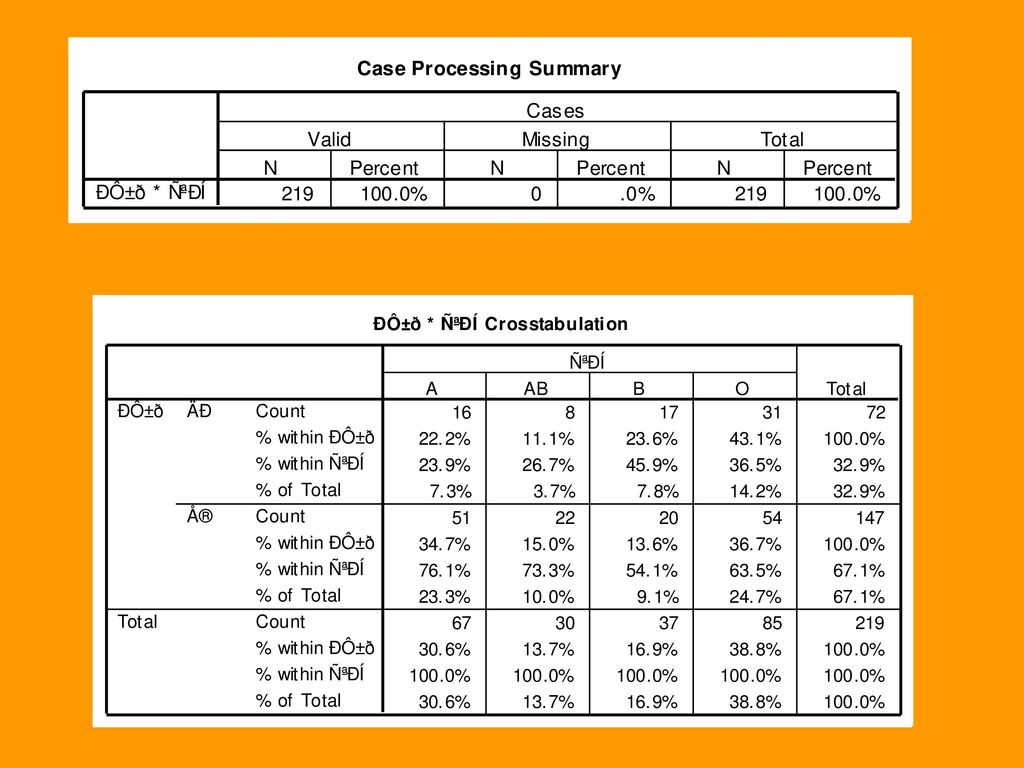
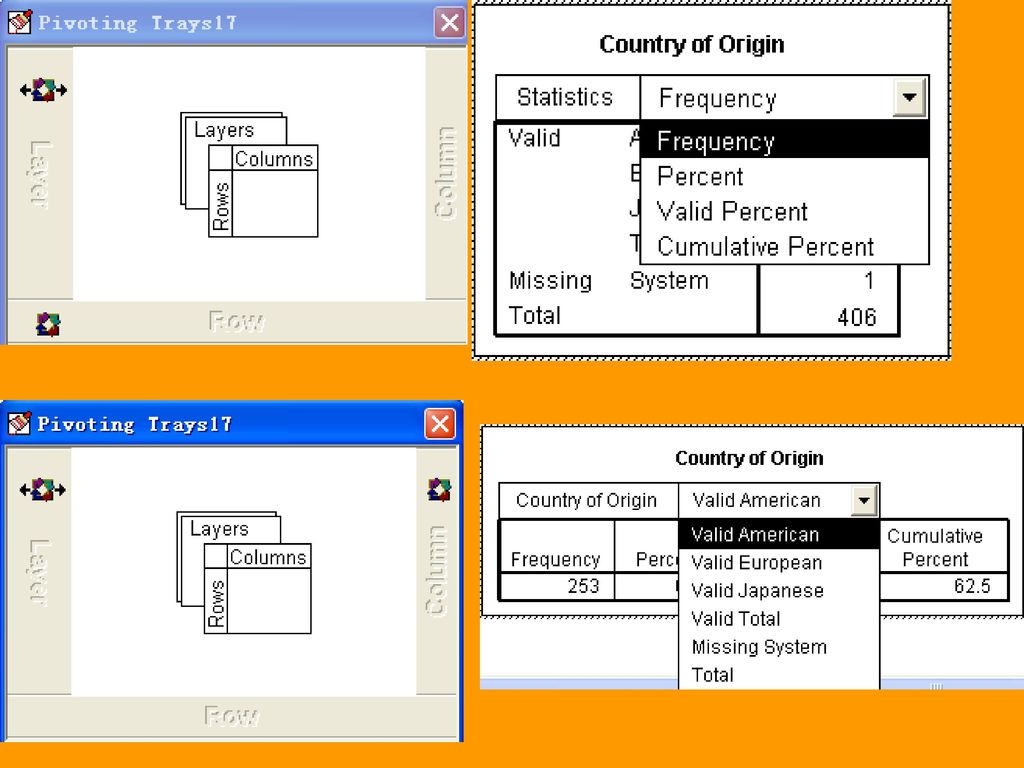








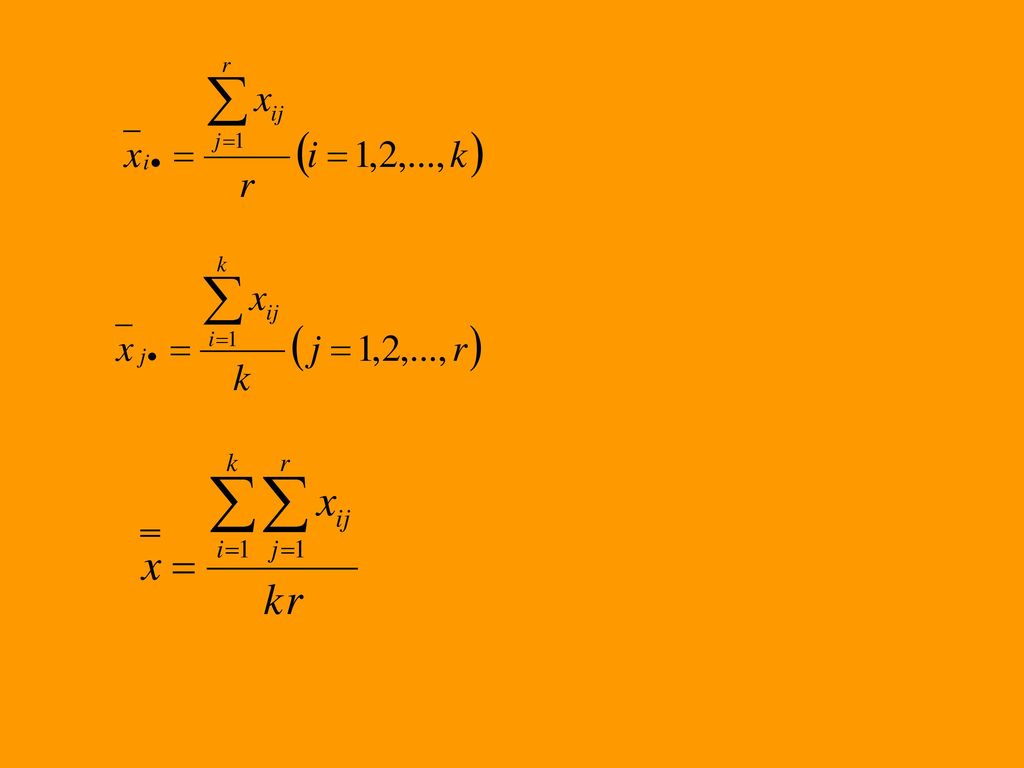
 1 SPSS 的环境与基本操作.>")














 电 话:>")



