Download presentation
Presentation is loading. Please wait.

1
统计学导论

2
第七章 相关与回归分析 第一节 相关与回归分析的基本概念 第二节 简单线性相关与回归分析 第三节 多元线性相关与回归分析
第七章 相关与回归分析 第一节 相关与回归分析的基本概念 第二节 简单线性相关与回归分析 第三节 多元线性相关与回归分析 第四节 Excel在相关与回归分析中的应用

3
第一节 相关与回归分析的基本概念 一、函数关系与相关关系 二、相关关系的种类 三、相关分析与回归分析 四、相关图

4
一、函数关系与相关关系 函数关系:当一个或几个变量取一定的值时,另一个变量有确定值与之相对应。
例如,商品的销售收入Y与该商品的销售量X以及该商品价格P之间的关系。 相关关系:当一个或几个相互联系的变量取一定数值时,与之相对应的另一变量的值虽然不确定,但它仍按某种规律在一定的范围内变化。 例如,劳动生产率与工资水平的关系。

5
变量之间的函数关系和相关关系,在一定条件下是可以互相转化的。
本来具有函数关系的变量,当存在观测误差时,其函数关系往往以相关的形式表现出来。 而具有相关关系的变量之间的联系,如果我们对它们有了深刻的规律性认识,并且能够把影响因变量变动的因素全部纳入方程,这时的相关关系也可能转化为函数关系。

6
相关关系也具有某种变动规律性,所以,相关关系经常可以用一定的函数形式去近似地描述。
客观现象的函数关系可以用数学分析的方法去研究,而研究客观现象的相关关系必须借助于统计学中的相关与回归分析方法。

7
例:判断下列关系是什么关系? 1)物体体积随温度升高而膨胀,随压力加大而压缩; 2)测量次数愈多,其平均长度愈接近实际值; 3)家庭收入愈多,其消费支出也有增长趋势; 4)秤砣的误差愈大,权衡的误差愈大; 5)物价愈上涨,商品的需求量愈小; 6)文化程度愈高,人口平均寿命也愈长; 7)园的半径愈长,园也愈长; 8)农作物产量与雨量、施肥量等有密切关系。
物价愈上涨,商品的需求量愈小; 6)文化程度愈高,人口平均寿命也愈长; 7)园的半径愈长,园也愈长; 8)农作物产量与雨量、施肥量等有密切关系。")
8
二、相关关系的种类 按相关的程度可分为完全相关、不完全相关和不相关。 完全相关:当一种现象的数量变化完全由另一个现象的数量变化所确定时。
相关关系便成为函数关系。也可以说函数关系是相关关系的一个特例。 不相关:当两个现象彼此互不影响,其数量变化各自独立时。 不完全相关:两个现象之间的关系介于完全相关和不相关之间。

9
按相关的方向可分为正相关和负相关。 当一个现象的数量增加(或减少),另一个现象的数量也随之增加(或减少)时,称为正相关。
例如,消费水平随收入的增加而提高。 当一个现象的数量增加(或减少),而另一个现象的数量向相反方向变动时,称为负相关。 例如商品流转的规模愈大,流通费用水平则愈低。
,而另一个现象的数量向相反方向变动时,称为负相关。 例如商品流转的规模愈大,流通费用水平则愈低。")
10
按相关的形式可分为线性相关和非线性相关。

11
按所研究的变量多少可分为单相关、复相关和偏相关。
两个变量之间的相关,称为单相关。 当所研究的是一个变量对两个或两个以上其他变量的相关关系时,称为复相关。 在某一现象与多种现象相关的场合,假定其他变量不变,专门考察其中两个变量的相关关系称为偏相关。例如,在假定人们的收入水平不变的条件下,某种商品的需求与其价格水平的关系就是一种偏相关。

12
三、相关分析与回归分析 相关分析是用一个指标来表明现象间相互依存关系的密切程度。
回归分析是根据相关关系的具体形态,选择一个合适的数学模型,来近似地表达变量间的平均变化关系。 相关分析和回归分析有着密切的联系,它们不仅具有共同的研究对象,而且在具体应用时,常常必须互相补充。

13
相关分析与回归分析之间在研究目的和方法上是有明显区别的。
相关分析研究变量之间相关的方向和相关的程度。 回归分析则是研究变量之间相互关系的具体形式,它对具有相关关系的变量之间的数量联系进行测定,确定一个相关的数学表达式,根据这个数学方程式可以从已知量来推测未知量,从而为估算和预测提供一个重要的方法。 相关分析不必确定变量中哪个是自变量,哪个是因变量,其所涉及的变量可以都是随机变量。 回归分析则必须事先确定哪个为自变量,哪个为因变量。因变量是随机的,而自变量是给定的非随机变量。

14
【例7-1】教堂数与监狱服刑人数同步增长。(引自吴柏林《现代统计学》,吴南图书出版有限公司,1999年版。)
美国印第安纳州的地区教会想要筹款兴建新教堂,提出教堂能洁净人们的心灵,减少犯罪,降低监狱服刑人数的口号。教会的神父收集了近15年的教堂数与在监狱服刑的人数进行统计分析。 结论:最近15年教堂数与监狱服刑人数呈显著的正相关。 也就是说,教堂建得越多,就可能带来更多的犯罪呢? 深入讨论,并进一步收集近15年的当地人口变动资料和犯罪率等资料作进一步分析,发现监狱服刑人数的增加和教堂数的增加都与人口的增加有关。教堂数的增加并非监狱服刑人数增加的原因。至此,教会人士总算松了一口气。

15
四、相关图 相关图又称散点图。它是以直角坐标系的横轴代表变量X,纵轴代表变量Y,将两个变量间相对应的变量值用坐标点的形式描绘出来,用来反映两变量之间相关关系的图形。

16
五、回归分析的种类 1)简单回归分析——是指研究两个变量之间相关关系的回归分析。 线性回归分析:两个变量之间的线性方程
非线性回归分析:两个变量之间的曲线方程 2)多元回归分析——是指研究两个以上变量之间相关关系的回归分析。 多元线性回归分析:一个因变量和多个自变量之间的线性关系
多元回归分析——是指研究两个以上变量之间相关关系的回归分析。 多元线性回归分析:一个因变量和多个自变量之间的线性关系.")
17
第二节 简单线性相关与回归分析 一、相关系数及其检验 二、标准的一元线性回归模型 三、一元线性回归模型的估计 四、一元线性回归模型的检验
第二节 简单线性相关与回归分析 一、相关系数及其检验 二、标准的一元线性回归模型 三、一元线性回归模型的估计 四、一元线性回归模型的检验 五、一元线性回归模型预测

18
一、相关系数及其检验 (一)相关系数的定义 总体相关系数的定义式是 总体相关系数是反映两变量之间线性相关程度的一种特征值,表现为一个常数。
样本相关系数的定义公式是 是根据样本观测值计算的,抽取的样本不同,其具体的数值也会有所差异。样本相关系数是总体相关系数的一致估计量。

19
(二)相关系数的特点 r的取值介于-1与1之间。 当r=0时,X与Y的样本观测值之间没有线性关系。 在大多数情况下,0<|r|<0,即X与Y的样本观测值之间存在着一定的线性关系,当r>0时,X与Y为正相关,当r<0时,X与Y为负相关。 如果|r|=1,则表明X与Y完全线性相关,当r=1时,称为完全正相关,而r=-1时,称为完全负相关。 r是对变量之间线性相关关系的度量。r=0只是表明两个变量之间不存在线性关系,它并不意味着X与Y之间不存在其他类型的关系。

20
(三)相关系数的计算 具体计算样本相关系数时,通常利用以下公式:
相关系数的计算 具体计算样本相关系数时,通常利用以下公式:")
21
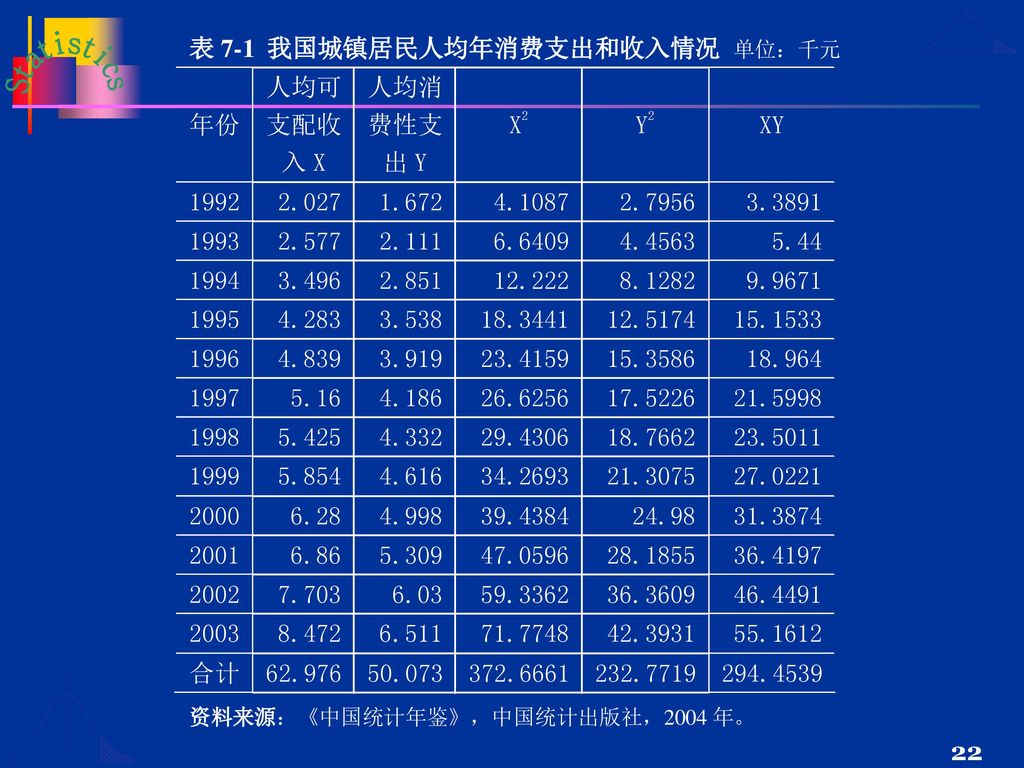
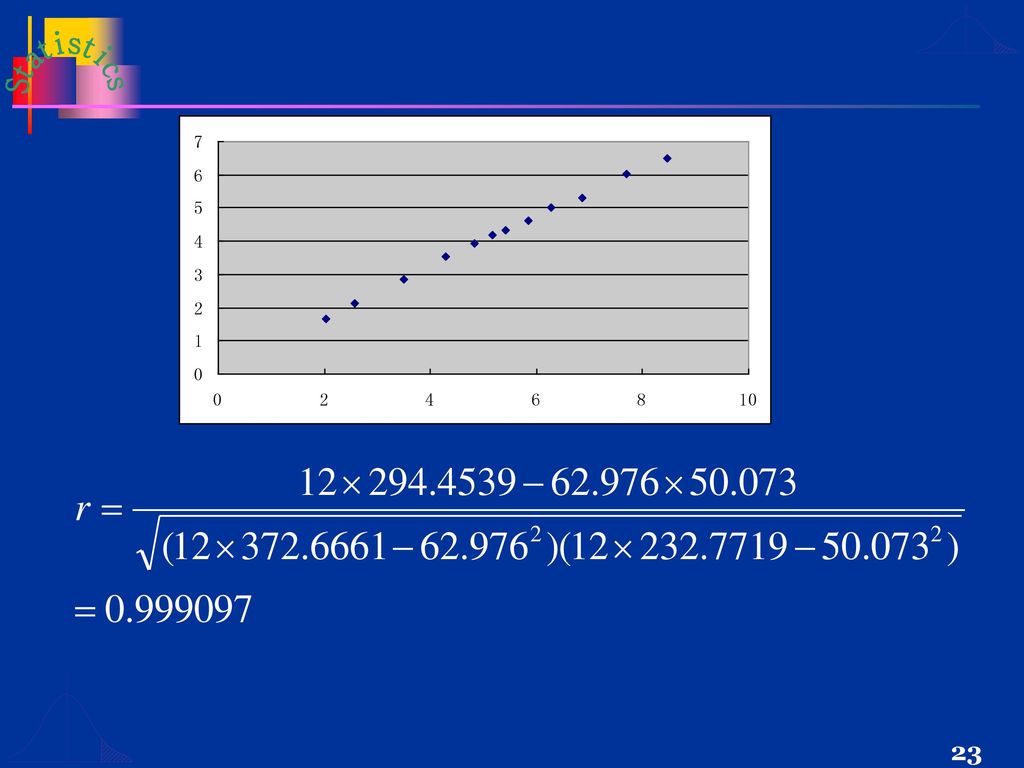
【例7-2】表7-1是 1992年-2003年我国城镇居民人均年消费性支出和人均年可支配收入的有关资料,试计算消费性支出与可支配收入的样本相关系数。

24
(四)相关系数的检验 对总体相关系数 是否等于0进行检验。 计算相关系数r的t值:
对总体相关系数 是否等于0进行检验。 计算相关系数r的t值: 根据给定的显著性水平和自由度(n-2),查找t分布表中相应的临界值tα/2。若|t|≥tα/2,表明r在统计上是显著的。 若|t|≤tα/2,表明r在统计上是不显著的。 ρ
,查找t分布表中相应的临界值tα/2。若|t|≥tα/2,表明r在统计上是显著的。 若|t|≤tα/2,表明r在统计上是不显著的。 ρ.")
25
目的:虚假相关——是指当r趋近于1时,理论上认为变量之间具有高度的相关关系,但实际上这两个变量之间毫无因果关系。

26
【例7-3】假设根据6对样本观测数据计算出某公司的股票价格与气温的样本相关系数r=0

27
解: H0:ρ=0; H1:ρ≠0 r的t检验值 查表可知:显著水平为5%,自由度为4的临界值tα/2=2.776 ,上式中的t值小于2.776,因此,r不能通过显著性检验。这就是说,尽管根据样本观测值计算的r达到0.5,但是由于样本单位过少,这一结论并不可靠,它不足以证明该公司的股票与气温之间存在一定程度的线性相关关系。

28
二、标准的一元线性回归模型 (一)总体回归函数
上式被称为总体回归函数。式中的β1和β2是未知的参数,又叫回归系数。Yt和Xt分别是Y和X的第t个观测值。u t是随机误差项,又称随机干扰项,它是一个特殊的随机变量,反映未列入方程式的其他各种因素对Y的影响。

29
(二)样本回归函数 在现实问题研究中,总体回归函数事实上是未知的,需要利用样本的信息对其进行估计。 一元线性回归模型的样本回归线可表示为: 式中 的是样本回归线上与Xt相对应的Y值,可视为E(Yt)的估计; 是样本回归函数的截距系数, 是样本回归函数的斜率系数,它们是对总体回归系数β1和β2的估计。
的估计; 是样本回归函数的截距系数, 是样本回归函数的斜率系数,它们是对总体回归系数β1和β2的估计。")
30
实际观测到的因变量Yt值,并不完全等于 ,如果用et表示二者之差, 则有:
(t=1,2,...n) 上式称为样本回归函数。式中et称为残差。
 上式称为样本回归函数。式中et称为残差。")
31
样本回归函数与总体回归函数之间的区别。 总体回归线是未知的,它只有一条。而样本回归线则是根据样本数据拟合的,每抽取一组样本,便可以拟合一条样本回归线。 总体回归函数中的β1和β2是未知的参数,表现为常数。而样本回归函数中的 和 是随机变量,其具体数值随所抽取的样本观测值不同而变动。 总体回归函数中的ut是Yt与未知的总体回归线之间的纵向距离,它是不可直接观测的。而样本回归函数中的et是Yt与样本回归线之间的纵向距离,当根据样本观测值拟合出样本回归线之后,可以计算出et的具体数值。

32
(三)误差项的标准假定 假定1:误差项的期望值为0,即对所有的t总有 假定2:误差项的方差为常数,即对所有的t总有 假定3:误差项之间不存在序列相关关系,其协方差为零,即当t≠s时有: 假定4:自变量是给定的变量,与随机误差项线性无关。 假定5:随机误差项服从正态分布。 满足以上标准假定的一元线性模型,称为标准的一元线性回归模型。

33
三、一元线性回归模型的估计 (一)回归系数的点估计 方法:最小二乘法,其依据是使残差平方和为最小
以上方程组称为正规方程组或标准方程组,式中的n是样本容量。求解这一方程组可得: 加以整理后有

34
的意义是什么? 当自变量变动一个单位时,因变量变动的值

35
【例7-4】我们利用例7-2的表7-1中已给出我国历年城镇居民人均消费支出和人均可支配收入的数据,来估计我国城镇居民的边际消费倾向和基础消费水平。
解:Yt=β1+β2Xt+ut =50.073÷ ×62.976÷12=0.2310 样本回归方程为: 上式中:0.7511是边际消费倾向,表示人均可支配收入每增加1千元,人均消费支出会增加0.7511千元;0.2310是基本消费水平,即与收入无关最基本的人均消费为0.2310千元。

36
例:已知某局下10 个企业销售收入与销售利润的数据资料如下:
试求两者 的回归直线 方程。 (单位是万 元)
")
37
解:散点图为:

38
计算表格:

39
代入公式计算得: 则方程为:

40
(二)总体方差的估计 数学上可以证明,σ2的无偏估计S2可由下式给出: 式中,分子是残差平方和,分母是自由度,其中n是样本观测值的个数,2是一元线性回归方程中回归系数的个数。S2的正平方根又叫做回归估计的标准误差。 一般采用以下公式计算残差平方和:

41
【例7-5】根据例7-2中给出的有关数据和例7-4中已得到的回归系数估计值,计算我国城镇居民消费函数的总体方差S2和回归估计标准差S。
解:根据例7-2中给出的有关数据和例7-4中已得到的回归系数估计值,可得: = × × =0.0407 S2=0.0407/(12-2)= 进而有:S=0.0638
= 进而有:S=")
42
(三)最小二乘估计量的性质 1、无偏性: 在标准假定能够得到满足的条件下,回归系数的最小二乘估计量的期望值等于其真值,即有: 2、有效性:回归系数的最小二乘估计量的方差最小;其方差为: 3、一致性:如果随着样本容量的增加, 估计量越来越接近于真值。
最小二乘估计量的性质 1、无偏性: 在标准假定能够得到满足的条件下,回归系数的最小二乘估计量的期望值等于其真值,即有: 2、有效性:回归系数的最小二乘估计量的方差最小;其方差为: 3、一致性:如果随着样本容量的增加, 估计量越来越接近于真值。")
43
(四)回归系数的区间估计 根据第五章中介绍的关于参数区间估计的原理,可得到以下回归系数区间估计的公式: (j =1,2) 式中, 是回归系数估计的样本标准误差, 是显著水平为α,自由度为(n-2)的t分布双侧临界值。
回归系数的区间估计 根据第五章中介绍的关于参数区间估计的原理,可得到以下回归系数区间估计的公式: (j =1,2) 式中, 是回归系数估计的样本标准误差, 是显著水平为α,自由度为(n-2)的t分布双侧临界值。")
44
【例7-6】利用例7-2的有关资料和例7-4与例7-5的结果,对例7-4中估计的我国城镇居民边际消费倾向进行置信度为95%的区间估计。
解: 查t分布表可知:显著水平为5%,自由度为10的t分布双侧临界值是2.228,前面已求得 ,将其代入回归系数区间估计的公式 ,可得:

45
四、一元线性回归模型的检验 (一) 回归模型检验的种类 回归模型的检验包括理论意义检验、一级检验和二级检验。
理论意义检验主要涉及参数估计值的符号和取值区间,如果它们与实质性科学的理论以及人们的实践经验不相符,就说明模型不能很好地解释现实的现象。例如,在前面所举的消费函数中,β2的取值区间应在0至1之间。 在对实际的社会经济现象进行回归分析时,常常会遇到经济意义检验不能通过的情况。造成这一结果的主要原因是:所观测的样本容量有可能偏小,不具有足够的代表性,或者不能满足标准线性回归分析所要求的假定条件。

46
一级检验又称统计学检验,它是利用统计学中的抽样理论来检验样本回归方程的可靠性,具体又可分为拟合程度评价和显著性检验。一级检验是对所有现象进行回归分析时都必须通过的检验。
二级检验又称经济计量学检验,它是对标准线性回归模型的假定条件能否得到满足进行检验,具体包括序列相关检验、异方差性检验、多重共线性检验等。二级检验对于社会经济现象的定量分析具有特别重要的意义。

47
(二)拟合程度的评价 总离差平方和的分解 对任一实际观测值Yt总有: 对上式两边取平方并求和,得到: 可以证明: 从而有: 即 SST=SSR+SSE 自由度 n r n-r-1

48
用图表示: y x 回归直线 Y的平均数

49
是可以由回归直线 作出解释的部分 各自的意义: 总变差(SST)剩余变差(SSE)回归变差(SSR) 说明了各观察 表示实际值围 表示估计值与 值与平均值的 绕回归直线的 平均值的离差 离差平方和。 变动程度。它 平方和。说明 是除了x对y的 了x变动引起 线性影响外其 估计值变动的 它随机因素所 程度。 引起y的变动。 是回归直线 不能解释的 部分。

50
上式中,SST是总离差平方和;SSR是由回归直线可以解释的那一部分离差平方和,称为回归平方和;SSE是用回归直线无法解释的离差平方和,称为残差平方和。式子两边同除以SST,得:
决定(可决)系数,即有: 决定系数是对回归模型拟合程度的综合度量,决定系数越大,模型拟合程度越高。决定系数越小,则模型对样本的拟合程度越差。
系数,即有: 决定系数是对回归模型拟合程度的综合度量,决定系数越大,模型拟合程度越高。决定系数越小,则模型对样本的拟合程度越差。")
51
决定系数r2具有如下特性: 1.决定系数r2具有非负性。 2.决定系数的取值范围为0≤ r2 ≤1。 3.决定系数是样本观测值的函数,它也是一个统计量。 4.在一元线性回归模型中,决定系数是相关系数的平方。 二者适用范围不同:可决系数适用更广。

52
【例7-7】利用例7-5中计算的残差平方和,计算例7-3所拟合的样本回归方程的决定系数。
解: 上式中的SST是利用表7-1中给出的数据按下式计算的:

53
可决系数的实际意义是: 在人均消费性支出的变差中,有99.82%可以由人均消费性支出与人均可支配收入之间的线性关系来解释,或者说,在人均消费性支出取值的变动中,有99.82%是由人均可支配收入所决定的。可见人均消费性支出与人均可支配收入之间有较强的线性关系 。

54
(三)显著性检验 所谓回归系数的显著性检验,就是根据样本估计的结果对总体回归系数的有关假设进行检验。 下面我们以β2的检验为例,介绍回归系数显著性检验的基本步骤:
显著性检验 所谓回归系数的显著性检验,就是根据样本估计的结果对总体回归系数的有关假设进行检验。 下面我们以β2的检验为例,介绍回归系数显著性检验的基本步骤:")
55
1.t检验 (1)提出假设。 式中,Ho表示原假设;H1表示备择假设; 是假设的总体回归系数的真值。 在许多回归分析的计算机程序里,令 =0。这是因为β2 是否为0,可以表明X对Y是否有显著的影响。
提出假设。 式中,Ho表示原假设;H1表示备择假设; 是假设的总体回归系数的真值。 在许多回归分析的计算机程序里,令 =0。这是因为β2 是否为0,可以表明X对Y是否有显著的影响。")
56
(2)确定显著水平α。 显著水平的大小应根据犯哪一类错误可能带来损失的大小确定。一般情况下可取0.05。 (3)计算回归系数的t值。 上式中,是回归系数估计的标准误差。
确定显著水平α。 显著水平的大小应根据犯哪一类错误可能带来损失的大小确定。一般情况下可取0.05。 (3)计算回归系数的t值。 上式中,是回归系数估计的标准误差。")
57
(4)确定临界值。 t检验的临界值是由显著水平和自由度df决定的。 对H0:β2=0,H1:β2≠0,进行的是双侧t检验;对H0:β2=0.9,H1:β2<0.9,进行的是单侧t检验。 (5)做出判断。 如果的绝对值大于临界值的绝对值,就拒绝原假设,接受备择假设;反之,如果的绝对值小于临界值的绝对值,则接受原假设。

58
2.p检验 回归系数的显著性检验还可以采用p检验。其前三步与t检验相同,但t值计算出来之后,计算自由度为n-2的t统计量大于或小于根据样本观测值计算数值的概率即p值。 然后将其与给定的显著水平α对比,如果p小于α,则拒绝原假设,反之则接受原假设。利用Excel进行回归分析时,计算机将直接给出回归系数估计的p值。

59
注意:在一元线性回归中,类似于T检验;在多元线性回归中有其独立的意义。
3、F检验 假设: 检验统计量: 临界值: 注意:在一元线性回归中,类似于T检验;在多元线性回归中有其独立的意义。 分母是估计值的 标准误差

60
【例7-8】利用例7-4和例7-6的有关资料和结果,对例7-4中估计的我国城镇居民边际消费倾向进行显著性检验。
(1)以5%的显著水平检验可支配收入是否对消费支出有显著影响。 (2)对Ho:β2=0.8,H1:β2<0.8进行检验。
以5%的显著水平检验可支配收入是否对消费支出有显著影响。 (2)对Ho:β2=0.8,H1:β2<0.8进行检验。")
61
解: (1) H0:β2=0,H1:β2≠0 其次,计算t值 =0.7511/0.0098= 查t分布表可知:显著水平为5%,自由度为10的双侧t检验的临界值是2.228。以上计算的t值远远大于此临界值,所以拒绝原假设,接受备择假设,即认为可支配收入对消费支出的影响是非常显著的。 (2)Ho:β2=0.8,H1:β2<0.8 =( )/0.0098= 查t分布表可知:显著水平为5%, 自由度为10的单侧t检验的临界值是1.812。因为计算的t值的绝对值大于此临界值,所以否定β2=0.8的原假设,接受备择假设,认为我国城镇居民的平均消费倾向小于0.8。
Ho:β2=0.8,H1:β2<0.8. =( )/0.0098= 查t分布表可知:显著水平为5%, 自由度为10的单侧t检验的临界值是1.812。因为计算的t值的绝对值大于此临界值,所以否定β2=0.8的原假设,接受备择假设,认为我国城镇居民的平均消费倾向小于0.8。")
62
例:生产费用与产量的回归问题,计算数据为:
作F检验。 解:计算得:

63
查F分布表得: 因为 所以,检验结果特别显著。

64
五、一元线性回归模型预测 (一)回归预测的基本公式 简单回归预测的基本公式如下: 式中,Xf是给定的X的具体数值;是Xf给定时Y的预测值;
回归预测是一种有条件的预测,在进行回归预测时,必须先给出Xf的具体数值。当给出的Xf属于样本内的数值时,利用该式去计算 称为内插检验或事后预测。而当给出的Xf在样本之外时,利用该式去计算称 为外推预测或事前预测。通常所说的预测是指事前预测。

65
在实际的回归模型预测中,发生预测误差的原因可以概括为以下四个:
(二)预测误差 在实际的回归模型预测中,发生预测误差的原因可以概括为以下四个: 1.模型本身中的误差因素所造成的误差;这一误差可以用总体随机误差项的方差来评价。 2.由于回归系数的估计值同其真值不一致所造成的误差;这一误差可以用回归系数的最小二乘估计量的方差来评价。 3.由于自变量X的设定值同其实际值的偏离所造成的误差。 4.由于未来时期总体回归系数发生变化所造成的误差。 在以上造成预测误差的原因中,3、4、两项不属于回归方程本身的问题,而且也难以事先予以估计和控制。因此,在下面的讨论中,假定只存在1、2、两种误差。
预测误差. 在实际的回归模型预测中,发生预测误差的原因可以概括为以下四个: 1.模型本身中的误差因素所造成的误差;这一误差可以用总体随机误差项的方差来评价。 2.由于回归系数的估计值同其真值不一致所造成的误差;这一误差可以用回归系数的最小二乘估计量的方差来评价。 3.由于自变量X的设定值同其实际值的偏离所造成的误差。 4.由于未来时期总体回归系数发生变化所造成的误差。 在以上造成预测误差的原因中,3、4、两项不属于回归方程本身的问题,而且也难以事先予以估计和控制。因此,在下面的讨论中,假定只存在1、2、两种误差。")
66
设Xf给定时Y的真值为Yf, Yf=β1+β2Xf+uf
则有 式中,ef是预测的残差。利用期望值与方差的运算规则以及前面给出的回归系数最小二乘估计量的期望值和方差,可以证明: 在此基础上,还可以进一步证明 是Yf的最优线性无偏预测,即在标准假定能够满足的情况下,公式 是Yf的最佳预测方式。

67
(三)区间预测 若用Sef来表示预测标准误差的估计值, 则数学上可以证明: 服从于自由度为(n-2)的t分布。按照确定置信区间的方法,可以得出Yf的(1-α )的置信区间为: 式中, 是置信度为(1-α ) 、自由度为(n-2)的t分布的临界值。
 、自由度为(n-2)的t分布的临界值。")
68
对于每一个给定的X值,计算相应的Y的置信区间,并将连接各点的曲线描绘在平面图上,便可得到右图。
从置信区间和Sef的计算公式以及右图,可以得到以下结论: 回归预测的置信区间

69
第一,置信区间的上下限对称地落在样本回归直线两边, 呈中间小两头大的喇叭型。当Xf= 时的置信区间最窄,而当Xf远离 时,其置信间逐渐增大。这就是说,在用回归模型进行预测时,X f的取值不宜离开 过远,否则预测精度将会降低,有可能使预测失效。 第二,在样本容量n保持不变时, 的值,随置信度(1-α ) 的提高而增加,因此,要求预测值的概率保证程度增加,在 其它条件不变时,也就意味着预测精度的降低。 第三,当其它条件不变时, 和Sef的值均为样本容量n的 减函数,即随着n的增加,这二者将逐渐减少。这说明随着 样本容量的增加,预测精度将会提高,而样本容量过小,预 测的精度就较差。
 的提高而增加,因此,要求预测值的概率保证程度增加,在 其它条件不变时,也就意味着预测精度的降低。 第三,当其它条件不变时, 和Sef的值均为样本容量n的 减函数,即随着n的增加,这二者将逐渐减少。这说明随着 样本容量的增加,预测精度将会提高,而样本容量过小,预 测的精度就较差。")
70
第四,当n足够大时, Sef会趋近于S; 会趋近于zα/2。(zα/2是置信度为(1-α)的标准正态分布的临界值)。 这时,可以用S和zα/2取代Sef和tα/2来确定预测区间。即样本容量充分大时,Yf的(1-α)的置信区间为: Yf±zα/2×S

71
【例7-9】假定已知某居民家庭的年人均可支配收入为8千元,要求利用例7-4中拟合的样本回归方程与有关数据,计算置信度为95%的年人均消费支出的预测区间。
解:将有关数据代入拟合好的样本回归方程,可得: 从前面几例的结果可知:S = , n=12 将其代入求预测标准误差估计值的公式,有 查t分布表可知:显著水平为5%,自由度为10的双侧t检验的临界值是2.228。因此,当人均可支配收入为8千元时,置信度为95 %的消费支出的预测区间如下: 6.2398-2.228× ≤ Yf ≤ +2.228×0.0717 (千元) ≤ Yf ≤ (千元)
 ≤ Yf ≤ (千元)")
72
例:产量与生产费用的问题,计算数据为: 回归直线方程为: 当某工厂的产量为130千个时,在显著水平为95%时,对该厂生产费用进行预测。

73
解:

74
例:销售收入与销售利润的回归问题,计算数据为
其回归直线方程为: 当销售收入为40万元时,在95%的显著水平下,对销售利润进行预测。

75
解:

76
例:某市的人口数与猪肉销售量的资料如表所示。
1)求人口数对猪肉销售量的回归直线方程。 2)对1)所求的直线作相关检验。 3)若来年人口数为56.9万人时,预测猪肉销售量将达到多少?显著水平为95%。
求人口数对猪肉销售量的回归直线方程。 2)对1)所求的直线作相关检验。 3)若来年人口数为56.9万人时,预测猪肉销售量将达到多少?显著水平为95%。")
77
资料表为:

78
解: 1)散点图:
散点图:")
79
2)直线方程的计算表为:
直线方程的计算表为:")
80
直线方程为: 即:

81
3)相关系数的检验: n=10,查表得: 因为 所以,检验结果两个变量之间特别显著。
相关系数的检验: n=10,查表得: 因为 所以,检验结果两个变量之间特别显著。")
82
4)预测:
预测:")
83
第三节 多元线性相关与回归分析 一、标准的多元线性回归模型 二、多元线性回归模型的估计

84
一、标准的多元线性回归模型 研究在线性相关条件下,两个和两个以上自变量对一个因变量的数量变化关系,称为多元线性回归分析,表现这一数量关系的数学公式,称为多元线性回归模型。 多元线性回归模型总体回归函数的一般形式如下: 多元线性回归模型的样本回归函数如下: (t=1,2,…,n) 上式中,et是Yt与其估计之间的离差,即残差。 多元线性回归分析的标准假定除了包括上一节中已经提出的关于随机误差项的假定外,还要追加一条假定。这就是回归模型所包含的自变量之间不能具有较强的线性关系,同时样本容量必须大于所要估计的回归系数的个数即n>k。我们称这条假定为标准假定6。
 上式中,et是Yt与其估计之间的离差,即残差。 多元线性回归分析的标准假定除了包括上一节中已经提出的关于随机误差项的假定外,还要追加一条假定。这就是回归模型所包含的自变量之间不能具有较强的线性关系,同时样本容量必须大于所要估计的回归系数的个数即n>k。我们称这条假定为标准假定6。")
85
二、多元线性回归模型的估计 (一)回归系数的估计 多元线性回归模型中回归系数的估计同样采用最小二乘法。设
根据微积分中求极小值的原理,可知残差平方和Q存在极小值,欲使Q达到最小,Q对 的偏导数必须等于零。将Q对 求偏导数,并令其等于零,加以整理后可得到以下k个方程式: 以上k元一次方程组称为正规方程组或标准方程组,通过求解这一方程组便可以得到 。

86
(二)总体方差的估计 多元线性回归模型中的σ2也是利用残差平方和除以其自由度来估计的。即有: 上式中,n是样本观测值的个数;k是方程中回归系数的个数;数学上可以证明,S2是σ2的无偏估计。S2的正平方根S又叫做回归估计的标准误差。 S越小表明样本回归方程的代表性越强。 其简化公式(对二元线性回归方程)
")
87
(三)最小二乘估计量的性质 在标准的多元线性回归模型中,高斯.马尔可夫定理同样成立。
最小二乘估计量的性质 在标准的多元线性回归模型中,高斯.马尔可夫定理同样成立。")
88
三、多元线性回归模型的检验和预测 (一)拟合程度的评价 利用R2来评价多元线性回归方程的拟合程度,必须注意以下问题。
在样本容量一定的条件下,总离差平方和与自变量的个数无关,而残差平方和则会随着模型中自变量个数的增加不断减少,至少不会增加。因此, R2是自变量个数的非递减函数。 然而在多元线性回归模型中,各回归模型所含的变量的数目未必相同,以R2的大小作为衡量拟合优劣的尺度是不合适的。

89
在多元回归分析中,人们更常用的评价指标是所谓的修正自由度的决定系数。 该指标的定义如下:
式中,n是样本容量;k是模型中回归系数的个数。( n -1)和( n - k )实际上分别是总离差平方和与残差平方和的自由度。
和( n - k )实际上分别是总离差平方和与残差平方和的自由度。")
90
修正自由度的决定系数具有以下特点: 。因为k≥1,所以根据 和R2各自的定义式可以得出这一结论。对于给定的R2值和n值, k值越大 越小。在进行回归分析时,一般总是希望以尽可能少的自变量去达到尽可能高的拟合程度。 作为综合评价这两方面情况的一项指标显然比R2更为合适。 小于1,但未必都大于0。在拟合极差的场合,有可能取负值。

91
【例7-10】假设有7年的年度统计资料,现利用其对同一因变量拟合了两个样本回归方程。方程一中:k=6, R2=0
【例7-10】假设有7年的年度统计资料,现利用其对同一因变量拟合了两个样本回归方程。方程一中:k=6, R2=0.82;方程二中:k=2, R2 =0.80。试对这两个回归方程的拟合程度做出评价。 解:如果仅从R2考察,似乎方程一的拟合程度更佳。但是,由于两个方程选用的自变量个数不同,这一结论是不正确的。将上列数据代入修正自由度的决定系数 公式,可得: 方程一的 =1-((7-1)/(7-6))(1-0.82)=-0.08 方程二的 =1-((7-1)/(7-2))(1-0.80)=0.76 由此可见,方程二的实际拟合程度远远优于方程一。
/(7-6))(1-0.82)= 方程二的 =1-((7-1)/(7-2))(1-0.80)=0.76. 由此可见,方程二的实际拟合程度远远优于方程一。")
92
(二)显著性检验 1.回归系数的显著性检验 多元回归中进行这一检验的目的主要是为了检验与各回归系数对应的自变量对因变量的影响是否显著,以便对自变量的取舍做出正确的判断。一般来说,当发现某个自变量的影响不显著时,应将其从模型中删除。这样才能够做到以尽可能少的自变量去达到尽可能高的拟合优度。 多元模型中回归系数的检验同样采用t检验和P检验,其原理和基本步骤与一元回归模型基本相同,这里不再赘述。下面仅给出回归系数显著性检验t统计量的一般计算公式。

93
j=1,2,…,k 式中, 是回归系数的估计值, 是的标准差的估计值,其按下式计算: 式中, 是(X’X)-1的第j个对角线元素,S2是随机误差项方差的估计值。上式的 t 统计量背后的原假设是H0:βj=0,因此 t 的绝对值越大表明βj为0的可能性越小,即表明相应的自变量对因变量的影响是显著的。
-1的第j个对角线元素,S2是随机误差项方差的估计值。上式的 t 统计量背后的原假设是H0:βj=0,因此 t 的绝对值越大表明βj为0的可能性越小,即表明相应的自变量对因变量的影响是显著的。")
94
2.回归方程的显著性检验 必须在方差分析的基础上利用F检验进行。其具体的方法步骤可归纳如下: (1)假设总体回归方程不显著,即有 H0:β2=β3=……=βk=0 (2)进行方差分析,列出回归方差分析表(见下表)
进行方差分析,列出回归方差分析表(见下表) .")
95
回归模型方差分析表 表中, 回归平方和的取值受k个回归系数估计值的影响,同时又要服从 的约束条件,因此其自由度是k-1。残差平方和取决于n个因变量的观测值,同时又要服从k个正规方程式的约束,因此其自由度是n-k。 回归平方和与残差平方和各除以自身的自由度得到的是样本方差。

96
(3)根据方差分析的结果求F统计量,即 数学上可以证明,在随机误差项服从正态分布同时原假设成立的条件下,F服从于自由度为(k-1)和(n-k)的F分布。 (4)根据自由度和给定的显著性水平α,查F分布表中的理论临界值Fα。当F > Fα时,拒绝原假设,即认为总体回归函数中各自变量与因变量的线性回归关系显著。当F < Fα时,接受原假设,即认为总体回归函数中,自变量与因变量的线性关系不显著,因而所建立的回归模型没有意义。
根据自由度和给定的显著性水平α,查F分布表中的理论临界值Fα。当F > Fα时,拒绝原假设,即认为总体回归函数中各自变量与因变量的线性回归关系显著。当F < Fα时,接受原假设,即认为总体回归函数中,自变量与因变量的线性关系不显著,因而所建立的回归模型没有意义。")
97
(三)多元线性回归预测 在通过各种检验的基础上,多元线性回归模型可以用于预测。多元线性回归预测与一元线性回归预测的原理是一致的,其基本公式如下: 式中,Xjf(j=2,3,……k)是给定的Xj在预测期的具体数值; 是已估计出的样本回归系数; 是Xj给定时Y的预测值。 该方程的矩阵形式为:

98
式中: 多元线性回归预测标准误差的计算公式如下: 式中,S是回归方程估计的标准误差。 多元线性回归预测Yf的(1-α)的置信区间可由下式给出: 式中,tα/2是显著水平为α的t分布双侧临界值。
的置信区间可由下式给出: 式中,tα/2是显著水平为α的t分布双侧临界值。")
99
四、复相关系数和偏相关系数 (一)复相关系数 样本复相关系数(以下简称复相关系数)的定义式如下:
实际计算复相关系数时,一般不直接根据其定义式,而是先计算出决定系数,然后再求决定系数的平方根。 复相关系数只取正值。因此,复相关系数只是反映一个变量Y与其他多个变量X2,X3,……,Xk之间线性相关程度的指标,而不能反映其相互之间线性相关的方向。 复相关系数的取值区间为:0≤R≤1。

100
(二)偏相关系数 在对其他变量的影响进行控制的条件下,衡量多个变量中某两个变量之间的线性相关程度和相关方向的指标称为偏相关系数。 在多变量相关的场合,由于变量之间存在错综复杂的关系,因此偏相关系数与单相关系数在数值上可能相差很大,有时甚至符号都可能相反。单相关系数受其他因素的影响,反映的往往是表面的非本质的联系,而偏相关系数则较能说明现象之间真实的联系。例如,一种商品的需求既受收入水平的影响又受其价格的影响。按照经济学理论,在一定的收入水平下,该商品的价格越高,商品的需求量就越小。也就是说,需求与价格之间应当是负相关。可是,在现实经济生活中,由于收入和价格常常都有不断提高的趋势,如果不考虑收入对需求的影响,仅仅利用需求和价格的时间序列数据去计算单相关系数,就有可能得出价格越高需求越大的错误结论。

101
样本单相关系数也可定义为两个样本回归系数的乘积的开方,即:
上式中r的符号应与回归系数的符号一致。回归系数为正数时, r取正值;回归系数为负数时, r取负值。 样本偏相关系数也可以按照类似的形式来定义,即偏相关系数等于两个相应的偏回归系数的几何平均数。 为简明起见,下面举3变量的偏相关分析为例。设有3个变量X1、X2和X3。3个变量各自以另两个变量为自变量拟合的样本回归方程如下:

102
利用以上偏回归系数,3个变量之间的偏相关系数可定义如下:
偏相关系数的取值范围与单相关系数一样也是在-1至+1之间,其符号与相应的偏回归系数相同。

103
以上偏相关系数的定义可以推广到k个变量的场合。在进行实际的客观现象的定量分析时,人们所关心的通常是某一个因变量Y 与多个自变量之间的偏相关程度。这时若令Y为X1,则Y与各自变量的偏相关系数的一般形式可表现为: 式中, 是Y对Xj的偏回归系数; 是Xj对Y的偏回归系数。 表示k个变量情况下Y与Xj的偏相关系数,它反映其他自变量保持不变时Y与Xj的净相关程度。

104
第四节 Excel在相关与回归分析中的应用
【例7-11】Checkers Pizza公司是美国休斯顿附近Westbury镇上仅有的从事家庭比萨饼送货业务的两家公司之一,另一家竞争者欧文公司也提供同样的产品与服务。此外,麦当劳连锁店提供的汉堡包等服务属于替代性商品,同样与公司存在竞争关系。 公司的经理安妮知道她的顾客对于价格是非常敏感的,镇上的比萨饼购买者很关注她与她的竞争者的价格变化。安妮决定估计她的比萨饼经验需求函数。她收集了过去24个月的有关数据(参见Excel文件)。 注:本案例数据引自美国S.Charles Maurice和Christopher R.Thomas 《管理经济学》(第7版)中译本207页,.陈章武等译,机械工业出版社2003年8月。
。 注:本案例数据引自美国S.Charles Maurice和Christopher R.Thomas 《管理经济学》(第7版)中译本207页,.陈章武等译,机械工业出版社2003年8月。")
105
要求 : 答案见Excel文件 1.绘制本公司比萨饼的需求量与价格的相关图。 2.估计以下线性需求模型的参数,并进行统计检验;
3.计算本公司比萨饼的需求量与上述模型中其他各变量的单相关系数;计算本公司比萨饼的需求量与小镇居民人均收入的偏相关系数。 4.假定小镇居民的人均年收入为29000美元,欧文公司和麦当劳公司商品的价格分别为:10.5美元和1.3美元,本公司价格维持9.75美元,试预测本公司比萨饼的需求量,并给出置信度为95%的预测区间。 答案见Excel文件

Similar presentations





![桐乡市地方税务局 2013 年度社会保险费汇算清缴有 关政策及事项说明. 一、政策规定 根据《中华人民共和国社会保险法》、《桐乡市社会保险费征缴管 理办法》(市政府令第 42 号)、《 关于完善社会保险费征缴管理有关问 题的通知》(桐政办发 [2012]152 号)及《关于完善社会保险费征缴管理.](/40/11070600/big_thumb.jpg "桐乡市地方税务局 2013 年度社会保险费汇算清缴有 关政策及事项说明. 一、政策规定 根据《中华人民共和国社会保险法》、《桐乡市社会保险费征缴管 理办法》(市政府令第 42 号)、《 关于完善社会保险费征缴管理有关问 题的通知》(桐政办发 [2012]152 号)及《关于完善社会保险费征缴管理.>")



财务验收 五、项目(课题)财务验收 2.>")
 一般结构(框架) 1 、课题名称 2 、研究目的和意义 3 、研究的基本内容 ( 1 )理论研究(细分为若干子项目) ( 2 )实践研究( 细分为若干子项目)>")








