資料分析 ---敘述統計分析
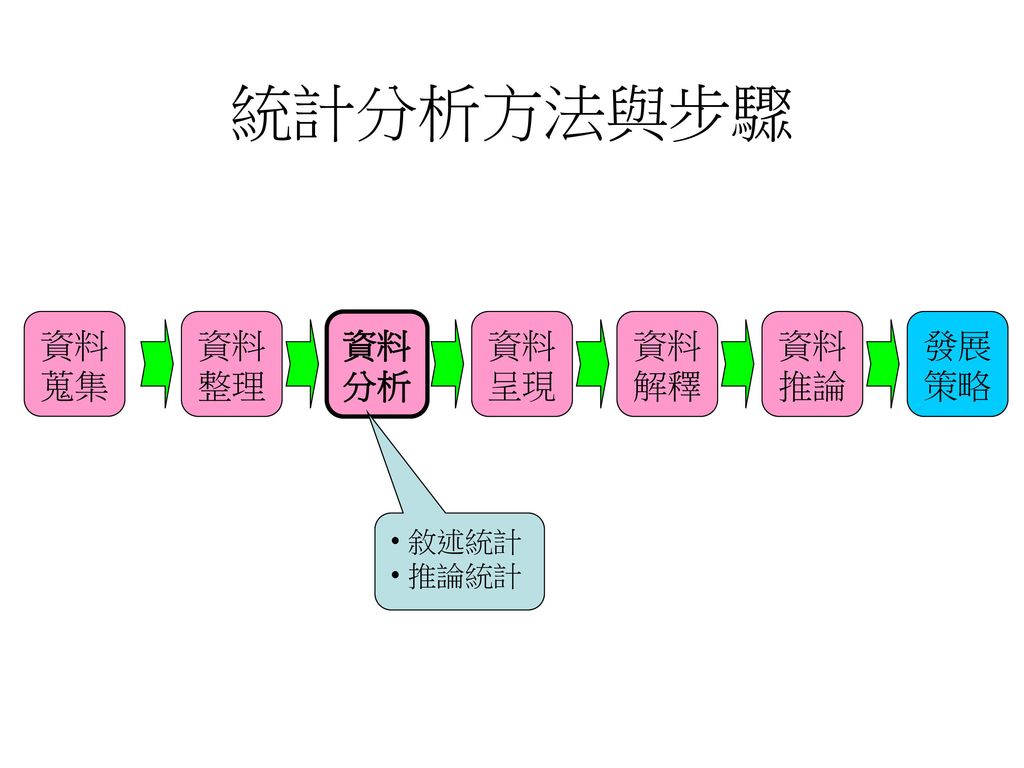
統計分析方法與步驟 資料 蒐集 資料 整理 資料 分析 資料 呈現 資料 解釋 資料 推論 發展 策略 敘述統計 推論統計 2
資料分析 敘述統計 統計測量值(統計量數) 利用具代表性的特徵說明整體資料 參數(母數)與統計量數 (一)中央趨勢(central tendency (二)分散度衡量(measures of dispersion)(離散趨勢量數) (差異量數) (三)峰態與偏態
資料分析 統計量數 (一)中央趨勢(central tendency)(集中趨勢量數) 呈現資料分配之中心位置或共同趨勢。而常用的中央趨勢測量值分為平均數、中位數、眾數、百分位數、四分位數等五種。 (1)眾數(mode) (2)中位數(mediam) (a)四分位數(quartiles) (b)百分位數(percentile) (3)平均數(mean)
資料分析 統計量數 (二)離散趨勢(measures of dispersion) (1)全距(range) (2)四分位距(interquartile range,IOQ) (3)變異數(variance) (4)標準差(standard deviation) (5)變異係數(coefficient of variance )
資料分析 統計量數 (三)平均數與標準差之應用 (四)離群值之判定 (五)兩變量相關性之統計測量值 (1)變異係數(coefficient of variance ) (2)Z分數(Z-score) (3)柴比雪夫定理(Chebyshev’s Theory) (4)經驗法則(the empirical rule) (四)離群值之判定 (1)Z分數判定法 (2)盒形圖判定法 (五)兩變量相關性之統計測量值 (1)共變異數(covariance) (2)相關係數(correlation coefficient )
資料分析 (一)集中趨勢(central tendency) (1)眾數(mode): 樣本或母體中出現次數最多且大於1 次的 數。 眾數可能不只一個。 要先排序 。
資料分析 (一)集中趨勢(central tendency) (1)眾數(mode): 已知樣本資料A為{6, 7, 5, 7, 4, 3, 7, 3},B為{1, 2, 4, 7, 5},C為{1, 2, 2, 3, 4, 3},求樣本資料A、B、C之眾數為何? a.因為7出現於樣本資料A共 3次為出現最多次之資料,所以資料A之眾數為7。 b.因為樣本資料B之資料值均只出現一次,因此沒有 眾數。 c.因為2及3均出現於樣本資料C有2次,其餘資料值僅出現一次,所以資料C之眾數為2及3。
資料分析 (一)集中趨勢(central tendency) (2)中位數(mediam): 中間位置的數 也要先排序 將一群數字區分為相等(個數)的兩部份 二分位數
資料分析 (一)集中趨勢(central tendency) (2)中位數(mediam): 將資料值依大小順序排列,取其正中央之數值或 正中央之兩數值之平均數。其數學式如下:
資料分析 (一)集中趨勢(central tendency) (2)中位數(mediam): 已知一樣本資料X為{9,7,6,11,7,13,10},另一樣本資料Y為 {9,7,6,11,7,13,10,25},試問樣本資料X、Y之中位數為何? 計算X之中位數前,需先將其資料排序{ 6,7,7,9,10,11,13}且因其樣本個數7為奇數,所以X之中位數: Y之樣本資料排序之結果為{ 6,7,7,9,10,11,13,25}且因其樣本個數 8為偶數,因此Y之中位數:
資料分析 (一)集中趨勢(central tendency) 百分位數(percentile): 將按大小順序排列後將資料化分為一百等分,若 至少有P %的資料小於或等於資料中之某資料值x, 且至少有的資料大於或等於x,則稱x為第P百分 位數,其計算方式如下: (a)將資料按順序排列大小 (b)令i=(p/100)*n,其中n為樣本個數 (c)若i為整數, 為第P 百分位數;若i不 為整數且m為整數使得 m < i < m + 1,則 即為第P 百分位數。 參見例2.23
資料分析 考慮樣本大小為8的資料{20, 25, 22, 23, 15, 17, 22, 27},請算出它的第20, 25, 75百分位數。 樣本按順序排列為15,17,20,22,22,23,25,27。 (1)p=20, 故第20百分位為17 (2)p=25, 故第25百分位為 (3)p=75, 故第75百分位為
資料分析 (一)集中趨勢(central tendency) 四分位數(quartiles): 第1四分位數Q1為第25百分位數,
資料分析 例題 2.24 某次1000人參加之高中數學模擬考試成績分布為 請問此資料之Q1、Q3分別位在那分數範圍內? 分數 10分以下 之第250人所在位置,因此位在31~40分之中。 (2)Q3為第75百分位數,佔全部人數1000人之75%,即由小至大 之第750人之所在位置,或由大至小之第250人之所在位置,因 此位在51~60分之中。 分數 10分以下 11~20分 21~30分 31~40分 41~50分 51~60分 61~70分 71~80分 81~90分 90分以上 人數 50 80 100 170 200 130 20 30
資料分析 (一)集中趨勢(central tendency) (3)平均數(mean): 加權平均數 幾何平均數 調和平均數 算數平均數 母體平均 樣本平均
資料分析 (一)集中趨勢(central tendency) (3)平均數(mean): (a)母體平均數(population mean): 以μ表之,若母體有N個,分別為X1, X2,…,XN,則 其數學式如下:
資料分析 (一)集中趨勢(central tendency) (b)樣本平均數(sample mean): 以 表之,若母體有n個,分別為X1, X2,…,Xn,則其 數學式如下:
資料分析 例: 若二年甲班共有15個人,其體重分別為40, 46, 44, 54, 63, 58, 70, 73, 45, 42, 46, 54, 54, 44, 44,今從此班級中抽出5個人,得其體重分別為46, 54, 70, 46, 58,求以此班級為母體之母體平均數及抽樣所得之樣本平均數。 母體平均數 樣本平均數
資料分析 (二)分散度衡量(measures of dispersion)(離散趨勢量數) (差異量數) 在資料的分析中,除了中央趨勢外,資料的分散程度或變異性也常是一重要的考量。以下我們討論一些常用之分散度的測量值: (1)全距(range) (2)四分位距(interquartile range,IOQ) (3)變異數(variance) (4)標準差(standard deviation)
資料分析 (二)離散趨勢(measures of dispersion) (1)全距(range): 樣本或母體中最大值與最小值的差。 要先排序 若資料由小到大依序排列為 , 則以R表示全距,其數學式如下:
資料分析 某次統計學期中考試,甲、乙兩班之成績如下: 甲班:50,52,55,58,60,60,62,63,65,69,70,71,73,75,78 乙班:10,50,50,54,58,60,62,62,65,70,70,73,73,75,75,75 試問甲、乙兩班個別之統計學期中考試成績之全距為何? (1)甲班成績之全距 (2)乙班成績之全距
資料分析 (二)離散趨勢(measures of dispersion) (2)四分位距(interquartile range IQR): 第3四分位與第1四分位之差。 此種分散度之測量可避免極端值造成的影響。 四分位距即為中間50% 資料(數)之全距。 公式如下:
資料分析 例 如上例,試問甲、乙兩班統計學期中考試成績之四分位距為何? (1)甲班成績之Q1、Q3如下: 因此,甲班成績之 因此,乙班成績之
資料分析 (二)離散趨勢(measures of dispersion) (3)變異數(variance): 考量每一個資料 與平均值 之間的差距,這個值稱 之為「對平均數的離差」,及各數與平均數的差,可代表離散的程度 此距有正(多於平均)有負(少於平均)差,因此若將所有資料值對平均數的離差加總,則即呈現正的離差與負的離差相互抵消,全部加總後變成0,離差的平均值便無法測量資料的變異程度。 防止離差的正負抵消的方法 取絕對值,加總後再求離差絕對值的平均值,這個數值稱之為「平均絕對離差」(MAD) 取離差的平方,加總後再取平均數,此值稱之為變異數。
資料分析 (二)離散趨勢(measures of dispersion) (3)變異數(variance): 總變異(變異總和) 變異數 不同 母體變異數 樣本變異數
資料分析 (a)母體變異數(population variance): (二)離散趨勢(measures of dispersion) 當資料為母體時,離差平方的平均值即為母體 變異數,以 表示之。則母體變異數之數學式 可表示如下:
資料分析 (二)離散趨勢(measures of dispersion) (b)樣本變異數(sample variance):樣本變異數之定義 為樣本資料之離差平方和除以樣本個數減一,以 表示之。則其數學式可表示如下: 另外,當樣本個數很大時,利用 的定義來計算顯 然太慢了,而以下定理便提供了另一種較快的計算 方式。定理2-1
資料分析 例 假設某人於市區與郊區分別經營兩家便利商店,今得知此兩家便利 商店一星期的營收如下: 若以此資料為樣本,求兩家便利商店此一星期之平均營收及其營收之變 異數。 (1)市區便利商店之平均營收及營收之變異數: (2)郊區便利商店之平均營收及營收之變異數: 日期 一 二 三 四 五 六 日 市區 5 6 7 郊區 3 4 8 10
資料分析 例 已知一樣本資料為{3,4,5,6,7,9,10,11,11,13,16,17,18, 20,25,26},求其樣本變異數 。 20,25,26},求其樣本變異數 。 因為 , ,且 ,利用定理2.1,
資料分析 (二)離散趨勢(measures of dispersion) (4)標準差(standard deviation): 變異數之平方根,其數學式可表示如下: (a)母體標準差: (b)樣本標準差:
資料分析 (a)當資料為母體: (三)平均數與標準差之應用 進一步將平均數與標準差結合起來,來探討以平均數及變異數相關之母體參數與統計測量值,作為進一步統計分析之基礎。 (1)變異係數(coefficient of variance ): 所謂的變異係數即為標準差除以平均數,以CV 示之。變異係數亦可以數學式表示如下: (a)當資料為母體: (b)當資料為樣本:
資料分析 例 假設甲、乙兩班由不同的二位老師教授,且二位老師給分 標準不同,若二班之統計學期中考的平均分數分別為80及 60分,其標準差分別為10分及9分,請以變異係數比較甲、 乙兩班統計學期中考成績之分散程度何者較大? 由此可知,乙班統計學期中考成績分配之分散程度較大。
資料分析 (2)Z分數(Z-score): (三)平均數與標準差之應用 決定資料中各資料值之相對位置,以 表示第i個 資料之Z 分數,其數學式可表示如下: (a)母體資料: (b)樣本資料: 樣
資料分析 例 如例2.31,請問(1)若林同學之統計學成績為50分,則其 Z分數為何?(2)若李同學之微積分成績為50分,則其Z分 數為何?(3)統計學考50分與微積分考50分之成績可否 相同? (1)林同學之統計學50分之Z分數為 (2)李同學之微積分50分之Z分數為 (3)由(1)、(2)得知,兩者之Z分數不相同,其中微積分50分之Z分數大於統計學50分之Z分數,因此以標準化值來比較,微積分之50分高於統計學之50分。
資料分析 (三)平均數與標準差之應用 (3)柴比雪夫定理(Chebyshev’s Theory): 在十九世紀早期,蘇聯數學家柴比雪夫証明至少有一定的數量之資料值與平均數距離的絕對值小 於或等於倍的標準差。 定理2-2 當 時,任一組資料至少有 比例的觀測值會 落在距離平均數k 個標準之內。 由以上定理得知,當k = 2時,至少有75% 的資料會落在距離平均數兩個標準差內。當k = 3時,至少有89% 的資料會落在距離平均數三個標準差內。
資料分析 例 假設有100位學生體重的平均數為60公斤,標準差為5公斤請利用柴比雪夫定理算出此100位學生至少有多少學生的體重介於52至68公斤之間? 介於52至68之間,代表與平均數距離有 個標準差,由柴比雪夫定理得知, 故在此100位學生中至少有60位體重介於52至68公斤之間。
資料分析 (三)平均數與標準差之應用 (4)經驗法則(the empirical rule): 實際上我們發現許多資料的分佈形狀為鐘(山)形分佈(如圖2.10),由圖可知在距離平均數的一個標準差內的資料數比例將明顯多於零,因此經驗法則乃針對鐘(山)形分佈的資料, 提供一個能獲得較精確值的方式。
資料分析 定理2-3 經驗法則 若資料呈鐘 (山) 形分佈,則: (1)接近68%的資料會落在距離平均數1個標準差內; (2)接近95%的資料會落在距離平均數2個標準差內; (3)幾乎所有的資料會落在距離平均數3個標準差內。
資料分析 (四)離群值之判定 在蒐集資料的時候,常常會因為某種原因(如: 筆誤、打瞌睡等)而產生不正常的極端大或極端小的資料值,此值稱之為離群值 (outlier)。 而此離群值的存在將會影響統計決策之判定,其 常用之判定方法有以下兩種判定法則: (1)Z分數判定法:決若資料值 的Z分數為 , 當 ,則 可視為離群值。關於Z分數的判 定法則主要是來自經驗法則,因為在現實生活中, 有許多資料分佈呈現鐘形分佈。
資料分析 例 隨機抽取天天蔬菜油工廠內之蔬菜油20罐,得其蔬菜油 內容量如下所示:(單位:公升) 1.8,1.9,2.1,2.0,2.0,2.1,1.9,2.6,2.1,2.0,2.1,1.9,1.9,2.0,2.1,1.6,2.0,2.1,1.9,1.9請以Z分數判定法 則判定此資料是否有離群值? 經計算得知此資料之樣本平均數與樣本標準差 以Z分數判定法判定離群值之臨界值為 由此得知,此資料中2.6大於臨界值為一離群值,其餘資料均 非離群值。
資料分析 (四)離群值之判定 (2)盒形圖判定法: 所謂盒形圖(box-whisker plot)是將資料的最值 、 、 、 及最大值 以盒形及直線之方式表示如圖2.11的圖形。
資料分析 承上圖盒形長度為IQR,此盒形圖可以幫助 我們瞭解資料的分佈情形: (a)若Q1至Q2的距離比Q2至Q3的距離長,則可知資料偏右 (即右邊資料較多)。 (b)若Q1至Q2的距離比Q2至Q3的距離短,則可知資料偏左 (即左邊資料較多)。 而以盒形圖判定離群值的方法如下: (a)當資料值超出Q3 有1.5倍的四分位距或小於Q1 有1.5倍 的四分位距,則此值為懷疑之離群值。 (b)當資料值超出有3倍的四分位距或小於有3倍的四分位距, 則此值為認定之離群值。
資料分析
資料分析 例 隨機檢測16個燈泡壽命 (單位:月),結果如下: 13, 9, 12, 4, 34, 16, 26, 13, 10, 18, 15, 6, 15, 12, 10, 5。 (1)請找出此資料的Q1、Q2、Q3。 (2)請劃出此組資料之盒型圖。 (3)請問此組資料是否有離群值? (1)首先將16個資料按大小順序排列:4, 5, 6, 9, 10, 10, 12, 12, 13, 13, 15, 15, 16, 18, 26, 34 。 Q1:因為 , Q2: Q3:因為 ,
資料分析 承例2.34,(2)因為 所以 其盒型圖如下:
資料分析 承例2.34,(3) 四分位距 IQR = 15.5 – 9.5 = 6,因此, 內圍值為 外圍值為 因為資料 ,即資料26落在內外圍之間,所以26為懷疑之離群值。而資料 34 > 33.5,即資料34落於外圍 之外,所以34可認定為離群值。
資料分析 (五)兩變量相關性之統計測量值 前面所介紹之統計測量值均為單變量之樣本資料,現在若考量兩個變量的樣本資料 , 前面所介紹之統計測量值均為單變量之樣本資料,現在若考量兩個變量的樣本資料 , 則在兩個變量之資料中,兩個變量之間可能會有多種不 同型態的關係,最常見的關係便是「線性關係」。 假設有兩個變量X、Y,若X、Y 具有正的線性相關,則X 愈大,Y也愈大,或X愈小,Y也愈小;另一方面,若X、Y具有負的線性相關,則X愈大,Y愈小,或X愈小,Y 愈大。
資料分析
資料分析 (五)兩變量相關性之統計測量值 (1)共變異數(covariance): (a)母體共變異數(population covariance):假設母 體資料為 ,則母體共變異數 可以 或 表示如下: (b)樣本共變異數(sample covariance):假設樣本資 料為 ,則樣本共變異數 可以表示如下:
假設A、B 兩種產品過去五個月的銷售量如下: 資料分析 例 假設A、B 兩種產品過去五個月的銷售量如下: 求此樣本共變異數 ? 由資料可得A、B 兩種產品之樣本平均數如下: A 3 5 2 6 B 8 9 7
資料分析 承例2.35中, =2.8所代表的意義為何呢? 我們由圖2.15表示如下,可知A、B具有正線性關係。
資料分析 (五)兩變量相關性之統計測量值 (c)共變異數與兩變量之線性關係 若我們將兩變量之資料區分為四個區域,則資料可能 分配之區域如下圖2.16:
資料分析 承上頁,共變異數與兩變量之線性關係可由圖2.16 說明如下: (a)若共變異數大於0:則表示X, Y同時比平均數大,或同 時比平均數小的情形較顯著,即表示大部分的資料值 均落在圖2.16之Ⅱ、III兩區,因此X, Y變量具有正的 線性關係。 (b)若其共變異數小於0:則表示X大於平均數且Y小於平均 數或X小於平均數且Y大於平均數的情形較為顯著,即 表示大部分的資料值均落在圖2.16中之Ⅰ、Ⅳ兩區, 因此X, Y變量具有負的線性關係。 (c)若共變異數等於0:即表示資料值平均分散在Ⅰ、Ⅱ、 Ⅲ、Ⅳ四區中,則X, Y變量沒有線性關係。
資料分析 (五)兩變量相關性之統計測量值 (2)相關係數(correlation coefficient ): 樣本相關係數: 由於不同的樣本資料可能有不同單位,因此共 變異數的大小很難決定兩個變量線性關係的強 弱。 母體相關係數: 樣本相關係數:
定理2-4 科西不等式(Cauchy inequality): 資料分析 承上頁,以下兩個定理便証明了相關係數介於-1與1之間。 定理2-4 科西不等式(Cauchy inequality): (1) (2)等式成立若且唯若對所有i = 1, 2, . . .,n, ,其中k 為一非零之常數。
資料分析 定理2-5 相關係數介於-1及1之間,即 ( )。由柯西不等式得知,
資料分析 相關係數之特性 承上頁可知,相關係數之特性如下: (1)若 ,則由柯西不等式可知,對所有觀測值 (1)若 ,則由柯西不等式可知,對所有觀測值 且 k > 0,即表示X, Y 變量有完美的正的線性關係 (2)若 ,則由柯西不等式可知,對所有觀測值 且 k < 0,即表示X, Y 變量有完美的負的線性關係 (3)若 ,則 ,即X, Y 變量具有正的線性關係 (4)若 ,則 ,即X, Y 變量具有負的線性關係 (5)若 ,則 ,即X, Y 變量沒有的線性關係
承例2.35,試求A、B之相關係數,並判斷A、B 資料分析 例 承例2.35,試求A、B之相關係數,並判斷A、B 之相關性。 因此A、B 有很強的正線性關係。