項目分析與探索式因素分析 李茂能, 2007,成大 Fred Li, 2007
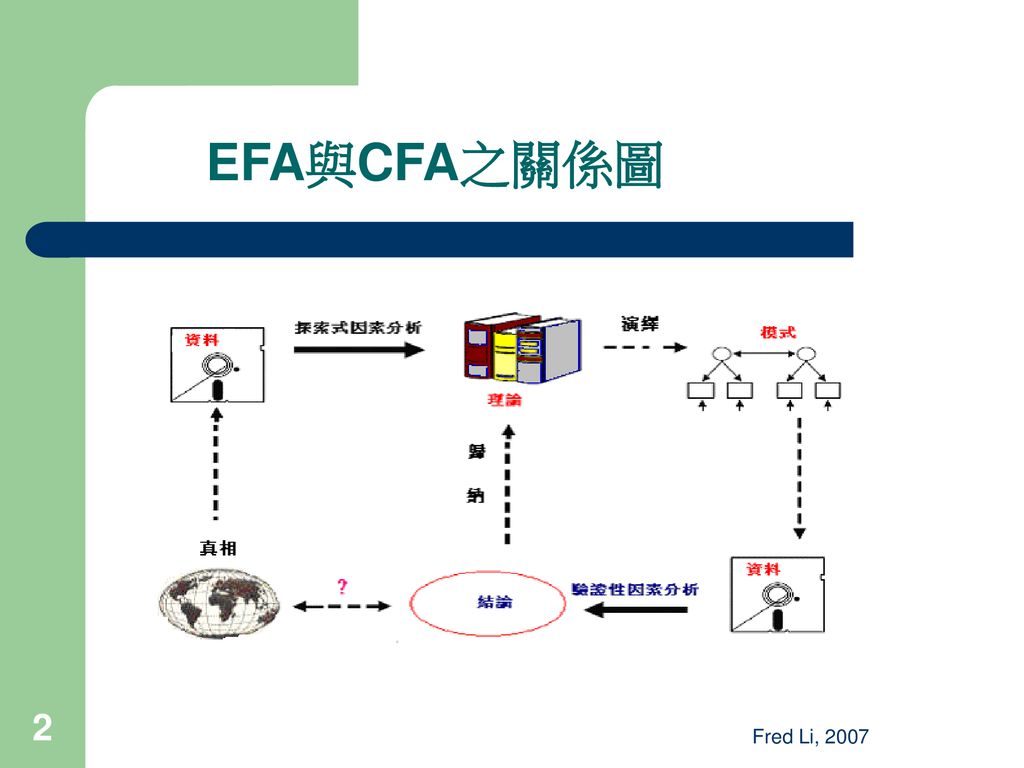
EFA與CFA之關係圖 Fred Li, 2007
Gould(1981)characterized FA as “ a bitch”. 令人困惑的因素分析 爭論多 迷思多 議題多 矩陣運算難題多、狀況多 Gould(1981)characterized FA as “ a bitch”. Fred Li, 2007
因素分析分析的用途 PCA解決回歸分析中多元共線性問題(利用主成份分數) 項目分析 發展分量表 簡化MANOVA中依變項過多問題 潛在架構分析(Latent structure analysis) 因素結構之檢驗 Fred Li, 2007
因素分析的鼻祖 Spearman (1904). 使用學生在不同學科的成績,研究智力。 I .90 M C H Am Ac Ah .80 .50 .90 M C H Am Ac Ah Fred Li, 2007
相關主題 探索式因素分析的理論基礎 探索式因素分析前的資料準備工作 輸入矩陣之型態 因素個數的決定 因素轉軸的方法 因素解釋度與有用性 因素命名 因素負荷量的顯著臨界值 探索式因素分析在測驗編製上的用途 Fred Li, 2007
因素分析的模式 Defined Factors 主成分法(PCA) 因素分析模式 主軸法 (PFA) Inferred Factors 最大概似法 Alpha法 Image法
常用因素模式的選擇 (3)變項數小於20時。 PCA: (1)欲以最少數的因素代表原始變項的最大變異量時, (2)事先已知特殊及誤差變異量並不大時 (3)變項數大於20時。 PFA: (1)欲代表原始變項的潛在向度或構念時, (2)事先對於特殊及誤差變異量所知有限,而又想加以排除時 (3)變項數小於20時。 Fred Li, 2007
PCA vs PFA PCA 根據原來的實際相關矩陣的固定解法 (相關矩陣對角線的初始值均為1). PFA 通常採疊代法(相關矩陣對角線的初始值可以共同性的估計值取代).例如, 初始值亦可採變項的SMC (squared multiple correlation,SMC為其他變項預測某一變項的決定係數)。 接著, 抽取指定之因素數目,根據此因子負荷量重新計算共同性(communalities),取代原來就的共同性,再抽取因素。 如此反覆疊代,一直到共同性的估計值改變不大為止. Fred Li, 2007
Factors vs. Components PFA gives factors; PCA yields components. 分析步驟大致相同 Differ in the variance that is analysed PCA: 所有觀察變項的變異量均加以分析(shared; unique; and error),常高估參數估計值 。 PFA: 僅分析共同變異量 理論上來說, factors 是潛在的變項(latent),它致使觀 察變項產生共變(covariation). Components 是實徵決定的濃縮變項。 Fred Li, 2007
主成份分析:Defined factor 將原始變項轉換成一組互為獨立的新變項,這些新變項稱為主成份(principal components),原來資料的線性轉換。所有觀察變項的變異量均加以分析,目的在濃縮變項以達到資料簡約(data reduction)的工作。 每一主成份分數(C)均為原來變項(例如X1,X2 ,X3)與主成份分數係數(a11 , a12 ,a13)的線性組合:如:C1=a11ZX1+a12ZX2+a13ZX3(1st主成份分數) Fred Li, 2007
PFA: Inferred Factors 因素的建構及因素的變異來源有推論上的假定 Zj=aj1F1+aj2F2+aj3F3+…+ajmFm+ djUj 共同性 獨特性 (J=1..n, m<n) Fred Li, 2007
主因素分析僅分析共同變異量 Fred Li, 2007
因素分析的轉軸 斜交轉軸 Oblique 轉軸的方式 Varimax 正交轉軸 Quartimax Equimax
PFA抽取技術(1) Principal factors - like PCA,希望每一因素均能抽取最大正交變異量 Alpha Factoring -希望共同因素的疊代值能獲得最大的Alpha係數 (因素信度).視變項為來自母群之樣本,而非像其他方法則視受試者為樣本,變項為固定因子, Alpha係數最高的因素最先抽取。 Unweighted least Squares – 僅考慮非對角線的相關矩陣元素 (不估計共同性)且最小化殘差相關(再製相關矩陣與實際相關矩陣之差)的平方值。 Generalised least squares使用同一標準,但進行相關矩陣的獨特性倒數加權,因此變項獨特性大的加權小,變項獨特性小的加權大。 Fred Li, 2007
PFA抽取技術(2) Maximum Likelihood – 估計因素負荷量的母群參數,希望其再製相關矩陣與原來的實際相關矩陣之差異達到最小。 Image Factoring – 為一種非疊代法使用“image score variance-covariance matrix” 當作因素抽取的基礎(而非原來的實際相關矩陣) Fred Li, 2007
因素分析在測驗編製上的步驟 (一) Fred Li, 2007
PCA&PFA的報表(1) Fred Li, 2007
因素分析的報表(2) Fred Li, 2007
因素分析在測驗編製上的步驟 (二) Fred Li, 2007
SPSS轉軸方法 Fred Li, 2007
因素分析前之準備工作 連續變項的要求(分數離散量不大時,使用多分相關或題組分析),盡量採用5~7點量尺 反向計分的問題 項目分析:難度、鑑別度與題目品質(內容) 以分測驗為分析單位 檢查項目間之交互相關矩陣 Fred Li, 2007
輸入矩陣之型態 各觀察變項的測量單位通常不等且沒有明確之意義,一般研究者都需使用相關矩陣進行因素分析。不過,研究者如希望考慮到變項間變異量的差異性,需使用共變數矩陣進行因素分析! Fred Li, 2007
樣本大小與遺漏值 Comrey and Lee: > 300 較佳 Klein and Barrett: 至少100 每一變項的最低觀察值: 10 遺漏值會形成不良的相關矩陣 Pairwise vs. Listwise 刪除法(non-positive matrix?) Listwise 為 SPSS的內定法 Fred Li, 2007
因素分析之注意事項綱要 因素分析對於相關係數的大小異常敏感,因此.應 注意列事項: 樣本大小 遺漏值 常態性 極端個案 多元共線性或奇異值(Singularity) 相關矩陣的可分析性(Factorisability) 極端變項 Fred Li, 2007
SPSS在項目分析上之應用 Fred Li, 2007
SPSS副程式Reliability報表 Fred Li, 2007
Cronbach 的考驗 Fred Li, 2007
Cronbach 的考驗結果 Fred Li, 2007
Cronbach 的公式 Fred Li, 2007
It’s easy to get a p-value! Time for a break! It’s easy to get a p-value! CAUSEweb.org by J.B. Landers Fred Li, 2007
PCA and PFA的步驟 探索階段 測量觀察變項 計算相關矩陣 抽取因素(或主成分) 因素轉軸(以便解釋) 解釋結果 驗證階段 進行複製研究以驗證因素結構, 或考驗抽取因素的建構效度 Fred Li, 2007
因素分析步驟 Adapted from Hair, et al(1998) Fred Li, 2007
Stage 1 因素分析的目的 找出變項間關係的基本結構 R factor analysis分析變項 Q factor analysis分析個案(Alternative to cluster analysis) 資料簡化 找出基本向度 取代原來變項 Fred Li, 2007
探索式或驗證性分析? Exploratory 因素結構未明 沒有理論可以說明因素結構 Confirmatory 驗證理論結構 因素結構已知 Fred Li, 2007
Stage 2 因素分析的設計 變項最好等距變數以上 樣本大小 最好 > 100 為變項的10 ~ 20倍 Fred Li, 2007
Stage 3 – 基本假設 違反normality & homoscedasticity會降低相關係數大小 相關矩陣的可因素分析性: A number of significant pair-wise correlations Bartlett test of sphericity. (H0 - the correlation m’x is an identity m’x) Measure of Sampling Adequacy (MSA). 刪除 MSA < 0.50的變項 Fred Li, 2007
Stage 4 – 因素的抽取方法與評估 如何抽取因素? PFA或PCA ? 抽取幾個因素 ? Fred Li, 2007
PFA & PCA PFA旨在找出可以反應共同變異量的基本因素:根據共同變異量(Communality)抽取因素 Fred Li, 2007
抽取因素的標準 特徵值 > 1 預設個數:A Priori criterion. 根據理論或複製別人的研究結果(直接告訴電腦需抽取之因素個數) 抽取變異量百分比:根據既定 %,社會科學上之應用最好在60%以上 陡坡法(Scree test criterion ),採用此法通常會比特徵值法多出1~3個因素 Velicer的最小淨相關考驗法(Minimum average partial test,MAP) 平行分析: Parallel analysis criteria(Lautenschlager, 1989) 使用驗證性因素分析決定因素個數,研究者可以利用2、RMSEA與ECVI判定哪一個因素個數的模式最適配(Fabrigar, Wegener, MacCallum, & Straham, 1999)。 抽取太少因素易導致錯誤的潛在架構,抽取太多因素易導致解釋困難 Fred Li, 2007
陡坡法 以因素的個數為橫軸,以特徵值為縱軸繪製陡坡圖 陡坡曲線開始極速下降且趨於水平化 陡坡曲線最先趨於直線的點即是抽取因素的最大值 Fred Li, 2007
陡坡圖(1) 劃一直線貫穿肘部特徵值 特徵值 # of components Fred Li, 2007
陡坡圖(2) # of components Fred Li, 2007
Stage 5 因素的解釋與有用性 未轉軸的因素抽取採正交解,各因素間獨立無關 因素負荷量 – 反應變項與因素間之相關 因素轉軸以反映更簡單且更有意義的因素結構 新發現的因素是否有意義與價值 決定因素個數後再轉軸 Fred Li, 2007
轉軸目的 以利於解釋與選題,但無法改善因素解 使用正交, 潛在因素間無關嗎? 嘗試斜交後,如發現因素間之相關甚小,則可使用正交轉軸。 Fred Li, 2007
正交轉軸方法 SPSS中可用的轉軸方法: Varimax (最普遍) , Quartimax ,Equamax與Orthomax (使用者可界定gamma []參數,以取得varimax [=1] & quartimax [=0]間之平衡點) Varimax maximises the variance of loadings within factors across variables (簡化因素:在特定的因素下, 使某些高負荷量的變項具有更高的負荷量,其它低負荷量的的變項,其負荷量則會更低),可用以決定哪些題目應保留在某一因素內。可用以決定分量表之內容。本法有利於因素之解釋與描述。 Quartimax increases variance of loadings within variables across factors (簡化變項:在特定的變項下,在某些因素上具有高的負荷量,其它因素上之負荷量則儘可能的低) ,可用以決定某一題目應落在哪一因素上。 Equamax: =0.5. 避免使用(除非明確因素數目已知悉) Fred Li, 2007
斜交轉軸方法 SPSS中可用的轉軸方法: Direct oblimin Quartimin Promax Direct oblimin研究者可自行設定 delta ()值,以界定變項間關係的程度. 可能需要嘗試錯誤的方式決定 值. 當 =0,即為direct quartimin,中度相關. If is around -4 then rotation orthogonal; 接近於1,高度相關,需要刪掉多餘之因素。縮小因素負荷量的交乘積,以簡化因素結構。 Promax 採取正交轉軸後,將負荷量乘冪化 (kappa, ). 通常為2, 4 or 6次方. 逼使負荷量小的趨近於0及因素間保有相關, 且獲得 “simple structure”。本法將正交因素旋轉到斜交位置。可用以選擇測驗之題目。 Fred Li, 2007
因素轉軸資料 Fred Li, 2007
正交與斜交轉軸 Fred Li, 2007
因素解之矩陣 正交轉軸法 Factor Loading Matrix: 變項與因素間之相關矩陣 斜交轉軸法 Factor Correlation Matrix: 分割成兩部分: Structure Matrix:變項與因素間之相關(含因素間之相關與變項與因素的獨特變異量),一般研究者偏好此 Pattern Matrix:代表每一變項對於因素之獨特貢獻量 (當因素間之相關增大時,在結構矩陣中難於分辨哪一變項具有較大之獨特性,因而最好,報告此矩陣) Factor Score Coefficients Matrix: 回歸係數似矩陣(用來由變項分數預測因素分數) Fred Li, 2007
因素負荷量的顯著性 因素負荷量原來變項與因素間之相關 (因素負荷量)2 說明了解釋之%。 例如 0.7的負荷量解釋了~ 50%的變異量。 (因素負荷量)2 說明了解釋之%。 例如 0.7的負荷量解釋了~ 50%的變異量。 Hair, et al(1998)提供下表作為考驗因素負荷量是否顯著的標準,此標準與N成反比。 Fred Li, 2007
因素負荷量的顯著臨界值 負荷量 樣本大小(=.05) ______________________________________ 負荷量 樣本大小(=.05) ______________________________________ .30 350 .35 250 .40 200 .45 150 .50 120 .55 100 .60 85 .65 70 .70 60 .75 50 _____________________________________ Power=.80 Fred Li, 2007
因素的命名與解釋 藝術?科學? 找出每一變項最高的因素負荷量在哪裡? 假如該變項並未在任何因素上有大的負荷量(如大於.30),刪除該變項 針對主要因素妥當命名 (Kline, 1994)認為研究者尚需考慮因素之內容是什麼。例如,這些因素是難度相似的題目所造成(難度因素)嗎? 還是這些因素是反向題目或是題目的格式所造成的? 還是這些因素是社會期許效應所造成的? 還是這些因素是灌水因素(Bloated factors)? Fred Li, 2007
新因素的再驗證 測驗編製者可利用外在效標或身分明確的指標因素(Marker factor)去驗證這些新因素,以排除這些新因素不是難度因素、灌水因素、反向題目因素、社會期許效應因素等等人為因素。 Fred Li, 2007
因素分析的命名方法 Fred Li, 2007
T-taste時間 CAUSEweb.org by J.B. Landers Fred Li, 2007