Download presentation
1
实验十十一 聚类算法

2
主要内容 1、聚类和聚类分析 2、数据类型 3、相似度量方法 4、聚类方法的分类 5、划分聚类的方法 6、层次聚类方法
7、基于空间索引的聚类方法 8、聚类的应用案例

3
1 聚类和聚类分析概述 1.1 聚类的起源 1.2 聚类举例 1.3 聚类的定义和相关概念

4
1.1 聚类的起源 人们认识世界的一种方法是将认识的对象按照一定的特征进行划分 同一类事物之间有着相似的属性 划分种类的方式包含分类和聚类

5
1.2 分类举例

6
1.2 聚类举例(一) 对10位应聘者做智能检验。3项指标X,Y和Z分别表示数学推理能力,空间想象能力和语言理解能力。其得分如下,选择合适的统计方法对应聘者进行分类。 应聘者 1 2 3 4 5 6 7 8 9 10 X 28 18 11 21 26 20 16 14 24 22 Y 29 23 27 Z

7
1.2 聚类举例(二) 例如当我们对企业的经济效益进行评价时,建立了一个由多个指标组成的指标体系,由于信息的重叠,一些指标之间存在很强的相关性,所以需要将相似的指标聚为一类,从而达到简化指标体系的目的。
 例如当我们对企业的经济效益进行评价时,建立了一个由多个指标组成的指标体系,由于信息的重叠,一些指标之间存在很强的相关性,所以需要将相似的指标聚为一类,从而达到简化指标体系的目的。")
8
1.3 聚类的定义及相关概念 1. 聚类的定义 2. 相关概念 无监督的知识发现 把物理或抽象对象的集合分成相似的对象类的过程成为聚类。
簇: 数据对象的集合 距离:数据对象间的距离 好的聚类:簇内部对象的距离小,而簇之间的距离大

9
假如要分两个簇,如何分?

10
2 数据类型 2.1 数据类型的分类 2.2 数值型数据的标准化

11
2.1 数据类型的分类 从数据聚类的角度看,数据可以分为 分类型和数值型 分类型: 数值型属性:属性值的加减、排序等均有意义
名义型、等级型和布尔型 名义型:属性值之间没有顺序,属性值的加减没有意义 等级型:属性值之间有大小顺序,但不知道一个值比另一个值究竟大多少 布尔型:分类型的特例,只有两个属性值 数值型属性:属性值的加减、排序等均有意义

13
2.2 数值型属性的标准化 1 为什么要标准化 数值型属性的量纲和单位不同,必须把不同的度量单位统一成相同的度量单位

14
2 标准化的常用方法 Z-score标准化:均值为0,方差为1 减去均值,除以绝对方差 标准化值域,将值域映射到[0,1]
除以均值:令均值为1 除以最大值:令最大值为1 前提:所有数值均为正值
![2 标准化的常用方法 Z-score标准化:均值为0,方差为1 减去均值,除以绝对方差 标准化值域,将值域映射到[0,1]](http://slidesplayer.com/slide/11150200/59/images/14/2+%E6%A0%87%E5%87%86%E5%8C%96%E7%9A%84%E5%B8%B8%E7%94%A8%E6%96%B9%E6%B3%95+Z-score%E6%A0%87%E5%87%86%E5%8C%96%EF%BC%9A%E5%9D%87%E5%80%BC%E4%B8%BA0%EF%BC%8C%E6%96%B9%E5%B7%AE%E4%B8%BA1+%E5%87%8F%E5%8E%BB%E5%9D%87%E5%80%BC%EF%BC%8C%E9%99%A4%E4%BB%A5%E7%BB%9D%E5%AF%B9%E6%96%B9%E5%B7%AE+%E6%A0%87%E5%87%86%E5%8C%96%E5%80%BC%E5%9F%9F%EF%BC%8C%E5%B0%86%E5%80%BC%E5%9F%9F%E6%98%A0%E5%B0%84%E5%88%B0%5B0%2C1%5D.jpg "除以均值:令均值为1. 除以最大值:令最大值为1. 前提:所有数值均为正值.")
15
3 注意: 不要为了标准化而标准化 当我们需要比较的两个(或多个)序列是同一量纲下的,则不必标准化 标准化是按照属性进行标准化
序列是同一量纲下的,则不必标准化 标准化是按照属性进行标准化")
16
对哪些数列进行标准化

17
作业:数列标准化(按小组交) 设计一个excel表,实现数列标准化
 设计一个excel表,实现数列标准化")
18
3 相似度量方法 对象间的相似性计算是聚类的核心,有两种主要的方法:距离和相似度。

19
3.1 距离 1 距离的要求

20
2 常见的距离 曼哈顿距离: 欧式距离: 切比雪夫距离:

21
例子:分析上海股市和深圳股市的距离

22
2.2 相似系数 1. 相似系数的要求

23
2 相似度的度量方式 数量积法 相关系数法

24
例子:分析上海股市和深圳股市的相似系数

25
简单匹配法 累积匹配的属性个数,匹配属性所占的比例作为相似系数 大家利用匹配算法计算一下样本3和4、8和11的相似系数

26
匹配系数 针对二值型 匹配系数=

27
大家利用匹配系数计算上证指数和深证成指的相似性

28
补充

30
4 聚类方法的分类 4.1 平凡聚类和不平凡聚类 4.2 覆盖聚类和非覆盖聚类 4.3 层次聚类和非层次聚类
4.4 数值型聚类、分类型聚类和混合型聚类 4.5 从聚类的方法进行分类

31
4.1 平凡聚类和不平凡聚类 一组数据D有N个对象,分成M个簇 平凡聚类:整个聚类只有一个簇或者每个对象单独成为一个簇
非平凡聚类: 其它的情况

32
4.2 覆盖聚类和非覆盖聚类 覆盖聚类: 每个对象至少属于一个簇,则为覆盖聚类 否则为非覆盖聚类

33
4.3 层次聚类和非层次聚类 如果存在两个聚类,其中一个聚类是另一个聚类的子集,则称为层次聚类,否则为非层次聚类

34
4.4 数值型聚类、分类型聚类和混合型聚类 根据属性的类型进行划分 只包含数值属性的——数值型聚类 只包含分类型属性的——分类型聚类
同时包含数值属性和分类型属性——混合型聚类

35
4.5 从聚类的方法进行聚类 划分聚类 层次聚类 基于密度的聚类 网格聚类

36
5 划分聚类方法 5.1 常见的划分聚类的方法 5.2 K-means算法的一般过程 5.3 例子

37
5.1 常见的划分聚类的方法 1 划分聚类的含义: 对于一组数据集合D,给定聚类数目k和目标函数F,划分聚类算法把D划分成k个组,使得目标函数在此划分下达到最优。 目标函数通常是:各个点到每个聚类中心的距离最短。

38
2 常见的划分聚类的方法有 K-means K-medoids 等等

39
5.2 k-means算法 聚类结果的表示形式 每个聚类至少有一个样本 每个样本至少属于一个聚类

40
5.2.2 K-means算法的过程 (1) 确定输入输出 (2) 具体处理流程 (3) k-means算法的结束条件 (4)
 确定输入输出 (2) 具体处理流程 (3) k-means算法的结束条件 (4)")
41
(1) K-means算法的输入输出 输入:聚类个数k,以及包含n个数据对象的数据库。 输出:满足方差最小标准的k个聚类。
 K-means算法的输入输出 输入:聚类个数k,以及包含n个数据对象的数据库。 输出:满足方差最小标准的k个聚类。")
42
(2) 处理流程: (1)从n个数据对象任意选择k个对象作为初始聚类中心。 (2)使用欧氏距离将剩余实例赋给距离它们最近的簇中心 (3)使用每簇中的实例计算每个簇对象的均值(中心对象),计算每个对象与这些中心对象的距离,并根据最小距离重新对相应对象进行分类。 (4)重新计算每个(有变化)聚类的均值(中心对象),直至新平均值等于上次迭代的平均值,算法结束。
 处理流程: (1)从n个数据对象任意选择k个对象作为初始聚类中心。 (2)使用欧氏距离将剩余实例赋给距离它们最近的簇中心 (3)使用每簇中的实例计算每个簇对象的均值(中心对象),计算每个对象与这些中心对象的距离,并根据最小距离重新对相应对象进行分类。 (4)重新计算每个(有变化)聚类的均值(中心对象),直至新平均值等于上次迭代的平均值,算法结束。")
43
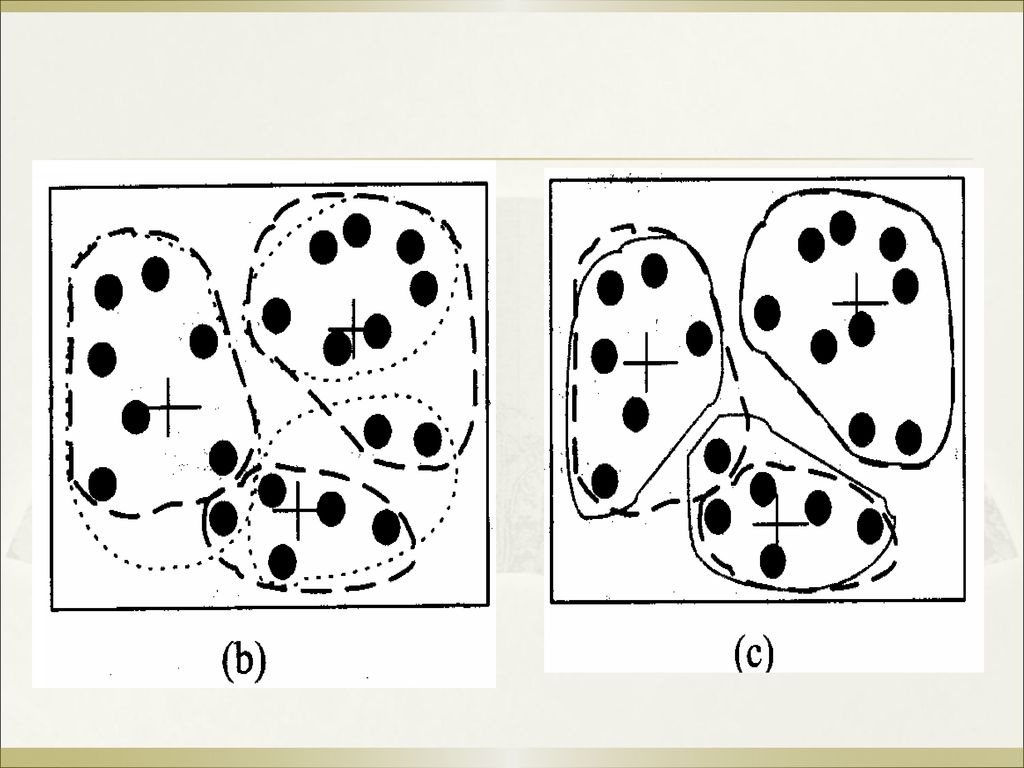
假设空间数据对象分布如图(a)所示,设是k=3,也就是需要将数据集划分为3份(聚类)。
所示,设是k=3,也就是需要将数据集划分为3份(聚类)。")
45
(3) K-means算法的结束条件: 目标函数值不再下降 两次迭代得到的聚点相同 两次迭代得到的划分相同 达到最大的迭代次数
 K-means算法的结束条件: 目标函数值不再下降 两次迭代得到的聚点相同 两次迭代得到的划分相同 达到最大的迭代次数")
46
(4)K-means算法的关键之处 1. 样本距离的确定 2. 样本中心点的确定 对于数值型属性而言,对应属性求均值
对于分类型属性而言,则复杂一些:选择频率最大的。

47
思考:三者中心如何确定

48
6 层次聚类法 6.1 层次聚类的定义 6.2 层次聚类的步骤 6.3 聚类之间距离的定义

49
6.1 层次聚类 层次聚类方法是指递归地对对象进行合并和分裂,直到满足某一终止条件为止。

50
6.2 层次聚类的过程 (1)计算对象两两之间的距离; (2)构造n个单成员聚类C1,C2,…,Cn,每个聚类高度为0;
(3)找到两个距离最近的聚类Ci和Cj,聚类的个数减1,以被合并的两个类之间的间距作为上层的高度 (4)重复3直到满足终止条件
找到两个距离最近的聚类Ci和Cj,聚类的个数减1,以被合并的两个类之间的间距作为上层的高度. (4)重复3直到满足终止条件.")
51
6.3 聚类之间距离的定义 最大距离、最小距离、类平均距离、中心距离

52
思考1 分成两个聚类,大家计算各聚类之间的距离

53
思考2 :层次聚类结果

54
练习 利用最长距离法,写出层次聚类结果 编号 1 2 3 4 5 4 0

55
7、基于空间索引的聚类方法 7.1 几个重要概念: 核心对象和边界对象
核心对象:在给定半径r的领域中的对象个数大于密度阈值minNum,则该对象称为核心对象。 边界对象:其它 令r=5,minNum=3 核心对象有哪些? 非核心对象有哪些? 编号 1 2 3 4 5 4 0

56
直接密度可达、密度可达、密度联通 直接密度可达: 如果p是一个核心对象,q属于p的领域,则称p直接密度可达q。
令p1=p,pk=q; 其中pi直接密度可达pi+1,则称p密度可达q。 问:p密度可达q是否意味着q密度可达p?为什么?

57
如果存在o,使得o密度可达p,o也密度可达q,则称p与q是密度联通的。
问1:若p密度联通q,那么q是否密度联通p 问2:p密度联通q,是否意味着p密度可达q? 若p密度可达q,是否意味着p密度联通q? 问3:如果存在o,使得p密度可达o,q也密度可达o,能否称p与q是密度联通的?

58
点1和点5有哪些关系?(密度可达、密度直接可达、密度联通) 点2和点4有哪些关系? (密度可达、密度直接可达、密度联通)
r=5,minNum=3 编号 1 2 3 4 5 4 0

59
基于密度的聚类步骤 1. 标记出核心对象Ci和边界对象Ni 2. 当ci和cj彼此密度可达,则ci和cj在同一个类中
3. 若ci密度可达Ni,则Ni所在类与ci相同,否则Ni单独归于一类

60
思考: 已知r=5,minNum=3,求下表的聚类结果 编号 1 2 3 4 5 4 0
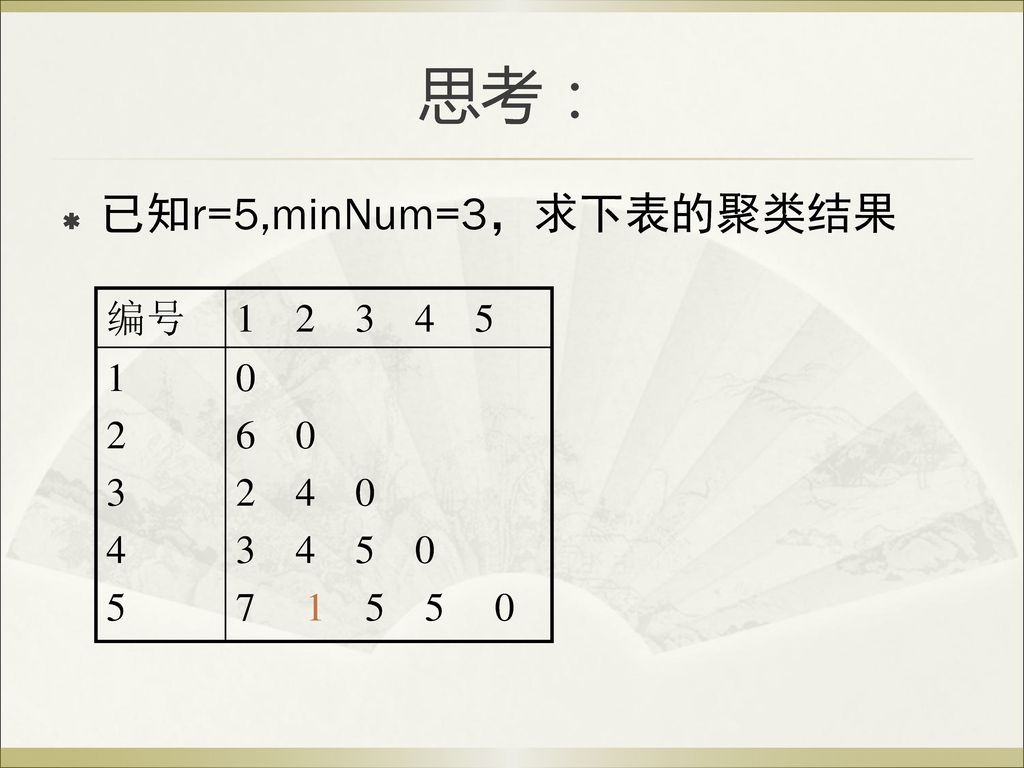
61
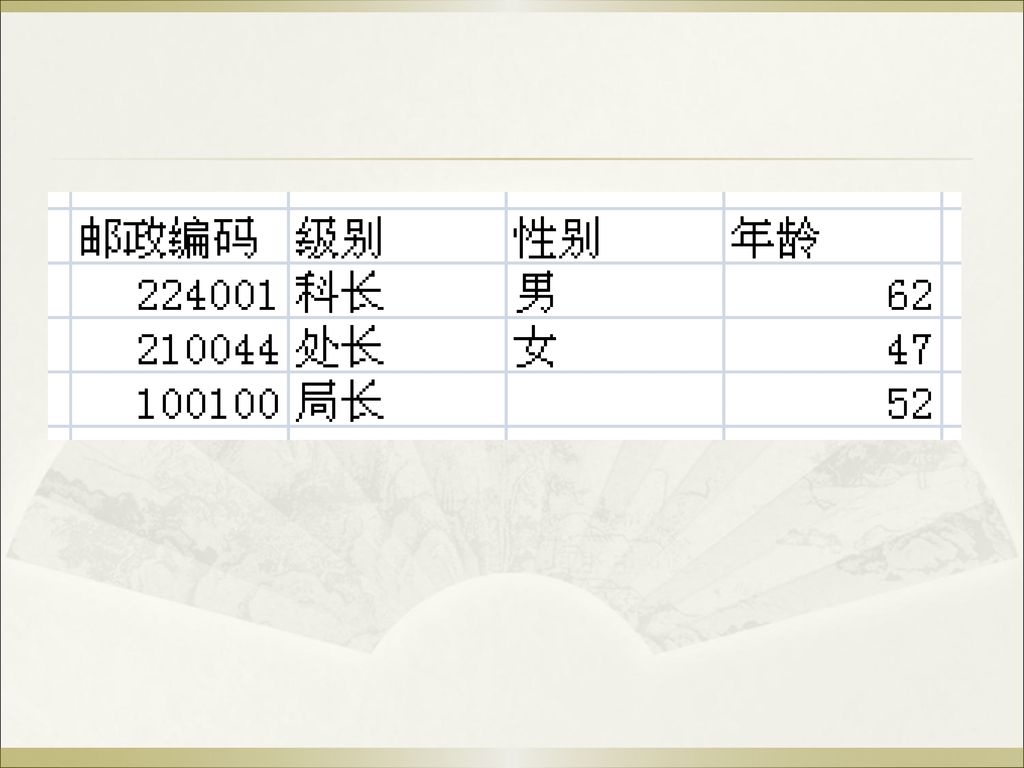
8 聚类的应用案例 8.1 旅游上的应用 情景:大家成立了一个旅行社,打算做一个调查问卷,针对学生进行宣传,发展学生旅游市场,请问你会怎么做?








![桐乡市地方税务局 2013 年度社会保险费汇算清缴有 关政策及事项说明. 一、政策规定 根据《中华人民共和国社会保险法》、《桐乡市社会保险费征缴管 理办法》(市政府令第 42 号)、《 关于完善社会保险费征缴管理有关问 题的通知》(桐政办发 [2012]152 号)及《关于完善社会保险费征缴管理.](/40/11070600/big_thumb.jpg "桐乡市地方税务局 2013 年度社会保险费汇算清缴有 关政策及事项说明. 一、政策规定 根据《中华人民共和国社会保险法》、《桐乡市社会保险费征缴管 理办法》(市政府令第 42 号)、《 关于完善社会保险费征缴管理有关问 题的通知》(桐政办发 [2012]152 号)及《关于完善社会保险费征缴管理.>")






班主题班会.>")






 第二十一章数据的整理与初步处理 21.1.4扇形统计图的制作.>")