Download presentation
1
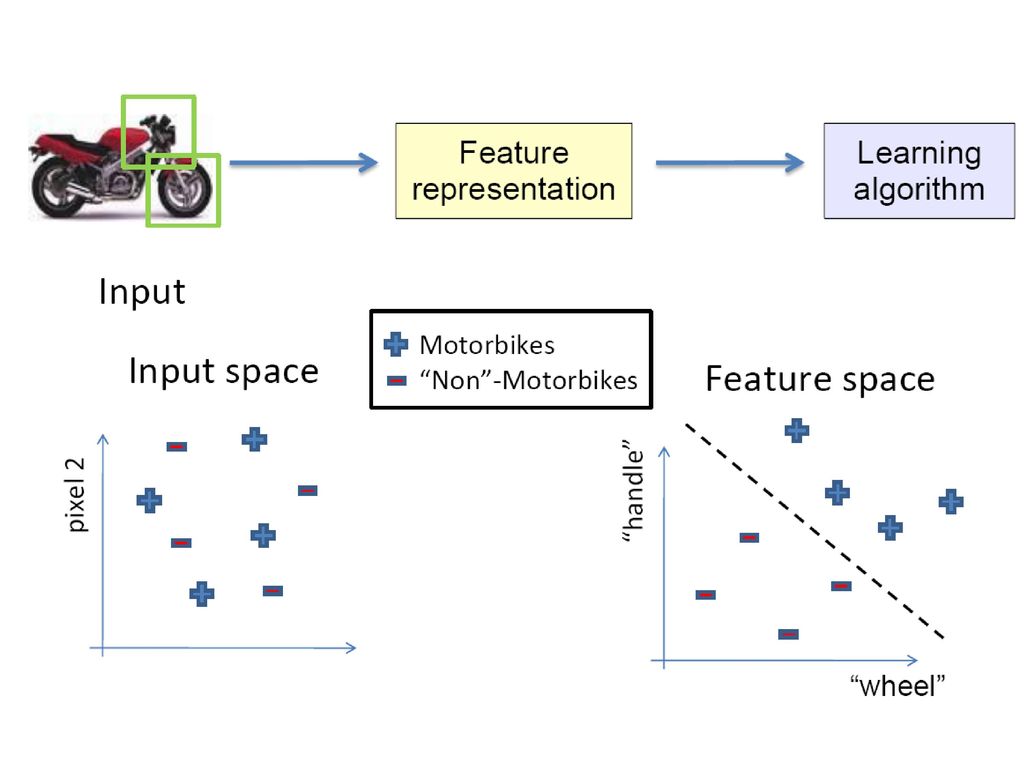
Unsupervised feature learning: autoencoders
诺明花

2
提纲 What is auto-encoders Sparse auto-encoders
Application——Paraphrase detection

4
深度学习与多层特征表示(1/2)
")
5
深度学习与多层特征表示(2/2) 神经网络的每一层都是上一层的非线性变换。 Deep networks的优点:
此时要求每一层的activation函数是非线性的(否则就没有必要用多层了)。 Deep networks的优点: 1)比单层神经网络能学习到更复杂的表达。 比如说用k层神经网络能学习到的函数(且每层网络节点个数是多项式的)如果要用k-1层神经网络来学习,则这k-1层神经网络节点的个数必须是指数级庞大的数字。 2)不同层的网络学习到的特征是由最底层到最高层慢慢上升的。 底层隐含层学习底层特征,高层隐含层学习高层特征。 比如在图像的学习中,第一个隐含层网络可能学习的是边缘特征,第二隐含层就学习到的是轮廓什么的,后面的就会更高级有可能是图像目标中的一个部位。 3)这种多层神经网络的结构和人体大脑皮层的多层感知结构非常类似,所以说有一定的生物理论基础。
。 Deep networks的优点: 1)比单层神经网络能学习到更复杂的表达。 比如说用k层神经网络能学习到的函数(且每层网络节点个数是多项式的)如果要用k-1层神经网络来学习,则这k-1层神经网络节点的个数必须是指数级庞大的数字。 2)不同层的网络学习到的特征是由最底层到最高层慢慢上升的。 底层隐含层学习底层特征,高层隐含层学习高层特征。 比如在图像的学习中,第一个隐含层网络可能学习的是边缘特征,第二隐含层就学习到的是轮廓什么的,后面的就会更高级有可能是图像目标中的一个部位。 3)这种多层神经网络的结构和人体大脑皮层的多层感知结构非常类似,所以说有一定的生物理论基础。")
6
Autoencoder(1/2) 降维问题:分类、可视化、通讯、高维数据的存储等方面很有用。
G. E. Hinton* and R. R. Salakhutdinov, SCIENCE 06, Reducing the Dimensionality of Data with Neural Networks 核心问题:用多层神经网络(核心层维度很低)将高维数据映射到一个低维的中间表达(编码),初始化权重如何设置合适? 这个用传统的主成分分析方法(PCA)很难; (Hinton,2006) 描述的自适应的,多层“编码”网络是PCA的非线性泛化; Hinton的深度自动编码(autoencoder)网络在设置初始化权重方面很有效,远比PCA好。 它能够将高维数据转换为低维编码,再用相似的“解码”网络从编码中恢复原始数据。 在coding过程中用神经网络降维,多个(2-4)隐含层的非线性autoencoders 权重优化问题比较困难 如果初始权重高了,autoencoders找到的是局部最小值不佳; 如果初始权重设的小了, 前端层的梯度很小,无法训练具有多个隐藏层的autoencoders 只有当初始权重接近于较好的(good solution)值,梯度下降能够很好地调整初始权重。但是找到这样的初始权重,需要有个一次学习一层特征的算法。 a nonlinear generalization of PCA 权重的优化,其实是减少输入和输出之间的差距;
将高维数据映射到一个低维的中间表达(编码),初始化权重如何设置合适? 这个用传统的主成分分析方法(PCA)很难; (Hinton,2006) 描述的自适应的,多层 编码 网络是PCA的非线性泛化; Hinton的深度自动编码(autoencoder)网络在设置初始化权重方面很有效,远比PCA好。 它能够将高维数据转换为低维编码,再用相似的 解码 网络从编码中恢复原始数据。 在coding过程中用神经网络降维,多个(2-4)隐含层的非线性autoencoders 权重优化问题比较困难. 如果初始权重高了,autoencoders找到的是局部最小值不佳; 如果初始权重设的小了, 前端层的梯度很小,无法训练具有多个隐藏层的autoencoders. 只有当初始权重接近于较好的(good solution)值,梯度下降能够很好地调整初始权重。但是找到这样的初始权重,需要有个一次学习一层特征的算法。 a nonlinear generalization of PCA. 权重的优化,其实是减少输入和输出之间的差距;")
7
优化目标:最小化重构误差(reconstruction error)
Autoencoder(2/2) (Hinton,2006)在降维过程中用的整个系统称为“autoencoder”; Autoencoder包含编码网络和解码网络; 给这两个网络随机设置初始权重,通过训练降低原始输入数据和得到的重构结果之间的差异; 使用错误反向传播链式法则(先通过解码器网络,再通过编码器网络)很容易得到所需的梯度。 优化目标:最小化重构误差(reconstruction error) Autoencoder (自动编码)是一种用于学习有效编码的人工神经网络。 为固定大小的输入(图像补丁或文档的字集表示)降低维度; 它是一种无监督的学习算法,通用应用反向传播算法将输入输出值等同起来; 它能够学习出对分类有用的特征。
 (Hinton,2006)在降维过程中用的整个系统称为 autoencoder ; Autoencoder包含编码网络和解码网络; 给这两个网络随机设置初始权重,通过训练降低原始输入数据和得到的重构结果之间的差异; 使用错误反向传播链式法则(先通过解码器网络,再通过编码器网络)很容易得到所需的梯度。 优化目标:最小化重构误差(reconstruction error) Autoencoder (自动编码)是一种用于学习有效编码的人工神经网络。 为固定大小的输入(图像补丁或文档的字集表示)降低维度; 它是一种无监督的学习算法,通用应用反向传播算法将输入输出值等同起来; 它能够学习出对分类有用的特征。")
8
SAE: stacked(deep) auto-encoder
本文引入二进制数据“预训练”操作,并扩展到实数范围内,证明它在各种数据集中的有效性。 确定这些初始权值的过程,被称为预训练。 Pre-training (无监督学习):每层网络用RBM预训练初始权重 就一组图片结构建模而言,单层二进制特征远远不够;特征学习是数据驱动的,一层特征检测学习之后,从数据中学习第二层特征。 下一个RBM中,第一层特征作为可见单元; 这一层层地学习可以重复很多次。 多层特征的预训练之后,模型用decoder网络进行展开。 Fine-tuning(用监督学习去调整所有层,全局的):通过在整个编码器网络中反向传播来调整权重,生成最优重构。用于降低交叉熵 Fine-tune是针对参数(权重)说的额; 使用反向传播技术进行微调(fine-tune) 多个RBM组成,每个只有一层特征检测器; Unroll:unfold 展开
:每层网络用RBM预训练初始权重. 就一组图片结构建模而言,单层二进制特征远远不够;特征学习是数据驱动的,一层特征检测学习之后,从数据中学习第二层特征。 下一个RBM中,第一层特征作为可见单元; 这一层层地学习可以重复很多次。 多层特征的预训练之后,模型用decoder网络进行展开。 Fine-tuning(用监督学习去调整所有层,全局的):通过在整个编码器网络中反向传播来调整权重,生成最优重构。用于降低交叉熵. Fine-tune是针对参数(权重)说的额; 使用反向传播技术进行微调(fine-tune) 多个RBM组成,每个只有一层特征检测器; Unroll:unfold 展开.")
9
SAE 使用RBM模型为图片(一组二进制向量)建模。 编码器网络应用如下可见层和隐含层之间的能量函数来为图片赋概率:
RBM是双层网络,像素是RBM的可见层,特征检测器是隐含层。 编码器网络应用如下可见层和隐含层之间的能量函数来为图片赋概率: 其中,vi是第i个像素, hj是第j个特征, bi和bj是它们的偏差(biases); wij是权重; 通过调整权重和偏差可以提高训练图像的概率,以便编码器网络反映真实的数据; 降低图像的能量并增强相似“编造”图片的能量。 实验结果证明,每一层的特征检测器数量不减少及其权重正确初始化的前提下,增加一个额外的层总是提高模型赋值给训练数据的对数概率的下界。这个下界不适用于特征很少的高层,但在深度autoencoder的权重预训练过程中,分层的学习算法非常有效。 每层得到的单元之间的关系比下一层更强、更高阶; 对各种不同数据集,它是一种找到低维度,非线性结构的有效方法。 二元组 在本文实验中,每个RBM的可见单元是[0,1]范围内的实数。最高层RBM之外的其他RBM中,隐含单元的状态都是二进制值,最顶部RBM的是高斯方差计算得到的实数值。
; wij是权重; 通过调整权重和偏差可以提高训练图像的概率,以便编码器网络反映真实的数据; 降低图像的能量并增强相似 编造 图片的能量。 实验结果证明,每一层的特征检测器数量不减少及其权重正确初始化的前提下,增加一个额外的层总是提高模型赋值给训练数据的对数概率的下界。这个下界不适用于特征很少的高层,但在深度autoencoder的权重预训练过程中,分层的学习算法非常有效。 每层得到的单元之间的关系比下一层更强、更高阶; 对各种不同数据集,它是一种找到低维度,非线性结构的有效方法。 二元组. 在本文实验中,每个RBM的可见单元是[0,1]范围内的实数。最高层RBM之外的其他RBM中,隐含单元的状态都是二进制值,最顶部RBM的是高斯方差计算得到的实数值。")
10
一般都是采用的层次贪婪训练方法来训练网络的参数,最后用这些训练好的网络参数值作为整体网络参数的初始值。
前面的网络层次基本都用无监督的方法获得; 只有最后一个输出层需要有监督的数据。 这些无监督学习其实已经隐形地提供了一些输入数据的先验知识,所以此时的参数初始化值一般都能得到最终比较好的局部最优解。 最后的就是用autoencoders学习到的参数来初始化整个网络了,此时整个网络可以看做是一个单一的神经网络模型,只是它是多层的而已,而通常的BP算法是对任意层的网络都有效的。

11
Autoencoder和PCA的比较效果(1/2)
1.Input 2.30-SAE 3.30-logisticPCA 4.30-PCA 1.Input 2.6-SAE 3.6-logisticPCA 4.18-logisticPCA 5.18-PCA 2.30-SAE 3.30-PCA 数字表示维数 (特征数量)或者 主成分的数量; Principal component analysis (PCA) 主成分分析 A:随机曲线;B:随机数字图像(分类用);C:测试数据集中的随机图片 A中,四种处理的误差分别为1.44, 7.64, 2.45, 5.90. B中,三种处理的误差分别为3.00, 8.01, C中,两种处理的误差分别为126和135. Autoencoder 显著胜于PCA
或者 主成分的数量; Principal component analysis (PCA) 主成分分析. A:随机曲线;B:随机数字图像(分类用);C:测试数据集中的随机图片. A中,四种处理的误差分别为1.44, 7.64, 2.45, B中,三种处理的误差分别为3.00, 8.01, C中,两种处理的误差分别为126和135. Autoencoder 显著胜于PCA.")
12
Autoencoder和PCA的比较效果(2/2)
2维的(两个特征面)自动编码器和两个主成分分析对比较图for 500 digits of each class produced by taking the first two principal components of all 60,000 training images 6万个0-9数字的训练图像,分别通过两个主成分分析方法和Autoencoder ( )的分类对比图 Autoencoder 显著胜于PCA
自动编码器和两个主成分分析对比较图for 500. digits of each class produced. by taking the first two principal components of all. 60,000 training images. 6万个0-9数字的训练图像,分别通过两个主成分分析方法和Autoencoder ( )的分类对比图. Autoencoder 显著胜于PCA.")
13
Autoencoder和LSA的比较效果
A:Autoencoder-10D,LSA-50D,LSA-10D在检索中的正确率 B: 2维-LSA C: autoencoder The fraction of retrieved documents in the same class as the query when a query document from the test set is used to retrieve other test set documents, averaged over all 402,207 possible queries. Latent Semantic Analysis (LSA), autoencoders的优点是能够快速检索; 804,414个新闻专线故事为数据源,构建2000个最常用词汇基于特定文档的单词向量; 在一半的上述故事语料中,用 autoencoder进行训练; 10个编码单元是线性的,其它隐含单元是Logistic; 两个编码夹角的余弦用于衡量相似度; Autoencoder 显著胜于著名的文档检索方法LSA (基于PCA) Autoencoders 也优于local linear embedding(较新的非线性降维算法)
, autoencoders的优点是能够快速检索; 804,414个新闻专线故事为数据源,构建2000个最常用词汇基于特定文档的单词向量; 在一半的上述故事语料中,用 autoencoder进行训练; 10个编码单元是线性的,其它隐含单元是Logistic; 两个编码夹角的余弦用于衡量相似度; Autoencoder 显著胜于著名的文档检索方法LSA (基于PCA) Autoencoders 也优于local linear embedding(较新的非线性降维算法)")
14
Autoencoder 小结 Y是X分布的一种表示方式;y是有损压缩,对所有输入x,它无法保证是损失小的好的压缩方式;
PCA:训练网络要用一个线性隐层(code)和均方误差准则,然后k个隐藏单元学习如何映射输入数据中的前k个主成分。 autoencoder 与PCA不同:隐层是非线性的, 有能力捕捉输入分布的综合方面(多方面信息)。 当处理叠加多个编码器(及其相应的解码器)的时候,构建深层的autoencoder 比起PCA作用显得更加重要。 Autoencoder的作用就是:在训练语料或与训练语料相同分布的语料中它能够提供较低的重构误差。 但是在encoding过程中得到的维度大于等于输入维度时,autoencoders 只学习出identity function,很多encoding出来的内容没用处(仅仅是输入的复制)。 以下几个方法可以避免这种对输入的复制,学习一些有用的信息: sparsity(稀疏限制,迫使许多隐藏的单元为零或接近于零); Restricted Boltzmann Machines (从输入到重构的随机性); Denoising Auto-Encoders(去噪自动编码算法) auto-encoders仅仅考虑重构误差最小化,没有其他限制的时候。。。 但均匀地选择输入向量的配置时,重构误差为高;
和均方误差准则,然后k个隐藏单元学习如何映射输入数据中的前k个主成分。 autoencoder 与PCA不同:隐层是非线性的, 有能力捕捉输入分布的综合方面(多方面信息)。 当处理叠加多个编码器(及其相应的解码器)的时候,构建深层的autoencoder 比起PCA作用显得更加重要。 Autoencoder的作用就是:在训练语料或与训练语料相同分布的语料中它能够提供较低的重构误差。 但是在encoding过程中得到的维度大于等于输入维度时,autoencoders 只学习出identity function,很多encoding出来的内容没用处(仅仅是输入的复制)。 以下几个方法可以避免这种对输入的复制,学习一些有用的信息: sparsity(稀疏限制,迫使许多隐藏的单元为零或接近于零); Restricted Boltzmann Machines (从输入到重构的随机性); Denoising Auto-Encoders(去噪自动编码算法) auto-encoders仅仅考虑重构误差最小化,没有其他限制的时候。。。 但均匀地选择输入向量的配置时,重构误差为高;")
15
Why sparse? Sparse Autoencoder即稀疏模式的自动编码器。
如果对隐含节点加入稀疏性限制(此时隐含层节点的个数一般比输入层要多),即对输入的数据而言,其大部分时间都处于抑制状态; 这时候学习到的特征就更有代表性,因为它只对它感兴趣的输入值响应,说明这些输入值就是我们需要学习的特征。 加入稀疏限制,网络的隐含层能够很好的代替输入的特征,它能够比较准确的还原出那些输入特征值
,即对输入的数据而言,其大部分时间都处于抑制状态; 这时候学习到的特征就更有代表性,因为它只对它感兴趣的输入值响应,说明这些输入值就是我们需要学习的特征。 加入稀疏限制,网络的隐含层能够很好的代替输入的特征,它能够比较准确的还原出那些输入特征值.")
17
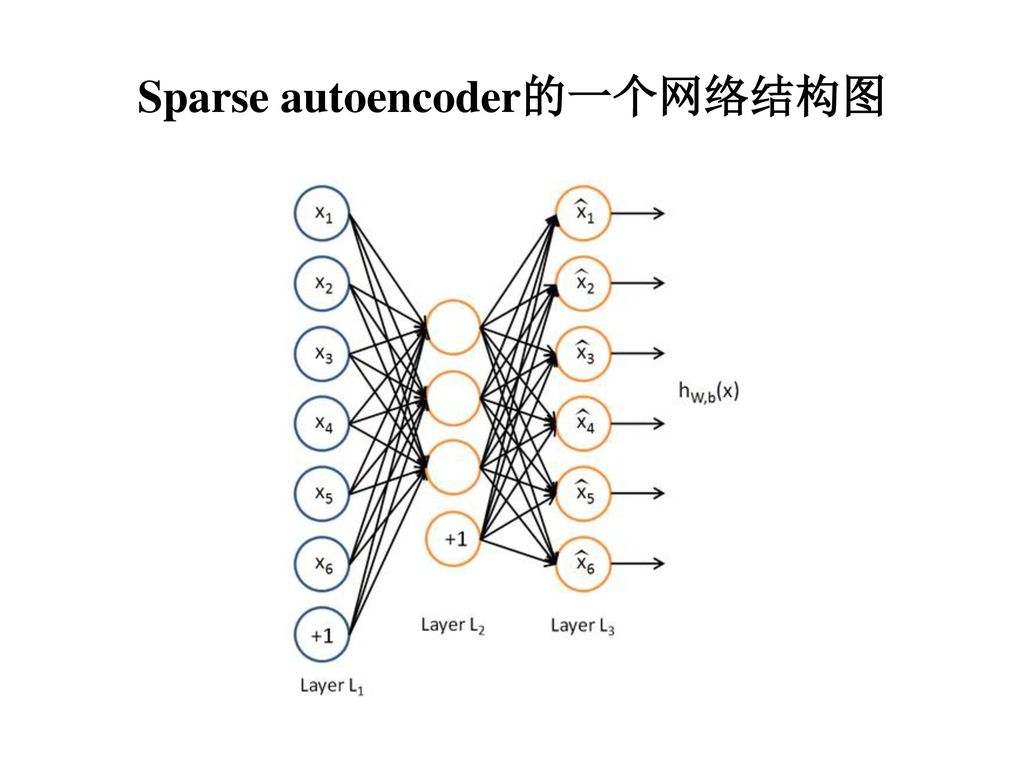
Sparse autoencoder的一个网络结构图

18
损失函数的求法——稀疏性惩罚值 所谓的稀疏性,并不是说对于某一个输入样本,隐含层中大部分的节点都处于非抑制状态,而是说对于所有的输入样本,某一个节点对这些输入的响应大部分都处于非抑制状态。 此时的稀疏性惩罚值公式如下所示: 其中的 变量(稀疏参数)一般取很小(0.05). 而 是隐藏单元的平均activation,如下: 是autoencoder中隐含层第j个单元的activation, 表示给定输入中第i个元素情况下,隐含层中第j个单元的activation是多少; sparsity penalty term (虽然事实上有可能确实是如此) 通常限制两个p相等,0.05; 把稀疏性惩罚值公式中的KL散度展开后,其公式如下:
一般取很小(0.05). 而 是隐藏单元的平均activation,如下: 是autoencoder中隐含层第j个单元的activation, 表示给定输入中第i个元素情况下,隐含层中第j个单元的activation是多少; sparsity penalty term (虽然事实上有可能确实是如此) 通常限制两个p相等,0.05; 把稀疏性惩罚值公式中的KL散度展开后,其公式如下:")
19
损失函数的求法——稀疏性惩罚值 无稀疏约束时网络的损失函数表达式如下:
稀疏编码是对网络的隐含层的输出有了约束,即隐含层节点输出的平均值应尽量为0,这样的话,大部分的隐含层节点都处于抑制状态。因此,此时的sparse autoencoder损失函数表达式为: 其中,KL距离的表达式: 隐含层 j 输出平均值求法如下: S2是隐含层神经元的个数; (KL散度是衡量两个不同分布的差距的标准函数)KL-divergence is a standard function for measuring how different two different distributions are 其中的参数一般取很小,比如说0.05,也就是小概率发生事件的概率。这说明要求隐含层的每一个节点的输出均值接近0.05(其实就是接近0,因为网络中activite函数为sigmoid函数),这样就达到稀疏的目的了。KL距离在这里表示的是两个向量之间的差异值。从约束函数表达式中可以看出,差异越大则”惩罚越大”,因此最终的隐含层节点的输出会接近0.05。
KL-divergence is a standard function for measuring how different two different distributions are. 其中的参数一般取很小,比如说0.05,也就是小概率发生事件的概率。这说明要求隐含层的每一个节点的输出均值接近0.05(其实就是接近0,因为网络中activite函数为sigmoid函数),这样就达到稀疏的目的了。KL距离在这里表示的是两个向量之间的差异值。从约束函数表达式中可以看出,差异越大则 惩罚越大 ,因此最终的隐含层节点的输出会接近0.05。")
20
损失函数的偏导数的求法 加入了稀疏性后,神经元节点的误差表达式由公式:
如果不加入稀疏规则,则正常情况下由损失函数求损失函数偏导数的过程如下: 1、前馈计算各个隐藏层 的activation(输入层对各个层的激活程度) 2、输出层nl中各个结点i求偏导 3、每个隐藏层 中各个结点i 4、计算偏导数 损失函数是由每个训练样本的损失叠加而成的,而按照加法的求导法则,损失函数的偏导也应该是由各个训练样本所损失的偏导叠加而成。 -从公式可以看出,损失函数的偏导其实是个累加过程,每来一个样本数据就累加一次。 因此,训练样本输入网络的顺序并不重要。 -每个训练样本所进行的操作是等价的; -后面样本的输入所产生的结果并不依靠前一次输入结果。
 2、输出层nl中各个结点i求偏导. 3、每个隐藏层 中各个结点i. 4、计算偏导数. 损失函数是由每个训练样本的损失叠加而成的,而按照加法的求导法则,损失函数的偏导也应该是由各个训练样本所损失的偏导叠加而成。 -从公式可以看出,损失函数的偏导其实是个累加过程,每来一个样本数据就累加一次。 因此,训练样本输入网络的顺序并不重要。 -每个训练样本所进行的操作是等价的; -后面样本的输入所产生的结果并不依靠前一次输入结果。")
21
梯度下降法求解 有了损失函数及其偏导数后就可以采用梯度下降法来求网络最优化的参数了,整个流程如下所示:
只是简单的累加而已,而这里的累加是顺序无关的

22
Autoencoder在NLP中的应用 有两篇文章
Richard Socher, Jeffrey Pennington, Eric Huang, Andrew Y. Ng, and Christopher D. Manning. Semi-Supervised Recursive Autoencoders for Predicting Sentiment Distributions. EMNLP 2011 在检测两个句子是否表达一个含义的问题中,从句法树中学习短语的特征向量,用这些特征来计算两个句子从单词和短语级别的相似度计算; 提出dynamic pooling layer(pooled表示作为分类器的输入) Richard Socher, Eric Huang, Jeffrey Pennington, Andrew Y. Ng, and Christopher D. Manning. Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection. NIPS 2011 预测句子级情感分布问题中的应用; 没有情感词典,分析器,情感分析的规则 在统一情感分析数据中的结果与其它方法的性能相同。
 Richard Socher, Eric Huang, Jeffrey Pennington, Andrew Y. Ng, and Christopher D. Manning. Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection. NIPS 预测句子级情感分布问题中的应用; 没有情感词典,分析器,情感分析的规则. 在统一情感分析数据中的结果与其它方法的性能相同。")
23
应用实例——paraphrase detection
意译(复述)实例: S1 The judge also refused to postpone the trial date of Sept. 29. S2 Obus also denied a defense motion to postpone the September trial date. 本文对意译问题的解决方案如下:两个句子的句法树表示训练单词和短语的特征,再计算这些特征的相似性。 应用单词特征和短语(句法树中得到)特征 用unfolding recursive autoencoder (RAE),在未标注的句法树中计算相似性 用本文提出的dynamic pooling layer输出固定大小的表示。 将确定句对是否意译问题转换为分类问题,用Sofrmax classifier等分类器来确定两个句子是否表示相同含义。
实例: S1 The judge also refused to postpone the trial date of Sept. 29. S2 Obus also denied a defense motion to postpone the September trial date. 本文对意译问题的解决方案如下:两个句子的句法树表示训练单词和短语的特征,再计算这些特征的相似性。 应用单词特征和短语(句法树中得到)特征. 用unfolding recursive autoencoder (RAE),在未标注的句法树中计算相似性. 用本文提出的dynamic pooling layer输出固定大小的表示。 将确定句对是否意译问题转换为分类问题,用Sofrmax classifier等分类器来确定两个句子是否表示相同含义。")
25
单词的神经元表示 分两步完成单词的连续向量参数表示。 第一步,用均值为0的高斯分布 简单初始化所有的单词向量 ;
第一步,用均值为0的高斯分布 简单初始化所有的单词向量 ; 这些词向量存储到一个嵌入矩阵 ,这个初始化工作在有监督的情况下效果好,整个网络随后修改这些向量来捕捉分布。 第二步,用无监督的神经语言模型预训练这些单词向量; 学习向量空间中的单词以及它们的上下文信息;通过梯度上升(gradient ascent)从共现统计信息中得到这些单词的语义和语法信息。 通过这两步从单词向量L得到一个矩阵,可以用于跟自然语言处理相关的任务。假设句子是m个单词序列,每个单词在嵌入矩阵中有个相应的索引k用于返回单词的向量表示。从数学上,这个操作可以看做是一种投影,用一个除了第k个位置之外全为0的二进制向量b。 用向量及嵌入矩阵表示句子,比起二进制模型更适合自动编码(因为sigmoid units是连续的)。 Pollack (1990)用的词汇量少,并且人工定义阈值的方法来完成向量二值化。
从共现统计信息中得到这些单词的语义和语法信息。 通过这两步从单词向量L得到一个矩阵,可以用于跟自然语言处理相关的任务。假设句子是m个单词序列,每个单词在嵌入矩阵中有个相应的索引k用于返回单词的向量表示。从数学上,这个操作可以看做是一种投影,用一个除了第k个位置之外全为0的二进制向量b。 用向量及嵌入矩阵表示句子,比起二进制模型更适合自动编码(因为sigmoid units是连续的)。 Pollack (1990)用的词汇量少,并且人工定义阈值的方法来完成向量二值化。")
26
Recursive Autoencoder
在编码过程中,递归应用公式 生成父结点(新的向量表示),并计算向量与其输入之间的欧氏距离 递归得到y2以及对应的重构误差。。。。 隐含层的萎缩(缩水。。。) 训练中,主要目标是最小化句法树T中非叶子结点p中输入输出之间的重构误差 ,即 递归生成整个树结构,并计算各个结点的重构误差(EL) 解码过程中,通过公式 得到y1; 缺点:1)hidden layers shrinking in norm; 2)最后一层的单词和短语权重相等
,并计算向量与其输入之间的欧氏距离. 递归得到y2以及对应的重构误差。。。。 隐含层的萎缩(缩水。。。) 训练中,主要目标是最小化句法树T中非叶子结点p中输入输出之间的重构误差 ,即. 递归生成整个树结构,并计算各个结点的重构误差(EL) 解码过程中,通过公式 得到y1; 缺点:1)hidden layers shrinking in norm; 2)最后一层的单词和短语权重相等.")
27
Unfolding Recursive Autoencoder
递归生成整个树结构,并计算各个结点的重构误差(EL) 在解码中重构层不同; 通过公式 得到 ; 递归分解 ,生成新的向量 通常,重复使用解码矩阵 ,展开生成与编码过程对称的树结构。 重构误差是当前结点范围内的连续单词向量计算得到;假设结点y从单词i到j: 在传统RAE的基础上,增强较大非叶子结点的重要性。 两种自动编码方式,在解码中重构层不同;
 在解码中重构层不同; 通过公式 得到 ; 递归分解 ,生成新的向量. 通常,重复使用解码矩阵 ,展开生成与编码过程对称的树结构。 重构误差是当前结点范围内的连续单词向量计算得到;假设结点y从单词i到j: 在传统RAE的基础上,增强较大非叶子结点的重要性。 两种自动编码方式,在解码中重构层不同;")
28
REA训练 训练过程是基于一组句法树的,最小化所有节点重构误差和。 应用文献13提出的结构的反向传播算法有效地计算了梯度。
对于非凸物体,L-BFGS run with mini-batch training效果很好。 算法能够平滑地收敛,并能够找到局部最优解。 RAE的非监督训练之后,特征表示包含了句法和语义层面的相似性,都能够用于检测意译。

29
An Architecture for Variable-Sized Similarity Matrices
1、计算给定的句法树中各个非叶子结点的短语向量; 2、计算两个句子对应的句法树中所有单词和短语的欧氏距离,并生成相似度矩阵S。 两个句子相似性比较中,如果简单提取矩阵S中汇总统计信息(比如平均距离或距离的直方图),无法准确地捕捉到全局结构。 就两个意译的句子而言,相似性矩阵的对角线或附近的元素往往有较低或为零的欧氏距离(两个句子之间的词对齐比较好的情况下发生)。 矩阵维度是根据句子长度不同而变化,不同维度导致无法将矩阵S转为一个标准的神经网络或分类器。
,无法准确地捕捉到全局结构。 就两个意译的句子而言,相似性矩阵的对角线或附近的元素往往有较低或为零的欧氏距离(两个句子之间的词对齐比较好的情况下发生)。 矩阵维度是根据句子长度不同而变化,不同维度导致无法将矩阵S转为一个标准的神经网络或分类器。")
30
Dynamic Pooling 设相似度矩阵S是有长度n和 m的两个句子组成; 句法树是二叉树,因此非叶子结点集合为:
分割过程中只有把2n-1和2m-1用np约,才会得到相等的维度。 矩阵S的行数 R=2n-1,那么每个合并窗口含有 个行; 表示剩余的行数,将这M个行分配到最后M个区域(每个具有 行) 对矩阵S列的划分也类同。 如果遇见 的情况, Pooling layer需要先补充样本。为此,通过简单的复制在行向量一直到
 对矩阵S列的划分也类同。 如果遇见 的情况, Pooling layer需要先补充样本。为此,通过简单的复制在行向量一直到.")
31
实验 实验数据: 在无监督RAE训练中,使用了《纽约时报》的15万句的子集和Gigaword语料库美联社的部分。使用斯坦福句法分析器解析所有的句子。对于初始的word embeddings本文使用100维的向量用无监督算法计算。 意译的实验数据是由Dolan et al.提供的Microsoft Research Paraphrase (MSRP) Corpus——包含5081句对,平均长度21;其中3900具有意译关系(双向的)。 训练数据:4076句对(67.5%是意译关系) 测试数据:1725句对(66.5%是意义关系) 句对之间是否意译关系,先有两位专家标注(二者83%统一),第三位专家解决有冲突的部分。 一般对参数进行regularization时,前面都有一个惩罚系数,这个系数称为regularization parameter 在数据集收集工作中,选择具有较高的词汇重叠的反面例子,防止数据过于简单。
 Corpus——包含5081句对,平均长度21;其中3900具有意译关系(双向的)。 训练数据:4076句对(67.5%是意译关系) 测试数据:1725句对(66.5%是意义关系) 句对之间是否意译关系,先有两位专家标注(二者83%统一),第三位专家解决有冲突的部分。 一般对参数进行regularization时,前面都有一个惩罚系数,这个系数称为regularization parameter. 在数据集收集工作中,选择具有较高的词汇重叠的反面例子,防止数据过于简单。")
32
最紧邻的定性评价 为了展示本文学习得到的特征表示(甚至在树结构中高层)抓获了重要的语义和句法信息,设想不同长度的最近邻短语;
用Gigaword语料 计算树中各个结点的最近邻; Recursive averaging baseline (R.Avg)、RAE和没有隐藏层的unfolding RAE之间的比较; R.Avg是递归计算句法树中各个叶子结点(两两计算)向量的平均值; 本文只报告没有隐藏层的RAEs中孩子和父母结点向量计算结果。 尽管深RAE网络有更多的参数学习出更复杂的编码,它们在意译和下一个任务中效果不是很好。这可能是由于它们在训练中陷入局部最优解。
、RAE和没有隐藏层的unfolding RAE之间的比较; R.Avg是递归计算句法树中各个叶子结点(两两计算)向量的平均值; 本文只报告没有隐藏层的RAEs中孩子和父母结点向量计算结果。 尽管深RAE网络有更多的参数学习出更复杂的编码,它们在意译和下一个任务中效果不是很好。这可能是由于它们在训练中陷入局部最优解。")
33
表中第一列是随机抽取的短语;其它列的短语(长度没有限制,不限制字长相同)是来自数据集中其它的句子最接近的短语;
上述表显示了一些有趣的现象。递归平均的问题在于使得最接近的短语错误地添加各种额外的信息,仅仅考虑顶部结点向量,忽略语法相似性;这将打破意译的关系。 传统RAE的结果比递归平均方法好。 Unfolding RAE捕捉了最接近底层的句法和语义结构。

34
通过递归解码重建短语 主要分析用unfolding RAE方法捕获的信息。 为了显示多少个信息能够恢复,本文编码后递归地重建句子。
它从一个句法树中非终结结点的短语向量开始;然后参照编码过程给出的结果展开树,每个重建叶节点向量中找最接近的相邻单词。 下表显示,unfolding RAE可以很好地重建长达5个单词的短语。 展开RAE的重建能力胜于其它方法。 这些较长的短语保留了正确的单词和词性,并将单词语义合并在一起。 unfolding RAE方法( 100维的短语向量) 递归平均; 展开(unfolding) 相邻单词?还是邻居单词?
 递归平均; 展开(unfolding) 相邻单词?还是邻居单词?")
35
全句意译的评价 评估无监督的特点和本文的动态资源池架构在主要任务意译检测中的作用。 因此,添加三个数字相关特征。
完全基于向量表示的方法总是失去一些信息。 例如,数字往往有非常类似的陈述,对于拒绝MSRP数据集的意译关系,即使是很小的差异也是至关重要的。 因此,添加三个数字相关特征。 1)如果两个句子包含完全相同的数字,或都没有数字出现特征值为1,否则为0; 2)如果两个句子包含相同的数字,特征值为1; 3)如果一个句子的数字集合是另一个句子数字集合的子集( strict subset ),特征值为1。 由于本文的pooling-layer不能捕捉句子长度或精确匹配串的数量,本文还增加句子的长度和不同句子中单词和短语的百分比差异的惩罚值。 our dynamic pooling architecture(动态资源池架构)
如果两个句子包含完全相同的数字,或都没有数字出现特征值为1,否则为0; 2)如果两个句子包含相同的数字,特征值为1; 3)如果一个句子的数字集合是另一个句子数字集合的子集( strict subset ),特征值为1。 由于本文的pooling-layer不能捕捉句子长度或精确匹配串的数量,本文还增加句子的长度和不同句子中单词和短语的百分比差异的惩罚值。 our dynamic pooling architecture(动态资源池架构)")
36
对于本文的所有模型和训练设置,训练数据上进行10-fold交叉验证,选择最佳的正则化参数和pooling矩阵 的维度np;
在本文模型中,最好的pooling size 是np = 15,稍低于平均句子长度。 第一组实验中,比较几个无监督的学习方法:递归平均、标准RAEs、展开的RAEs。 三种方法均应用交叉验证训练出训练数据的超参数(hyperparameter),给出最佳性能。 观察到动态资源池层是非常强大的,因为它抓住了全局结构的相似性矩阵,抓住了两个句子的句法和语义相似性。 传统RAE和递归平均在此训练数据集上的正确率分别为75.5%和75.9%; 没有隐藏层的展开RAE得到的最好正确率为76.8%; 试着加入1和2隐藏的编码和解码层,性能仅下降0.2%,训练速度变慢。 SOFTMAX分类器
,给出最佳性能。 观察到动态资源池层是非常强大的,因为它抓住了全局结构的相似性矩阵,抓住了两个句子的句法和语义相似性。 传统RAE和递归平均在此训练数据集上的正确率分别为75.5%和75.9%; 没有隐藏层的展开RAE得到的最好正确率为76.8%; 试着加入1和2隐藏的编码和解码层,性能仅下降0.2%,训练速度变慢。 SOFTMAX分类器.")
37
对于每种实验设置,训练数据上的交叉验证,得到的最佳性能如下: (i) S-Hist (73.0%): 矩阵S的直方图表示;
简单的特征提取方法和dynamic pooling 比较结果表明,动态资源池架构( dynamic pooling architecture )能够达到较高精度。 对于每种实验设置,训练数据上的交叉验证,得到的最佳性能如下: (i) S-Hist (73.0%): 矩阵S的直方图表示; 它较低的性能表明,我们的dynamic pooling layer 比起汇总统计信息更能抓住全局相似性。 (ii) Only Feat (73.2%) :上述三种数字特征; 这表明简单的二进制字符串和数字匹配可以检测很多简单意译句子,但不能检测出复杂的情况。 (iii) Only Spooled (72.6%): 不加三种数字特征; 这表明Spooled中的一些信息丢失,需要更好地处理数字。 为了更好地恢复精确字符串匹配,可能有必要探索重叠的pooling regions 。 (iv) Top Unfolding RAE Node (74.2%): 结果证明, Unfolding RAE本身是非常强大的,动态资源池层( dynamic pooling layer )用于从句法树中提取所有信息。
能够达到较高精度。 对于每种实验设置,训练数据上的交叉验证,得到的最佳性能如下: (i) S-Hist (73.0%): 矩阵S的直方图表示; 它较低的性能表明,我们的dynamic pooling layer 比起汇总统计信息更能抓住全局相似性。 (ii) Only Feat (73.2%) :上述三种数字特征; 这表明简单的二进制字符串和数字匹配可以检测很多简单意译句子,但不能检测出复杂的情况。 (iii) Only Spooled (72.6%): 不加三种数字特征; 这表明Spooled中的一些信息丢失,需要更好地处理数字。 为了更好地恢复精确字符串匹配,可能有必要探索重叠的pooling regions 。 (iv) Top Unfolding RAE Node (74.2%): 结果证明, Unfolding RAE本身是非常强大的,动态资源池层( dynamic pooling layer )用于从句法树中提取所有信息。")
38
上表显示了本文的研究结果与已有方法(意译问题中的经典方法)性能比较结果。
本文的unfolding RAE 和 dynamic similarity pooling architecture得到了最好性能,它不需要人工设计语义分类法和WordNet等特性。 注:精度的有效范围介于66%(最常用的分类基线系统)和83%(标注专家达成一致的比例)之间。
和83%(标注专家达成一致的比例)之间。")
39
表中,给出了几个正确分类的意译候选句对实例,以及它们dynamic min-pooling之后的相似矩阵。 第一个和最后一个例句比较简单。
第二个例子显示了一个pooled 相似矩阵,因为两个句子中语块有位置的交换。 本文的模型针对这种转变非常强大,句对之间的概率达到了82%。 针对例3等直接字符串匹配很少(个别的蓝色正方形)的更复杂例子,给出了正确分类。 倒数第二个例子有一个清晰的对角线与良好的字符串匹配,但是在中心的间距表明,第一句话有很多额外的信息。 这中意译也被本文的模型给出正确分类结果。
的更复杂例子,给出了正确分类。 倒数第二个例子有一个清晰的对角线与良好的字符串匹配,但是在中心的间距表明,第一句话有很多额外的信息。 这中意译也被本文的模型给出正确分类结果。")
40
Reference http://deeplearning.net/tutorial/dA.html#daa
视频 Richard Socher, Jeffrey Pennington, Eric Huang, Andrew Y. Ng, and Christopher D. Manning. Semi-Supervised Recursive Autoencoders for Predicting Sentiment Distributions. EMNLP 2011 Richard Socher, Eric Huang, Jeffrey Pennington, Andrew Y. Ng, and Christopher D. Manning. Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection. NIPS 2011



 一上一下二上二下三上 校訂必修校訂必修 英文 I 中文閱讀與寫作 I 計算機概論 I 體育 服務與學習教育 I 英文 II 中文閱讀與寫作 II 計算機概論 II 體育 服務與學習教育 II.>")











>")






