Download presentation
Presentation is loading. Please wait.

1
一种对于单声道声源定位的3D声音定位算法DSP执行器
DSP IMPLEMENTATION OF 3D SOUND LOCALIZATION ALGORITHM FOR MONAURAL SOUND SOURCE

2
摘要 这篇论文描述了一个实时的3D声音定位算法.通过使用一个低功耗嵌入式DSP来执行验证。这种执行器的最大不同在于音频被分成了三段,通过分析声音的反射和衍射效应对于不同的媒介来自于一定的声源。在低、中、高三个不同的子频带。3D声音定位的不同方案被设计通过一个IIR滤波器,参数补偿器和comb滤波器。以实现在一个实时的DSP上运行。它是在一个50MHZ的低频下运行的。来保持高质量的声音定位效果。通过一个目标听者测试,这个3D声音定位系统可以用于移动听筒,或者手机等嵌入式设备。

3
引言 最近几年里,在声学信号处理领域里一些复杂的方法已经被使用来实现3D声音作用。主要建立在一个所谓的头相关传递函数(HRTF)基础上的它是受到声源的反射和衍射作用影响的。通常情况下,给定一个声源,3D声音定位可以实现在基于HRTF上从声源到左右耳。
基础上的它是受到声源的反射和衍射作用影响的。通常情况下,给定一个声源,3D声音定位可以实现在基于HRTF上从声源到左右耳。")
4
一个HRTF特性通常过于复杂对于不同的数字滤波为了有更大的自由度必须在整个过程都改变参数。然而,这个HRTF的方法已经不能胜任一个DSP的实时3D声音定位。
为了解决这些困难,这篇论文设计了一个实时3D声音定位算法的DSP执行器。在它上面计算的复杂度被评估去说明这种方法的可行性。最后声音质量被评估由一个目标听者测试。

5
通常的3D声音定位方法 通常的HRTF的3D声音定位系统可以被简单的描述如下:首先,计算必要的HRTF函数,可以通过两个等式来实现。一个是代表给定的声源信号,另一个是表明来自于虚拟头微听筒的声音输出。然后,单声道输入数据被这些HRTF函数处理,最后把结果提供给了输出的立体听筒

6
通常情况下,HRTF的频率响应特性是如此复杂以至于需要大量的数字滤波对于3D声音定位。例如,一个参数补偿器是由大量的数字滤波器组成的。所有的参数包括频率,增益,和质量因子等都要考虑在内。而且,不同的频率响应特性对于左耳右耳都不同,这样就需要很多的不同结构的滤波器。如果都用参数补偿器来实现HRTF,单声道就需要30个补偿器。 结果,这种方法还有很多的空间来改变计算复杂性的障碍,为了完成3D声音定位的DSP执行器。

8
传奇的实时算法 为了给出一个新的算法我们首先分析了HRTF函数为了提炼出主要的因素来降低全部的计算复杂性。
图1描述了一个HRTF频率响应通过双耳记录在一个右耳的45度角设置声源。通常情况下,通常一个HRTF频率特性可以像图1那样分三个子带,其中低频带特性曲线很平滑的上下改变。在中层的带宽突然的跌破的改变,高频呢是剧烈的震动。 因此,在下面一个有效的模拟衍射特性的方案被用于每个频段。

9
3.1低频带 在低频带,从 KHZ的频率,响应在这里很平缓的上下波动。而且在这一阶段左右耳的不同假设音速和头直径是340m/s和 mm边界频率是f=v/(2d)= hz。 结果,可以被证明在这个频带里,头部的声音衍射必须被考虑为一个主要的因素。仅仅通过声音容量和延迟在两耳的不同对于定位有很多的影响。 为了实现这些参数一个IIR滤波器可以被使用,这个特性可以被构造通过采用一个高通IIR滤波。

10
3.2高频带 现在,我们考虑声音衍射通过人耳,假设人耳是一个圆锥体直径在35-55mm,如果声源半波长比基本直径短的话,这是就必须考虑它对声音衍射的影响了。可以通过一个comb滤波器来估计高频带的频率响应特性

11
3.3中频带 在中频带主要是介于1khz到5khz之间。这里有一些突变的波形在图一中可以看到。 因此,3D声音定位可以通过采用参数补偿来执行,对于左右耳在同样的方式,像通常的方法一样。因为这些复杂的特性很难精确的实现用带通滤波器。在这个频率里一个HRTF传函主要是被声音衍射通过头和耳等来影响的。 在我们的算法里,PEQs仅仅在中带频段里用到,因此大量的步骤可以被减少。在通常的方法里在低高带里都用到了参数补偿器。

12
实时算法的DSP执行器 我们采用了16位定点DSPTMS320C54x在图二中给出。正如图中所说,这个实时算法的执行程序被分成了三个阶段,第一,分频阶段。第二,声音定位。第三,混合。在这个已经完成的3D定位的例子里,听觉输入数据被分成了左右两个通道,并视听输入数据在时间队列里被一个一个的处理。每个阶段被归纳如下:

14
阶段一,分频:我们的实时算法是从把一个给定的频分音频输入分频开始的。声音被分成低中高三个频带,通过三个三阶低通带通和高通FIR滤波。例如FIR滤波器有一个特性是相位正比于频率。参数被存在了一个DSP的内部存储器。 第二阶段,声音定位:3D声音定位调用听觉数据在每一个频带里。在这个阶段里,声源的方向和距离声源的位置在每个频带里被看做听觉数据。 在低频带里,我们仅仅考虑在左右通道的声音延迟和体积参数。我们注意到3D声音定位系统可以被实现通过只使用一个一阶IIR滤波器。 在中频带里,为了精确的产生一个HRTF的频率响应特性,三个三阶IIR滤波器被采用作为补偿器。 在高频带里,一个comb滤波器,被采用来实现3D声音定位。共包括四个参数直接增益,效应增益,反馈增益和延迟是必须的。 第三阶段,混合。在3D声音定位之后,三个频带的声音数据被混合。 在这个混合阶段,每个数据可以被调整通过一个倍乘增益。整个延迟控制在图二中被用于两耳的到达时间的不同。

15
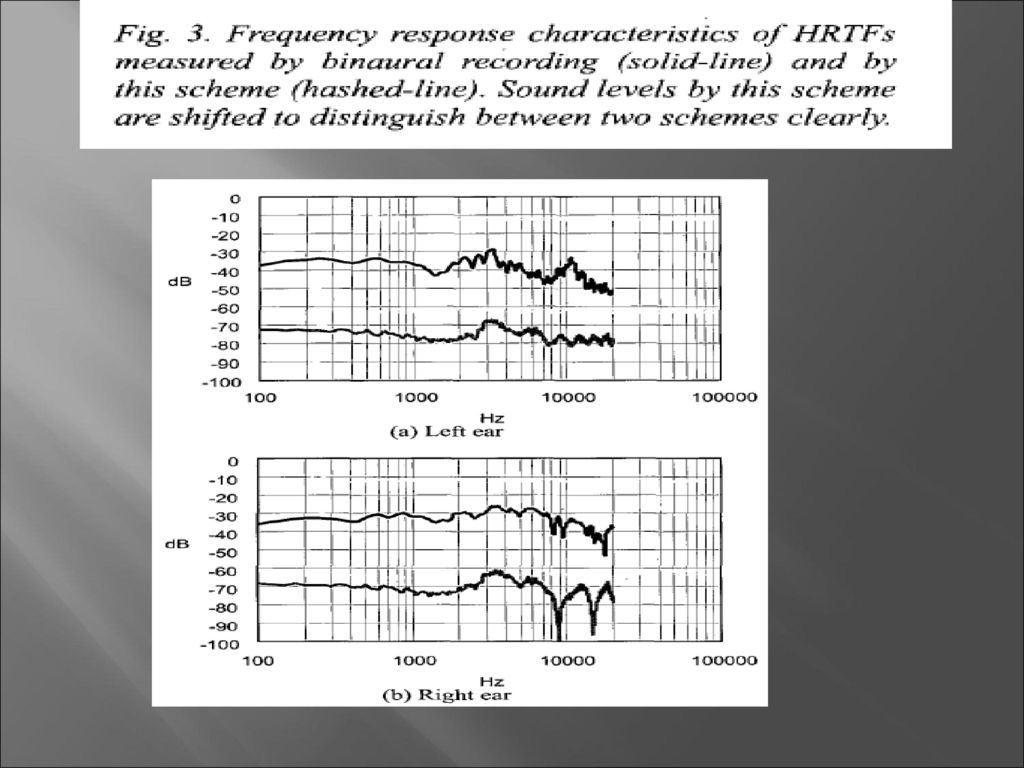
试验结果 图三,显示了这种方法对于白噪声的响应。我们可以看到建议的方法成功的实现了HRTF的频率响应特性。

17
表二,归纳了我们方法对于普通方法的对比的结果。我们给的方法任然获得了“好”的评估

18
判断出了三个类型:声音定位,距离和方向。对于声音定位我们问的是“你能察觉到在在你头外的声源通过听筒吗?”对于距离我们问:“你能说出离你远1m的声音的位置”对于方向而言是:“你知道声音来自于哪个方向呢?”我们评估了五级“极好”“好”“一般”“差”“太差”。

19
结论 这篇论文描述了一个基于实时3D声音定位方法的DSP执行器。它的特殊的之处在于这种方法把声音频带分为三个不同的频段。一个特殊的3D声音定位程序被用于每个阶段。用了一个16位定点DSPTMS320C54x实时3D声音定位方法对于一个给定的单声道声源可以被实现在一个50MHZ的低频保证了高质量的声音定位。 结果,我们的新方法可以有效的提供一个听者一个3D定位通过听筒等等。这个是在一个低成本低功耗的DSP执行器上实现的。

Similar presentations




 庄子(道家学派) 老子(道家学派)>")



声音的产生:声音是由于物体的振动产生的。 凡是发声的物体都在振动。振动停止,发声也停止。 ( 2 )声源:正在发声的物体叫声源。固体、液体、气体 都可以作为声源,有声音一定有声源。 ( 3 )声音的传播:声音的传播必须有介质,声音可以在.>")








>")



有限公司 毕业生招聘宣讲会>")
 第一章 有理数 授课人:三元中学 苏鼎明.>")