Download presentation
1
Tel: 13576088276 第八章 时间序列分析 周早弘 旅游与城市管理学院 zhzhou3995@126.com
2017/3/92017/3/9

2
概述 时间序列分析是一种动态数据处理的统计方法。该方法基于随机过程理论和数理统计学方法,研究随机数据序列所遵从的统计规律,以用于解决实际问题。 时间序列是按随机过程的一次实现,即随时间而变化、具有动态性和随机性数字序列。在现实中,许多统计资料都是按照时间进行观测记录的,因此时间序列分析在实际分析中具有广泛的应用。

3
概述 时间序列模型不同于一般的经济计量模型,其不以经济理论为依据,而是依据变量自身的变化规律,利用外推机制描述时间序列的变化。时间序列模型在处理的过程中必须明确考虑时间序列的非平稳性。

4
时间序列数据类型 四种类型: 长期趋势性T:总体上持续上升或下降的总变化趋势,其间的变动幅度可能有时不等。
周期性C:决定于系统内部因素的周期性变化规律,又分短周期、中周期、长周期等几种。 季节性S:以一年为周期,四个季节呈某种周期性,各季节出现波峰和波谷的规律类似。 不规则性I:包括突然性和随机性变动两种。 任何一个时间序列可以表示为几种变动的不同组合的总结果,且可表示为: 加法模型:Y=T+S+C+I 乘法模型:Y=T·S·C·I 季节性变动是一种典型的周期变动,它以一年为周期,而且这种周期主要是由外部因素(季节)造成的。 任一时间序列可表示为几种变动的不同组合的总结果,且可表示为: 加法模型:Y=T+S+C+I 乘法模型:Y=T·S·C·I
造成的。 任一时间序列可表示为几种变动的不同组合的总结果,且可表示为: 加法模型:Y=T+S+C+I. 乘法模型:Y=T·S·C·I.")
5
—— 长期趋势项 —— 周期项 —— 随机项

6
一、时间序列的预处理 SPSS的时间序列的预处理是指定义时间序列和时间序列平稳化处理。 进行时间序列分析前是必须进行的一个环节,因为SPSS无法自动识别时间序列数据并且时间序列数据在处理的过程中必须明确考虑时间序列的非平稳性,因此在进行时间序列分析前,我们必须对时间序列进行预处理。

7
8.1.1预处理的基本原理 通过预处理,一方面能够使序列的随“时间”变化的、“动态”的特征体现得更加明显,利用模型的选择;另一方面也使得数据满足与模型的要求。

8
预处理内容 (1)特征分析 所谓特征分析就是在对数据序列进行建模之前,通过从时间序列中计算出一些有代表性的特征参数,用以浓缩、简化数据信息,以利数据的深入处理,或通过概率直方图和正态性检验分析数据的统计特性。通常使用的特征参数有样本均值、样本方差、标准偏度系数、标准峰度系数等。 (2)相关分析 所谓相关分析就是测定时间序列数据内部的相关程度,给出相应的定量度量,并分析其特征及变化规律。 理论上,自相关系数序列与时间序列具有相同的变化周期.所以,根据样本自相关系数序列随增长而衰减的特点或其周期变化的特点判断序列是否具有平稳性,识别序列的模型,从而建立相应的模型。
相关分析. 所谓相关分析就是测定时间序列数据内部的相关程度,给出相应的定量度量,并分析其特征及变化规律。 理论上,自相关系数序列与时间序列具有相同的变化周期.所以,根据样本自相关系数序列随增长而衰减的特点或其周期变化的特点判断序列是否具有平稳性,识别序列的模型,从而建立相应的模型。")
9
进行时间序列预处理的时候,常常需要对数据一些变换,例如,季节性差分,取对数,做一阶差分,等。
注意事项 进行时间序列预处理的时候,常常需要对数据一些变换,例如,季节性差分,取对数,做一阶差分,等。

10
2 时间序列预处理的操作 Step01:数据准备 选择菜单栏中的【数据】→【定义日期】命令,弹出【定义日期 】对话框。

11
单击【OK(确认)】按钮, 此时完成时间的定义, SPSS将在当前数据编辑窗 口中自动生成标志时间的变量。
】按钮, 此时完成时间的定义, SPSS将在当前数据编辑窗 口中自动生成标志时间的变量。")
12
数据采样 选择菜单栏中的【Data(数据)】→【Select Cases(选择个案)】命令,弹出【Select Cases(选择个案)】对话框。
】→【Select Cases(选择个案)】命令,弹出【Select Cases(选择个案)】对话框。")
13
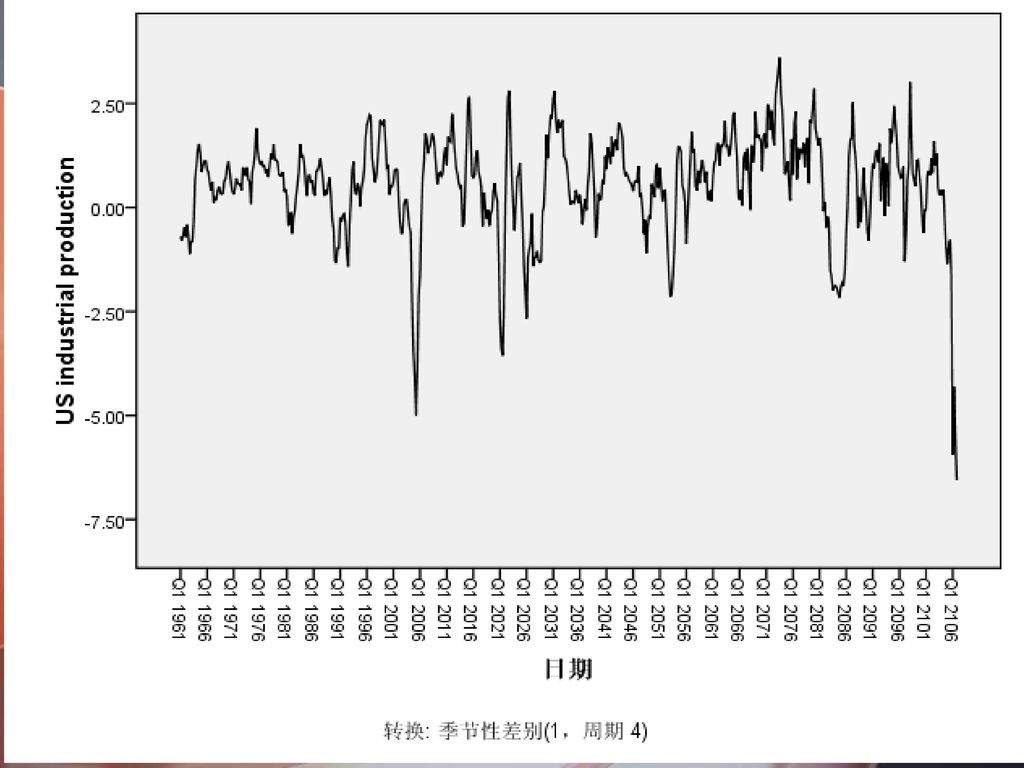
直观分析 当数据准备好,为认识数据的变化规律,判断数据是否存在离群点和缺损值,最直接的观察方法是绘制序列的图像。
选择菜单栏中的【分析】→【预测】→【序列图)】命令,弹出【序列图】对话框。
】命令,弹出【序列图】对话框。")
15
相关分析 选择菜单栏中的【分析】→【预测】→【自相关】命令,弹出【自相关】对话框。

17
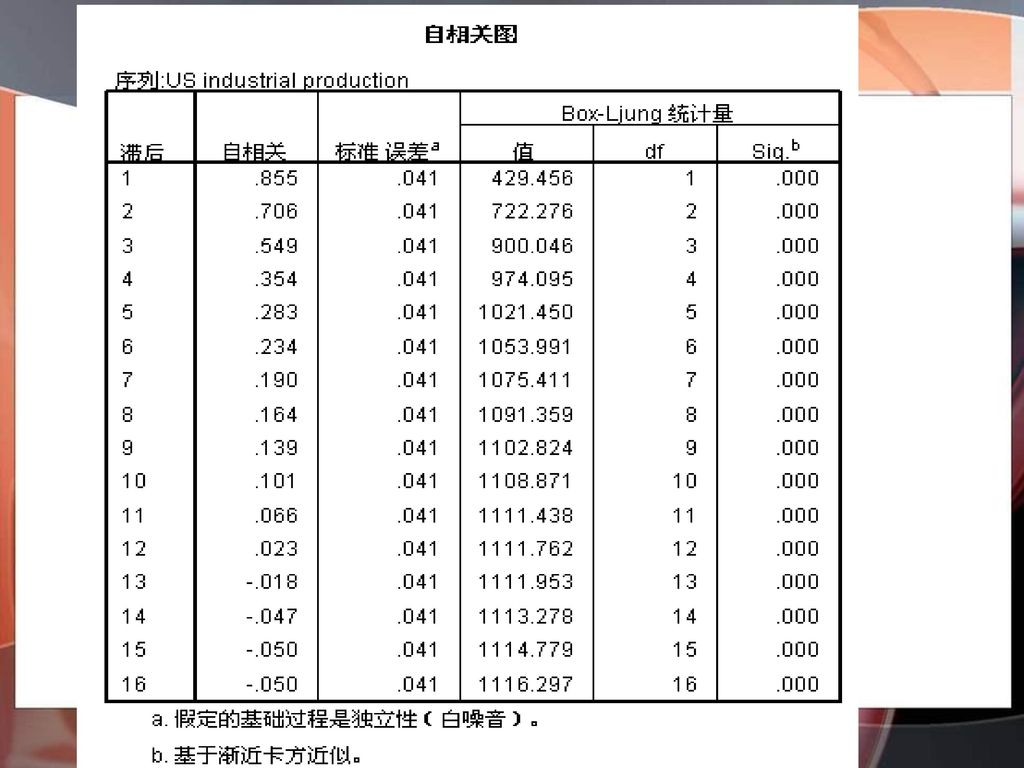
相关分析结果 在SPSS中给出了不同滞后期(Lag列)的样本自相关系数的值(Autocorrelation列),样本自相关系数的标准误差(Std Error列),以及Box-ljung Statistic的值、自由度(d f列)和相伴概率(Sig)。 通过标准误差值以及Box-ljung Statistic的相伴概率都可以说该时间序列不是白噪声,是具有自相关性的时间序列,可以建立ARIMA等模型。Box-ljung Statistic的相伴概率是在近似认为Box-ljung Statistic服从卡方分布得到。

19
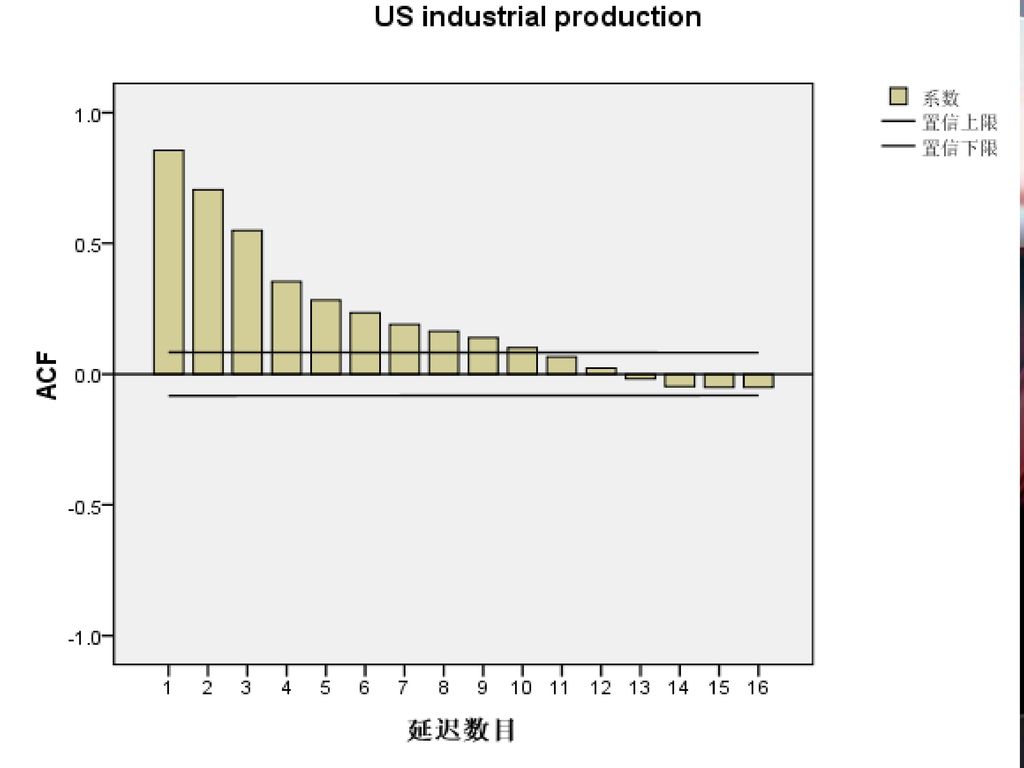
(2)样本自相关系数的图形 在SPSS中画出了样本自相关系数图。图中的横轴为滞后期(Lag Number),纵轴为样本自相关系数(ACF)。图中用条形形状来表示样本自相关系数,并画出了95%的置信上下限的线条。从下图可以看出该时间序列的自相关系数呈负指数收敛,其衰减速度较快。
样本自相关系数的图形 在SPSS中画出了样本自相关系数图。图中的横轴为滞后期(Lag Number),纵轴为样本自相关系数(ACF)。图中用条形形状来表示样本自相关系数,并画出了95%的置信上下限的线条。从下图可以看出该时间序列的自相关系数呈负指数收敛,其衰减速度较快。")
21
(3)样本偏相关系数的值 在SPSS中给出了不同滞后阶(Lag列)的样本偏相关系数的值(Partial Autocorrelations 列),样本偏相关系数的标准误差(Std Error列)。从右表中,样本偏相关系数的数据表可以看出该时间序列不是白噪声。
样本偏相关系数的值 在SPSS中给出了不同滞后阶(Lag列)的样本偏相关系数的值(Partial Autocorrelations 列),样本偏相关系数的标准误差(Std Error列)。从右表中,样本偏相关系数的数据表可以看出该时间序列不是白噪声。")
22
(4)样本偏相关系数的图形 图中的横轴为滞后期(Lag Number),纵轴为样本偏相关系数(PACF)。图中用条形形状来表示样本偏相关系数,并画出了95%的置信上下限的线条。从下图可以看出该时间序列的偏相关系数在一阶滞后期、3阶滞后期比较大,说明该时间序列不是平稳时间序列。
样本偏相关系数的图形 图中的横轴为滞后期(Lag Number),纵轴为样本偏相关系数(PACF)。图中用条形形状来表示样本偏相关系数,并画出了95%的置信上下限的线条。从下图可以看出该时间序列的偏相关系数在一阶滞后期、3阶滞后期比较大,说明该时间序列不是平稳时间序列。")
23
休息一下!

24
时间序列分析认为长期趋势变动、季节性变动、周期变动是依一定的规则而变化的,不规则变动因素在综合中可以消除。基于这种认识,形成了确定性时间序列分析。
通过确定性时间序列分析,一方面能够使序列的长期趋势变动特征、季节效应、周期变动体现得更加明显;另一方面能确立模型,从而成功捕捉数据的随“时间”变化的、“动态”的、“整体”的统计规律。因此,对时间序列进行确定分析,从而建立模型是非常必要的。

25
第二节 指数平滑模型 指数平滑模型可以对不规则的时间序列数据加以平滑,从而获得其变化规律和趋势,以此对未来的经济数据进行推断和预测。
指数平滑模型的思想是对过去值和当前值进行加权平均、以及对当前的权数进行调整以前抵消统计数值的摇摆影响,得到平滑的时间序列。 指数平滑法不舍弃过去的数据,但是对过去的数据给予逐渐减弱的影响程度(权重)。
。")
26
(1)指数平滑法 指数平滑法有助于预测存在趋势和(或)季节的序列。指数平滑法分为两步来建模,第一步确定模型类型,确定模型是否需要包含趋势、季节性,创建最适当的指数平滑模型,第二步选择最适合选定模型的参数。 指数平滑模法一般分为无季节性模型、季节性模型。无季节性模型包括简单指数平滑法、布朗单参数线性指数平滑法等,季节性模型包括温特线性和季节性指数平滑法。 指数平滑法,又称指数加权平均法,实际是加权的移动平均法,它是选取各时期权重数值为递减指数数列的均值方法。

27
休息一下!

28
ARIMA模型 ARIMA模型是时间序列分析中最常用的模型之一,ARIMA模型提供了一套有效的预测技术,在时间序列预测中具有广泛的应用。

29
时间序列的随机分析通常利用Box-Jenkins建模方法。利用Box-Jenkins方法建模的步骤为:
(1)计算观测序列的样本相关系数和样本偏相关系数。 (2)模式识别:检验序列是否为平稳非白噪声序列。如果序列是白噪声序列,建模结束;如果序列为非平稳序列,采用非平稳时间序列的建模方法,建立ARIMA模型或SARIMA模型;如果序列为平稳序列,建立ARIMA模型。 (3)初步定阶和参数估计:模型识别后,框定所属模型的最高阶数;然后在已识别的类型中,从低阶到高阶对模型进行拟合及检验。 (4)拟合优度检验:利用定阶方法对不同的模型进行比较,以确定最适宜的模型。 (5)适应性检验:对选出的模型进行适应性检验和参数检验,进一步从选出的模型出发确定最适宜的模型。 (6)预测:利用所建立的模型,进行预测。
计算观测序列的样本相关系数和样本偏相关系数。 (2)模式识别:检验序列是否为平稳非白噪声序列。如果序列是白噪声序列,建模结束;如果序列为非平稳序列,采用非平稳时间序列的建模方法,建立ARIMA模型或SARIMA模型;如果序列为平稳序列,建立ARIMA模型。 (3)初步定阶和参数估计:模型识别后,框定所属模型的最高阶数;然后在已识别的类型中,从低阶到高阶对模型进行拟合及检验。 (4)拟合优度检验:利用定阶方法对不同的模型进行比较,以确定最适宜的模型。 (5)适应性检验:对选出的模型进行适应性检验和参数检验,进一步从选出的模型出发确定最适宜的模型。 (6)预测:利用所建立的模型,进行预测。")
30
(4)模型的拟合图 在获得了参数估计值和模型结构后,代入初值,便可以拟合数据,从而绘制图像。拟合数据以前缀为Predicted的变量Predicted_VAR000001_ Model_1出现在SPSS的当前数据编辑窗口中。
模型的拟合图 在获得了参数估计值和模型结构后,代入初值,便可以拟合数据,从而绘制图像。拟合数据以前缀为Predicted的变量Predicted_VAR000001_ Model_1出现在SPSS的当前数据编辑窗口中。")
31
实例进阶分析 1. 进阶分析 上面所建立的ARIMA(1,1,1)(1,1,1)模型并不是最佳的模型,所以,需要重新建模,可以利用专家建模器来完成。 2. 实例操作
(1,1,1)模型并不是最佳的模型,所以,需要重新建模,可以利用专家建模器来完成。 2. 实例操作")
32
Step01:打开【Seasonal Decomposition(周期性分解)】对话框
选择菜单栏中的【Analyze(分析)】→【Forecasting(预测)】→【Create Models(创建模型)】命令,弹出【Create Models(创建模型)】对话框。将该对话框左侧的【 VAR00001】移入【Dependent Variables(因变量】列表框。在【Method(模型)】下拉列表框中选择【Expert Model】选项。
】→【Forecasting(预测)】→【Create Models(创建模型)】命令,弹出【Create Models(创建模型)】对话框。将该对话框左侧的【 VAR00001】移入【Dependent Variables(因变量】列表框。在【Method(模型)】下拉列表框中选择【Expert Model】选项。")
33
Step03:统计量的选择 单击【Statistics(统计量)】选项卡,选择展示模型拟合度量、Box-ljung 统计量、被模型过滤掉的样本数据的个数的选项,选择显示模型参数的估计值,选择好以后,单击【Output Filter(输出过滤)】选项卡.
】选项卡,选择展示模型拟合度量、Box-ljung 统计量、被模型过滤掉的样本数据的个数的选项,选择显示模型参数的估计值,选择好以后,单击【Output Filter(输出过滤)】选项卡.")
34
Step04:在【Output Filter(输出过滤)】选项卡中选择【Filter models based on goodness fit】,输出拟合优度最好的那一个模型,选择拟合优度准则为标准BIC准则。选择好以后,单击 【Save(保存)】选项卡。
】选项卡中选择【Filter models based on goodness fit】,输出拟合优度最好的那一个模型,选择拟合优度准则为标准BIC准则。选择好以后,单击 【Save(保存)】选项卡。")
35
Step05:保持变量的选择 在 【Save(保存)】选项卡中选择保存预测值,保存残差的值。
】选项卡中选择保存预测值,保存残差的值。")
36
Step06:完成操作 单击【OK(确认)】,将进行ARIMA模型建模,完成操作。此时,输出结果,同时在当前数据编辑窗口中自动生成带前缀Predicted的预测值和带前缀NResidual的残差的值。
】,将进行ARIMA模型建模,完成操作。此时,输出结果,同时在当前数据编辑窗口中自动生成带前缀Predicted的预测值和带前缀NResidual的残差的值。")
37
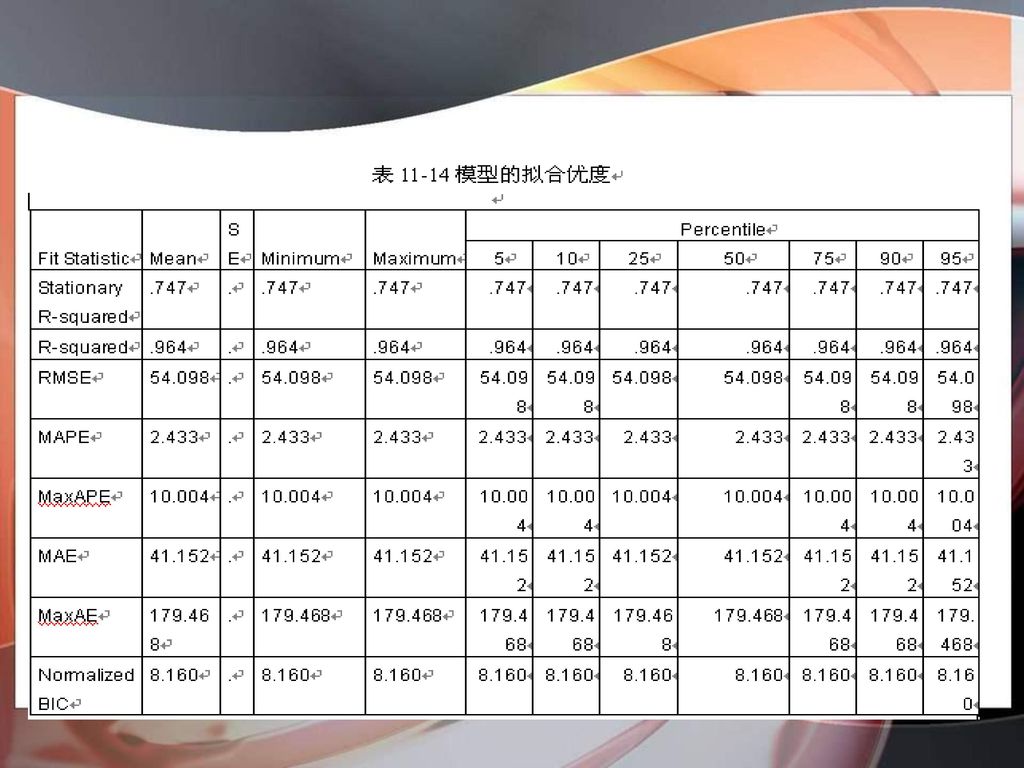
3 实例结果及分析 (2)模型拟合优度 对VAR00001建立ARIMA(1,1,0)(0,1,1)模型的拟合优度,包括了调整R-Square,标准化的BIC等所有拟合优度的值。
模型拟合优度 对VAR00001建立ARIMA(1,1,0)(0,1,1)模型的拟合优度,包括了调整R-Square,标准化的BIC等所有拟合优度的值。")
39
(3)模型的统计量的结果 由于在【Statistics(统计量)】对话框中,选择了展示模型拟合度量、ljung- Box统计量、被模型过滤掉的样本数据的个数的选项,所以,在输出结果中出现了调整R-Square,标准化的BIC的值,ljung- Box统计量的值。 从表11-15中可以看出标准BIC值为8.160,比 ARIMA(1,1,1)(1,1,1)模型的标准BIC值小一些。
(1,1,1)模型的标准BIC值小一些。")
40
由于在【Statistics(统计量)】对话框中,选择显示模型参数的估计值,所以,在输出结果中出现模型的参数估计的结果。
从表10-12可以看出,对原始数据建立的Winters' 加法模型,Alpha 的参数估计值是0.091,该模型是最优的模型,对数据的分析比较的恰当。

41
(4)模型的拟合图
模型的拟合图")
42
休息一下!

43
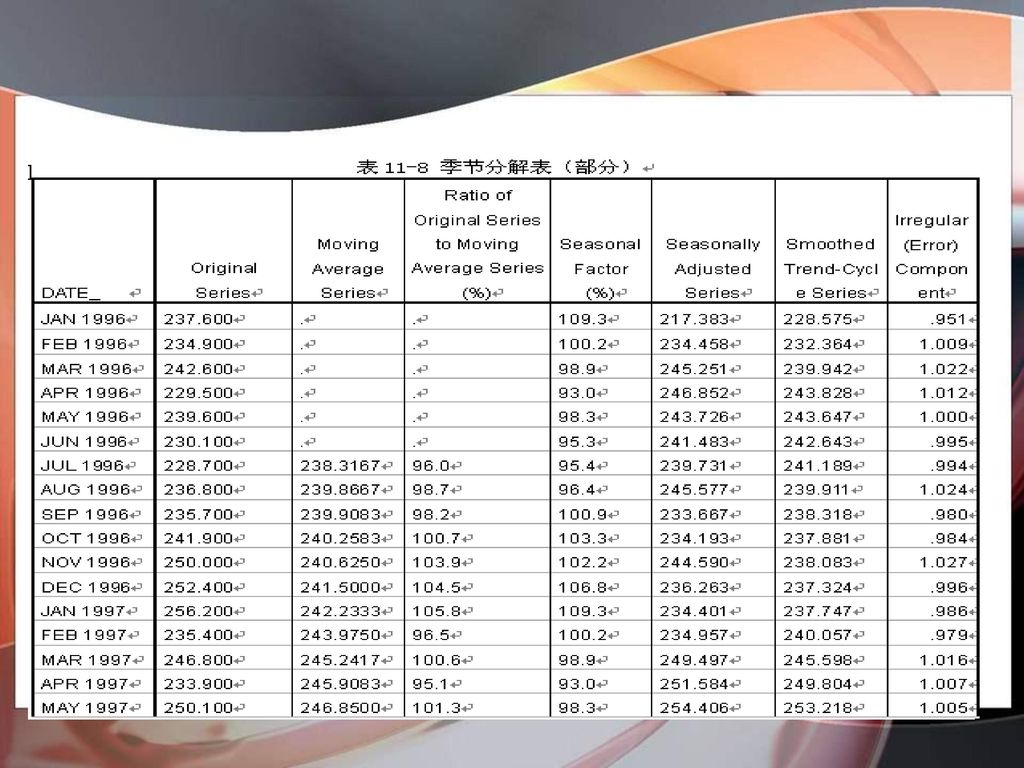
季节分解模型 季节变动趋势是时间序列的四种主要变动趋势之一,所谓季节性变动是指由于季节因素导致的时间序列的有规则变动。引起季节变动的除自然原因外,还有人为原因,如节假日、风俗习惯等。季节分解的主要方法包括按月(季)平均法和移动平均趋势剔除法。
平均法和移动平均趋势剔除法。")
44
(2)季节分解法 季节分解的一般步骤如下: 第一步,确定季节分解的模型; 第二步,计算每一周期点(每季度,每月等等)的季节指数(乘法模型)或季节变差(加法模型); 第三步,用时间序列的每一个观测值除以适当的季节指数(或减去季节变差),消除季节影响; 第三步,对消除了季节影响的时间序列进行适当的趋势性分析; 第四步,剔除趋势项,计算周期变动; 第五步,剔除周期变动,得到不规则变动因素; 第六步,用预测值乘以季节指数(或加上季节变差),乘以周期变动,计算出最终的带季节影响的预测值。
,乘以周期变动,计算出最终的带季节影响的预测值。")
46
2017/3/9







;>")





”项,在“请选择文档中的位置(C):”中选择需要链接的幻灯片,单击“确定”按钮。>")








 2008 作者 贾俊平 统计学.>")