Download presentation
1
第十一章 非参数检验 (nonparametric test)
")
2
参数检验 parametric test 如 t 检验: F 检验: 这时,对总体参数m、p的假设检验称为参数检验。
(1)总体分布类型已知,如率服从二项分布、样本均数服从正态分布; (2)由样本统计量推断未知总体参数。 这时,对总体参数m、p的假设检验称为参数检验。 如 t 检验: F 检验:
总体分布类型已知,如率服从二项分布、样本均数服从正态分布; (2)由样本统计量推断未知总体参数。 这时,对总体参数m、p的假设检验称为参数检验。 如 t 检验: F 检验:")
3
非参数检验(nonparametric test)对数据的总体分布类型不作严格假定,又称任意分布检验(distribution-free test),
它直接对总体分布的位置作假设检验。

4
参数检验 非参数检验 (nonparametric test) (parametric test) 已知总体分布类型,对未知参数进行统计推断
对总体的分布类型不作严格要求 不受分布类型的影响,比较的是总体分布位置 依赖于特定分布类型,比较的是参数 优点:方法简便、易学易用,易于推广使用、应用范围广;可用于参数检验难以处理的资料(如等级资料,或含数值“>50mg”等 ) 缺点:方法比较粗糙,对于符合参数检验条件者,采用非参数检验会损失部分信息,其检验效能较低;样本含量较大时,两者结论常相同
 缺点:方法比较粗糙,对于符合参数检验条件者,采用非参数检验会损失部分信息,其检验效能较低;样本含量较大时,两者结论常相同.")
5
应用非参数检验的情况 1.不满足正态和方差齐性条件的小样本资料; 2.总体分布类型不明的小样本资料;
3.一端或二端是不确定数值(如<0.002、>65等)的资料(必选); 4.单向有序列联表资料; 5. 各种资料的初步分析。
的资料(必选); 4.单向有序列联表资料; 5. 各种资料的初步分析。")
6
本章介绍的非参数统计方法 均基于秩次 秩次(rank)——将数值变量值从小到大,或等级变量值从弱到强所排列的序号。
例 只大鼠存活天数: 存活天数4,10,7,50,3,15,2,9,13,>60,>60 秩次 例 名 肺炎病人的治疗结果: 危险程度 治愈 治愈 死亡 无效 治愈 有效 治愈 秩次 平均秩次 秩次相同(tie)取平均秩次!!
取平均秩次!!")
7
第二节 两个独立样本检验 Wilcoxon秩和检验 Wilcoxon rank sum test
第二节 两个独立样本检验 Wilcoxon秩和检验 Wilcoxon rank sum test 1.区间(计量)数据的两样本比较 2.有序(等级)数据的两样本比较
数据的两样本比较 2.有序(等级)数据的两样本比较.")
8
1.区间(计量)数据的两样本比较 符合参数条件时,采用两样本均数的t检验
数据的两样本比较 符合参数条件时,采用两样本均数的t检验")
9
例11.1 表 不同作业的两组工人的血铅值 例数较小者为n1、T1

10
检验步骤 H0:两组总体分布位置相同; H1 :分布位置不相同;α=0.05 求检验统计量T 值 (同一组可直接写秩号)
")
11
确定P值,作出推断下结论 1. 查表法 (样本含量较小,根据T查P值) 本书为附表11 2. 较大作正态近似性检验
 本书为附表11 2. 较大作正态近似性检验")
12
data a; input y g; cards; 5 1 6 1 7 1 9 1 12 1 13 1 15 1 18 1 21 1 17 2 18 2 20 2 25 2 34 2 43 2 2 ; proc npar1way wilcoxon; class g; var y; run; SAS 程序

13
SAS 输出结果 The NPAR1WAY Procedure Wilcoxon Scores (Rank Sums) for Variable y Classified by Variable g Sum of Expected Std Dev Mean g N Scores Under H Under H0 Score Average scores were used for ties. Wilcoxon Two-Sample Test Statistic Normal Approximation Z =2.9313 One-Sided Pr > Z Two-Sided Pr > |Z| t Approximation One-Sided Pr > Z Two-Sided Pr > |Z| Z includes a continuity correction of 0.5. Kruskal-Wallis Test Chi-Square DF Pr > Chi-Square

14
2.有序(等级)数据的两样本比较 常错误采用 卡方检验 名义数据的两样本比较,采用率或构成比的卡方 检验
数据的两样本比较 常错误采用 卡方检验 名义数据的两样本比较,采用率或构成比的卡方 检验")
15
表 吸烟与不吸烟工人的HbCO(%)含量的比较
含量的比较")
16
①先确定各等级的合计人数、秩范围和平均秩,见表8-6的(4)栏、(5)栏和(6)栏,再计算两样本各等级的秩和,见(7)栏和(8)栏;
②本例T=1917;

17
③计算Z值

18
data a; input y g FREQ; cards; 1 1 1 2 1 8 3 1 16 4 1 10 5 1 4 1 2 2 2 2 23 3 2 11 4 2 4 5 2 0 ; proc npar1way wilcoxon; class g; FREQ FREQ; var y; run; SAS 程序

19
SAS 输出结果 The NPAR1WAY Procedure Wilcoxon Scores (Rank Sums) for Variable y Classified by Variable g Sum of Expected Std Dev Mean g N Scores Under H Under H0 Score Average scores were used for ties. Wilcoxon Two-Sample Test Statistic Normal Approximation Z = One-Sided Pr > Z Two-Sided Pr > |Z| t Approximation One-Sided Pr > Z Two-Sided Pr > |Z| Z includes a continuity correction of 0.5. Kruskal-Wallis Test Chi-Square DF Pr > Chi-Square

20
第三节 K个独立样本检验 1.区间(计量)数据的多个样本比较 2.有序(等级)数据的多个样本比较 完全随机设计多个样本比较的
Kruskal-Wallis H检验 1.区间(计量)数据的多个样本比较 2.有序(等级)数据的多个样本比较
数据的多个样本比较 2.有序(等级)数据的多个样本比较.")
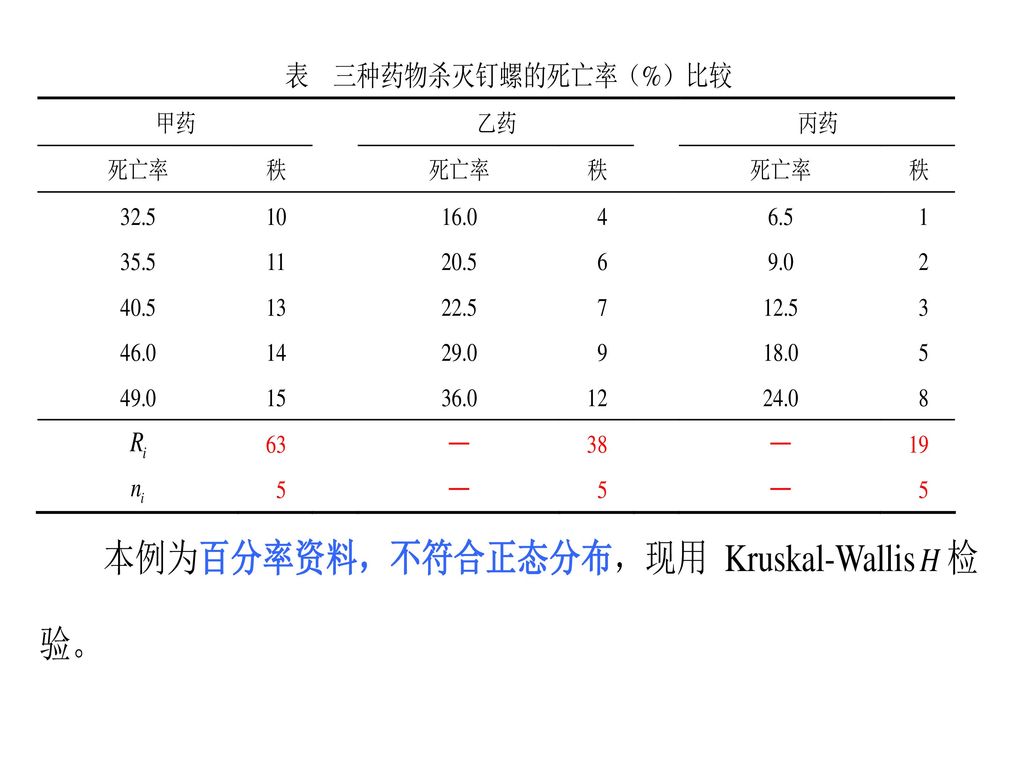
21
1.区间(计量)数据的多个样本比较 Kruskal-Wallis H检验
H0 :多个总体分布位置相同; H1 :多个总体分布位置不全相同。 如果满足参数条件,这类资料一般作完全随机设计ANOVA

25
data a; input y g; cards; 32.5 1 35.5 1 40.5 1 20.5 2 22.5 2 12.5 3 ; proc npar1way wilcoxon; class g; var y; run; SAS 程序

26
SAS 输出结果 The NPAR1WAY Procedure Wilcoxon Scores (Rank Sums) for Variable y Classified by Variable g Sum of Expected Std Dev Mean g N Scores Under H Under H Score Kruskal-Wallis Test Chi-Square DF Pr > Chi-Square

27
2.有序(等级)数据的多个样本比较 这种数据常被错误采用卡方检验
数据的多个样本比较 这种数据常被错误采用卡方检验")
30
data a; input y g FREQ; cards; 1 1 0 2 1 2 3 1 9 4 1 6 1 2 3 2 2 5 3 2 5 4 2 2 1 3 5 2 3 7 3 3 3 4 3 2 1 4 3 2 4 5 3 4 3 ; proc npar1way wilcoxon; class g; FREQ FREQ; var y; run; SAS 程序

31
SAS 输出结果 The NPAR1WAY Procedure Wilcoxon Scores (Rank Sums) for Variable y Classified by Variable g Sum of Expected Std Dev Mean g N Scores Under H Under H Score Average scores were used for ties. Kruskal-Wallis Test Chi-Square DF Pr > Chi-Square

32
多个独立样本作两两比较的 Nemenyi法检验

33
第四节 两个相关样本检验 配对样本比较的Wilcoxon符号秩检验 (Wilcoxon signed-rank test)
第四节 两个相关样本检验 配对样本比较的Wilcoxon符号秩检验 (Wilcoxon signed-rank test) 1.配对样本差值的中位数与0的比较 2.单个样本中位数和总体中位数比较
 1.配对样本差值的中位数与0的比较 2.单个样本中位数和总体中位数比较.")
34
1.配对样本差值的中位数与0的比较 表 12份血清两法测血清谷-丙转氨酶(nmol· S-1/L)的比较
的比较")
35
检验步骤 3. 确定P值,作出推断结论 1. 建立检验假设,确定检验水平 2. 求检验统计量T值 ①省略所有差值为0的对子数
②按差值的绝对值从小到大编秩,相同秩(ties)】则取平均秩 ③任取正秩和或负秩和为T,本例取T=11.5。 3. 确定P值,作出推断结论
】则取平均秩. ③任取正秩和或负秩和为T,本例取T=11.5。 3. 确定P值,作出推断结论.")
36
T 在范围之内,P> (T范围越小,P越大)
(1)当n≤50时,查T界值表(附表10) 判断原则:T 在范围之外,P< ; T 在范围之内,P> (T范围越小,P越大) n=11, =0.10 : =0.05 :10-56 T=11.5 (2)若当n>50,超出附表9范围,可用正态近似法作z检验。
当n≤50时,查T界值表(附表10) 判断原则:T 在范围之外,P< ; T 在范围之内,P> (T范围越小,P越大) n=11, =0.10 :13-53 =0.05 : T=11.5. (2)若当n>50,超出附表9范围,可用正态近似法作z检验。")
37
SAS 程序 data d1; input id x1 x2 ; d=x1-x2; cards; ; proc univariate; var d; run;

38
Test -Statistic- -----p Value------
SAS 输出结果 Univariate Procedure Variable=D1 Tests for Location: Mu0=0 Test Statistic p Value------ Student's t t Pr > |t| Sign M Pr >= |M| Signed Rank S Pr >= |S|

39
2.单个样本中位数和总体中位数比较

40
SAS 程序 data d1; input x ; d=x-45.3; cards; 44.21 45.30 46.39 49.47 51.05 53.16 53.26 57.37 63.16 67.37 71.05 87.37 ; proc univariate; var d; run;

41
Signed Rank S 31.5 Pr >= |S| 0.0029
SAS 输出结果 Univariate Procedure Variable=D1 Tests for Location: Mu0=0 Test -Statistic p Value------ Student's t t Pr > |t| Sign M Pr >= |M| Signed Rank S Pr >= |S|

42
第五节 K个相关样本检验 随机区组设计多个样本比较的 Friedman M检验

43
在每个配伍组内编秩次

45
SAS 程序 data a; input block group y @@; cards; 1 1 8.4 1 2 9.6
; Proc freq; tables block*group*y / noprint cmh2 scores=rank; run; SAS 程序

46
SAS 输出结果 The FREQ Procedure Summary Statistics for group by y
Controlling for block Cochran-Mantel-Haenszel Statistics (Based on Rank Scores) Statistic Alternative Hypothesis DF Value Prob 1 Nonzero Correlation 2 Row Mean Scores Differ Total Sample Size = 32
 Statistic Alternative Hypothesis DF Value Prob. 1 Nonzero Correlation Row Mean Scores Differ Total Sample Size = 32.")
47
两两比较的q检验 .

48
表11.12 不同时间产妇羊水中前列腺素含量(ng)
编号 用药前 用药后1小时 产程开始 分娩时 (1) 0.040(2) (3) 22.2(4) (1) (2) (3) 21.1(4) (1) (2) (3) 17.7(4) (1) (2) (3) (4) (2) (1) (3) 14.58(4) (1) (2) (3) 13.93(4) mi (mi - E) (mi - E)
 0.040(2) 4.90(3) 22.2(4) (1) 0.074(2) 4.80(3) 21.1(4) (1) 0.093(2) 1.70(3) 17.7(4) (1) 0.099(2) 1.04(3) 3.93(4) (2) 0.074(1) 2.12(3) 14.58(4) (1) 0.300(2) 7.04(3) 13.93(4) mi (mi - E) (mi - E)")
49
1. 建立检验假设,确定检验水准 2. 计算统计量M H0:不同时间羊水中前列腺素含量相同。
α= 0.05 2. 计算统计量M (1)在各区组(b)内编秩,相同数据取平均秩次 (2)求各处理组(k)秩和mi (3) 求平均秩E: b:区组数,k:处理数 本例b=6,k=4,则 (4) 计算M
在各区组(b)内编秩,相同数据取平均秩次. (2)求各处理组(k)秩和mi. (3) 求平均秩E: b:区组数,k:处理数. 本例b=6,k=4,则. (4) 计算M.")
50
3. 确定概率,判断结果 查附表12,当b=6,k=4时,M0.05=76。
因M=170>M0.05,P<0.05,故可认为不同时间羊水中前列腺素含量差异有统计学意义。 20.05(3)=7.81, 20.01(3)=11.34 2=17> 20.01(3) , P<0.01
=7.81, 20.01(3)= 2=17> 20.01(3) , P<0.01.")
51
SAS 程序 data a; input block group y @@; cards;
; Proc freq; tables block*group*y / noprint cmh2 scores=rank; run;

52
SAS 输出结果 The FREQ Procedure Summary Statistics for group by y
Controlling for block Cochran-Mantel-Haenszel Statistics (Based on Rank Scores) Statistic Alternative Hypothesis DF Value Prob Nonzero Correlation <.0001 Row Mean Scores Differ Total Sample Size = 24
 Statistic Alternative Hypothesis DF Value Prob. 1 Nonzero Correlation < Row Mean Scores Differ Total Sample Size = 24.")
53
第六节 等级相关 应用: 两个样本的相关分析 当两个变量不服从正态分布时,可以采用等级相关分析。

54
回忆: Pearson相关系数的估计和检验 1)估计相关系数ρ,估计公式: y x 80 307 75 259 90 341 70 237
其中,{xi}和{yi}是服从正态分布的两个随机变量, 分别是这两个随机变量的均值。

55
2、 计算估计值r 的标准误 3、 ρ的假设检验 H0: ρ=0 vs H1: ρ≠0 4、统计推断结论:查ν=n-2 的 t-分布表。

56
Spearman 相关系数的估计和检验 ρ的估计公式: 与计算Pearson相关系数的区别:采用秩次代替原变量
当两个随机变量{xi}和{yi}不服从正态分布或分布未知时,用下面公式估计相关系数,这就是Spearman相关系数。 其中{si}和{ti}分别是{xi}和{yi}的秩次, 分别是{si}和{ti}的均值。 与计算Pearson相关系数的区别:采用秩次代替原变量

57
Spearman相关系数ρ的另一计算公式:
其中,d= s-t 相同秩次较多时 TX(或TY)=(t3-t)/12,t为X(或Y)中相同秩次的个数。
=(t3-t)/12,t为X(或Y)中相同秩次的个数。")
58
【例11. 6】 某地作肝癌病因研究,调查了10个不同地区肝癌死亡率(1/10万)与某种食物中黄曲霉素相对含量,见表15
【例11.6】 某地作肝癌病因研究,调查了10个不同地区肝癌死亡率(1/10万)与某种食物中黄曲霉素相对含量,见表15.16第(2)、(4)栏。试作等级相关分析 。
与某种食物中黄曲霉素相对含量,见表15.16第(2)、(4)栏。试作等级相关分析 。")
60
H1:不同地区肝癌死亡率与黄曲霉素相对含量相关。
1. 建立检验假设,确定检验水准 H0: 不同地区肝癌死亡率与黄曲霉素相对含量不相关。 H1:不同地区肝癌死亡率与黄曲霉素相对含量相关。 α= 0.05 2. 计算统计量rs (1)编等级 (2)求等级差d及d2 (3) 计算rs rs=1- 3. 确定概率,判断结果 查表得rs0.05(10)=0.648, rs0.01(10)=0.794 P<0.05, 拒绝H0,可认为黄曲霉素与肝癌死亡率间 存在正相关。
编等级 (2)求等级差d及d2. (3) 计算rs. rs=1- 3. 确定概率,判断结果. 查表得rs0.05(10)=0.648, rs0.01(10)= P<0.05, 拒绝H0,可认为黄曲霉素与肝癌死亡率间. 存在正相关。")
61
data d5; input x y ; cards;
; proc corr nosimple spearman; var x y; run; SAS 程序

62
SAS 输出结果 Correlation Analysis 2 'VAR' Variables: X Y
Spearman Correlation Coefficients / Prob > |r| under Ho: Rho=0 / N = 10 X Y X Y SAS 输出结果

63
1 3 2 2 3 1 4 7 5 4 6 9 7 6 8 5 9 10 10 8 data d5; input s t ; cards;
1 3 2 2 3 1 4 7 5 4 6 9 7 6 8 5 9 10 10 8 ; proc corr nosimple pearson; var s t; run; SAS 程序

64
总之: ① 分别将x与y从小到大编秩次,若遇相同值取平均秩次
Correlation Analysis 2 'VAR' Variables: X Y Pearson Correlation Coefficients / Prob > |r| under Ho: Rho=0 / N = 10 X Y X Y SAS 输出结果 总之: ① 分别将x与y从小到大编秩次,若遇相同值取平均秩次 ② 然后按前面Pearson相关系数的计算方法求解即得Spearman等级相关系数。

65
SUMMARY Wilcoxon符号秩检验:配对设计两样本比较 Wilcoxon秩和检验:完全随机设计两样本比较
Kruskal-Wallis秩和检验:完全随机设计设计多样本比较 (Nemenyi秩和检验:完全随机设计多样本两两比较) Friedman秩和检验:随机区组设计资料的多样本比较 Spearman 相关系数:两变量不满足直线相关分析的条件
 Friedman秩和检验:随机区组设计资料的多样本比较. Spearman 相关系数:两变量不满足直线相关分析的条件.")
66
作业:实习册—P27:2,3,4









 不依赖总体分布类型, 也不对总体参数进行统计推 断的假设检验, 称为非参数检验 配对资料比较时,H 0 为差值总体中位数 M d = 0 H 0 成立时, 配对数据的差值服从以 0 为中心的对称 分布. 把差值按绝对值从小到大用.>")
>")

>")






 2008 作者 贾俊平 统计学.>")



 雙變項統計分析(一)>")
>")


