Download presentation
Presentation is loading. Please wait.

1
假設檢定

2
問題 假設檢定時要用甚麼distribution來看? Rejection region 一定在右邊嗎? 要如何 判別?
Rejection region & p-value的關係

3
假設檢定時要用甚麼distribution來看?

4
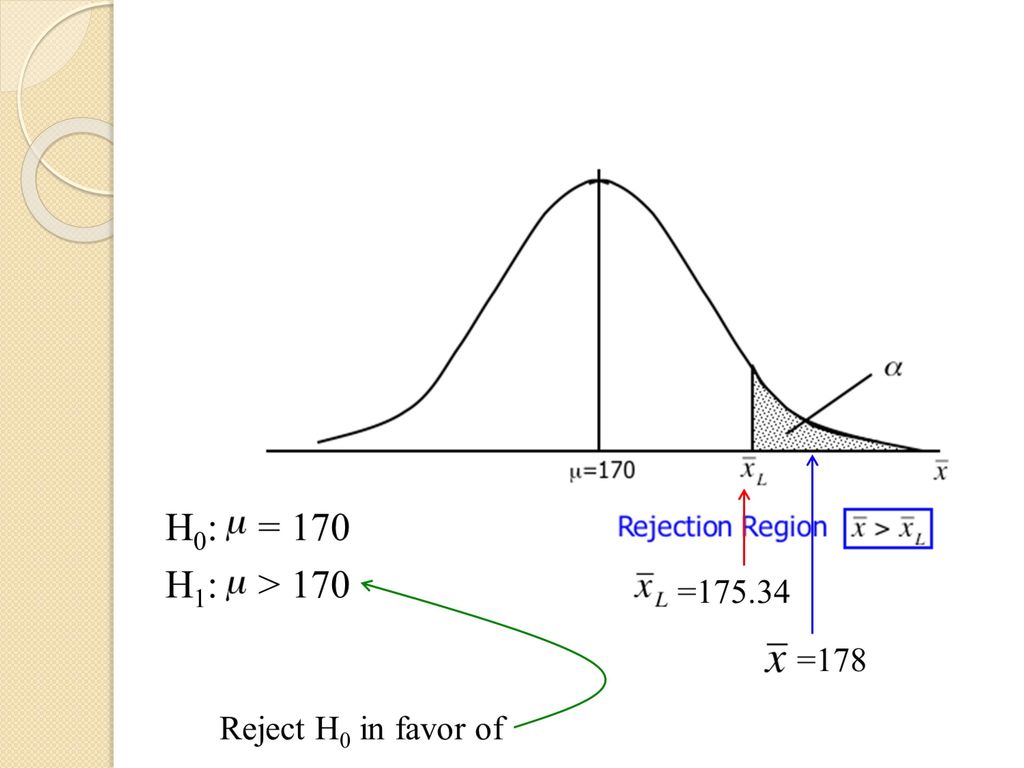
Example 11.1 The manager of a department store is thinking about establishing a new billing system for the store's credit customers. She determines that the new system will be cost-effective only if the mean monthly account is more than $170. A random sample of 400 monthly accounts is drawn, for which the sample mean is $178. The manager knows that the accounts are approximately normally distributed with a standard deviation of $65. Can the manager conclude from this that the new system will be cost-effective?

5
In Chapter 9, we know We can generalize the mean and variance of the sampling of two dice: …to n-dice: The standard deviation of the sampling distribution is called the standard error:

6
Based on CLT The sampling distribution of the mean of a random sample drawn from any population is approximately normal for a sufficiently large sample size. The larger the sample size, the more closely the sampling distribution of X will resemble a normal distribution.

7
Hence, If the population mean = 170, and we keep getting a sample (size of 400) from this population, the sampling distribution follows normal distribution approximately and the mean = 170 and the standard deviation = 65/400^0.5 HT(假設檢定) – 先假設(母體資訊)再檢定(樣本資訊) Assume population mean = 170 (H0 is true) Sampling dist. follows normal with mean 170, and std 65/400^0.5 Get one sample from population Compare sample mean with sampling distribution Based on sample mean, we Reject H0 (if sample mean makes us to think the population mean is not 170) Do not reject H0 (if sample mean makes us believe population mean is 170)
 from this population, the sampling distribution follows normal distribution approximately and the mean = 170 and the standard deviation = 65/400^0.5. HT(假設檢定) – 先假設(母體資訊)再檢定(樣本資訊) Assume population mean = 170 (H0 is true) Sampling dist. follows normal with mean 170, and std 65/400^0.5. Get one sample from population. Compare sample mean with sampling distribution. Based on sample mean, we. Reject H0 (if sample mean makes us to think the population mean is not 170) Do not reject H0 (if sample mean makes us believe population mean is 170)")
8
Type I and Type II errors
Type I error If population mean is really 170, the sampling dist. Mean = 170 and std. = 65/400^0.5 Since it follows normal, it is still likely to get a sample with an extreme (too large or too small) mean Type I error happens if we really get one sample from the population with mean =170 but since the sample mean is too large or too small, we mistakenly say that the population mean is not 170 (reject H0) Type II error If population mean is not 170, but the sample mean we get is close enough to 170 Hence, we say population mean is 170 (do not reject H0)
 mean. Type I error happens if we really get one sample from the population with mean =170 but since the sample mean is too large or too small, we mistakenly say that the population mean is not 170 (reject H0) Type II error. If population mean is not 170, but the sample mean we get is close enough to 170. Hence, we say population mean is 170 (do not reject H0)")
9
Rejection region 一定在右邊嗎? 要如判別?

10
我們假設都是真的,所以才可以用相關的sampling distribution
The system will be cost effective if the mean account balance for all customers is greater than $170. We express this belief as our research hypothesis, that is: H1: µ > 170 (this is what we want to determine) Thus, our null hypothesis becomes: H0: µ = 170 (this specifies a single value for the parameter of interest) 這是我們關心的 我們假設都是真的,所以才可以用相關的sampling distribution
 Thus, our null hypothesis becomes: H0: µ = 170 (this specifies a single value for the parameter of interest) 這是我們關心的. 我們假設都是真的,所以才可以用相關的sampling distribution.")
11
Example 11.1 Rejection region
COMPUTE Example 11.1 Rejection region It seems reasonable to reject the null hypothesis in favor of the alternative if the value of the sample mean is large relative to 170, that is if > 我們關心是否sample mean > 170, 所以若抓出來的sample mean太大,要reject, 若關心的是是否sample mean < 170, rejection region就會在左邊 α = P(Type I error) = P( reject H0 given that H0 is true) α = P( > )
 = P( reject H0 given that H0 is true) α = P( > )")
13
Rejection region & p-value的關係

14
P-value是若你從這樣的一個sampling distribution下能抓到的一個樣本平均為某 一數值及以上(如果是右尾)的機率是?
Rejection region是在設定的一個 下找一 個 threshold point,使得threshold point以 外的區域面積剛好是 E.g = 0.05 , threshold point175.34 P-value是若你從這樣的一個sampling distribution下能抓到的一個樣本平均為某 一數值及以上(如果是右尾)的機率是? 隱含抓到一個樣本且平均為175.34的p-value是 0.05
的機率是 隱含抓到一個樣本且平均為175.34的p-value是")
15
P-value=0.0069

Similar presentations















.>")



