Download presentation
1
第十四章 数值变量的统计描述

2
第十四章 数值变量的统计描述 第一节 数值变量资料的频数分布表与频数分布图 第二节 集中趋势的描述 第三节 离散趋势的描述
第十四章 数值变量的统计描述 第一节 数值变量资料的频数分布表与频数分布图 第二节 集中趋势的描述 第三节 离散趋势的描述 第四节 正态分布和医学参考值范围的估计

3
常用的描述定量资料分布规律的统计方法 有两类: 统计图表:频数分布表/图 选用适当的统计指标: 集中趋势指标:均数、中位数
离散趋势指标:极差、标准差

4
一、频数分布表的编制 第一节 数值变量资料的频数分布表与频数分布图 一.频数分布表的编制
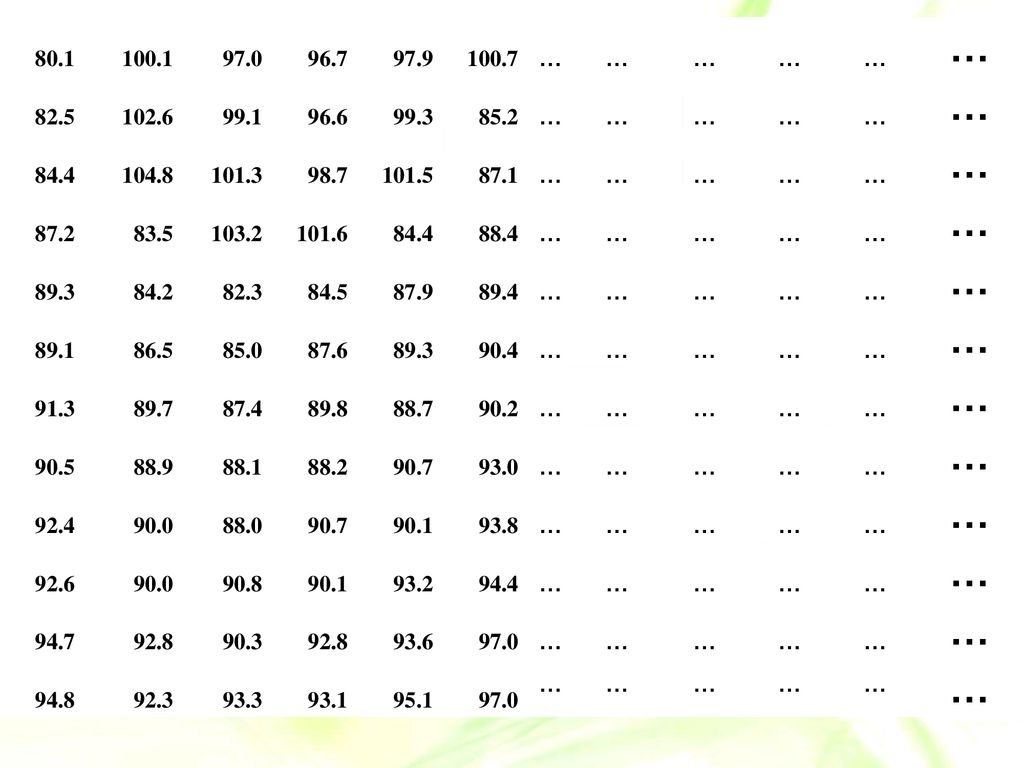
例14-1 某巿用随机测量了150名3岁女孩身高(CM)资料如下,试编制频数分布表。
资料如下,试编制频数分布表。")
5
80.1 100.1 97.0 96.7 97.9 100.7 … 82.5 102.6 99.1 96.6 99.3 85.2 84.4 104.8 101.3 98.7 101.5 87.1 87.2 83.5 103.2 101.6 88.4 89.3 84.2 82.3 84.5 87.9 89.4 89.1 86.5 85.0 87.6 90.4 91.3 89.7 87.4 89.8 88.7 90.2 90.5 88.9 88.1 88.2 90.7 93.0 92.4 90.0 88.0 90.1 93.8 92.6 90.8 93.2 94.4 94.7 92.8 90.3 93.6 94.8 92.3 93.3 93.1 95.1
6
表14-1 某市150名3岁女孩身高的频数分布 组段 f x fx fx2 80~ 1 81 6561 82~ 3 83 249 20667
表14-1 某市150名3岁女孩身高的频数分布 组段 f x fx fx2 80~ 1 81 6561 82~ 3 83 249 20667 84~ 8 85 680 57800 86~ 10 87 870 75690 88~ 19 89 1691 150499 90~ 23 91 2093 190463 92~ 26 93 2418 224874 94~ 24 95 2280 216600 96~ 17 97 1649 159953 98~ 99 990 98010 100~ 6 101 606 61206 102~ 2 103 206 21218 104~106 105 11025 合计 150 - 13918 2018/11/14 6

7
二.频数分布的特征 从频数表可以看到频数分布的两个重要的特征 集中趋势(central tendency)
身高值向中央部分(中等水平)集中,以中等水平的身高值者居多,是为集中趋势。 离散趋势(tendency of dispersion) 从中央部分到两侧(身高值从中等水平到较低或较高水平)的频数分布逐渐减少,是为离散趋势。 集中趋势和离散趋势是频数分布的两个重要侧面,从这两方面就可全面的分析所研究的事物。
集中,以中等水平的身高值者居多,是为集中趋势。 离散趋势(tendency of dispersion) 从中央部分到两侧(身高值从中等水平到较低或较高水平)的频数分布逐渐减少,是为离散趋势。 集中趋势和离散趋势是频数分布的两个重要侧面,从这两方面就可全面的分析所研究的事物。")
8
三.频数分布的类型 频数分布又可分为对称分布和偏态分布 对称分布:集中位置在正中,左右两侧频数分布大体对称
偏态分布:集中位置偏向一侧,频数分布不对称 正偏态分布:集中位置偏向年龄小的一侧 负偏态分布:集中位置偏向年龄大的一侧 不同类型的分布,应采用相应的统计分析方法。

9
( normal distribution )
正态分布 ( normal distribution ) 中间高、两边低、左右对称属于对称分布的一种 许多医学资料都属于这种分布,例如人体正常的生理生化指标 正态分布
 中间高、两边低、左右对称属于对称分布的一种. 许多医学资料都属于这种分布,例如人体正常的生理生化指标. 正态分布.")
10
正偏态分布:峰偏左,尾部向右侧延伸 如:以儿童为主的传染病发病人数的分布 右偏态 正偏态分布 负偏态分布:峰偏右,尾部向左侧延伸
(positive skewed) 负偏态分布 负偏态分布:峰偏右,尾部向左侧延伸 如:以老年人为主的慢性病发病人数的分布 左偏态 (negative skewed)
 负偏态分布. 负偏态分布:峰偏右,尾部向左侧延伸. 如:以老年人为主的慢性病发病人数的分布. 左偏态. (negative skewed)")
11
四、频数分布图 绘制频数分布直方图 坐标轴 直条 累计 直条的宽度:组距 直条的高度:每一组段的频数
横坐标:变量值即研究指标,无需从0开始,以单位尺度划分。 纵坐标:为频数f,必须从0开始(f为每一组段内的人数) 直条 直条的宽度:组距 直条的高度:每一组段的频数 累计
 直条. 直条的宽度:组距. 直条的高度:每一组段的频数. 累计.")
12
频数分布图 图14-1 某市150名3岁女孩身高的频数分布

13
第二节 集中趋势的描述 算术均数(arithmetic mean) 几何均数(geometric mean)
中位数和百分位数(median percentile) 以上统称为平均数(average)常用于描述一组变量值的集中位置,代表其平均水平或是集中位置的特征值。
 以上统称为平均数(average)常用于描述一组变量值的集中位置,代表其平均水平或是集中位置的特征值。")
14
某公司员工工资,请描述平均水平 1、1800,1900,1900,2000,2000,2000,2000,2100,2100,2200,
平均工资为2000. 2、1800,1900,1900,2000,2000,2000,2000,2100,2100,10000 平均工资为2800,合理吗?

15
请描述以下资料中变量的平均水平 1、8名某病患者血清抗体滴度为:1:2,1:4,1:8,1:16,1:32,1:64,1:128。
2、某医院收治某癌症患者6人,其生存时间(月)分别为10,8,19,6,20,≥25
分别为10,8,19,6,20,≥25.")
16
一、算术均数 又简称为均数(mean) 定义:是反映一组观察值在数量上的平均水平。
(arithmetic mean) 又简称为均数(mean) 定义:是反映一组观察值在数量上的平均水平。 总体均数用希腊字母 表示,样本均数用 表示 应用: 对称分布,特别是正态分布或近似正态分布的数值变量资料 计算方法: 直接法: 加权法:
 又简称为均数(mean) 定义:是反映一组观察值在数量上的平均水平。 总体均数用希腊字母 表示,样本均数用 表示. 应用: 对称分布,特别是正态分布或近似正态分布的数值变量资料. 计算方法: 直接法: 加权法:")
17
一、算术均数 计算方法 直接法:即将所有观察值x1,x2,x3,…,xn直接相加再除以观察值的个数,写成公式 为样本均数, n为变量值个数,
Σ表示求和

18
一、算术均数 例14.2 有10名3岁女孩身高(CM)分别为92.5,82.5,102.6,99.1,96.6,99.3,85.2,89.2,90.6,95.1,求算术均数。
分别为92.5,82.5,102.6,99.1,96.6,99.3,85.2,89.2,90.6,95.1,求算术均数。")
19
一、算术均数 计算方法 加权法(weighting method)
当资料中相同观察值的个数较多时,可将相同观察值的个数,即频数f,乘以该观察值x,以代替相同观察值逐个相加。 对于频数表资料,用各组段的频数作f,以相应的组中值(class mid-value)作x。组中值=(下限+上限)/ 2 公式 fi为各组段的频数 xi为各组段的组中值
作x。组中值=(下限+上限)/ 2. 公式. fi为各组段的频数. xi为各组段的组中值.")
20
表14-1 某市150名3岁女孩身高的频数分布 组段 f x fx fx2 80~ 1 81 6561 82~ 3 83 249 20667
表14-1 某市150名3岁女孩身高的频数分布 组段 f x fx fx2 80~ 1 81 6561 82~ 3 83 249 20667 84~ 8 85 680 57800 86~ 10 87 870 75690 88~ 19 89 1691 150499 90~ 23 91 2093 190463 92~ 26 93 2418 224874 94~ 24 95 2280 216600 96~ 17 97 1649 159953 98~ 99 990 98010 100~ 6 101 606 61206 102~ 2 103 206 21218 104~106 105 11025 合计 150 - 13918 2018/11/14 20

21
一、算术均数 组中值=(下限+上限)/ 2
/ 2")
22
一、算术均数 f1, f2,…,fk分别为各组段的频数,这里的f起到了“权数”的作用,它权衡了各组中值由于频数不同对均数的影响。即频数多,权数大,作用也大;频数少,权数小,作用也小,故称为加权法。 92.79≈93.27cm 用组中值,加权法计算出的均数是精确值吗?

23
二、几何均数 (geometric mean) 定义:有些医学资料,如抗体滴度、细菌计数等,其频数分布明显偏态,各观察值之间呈倍数变化(等比关系),此时宜用几何均数反映其平均增减倍数。 应用:等比资料或对数正态分布资料 计算方法: 直接法 加权法

24
二、几何均数 计算方法: 直接法:直接将n个观察值( x1,x2,x3,…,xn )的乘积开n次 公式 写成对数形式为 几何均数:
变量对数值 的算术均数 的反对数。

25
二、几何均数 例14-3 设有5人的血清抗体效价为1:10,1:100,1:1000,1:10000,1:100000,求平均抗体效价。
例14-3 设有5人的血清抗体效价为1:10,1:100,1:1000,1:10000,1:100000,求平均抗体效价。 本例先求抗体效价的倒数,再求几何均数 血清抗体的平均效价为1:1000

26
二、几何均数 计算方法: 加权法:当资料中相同观察值得个数f(即频数)较多时,如频数表资料 写成公式
较多时,如频数表资料 写成公式")
27
二、几何均数 注意事项 等比资料,如:抗体的平均滴度、药物的平均效价、卫生事业平均发展速度、人口的几何增长 对数正态分布:是右偏态分布
观察值不能有0,因为0不能去对数,不能与任何其他数呈倍数 关系。 观察值不能同时有正值和负值。若全是负值,计算是可以把负号去掉,得出结果后再加上负号。 同一组资料求得的几何均数小于算术均数。

28
三、中位数 (median) (一)中位数 X: 5,5, 6, 7, 20, 位次: 1 2 3 4 5 23 6 中位数(M): 6
定义:是将一组观察值从小到大按顺序排列,位次居中的观察值就是中位数。 例: X: 5,5, 6, 7, 20, 位次: 23 6 中位数(M): 6 6.5
:")
29
计算方法: 直接由原始数据计算中位数 先将观察值按大小顺序排列,再按下面公式计算: 位次上的观察值

30
请大家思考下:计算中位数和其他平均数有什么不同?
例14-5 某病患者10人的潜伏期从小到大排列为1,3,8,9,15,19,20,23,25,30,求中位数。 解:n=10 为偶数 特点:仅利用了中间的1~2个数据 请大家思考下:计算中位数和其他平均数有什么不同?

31
计算方法: 用频数表计算中位数, 按所分组段,由小到大计算累计频数和累计频率。 再按下面公式计算为:

32
下限值L 上限值U i; fm 中位数M

33
表 名食物中毒患者的潜伏期 天数 f 累计频数 累计频率% 0~ 30 16.57 12~ 63 93 51.38 24~ 47 140 77.35 36~ 20 160 88.40 48~ 12 172 95.03 60~ 8 180 99.45 72~84 1 181 100.00

34
中位数的特征 反映了位次居中的观察值的水平 优点:不受两端特大值和特小值影响 缺点:并非考虑到每个观测值 适用于各种分布类型的资料,
特别适合于:大样本明显偏态分布资料、分布不明的资料、 或者一端/两端无确切数值的资料 3.中位数和算术均数在对称分布的资料中,理论上数值是相 同的

35
小 结 常用平均数的意义及其应用场合

36
第三节 离散趋势的描述 平均水平的指标只是描述了一组数据的集中趋势指标,可以作为总体的一个代表值,那么不同组观察值之间是否存在差异?描述差异的指标有哪些呢?差异究竟有多大?如何计算?

37
例2-11 三组同龄男孩的身高值(cm) 甲组 90 95 100 105 110 乙组 96 98 100 102 104
甲组 乙组 丙组 丙 乙 甲

38
第三节 离散趋势的描述 描述计量资料数据间离散程度的指标 —变异指标。 常用的指标: 极差 四分位间距 方差 标准差 变异系数。

39
一、极差 定义:亦称为全距,即一组观察值中最大值与最小值之差 计算方法: R=XMax-XMin 意义: R值越大,表示该组数据的变异越大。
(Range) 定义:亦称为全距,即一组观察值中最大值与最小值之差 计算方法: R=XMax-XMin 意义: R值越大,表示该组数据的变异越大。 优点:计算简单,意义明了。 缺点: 数据利用不全,仅利用了两个极端值,部分信息损失,结果不稳定。
 定义:亦称为全距,即一组观察值中最大值与最小值之差. 计算方法: R=XMax-XMin. 意义: R值越大,表示该组数据的变异越大。 优点:计算简单,意义明了。 缺点: 数据利用不全,仅利用了两个极端值,部分信息损失,结果不稳定。")
40
例 三组同龄男孩的身高值(cm) R 甲组 乙组 丙组

41
二、百分位数 定义:是一种位置指标,用 PX 来表示。
将n个变量值从小到大依次排列,再把它们的位次转换为百分位。对应于X%位次的数值即为第X百分位数。 变量值: … … 位 次: … … 百分位次:0.7% % 2% … 50% … 100%

42
计算方法 频数表法 公式如下 Lx:第X百分位数所在组段的下限 ix:第X百分位数所在组段的组距 fx:第X百分位数所在组段的频数
计算方法 频数表法 公式如下 Lx:第X百分位数所在组段的下限 ix:第X百分位数所在组段的组距 fx:第X百分位数所在组段的频数 :第X百分位数所在组段上一组段累计频数

43
n×25%- 表14-4 181名食物中毒患者的潜伏期 天数 f 累计频数 累计频率% 0~ 30 16.57 12~ 63 93
表 名食物中毒患者的潜伏期 天数 f 累计频数 累计频率% 0~ 30 16.57 12~ 63 93 51.38 24~ 47 140 77.35 36~ 20 160 88.40 48~ 12 172 95.03 60~ 8 180 99.45 72~84 1 181 100.00 n×25%-

44
四分位数间距 (inter-quartile range) 四分位数( quartile ):可看作特定的百分位数,第25百分位数P25,表示全部观察值中有25%(四分之一)的观察值比它小,为下四分位数,记做QL ;同理第75百分位数P75为上四分位数,记做记做Qu ; 四分位数间距,简记为Q,第75百分位数与第25百分位数之差。 P75 P25 P50

45
计算方法:Q= Qu – QL=P75%-P25% 意义: Q值越大,表示该组数据的变异度越大。 优点:1. 四分位数间距包括了全部观察值的一半,因此也可看成是中间一半观察值的极差。 2.四分位数间距作为说明个体差异的指标,比极差稳定。 缺点:未考虑到每个观察值的变异度大。 应用:常用于表示偏态分布资料的变异。

46
例14-4 Q=QU–QL = =20.01(h)
")
47
第三节 离散趋势的描述 极差仅采用了观察值中的最大值和最小值;而四分位数间距也仅仅采用了上、下四分位数,均没有考虑每个观察值,因此这两项指标不能全面反映资料的离散程度。

48
三、方差 (variance ) 若要克服以上缺点,就必须全面考虑到每一个观察值。
可用总体中每一个观察值xi与总体均数 ,之差的总和(离均差总和),反映资料的离散程度,但 。 若计算离均差平方和 ,结果就不为0,但受到样本例数多少的影响,为了消除这一影响,就取离均差平方和的均数,该指标简称为方差(variance)。 总体方差用σ2 表示,样本方差用S2表示。
,反映资料的离散程度,但 。 若计算离均差平方和 ,结果就不为0,但受到样本例数多少的影响,为了消除这一影响,就取离均差平方和的均数,该指标简称为方差(variance)。 总体方差用σ2 表示,样本方差用S2表示。")
49
三、方差 公 式 奇怪:为什么样本方差是除以(n-1)呢?
呢?")
50
方差 (variance)是全部观察值的离均差平方和的均值。表示一组数据的平均离散情况。
特点: 方差的分子——离均差平方和,是将每一个观察值与均数作差之后平方:反映了全部观察值的离散程度;但同时也将变量值的度量衡单位平方了,变成了(m)2、(kg)2… 唉!这个指标还是不够尽善尽美,继续探索…
2、(kg)2… 唉!这个指标还是不够尽善尽美,继续探索…")
51
四、标准差 方差的单位是原度量衡单位的平方,为了用原单位,就把总体方差开平方,取其正的平方根,这就是总体标准差,用σ表示:
其单位与原变量x的单位相同。

52
自由度(degrees of freedom)。
自由度是统计学术语,其意义是随机变量能自由取值的个数。如:n个数据如不受任何条件的限制,则n个数据可取任意值,称为有n个自由度。若受到k个条件的限制,就只有(n-k)个自由度了。 如有一个n=4数据样本,受到 =5的条件限制,在自由确定 4,2,5三个数据之后,第四个数据只能是9,否则均数不是5, 推而广之,任何统计量的v=n-限制条件的个数。
个自由度了。 如有一个n=4数据样本,受到 =5的条件限制,在自由确定. 4,2,5三个数据之后,第四个数据只能是9,否则均数不是5, 推而广之,任何统计量的v=n-限制条件的个数。")
53
例2-13 试计算三组同龄男童的身高的标准差 编号 甲组 乙组 丙组 甲2 乙2 丙2 1 90 96 8100 9216 2 95 98
例 试计算三组同龄男童的身高的标准差 编号 甲组 乙组 丙组 甲2 乙2 丙2 1 90 96 8100 9216 2 95 98 99 9025 9604 9801 3 100 10000 4 105 102 101 11025 10404 10201 5 110 104 12100 10816 合计 500 50250 50040 50034

54
150名3岁女孩身高的标准差

55
用 途: 用于对称分布,特别是正态分布资料,反映一组观察值的离散程度。标准差小,数据间的离散程度小,均数的代表性好。
用 途: 用于对称分布,特别是正态分布资料,反映一组观察值的离散程度。标准差小,数据间的离散程度小,均数的代表性好。 结合均值与正态分布规律估计医学参考值范围。 用于计算标准误 用于计算变异系数

56
五、变异系数 变异系数(coefficient of variation,CV) 应 用 即标准差s与均数 之比用百分数表示,写成公式为
应 用 (1)比较度量衡单位不同的多组资料的变异度 (2)比较均数相差悬殊的多组资料的变异度。
比较度量衡单位不同的多组资料的变异度. (2)比较均数相差悬殊的多组资料的变异度。")
57
单位:极差、四分位数间距和标准差都是有单位的,其单位与观察值单位相同,而变异系数是相对数,没有单位,更便于资料间的分析比较。

58
(1)比较度量衡单位不同的多组资料的变异度 例10名小学生,试比较胸围、背肌力变异度何者为大?
均数 标准差 胸围 67.1cm 3.0cm 背肌力 37.0 kg 2.5 kg

59
例: 结论:随着年龄增加,身高的变异变小。 (2)比较均数相差悬殊的多组资料的变异度。 均数 标准差 2月女婴 56.9cm 2.3cm
5岁女孩 109.2cm 3.1cm

60
变异指标小结 1.极差较粗,适合于任何分布 2.四分位数间距,也不全面,常用于偏态分布
3.标准差与均数的单位相同,最常用,适合于正态/近似正态分布 4.变异系数主要用于单位不同或均数相差悬殊资料 5.平均指标和变异指标分别反映资料的不同特征, 常配套使用 如 正态分布:均数、标准差; 偏态分布:中位数、四分位数间距

61
第四节 正态分布和医学参考值范围的估计 (Normal distribution)
正态分布是描述连续型变量值分布的曲线,医学资料许多服从正态分布。

62
62 图 频数分布与正态分布示意图

63
一、正态分布的概念和特征 正态分布(normal distribution)又称Gauss分布(Gauss distribution ),是以均数为中心,中间频数分布多,两侧逐渐减少的对称分布, 由于频率的总和等于100%或1,故横轴上曲线下的面积等于100%或1。 f(x) x μ
 x. μ.")
64
1.正态分布曲线的数学函数表达式: X为连续随机变量,μ为X值的总体均数,σ2 为总体方差,记为X~N(μ,σ2)
当x确定后,就可由此式求得其密度函数f(x),即纵坐标的高度了,嘿嘿
,即纵坐标的高度了,嘿嘿.")
65
2.正态分布的特征 (1)正态曲线(normal curve)在横轴上方,且均数所在处最高; (2)正态分布以均数μ 为中心,左右对称;
(3)正态分布有两个参数,即均数与标准差(与) 总体均数μ是位置参数:描述正态分布的集中趋势位置。 总体标准差σ是变异度参数:描述正态分布离散趋势,标准差越小,分布越集中,曲线形状越“瘦高”;反之越“矮胖”。 (4)正态分布的面积分布有一定的规律性,总面积=1;
正态分布有两个参数,即均数与标准差(与) 总体均数μ是位置参数:描述正态分布的集中趋势位置。 总体标准差σ是变异度参数:描述正态分布离散趋势,标准差越小,分布越集中,曲线形状越 瘦高 ;反之越 矮胖 。 (4)正态分布的面积分布有一定的规律性,总面积=1;")
66
正态分布参数位置变化示意图

67
正态分布变异度不同变化示意图

68
(standard normal distribution)
二、标准正态分布 (standard normal distribution) 标准正态离差 正态分布 标准正态分布 u为标准化变量值 标准正态分布概率密度函数,记作N(0,1)。
 标准正态离差. 正态分布. 标准正态分布. u为标准化变量值. 标准正态分布概率密度函数,记作N(0,1)。")
69
将正态分布曲线的原点移到的位置,横轴尺度以σ为单位,令μ=0,σ=1,则将正态分布变换为标准正态分布
u→±∞ Φ (u) →0 - 4 3 2 1 u Φ ( ) ∞ +∞
 → u. Φ. ( ) ∞ +∞")
70
三、正态曲线下面积的分布规律 是正态变量x的累计分布函数,反映正态曲线下, 横轴自-∞到x的面积,即下侧累计面积(概率)
")
71
φ(u)表示从-∞到u值范围内X分布面积
标准正态分布曲线下面积 左侧任一区间的面积可以通过对下式积分求得 φ(u)表示从-∞到u值范围内X分布面积
表示从-∞到u值范围内X分布面积.")
72
曲线下面积分布规律 -1 1 -1.96 1.96 -2.58 2.58 68.27% 95.00% 99.00% 标准正态曲线 横轴为u值

73
二 医学参考值范围的估计 (一)基本概念 医学参考值范围(reference ranges)是指绝大多数正常人(或动物)的人体形态、功能和代谢产物等各种生理及生化指标常数。 由于存在个体差异,参考值范围并非为常数,而是在一定范围内波动。 确定医学参考值范围,是常用95%或99%的分布范围作为判定正常和异常的参考标准。

74
(二)制定医学参考值范围的基本原则 1.抽取样本含量足够大的“正常人”
“正常人”:不是机体任何器官、组织的形态及机能都正常的人,而是排除了影响所研究指标的疾病和有关因素的同质人群。 如:指定“谷丙转氨酶”的医学参考值范围 正常人条件:肝、肾、心、脑、肌肉等无器质性疾患;近期无使用损肝药物;测定前未做剧烈运动。 样本量:100例以上

75
2.对抽取的正常人进行准确而统一的测定,控制测量误差 3.判断是否需要分组制定 4.决定单侧或双侧界值。
5.选择适当的百分界值:习惯用80%、90%、95%、99%。 减少误诊——选择高的,95%或99% 减少漏诊——选择低的,80%或90% 6.根据资料的分布类型选用恰当的方法估计 (a)白细胞数参考值范围 (b)24小时尿糖参考值范围 (c)肺活量参考值范围
白细胞数参考值范围. (b)24小时尿糖参考值范围. (c)肺活量参考值范围.")
76
医学参考值范围 医学参考值范围的计算方法: 正态分布法 百分位数法 76

77
1、正态分布法 应用条件:正态分布或近似正态分布资料 计算 双侧100(1-α)%正常值范围: 单侧100(1-α)%正常值范围:
应用条件:正态分布或近似正态分布资料 计算 双侧100(1-α)%正常值范围: 单侧100(1-α)%正常值范围: 双侧95%正常值范围: 单侧95%正常值范围:
%正常值范围: 单侧100(1-α)%正常值范围: 双侧95%正常值范围: 单侧95%正常值范围:")
78
例14-14 根据14-2中150名3岁女孩身高资料,估计其95%参考值范围
图14-1 某市150名3岁女孩身高的频数分布

80
2、百分位数法 适用于偏态分布资料 双侧95%正常值范围: P2.5~P97.5 单侧95%正常值范围: < P95(上限)
")
81
例如: 1.确定白细胞总数的95%参考值范围 由于白细胞数过高过低均为异常,故应分别计算P2.5和P97.5 2.确定肺活量的95%参考值范围 由于肺活量只过低为异常,故只计算P5 3.确定尿铅的95%参考值范围 由于尿铅只以过高为异常,应计算P95

82
小结 1.正态分布是一种很重要的连续型分布,不少的医学现象服从正态分布或近似正态分布,或经变量变换转换为正态分布,可按正态分布规律来处理。它也是许多统计方法的理论基础。 2.正态分布的特征: (1)曲线在横轴上方,均数处最高 (2)以均数为中心,左右对称 (3)确定正态分布的两个参数是均数μ和标准差σ
以均数为中心,左右对称. (3)确定正态分布的两个参数是均数μ和标准差σ.")
83
小结 3.正态分布用N(μ,σ2) 表示,为了应用方便,常对变量x作 变换,使μ=0,σ=1,则正态分布转换为标准正态分布,用N(0,1)表示。 4.正态曲线下面积的分布有一定规律。理论上μ±1σ,μ±1.96σ和μ±2.58σ区间的面积(观察单位数)各占总面积的(总观察单位数)的68.27%,95%和99%,可用来估计医学参考值范围和质量控制等方面。
各占总面积的(总观察单位数)的68.27%,95%和99%,可用来估计医学参考值范围和质量控制等方面。")


=0 变换为 x= (x), 然后建立迭代格式, 返回下一页 则称迭代格式 收敛, 否则称为发散 上一页.>")

 求积公式.>")
















