Download presentation
1
第三章 迴歸模式之評估與修訂

3
迴歸分析之基本假設 在應用某種統計程序之前,必須注意其基本假設是否符合要求。
迴歸分析有三項基本假設: (1)常態性(2)均質性(3)獨立性。 「常態性」要求給定每一個預測變數 x 的值後,y 值的分配具有常態性。
常態性(2)均質性(3)獨立性。 「常態性」要求給定每一個預測變數 x 的值後,y 值的分配具有常態性。")
4
條件常態分配 迴歸模式中的常態分配指的是條件常態分配,即給定 x 值後 y 的分配是常態分配,至於全部的 y 值是否為常態分配並不是要求的條件。 迴歸分析對常態分配的假設也與 t 檢定、F 檢定一樣具有穩健性(Robust),也就是說,當資料偏離常態不是很嚴重時,仍可接受常態分配的假設條件成立。
,也就是說,當資料偏離常態不是很嚴重時,仍可接受常態分配的假設條件成立。")
5
均質性 與 獨立性 「均質性」指的是不論甚麼樣的 x 值,y 分配的變異數均相等。
均質性的假設對以普通最小平方法作迴歸係數的估計是重要的,如果各組變異數的差別很大,則必須利用變數變換或是加權最小平方法來處理。 「獨立性」指的是前一個誤差不會影響後一個誤差,也就是資料具有相同的分配且獨立,亦即誤差項無自我相關。

6
條件常態分配、均質性及線性

7
古典線性迴歸之基本假設 線性迴歸模型:迴歸模型對參數是線性的 Yi = β0 + β1Xi + i
誤差項 i 的平均值為零,即 E(i ) =0 誤差項 i 的變異數相等,即 Var(i ) =σ2 誤差項 i 無自我相關,即 Cov(i ,j) =0 , i≠j 誤差項 i 和 Xi 的共變異數為零,Cov(i ,Xi) =0
 =0. 誤差項 i 的變異數相等,即 Var(i ) =σ2. 誤差項 i 無自我相關,即 Cov(i ,j) =0 , i≠j. 誤差項 i 和 Xi 的共變異數為零,Cov(i ,Xi) =0.")
8
古典線性迴歸之基本假設 在重複抽樣中 X 值是固定的:X 不是隨機變數 觀測次數 n 必須大於待估計的參數個數
正確地設定了迴歸模型,即模型沒有設定偏誤 解釋變數之間沒有完全的共線性

9
古典線性迴歸之基本假設 當我們把普通最小平方法應用於古典線性迴歸模型時,並沒有對誤差項 i 的機率分配作任何假設(並不需要假設常態分配)。
有了這些假設,便看到 OLS 估計量 β0 、 β1 和 σ2 滿足線性、不偏和最小變異數(BLUE)等優良的統計性質。 ︿ ︿
等優良的統計性質。 ︿ ︿")
10
古典線性迴歸之基本假設 ︿ ︿ 因為 OLS 估計量 β0 和 β1 都是 i 的線性函數,而按假設 i 是隨機的,因此,OLS 估計量的抽樣分配或機率分配將依賴於 i 假設的機率分配。 因為必須知道這些估計量的機率分配,方能對它們的母體值進行推論,所以為了假設檢定,必須先對 i 的機率分配作出假設。

11
誤差項 i 的常態假設 誤差項 i 的平均值為零,即 E(i ) =0 誤差項 i 的變異數相等,即 Var(i ) =σ2
誤差項 i 之間無自我相關,即 Cov(i ,j) =0 , i≠j 誤差項 i 服從常態分配,即 i ~ ~N(0, σ2) i.i.d
 =0 , i≠j. 誤差項 i 服從常態分配,即 i ~ ~N(0, σ2) i.i.d.")
12
OLS 估計量的抽樣分配 因為 誤差項 i 代表沒有納入迴歸模型的其他所有影響因素,而在這些影響因素中,每種因素對 Y 的影響都很微弱。
常態變數的線性函數仍服從常態分配。

13
中央極限定理 由母體平均數為 μ 與變異數為 σ2 的任意母體 中,抽出樣本數為 T 的一組隨機樣本 X1, X2, … , XN。若樣本數 T (觀察值) 夠大 (T≧30) , 則樣本平均數 XN 的抽樣分配,會趨近於常態 分配。 或

14
OLS 估計量的抽樣分配 由於 Yi = β0 + β1Xi + i , 而因為 β0 和 β1 是常數,Xi 也是給定的值,所以 Yi 是 i 的線性組合。 因此,若 i ~ N (0, σ2), 則 Yi ~ N ( β0+β1Xi , σ2)
, 則 Yi ~ N ( β0+β1Xi , σ2)")
15
OLS 估計量的抽樣分配 ︿ ︿ ︿ 因為 β0 和 β1 是 Yi 的線性組合,所以 β0 和 β1 也是常態分配。
因此, β0 ~ N (β0 , σ02), β1 ~ N ( β1 , σ12) 知道 β0 和 β1 的抽樣分配,才能對迴歸式的參數做假設檢定。 ︿ ︿ ︿ ︿ ︿
, β1 ~ N ( β1 , σ12) 知道 β0 和 β1 的抽樣分配,才能對迴歸式的參數做假設檢定。 ︿ ︿ ︿ ︿ ︿")
16
殘 差 分 析 如何檢查迴歸模式是否滿足其基本的假設,主要是利用殘差分析。
基本上,如果模式正確,則殘差圖應該會「很亂」,即殘差圖上找不出有任何圖案。如果殘差圖有圖案存在,表示模式不好,需作適當的修正。

17
殘 差 分 析 為甚麼殘差圖要很亂才表示模式正確呢?因為我們將觀察值 yi 分解成二部份:可解釋的部份與不可解釋的部份。
不可解釋的部份即殘差項,它是所有「噪音」(雜訊) 的整合體,不能有圖案,否則應再將它抽離出來,放在可解釋的部份。
 的整合體,不能有圖案,否則應再將它抽離出來,放在可解釋的部份。")
18
迴 歸 模 型 Yi = β0 + β1X1i + i

19
殘差圖之「圖案」 (1)標準的圖案。 (2)殘差項有趨勢存在。 (3)殘差項為二次式。 (4)殘差的變異數隨 x 而改變。 (5)存在自我相關的迴歸式。 (6)可能需加入其它重要的變數。 (7)異常點。
標準的圖案。 (2)殘差項有趨勢存在。 (3)殘差項為二次式。 (4)殘差的變異數隨 x 而改變。 (5)存在自我相關的迴歸式。 (6)可能需加入其它重要的變數。 (7)異常點。")
20
殘差隨機跳動之標準型

21
殘差項有趨勢存在

22
加入趨勢項 Yi = β0 + θT + β1X1i + I H0:θ=0

23
殘差圖呈現二次型

24
加入二次項 Yi = β0 + θT + β1X1i + β2X21i + I H0:β2=0

25
殘差項有異質變異數 採用加權最小平方法估計及檢定

26
殘差項有異質變異數 採用加權最小平方法估計及檢定

27
殘差項有自我相關 改用時間數列分析的方法

28
可能要加入其他變數

29
可能要加入其他變數 體重 身高 ◎ ◎ ◎ ◎ ◎ ◎ ◎ * ◎ * * ◎ * ◎ * * * * ◎ * * ◎ ◎ * ◎ *
◎:男 * * ◎ * *:女 身高

30
可能要加入其他變數

31
虛 擬 變 數 Yi = β0 + β1Xi + i Yi = β0 + δD+ β1Xi + i D = 1,若為男性 0,若為女性

32
虛 擬 變 數 Yi = β0 + β1Xi + i Yi = (β0 + δ)+ β1Xi + i H0: δ=0 H1: δ≠0
女性: 男性:

33
加入虛擬變數的結果 體重 δ 身高 β0 ◎ ◎ ◎ ◎ ◎ ◎ ◎ * ◎ * * ◎ * ◎ * * * * ◎ * * ◎ ◎ * ◎
◎:男 * * ◎ * *:女 δ β0 身高

34
加入虛擬變數後的殘差 * * * * ◎ * * ◎ ◎ ◎ ◎ ◎ * * ◎ * ◎ ◎ * ◎ ◎

35
虛擬變數陷阱 Yi = β0 + β1Xi + i Yi = β0 + δD1+ γD2 + β1Xi + I 1,若為男性
0,若為男性 D1 = D2 = 0,若為女性 1,若為女性 會產生完全多重共線性的問題

36
虛擬變數的個數 一般的原則是:如果模型有共同的截距項,且屬質變數 (類別變數) 有 m 種分類,則需引入 ( m-1 ) 個虛擬變數。
如果不符合這條原則,則會陷入虛擬變數陷阱,即「完全多重共線性」。

37
函數型式 與 結構轉變 欲知四季對可支配所得與消費之間的關係,模型如下:
Ct = β1 + β2 × Xt + δ1 × Dt1 + δ2 × Dt2 + δ3 × Dt3 + εt 其中 D 為虛擬變數,其值為 0 或 1。以第四季為基準。 如果模型中有截距項,則 4 個類別只能使用 3 個虛擬變 數,若使用 4 個虛擬變數,則會有「虛擬變數陷阱」的 問題,即會產生「完全多重共線性」的問題。 當模型中有截距項,則 β1 表示第 4 季 (基準) 的效果,而 δ1 、 δ2 、 δ3 分別表示第 1、2、3 季和第 4 季的差距。 37
 的效果,而 δ1 、 δ2 、 δ3 分別表示第 1、2、3 季和第 4 季的差距。 37.")
38
函數型式 與 結構轉變 欲知季節性對可支配所得與消費之間的關係,模型如下:
Ct = β1 × Xt + δ1 × Dt1 + δ2 × Dt2 + δ3 × Dt3 + δ4 × Dt4 + εt 如果模型中沒有截距項,則 4 個類別就可以使用 4 個虛 擬變數,此時不會有「虛擬變數陷阱」的問題。 當模型中沒有截距項,則 δ1 、 δ2 、 δ3 、 δ4 分別表示在 所得保持固定下,第 1、2、3、4 季的效果。 38

39
類別變數 與 虛擬變數 的差異性 欲知學歷對所得的影響,模型如下: Income = β1 + β2 × age + δ × E + εt
其中,E 為類別變數,其值如下:E = 0,若為大學以下; E = 1,若為大學畢業;E = 2,若為碩士畢業;E = 3,若 為博士畢業。 此種類別變數的設定,隱含不必要的限制條件:它隱含 不同學歷差距的所得差距是相等的,即大學以下為 β1 , 大學畢業為 β1 + δ ,碩士為 β1 + 2δ ,而博士為 β1 + 3δ 。 39

40
類別變數 與 虛擬變數 的差異性 欲知學歷對所得的影響,較好的模型如下:
Income = β1 + β2 × age + δB × B + δM × M + δP × P + εt 其中,B、M、P 分別為虛擬變數,其值為 1 時,分別代 表大學、碩士、博士;否則為 0。 此種模型下,以「大學以下」為比較基準。學歷的效果: 大學以下為 β1 ,大學畢業為 β1 + δB ,碩士為 β1 + δM , 而博士為 β1 + δP 。即大學畢業比大學以下多賺 δB,碩士 比大學以下多賺 δM ,而博士則比大學以下多賺 δP 。 40

41
函數型式 與 結構轉變 Income = β1 + β2 × age + δB × B + δM × M + δP × P + εt
41

42
函數型式 與 結構轉變 Income = β1 + β2 × age + δB × B + δM × M + δP × P + εt
此模型,也可定義,只要具有該學歷,即給值 1,則在給 定 age 的條件下,其對所得的影響的係數分別如下,此 時 δB、 δM、 δP 的值分別代表不同學歷的邊際效果。 42

43
類別變數 與 虛擬變數 的差異性 假設類別變數有三類,使用類別變數的模型如下: Yi = α + βXi + εi
43

44
類別變數 與 虛擬變數 的差異性 跑完迴歸後,此類別變數對 Yi 的平均影響如下:
此種模型的估計,隱含 μA ≠ μB ≠ μC ,且 μA 和 μC 的差距 (2β) 是 μA 和 μB 的差距 (β) 的二倍,這種隱含的效果是不 適當的。所以一般以採用虛擬變數的方法為佳。 44
 是 μA 和 μB 的差距 (β) 的二倍,這種隱含的效果是不 適當的。所以一般以採用虛擬變數的方法為佳。 44.")
45
類別變數 與 虛擬變數 的差異性 假設類別變數有三類,使用虛擬變數的模型如下: Yi = β1 + β2D2i + β3D3i + εi
45

46
類別變數 與 虛擬變數 的差異性 跑完迴歸後,此虛擬變數對 Yi 的平均影響如下: E(Yi ) = β1 + β2D2i + β3D3i
= β = μA 當 D2i = 0,且D3i = 0 = β1 + β = μB 當 D2i = 1 ,且D3i = 0 = β1 + β = μC 當 D3i = 1 ,且D2i = 0 此時, μA ≠ μB ≠ μC ,但其間的差距並不相同。 46

47
適合度檢定 常態性的檢定法: (1)畫直方圖(2)畫常態機率圖 (3)卡方檢定法(4)S-W法、K-S 法和 J-B 法
異質變異數的檢定法: (1)畫殘差圖(2) White 的一般異質性變異數檢定(3)其他異質性變異數檢定方法 獨立性的檢定法: (1)畫殘差圖(2) Durbin-Watson d 檢定 (3)其他誤差項自我相關檢定方法 (連檢定)
畫殘差圖(2) White 的一般異質性變異數檢定(3)其他異質性變異數檢定方法. 獨立性的檢定法: (1)畫殘差圖(2) Durbin-Watson d 檢定 (3)其他誤差項自我相關檢定方法 (連檢定)")
48
模式之修訂與變數變換 模式之修訂: (1)變數變換。(2)加入其它變數。 (3)放棄線性迴歸式,改用非線性迴歸式, 或其它方式如時間數列分析等。 Box-Cox 變數變換: Y* = Yλ

49
模 式 變 換 其它常用的模式變換: (1)倒數變換。 (2)指數模式。 (3)乘冪函數模式。 (4)經過原點的迴歸線模式。
倒數變換。 (2)指數模式。 (3)乘冪函數模式。 (4)經過原點的迴歸線模式。")
50
過原點的迴歸 採用經過原點之迴歸模式的時機: (1)有學理上的依據時。 (2)在求出一般的線性迴歸式後,發現其參 數估計表中的截距項不顯著。
採用經過原點之迴歸模式的時機: (1)有學理上的依據時。 (2)在求出一般的線性迴歸式後,發現其參 數估計表中的截距項不顯著。 除非有非常強的事前預期,否則以採取含有截距的模型較好。若模型中確實應含有截距項而卻配適過原點的迴歸,則犯了模型設定偏誤的錯。其次,若經檢定後發現截距項不顯著,則事後再改成過原點的迴歸即可。
有學理上的依據時。 (2)在求出一般的線性迴歸式後,發現其參 數估計表中的截距項不顯著。 除非有非常強的事前預期,否則以採取含有截距的模型較好。若模型中確實應含有截距項而卻配適過原點的迴歸,則犯了模型設定偏誤的錯。其次,若經檢定後發現截距項不顯著,則事後再改成過原點的迴歸即可。")
51
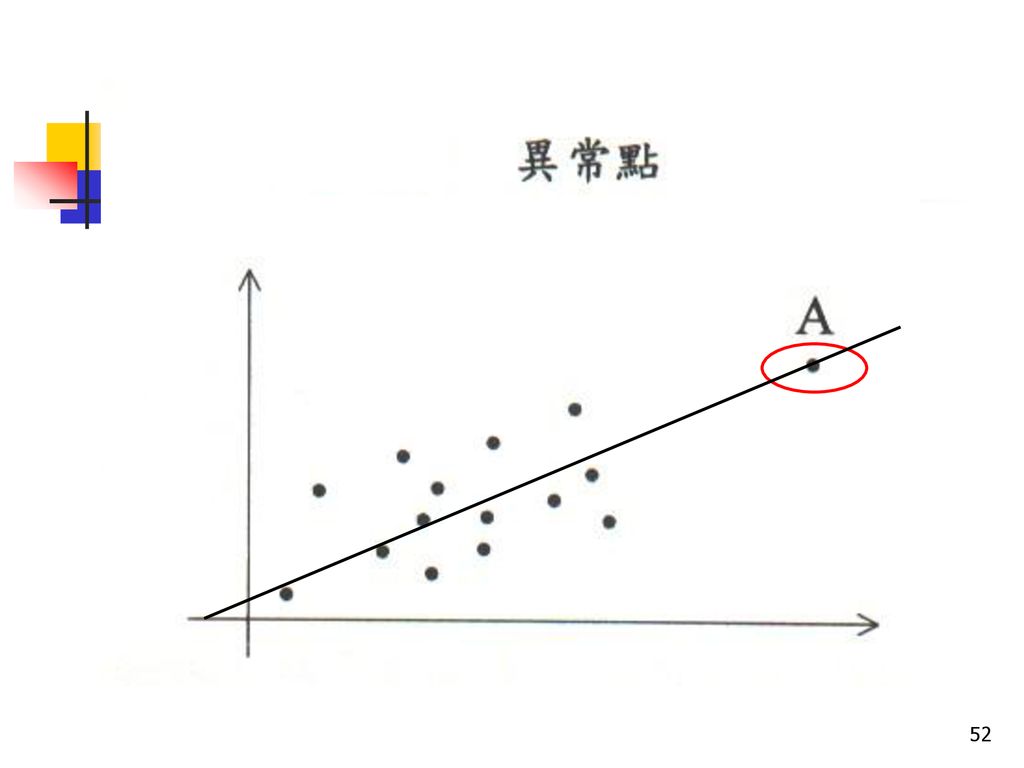
異常點 與 影響點 異常點:在散佈圖上,有些點與其它點離得很遠,但是此點的有無不會對迴歸線產生影響。
影響點:在散佈圖上,有些點與其它點離得很遠,且此點的有無會對迴歸線產生重大影響。 當出現離群值時,通常需提出解釋。

53
影 響 點

54
函數型式—Box-Cox 轉換 以下二式,哪一式是較好的函數型式? 注意:因為應變數不同,所以先前的方法不能用。 54

55
函數型式—Box-Cox 轉換 雖然經濟學家對於哪些變數應該包含在一特定的關係之 中,通常會有相當強的先驗資訊,但對於其精確的函數 型式,卻通常只有相當少的資訊。 由 Box-Cox 於 1964 年首度引入的 Box-Cox 轉換,已因 Zarembka 於 1968、1974 年將其作為以資料來決定哪一 個函數型式是最合適的,而在經濟學界廣受歡迎。 所謂「由資料決定函數型式」的意思是說,函數的型式 應該由對函數參數的估計值來定義。 55

56
函數型式—Box-Cox 轉換 56

57
函數型式—Box-Cox 轉換 當 = 0 時,z() = ln z,因此 (12.5.4) 式 ( 沒有下標,所 以是相同的) 會與 (12.5.2) 式相同。 57
 = ln z,因此 (12.5.4) 式 ( 沒有下標,所 以是相同的) 會與 (12.5.2) 式相同。 57")
58
函數型式—Box-Cox 轉換 當 = 1 時,z() = z - 1,因此 (12.5.4) 式可改寫成 (12.5.5) 式,而 (12.5.5) 式其實等於 (12.5.1) 式。 58
 = z - 1,因此 (12.5.4) 式可改寫成 (12.5.5) 式,而 (12.5.5) 式其實等於 (12.5.1) 式。 58.")
59
函數型式—Box-Cox 轉換 如果轉換的參數對每個變數都不同 ( 有下標,所以是不 同的) ,則在估計 (12.5.6) 式時會更有彈性: 但是增加彈性並非沒有代價。在這個模型中,如果沒有 大量的觀察值,則要想可靠地估計所有的參數就會有困 難。 59

60
White Robust 修正異質變異數 先以 OLS 跑原始迴歸,得出殘差,存殘差平方。
H0 : 無異質變異 v.s. H1 : 有異質變異。 檢定統計量為: n R2 ~X2(k) 其中 k 為輔助迴歸中迴歸變數的個數。 60
 其中 k 為輔助迴歸中迴歸變數的個數。 60.")
61
White Robust 修正異質變異數 原始迴歸: Yi = β1 + β2X2i + β3X3i + εi 。
先以 OLS 跑原始迴歸,得出殘差,存殘差平方。 將原始迴歸的解釋變數加入平方項 (及交叉相乘項) ,以 殘差平方對常數項及全部解釋變數跑 OLS,稱輔助迴歸。 輔助迴歸: Yi = β1 + β2X2i + β3X3i + β4X2i2 + β5X3i2 + β6X2i X3i + εi 。 從輔助迴歸中,得出 R2。 檢定統計量為: n R2 ~X2(k) 61
 ,以 殘差平方對常數項及全部解釋變數跑 OLS,稱輔助迴歸。 輔助迴歸: Yi = β1 + β2X2i + β3X3i + β4X2i2 + β5X3i2 + β6X2i X3i + εi 。 從輔助迴歸中,得出 R2。 檢定統計量為: n R2 ~X2(k) 61.")
62
假性迴歸 (spurious regressions)
兩個隨機漫步模型 yt = yt-1 + t 與 xt = xt-1 + t, t 與 t 獨立,因此, yt = yt-1 + t 與 xt = xt-1 + t 應為獨立 (無關) 的時間序列。迴歸 yt = + xt + t 在直覺上應該會接受 H0: = = 0 的虛無假設。但執行迴歸 yt = + xt + t 的 t 檢定,拒絕 H0: = 0 的機率約為 75% 而非 5%,產 生錯誤的統計推論,此即所謂假性迴歸的問題。 因為迴歸 yt = + xt + t 的誤差項 t 不是定態的時間序 列,若直接將非定態的變數進行迴歸分析,可能產生假 性迴歸的問題。也就是說傳統的 t 檢定和 F 檢定會產生 過度拒絕 H0 的結果,因而產生錯誤的統計推論。 62
 的時間序列。迴歸 yt = + xt + t 在直覺上應該會接受 H0: = = 0 的虛無假設。但執行迴歸 yt = + xt + t 的 t 檢定,拒絕 H0: = 0 的機率約為 75% 而非 5%,產 生錯誤的統計推論,此即所謂假性迴歸的問題。 因為迴歸 yt = + xt + t 的誤差項 t 不是定態的時間序 列,若直接將非定態的變數進行迴歸分析,可能產生假 性迴歸的問題。也就是說傳統的 t 檢定和 F 檢定會產生 過度拒絕 H0 的結果,因而產生錯誤的統計推論。 62.")
63
假性迴歸 與 共整合 yt 與 xt 均為隨機漫步的時間序列 I(1),且 t = yt - - xt 亦為 I(1),表示 yt 與 xt 為無關的隨機漫步。若將 yt 對 xt 跑迴歸, yt = + xt + t ,則會有虛假迴歸的問題。 yt 與 xt 均為隨機漫步的時間序列 I(1),但 t = yt - - xt 為 I(0),則表示 yt 與 xt 為共整合。此時若將 yt 對 xt 跑迴 歸, yt = + xt + t ,則所得出的結果是有意義的。 yt 與 xt 均為隨機漫步,分別代表兩個醉漢的足跡;若 yt 與 xt 為共整合,表示兩個醉漢以一段繩子綁住後的足跡, 兩個醉漢的足跡雖是隨機漫步,但又不會相距太遠。 63
,但 t = yt - - xt 為 I(0),則表示 yt 與 xt 為共整合。此時若將 yt 對 xt 跑迴 歸, yt = + xt + t ,則所得出的結果是有意義的。 yt 與 xt 均為隨機漫步,分別代表兩個醉漢的足跡;若 yt 與 xt 為共整合,表示兩個醉漢以一段繩子綁住後的足跡, 兩個醉漢的足跡雖是隨機漫步,但又不會相距太遠。 63.")











 Wonnacott and Wonnacott. Introductory>")









