Download presentation
Presentation is loading. Please wait.

1
第四章 随机变量的数字特征 随机变量的分布是对随机变量的一种完整的描述,知道随机变量的分布就全都知道随机变量的所有特征。然后随机变量的概率分布往往不容易求得的。 随机变量的这些统计特征通常用数字表示的。这些用来描述随机变量统计性的数字称为随机变量的数字特征。其中最重要的是数学期望(均值)和方差二种。 §4.1 数学期望与方差 一.数学期望
和方差二种。 §4.1 数学期望与方差. 一.数学期望.")
2
随机变量x及它所取的数和相应频率的乘积和,称为x的平 均数(属于加权平均)也称为随机变量的数学期望或均值.
(一)离散型随机变量的数学期望 定义1 离散型随机变量X 有概率函数 P(X=xk)=Pk (k=1,2,....) 若级数 绝对收敛,则称这个级数为X 的数学期望 =
离散型随机变量的数学期望. 定义1 离散型随机变量X 有概率函数 P(X=xk)=Pk (k=1,2,....) 若级数 绝对收敛,则称这个级数为X 的数学期望. =")
3
例1 甲在机床上生产某产品,若一等品能赚5元,二等品赚3元,
次品亏2元.甲生产时一等品、二等品及次品的概率为0.6,0.3,0.1 .问生产每件产品平均能创造多少财富? 分析: x p 数学期望为3.7元.表示生产一件产品能创造3.7元

4
ò 随机变量X的数学期望是随机变量的平均数.它是将随机变量 x及它所取的数和相应频率的乘积和. = (1) (二)连续型随机变量的数学期望
定义 设连续型随机变量 有概率密度 若 绝对收敛,则 称为 的 数学期望 ) 2 3 ( - = ò dx x E j
 ( - = ò. dx. x. E. j.")
5
例2 计算在区间[a,b]上服从均匀分布的随机变量 的数学期望
可见均匀分布的数学期望为区间的中值.
![例2 计算在区间[a,b]上服从均匀分布的随机变量 的数学期望](http://slidesplayer.com/slide/11358348/61/images/5/%E4%BE%8B2+%E8%AE%A1%E7%AE%97%E5%9C%A8%E5%8C%BA%E9%97%B4%5Ba%2Cb%5D%E4%B8%8A%E6%9C%8D%E4%BB%8E%E5%9D%87%E5%8C%80%E5%88%86%E5%B8%83%E7%9A%84%E9%9A%8F%E6%9C%BA%E5%8F%98%E9%87%8F+%E7%9A%84%E6%95%B0%E5%AD%A6%E6%9C%9F%E6%9C%9B.jpg "可见均匀分布的数学期望为区间的中值.")
6
2.随机变量函数的数学期望 定理1 设Y是随机变量X的函数,Y=g(X)(g是连续函数) (1)若X是离散型随机变量,它的分布律为P{X=xk}=pk. K=1,2,.. 若 (2)若X是连续型随机变量,它的概率密度为f(x). 定理1表示:求E(Y)时,不必知道Y的分布,而只要知道X的分布
时,不必知道Y的分布,而只要知道X的分布.")
7
定理2 设Z是随机变量X和Y的函数,Z=g(X,Y)(g是连续函数),那么Z也是一个随机变量,设(X,Y)的概率密度为f(x,y),则
这里假设上式右边的积分绝对收敛. 若(X,Y)为离散型随机变量,其分布律为 P{X= , Y= }= ,i,j=1,2,... 则
为离散型随机变量,其分布律为. P{X= , Y= }= ,i,j=1,2,... 则.")
8
例3 已知X在[-a,a]上服从均匀分布,试求Y=X3-kX和Y2=(X3-kX)2的数学期望
解:由(8)式,得到
![例3 已知X在[-a,a]上服从均匀分布,试求Y=X3-kX和Y2=(X3-kX)2的数学期望](http://slidesplayer.com/slide/11358348/61/images/8/%E4%BE%8B3+%E5%B7%B2%E7%9F%A5X%E5%9C%A8%5B-a%2Ca%5D%E4%B8%8A%E6%9C%8D%E4%BB%8E%E5%9D%87%E5%8C%80%E5%88%86%E5%B8%83%2C%E8%AF%95%E6%B1%82Y%3DX3-kX%E5%92%8CY2%3D%28X3-kX%292%E7%9A%84%E6%95%B0%E5%AD%A6%E6%9C%9F%E6%9C%9B.jpg "解:由(8)式,得到.")
9
3. 数学期望的性质 (1) E(C)=C. (2) E( +C)=E +C 证明:对离散型随机变量 对连续型随机变量
 E(C)=C. (2) E( +C)=E +C 证明:对离散型随机变量 对连续型随机变量")
10
(3) 证明:若C=0,则 是一个常数0,由性质1可知它成立。
 证明:若C=0,则 是一个常数0,由性质1可知它成立。")
11
å h x E p y xp + = (4) (5)两个随机变量之和的数学期望等于这两个随机变量数学 期望的和。 证明:设 是离散型随机变量
证明:设 是离散型随机变量 h x E p y xp j i ij + = å ) 2 ( 1 这个性质可以推广到有限多个
 2. ( 1. 这个性质可以推广到有限多个.")
12
推理: (6)两个相互独立的随机变量乘积的数学期望等于它们数学 期 望的乘积。 证明:因为 相互独立, 连续型随机变量
两个相互独立的随机变量乘积的数学期望等于它们数学 期 望的乘积。 证明:因为 相互独立, 连续型随机变量")
13
例7 仪器由二部分组成,其总长为二部分长度的和。
求 p 分析: p 因为 不独立,只能用(3-6)式进行计算.
式进行计算.")
14
下面介绍几个常用的公式

15
(一) 方差的定义 定义 如果随机变量 的数学期望 存在,称 为随机 变量 的离差,显然 不论正偏差大或是负偏差大,同样是离散程度大,用 来
定义 如果随机变量 的数学期望 存在,称 为随机 变量 的离差,显然 不论正偏差大或是负偏差大,同样是离散程度大,用 来 衡量 和 的偏差 定义3-4 随机变量离差平方的数学期望,称为随机变量的方差, 记 或 而 称为 的标准差

16
随机变量的方差是一个正数, 当 的可能值在它的期望值 附近,方差小,反之则大.方差表示随机变量的离散程度.
若 是离散型随机变量,且 若 是连续型随机变量,有概率密度 随机变量的方差是一个正数, 当 的可能值在它的期望值 附近,方差小,反之则大.方差表示随机变量的离散程度.

17
例8 甲乙两个射手,射击点和目标的距离分别为 ,且分布律
p p 求 甲,乙双方的数学期望相同,表示他们的准确度相同.由于乙的方 差小,表示乙射手比甲射手好

18
(二) 方差的性质 1、常数的方差等于0 证明: 2、随机变量和常数之和的方差就等于这个随机变量的方差。 证明: 3、常数和随机变量乘积的方差等于这个常数的平方和随机 变量方差的乘积。 证明:
 方差的性质 1、常数的方差等于0 证明: 2、随机变量和常数之和的方差就等于这个随机变量的方差。 证明: 3、常数和随机变量乘积的方差等于这个常数的平方和随机 变量方差的乘积。 证明:")
19
4. 两个独立的随机变量之和的方差等于两个随机变量方差的 和
4. 两个独立的随机变量之和的方差等于两个随机变量方差的 和 证明: 若 独立

20
) 17 3 ( - = x E D 进一步可得到:n个相互独立的随机变量算术平均数的方差等于 其方差算术平均数的1/n倍。
5、任意随机变量的方差等于这个随机变量平方的期望和它期 望的平方之差,即 ) 17 3 ( 2 - = x E D 证明: 这个公式用来简化方差计算。且说明随机变量平方的数学期望 大于期望的平方。
 ( 2. - = x. E. D. 证明: 这个公式用来简化方差计算。且说明随机变量平方的数学期望. 大于期望的平方。")
21
例9 计算在区间[a,b]上服从均匀分布的随机变量 的方差
![例9 计算在区间[a,b]上服从均匀分布的随机变量 的方差](http://slidesplayer.com/slide/11358348/61/images/21/%E4%BE%8B9+%E8%AE%A1%E7%AE%97%E5%9C%A8%E5%8C%BA%E9%97%B4%5Ba%EF%BC%8Cb%5D%E4%B8%8A%E6%9C%8D%E4%BB%8E%E5%9D%87%E5%8C%80%E5%88%86%E5%B8%83%E7%9A%84%E9%9A%8F%E6%9C%BA%E5%8F%98%E9%87%8F+%E7%9A%84%E6%96%B9%E5%B7%AE.jpg "例9 计算在区间[a,b]上服从均匀分布的随机变量 的方差")
22
对于二维随机变量(X,Y),方差D(X,Y)=[D(X),D(Y)] (20)
![对于二维随机变量(X,Y),方差D(X,Y)=[D(X),D(Y)] (20)](http://slidesplayer.com/slide/11358348/61/images/22/%E5%AF%B9%E4%BA%8E%E4%BA%8C%E7%BB%B4%E9%9A%8F%E6%9C%BA%E5%8F%98%E9%87%8F%28X%2CY%29%2C%E6%96%B9%E5%B7%AED%28X%2CY%29%3D%5BD%28X%29%2CD%28Y%29%5D+%2820%29.jpg "对于二维随机变量(X,Y),方差D(X,Y)=[D(X),D(Y)] (20)")
23
§4.2 几个重要分布的数学期望及方差 (一)两点分布 x pk p p
两点分布 x 1 0 pk p 1-p")
24
(二)二项分布(具有独立和‘是与否’二种结果的条件。
当n=1时,它为两点分布。)
")
25
利用二点分布 也可推出二项分布的期 望及方差。

26
(3)泊松分布 π(λ) 泊松分布的数学期望和方差都等于参数λ.
泊松分布 π(λ) 泊松分布的数学期望和方差都等于参数λ.")
27
(4)指数分布 f(x)= (4-6) 其他
指数分布 f(x)= (4-6) 其他")
28
, ) ( 1 > G = - x e r l j (6) 分布 (4-7) 其他 令
 ( 1 > G = - x e r l j (6) 分布 (4-7) 其他 令")
29
(7) 正态分布
 正态分布")
30
(7) 正态分布
 正态分布")
32
几种重要分布的数学期望和方差: 两点分布 p p(1-p) 二项分布 np npq 超几何分布 nN1/N 普哇松分布 指数分布 分布 正态分布

33
§4.3 其他数字特征 介绍另外一些数字特征,包括矩,协方差与相关系数. 矩的概念 (1). k阶原点矩
§4.3 其他数字特征 介绍另外一些数字特征,包括矩,协方差与相关系数. 矩的概念 (1). k阶原点矩 定义1 设X为随机变量,如果αk=E(Xk),k=1,2, (1) 存在时,称αk为X的k阶原点矩,简称k阶矩. 由定义1可知,X的k阶原点矩就是Xk的数学期望,所以求原点矩 的问题,就是求随机变量的函数Y=Xk的数学期望.特别地,X的数 学期望就是一阶原点矩.
. k阶原点矩. 定义1 设X为随机变量,如果αk=E(Xk),k=1,2,... (1) 存在时,称αk为X的k阶原点矩,简称k阶矩. 由定义1可知,X的k阶原点矩就是Xk的数学期望,所以求原点矩. 的问题,就是求随机变量的函数Y=Xk的数学期望.特别地,X的数. 学期望就是一阶原点矩.")
34
(2) k阶中心矩 定义2 设X为随机变量,如果E(X)存在,那么,当 = ,k=1, (2)存在时,称 为X的k阶中心矩. 显然,X的方差D(X)就是X的二阶中心矩. (3) 混合矩 定义3 设(X,Y)是二维随机变量,如果 = ,k,L=1,2,... (3)存在,则称 为二维随机变量(X,Y)的k+L阶混合(原点)矩.
就是X的二阶中心矩. (3) 混合矩. 定义3 设(X,Y)是二维随机变量,如果 = ,k,L=1,2,... (3)存在,则称 为二维随机变量(X,Y)的k+L阶混合(原点)矩.")
35
(4) 混合中心矩 定义4 设(X,Y)为二维随机变量,如果μkl=E{[X-E(X)]k[Y-E(Y)]L} k,L=1,2, (4)存在,则称μkL为二维随机变量(X,Y)的k+L阶混合中心矩. 协方差与相关系数
![(4) 混合中心矩 定义4 设(X,Y)为二维随机变量,如果μkl=E{[X-E(X)]k[Y-E(Y)]L} k,L=1,2,.... (4)存在,则称μkL为二维随机变量(X,Y)的k+L阶混合中心矩.](http://slidesplayer.com/slide/11358348/61/images/35/%284%29+%E6%B7%B7%E5%90%88%E4%B8%AD%E5%BF%83%E7%9F%A9+%E5%AE%9A%E4%B9%894+%E8%AE%BE%28X%2CY%29%E4%B8%BA%E4%BA%8C%E7%BB%B4%E9%9A%8F%E6%9C%BA%E5%8F%98%E9%87%8F%2C%E5%A6%82%E6%9E%9C%CE%BCkl%3DE%7B%5BX-E%28X%29%5Dk%5BY-E%28Y%29%5DL%7D+k%2CL%3D1%2C2%2C....+%284%29%E5%AD%98%E5%9C%A8%2C%E5%88%99%E7%A7%B0%CE%BCkL%E4%B8%BA%E4%BA%8C%E7%BB%B4%E9%9A%8F%E6%9C%BA%E5%8F%98%E9%87%8F%28X%2CY%29%E7%9A%84k%2BL%E9%98%B6%E6%B7%B7%E5%90%88%E4%B8%AD%E5%BF%83%E7%9F%A9..jpg "协方差与相关系数.")
36
定义5 设(X,Y)为二维随机变量,称1+1阶混合中心矩E{[X-E(X)][Y-E(Y)]}为X与Y的协方差,记为Cov(X,Y),即Cov(X,Y)=E{[X-E(X)][Y-E(Y)]}而
由协方差的定义可得 Cov(X,Y)= E{[X-E(X)][Y-E(Y)]}=E{XY-E(X)Y-E(Y)X+E(X)E(Y)=E(XY)-E(X)E(Y)
![定义5 设(X,Y)为二维随机变量,称1+1阶混合中心矩E{[X-E(X)][Y-E(Y)]}为X与Y的协方差,记为Cov(X,Y),即Cov(X,Y)=E{[X-E(X)][Y-E(Y)]}而](http://slidesplayer.com/slide/11358348/61/images/36/%E5%AE%9A%E4%B9%895+%E8%AE%BE%28X%2CY%29%E4%B8%BA%E4%BA%8C%E7%BB%B4%E9%9A%8F%E6%9C%BA%E5%8F%98%E9%87%8F%2C%E7%A7%B01%2B1%E9%98%B6%E6%B7%B7%E5%90%88%E4%B8%AD%E5%BF%83%E7%9F%A9E%7B%5BX-E%28X%29%5D%5BY-E%28Y%29%5D%7D%E4%B8%BAX%E4%B8%8EY%E7%9A%84%E5%8D%8F%E6%96%B9%E5%B7%AE%2C%E8%AE%B0%E4%B8%BACov%28X%2CY%29%2C%E5%8D%B3Cov%28X%2CY%29%3DE%7B%5BX-E%28X%29%5D%5BY-E%28Y%29%5D%7D%E8%80%8C.jpg "由协方差的定义可得. Cov(X,Y)= E{[X-E(X)][Y-E(Y)]}=E{XY-E(X)Y-E(Y)X+E(X)E(Y)=E(XY)-E(X)E(Y)")
37
(2)Cov(aX,bY)=abCov(X,Y). a,b是常数 (3)Cov( + ,Y)=Cov( ,Y)+Cov( , Y).
协方差具有以下的性质. (1)Cov(X,Y)=Cov(Y,X) (2)Cov(aX,bY)=abCov(X,Y) a,b是常数 (3)Cov( ,Y)=Cov( ,Y)+Cov( , Y). 定理1 (1)若X与Y相互独立,则ρxy=0; (2)| ρxy|≤1; (3)| ρxy|=1的充分必要条件是:存在常数a,b使P{Y=aX+b} =1.即X与Y以概率为1线性相关.
Cov(X,Y)=Cov(Y,X) (2)Cov(aX,bY)=abCov(X,Y). a,b是常数. (3)Cov( + ,Y)=Cov( ,Y)+Cov( , Y). 定理1 (1)若X与Y相互独立,则ρxy=0; (2)| ρxy|≤1; (3)| ρxy|=1的充分必要条件是:存在常数a,b使P{Y=aX+b} =1.即X与Y以概率为1线性相关.")
38
证明:(1) X与Y相互独立,我们有E(XY)=E(X)E(Y),
因为Cov(X,Y)=E{[X-E(X)][Y- E(Y)]=E(XY)-E(X)E(Y) 所以Cov(X,Y)=0, 有ρxy的公式表示它为0. ) ( , Y D X Cov xy = r (2)先证一个重要的不等式---柯西-许瓦兹不等式:若E(W2) 及E(V2)存在,则[E(WV)]2≤E(W2)×E(V2) (8) 令g(t)=E[(tW-V)2]=t2E(W2)-2tE(WV)+E(V2)显然大于0的数学期 望 必定大于0.因此对一切实数t,都有(tW-V)2≥0,所以g(t)≥0. 这表示图形在X轴上方.从而二次方程g(t)=0或者没有实根,或者 只有重根.
=E{[X-E(X)][Y- E(Y)]=E(XY)-E(X)E(Y) 所以Cov(X,Y)=0, 有ρxy的公式表示它为0. ) ( , Y. D. X. Cov. xy. = r. (2)先证一个重要的不等式---柯西-许瓦兹不等式:若E(W2) 及E(V2)存在,则[E(WV)]2≤E(W2)×E(V2). (8) 令g(t)=E[(tW-V)2]=t2E(W2)-2tE(WV)+E(V2)显然大于0的数学期. 望 必定大于0.因此对一切实数t,都有(tW-V)2≥0,所以g(t)≥0. 这表示图形在X轴上方.从而二次方程g(t)=0或者没有实根,或者. 只有重根.")
39
其判别式 △=4[E(WV)]2-4E(W2)×E(V2)≤0 得到[E(WV)]2≤E(W2)×E(V2). →(8)式得到证明. 设W=X-E(X),V=Y-E(Y),那么
![其判别式 △=4[E(WV)]2-4E(W2)×E(V2)≤0 得到[E(WV)]2≤E(W2)×E(V2). →(8)式得到证明. 设W=X-E(X),V=Y-E(Y),那么](http://slidesplayer.com/slide/11358348/61/images/39/%E5%85%B6%E5%88%A4%E5%88%AB%E5%BC%8F+%E2%96%B3%3D4%5BE%28WV%29%5D2-4E%28W2%29%C3%97E%28V2%29%E2%89%A40+%E5%BE%97%E5%88%B0%5BE%28WV%29%5D2%E2%89%A4E%28W2%29%C3%97E%28V2%29.+%E2%86%92%288%29%E5%BC%8F%E5%BE%97%E5%88%B0%E8%AF%81%E6%98%8E.+%E8%AE%BEW%3DX-E%28X%29%2CV%3DY-E%28Y%29%2C%E9%82%A3%E4%B9%88.jpg "其判别式 △=4[E(WV)]2-4E(W2)×E(V2)≤0 得到[E(WV)]2≤E(W2)×E(V2). →(8)式得到证明. 设W=X-E(X),V=Y-E(Y),那么")
40
由(9)式知, |ρ xy|=1 等价于 [E(WV)]2=E(W2)E(V2). 即
g(t)= E[tW-V)2] =t2E(W2)-2tE(WV)+E(V2) =0 (10) 由于 E[X-E(X)]=E(x)-E(X) =0, E[Y-E(Y)]=E(Y)-E(Y) =0.故 E(tW-V)=tE(W)-E(V)=tE[X-E(X)]-E[Y-E(Y)]=0 所以 D(tW-V)=E{[tW-V-E(tW-V)]2}=E[(tW-V)2]= (11) 由于数学期望为0,方差也为0,即(11)式成立的充分必要条件是 P{tW-V=0}=1
![由(9)式知, |ρ xy|=1 等价于 [E(WV)]2=E(W2)E(V2). 即](http://slidesplayer.com/slide/11358348/61/images/40/%E7%94%B1%289%29%E5%BC%8F%E7%9F%A5%2C+%7C%CF%81+xy%7C%3D1+%E7%AD%89%E4%BB%B7%E4%BA%8E+%5BE%28WV%29%5D2%3DE%28W2%29E%28V2%29.+%E5%8D%B3.jpg "g(t)= E[tW-V)2] =t2E(W2)-2tE(WV)+E(V2) =0 (10) 由于 E[X-E(X)]=E(x)-E(X) =0, E[Y-E(Y)]=E(Y)-E(Y) =0.故. E(tW-V)=tE(W)-E(V)=tE[X-E(X)]-E[Y-E(Y)]=0. 所以 D(tW-V)=E{[tW-V-E(tW-V)]2}=E[(tW-V)2]=0 (11) 由于数学期望为0,方差也为0,即(11)式成立的充分必要条件是. P{tW-V=0}=1.")
41
即(11)式成立的充分必要条件是 P{tW-V=0}=1
这等价于 P{Y=aX+b}=1 其中a=t,b=E(Y)-tE(X) W=X-E(X),V=Y-E(Y),tW-V=tX-tE(X)-Y+E(Y)=0 定理证毕. 定理1告诉我们, 当X,Y相互独立时,|ρxy|达到最小值0, 当ρxy=0时称X和Y不相关, 当X和Y线性相关时,| ρxy|达到最大值1, 这说明ρxy在一定程 度上表达了X和Y之间的线性相关程度,称为相关系数.
-tE(X) W=X-E(X),V=Y-E(Y),tW-V=tX-tE(X)-Y+E(Y)=0 定理证毕. 定理1告诉我们, 当X,Y相互独立时,|ρxy|达到最小值0, 当ρxy=0时称X和Y不相关, 当X和Y线性相关时,| ρxy|达到最大值1, 这说明ρxy在一定程. 度上表达了X和Y之间的线性相关程度,称为相关系数.")
42
例2 设(X,Y)服从二维正态分布,其概率密度为
服从二维正态分布,其概率密度为")
43
所以E(X)=μ1,D(X)=σ12,E(Y)=μ2,D(Y)=σ22,而
=μ1,D(X)=σ12,E(Y)=μ2,D(Y)=σ22,而")
44
令

45
切比雪夫不等式 设随机变量X 具有数学期望E(X)=μ,方差D(X)=σ2 。则任给正 数ε, 有 不等式(14)和(15)称为切比雪夫不等式 它反映了均值与方差的意义,|X-E(X)|≥ξ即X取值不在E(X)附 近的概率不超过.当D(X)较小时, D(x)/ξ2就较小,X取值集中在 E(X)附近故E(X)是X取值的集中点.D(X)反映X在E(X)附近取值 的个数是多还是少.
较小时, D(x)/ξ2就较小,X取值集中在. E(X)附近故E(X)是X取值的集中点.D(X)反映X在E(X)附近取值. 的个数是多还是少.")
46
证明: X 是离散型随机变量 证明完毕

47
切比雪夫不等式给出了在随机变量X的分布未知的情况下,估计事件{|X-μ|<ε}的概率的方法.
例如取ε=3σ,得所谓“3σ规则”: P{|X-μ|<3σ}≥0.8889, 即事件|X-μ|<3σ的概率大约为0.9.特别是若X是正态随机变量,可算得到 P{μ-3σ<X<μ+3σ}=Φ(3)-Φ(-3)=2Φ(3)-1=0.9974
-Φ(-3)=2Φ(3)-1=")
Similar presentations
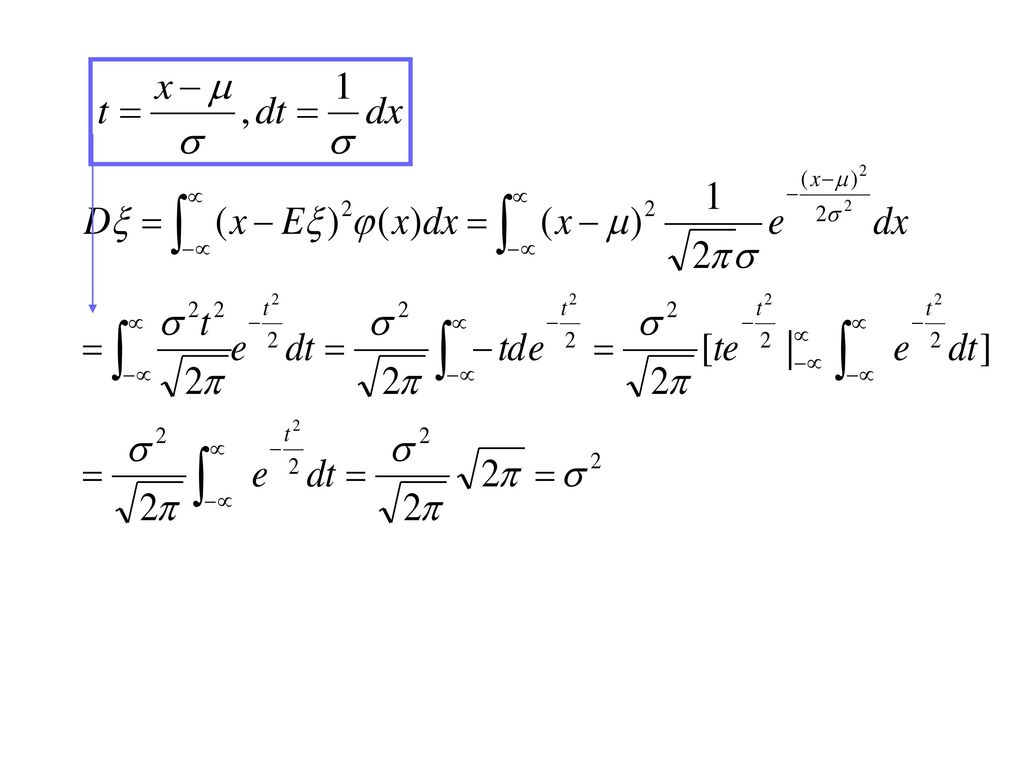
 3. 二项分布 4. Poisson 分布 2. 超几何分布 n →∞ , N→∞ , (x = 0, 1, 2, , n) (x.>")









2 +(y-b)2=r2 x2+y2+Dx+Ey+F=0 Ax2+Bxy+Cy2+Dx+Ey+ F=0.>")








