Download presentation
Presentation is loading. Please wait.

1
第六章 杂凑函数 聂旭云

2
Message Authentication
认证:消息的接收者对消息进行的验证 真实性:消息确实来自于其真正的发送者,而非假冒; 完整性:消息的内容没有被篡改。 是一个证实收到的消息来自可信的源点且未被篡改的过程。它也可以验证消息的顺序和及时性

3
消息认证概念 三元组(K,T,V) 密钥生成算法K 标签算法T 验证算法V 攻击者 信宿 信源 认证编码器 认证译码器 安全信道 密钥源
 密钥生成算法K 标签算法T 验证算法V 攻击者 信宿 信源 认证编码器 认证译码器 安全信道 密钥源")
4
认证函数 鉴别编码器和鉴别译码器可抽象为认证函数 认证函数 产生一个鉴别标识(Authentication Identification)
给出合理的认证协议(Authentication Protocol) 接收者完成消息的鉴别(Authentication)
 接收者完成消息的鉴别(Authentication)")
5
认证函数分类 认证的函数分为三类: 消息加密函数(Message encryption)
用完整信息的密文作为对信息的认证。 消息认证码MAC (Message Authentication Code) 是对信源消息的一个编码函数。 散列函数 (Hash Function) 是一个公开的函数,它将任意长的信息映射成一个固定长度的信息。
 是对信源消息的一个编码函数。 散列函数 (Hash Function) 是一个公开的函数,它将任意长的信息映射成一个固定长度的信息。")
6
认证函数:Hash函数 Hash Function 哈希函数、摘要函数 输入:任意长度的消息报文 M 输出:一个固定长度的散列码值 H(M)
是报文中所有比特的函数值 单向函数

7
认证函数:Hash函数(续) 根据是否使用密钥
带秘密密钥的Hash函数:消息的散列值由只有通信双方知道的秘密密钥K来控制。此时,散列值称作MAC。 不带秘密密钥的Hash函数:消息的散列值的产生无需使用密钥。此时,散列值称作MDC。

8
认证函数:Hash函数(续) 哈希函数的基本用法(a) K M M M || E D H K H(M) EK(M|H(M)) H M 比较
Bob Alice 提供认证 提供保密

9
认证函数:Hash函数(续) 哈希函数的基本用法(b) H M M || 比较 D H E Bob Alice EK(H(M)) K K
提供认证

10
认证函数:Hash函数(续) 哈希函数的基本用法(c) H M M || 比较 E H D Bob Alice DK’b(H(M)) Kb
提供认证

11
认证函数:Hash函数(续) 哈希函数的基本用法(d) K M M M D || E D K H DK’b(H(M)) Bob
Ek(M|DK’b(H(M)) Alice K’b H M 比较 E 提供认证 提供保密 Kb
) Alice. K’b. H. M. 比较. E. 提供认证. 提供保密. Kb.")
12
认证函数:Hash函数(续) 哈希函数的基本用法(e) S || H M || M 比较 || H S H(M||S) Alice Bob
提供认证

13
认证函数:Hash函数(续) 哈希函数的基本用法(f) K M M M || E D || H K S S H(M||S)
EK(M||H(M||S) || H M 比较 Bob Alice 提供认证 提供保密
 || H. M. 比较. Bob. Alice. 提供认证. 提供保密.")
14
杂凑函数应满足的条件 函数的输入可以是任意长 函数的输出是固定长 已知x,求H(x)较为容易
已知h,求H(x)=h的在计算上不可行,即单向杂凑函数. 已知x,找出y(y≠x)使得H(y)=H(x)在计算上是不可行的。满足这一性质,则称其为弱单向杂凑函数。 找出任意两个不同的x,y,是H(x)=H(y)在计算上不可行,满足这一性质,称为强单向杂凑函数
=h的在计算上不可行,即单向杂凑函数. 已知x,找出y(y≠x)使得H(y)=H(x)在计算上是不可行的。满足这一性质,则称其为弱单向杂凑函数。 找出任意两个不同的x,y,是H(x)=H(y)在计算上不可行,满足这一性质,称为强单向杂凑函数.")
15
生日攻击 (第I类生日攻击)H有n个输出,H(x)是一个特定的输出,如果对H随机取k个输入,至少有一个y使H(y)=H(x)的概率为0.5时,k有多大? H(y)=H(x)的概率为1/n,不等的概率为1-1/n.取k个值都不等的为[1-1/n]k.至少有一个等的概率为1- [1-1/n]k,近似等于k/n。所以概率为0.5,k为n/2。
=H(x)的概率为1/n,不等的概率为1-1/n.取k个值都不等的为[1-1/n]k.至少有一个等的概率为1- [1-1/n]k,近似等于k/n。所以概率为0.5,k为n/2。")
16
生日悖论 在一个会场参加会议的人中,问使参会人员中至少 有两个同日生的概率超过0.5的参会人数仅为23人。 t个人都不同时生日概率为
,因此,至少有两人于同日生的概率为 解之,当t23时,p>0.5。对于n比特杂凑值的 生日攻击,由上式可计算出,当进行2n/2次的选择 明文攻击下成功的概率将超过0.63。

17
迭代型杂凑函数的一般结构 f f f 明文M被分为L个分组 Y0,Y1,…,YL-1 b:明文分组长度 n:输出hash长度
CV:各级输出,最后 一个输出值是hash值 Y0 Y1 YL-1 b b b f f f CVL n n n n n CVL-1 IV=CV0 CV1 无碰撞压缩函数f是设计的关键

18
hash函数通用模型 由Merkle于1989年提出 几乎被所有hash算法采用 具体做法: 把原始消息M分成一些固定长度的块Yi
最后一块padding并使其包含消息M的长度 设定初始值CV0 压缩函数f, CVi=f(CVi-1,Yi-1) 最后一个CVi为hash值
 最后一个CVi为hash值.")
19
算法描述 MD4是MD5杂凑算法的前身,由Ron Rivest于1990年10月作为RFC提出,1992年4月公布的MD4的改进(RFC 1320,1321)称为MD5。 MD5
称为MD5。 MD5")
20
MD5产生报文摘要的过程 报文 K bits L512 bits=N 32bits 100…0 Y0 Y1 Yq YL-1 HMD5
报文长度(K mod 264) 100…0 Y0 512 bits Y1 Yq YL-1 HMD5 IV 128 CV1 CVq CVL-1 512 填充 (1 to 512 bits) 128-bit 摘要
 100…0. Y bits. Y1. Yq. YL-1. HMD5. IV CV1. CVq. CVL 填充. (1 to 512 bits) 128-bit. 摘要.")
21
③ 对MD缓冲区初始化算法使用128比特长的缓冲区以存储中间结果和最终杂凑值,缓冲区可表示为4个32比特长的寄存器(A,B,C,D),每个寄存器都以littleendian方式存储数据,其初值取为(以存储方式)A= ,B=89ABCDEF, C=FEDCBA98,D= ,实际上为 ,EFCDAB89,98BADCFE, 。
,每个寄存器都以littleendian方式存储数据,其初值取为(以存储方式)A= ,B=89ABCDEF, C=FEDCBA98,D= ,实际上为 ,EFCDAB89,98BADCFE, 。")
22
图6.6 MD5的分组处理框图

23
图6.6 MD5的分组处理框图

24
步骤③到步骤⑤的处理过程可总结如下: CV0=IV; CVq+1=CVq+RFI[Yq,RFH[Yq,RFG[Yq,RFF[Yq,CVq]]]] MD=CVL 其中IV是步骤③所取的缓冲区ABCD的初值,Yq是消息的第q个512比特长的分组,L是消息经过步骤①和步骤②处理后的分组数,CVq为处理消息的第q个分组时输入的链接变量(即前一个压缩函数的输出),RFx为使用基本逻辑函数x的轮函数,+为对应字的模232加法,MD为最终的杂凑值。
![步骤③到步骤⑤的处理过程可总结如下: CV0=IV; CVq+1=CVq+RFI[Yq,RFH[Yq,RFG[Yq,RFF[Yq,CVq]]]] MD=CVL.](http://slidesplayer.com/slide/11173322/60/images/24/%E6%AD%A5%E9%AA%A4%E2%91%A2%E5%88%B0%E6%AD%A5%E9%AA%A4%E2%91%A4%E7%9A%84%E5%A4%84%E7%90%86%E8%BF%87%E7%A8%8B%E5%8F%AF%E6%80%BB%E7%BB%93%E5%A6%82%E4%B8%8B%EF%BC%9A+CV0%3DIV%3B+CVq%2B1%3DCVq%2BRFI%5BYq%2CRFH%5BYq%2CRFG%5BYq%2CRFF%5BYq%2CCVq%5D%5D%5D%5D+MD%3DCVL..jpg "其中IV是步骤③所取的缓冲区ABCD的初值,Yq是消息的第q个512比特长的分组,L是消息经过步骤①和步骤②处理后的分组数,CVq为处理消息的第q个分组时输入的链接变量(即前一个压缩函数的输出),RFx为使用基本逻辑函数x的轮函数,+为对应字的模232加法,MD为最终的杂凑值。")
25
a←b+CLSs(a+g(b,c,d)+X[k]+T[I])
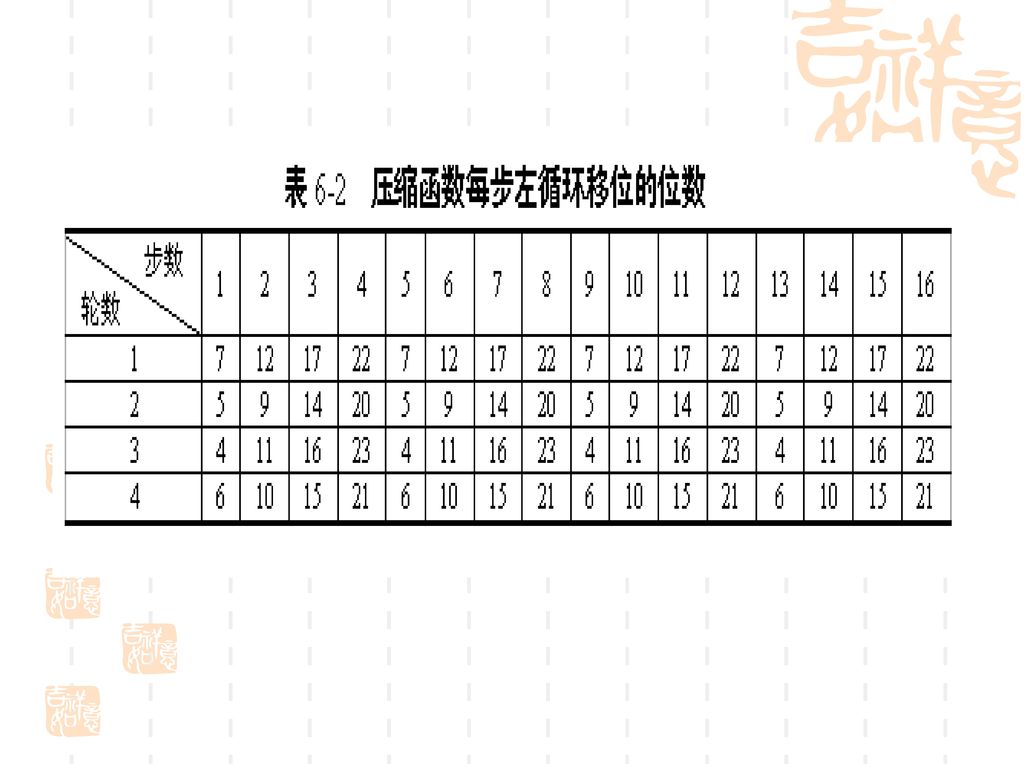
MD5的压缩函数 压缩函数HMD5中有4轮处理过程,每轮又对缓冲区ABCD进行16步迭代运算,每一步的运算形式为(见图6.7) a←b+CLSs(a+g(b,c,d)+X[k]+T[I]) 其中a、b、c、d为缓冲区的4个字,运算完成后再右循环一个字,即得这一步迭代的输出。g是基本逻辑函数F、G 、H、I之一。CLSs是左循环移s位,s的取值由表6.2给出。(见176页表6.2)
![a←b+CLSs(a+g(b,c,d)+X[k]+T[I])](http://slidesplayer.com/slide/11173322/60/images/25/a%E2%86%90b%2BCLSs%28a%2Bg%28b%2Cc%2Cd%29%2BX%5Bk%5D%2BT%5BI%5D%29.jpg "MD5的压缩函数. 压缩函数HMD5中有4轮处理过程,每轮又对缓冲区ABCD进行16步迭代运算,每一步的运算形式为(见图6.7) a←b+CLSs(a+g(b,c,d)+X[k]+T[I]) 其中a、b、c、d为缓冲区的4个字,运算完成后再右循环一个字,即得这一步迭代的输出。g是基本逻辑函数F、G 、H、I之一。CLSs是左循环移s位,s的取值由表6.2给出。(见176页表6.2)")
26
图6.7 压缩函数中的一步迭代示意图

30
T[i]为表T中的第i个字,+为模232加法。X[k]=M[q×16+k],即消息第q个分组中的第k个字(k=1,…,16)。4轮处理过程中,每轮以不同的次序使用16个字,其中在第1轮以字的初始次序使用。第2轮到第4轮分别对字的次序i做置换后得到一个新次序,然后以新次序使用16个字。3个置换分别为 ρ2(i)=(1+5i) mod 16 ρ3(i)=(5+3i) mod 16 ρ4(i)=7i mod 16
![T[i]为表T中的第i个字,+为模232加法。X[k]=M[q×16+k],即消息第q个分组中的第k个字(k=1,…,16)。4轮处理过程中,每轮以不同的次序使用16个字,其中在第1轮以字的初始次序使用。第2轮到第4轮分别对字的次序i做置换后得到一个新次序,然后以新次序使用16个字。3个置换分别为](http://slidesplayer.com/slide/11173322/60/images/30/T%5Bi%5D%E4%B8%BA%E8%A1%A8T%E4%B8%AD%E7%9A%84%E7%AC%ACi%E4%B8%AA%E5%AD%97%EF%BC%8C%2B%E4%B8%BA%E6%A8%A1232%E5%8A%A0%E6%B3%95%E3%80%82X%5Bk%5D%3DM%5Bq%C3%9716%2Bk%5D%EF%BC%8C%E5%8D%B3%E6%B6%88%E6%81%AF%E7%AC%ACq%E4%B8%AA%E5%88%86%E7%BB%84%E4%B8%AD%E7%9A%84%E7%AC%ACk%E4%B8%AA%E5%AD%97%EF%BC%88k%3D1%2C%E2%80%A6%2C16%EF%BC%89%E3%80%824%E8%BD%AE%E5%A4%84%E7%90%86%E8%BF%87%E7%A8%8B%E4%B8%AD%EF%BC%8C%E6%AF%8F%E8%BD%AE%E4%BB%A5%E4%B8%8D%E5%90%8C%E7%9A%84%E6%AC%A1%E5%BA%8F%E4%BD%BF%E7%94%A816%E4%B8%AA%E5%AD%97%EF%BC%8C%E5%85%B6%E4%B8%AD%E5%9C%A8%E7%AC%AC1%E8%BD%AE%E4%BB%A5%E5%AD%97%E7%9A%84%E5%88%9D%E5%A7%8B%E6%AC%A1%E5%BA%8F%E4%BD%BF%E7%94%A8%E3%80%82%E7%AC%AC2%E8%BD%AE%E5%88%B0%E7%AC%AC4%E8%BD%AE%E5%88%86%E5%88%AB%E5%AF%B9%E5%AD%97%E7%9A%84%E6%AC%A1%E5%BA%8Fi%E5%81%9A%E7%BD%AE%E6%8D%A2%E5%90%8E%E5%BE%97%E5%88%B0%E4%B8%80%E4%B8%AA%E6%96%B0%E6%AC%A1%E5%BA%8F%EF%BC%8C%E7%84%B6%E5%90%8E%E4%BB%A5%E6%96%B0%E6%AC%A1%E5%BA%8F%E4%BD%BF%E7%94%A816%E4%B8%AA%E5%AD%97%E3%80%823%E4%B8%AA%E7%BD%AE%E6%8D%A2%E5%88%86%E5%88%AB%E4%B8%BA.jpg "ρ2(i)=(1+5i) mod 16. ρ3(i)=(5+3i) mod 16. ρ4(i)=7i mod 16.")
33
MD5的安全性

34
安全杂凑算法 安全杂凑算法SHA(Secure Hash Algorithm)由美国NIST设计,于1993年作为联邦信息处理标准(FIPS PUB 180)公布。SHA-0是SHA的早期版本,SHA-0被公布后,NIST很快就发现了它的缺陷,修改后的版本称为SHA-1,简称为SHA。SHA是基于MD4算法,其结构与MD4非常类似。 SHA1
由美国NIST设计,于1993年作为联邦信息处理标准(FIPS PUB 180)公布。SHA-0是SHA的早期版本,SHA-0被公布后,NIST很快就发现了它的缺陷,修改后的版本称为SHA-1,简称为SHA。SHA是基于MD4算法,其结构与MD4非常类似。 SHA1.")
35
算法描述 算法的输入为小于264比特长的任意消息,分为512比特长的分组,输出为160比特长的消息摘要。算法的框图与图6.5一样,但杂凑值的长度和链接变量的长度为160比特。

36
算法的处理过程有以下几步: ① 对消息填充与MD5的步骤①完全相同。 ② 附加消息的长度与MD5的步骤②类似,不同之处在于以big-endian方式表示填充前消息的长度。即步骤①留出的64比特当作64比特长的无符号整数。 ③ 对MD缓冲区初始化算法使用160比特长的缓冲区存储中间结果和最终杂凑值,缓冲区可表示为5个32比特长的寄存器(A, B, C, D, E),每个寄存器都以big-endian方式存储数据,其初始值分别为A= ,B=EFCDAB89,C=98BADCFB,D= ,E=C3D2E1F0。
,每个寄存器都以big-endian方式存储数据,其初始值分别为A= ,B=EFCDAB89,C=98BADCFB,D= ,E=C3D2E1F0。")
37
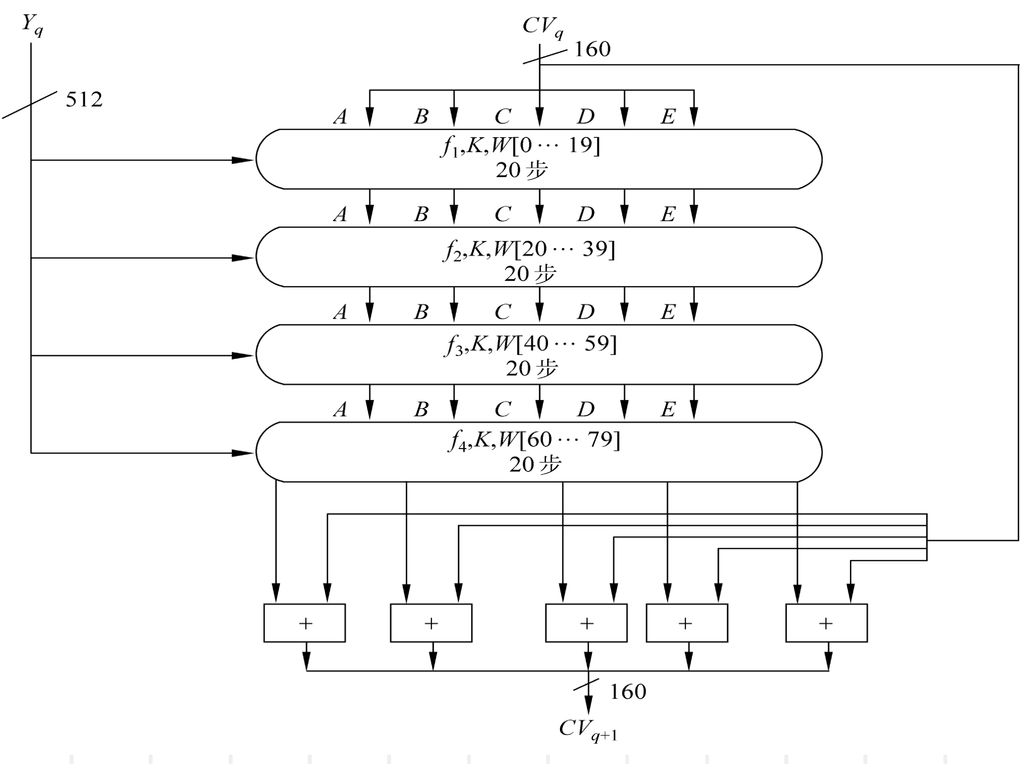
④ 以分组为单位对消息进行处理每一分组Yq都经一压缩函数处理,压缩函数由4轮处理过程(如图6
④ 以分组为单位对消息进行处理每一分组Yq都经一压缩函数处理,压缩函数由4轮处理过程(如图6.8所示)构成,每一轮又由20步迭代组成。4轮处理过程结构一样,但所用的基本逻辑函数不同,分别表示为f1,f2,f3,f4。每轮的输入为当前处理的消息分组Yq和缓冲区的当前值A,B,C,D,E,输出仍放在缓冲区以替代A,B,C,D,E的旧值,每轮处理过程还需加上一个加法常量Kt,其中0≤t≤79表示迭代的步数。80个常量中实际上只有4个不同取值,如表6.5所示,其中 为x的整数部分。(见178页表6.5)
构成,每一轮又由20步迭代组成。4轮处理过程结构一样,但所用的基本逻辑函数不同,分别表示为f1,f2,f3,f4。每轮的输入为当前处理的消息分组Yq和缓冲区的当前值A,B,C,D,E,输出仍放在缓冲区以替代A,B,C,D,E的旧值,每轮处理过程还需加上一个加法常量Kt,其中0≤t≤79表示迭代的步数。80个常量中实际上只有4个不同取值,如表6.5所示,其中 为x的整数部分。(见178页表6.5)")
39
第4轮的输出(即第80步迭代的输出)再与第1轮的输入CVq相加,以产生CVq+1,其中加法是缓冲区5个字中的每一个字与CVq中相应的字模232相加。
⑤ 输出消息的L个分组都被处理完后,最后一个分组的输出即为160比特的消息摘要。

40
步骤③到步骤⑤的处理过程可总结如下: CV0=IV; CVq+1=SUM32(CVq,ABCDEq); MD=CVL 其中IV是步骤③定义的缓冲区ABCDE的初值,ABCDEq是第q个消息分组经最后一轮处理过程处理后的输出,L是消息(包括填充位和长度字段)的分组数,SUM32是对应字的模232加法,MD为最终的摘要值。
的分组数,SUM32是对应字的模232加法,MD为最终的摘要值。")
41
SHA的压缩函数 如上所述,SHA的压缩函数由4轮处理过程组成,每轮处理过程又由对缓冲区ABCDE的20步迭代运算组成,每一步迭代运算的形式为(见图6.9) 其中A,B,C,D,E为缓冲区的5个字,t是迭代的步数(0≤t≤79),ft(B,C,D)是第t步迭代使用的基本逻辑函数,CLSs为左循环移s位,Wt是由当前512比特长的分组导出的一个32比特长的字(导出方式见下面),Kt是加法常量,+是模232加法。
,ft(B,C,D)是第t步迭代使用的基本逻辑函数,CLSs为左循环移s位,Wt是由当前512比特长的分组导出的一个32比特长的字(导出方式见下面),Kt是加法常量,+是模232加法。")
42
图6.9 SHA的压缩函数中一步迭代示意图

43
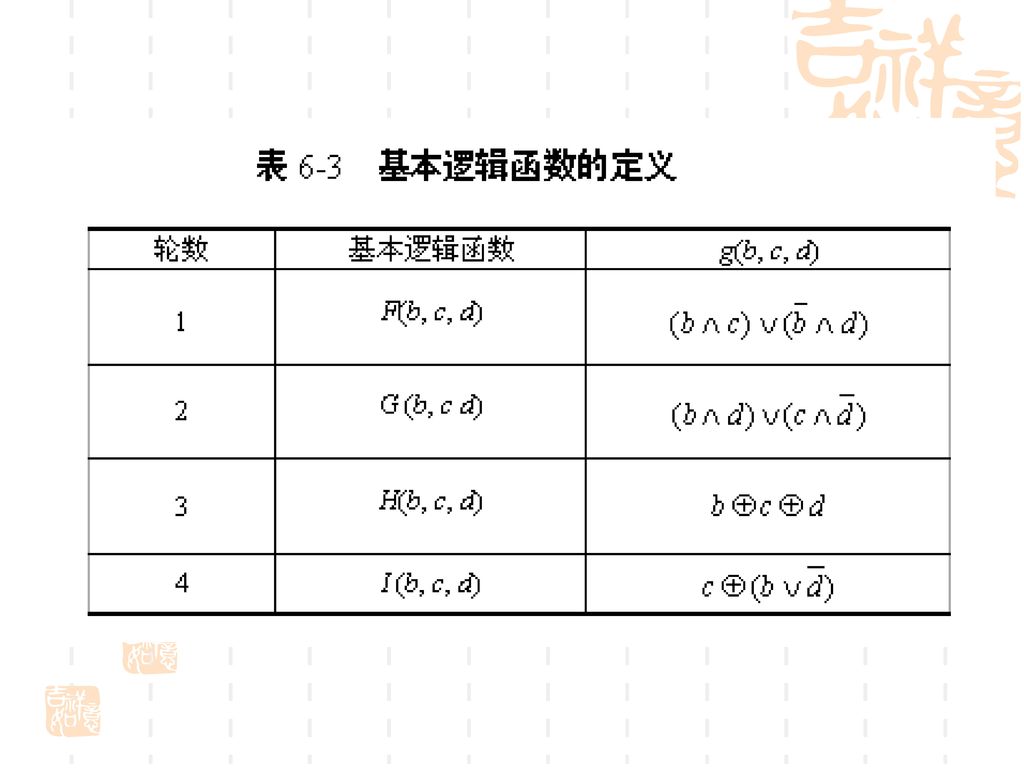
基本逻辑函数的输入为3个32比特的字,输出是一个32比特的字,其中的运算为逐比特逻辑运算,即输出的第n个比特是3个输入的相应比特的函数。函数的定义如表6.6。表中∧,∨, -,分别是与、或、非、异或4个逻辑运算,函数的真值表如表6.7所示。(见179页表6.6,180页表6.7)
")
46
下面说明如何由当前的输入分组(512比特长)导出Wt(32比特长)。前16个值(即W0,W1,…,W15)直接取为输入分组的16个相应的字,其余值(即W16,W17,…,W79)取为
见图6.10。与MD5比较,MD5直接用一个消息分组的16个字作为每步迭代的输入,而SHA则将输入分组的16个字扩展成80个字以供压缩函数使用,从而使得寻找具有相同压缩值的不同的消息分组更为困难。

47
图6.10 SHA分组处理所需的80个字的产生过程

48
SHA与MD5的比较 抗穷搜索能力 寻找指定hash值, SHA:O(2160),MD5:O(2128)
抗密码分析攻击的强度 SHA似乎高于MD5 速度 SHA较MD5慢 简捷与紧致性 描述都比较简单,都不需要大的程序和代换表

49
(Chaum–Van, Heijst–Pfitzmann散列算法)
基于离散对数问题的散列函数算法 (Chaum–Van, Heijst–Pfitzmann散列算法) 设P是一个大素数,且q=(p-1)/2也为素数,取定FP(P 元有限域)中的一个本原元α,给定一个保密的指数λ, (λ,p–1)=1,于是β=αλ也为FP中的本原元。值 λ=logαβ不公开,计算这个对数值是计算上难处理的。
 设P是一个大素数,且q=(p-1)/2也为素数,取定FP(P. 元有限域)中的一个本原元α,给定一个保密的指数λ, (λ,p–1)=1,于是β=αλ也为FP中的本原元。值. λ=logαβ不公开,计算这个对数值是计算上难处理的。")
50
散列算法 h:{0,1,…,q-1}{0,1,…,q-1}Fp* 定义为 h(x1,x2)=αx1βx2(mod p) 下面要证明,散列算法h是强无碰撞的!相当于证明: 定理:若上述算法h的碰撞算法是可行的,那么计算离散 对数logαβ也是可行的。 证明: 假设我们给了一个碰撞h (x1, x2)=h (x3, x4)其中 (x1,x2)≠(x3, x4),则有下列同余式 αx1βx2≡αx3βx4(modp)
=h (x3, x4)其中. (x1,x2)≠(x3, x4),则有下列同余式. αx1βx2≡αx3βx4(modp)")
51
也即,αx1-x3βx4-x2(mod p) 记 gcd(x4-x2,p-1)=d,易见d∈{1,2,q,p-1} ,原因是p–1=2q. 1°若d=1,此时可设 y= (x4–x2)–1(mod p–1) 有 β β(x4-x2)y(mod p) α(x1-x3)y(modp) 于是,计算出离散对数 logαβ=(x1–x3)y =(x1–x3)(x4–x2)–1 (mod p–1) 2°若d=2: 由p-1=2q, q为奇素数,必有gcd (x4-x2, q)=1, 设 y= (x4-x2)-1 (mod q) 于是 (x4-x2)* y≡1 (mod q)
y(mod p) α(x1-x3)y(modp) 于是,计算出离散对数. logαβ=(x1–x3)y. =(x1–x3)(x4–x2)–1 (mod p–1) 2°若d=2: 由p-1=2q, q为奇素数,必有gcd (x4-x2, q)=1, 设 y= (x4-x2)-1 (mod q) 于是 (x4-x2)* y≡1 (mod q)")
52
也就是存在整数k使得(x4-x2)*y=k*q+1
所以β(x4-x2)*yβk*q+1(mod p) (-1)kβ(mod p) (因为β(p-1)/2 -1(mod p)) β(modp) 这样 α(x1-x2)y β(x4-x2)*y(modp) ±β(mod p) (i) 若α(x1-x3)y β(mod p) 则logαβ=(x1-x3)y (mod p-1) (ii)若α(x1-x3)y β(mod p) α(p-1)/2*β(mod p) ==>α(x1-x3)y*α(p-1)/2 β(mod p) 所以,logαβ=(x1-x3)y+(p-1)/2(mod p-1) 可见,(i)、(ii)都是易计算的。
*yβk*q+1(mod p) (-1)kβ(mod p) (因为β(p-1)/2 -1(mod p)) β(modp) 这样 α(x1-x2)y β(x4-x2)*y(modp) ±β(mod p) (i) 若α(x1-x3)y β(mod p) 则logαβ=(x1-x3)y (mod p-1) (ii)若α(x1-x3)y β(mod p) α(p-1)/2*β(mod p) ==>α(x1-x3)y*α(p-1)/2 β(mod p) 所以,logαβ=(x1-x3)y+(p-1)/2(mod p-1) 可见,(i)、(ii)都是易计算的。")
53
3°若d=q:因为0≤x2≤q-1,0≤x4≤q-1 有结果,gcd(x4-x2, p-1)=q是不可能的。 4°若d=p-1,此时仅当x4=x2时发生,此时有 αx1βx2αx3βx2(mod p) αx1 αx3(mod p)=>x1=x3 于是,(x1,x2)=(x3,x4)与假设矛盾,此种情况不可 能发生。 综上知,如果计算FP中离散对数logαβ是不可行的, 那么我们推出该算法h是强无碰撞的。
=>x1=x3. 于是,(x1,x2)=(x3,x4)与假设矛盾,此种情况不可. 能发生。 综上知,如果计算FP中离散对数logαβ是不可行的, 那么我们推出该算法h是强无碰撞的。")
54
HMAC算法

55
HMAC的设计目标 Hash函数不使用密钥,不能直接用于MAC HMAC要求 可不经修改使用现有hash函数
其中镶嵌的hash函数可易于替换为更快和更安全的hash函数 保持镶嵌的hash函数的最初性能,不因适用于HAMC而使其性能降低 以简单方式使用和处理密钥 在对镶嵌的hash函数合理假设的基础上,易于分析 HMAC用于认证时的密码强度

56
算法描述 Ipad:b/8个 Opad:b/8个 K+:左面经填充0后的K.K+的长度为b比特

57
HMAC的安全性 取决于hash函数的安全性
证明了算法强度和嵌入的hash函数强度的确切关系,即证明了对HMAC攻击等价于对内嵌hash函数的下述两种攻击 攻击者能够计算压缩函数的一个输出,即使IV是秘密的和随机的 攻击者能够找出hash函数的碰撞,即使IV是随机的和秘密的。

Similar presentations





 一上一下二上二下三上 校訂必修校訂必修 英文 I 中文閱讀與寫作 I 計算機概論 I 體育 服務與學習教育 I 英文 II 中文閱讀與寫作 II 計算機概論 II 體育 服務與學習教育 II.>")

















>")
