Download presentation
Presentation is loading. Please wait.

1
變異數分析 Analysis of Variance
量化研究法二 統計原理與分析技術 第9章 變異數分析 Analysis of Variance

2
基本定義 平均數考驗方法 變異數分析是一套應用於探討平均數差異的統計方法
當研究者所欲分析的資料是不同樣本的平均數,也就是探討類別變項對於連續變項的影響,平均數的差異成為主要分析重點 超過兩個以上的平均數的考驗,其原理是運用F考驗來檢驗平均數間的變異量是否顯著的高於隨機變異量,又稱為變異數分析

3
變異數分析的基本原理 平均數差異檢定:基本原理是計算兩個數值(平均數)之間的差異,如果差異夠大,大於統計上的隨機差異,便可能獲得顯著的結果,拒絕虛無假設、接受對立假設。平均數差異與隨機差異的比值,決定了統計的顯著與否。 平均數變異分析:超過兩個平均數的考驗,其原理仍是以平均數間的變異數(組間變異)除以隨機變異得到的比值(F值),來取代平均數差異與隨機差異的比值(t或Z值),而能夠同時檢驗三個平均數的差異情形 當F值越大,表示研究者關心的組平均數的分散情形較誤差變異來得大,若大於研究者設定的臨界值,研究者即可獲得拒絕虛無假設、接受對立假設的結論。
除以隨機變異得到的比值(F值),來取代平均數差異與隨機差異的比值(t或Z值),而能夠同時檢驗三個平均數的差異情形. 當F值越大,表示研究者關心的組平均數的分散情形較誤差變異來得大,若大於研究者設定的臨界值,研究者即可獲得拒絕虛無假設、接受對立假設的結論。")
4
單因子變異數分析資料實例 可以計算出四個平均數,即三個組平均數與一個總平均數(grand mean)。變異數分析檢驗的就是這三個組平均數是否具有顯著的差異 研究假設為:高、中、低三種不同運動量的受測者,其睡眠時間不同

5
SSwithin and SSbetween

6
實驗、族系與比較錯誤率 實驗誤差率(experiment-wise error rate;EWE)
統計的決策,是以整個實驗的型I錯誤率維持一定(例如.05)的情況下,導出各次決策所犯的型I錯誤率為何 族系誤差率(familywise error rate; FWE) 將每一個被檢驗的效果(例如主要效果、交互效果)的統計考驗的型I錯誤率維持一定,導出各次決策所犯的型I錯誤率 比較錯誤率(comparison-wise error rate) 將型I錯誤率設定於每一次的統計考驗,均有相同的犯第一類型錯誤的機率 實驗與族系誤差率 為了維持整體的α水準為.05,必須降低各次考驗的α水準
的情況下,導出各次決策所犯的型I錯誤率為何. 族系誤差率(familywise error rate; FWE) 將每一個被檢驗的效果(例如主要效果、交互效果)的統計考驗的型I錯誤率維持一定,導出各次決策所犯的型I錯誤率. 比較錯誤率(comparison-wise error rate) 將型I錯誤率設定於每一次的統計考驗,均有相同的犯第一類型錯誤的機率. 實驗與族系誤差率. 為了維持整體的α水準為.05,必須降低各次考驗的α水準.")
7
固定效果模式與隨機效果模式 固定效果模式(fixed effect model)。當一個研究的自變項的水準個數(k組),包括了該變項所有可能的水準數(K組),也就是樣本的水準數等於母體的水準數(K=k) 。 例如比較大學四個年級學生的曠課次數,此時自變項為年級,具有四個水準,而母體亦為四個年級。 隨機效果模式(random effect model)。研究所取用的自變項,只包含特定的一些水準,而並非包括所有可能的類別,即樣本的水準數小於母體的水準數(K>k) 。 例如教育學者比較不同地區的學校教學方法的成效有所不同,因此隨機選取幾個地區的一些學校共四所(自變項),該研究所關心的四個水準,可以說是隨機自教學方法的母體中,隨機取用得來的。 隨機模式所得到的結論,在推論上需考量如何自所選取的水準去推論自變項的所有水準。多使用重複量數設計來分析
。研究所取用的自變項,只包含特定的一些水準,而並非包括所有可能的類別,即樣本的水準數小於母體的水準數(K>k) 。 例如教育學者比較不同地區的學校教學方法的成效有所不同,因此隨機選取幾個地區的一些學校共四所(自變項),該研究所關心的四個水準,可以說是隨機自教學方法的母體中,隨機取用得來的。 隨機模式所得到的結論,在推論上需考量如何自所選取的水準去推論自變項的所有水準。多使用重複量數設計來分析.")
8
一般線性模式 單因子變異數分析的通式 為總平均數(grand mean) j表獨變項效果 ε為誤差效果 全體觀測值的平均值
表示母體中的任何一位樣本的依變項初始狀態是相同的。 j表獨變項效果 獨變項的第j組對於依變項的效果,強度為j-,(第j組的離均差) 對於第j組當中每一位受試者,j為一常數,各組離均差總和為0 ε為誤差效果 為常態隨機變數,記為N(0, )。 同一個組別下的每一位受試者在Y變項上產生差異的隨機效果
 對於第j組當中每一位受試者,j為一常數,各組離均差總和為0. ε為誤差效果. 為常態隨機變數,記為N(0, )。 同一個組別下的每一位受試者在Y變項上產生差異的隨機效果.")
9
ANOVA的假設考驗

10
變異量拆解 SStotal=SSb+SSw 各離均差平方和平均化後,得到均方和(MS),即為變異數的概念
SSb「導因於獨變項影響的變異」 (組間離均差平方和,sum of squares between groups) SSw「導因於獨變項以外的變異」(隨機變異)(組內離均差平方和,sum of squares within groups) 各離均差平方和平均化後,得到均方和(MS),即為變異數的概念
 SSw「導因於獨變項以外的變異」(隨機變異)(組內離均差平方和,sum of squares within groups) 各離均差平方和平均化後,得到均方和(MS),即為變異數的概念.")
11
F ratio 兩個變異數的比值稱為F統計量 F統計量的機率分配為F分配 F值越大,表示研究者關心的組平均數的分散情形較誤差變異來得大
若大於臨界值,研究者即可獲得拒絕H0的結論

12
變異數分析摘要表 變異數分析的結果可以整理成摘要表形式

13
統計顯著性(statistical significance)
關聯強度分析 統計顯著性(statistical significance) 基於機率理論的觀點,說明獨變項效果相對於隨機變化的一種統計意義的檢驗 例如利用F考驗來決定獨變項效果的統計意義 實務顯著性(practical significance) 反應獨變項效果在真實世界的強度意義 常用ω2 、 η2、f量數表示 也稱為臨床顯著性(clinical significance)
 基於機率理論的觀點,說明獨變項效果相對於隨機變化的一種統計意義的檢驗. 例如利用F考驗來決定獨變項效果的統計意義. 實務顯著性(practical significance) 反應獨變項效果在真實世界的強度意義. 常用ω2 、 η2、f量數表示. 也稱為臨床顯著性(clinical significance)")
14
omega squared)量數 類似於迴歸分析的R2 定義式 ω2量數 樣本估計式: 為組間變異與總變異的比值
表示依變項變異量能被獨變項解釋的百分比 亦即獨變項與依變項的關聯強度 樣本估計式:

15
ω2量數的特性 Cohen(1988)建議下列的判斷準則 數值介於0到1之間,越接近1表示關聯越強
ω2量數值分佈為以.05到.06為眾數的正偏態分配,達到.1以上者,即屬於高強度的獨變項效果 一般期刊上所發表的實證論文的,也僅多在.06左右 Cohen(1988)建議下列的判斷準則
建議下列的判斷準則.")
16
η2 (eta square)量數 η2是迴歸分析當中的R2,除了作為X對Y解釋強度的指標外,經常也被視為效果量的指標
樣本數小時,為母體的偏估計數,需以下式進行調整,以得到不偏估計數(Wherry, 1931) 淨η2 (partial η2 )量數 扣除了其他效果項的影響後的關聯強度量數
 淨η2 (partial η2 )量數. 扣除了其他效果項的影響後的關聯強度量數.")
17
效果量係數 效果量(size of effect)係數 D量數 f量數 用來衡量獨變項強度的統計量。 最簡單的效果量 指平均數之間的差異程度
平均數間差異越大,表示獨變項的強度越強 f量數 適用於當平均數數目大於2時

18
檢定力分析(power analysis)
一個研究可以正確拒絕錯誤虛無假設的能力 以1-β來表示 檢定力分析(power analysis) Power反應了一個研究的實務顯著性,太低的檢定力表示研究的數據可參考價值低 對於檢定Power進行分析可檢視統計考驗的敏銳度,據以推算合理的樣本規模 檢定力分析牽涉中央F分配與非中央F分配的概念
 Power反應了一個研究的實務顯著性,太低的檢定力表示研究的數據可參考價值低. 對於檢定Power進行分析可檢視統計考驗的敏銳度,據以推算合理的樣本規模. 檢定力分析牽涉中央F分配與非中央F分配的概念.")
19
中央性與非中央性F分配 中央性F分配(central F distribution)
當虛無假設(H0)為真時,F考驗值呈現F分配 中央F分配的機率變化受到兩個參數的影響 分子自由度(v1) 分母自由度(v2) 非中央性F分配(non-central F distribution) 當虛無假設為偽、對立假設(H1)為真時,表示中央F分配失效,另外有一個H1分配存在,此時Power的計算需以非中央性F分配的概念來處理 非中央性F分配的機率密度變化受到三個參數的影響 非中央性參數(non-centrality parameter,以表示),反應虛無假設為偽的程度
為真時,F考驗值呈現F分配. 中央F分配的機率變化受到兩個參數的影響. 分子自由度(v1) 分母自由度(v2) 非中央性F分配(non-central F distribution) 當虛無假設為偽、對立假設(H1)為真時,表示中央F分配失效,另外有一個H1分配存在,此時Power的計算需以非中央性F分配的概念來處理. 非中央性F分配的機率密度變化受到三個參數的影響. 非中央性參數(non-centrality parameter,以表示),反應虛無假設為偽的程度.")
20
檢定力的計算 Tang(1938)提出
提出")
21
樣本規模的決定 檢定力算則 d量數試探法 利用統計檢定力、顯著水準、 以及獨變項效應量 各項資料來推估N
但在實驗進行之前,誤差變異量( )與獨變項效應量是不得而知,因此多建議以前人的研究數據,或先進行一個前導研究來獲得這些數據,才能利用檢定力算則來推估樣本數 d量數試探法 適用於在誤差變異數與獨變項效應量未知的情況下
與獨變項效應量是不得而知,因此多建議以前人的研究數據,或先進行一個前導研究來獲得這些數據,才能利用檢定力算則來推估樣本數. d量數試探法. 適用於在誤差變異數與獨變項效應量未知的情況下.")
22
整體考驗與多重比較 整體考驗(overall test)
當變異數分析F考驗值達顯著水準,即推翻了平均數相等的虛無假設,亦即表示至少有兩組平均數之間有顯著差異存在。多個平均數整體效果(overall effect)達顯著水準 當整體考驗顯著後必須檢驗哪幾個平均數之間顯著有所不同,即進行多重比較(multiple comparison)來檢驗。 多重比較在進行F考驗之前進行,稱為事前比較(priori comparisons),在獲得顯著的F值之後所進行的多重比較,稱為事後比較(posteriori comparisons)。
達顯著水準. 當整體考驗顯著後必須檢驗哪幾個平均數之間顯著有所不同,即進行多重比較(multiple comparison)來檢驗。 多重比較在進行F考驗之前進行,稱為事前比較(priori comparisons),在獲得顯著的F值之後所進行的多重比較,稱為事後比較(posteriori comparisons)。")
23
多重比較問題 第一類型錯誤膨脹問題 變異數同質假設問題 當比較次數越多,犯下決策錯誤的可能性就更高
多重比較的統計原理多以族系錯誤率(FWE)的控制為主,期能使整體的錯誤率維持在一定的水準之下 變異數同質假設問題 多個平均數的比較必須在變異數同質假設維繫的情況下才有相同的標準誤 如果各組變異數不同質時,多重比較的顯著性考驗還必須對變異數不同質進行調整處理
的控制為主,期能使整體的錯誤率維持在一定的水準之下. 變異數同質假設問題. 多個平均數的比較必須在變異數同質假設維繫的情況下才有相同的標準誤. 如果各組變異數不同質時,多重比較的顯著性考驗還必須對變異數不同質進行調整處理.")
24
事前比較 時機 在進行研究之前,研究者即基於理論的推理或個人特定的需求,事先另行建立研究假設,以便能夠進行特定的兩兩樣本平均數的考驗
事前比較所處理的是個別比較的假設考驗,在顯著水準的處理上,屬於比較面顯著水準,而不需考慮實驗面的顯著水準 可直接應用t考驗,針對特定的水準,進行平均數差異考驗

25
事後比較 變異數同質時(當各組樣本數相同時)
Tukey’s HSD法:將所有的配對比較視為一體,使整個研究的第一類型錯誤維持衡定,第一類型錯誤是一種實驗誤差(experiment-wise error) LSD法又稱為Fisher擔保t檢定(Fisher’s protected t-test),表示這個t檢定是以F考驗達到顯著之後所進行的後續考驗,同時也在F考驗的誤差估計下所進行
 LSD法又稱為Fisher擔保t檢定(Fisher’s protected t-test),表示這個t檢定是以F考驗達到顯著之後所進行的後續考驗,同時也在F考驗的誤差估計下所進行.")
26
HSD法 HSD法原理 在常態性、同質性假設成立下,各組人數相等的一種以族系誤差率的控制為原則的多重比較程序
稱為誠實顯著差異(Honestly Significant Difference) 所謂誠實,就是在凸顯LSD法並沒有考慮到實驗與族系面誤差的問題 代價是降低了統計考驗的檢定力。以HSD法所得到的顯著性,會比沒有考慮型一錯誤膨脹問題的檢定方法來的高(例如如果比較次數為三次,HSD的p值為會是LSD法的三倍) Kramer則將Tukey的方法加以延伸至各組樣本數不相等的情況下,由於原理相同,故合稱為Tukey-Kramer法
 所謂誠實,就是在凸顯LSD法並沒有考慮到實驗與族系面誤差的問題. 代價是降低了統計考驗的檢定力。以HSD法所得到的顯著性,會比沒有考慮型一錯誤膨脹問題的檢定方法來的高(例如如果比較次數為三次,HSD的p值為會是LSD法的三倍) Kramer則將Tukey的方法加以延伸至各組樣本數不相等的情況下,由於原理相同,故合稱為Tukey-Kramer法.")
27
Newman-Keuls Methed 原理及計算公式與Tukey’s HSD法相同,唯一不同的是臨界值的使用
N-K法考慮相比較的兩個平均數在排列次序中相差的層級數r(the number of steps between ordered mean),作為自由度的依據,而非HSD的平均數個數k。 由於此法也是利用t檢定原理,因此在SPSS中稱為S-N-K法(Student-Newman-Keuls法) HSD法對於平均數配對差異檢驗較N-K法嚴謹,但是HSD法的統計檢定力則較N-K法為弱
,作為自由度的依據,而非HSD的平均數個數k。 由於此法也是利用t檢定原理,因此在SPSS中稱為S-N-K法(Student-Newman-Keuls法) HSD法對於平均數配對差異檢驗較N-K法嚴謹,但是HSD法的統計檢定力則較N-K法為弱.")
28
Scheff’s methed 原理 一種以F考驗為基礎,適用於n不相等的多重比較技術
此一方法對分配常態性與變異一致性兩項假定之違反頗不敏感,且所犯第一類型錯誤(type I error)的機率較小。可以說是各種方法中最嚴格、檢定力最低的一種多重比較。 Cohen(1996)甚至認為Scheffe執行前不一定要執行F整體考驗,因為如果F考驗不顯著,Scheffe考驗亦不會顯著,但是如果F整體考驗顯著,那麼Scheffe檢定則可以協助研究者尋找出整體考驗下的各種組合效果
的機率較小。可以說是各種方法中最嚴格、檢定力最低的一種多重比較。 Cohen(1996)甚至認為Scheffe執行前不一定要執行F整體考驗,因為如果F考驗不顯著,Scheffe考驗亦不會顯著,但是如果F整體考驗顯著,那麼Scheffe檢定則可以協助研究者尋找出整體考驗下的各種組合效果.")
29
變異數同質假定違反的多重比較 Dunnett’s T3法 調整臨界值來達成族系與實驗面的錯誤機率,使型一機率控制在一定的水準下
表示有nj個人的第j組變異數,表示各平均數變異誤估計數 W考驗(Welch test) 類似於t考驗,查表(Studentized maximum modulus distribution)後即可決定臨界值(c),決定假設是否成立
 類似於t考驗,查表(Studentized maximum modulus distribution)後即可決定臨界值(c),決定假設是否成立.")
30
Games-Howell法 原理 計算出調整自由度 後,直接與查自於Studentized range distribution的qcv臨界值相比,來決定顯著性 當各組人數大於50時Games-Howell法所求出的機率估計會較T3法正確,類似於Dunnett另外提出的C法

31
SPSS各種多重比較分析摘要表

32
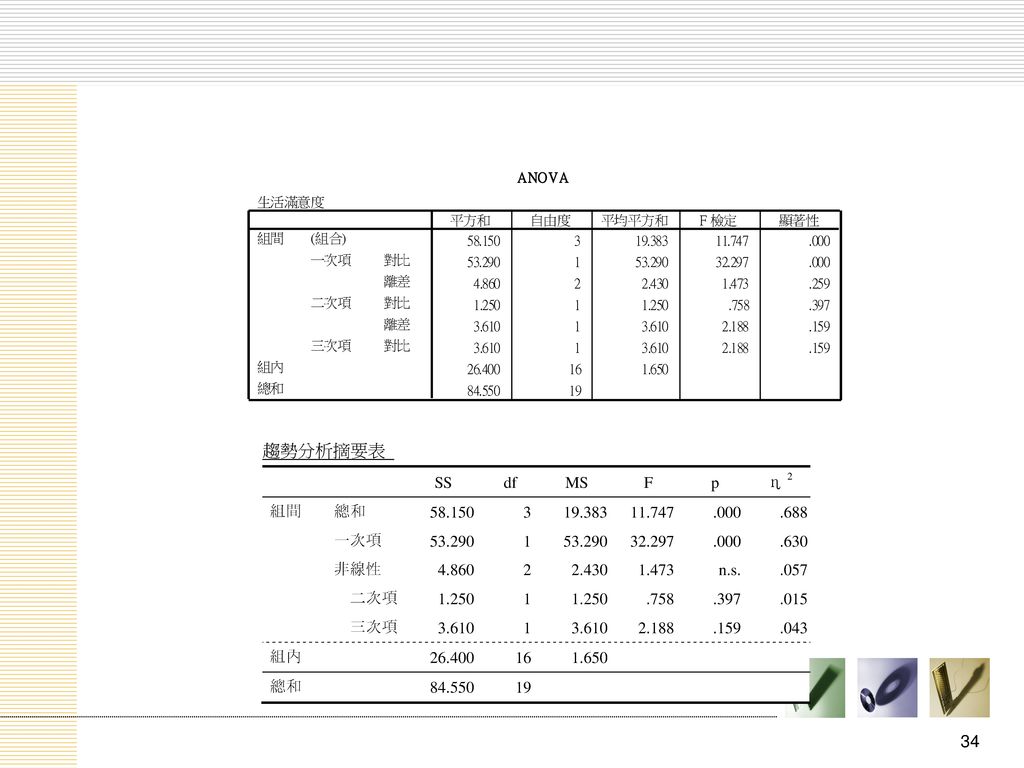
趨勢分析 趨勢分析(trend analysis) 趨勢分析的通式 變異數分析的一種應用模式,用來探討平均數的變化是否具有特定的趨勢
在ANOVA當中,平均數變動趨勢是利用多項式對比比較的方法來進行檢驗 當獨變項是具有特定順序關係的類別時(例如不同強度的實驗處理) 將不同水準下的依變項平均數依序排列,觀察這些平均數是否具有變動的趨勢 如果獨變項的各水準沒有順序可言(例如不同類型的教學方法),依變項平均數的比較與排列即沒有意義。 趨勢分析的通式 線性趨勢(linear trend):平均數呈現逐漸遞增或遞減 二次方程式(quadratic trend)、三次方程式(cubic trend):一次方程式無法充分解釋平均數的變動
 將不同水準下的依變項平均數依序排列,觀察這些平均數是否具有變動的趨勢. 如果獨變項的各水準沒有順序可言(例如不同類型的教學方法),依變項平均數的比較與排列即沒有意義。 趨勢分析的通式. 線性趨勢(linear trend):平均數呈現逐漸遞增或遞減. 二次方程式(quadratic trend)、三次方程式(cubic trend):一次方程式無法充分解釋平均數的變動.")
33
範例

35
Dunnett method 類似於Scheff法,適用於實驗研究中
當實驗具有k個平均數,k-1個為實驗控制,一個對照組,每一個實驗組需與對照組比較,因此需進行k-1次配對比較,第一類型錯誤的設定,是以整體實驗的成敗為考量,為一種experiment-wise error。 杜納法基於t分配的機率原理,檢定k-1個實驗組的平均數與單一控制組的平均數之間的差異顯著性,屬於非正交比較(non-orthogonal comparison)。
。")
36
ANOVA的基本假設 (一)常態性假設 (二)變異數同質性假設 (三)可加性假設 (四)球面性假設(sphericity)
變異數分析需處理超過三個以上的平均數,須假設樣本是抽取自常態化母群體,當樣本數越大,常態化的假設越不易違反。 (二)變異數同質性假設 多個樣本平均數的比較,必須建立在樣本的其他參數保持恆定的基礎上,如果樣本的變異數不同質,將造成推論上的偏誤。也就是樣本變異數同質性假設(homogeneity of variance)。 (三)可加性假設 變異數分析牽涉到變異量的拆解,因此,各種變異來源的變異量須相互獨立,且可以進行累積與加減,稱為可加性(additivity)假設。在進行加總時,係使用離均差平方和,而非變異數本身。 (四)球面性假設(sphericity) 適用於相依樣本的變異數分析,係指不同水準的同一組樣本,在依變項上的得分,兩兩配對相減所得的差的變異數必須相等(同質)。也就是說,不同的受試者在不同水準間配對或重複測量,其變動情形應具有一致性。
變異數同質性假設. 多個樣本平均數的比較,必須建立在樣本的其他參數保持恆定的基礎上,如果樣本的變異數不同質,將造成推論上的偏誤。也就是樣本變異數同質性假設(homogeneity of variance)。 (三)可加性假設. 變異數分析牽涉到變異量的拆解,因此,各種變異來源的變異量須相互獨立,且可以進行累積與加減,稱為可加性(additivity)假設。在進行加總時,係使用離均差平方和,而非變異數本身。 (四)球面性假設(sphericity) 適用於相依樣本的變異數分析,係指不同水準的同一組樣本,在依變項上的得分,兩兩配對相減所得的差的變異數必須相等(同質)。也就是說,不同的受試者在不同水準間配對或重複測量,其變動情形應具有一致性。")
Similar presentations


 第六週 雙因子實驗統計原理 與實務案例 第七週 雙因子實驗人工統計實作 與 SPSS 操作 第八週 學習成效及時檢測 ( 紙筆測驗與上機測驗.>")





 雙變項統計分析(一)>")
 Wonnacott and Wonnacott. Introductory>")


>")




 2012/7/6.>")

