Download presentation
Presentation is loading. Please wait.

1
一种基于结构序列 藕合模块辨别人类 miRNA前体的新方法
刘秀芹

2
内容提要 miRNA的产生 miRNA概述 Mirident方法流程结果 与已有的方法的比较 讨论

3
miRNA的产生——中心法则

4
miRNA的产生 蛋白基因1 miRNA基因 DNA序列 Protein Gene miRNA gene 转录 转录 mRNA
pri-miRNA Protein 翻译 行使功能

5
miRNA的产生

6
miRNA概述 长约20~25碱基的单链RNA 功能:在对mRNA进行转录后调控 ——mRNA 降解 ——阻止mRNA翻译成蛋白

7
miRNA的发现: 试验的方法 计算方法(分类算法) 各种机器学习方法用于预测miRNA. SVM, 随机树,线性规划,隐马氏模型等。
2. 机器学习的方法的关键之一是选取合适的特征。常用的特征: 序列特征(如,保守性,G C含量,) 结构特征(臂的长度,loop长度)
 结构特征(臂的长度,loop长度)")
8
用耦合特征辨别miRNA和假pre-miRNA.
已有方法的局限性: 受对miRNA认识的限制 一般分别考虑序列和结构的性质,大部分没有充分考虑序列和结构之间的相互关系 本文想法: 充分挖掘序列和结构耦合的特征。 用耦合特征辨别miRNA和假pre-miRNA.

9
Mirident方法流程 准备序列结构(sequence-structure) 寻找耦合特征 用线性SVM对特征进行排序 用支持向量机训练分类器,进行预测
 寻找耦合特征 用线性SVM对特征进行排序 用支持向量机训练分类器,进行预测")
10
算法步骤 1. 阳性集合准备 (1) hsa.fa是human的678条pre-miRNA序列(hairpin.fa
是所有物种的pre-miRNAs,用hsa.py取出人的)。 (2) 去重复率高于90%的序列,剩638条(quxiangsilian.py)。 (3) 计算二级结构,去多环,剩608条。
。 (2) 去重复率高于90%的序列,剩638条(quxiangsilian.py)。 (3) 计算二级结构,去多环,剩608条。")
11
(4)把每个位点的二级结构放在相应的位点后面,形成sequence-structure.
>hsa-mi MI Homo sapiens mi stem-oop UUCUCGUCCCAGUUCUUCCCAAAGUUGAGAAAAGCUGGGUUGAGAGGA ((((((.(((((((.(((.((....)).))).))))))).)))))).. U(U(C(U(C(G(U.C(C(C(A(G(U(U(C.U(U(C(C.C(A(A.A.G.U.U )G)A.G)A)A)A.A)G)C)U)G)G)G)U.U)G)A)G)A)G)G.A. L代表’(‘ R代表’)’ D表示’.’ ULULCLULCLGLUDCLCLCLALGLULULCDULULCLCDCLALADADGDUDURGRADGRARARADARGRCRURGRGRGRUdURGRARGRARGRGDAD (5)用软件 teiresias找457条公共特征(457/608=75%)。
).))).))))))).)))))).. U(U(C(U(C(G(U.C(C(C(A(G(U(U(C.U(U(C(C.C(A(A.A.G.U.U. )G)A.G)A)A)A.A)G)C)U)G)G)G)U.U)G)A)G)A)G)G.A. L代表’(‘ R代表’)’ D表示’.’ ULULCLULCLGLUDCLCLCLALGLULULCDULULCLCDCLALADADGDUDURGRADGRARARADARGRCRURGRGRGRUdURGRARGRARGRGDAD. (5)用软件 teiresias找457条公共特征(457/608=75%)。")
12
2. 阴性集合准备 (1)、在ucsc下载refseq.fa (2)、过滤剩11426条 (3)、去重复序列,只剩7898条
(4)、随机抽取608条,计算二级结构。 (5)、把每个位点的二级结构放在相应的位点后面,形成sequence-structure. (6)、用teiresias找457条(457/608=75%)共有的motifs(L=4,W=12,K=457)
、随机抽取608条,计算二级结构。 (5)、把每个位点的二级结构放在相应的位点后面,形成sequence-structure. (6)、用teiresias找457条(457/608=75%)共有的motifs(L=4,W=12,K=457)")
13
3. Libsvm分类: (1) 把阴性和阳性集合中得到的特征放到一起形成head.txt. 在阳性阴性集合中提取特征向量。
抽取特征向量的过程: >hsa-mi MI Homo sapiens mi stem-oop UUCUCGUCCCAGUUCUUCCCAAAGUUGAGAAAAGCUGGGUUGAGAGGA ((((((.(((((((.(((.((....)).))).))))))).)))))).. U(U(C(U(C(G(U.C(C(C(A(G(U(U(C.U(U(C(C.C(A(A.A.G.U.U )G)A.G)A)A)A.A)G)C)U)G)G)G)U.U)G)A)G)A)G)G.A. L代表’(‘ R代表’)’ D表示’.’ ULULCLULCLGLUdCLCLCLALGLULULCdULULCLCdCLALAdAdGdUdU RGRAdGRARARAdARGRCRURGRGRGRUdURGRARGRARGRGdAd
).))).))))))).)))))).. U(U(C(U(C(G(U.C(C(C(A(G(U(U(C.U(U(C(C.C(A(A.A.G.U.U. )G)A.G)A)A)A.A)G)C)U)G)G)G)U.U)G)A)G)A)G)G.A. L代表’(‘ R代表’)’ D表示’.’ ULULCLULCLGLUdCLCLCLALGLULULCdULULCLCdCLALAdAdGdUdU. RGRAdGRARARAdARGRCRURGRGRGRUdURGRARGRARGRGdAd.")
14
特征 LUL..C在序列>hsa-mi-320-1 中的特征向量的分量为2.
它的特征向量为: (2,2,4,2,2,1,1,3,2,4,0,3,2,2,2,2,1,3,2,3,2,2,0,0,1,4,3,2,0,0,2,1,2,1,2,3,2,4,2,2,1,0,1,4,3,4,3,1,2,4,1,1,2,3,3,0,2,0,3,0,1,2,2,7,1,1,1,2,2,1,6,2,0,1,1,3,3,0,2,2,2,1,2,1,1,1,2,3,2,1,2,6,3,3,2,1,2,0,2,3,4,0,0,0,1,1,1,1,0,2,3,1,3,1,1,3,2,4,1,0,3,1,3,3,0,3,3,2,2,3,3,2,1,3,0,0,5,1,2,2,2,1,1,0,1,2,2,1,3,1,1,1,2,2,1,1,1,2,3,3,2,0,2,4,4,1,2,1,3,6,3,2,3,1,1,1,0,3,1,0,3,2,2,3,4,1,0,3,1,1,3,4,0,1,0,1,1,2,1,3,2,0,1,2,2,0,1,2,2,1,1,0,1,1,3,3,1,0,2,3,0,1,3,0,1,0,0,1,1,2,1,1,1,1,2,3,3,1,2,0,3,2,1,1,0,1,0,2,2,1,2,0,1,1,0,0,2,4,1,0,3,1,1,2,1,1,1,1,0,0,4,3,0,0,1,0,0,3,3,2,3,2,1,1,2,3,2,1,3,2,1,2,2,4,2,3,1,0,2,0,2,1,1,3,1,0,2,1,2,0,0,2,1,2,2,4,2,0,1,0,1,0,2,0,3,1,0,1,4,4,3,2,5,2,3,2,2,1,2,5,0,4,1,2,1,1,1,2,2,3,2,5,2,0,0,0,2,0,2,2,2,2,2,1,1,2,3,1,2,1,0,4,2,0,0,1,3,2,0,0,0,1,2,2,2,1,1,1,2,3,1,1,2,1,2,3,0,0,1,3,2,0,2,0,2,2,5,0,1,3,0,2,3,1,0,1,5,0,1,4,2,0,0,2,3,1,4,1,2,0,2,0,1,2,2,1,2,1,1,3,0,3,2,3,2,1,0,1,2,1,3,2,2,0,1,1,2,1,2,1,0,1,5,3,0,0,1,2,1,0,0,0,2,3,3,2,1,1,2,1,2,2,2,3,2,1,0,1,0,2,2,1,1,1,0,1,2,1,0,2,1,2,1,0,1,0,1,4,0,1,0,1,0,3,2,1,0,1,2,4,0,3,2,5,0,2,3,1,1,0,0,1,0,1,1,2,1,3,2,1,1,1,1,3,3,0,1,1,2,1,0,1,1,2,1,2,0,3,1,2,1,3,0,4,2,1,2,3,1,1,2,3,0,0,0,2,3,1,1,2,2,2,4,1,2,1,2,0,1,0,0,2,0,0,3,0,2,1,1,1,0,0,1,1,0,0,0,2,2,2,1,0,2,2,1,2,1,1,4,5,2,1,0,1,1,2,1,3,1,0,1,3,0,0,2,0,2,1,1,4,2,0,4,0,0,1,0,1,1,2,2,0,1,0,2,3,2,0,3,4,1,1,1,1,2,0,0,1,0,2,0,1,0,4,3,0,3,1,1,3,2,0,1,0,1,0,1,1,1,2,1,0,0,0,0,0,2,0,2,1,1,2,1,1,2,0,1,3,2,0,3,0,1,2,0,3,1,2,0,0,2,3,2,0,1,1,3,0,5,2,0,1,3,4,1,1,1,2,2,1,1,0,1,0,2,3,5,3,2,0,2,1,4,2,0,0,1,1,2,1,0,1,4,3,4,0,0,1,0,1,0,0,0,2,0,3,2,1,2,4,1,2,5,1,2,0,1,0,2,2,3,0,0,1,2,4,3,2,2,1,6,0,3,1,1,3,3,1,1,0,0,2,2,0,0,1,1,0,1,0,2,0,0,3,1,1,1,2,1,0,1,1,1,1,1,2,2,0,0,1,0,4,0,0,4,0,2,3,1,0,2,1,1,0,2,0,1,3,1,4,0,1,1,2,3,1,2,1,1,1,2,1,0,0,2,1,3,1,2,1,1,1,2,0,1,0,2,0,3,3,0,3,1,3,0,4,1,1,1,0,2,2,0,0,0,0,0,1,2,2,1,2,2,3,0,4,0,0,3,1,2,2,1,1,0,2,0,0,3,1,0,0,3,3,1,0,0,3,3,1,1,1,0,2,0,1,1,0,1,1,0,2,1,0,2,0,2,0,0,1,2,0,3,2,2,1,0,1,1,0,3,1,0,0,0,3,2,0,0,1,0,2,3,4,1,2,0,3,2,0,1,0,1,1,1,0,0,0,1,2,1,1,2,3,3,0,4,2,1,2,1,5,1,1,0,1,0,2,1,2,1,1,4,0,0,0,1,2,3,1,1,1,1,0,1,2,2,1,1,0,0,1,2,0,1,0,0,2,0,0,0,0,2,5,3,2,1,0,1,0,3,4,3,0,0,1,2,1,3,2,0,3,1,2,0,1,3,0,1,2,0,3,1,1,1,0,0,0,0,0,1,2,1,1,2,3,3,1,1,1,1,3,1,2,0,4,1,4,0,1,1,1,3,1,1,1,2,0,2,3,1,1,3,0,4,2,1,1,1,1,1,1,0,2,2,2,1,1,1,0,2,1,0,2,1,0,2,2,1,0,0,0,1,2,1,2,1,0,0,2,0,2,4,0,0,1,0,3,0,0,1,3,1,3,1,5,2,2,2,2,0,0,0,1,1,3,0,0,1,2,1,2,3,2,0,1,3,1,3,2,5,0,3,2,3,1,0,2,2,0,2,4,3,1,2,2)
")
15
(2).用特征矩阵作线性libsvm,按 绝对值大小经行排序。
(3).在608个阳性集合中随机选取4/5,在608个阴性集合中随机选取4 /5放在一起作为训练集,剩余的作为测试集。 (4).选取前面的1300特征做高斯核libsvm.(试了选取不同个数的特征个数)。 (5). 结果,ACC= %, sp= %, se=96.774% , AUC=0.9929%
.在608个阳性集合中随机选取4/5,在608个阴性集合中随机选取4 /5放在一起作为训练集,剩余的作为测试集。 (4).选取前面的1300特征做高斯核libsvm.(试了选取不同个数的特征个数)。 (5). 结果,ACC= %, sp= %, se=96.774% , AUC=0.9929%")
16
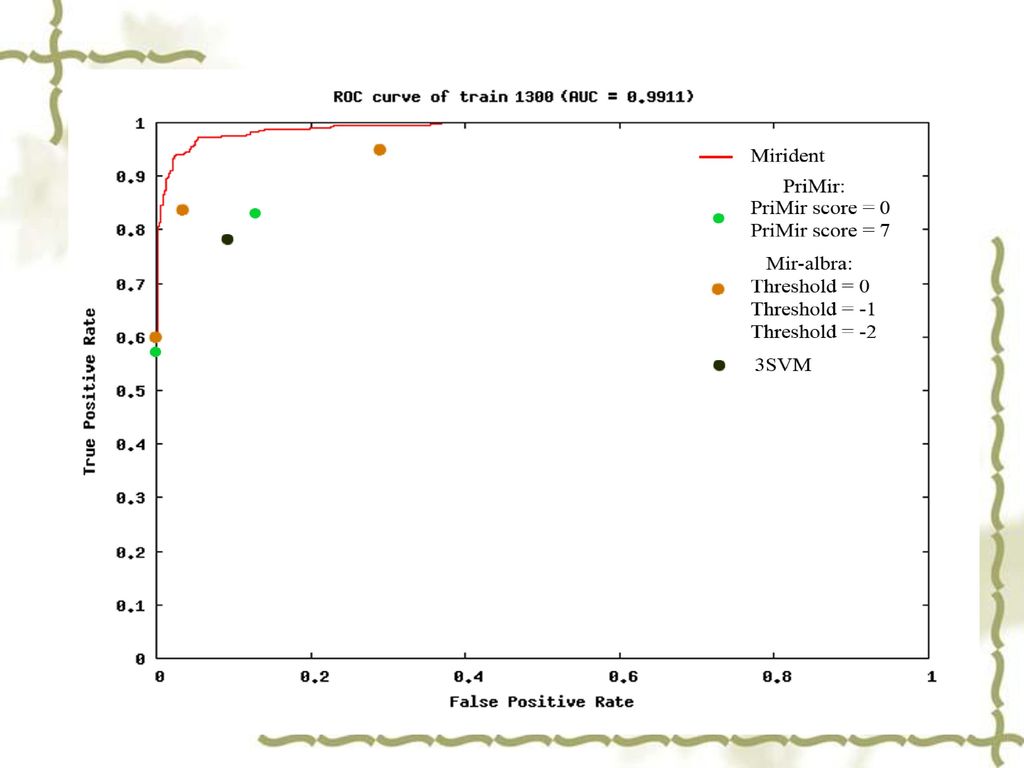
与已有的方法的较: ACC SP SE AUC Mirident 98.39% 99.1935% 97.58% 99.11% 3SVM
83.87% 89.516% 78.226% 3SVM(same training data) 80.24% 84.67% 75.8% Mir-albra Threshold= 0 80.242% 1 % Threshold= -1 89.5% 95.968% 83.645% Threshold=-2 81.45% 69.354% 93.55% PriMir Score=7 79.84% 100% 54.84% 92% Score=0 84.68% 87.2% 82.26%
 80.24% 84.67% 75.8% Mir-albra. Threshold= % % Threshold= % % % Threshold= % % 93.55% PriMir. Score= % 100% 54.84% 92% Score= % 87.2% 82.26%")
18
特征的位置分布:

21
讨论: 1.本文的新意在于把序列和序列的二级结构耦合在一起,用软件Teiresias找到了一些miRNAs的特征。有序列和结构耦合在一起的特征(以往的特征序列结构都是分开的)。 2.以往的特征都是很简单的容易察觉的或者来源于生物知识的特征,特征数目很有限,一般最多只有几十个,只能片面性的描述miRNA的特性, 本文方法摆脱了现有生物知识的束缚,从结构和序列出发穷举所有的特征,得到了上万个特征。全面的涵盖了miRNA的序列和结构以及它们耦合在一起的特征。 3.该方法得到的特征,可以给生物学家提供线索,更好的探寻miRNA的发生和功能。 4.用线性libSVM对特征进行排序。选取适当的特征数用高斯核训练分类器。对测试集进行预测,得到很高的SP和SE,比目前已有的方法预测效果都要好。

22
谢谢大家!

Similar presentations






. 第一关:测基础 判正误 第二关:练规范 强素质 第一关:测基础 判正误 1. 病毒是一种生物,但它不是一个独立的生命系统 ( ) 2. 细胞学说揭示了细胞的统一性和多样性 ( ) 3. 原核细胞中只含有核糖体一种细胞器 ( ) 4. 蓝藻细胞不含有叶绿体,不能进行光合作用.>")

 类型 :>")






大家都很困惑 文化究竟是什么?似乎谁都知道,又似乎谁也说不清楚…… 对“文化”的定义多达两百多种,但没有公认的、令人满意的定义。 多数定义:广义的文化是人类创造的物质财富和精神财富的总和,狭义仅指精神财富。 “文化”一词,似乎能够包罗万象,又似乎很虚,虚到无法理解。>")



