Download presentation
1
第五讲 抽样分布与参数估计

2
不象其他科学,统计从来不打算使 自己完美无缺,统计意味着你永远 不需要确定无疑。 —— Gudmund R.Iversen
统计名言 不象其他科学,统计从来不打算使 自己完美无缺,统计意味着你永远 不需要确定无疑。 —— Gudmund R.Iversen 2008年8月

3
【教学目的和要点】 ▼通过本讲学习,学生应该掌握构建样本平均数和样本比例的抽样分布以及掌握如何根据样本的信息推断总体的信息。

4
本讲内容 ■有关概念 ■抽样分布 ■参数估计 ♦单一总体均值估计 ♦单一总体比率估计 ♦两个总体均值之差估计 ♦两个总体比率差异估计
■确定样本容量

5
有关概念 参数与统计量 统计误差

6
参数与统计量 参数:反应总体分布特征的指标统称为总体参数,简称参数。常用的有
统计量:反应样本分布特征的指标统称为样本统计量,简称统计量。常用

7
总体参数 样本统计量 平均数 比率 方差

8
抽样推断流程 研究样本统计量抽样分布的意义何在?

9
统计误差 非抽样误差 统计误差 抽样误差: 随机性误差

10
抽样分布 定义:样本统计量的概率分布称为抽样分布。用以描述抽样误差的规律性,是统计推断的理论基础。 有关统计量的抽样分布
单一样本均值的抽样分布 两个样本均值之差的抽样分布 样本比率的抽样分布

11
的抽样分布 单一样本均值的抽样分布 正态分布再生定理 中心极限定理 两样本均值差异的抽样分布

12
正态分布再生定理 ■当总体服从正态分布时,从中抽取样本容量为n的样本,样本均值一定服从正态分布。
■样本均值的期望值和方差?它们与总体的期望值和方差有何关系 样本均值的期望值等于总体均值 方差(有退还抽样、无退还抽样 (退还抽样) (不退还抽样)
 (不退还抽样)")
13
中心极限定理 ■设某总体的元素总量为N,期望值为 ,标准差为 ;若从该总体中随机抽取样本容量为n的样本,当n很大(n>30)时,则样本平均数 的抽样分布近似为正态分布,即: (退还抽样) (不退还抽样)
")
14
抽样分布定理 大前提: 1)X服从正态分布; 小前提: (样本容量不限) 结论: 大前提: (X服从任意分布)
的概率分布 正态分布再生定理 中心极限定理 小样本定理 大前提: 1)X服从正态分布; 2)总体标准差已知。 小前提: (样本容量不限) 结论: 大前提: (X服从任意分布) 总体标准差已知。 小前提:样本容量足够大( n>30) 结论: 大前提: 1) X服从正态分布; 2)总体标准差未知。 小前提:理论上不设定,实践上n<=30 结论: 逼近正态分布。 服从标准正态分布 也服从 正态分布。 服从标准正态分布 服从t 分布
X服从正态分布; 2)总体标准差已知。 小前提: (样本容量不限) 结论: 大前提: (X服从任意分布) 总体标准差已知。 小前提:样本容量足够大( n>30) 结论: 大前提: 1) X服从正态分布; 2)总体标准差未知。 小前提:理论上不设定,实践上n<=30. 结论: 逼近正态分布。 服从标准正态分布. 也服从. 正态分布。 服从标准正态分布. 服从t 分布.")
15
样本均值抽样分布总结 非正态分布 正态分布

16
两个样本均值之差的抽样分布 从两个总体中分别独立的抽取样本容量分别为n1和n2的两个样本,在重复选取容量为n1和n2的样本时,由两个样本均值之差的所有可能形式的相对频数构成它们分布形态,也称为两个样本均值之差的抽样分布.

17
两个样本均值之差的抽样分布(大样本) 两个总体均值之差,即 其分布的方差为各自的方差之和,即 从而
 两个总体均值之差,即 其分布的方差为各自的方差之和,即 从而")
18
比率的抽样分布 设某二项分布总体,总体比率为 ,若从该总体中随机抽取样本容量为n的样本,当样本容量足够大( )时, 样本比率p的抽样 分布近似为正态分布,即: (退还抽样) (不退还抽样)
 (不退还抽样)")
19
假设一则关于公务旅游的报纸广告的达中率是7%。对单位客户随机抽取800户,问对样本客户达中率在8.3%以上的概率有多大。
解:已知π=0.07,n=800, 则nπ=800(0.07)=56, n(1-π)=800(1-0.07)=744, 两者都大于5, p 服从以π=0.07为期望值的正态分布。 p的抽样标准误为 。 P(p>0.083)= P(z> )= P(z> 1.30)=0.0968。 0.01 结论:对样本客户达中率在8.3%以上的概率是9.68%。
=56, n(1-π)=800(1-0.07)=744, 两者都大于5, p 服从以π=0.07为期望值的正态分布。 p的抽样标准误为 。 P(p>0.083)= P(z> )= P(z> 1.30)=0.0968。 结论:对样本客户达中率在8.3%以上的概率是9.68%。")
20
思考题: 1.什么是统计量,为什么要引进统计量? 2.为什么要求统计量中不含任何未知参数?

21
1.统计量是指不含任何未知参数的样本的函数,样本均值、样本方差都是统计量。引进统计量的目的是为了将无规律的样本值整理成便于对所研究问题进行统计推断、分析的形式。
将样本中所含的有关所研究问题的信息集中起来,从而更有效地揭示出问题的实质,进而得到解决问题的办法。例如,为了估计总体的均值,科将样本中关于总体取值的信息集中起来,这一信息就集中体现在样本的均值中。因为若总体期望比较大时,取自总体观测值的均值自然也应有偏大倾向,反之则将有偏小倾向。

22
2.因为统计量的适用目的在于对所研究的问题进行统计推断和分析。比如用统计量对未知参数进行估计时,若统计量本身仍含有未知参数,那么就无法根据所测得的样本值求得未知参数的估计值,利用统计量估计未知参数将失去意义。再如,在假设检验中,若检验统计量中含有未知参数,那么由样本值就无法求出相应的检验统计量的值,也就无法与相应的临界值进行比较,从而使得通过统计量表示的拒绝域将失去意义。

23
参数估计 估计方法 点估计 区间估计 单一总体均值估计 单一总体比率估计 两个总体均值之差估计

24
参数估计的方法 ●点估计 ●区间估计

25
点估计 (point estimate) 用样本的估计量的某个取值直接作为总体参数的估计值 无法给出估计值接近总体参数程度的信息
例如:用样本均值直接作为总体均值的估计;用两个样本均值之差直接作为总体均值之差的估计 无法给出估计值接近总体参数程度的信息 由于样本是随机的,抽出一个具体的样本得到的估计值很可能不同于总体真值 一个点估计量的可靠性是由它的抽样标准误差来衡量的,这表明一个具体的点估计值无法给出估计的可靠性的度量

26
点估计 估计量优良性的标准 无偏性 有效性 一致性

27
无偏性 (unbiasedness) 无偏性:估计量抽样分布的数学期望等于 被估计的总体参数: ---考虑估计量与参数的系统偏差问题 B A
无偏性:估计量抽样分布的数学期望等于 被估计的总体参数: ---考虑估计量与参数的系统偏差问题 P( ) B A 无偏 有偏 An estimator is a random variable used to estimate a population parameter (characteristic). Unbiasedness An estimator is unbiased if the mean of its sampling distribution is equal to the population parameter. Efficiency The efficiency of an unbiased estimator is measured by the variance of its sampling distribution. If two estimators, with the same sample size, are both unbiased, then the one with the smaller variance has greater relative efficiency. Consistency An estimator is a consistent estimator of a population parameter if the larger the sample size, the more likely it is that the estimate will come close to the parameter.
 B. A. 无偏. 有偏. An estimator is a random variable used to estimate a population parameter (characteristic). Unbiasedness. An estimator is unbiased if the mean of its sampling distribution is equal to the population parameter. Efficiency. The efficiency of an unbiased estimator is measured by the variance of its sampling distribution. If two estimators, with the same sample size, are both unbiased, then the one with the smaller variance has greater relative efficiency. Consistency. An estimator is a consistent estimator of a population parameter if the larger the sample size, the more likely it is that the estimate will come close to the parameter.")
28
有效性 (efficiency) 有效性:对同一总体参数的两个无偏点估计 量,有更小标准差的估计量更有效
---考虑估计量的值接近总体参数的程度 A B 的抽样分布 P( ) An estimator is a random variable used to estimate a population parameter (characteristic). Unbiasedness An estimator is unbiased if the mean of its sampling distribution is equal to the population parameter. Efficiency The efficiency of an unbiased estimator is measured by the variance of its sampling distribution. If two estimators, with the same sample size, are both unbiased, then the one with the smaller variance has greater relative efficiency. Consistency An estimator is a consistent estimator of a population parameter if the larger the sample size, the more likely it is that the estimate will come close to the parameter.
 An estimator is a random variable used to estimate a population parameter (characteristic). Unbiasedness. An estimator is unbiased if the mean of its sampling distribution is equal to the population parameter. Efficiency. The efficiency of an unbiased estimator is measured by the variance of its sampling distribution. If two estimators, with the same sample size, are both unbiased, then the one with the smaller variance has greater relative efficiency. Consistency. An estimator is a consistent estimator of a population parameter if the larger the sample size, the more likely it is that the estimate will come close to the parameter.")
29
一致性 (consistency) B A 一致性:随着样本量的增大,估计量的 值越来越接近被估计的总体参数 P( ) 较大的样本量
An estimator is a random variable used to estimate a population parameter (characteristic). Unbiasedness An estimator is unbiased if the mean of its sampling distribution is equal to the population parameter. Efficiency The efficiency of an unbiased estimator is measured by the variance of its sampling distribution. If two estimators, with the same sample size, are both unbiased, then the one with the smaller variance has greater relative efficiency. Consistency An estimator is a consistent estimator of a population parameter if the larger the sample size, the more likely it is that the estimate will come close to the parameter. B 较小的样本量 A
. Unbiasedness. An estimator is unbiased if the mean of its sampling distribution is equal to the population parameter. Efficiency. The efficiency of an unbiased estimator is measured by the variance of its sampling distribution. If two estimators, with the same sample size, are both unbiased, then the one with the smaller variance has greater relative efficiency. Consistency. An estimator is a consistent estimator of a population parameter if the larger the sample size, the more likely it is that the estimate will come close to the parameter. B. 较小的样本量. A.")
30
一致性 (consistency) 应用:较大方差的无偏估计量与较小方差的有偏估计量的比较评价 第一项:估计量 的方差;
第一项:估计量 的方差; 第二项: 估计 的系统偏差的平方

31
区间估计 区间估计的定义 区间估计的原理 区间估计的程序 单一总体平均数的区间估计 单一总体比率的区间估计 两个总体均值之差的区间估计
两个总体比率差异的区间估计

32
区间估计的定义 ♦ 区间估计是在一定的置信系数的保证下,根据统计量得到的一个取值范围去估计总体的参数。
♦ 区间估计是在一定的置信系数的保证下,根据统计量得到的一个取值范围去估计总体的参数。 为 的置信区间, 为置信度, 和 分别为置信下限和置信上限

33
区间估计 (interval estimate)
在点估计的基础上,给出总体参数估计的一个估计区间,该区间由样本统计量加减估计误差而得到 根据样本统计量的抽样分布能够对样本统计量与总体参数的接近程度给出一个概率度量 比如,某班级平均分数在75~85之间,置信水平是95% 置信区间 置信下限 置信上限 样本统计量 (点估计)
")
34
区间估计的基本原理 如果有 那么有 有95.44%的把握估计区间 包含总体均值

35
区间估计的图示 x 90%的样本 95% 的样本 99% 的样本 - 2.58x +2.58x -1.96 x
2008年8月 33

36
区间估计的几个关键概念 置信系数 使人相信区间包含总体均值的概率,一般取 0.95,0.90,0.99.它的大小说明估计的把握性的大小.
置信系数 使人相信区间包含总体均值的概率,一般取 0.95,0.90,0.99.它的大小说明估计的把握性的大小. 置信区间:在一定概率的保证下,包含总体均值的区间,区间的宽窄说明估计精度的大小.区间越宽,估计的精度就小;否则就大. 临界值:置信区间的上限和下限 注意置信系数和区间宽窄的关系

37
置信水平(置信系数) (confidence level)
将构造置信区间的步骤重复很多次,置信区间包含总体参数真值的次数所占的比例,也称置信度 表示为 (1 - 为是总体参数未在区间内的比例 常用的置信水平值有 99%, 95%, 90% 相应的 为0.01,0.05,0.10

38
总体均值区间的一般表达式 总体均值的置信区间是由样本均值加减估计误差得到的
估计误差由两部分组成:一是点估计量的标准误差,它取决于样本统计量的抽样分布。二是估计时所要求置信水平,统计量分布两侧面积的分位数值,它取决于事先所要求的可靠程度 总体均值在置信水平下的置信区间可一般性地表达为 样本均值±分位数值×样本均值的标准误差

39
置信区间的表述 (confidence interval)
由样本估计量构造出的总体参数在一定置信水平下的估计区间 统计学家在某种程度上确信这个区间会包含真正的总体参数,所以给它取名为置信区间 如果用某种方法构造的所有区间中有95%的区间包含总体参数的真值,5%的区间不包含总体参数的真值,那么,用该方法构造的区间称为置信水平为95%的置信区间。同样,其他置信水平的区间也可以用类似的方式进行表述

40
置信区间的表述 (confidence interval)
总体参数的真值是固定的,而用样本构造的区间则是不固定的,因此置信区间是一个随机区间,它会因样本的不同而变化,而且不是所有的区间都包含总体参数 实际估计时往往只抽取一个样本,此时所构造的是与该样本相联系的一定置信水平(比如95%)下的置信区间。我们只能希望这个区间是大量包含总体参数真值的区间中的一个,但它也可能是少数几个不包含参数真值的区间中的一个
下的置信区间。我们只能希望这个区间是大量包含总体参数真值的区间中的一个,但它也可能是少数几个不包含参数真值的区间中的一个.")
41
从均值为185的总体中抽出n=10的20个样本构造出的20个置信区间
置信区间的表述 (95%的置信区间) 我没有抓住参数! 点估计值 从均值为185的总体中抽出n=10的20个样本构造出的20个置信区间 2008年8月
 我没有抓住参数! 点估计值. 从均值为185的总体中抽出n=10的20个样本构造出的20个置信区间. 2008年8月.")
42
区间估计的程序 选定置信系数 抽取一个样本容量为n的样本 计算相应的统计量 确定统计量的概率分布 得到置信区间的临界值 得到参数的置信区间

43
单一总体平均数的区间估计 当σ已知时μ的置信区间 当σ未知时μ的置信区间 大样本 小样本

44
当 已知时计算μ的置信区间的步骤 选定置信系数 抽取一个样本容量为n的样本 计算 确定 统计量的概率分布 求置信区间的临界值
当 已知时计算μ的置信区间的步骤 选定置信系数 抽取一个样本容量为n的样本 计算 确定 统计量的概率分布 求置信区间的临界值 单一总体平均数的置信区间的临界值为

45
总体均值的区间估计 (大样本的估计) 1. 假定条件 使用正态分布统计量 z 总体均值 在1- 置信水平下的置信区间为
1. 假定条件 总体服从正态分布,且方差(2) 已知 如果不是正态分布,可由正态分布来近似 (n 30) 使用正态分布统计量 z 总体均值 在1- 置信水平下的置信区间为
 已知. 如果不是正态分布,可由正态分布来近似 (n 30) 使用正态分布统计量 z. 总体均值 在1- 置信水平下的置信区间为.")
46
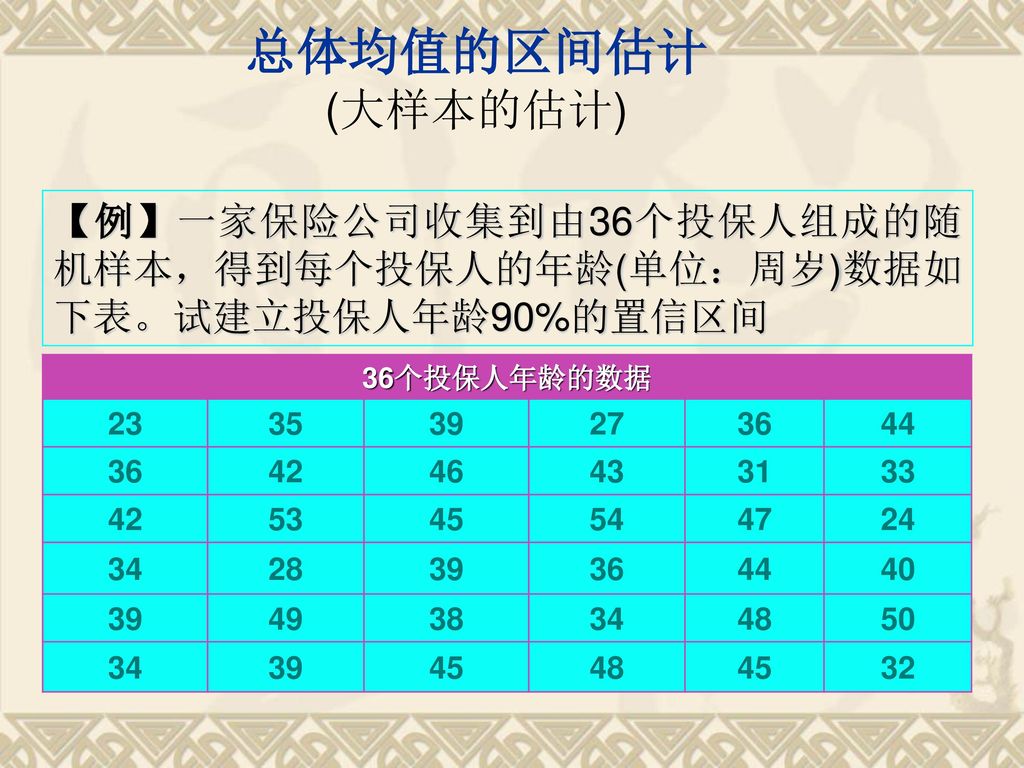
总体均值的区间估计 (大样本的估计) 【例】一家保险公司收集到由36个投保人组成的随机样本,得到每个投保人的年龄(单位:周岁)数据如下表。试建立投保人年龄90%的置信区间 36个投保人年龄的数据 23 35 39 27 36 44 42 46 43 31 33 53 45 54 47 24 34 28 40 49 38 48 50 32
47
总体均值的区间估计 (大样本的估计) 解:已知n=36, 1- = 90%,z/2=1.65。根据样本数据计算得: ,
总体均值的区间估计 (大样本的估计) 解:已知n=36, 1- = 90%,z/2=1.65。根据样本数据计算得: , 总体均值在1- 置信水平下的置信区间为 投保人平均年龄的置信区间为37.36岁~41.64岁
 解:已知n=36, 1- = 90%,z/2=1.65。根据样本数据计算得: , 总体均值在1- 置信水平下的置信区间为. 投保人平均年龄的置信区间为37.36岁~41.64岁.")
48
单一总体平均数的置信区间的临界值为

49
T分布(背景材料) t分布又称学生分布(STUDENT分布)由英国统计学家威廉西利.戈塞特于1900年提出,他当时受雇于爱尔兰首都的一家啤酒厂,由于该厂不允许雇员用自己的名字发表成果,于是他采用了学生这个笔名发表文章,阐述他发明的小样本理论。
 t分布又称学生分布(STUDENT分布)由英国统计学家威廉西利.戈塞特于1900年提出,他当时受雇于爱尔兰首都的一家啤酒厂,由于该厂不允许雇员用自己的名字发表成果,于是他采用了学生这个笔名发表文章,阐述他发明的小样本理论。")
50
T分布( t分布的性质) 1. t分布是对称的,即 E(t)=E(z)=0
当样本容量n较小时,t分布 的标准差大于1, 当 时 其标准差就趋于1,t分布就近于正态分布, 因为 此时S和 接近。

51
2. t分布是一个分布族,不同的n(在 统计上也称自由度)对应于不同的分布。但它们的均值都等于零。
T分布( t分布的性质) 2. t分布是一个分布族,不同的n(在 统计上也称自由度)对应于不同的分布。但它们的均值都等于零。 3. 与标准正态分布相比。t分布的中心部位较低,两个尾部较高。
 2. t分布是一个分布族,不同的n(在 统计上也称自由度)对应于不同的分布。但它们的均值都等于零。 3. 与标准正态分布相比。t分布的中心部位较低,两个尾部较高。")
52
t分布与z分布的比较图 z 分布 t分布n=15 t 分布(n=2)
")
53
总体均值的区间估计 (小样本的估计) 1.假定条件 使用 t 分布统计量 总体均值 在1-置信水平下的置信区间为
总体服从正态分布,但方差(2) 未知 小样本 (n < 30) 使用 t 分布统计量 总体均值 在1-置信水平下的置信区间为
 未知. 小样本 (n < 30) 使用 t 分布统计量. 总体均值 在1-置信水平下的置信区间为.")
54
总体均值的区间估计 (小样本的估计) 【例】已知某种灯泡的寿命服从正态分布,现从一批灯泡中随机抽取16只,测得其使用寿命(单位:h)如下。建立该批灯泡平均使用寿命95%的置信区间 16灯泡使用寿命的数据 1510 1520 1480 1500 1450 1490 1530 1460 1470

55
总体均值的区间估计 (小样本的估计) 解:已知X~N(,2),n=16, 1- = 95%,t/2(15)=2.131
根据样本数据计算得: , 总体均值在1-置信水平下的置信区间为 该种灯泡平均使用寿命的置信区间为1476.8h~1503.2h

56
单一总体比率的区间估计 应用条件: ( )时, 样本比率 p近似服从正态分布。 使用正态分布统计量Z
( )时, 样本比率 p近似服从正态分布。 使用正态分布统计量Z 总体比率 在1- 置信水平下的置信区间为
时, 样本比率 p近似服从正态分布。 使用正态分布统计量Z. 总体比率 在1- 置信水平下的置信区间为.")
57
总体比例的区间估计 样本比例±分位数值×样本比例的标准误差 1. 假定条件 使用正态分布统计量 z
1. 假定条件 总体服从二项分布 可以由正态分布来近似 np(成功次数)和n(1-p)(失败次数)均应该大于或等于5 使用正态分布统计量 z 3. 总体比例在1-置信水平下的置信区间为 样本比例±分位数值×样本比例的标准误差
和n(1-p)(失败次数)均应该大于或等于5. 使用正态分布统计量 z. 3. 总体比例在1-置信水平下的置信区间为. 样本比例±分位数值×样本比例的标准误差.")
58
总体比例的区间估计 (例题分析) 解:已知 n=100,p=65% , 1- = 95%,z/2=1.96
【例】某城市想要估计下岗职工中女性所占的比例,随机地抽取了100名下岗职工,其中65人为女性职工。试以95%的置信水平估计该城市下岗职工中女性比例的置信区间 该城市下岗职工中女性比例的置信区间为55.65%~74.35%

59
两个总体平均数差异的估计 点估计 区间估计

60
两个总体平均数差异的区间估计 应用条件: ♦两个样本都是大样本 ♦两样本彼此独立
两个总体平均数之差1-2在1- 置信水平下的置信区间为

61
(x1-x2 )±分位数值× (x1-x2 )的标准误差
均值之差区间的一般表达式 两个总体均值的置信区间是由两个样本均值之差加减估计误差得到的 估计误差由两部分组成:一是点估计量的标准误差,它取决于样本统计量的抽样分布。二是估计时所要求的置信水平,统计量分布两侧面积的分位数值,它取决于事先所要求的可靠程度 两个总体均值之差(1-2)在置信水平下的置信区间可一般性地表达为 (x1-x2 )±分位数值× (x1-x2 )的标准误差
在置信水平下的置信区间可一般性地表达为. (x1-x2 )±分位数值× (x1-x2 )的标准误差.")
62
两个总体均值之差的估计 (独立大样本) 1.假定条件 使用正态分布统计量 z 两个总体都服从正态分布,12、 22已知
若不是正态分布, 可以用正态分布来近似(n130和n230) 两个样本是独立的随机样本 使用正态分布统计量 z
 两个样本是独立的随机样本. 使用正态分布统计量 z.")
63
两个总体均值之差的估计 (独立大样本) 1. 12, 22已知时,两个总体均值之差1-2在1- 置信水平下的置信区间为
1. 12, 22已知时,两个总体均值之差1-2在1- 置信水平下的置信区间为 12、 22未知时,两个总体均值之差1-2在1- 置信水平下的置信区间为

64
两个总体均值之差的估计 (独立大样本) English
【例】某地区教育管理部门想估计两所中学的学生高考时的英语平均分数之差,为此在两所中学独立抽取两个随机样本,有关数据如右表 。建立两所中学高考英语平均分数之差95%的置信区间 两个样本的有关数据 中学1 中学2 n1=46 n1=33 S1=5.8 S2=7.2 English

65
两个总体均值之差的估计 (独立大样本) 解: 两个总体均值之差在1-置信水平下的置信区间为 两所中学高考英语平均分数之差的置信区间为
5.03分~10.97分 90

66
(p1- p2)±分位数值×(p1- p2)的标准误差
两个总体比例之差的区间估计 1. 假定条件 两个总体服从二项分布 可以用正态分布来近似 两个样本是独立的 n1p1和n1(1-p1), n2p2和n2(1-p2),均应该大于等于5 2. 两个总体比例之差1- 2在1- 置信水平下的置信区间为 (p1- p2)±分位数值×(p1- p2)的标准误差
, n2p2和n2(1-p2),均应该大于等于5. 2. 两个总体比例之差1- 2在1- 置信水平下的置信区间为. (p1- p2)±分位数值×(p1- p2)的标准误差.")
67
两个总体比例之差的估计 (例题分析) 【例】在某个电视节目的收视率调查中,农村随机调查了400人,有32%的人收看了该节目;城市随机调查了500人,有45%的人收看了该节目。试以95%的置信水平估计城市与农村收视率差别的置信区间
 【例】在某个电视节目的收视率调查中,农村随机调查了400人,有32%的人收看了该节目;城市随机调查了500人,有45%的人收看了该节目。试以95%的置信水平估计城市与农村收视率差别的置信区间.")
68
两个总体比例之差的估计 (例题分析—传统方法)
两个总体比例之差的估计 (例题分析—传统方法) 解: 已知 n1=500 ,n2=400, p1=45%, p2=32%, 1- =95%, z/2=1.96 1- 2置信度为95%的置信区间为 城市与农村收视率差值的置信区间为6.68%~19.32% 90
 解: 已知 n1=500 ,n2=400, p1=45%, p2=32%, 1- =95%, z/2=1.96. 1- 2置信度为95%的置信区间为. 城市与农村收视率差值的置信区间为6.68%~19.32% 90.")
69
样本容量的确定 估计总体均值时样本容量的确定 估计总体比率时样本容量的确定

70
样本容量的确定 ●估计总体均值时 根据均值区间估计公式可得样本容量n为

71
样本容量的确定 ●估计总体比率时 根据比率区间估计公式可得n为

72
例1:根据某城市一次样本容量为N=900户的随机抽样调查结果,被调查的家庭在过去的一年中耐用消费品的购买额均值为450元。另根据经验估计的标志差为120。如果置信系数为0.95且误差在± 4.5户以内,问样本量应确定为多少? 例2:某市消费者协会,希望了解当地公众认为面前我国市场上存在的最主要问题是什么。最好得到的结果是对有关比率的估计。他们希望以90%的把握作出估计,并使估计误差在± 0.05的范围内,问样本量应为多大?

73
本讲要点回顾1 有关概念 参数、统计量 抽样分布 单一样本均值的抽样分布 两个样本均值之差的抽样分布 样本比率的抽样分布

74
本讲要点回顾2 参数估计 估计方法 点估计 区间估计 单一总体均值估计 单一总体比率估计 两个总体均值之差估计 确定样本容量

75
思考与练习题(抽样分布) 一、判断题 二、单项选择题 三、多项选择题
 一、判断题 二、单项选择题 三、多项选择题")
76
一、判断题 1.在进行分层抽样时,应保证所分的层与总体具备相同的结构。 2.对数量特征具有周期性变化的观测值,采用直线式系统抽样会导致代表性降低。 3.总体参数并不是唯一确定的量,有时是随机变量。 4.一般而言,在同等条件下,较大的样本所提供的有关总体的信息要比较小的样本多。 5.样本统计量的概率分布实际上一种理论分布,是抽样推断的理论依据。

77
6.估计量的无偏性是指大量重复抽样的样本估计值应等于被估计总体参数的真实值。
7.在设计一个抽样方案时,抽取的样本量越多越好。 8.在采用分层抽样时,若某层内的变异较大,可以在该层取较多的样本单位。 9.对分布严重偏斜的总体,可以根据正态分布抽取小于30的样本量进行区间估计。

78
二、单项选择题(在每小题的四个备选答案中选出一个正确的答案,并将正确答案的号码填在题干后的括号内)
1.样本均值的抽样标准差所描述的是( ) A.样本均值的离散程度 B.一个样本中各观测值得离散程度 C.总体所有观测值的离散程度 D.样本方差的离散程度 2.设总体服从均值为 ,方差为 正态分布,从总体N中按放回抽样方法抽取容量为年n的简单随机样本,则样本均值 的抽样分布服从( ) A B C D
 A.样本均值的离散程度 B.一个样本中各观测值得离散程度. C.总体所有观测值的离散程度 D.样本方差的离散程度. 2.设总体服从均值为 ,方差为 正态分布,从总体N中按放回抽样方法抽取容量为年n的简单随机样本,则样本均值 的抽样分布服从( ) A B C D.")
79
3.某市有各类书店500家,其中大型50家,中型150家,小型300家。为了调查该市图书销售情况,拟抽取30家书店进行调查。如果采用分层等比例抽样法,下列在大型、中型、小型书店中样本的正确分配量为( ) A.5、15、10 B.7、10、13 C.10、10、10 D.3、9、18 4.抽样调查中,无法避免和消除的是( ) A.登记误差 B.系统性误差 C.随机误差 D.测量工具误差
 A.登记误差 B.系统性误差. C.随机误差 D.测量工具误差.")
80
5.若一个总体内各个观察值的差异较大,进行抽样时适宜采用( ) 分层抽样 整群抽样 简单随机抽样 多步抽样
6.总体方差的无偏估计是( ) A B C D.
 A. B. C. D.")
81
7.下列说法中不正确的是( ) A.样本均值的数学期望是总体均值的无偏估计量 B.样本比率的数学期望是总体比率的无偏估计量 C.样本标志差是总体标准差的无偏估计量 D.样本中位数和样本均值都是总体均值的无偏估计 量,但样本均值具有较小方差

82
三、多项选择题(从每小题的五个备选答案中选出二至五个正确答案,并将正确答案的号码分别填写在题干后的括号内)
1.基本的抽样设计有( ) A.整群抽样 B.分层抽样 C.简单随机抽样 D.系统抽样 E.多步抽样 2.关于样本比率p的抽样分布,下列正确的表述是( ) A.当随机变量x服从二项分布时,则p=x/n也服从二项分布 B.当 都不小于5时,样本比率近似服从正态分布 C.样本比率p的数学期望等于总体比率 D.样本比率p的标志差是 E.样本比率p的标志差是
 A.整群抽样. B.分层抽样. C.简单随机抽样. D.系统抽样. E.多步抽样. 2.关于样本比率p的抽样分布,下列正确的表述是( ) A.当随机变量x服从二项分布时,则p=x/n也服从二项分布. B.当 都不小于5时,样本比率近似服从正态分布. C.样本比率p的数学期望等于总体比率. D.样本比率p的标志差是. E.样本比率p的标志差是.")
83
3.下列哪些情况符合使用正态分布的条件?( ) A.从正态总体中抽取小样本,总体标志差已知 B.从正态总体中抽取大样本,总体标志差已知
3.下列哪些情况符合使用正态分布的条件?( ) A.从正态总体中抽取小样本,总体标志差已知 B.从正态总体中抽取大样本,总体标志差已知 C.从非正态总体中抽取小样本,总体标准差已知 D.从非正态总体中抽取大样本,总体标志差未知 E.从正态总体中抽取小样本,总体标准差未知 5.比率的抽样分布服从正态分布的前提条件是( ) A.N 20n B.np 5 C.n(1-p) D. E.
 A.从正态总体中抽取小样本,总体标志差已知. B.从正态总体中抽取大样本,总体标志差已知. C.从非正态总体中抽取小样本,总体标准差已知. D.从非正态总体中抽取大样本,总体标志差未知. E.从正态总体中抽取小样本,总体标准差未知. 5.比率的抽样分布服从正态分布的前提条件是( ) A.N 20n B.np 5. C.n(1-p) 5 D. E.")
84
思考与练习题(参数估计) 一、判断题 二、单项选择题 三、多项选择题 四、简答题 五、计算题
 一、判断题 二、单项选择题 三、多项选择题 四、简答题 五、计算题")
85
一、判断题 1.对同一总体进行n次抽样,构造n个置信区间,这些置信区间的中心在同一位置。 2.对方差未知的正态总体进行样本量相同的N次抽样,这N个置信区间的宽度必然相等。 3.样本均值的标志差也称抽样估计的标准误差,可用公式表示为 。 4.样本均值的抽样分布形式仅与样本量N的大小有关。 5.样本统计量与总体参数之间的差异是抽样造成的。

86
6.抽样误差产生的原因是由于在抽样过程中没有遵循随机原则。
7.抽取样本容量的多少与估计时要求的可靠程度成反比。 8.T分布与正态分布的区别是前者是分布形态不对称的,后者是对称的。 9.当总统比率P<0.7或P>0.7,抽取小样本,样本比率近似服从正态分布。 10.当时n<30, ,且 未知,则统计量的分布服从自由度为N-1的T分布。

87
二、单项选择题(在每小题的四个备选答案中选出一个正确的答案,并将正确答案的号码填在题干后的括号内)
1.估计量的数学期望等于总体参数这一性质称为( ) A.一致性 B.无偏性 C.有效性 D.随机性 2.总体均值的置信区间等于样本均值加减估计误差,其中的估计误差等于置信水平的临界值乘以( ) A.样本均值的抽样标准差 B.样本标志差 C.样本方差 D.总体标志差
 A.一致性 B.无偏性. C.有效性 D.随机性. 2.总体均值的置信区间等于样本均值加减估计误差,其中的估计误差等于置信水平的临界值乘以( ) A.样本均值的抽样标准差 B.样本标志差. C.样本方差 D.总体标志差.")
88
3.下列关于统计量的表述中,不正确的是( ) A.统计量是样本的函数 B.估计同一总体参数可以用多个不同统计量 C.统计量是随机变量 D.统计量的数值是唯一的 4.某品牌袋装白糖每袋重量的标志是500 ± 5克。为了检验该产品的重量是否符合标准,现从某日生产的这种糖果中随机抽查10袋,测得平均每袋重量为498克。下列说法中错误的是( ) A.样本量为 B.抽样误差是2克 C.样本平均每袋重量是估计量 D.点估计值为498克
 A.样本量为10 B.抽样误差是2克. C.样本平均每袋重量是估计量 D.点估计值为498克.")
89
5.对一部贺岁片收视率进行调查,随机抽取100人,其中有20人没有看过该部贺岁片,则看过该部贺岁片人数点估计值为( )
20% B C D.80% 6.在其他条件不变的情况下,要使置信区间的宽度缩小一半,样本量应增加( ) A.一半 B.一倍 C.三倍 D.四倍 7.在抽样估计中,随着样本容量的增大,样本统计量接近总体参数的概率就越大,这称为( )。 A.无偏性 B.有效性 C.一致性 D.及时性 8.影响区间估计精度的因素不包括( ) A.置信系数 B.总体参数 C.样本容量 D.观察值本身的变异
 A.一半 B.一倍 C.三倍 D.四倍. 7.在抽样估计中,随着样本容量的增大,样本统计量接近总体参数的概率就越大,这称为( )。 A.无偏性 B.有效性 C.一致性 D.及时性. 8.影响区间估计精度的因素不包括( ) A.置信系数 B.总体参数. C.样本容量 D.观察值本身的变异.")
90
9.设一正态总体N=100,均值是20。对其进行样本量为4的简单随机抽样,样本均值的抽样分布的期望值为( )
A B C D.A、B、C都不对 10.某企业根据对顾客随机抽样的信息得到对该企业产品表示满意的顾客比率的95%置信度的置信区间是(56%,64%)。下列正确的表述是( )。 A.总体比率的95%置信度的置信区间为(56%,64%) B.总体真实比率有95%的可能落在(56%,64%)中 C.区间(56%,64%)有95%的概率包含了总体真实比率 D.由100次抽样构造的100个置信区间中,约有95个覆盖了总体真实比率
。下列正确的表述是( )。 A.总体比率的95%置信度的置信区间为(56%,64%) B.总体真实比率有95%的可能落在(56%,64%)中. C.区间(56%,64%)有95%的概率包含了总体真实比率. D.由100次抽样构造的100个置信区间中,约有95个覆盖了总体真实比率.")
91
11.有30个调查者分别对同一正态总体进行了随机抽样,样本量都是100,总体方差未知。调查者分别根据各自的样本数据得到总体均值的一个置信度90%的置信区间,这些置信区间中覆盖总体均值的区间有( )
A.30个 B.90个 C.27个 D.3个 12.某学校数学考试成绩服从正态分布,以往经验表明成绩的标准差是10,从学生中随机抽取25个简单随机样本,得到平均分数是84.32分。根据这些数据计算均值95%的置信区间是( ) 。 A ±39.2 B ±1.96 C ±3.92 D ±19.60
 。 A ±39.2. B ±1.96. C ±3.92. D ±")
92
三、多项选择题(从每小题的五个备选答案中选出二至五个正确答案,并将正确答案的号码分别填写在题干后的括号内)
1.以下哪些属于优良估计量的评价标准( ) A.一致性 B.把握性 C.有效性 D.无偏性 E.正态性 2.在对总体均值进行区间估计时,影响置信区间宽度的影响是( ) A.总体中各个数据的差异程度 B.抽取样本的方式 C.样本容量的大小 D.估计的可靠性 E.总体数量的大小
 A.一致性 B.把握性. C.有效性 D.无偏性. E.正态性. 2.在对总体均值进行区间估计时,影响置信区间宽度的影响是( ) A.总体中各个数据的差异程度. B.抽取样本的方式. C.样本容量的大小. D.估计的可靠性. E.总体数量的大小.")
93
3.要提高抽样判断的精度,可采用的方法有( ) A.增加样本单位数目 B.减少样本单位数目 C.缩小观测值之间的差异程度
3.要提高抽样判断的精度,可采用的方法有( ) A.增加样本单位数目 B.减少样本单位数目 C.缩小观测值之间的差异程度 D.改善抽样的组织方式 E.改善抽样的方法 4.在简单重复随机抽样条件下,要使误差范围缩小1/2,其他条件不变,则样本容量必须( ) A.增加2倍 B.增加3倍 C.增加到4倍 D.减少2倍 E.减少3倍
 A.增加样本单位数目. B.减少样本单位数目. C.缩小观测值之间的差异程度. D.改善抽样的组织方式. E.改善抽样的方法. 4.在简单重复随机抽样条件下,要使误差范围缩小1/2,其他条件不变,则样本容量必须( ) A.增加2倍 B.增加3倍. C.增加到4倍 D.减少2倍. E.减少3倍.")
94
5.在抽样调查中,下列说法正确的是( ) A.样本指标是随机变量 B.总体指标是随机变量 C.样本指标是唯一确定的量
5.在抽样调查中,下列说法正确的是( ) A.样本指标是随机变量 B.总体指标是随机变量 C.样本指标是唯一确定的量 D.总体指标是唯一确定的量 E.样本指标是样本变量的函数 6.在计算抽样平均误差时,若总体方差未知,一般可取而代之的有( ) A.样本方差 B.以往调查中该现象方差最大者 C.以往调查中该现象方差最小者 D.比率方差可用0.25代替 E.比率方差可用0.5代替 7.在置信系数一定的情况下( ) A.允许误差越大,应抽取的样本单位数越多 B.允许误差越小,应抽取的样本单位数越多 C.允许误差越小,应抽取的样本单位数越小 D.允许误差越大,应抽取的样本单位数越少 E.允许误差平方和大小与应抽取的单位数多少成反比
 A.样本指标是随机变量. B.总体指标是随机变量. C.样本指标是唯一确定的量. D.总体指标是唯一确定的量. E.样本指标是样本变量的函数. 6.在计算抽样平均误差时,若总体方差未知,一般可取而代之的有( ) A.样本方差 B.以往调查中该现象方差最大者. C.以往调查中该现象方差最小者 D.比率方差可用0.25代替. E.比率方差可用0.5代替. 7.在置信系数一定的情况下( ) A.允许误差越大,应抽取的样本单位数越多 B.允许误差越小,应抽取的样本单位数越多. C.允许误差越小,应抽取的样本单位数越小. D.允许误差越大,应抽取的样本单位数越少. E.允许误差平方和大小与应抽取的单位数多少成反比.")
95
四、简单题 为什么希望未知参数的估计量具有无偏性?

96
用统计量 对未知参数 进行估计时,通常不希望它有系统偏差。实际上,由于 是随机变量,每次抽样后得到的估计 的观测值不一定能与 吻合,即 不一定为零。但是希望大量重复抽样试验而得到多个估计值与 之差能正负抵消。即希望 ,即 ,所有说无偏估计可使其没有系统偏差。

97
五、计算题 1、在一家大型超市,随机抽取100名顾客,测得某服务员对这100名顾客的收款时间的平均数为3.5分钟,标准差为1.2分钟,求置信系数为0.95时,该服务员对顾客收款时间平均数的总置信区间。

98
2.为了治理交通堵塞现象,某城市欲推广私家车单双号限行措施,为了了解车主对限行的态度,委托某调研机构根据车主的手机号码随机抽取了1400人,其中340人表示“赞同限行”,以90%置信系数求“赞同限行”人数比率的置信区间。

99
3.某产品组装生产线中某部件的设计组装时间为15分钟,现根据随机抽选的8名工人的工作时间进行观察结果进行时间研究,观察结果为15.8,15.4,13.6,15.3,18.6,15.8,14.5,13.8分钟。假设工人的组装时间服从正态分布,求工人组装该部件的平均时间的90%的置信区间。

100
4.某高校过去多次英语考试的成绩表明,男女学生的平均成绩是基本相同的,在最近的一次英语考试中,随机抽取100名学生,其中女生40人。女生平均成绩为78分,成绩的标志差为11分,男生平均成绩76分,成绩的标志差为14分。以90%的置信系数对女生与男生平均成绩的差异进行区间估计。

101
5.某咨询机构欲了解A市与B市的电脑拥有率,随机调查了A市529户和B市625户家庭,分别得到A市拥有电脑的户数为386和B市拥有电脑的户数为438,如果置信系数为90%,求A市和B市的电脑拥有率差异的置信区间。

102
6.某广告公司为了估计某地区收看某一新电视节目的居民人数所占比率,要设计一个简单随机样本的抽样方案。该公司希望有90%的信心使所估计的比率只有2个百分点左右的误差。为了节约调查费用,样本尽可能小,在这种情况下应该抽取多少样本?

103
第五讲 结束 谢谢! 返回














 常数项级数的概念 袁安锋 2016.7.>")

 罗洪群.>")




