Download presentation
1
§4.3 多重共线性 Multi-Collinearity

2
一、多重共线性的概念 二、实际经济问题中的多重共线性 三、多重共线性的后果 四、多重共线性的检验 五、克服多重共线性的方法 六、案例
§4.3 多重共线性 一、多重共线性的概念 二、实际经济问题中的多重共线性 三、多重共线性的后果 四、多重共线性的检验 五、克服多重共线性的方法 六、案例 *七、分部回归与多重共线性

3
一、多重共线性的概念 对于模型 Yi=0+1X1i+2X2i++kXki+i i=1,2,…,n
其基本假设之一是解释变量是互相独立的。 如果某两个或多个解释变量之间出现了相关性,则称为多重共线性(Multicollinearity)。
。")
4
如果存在 如果存在 c1X1i+c2X2i+…+ckXki=0 i=1,2,…,n
其中: ci不全为0,则称为解释变量间存在完全共线性(perfect multicollinearity)。 如果存在 c1X1i+c2X2i+…+ckXki+vi= i=1,2,…,n 其中ci不全为0,vi为随机误差项,则称为 近似共线性(approximate multicollinearity)或交互相关(intercorrelated)。
。 如果存在. c1X1i+c2X2i+…+ckXki+vi=0 i=1,2,…,n. 其中ci不全为0,vi为随机误差项,则称为 近似共线性(approximate multicollinearity)或交互相关(intercorrelated)。")
5
在矩阵表示的线性回归模型 Y=X+ 中,完全共线性指:秩(X)<k+1,即
中,至少有一列向量可由其他列向量(不包括第一列)线性表出。 如:X2= X1,则X2对Y的作用可由X1代替。
线性表出。 如:X2= X1,则X2对Y的作用可由X1代替。")
6
注意: 完全共线性的情况并不多见,一般出现的是在一定程度上的共线性,即近似共线性。

7
一般地,产生多重共线性的主要原因有以下三个方面: (1)经济变量相关的共同趋势
二、实际经济问题中的多重共线性 一般地,产生多重共线性的主要原因有以下三个方面: (1)经济变量相关的共同趋势 时间序列样本:经济繁荣时期,各基本经济变量(收入、消费、投资、价格)都趋于增长;衰退时期,又同时趋于下降。 横截面数据:生产函数中,资本投入与劳动力投入往往出现高度相关情况,大企业二者都大,小企业都小。
经济变量相关的共同趋势. 时间序列样本:经济繁荣时期,各基本经济变量(收入、消费、投资、价格)都趋于增长;衰退时期,又同时趋于下降。 横截面数据:生产函数中,资本投入与劳动力投入往往出现高度相关情况,大企业二者都大,小企业都小。")
8
(2)滞后变量的引入 在经济计量模型中,往往需要引入滞后经济变量来反映真实的经济关系。 例如,消费=f(当期收入, 前期收入) 显然,两期收入间有较强的线性相关性。
滞后变量的引入 在经济计量模型中,往往需要引入滞后经济变量来反映真实的经济关系。 例如,消费=f(当期收入, 前期收入) 显然,两期收入间有较强的线性相关性。")
9
(3)样本资料的限制 由于完全符合理论模型所要求的样本数据较难收集,特定样本可能存在某种程度的多重共线性。 一般经验:
时间序列数据样本:简单线性模型,往往存在多重共线性。 截面数据样本:问题不那么严重,但多重共线性仍然是存在的。

10
1、完全共线性下参数估计量不存在 二、多重共线性的后果 的OLS估计量为:
如果存在完全共线性,则(X’X)-1不存在,无法得到参数的估计量。
-1不存在,无法得到参数的估计量。")
11
例:对离差形式的二元回归模型 如果两个解释变量完全相关,如x2= x1,则 这时,只能确定综合参数1+2的估计值:

12
近似共线性下,可以得到OLS参数估计量,
但参数估计量方差的表达式为 由于|X’X|0,引起(X’X) -1主对角线元素较大,使参数估计值的方差增大,OLS参数估计量非有效。
 -1主对角线元素较大,使参数估计值的方差增大,OLS参数估计量非有效。")
13
仍以二元线性模型 y=1x1+2x2+ 为例:
恰为X1与X2的线性相关系数的平方r2 由于 r2 1,故 1/(1- r2 )1
1.")
14
当完全不共线时, r2 =0 当近似共线时, 0< r2 <1 多重共线性使参数估计值的方差增大,1/(1-r2)为方差膨胀因子(Variance Inflation Factor, VIF) 当完全共线时, r2=1,
为方差膨胀因子(Variance Inflation Factor, VIF) 当完全共线时, r2=1, .")
15
如果模型中两个解释变量具有线性相关性,例如 X2= X1 ,
3、参数估计量经济含义不合理 如果模型中两个解释变量具有线性相关性,例如 X2= X1 , 这时,X1和X2前的参数1、2并不反映各自与被解释变量之间的结构关系,而是反映它们对被解释变量的共同影响。 1、2已经失去了应有的经济含义,于是经常表现出似乎反常的现象:例如1本来应该是正的,结果恰是负的。

16
4、变量的显著性检验失去意义 存在多重共线性时 参数估计值的方差与标准差变大 容易使通过样本计算的t值小于临界值, 误导作出参数为0的推断
可能将重要的解释变量排除在模型之外

17
5、模型的预测功能失效 变大的方差容易使区间预测的“区间”变大,使预测失去意义。

18
注意: 除非是完全共线性,多重共线性并不意味着任何基本假设的违背;
因此,即使出现较高程度的多重共线性,OLS估计量仍具有线性性等良好的统计性质。 问题在于,即使OLS法仍是最好的估计方法,它却不是“完美的”,尤其是在统计推断上无法给出真正有用的信息。

19
三、多重共线性的检验 多重共线性检验的任务是:
多重共线性表现为解释变量之间具有相关关系,所以用于多重共线性的检验方法主要是统计方法:如判定系数检验法、逐步回归检验法等。 多重共线性检验的任务是: (1)检验多重共线性是否存在; (2)估计多重共线性的范围,即判断哪些变量之间存在共线性。
检验多重共线性是否存在; (2)估计多重共线性的范围,即判断哪些变量之间存在共线性。")
20
(1)对两个解释变量的模型,采用简单相关系数法
1、检验多重共线性是否存在 (1)对两个解释变量的模型,采用简单相关系数法 求出X1与X2的简单相关系数r,若|r|接近1,则说明两变量存在较强的多重共线性。 (2)对多个解释变量的模型,采用综合统计检验法 若 在OLS法下:R2与F值较大,但t检验值较小,说明各解释变量对Y的联合线性作用显著,但各解释变量间存在共线性而使得它们对Y的独立作用不能分辨,故t检验不显著。
对两个解释变量的模型,采用简单相关系数法. 求出X1与X2的简单相关系数r,若|r|接近1,则说明两变量存在较强的多重共线性。 (2)对多个解释变量的模型,采用综合统计检验法. 若 在OLS法下:R2与F值较大,但t检验值较小,说明各解释变量对Y的联合线性作用显著,但各解释变量间存在共线性而使得它们对Y的独立作用不能分辨,故t检验不显著。")
21
如果存在多重共线性,需进一步确定究竟由哪些变量引起。
2、判明存在多重共线性的范围 如果存在多重共线性,需进一步确定究竟由哪些变量引起。 (1) 判定系数检验法 使模型中每一个解释变量分别以其余解释变量为解释变量进行回归,并计算相应的拟合优度。 如果某一种回归 Xji=1X1i+2X2i+LXLi 的判定系数较大,说明Xj与其他X间存在共线性。
 判定系数检验法. 使模型中每一个解释变量分别以其余解释变量为解释变量进行回归,并计算相应的拟合优度。 如果某一种回归. Xji=1X1i+2X2i+LXLi. 的判定系数较大,说明Xj与其他X间存在共线性。")
22
式中:Rj•2为第j个解释变量对其他解释变量的回归方程的决定系数,
具体可进一步对上述回归方程作F检验: 构造如下F统计量 式中:Rj•2为第j个解释变量对其他解释变量的回归方程的决定系数, 若存在较强的共线性,则Rj•2较大且接近于1,这时(1- Rj•2 )较小,从而Fj的值较大。 因此,给定显著性水平,计算F值,并与相应的临界值比较,来判定是否存在相关性。
较小,从而Fj的值较大。 因此,给定显著性水平,计算F值,并与相应的临界值比较,来判定是否存在相关性。")
23
在模型中排除某一个解释变量Xj,估计模型;
另一等价的检验是: 在模型中排除某一个解释变量Xj,估计模型; 如果拟合优度与包含Xj时十分接近,则说明Xj与其它解释变量之间存在共线性。

24
以Y为被解释变量,逐个引入解释变量,构成回归模型,进行模型估计。
(2)逐步回归法 以Y为被解释变量,逐个引入解释变量,构成回归模型,进行模型估计。 根据拟合优度的变化决定新引入的变量是否独立。 如果拟合优度变化显著,则说明新引入的变量是一个独立解释变量; 如果拟合优度变化很不显著,则说明新引入的变量与其它变量之间存在共线性关系。
逐步回归法. 以Y为被解释变量,逐个引入解释变量,构成回归模型,进行模型估计。 根据拟合优度的变化决定新引入的变量是否独立。 如果拟合优度变化显著,则说明新引入的变量是一个独立解释变量; 如果拟合优度变化很不显著,则说明新引入的变量与其它变量之间存在共线性关系。")
25
如果模型被检验证明存在多重共线性,则需要发展新的方法估计模型,最常用的方法有三类。
四、克服多重共线性的方法 如果模型被检验证明存在多重共线性,则需要发展新的方法估计模型,最常用的方法有三类。 1、第一类方法:排除引起共线性的变量 找出引起多重共线性的解释变量,将它排除出去。 以逐步回归法得到最广泛的应用。 注意: 这时,剩余解释变量参数的经济含义和数值都发生了变化。

26
时间序列数据、线性模型:将原模型变换为差分模型: Yi=1 X1i+2 X2i++k Xki+ i
2、第二类方法:差分法 时间序列数据、线性模型:将原模型变换为差分模型: Yi=1 X1i+2 X2i++k Xki+ i 可以有效地消除原模型中的多重共线性。 一般讲,增量之间的线性关系远比总量之间的线性关系弱得多。

27
例 如:

28
由表中的比值可以直观地看到,增量的线性关系弱于总量之间的线性关系。
进一步分析: Y与C(-1)之间的判定系数为0.9988, △Y与△C(-1)之间的判定系数为0.9567
之间的判定系数为0.9988, △Y与△C(-1)之间的判定系数为")
29
3、第三类方法:减小参数估计量的方差 多重共线性的主要后果是参数估计量具有较大的方差,所以 采取适当方法减小参数估计量的方差,虽然没有消除模型中的多重共线性,但确能消除多重共线性造成的后果。 例如: ①增加样本容量,可使参数估计量的方差减小。

30
*②岭回归法(Ridge Regression)
70年代发展的岭回归法,以引入偏误为代价减小参数估计量的方差,受到人们的重视。 具体方法是:引入矩阵D,使参数估计量为 (*) 其中矩阵D一般选择为主对角阵,即 D=aI a为大于0的常数。 显然,与未含D的参数B的估计量相比,(*)式的估计量有较小的方差。
 其中矩阵D一般选择为主对角阵,即. D=aI. a为大于0的常数。 显然,与未含D的参数B的估计量相比,(*)式的估计量有较小的方差。")
31
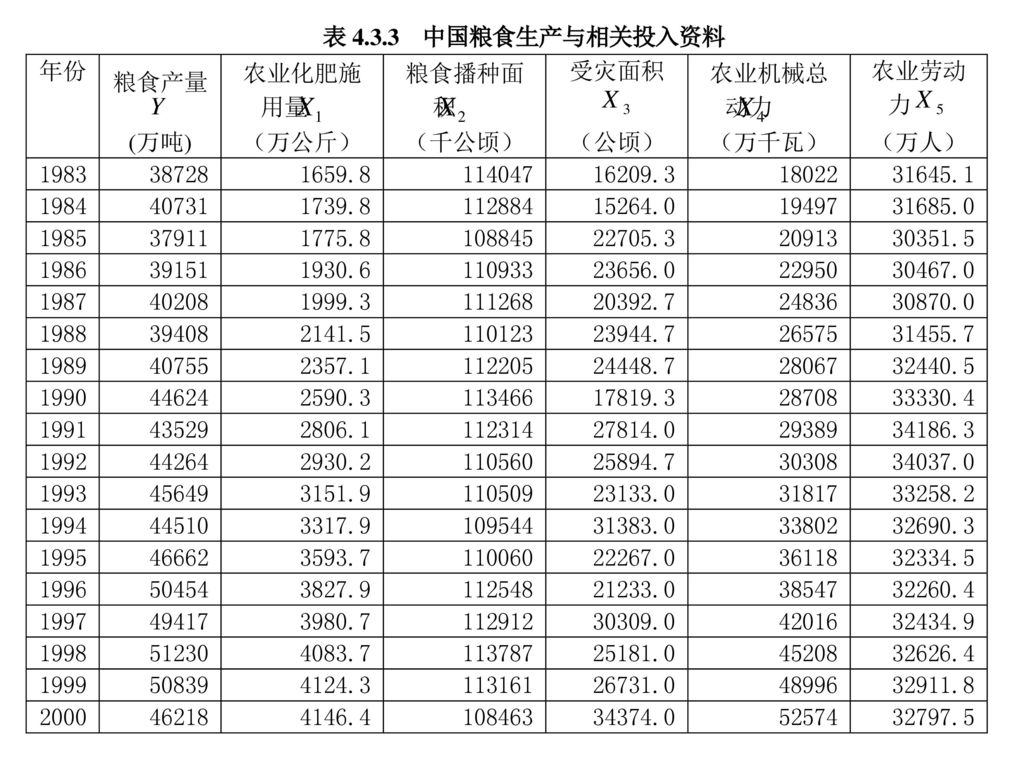
根据理论和经验分析,影响粮食生产(Y)的主要因素有:
六、案例——中国粮食生产函数 根据理论和经验分析,影响粮食生产(Y)的主要因素有: 农业化肥施用量(X1);粮食播种面积(X2) 成灾面积(X3); 农业机械总动力(X4); 农业劳动力(X5) 已知中国粮食生产的相关数据,建立中国粮食生产函数: Y=0+1 X1 +2 X2 +3 X3 +4 X4 +4 X5 +
的主要因素有: 农业化肥施用量(X1);粮食播种面积(X2) 成灾面积(X3); 农业机械总动力(X4); 农业劳动力(X5) 已知中国粮食生产的相关数据,建立中国粮食生产函数: Y=0+1 X1 +2 X2 +3 X3 +4 X4 +4 X5 +")
33
1、用OLS法估计上述模型: R2接近于1; 给定=5%,得F临界值 F0.05(5,12)=3.11
(-0.91) (8.39) (3.32) (-2.81) (-1.45) (-0.14) R2接近于1; 给定=5%,得F临界值 F0.05(5,12)=3.11 F=638.4 > 15.19, 故认上述粮食生产的总体线性关系显著成立。 但X4 、X5 的参数未通过t检验,且符号不正确,故解释变量间可能存在多重共线性。
 (8.39) (3.32) (-2.81) (-1.45) (-0.14) R2接近于1; 给定=5%,得F临界值 F0.05(5,12)=3.11. F=638.4 > 15.19, 故认上述粮食生产的总体线性关系显著成立。 但X4 、X5 的参数未通过t检验,且符号不正确,故解释变量间可能存在多重共线性。")
34
2、检验简单相关系数 列出X1,X2,X3,X4,X5的相关系数矩阵: 发现: X1与X4间存在高度相关性。

35
3、找出最简单的回归形式 分别作Y与X1,X2,X4,X5间的回归: 可见,应选第1个式子为初始的回归模型。 (25.58) (11.49)
(25.58) (11.49) R2= F= DW=1.56 (-0.49) (1.14) R2= F= DW=0.12 (17.45) (6.68) R2= F= DW=1.11 (-1.04) (2.66) R2= F= DW=0.36 可见,应选第1个式子为初始的回归模型。
 (11.49) R2= F=132.1 DW=1.56. (-0.49) (1.14) R2=0.075 F=1.30 DW=0.12. (17.45) (6.68) R2= F=48.7 DW=1.11. (-1.04) (2.66) R2= F=7.07 DW=0.36. 可见,应选第1个式子为初始的回归模型。")
36
4、逐步回归 将其他解释变量分别导入上述初始回归模型,寻找最佳回归方程。

37
5、结论 回归方程以Y=f(X1,X2,X3)为最优:
为最优:")
38
*七、分部回归与多重共线性

39
1、分部回归法(Partitioned Regression)
对于模型 将解释变量分为两部分,对应的参数也分为两部分: 在满足解释变量与随机误差项不相关的情况下,可以写出关于参数估计量的方程组:

40
如果存在 则有 这就是仅以X1作为解释变量时的参数估计量 同样有 这就是仅以X2作为解释变量时的参数估计量。

41
2、由分部回归法导出 如果一个多元线性模型的解释变量之间完全正交,可以将该多元模型分为多个一元模型、二元模型、…进行估计,参数估计结果不变;
实际模型由于存在或轻或重的共线性,如果将它们分为多个一元模型、二元模型、…进行估计,参数估计结果将发生变化;

42
当模型存在共线性,将某个共线性变量去掉,剩余变量的参数估计结果将发生变化,而且经济含义有发生变化;
严格地说,实际模型由于总存在一定程度的共线性,所以每个参数估计量并不 真正反映对应变量与被解释变量之间的结构关系。










>")





>")


 由未知数的系数组成的n阶行列式>")

