Download presentation
1
第四章 经典单方程计量经济学模型:放宽基本假定的模型
第四章 经典单方程计量经济学模型:放宽基本假定的模型

2
§4.1 异方差性 §4.2 序列相关性 §4.3 多重共线性 §4.4 随机解释变量问题
§4.1 异方差性 §4.2 序列相关性 §4.3 多重共线性 §4.4 随机解释变量问题

3
基本假定违背主要 包括: (1)随机误差项序列存在异方差性; (2)随机误差项序列存在序列相关性; (3)解释变量之间存在多重共线性; (4)解释变量是随机变量且与随机误差项相关的随机解释变量问题;
随机误差项序列存在异方差性; (2)随机误差项序列存在序列相关性; (3)解释变量之间存在多重共线性; (4)解释变量是随机变量且与随机误差项相关的随机解释变量问题;")
4
(5)模型设定有偏误; (6)解释变量的方差不随样本容量的增而收敛。 计量经济检验:对模型基本假定的检验 本章主要学习:前4类
模型设定有偏误; (6)解释变量的方差不随样本容量的增而收敛。 计量经济检验:对模型基本假定的检验 本章主要学习:前4类")
5
§4.1 异方差性 一、异方差的概念 二、异方差的类型 三、实际经济问题中的异方差性 四、异方差性的后果 五、异方差性的检验
§4.1 异方差性 一、异方差的概念 二、异方差的类型 三、实际经济问题中的异方差性 四、异方差性的后果 五、异方差性的检验 六、异方差的修正 七、案例

6
一、异方差的概念 对于模型 如果出现 即对于不同的样本点,随机误差项的方差不再是常数,而互不相同,则认为出现了异方差性(Heteroskedasticity)。
。")
7
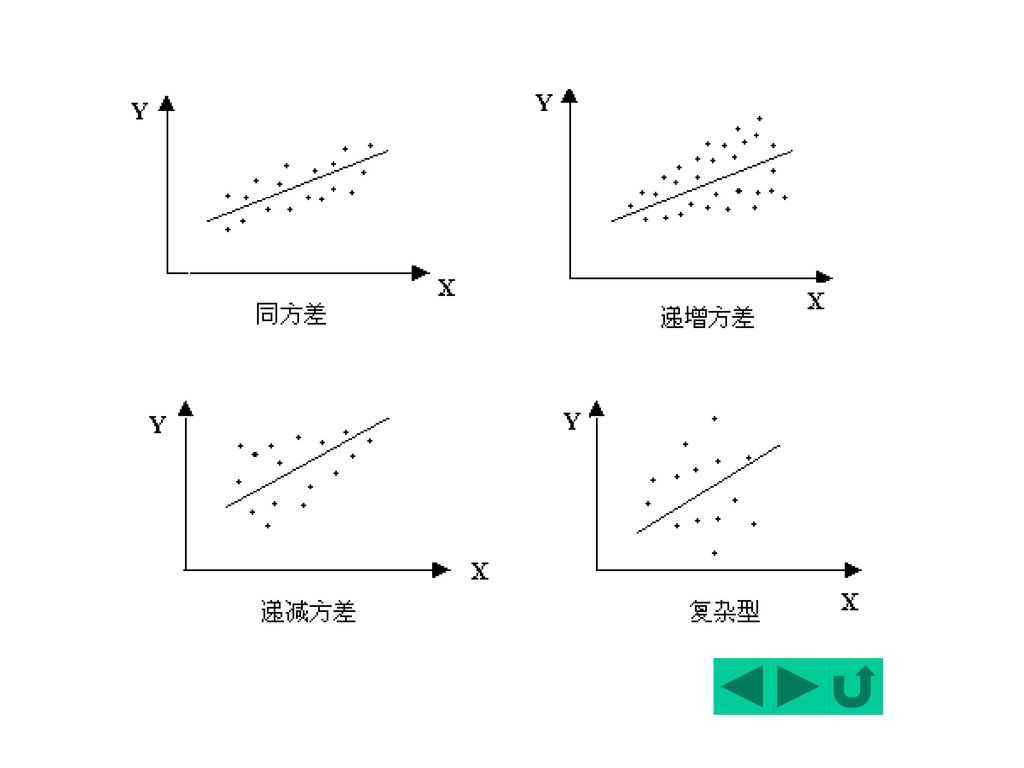
二、异方差的类型 同方差:i2 = 常数 f(Xi) 异方差: i2 = f(Xi) 异方差一般可归结为三种类型:
(1)单调递增型: i2随X的增大而增大 (2)单调递减型: i2随X的增大而减小 (3)复 杂 型: i2与X的变化呈复杂形式
单调递增型: i2随X的增大而增大. (2)单调递减型: i2随X的增大而减小. (3)复 杂 型: i2与X的变化呈复杂形式.")
9
三、实际经济问题中的异方差性 例4.1.1:截面资料下研究居民家庭的储蓄行为: Yi=0+1Xi+i
Yi:第i个家庭的储蓄额 Xi:第i个家庭的可支配收入。 高收入家庭:储蓄的差异较大 低收入家庭:储蓄则更有规律性,差异较小 i的方差呈现单调递增型变化

10
例4.1.2,以绝对收入假设为理论假设、以截面数据为样本建立居民消费函数:
Ci=0+1Yi+I 将居民按照收入等距离分成n组,取组平均数为样本观测值。

11
一般情况下,居民收入服从正态分布:中等收入组人数多,两端收入组人数少。而人数多的组平均数的误差小,人数少的组平均数的误差大。
所以样本观测值的观测误差随着解释变量观测值的不同而不同,往往引起异方差性。

12
例4.1.3,以某一行业的企业为样本建立企业生产函数模型:
Yi=Ai1 Ki2 Li3ei 被解释变量:产出量Y 解释变量:资本K、劳动L、技术A, 那么:每个企业所处的外部环境对产出量的影响被包含在随机误差项中。

13
每个企业所处的外部环境对产出量的影响程度不同,造成了随机误差项的异方差性。
这时,随机误差项的方差并不随某一个解释变量观测值的变化而呈规律性变化,呈现复杂型。

14
计量经济学模型一旦出现异方差性,如果仍采用OLS估计模型参数,会产生下列不良后果:
四、异方差性的后果 计量经济学模型一旦出现异方差性,如果仍采用OLS估计模型参数,会产生下列不良后果: 1. 参数估计量非有效 OLS估计量仍然具有无偏性,但不具有有效性 因为在有效性证明中利用了 E(’)=2I 而且,在大样本情况下,尽管参数估计量具有一致性,但仍然不具有渐近有效性。
=2I. 而且,在大样本情况下,尽管参数估计量具有一致性,但仍然不具有渐近有效性。")
15
2. 变量的显著性检验失去意义 变量的显著性检验中,构造了t统计量 其他检验也是如此。

16
一方面,由于上述后果,使得模型不具有良好的统计性质;
3. 模型的预测失效 一方面,由于上述后果,使得模型不具有良好的统计性质; 所以,当模型出现异方差性时,参数OLS估计值的变异程度增大,从而造成对Y的预测误差变大,降低预测精度,预测功能失效。

17
五、异方差性的检验 由于异方差性就是相对于不同的解释变量观测值,随机误差项具有不同的方差。那么: 检验思路:
检验异方差性,也就是检验随机误差项的方差与解释变量观测值之间的相关性及其相关的“形式”。

18
问题在于用什么来表示随机误差项的方差 一般的处理方法:

19
几种异方差的检验方法: 1. 图示法 (1)用X-Y的散点图进行判断 看是否存在明显的散点扩大、缩小或复杂型趋势(即不在一个固定的带型域中)
用X-Y的散点图进行判断 看是否存在明显的散点扩大、缩小或复杂型趋势(即不在一个固定的带型域中)")
20
看是否形成一斜率为零的直线

21
2. 帕克(Park)检验与戈里瑟(Gleiser)检验
基本思想: 偿试建立方程: 或 选择关于变量X的不同的函数形式,对方程进行估计并进行显著性检验,如果存在某一种函数形式,使得方程显著成立,则说明原模型存在异方差性。 如: 帕克检验常用的函数形式:

22
若在统计上是显著的,表明存在异方差性。
或 若在统计上是显著的,表明存在异方差性。 3. 戈德菲尔德-匡特(Goldfeld-Quandt)检验 G-Q检验以F检验为基础,适用于样本容量较大、异方差递增或递减的情况。
检验. G-Q检验以F检验为基础,适用于样本容量较大、异方差递增或递减的情况。")
23
G-Q检验的思想: 先将样本一分为二,对子样①和子样②分别作回归,然后利用两个子样的残差平方和之比构造统计量进行异方差检验。
由于该统计量服从F分布,因此假如存在递增的异方差,则F远大于1;反之就会等于1(同方差)、或小于1(递减方差)。
、或小于1(递减方差)。")
24
G-Q检验的步骤: ①将n对样本观察值(Xi,Yi)按观察值Xi的大小排队; ②将序列中间的c=n/4个观察值除去,并将剩下的观察值划分为较小与较大的相同的两个子样本,每个子样样本容量均为(n-c)/2; ③对每个子样分别进行OLS回归,并计算各自的残差平方和;

25
④在同方差性假定下,构造如下满足F分布的统计量

26
若F> F(v1,v2), 则拒绝同方差性假设,表明存在异方差。
当然,还可根据两个残差平方和对应的子样的顺序判断是递增型异方差还是递减异型方差。

27
4. 怀特(White)检验 怀特检验不需要排序,且适合任何形式的异方差。 怀特检验的基本思想与步骤(以二元为例): 然后做如下辅助回归
检验 怀特检验不需要排序,且适合任何形式的异方差。 怀特检验的基本思想与步骤(以二元为例): 然后做如下辅助回归")
28
R2为(*)的可决系数,h为(*)式解释变量的个数,
可以证明,在同方差假设下: R2为(*)的可决系数,h为(*)式解释变量的个数, 表示渐近服从某分布。
的可决系数,h为(*)式解释变量的个数, 表示渐近服从某分布。")
29
辅助回归仍是检验与解释变量可能的组合的显著性,因此,辅助回归方程中还可引入解释变量的更高次方。
注意: 辅助回归仍是检验与解释变量可能的组合的显著性,因此,辅助回归方程中还可引入解释变量的更高次方。 如果存在异方差性,则表明确与解释变量的某种组合有显著的相关性,这时往往显示出有较高的可决系数以及某一参数的t检验值较大。 当然,在多元回归中,由于辅助回归方程中可能有太多解释变量,从而使自由度减少,有时可去掉交叉项。

30
六、异方差的修正 加权最小二乘法的基本思想:
模型检验出存在异方差性,可用加权最小二乘法(Weighted Least Squares, WLS)进行估计。 加权最小二乘法的基本思想: 加权最小二乘法是对原模型加权,使之变成一个新的不存在异方差性的模型,然后采用OLS估计其参数。
进行估计。 加权最小二乘法的基本思想: 加权最小二乘法是对原模型加权,使之变成一个新的不存在异方差性的模型,然后采用OLS估计其参数。")
31
在采用OLS方法时: 对较小的残差平方ei2赋予较大的权数; 对较大的残差平方ei2赋予较小的权数。 例如,如果对一多元模型,经检验知:

32
新模型中,存在 即满足同方差性,可用OLS法估计。

33
一般情况下: 存在: 对于模型Y=X+ 即存在异方差性。 W是一对称正定矩阵,存在一可逆矩阵D使得 W=DD’

34
用D-1左乘 Y=X+ 两边,得到一个新的模型: 该模型具有同方差性。因为

35
这就是原模型Y=X+的加权最小二乘估计量,是无偏、有效的估计量。
这里权矩阵为D-1,它来自于原模型残差项的方差-协方差矩阵2W 。

36
如何得到2W ? 从前面的推导过程看,它来自于原模型残差项的方差—协方差矩阵。因此仍对原模型进行OLS估计,得到随机误差项的近似估计量ěi,以此构成权矩阵的估计量,即 这时可直接以 作为权矩阵。

37
在实际操作中人们通常采用如下的经验方法:
注意: 在实际操作中人们通常采用如下的经验方法: 不对原模型进行异方差性检验,而是直接选择加权最小二乘法,尤其是采用截面数据作样本时。 如果确实存在异方差,则被有效地消除了; 如果不存在异方差性,则加权最小二乘法等价于普通最小二乘法。

38
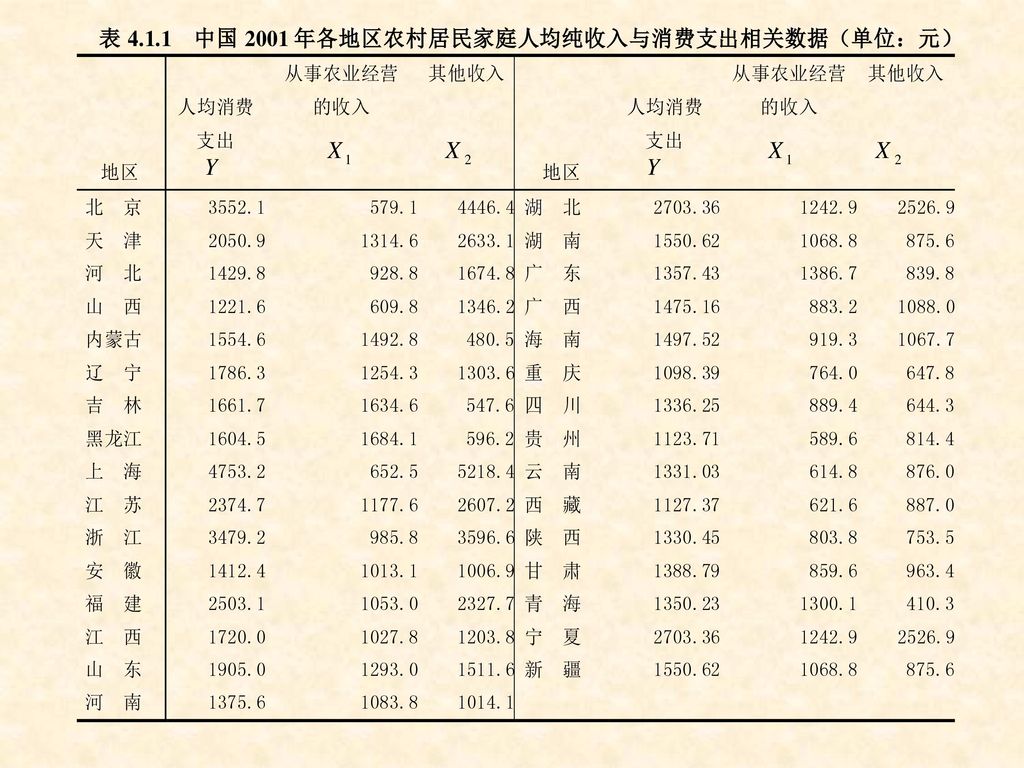
七、案例——中国农村居民人均消费函数 例4.1.4 中国农村居民人均消费支出主要由人均纯收入来决定。
例 中国农村居民人均消费支出主要由人均纯收入来决定。 农村人均纯收入包括:(1)从事农业经营的收入;(2)包括从事其他产业的经营性收入(3)工资性收入;(4)财产收入;(4)转移支付收入。 考察从事农业经营的收入(X1)和其他收入(X2)对中国农村居民消费支出(Y)增长的影响:
从事农业经营的收入;(2)包括从事其他产业的经营性收入(3)工资性收入;(4)财产收入;(4)转移支付收入。 考察从事农业经营的收入(X1)和其他收入(X2)对中国农村居民消费支出(Y)增长的影响:")
40
普通最小二乘法的估计结果:

41
异方差检验

42
进一步的统计检验 (1)G-Q检验 将原始数据按X2排成升序,去掉中间的7个数据,得两个容量为12的子样本。 对两个子样本分别作OLS回归,求各自的残差平方和RSS1和RSS2:
G-Q检验 将原始数据按X2排成升序,去掉中间的7个数据,得两个容量为12的子样本。 对两个子样本分别作OLS回归,求各自的残差平方和RSS1和RSS2:")
43
子样本1: R2=0.7068, RSS1=0.0648 子样本2: R2=0.8339, RSS2=0.2729
(3.18) (4.13) (0.94) R2=0.7068, RSS1=0.0648 子样本2: (0.43) (0.73) (6.53) R2=0.8339, RSS2=0.2729
 (4.13) (0.94) R2=0.7068, RSS1= 子样本2: (0.43) (0.73) (6.53) R2=0.8339, RSS2=")
44
计算F统计量: F= RSS2/RSS1=0.2792/0.0648=4.31 查表 给定=5%,查得临界值 F0.05(9,9)=2.97 判断 F> F0.05(9,9) 否定两组子样方差相同的假设,从而该总体随机项存在递增异方差性。
 否定两组子样方差相同的假设,从而该总体随机项存在递增异方差性。 .")
45
=5%下,临界值 20.05(5)=11.07,拒绝同方差性。
(2)怀特检验 作辅助回归: ( (0.10) (0.21) (-0.12) (1.47) (-1.11) R2 =0.4638 似乎没有哪个参数的t检验是显著的 。但 n R2 =31*0.4638=14.38 =5%下,临界值 20.05(5)=11.07,拒绝同方差性。
怀特检验. 作辅助回归: (-0.04 (0.10) (0.21) (-0.12) (1.47) (-1.11) R2 = 似乎没有哪个参数的t检验是显著的 。但. n R2 =31*0.4638= =5%下,临界值 20.05(5)=11.07,拒绝同方差性。")
46
X2项与X2的平方项的参数的t检验是显著的,且
去掉交叉项后的辅助回归结果 (1.36) (-0.64) (064) (-2.76) (2.90) R2 =0.4374 X2项与X2的平方项的参数的t检验是显著的,且 n R2 =31 =13.56 =5%下,临界值 20.05(4)=9.49,拒绝同方差的原假设。
 (-0.64) (064) (-2.76) (2.90) R2 = X2项与X2的平方项的参数的t检验是显著的,且. n R2 =31 = =5%下,临界值 20.05(4)=9.49,拒绝同方差的原假设。")
47
原模型的加权最小二乘回归 对原模型进行OLS估计,得到随机误差项的近似估计量ěi,以此构成权矩阵2W的估计量; 再以1/| ěi|为权重进行WLS估计,得 各项统计检验指标全面改善

48
§4.2 序列相关性 一、序列相关性概念 二、实际经济问题中的序列相关性 三、序列相关性的后果 四、序列相关性的检验 五、案例

49
如果对于不同的样本点,随机误差项之间不再是不相关的,而是存在某种相关性,则认为出现了序列相关性(Serial Correlation)。
一、序列相关性概念 对于模型 Yi=0+1X1i+2X2i+…+kXki+i i=1,2, …,n 随机项互不相关的基本假设表现为 Cov(i , j)= ij, i,j=1,2, …,n 如果对于不同的样本点,随机误差项之间不再是不相关的,而是存在某种相关性,则认为出现了序列相关性(Serial Correlation)。
=0 ij, i,j=1,2, …,n. 如果对于不同的样本点,随机误差项之间不再是不相关的,而是存在某种相关性,则认为出现了序列相关性(Serial Correlation)。")
50
或

51
i=i-1+i -1<<1
如果仅存在 E(i i+1) i=1,2, …,n 称为一阶列相关,或自相关(autocorrelation) 自相关往往可写成如下形式: i=i-1+i <<1 其中:被称为自协方差系数(coefficient of autocovariance)或一阶自相关系数(first-order coefficient of autocorrelation)
0 i=1,2, …,n. 称为一阶列相关,或自相关(autocorrelation) 自相关往往可写成如下形式: i=i-1+i -1<<1. 其中:被称为自协方差系数(coefficient of autocovariance)或一阶自相关系数(first-order coefficient of autocorrelation)")
52
i是满足以下标准OLS假定的随机干扰项:
由于序列相关性经常出现在以时间序列为样本的模型中,因此,本节将用下标t代表i。

53
二、实际经济问题中的序列相关性 1.经济变量固有的惯性 例如,绝对收入假设下居民总消费函数模型:
大多数经济时间数据都有一个明显的特点:惯性,表现在时间序列不同时间的前后关联上。 例如,绝对收入假设下居民总消费函数模型: Ct=0+1Yt+t t=1,2,…,n 由于消费习惯的影响被包含在随机误差项中,则可能出现序列相关性(往往是正相关 )。
。")
54
因此, vt=3X3t + t,如果X3确实影响Y,则出现序列相关。
2.模型设定的偏误 所谓模型设定偏误(Specification error)是指所设定的模型“不正确”。主要表现在模型中丢掉了重要的解释变量或模型函数形式有偏误。 例如,本来应该估计的模型为 Yt=0+1X1t+ 2X2t + 3X3t + t 但在模型设定中做了下述回归: Yt=0+1X1t+ 1X2t + vt 因此, vt=3X3t + t,如果X3确实影响Y,则出现序列相关。
是指所设定的模型 不正确 。主要表现在模型中丢掉了重要的解释变量或模型函数形式有偏误。 例如,本来应该估计的模型为. Yt=0+1X1t+ 2X2t + 3X3t + t. 但在模型设定中做了下述回归: Yt=0+1X1t+ 1X2t + vt. 因此, vt=3X3t + t,如果X3确实影响Y,则出现序列相关。")
55
又如:如果真实的边际成本回归模型应为: Yt= 0+1Xt+2Xt2+t 其中:Y=边际成本,X=产出。 但建模时设立了如下模型: Yt= 0+1Xt+vt 因此,由于vt= 2Xt2+t, ,包含了产出的平方对随机项的系统性影响,随机项也呈现序列相关性。

56
例如:季度数据来自月度数据的简单平均,这种平均的计算减弱了每月数据的波动性,从而使随机干扰项出现序列相关。
3. 数据的“编造” 在实际经济问题中,有些数据是通过已知数据生成的。 因此,新生成的数据与原数据间就有了内在的联系,表现出序列相关性。 例如:季度数据来自月度数据的简单平均,这种平均的计算减弱了每月数据的波动性,从而使随机干扰项出现序列相关。

57
计量经济学模型一旦出现序列相关性,如果仍采用OLS法估计模型参数,会产生下列不良后果:
还有就是两个时间点之间的“内插”技术往往导致随机项的序列相关性。 二、序列相关性的后果 计量经济学模型一旦出现序列相关性,如果仍采用OLS法估计模型参数,会产生下列不良后果:

58
1. 参数估计量非有效 因为,在有效性证明中利用了 E(NN’)=2I 即同方差性和互相独立性条件。 而且,在大样本情况下,参数估计量虽然具有一致性,但仍然不具有渐近有效性。
=2I 即同方差性和互相独立性条件。 而且,在大样本情况下,参数估计量虽然具有一致性,但仍然不具有渐近有效性。")
59
在变量的显著性检验中,统计量是建立在参数方差正确估计基础之上的,这只有当随机误差项具有同方差性和互相独立性时才能成立。
2. 变量的显著性检验失去意义 在变量的显著性检验中,统计量是建立在参数方差正确估计基础之上的,这只有当随机误差项具有同方差性和互相独立性时才能成立。 其他检验也是如此。

60
区间预测与参数估计量的方差有关,在方差有偏误的情况下,使得预测估计不准确,预测精度降低。
3. 模型的预测失效 区间预测与参数估计量的方差有关,在方差有偏误的情况下,使得预测估计不准确,预测精度降低。 所以,当模型出现序列相关性时,它的预测功能失效。

61
序列相关性检验方法有多种,但基本思路相同:
三、序列相关性的检验 基本思路: 序列相关性检验方法有多种,但基本思路相同: 然后,通过分析这些“近似估计量”之间的相关性,以判断随机误差项是否具有序列相关性。

62
1. 图示法

63
2. 回归检验法 ……

64
如果存在某一种函数形式,使得方程显著成立,则说明原模型存在序列相关性。
回归检验法的优点是:(1)能够确定序列相关的形式,(2)适用于任何类型序列相关性问题的检验。
能够确定序列相关的形式,(2)适用于任何类型序列相关性问题的检验。")
65
3. 杜宾—瓦森(Durbin-Watson)检验法
D-W检验是杜宾(J.Durbin)和瓦森(G.S. Watson)于1951年提出的一种检验序列自相关的方法。该方法的假定条件是: (1)解释变量X非随机; (2)随机误差项i为一阶自回归形式: i=i-1+i
和瓦森(G.S. Watson)于1951年提出的一种检验序列自相关的方法。该方法的假定条件是: (1)解释变量X非随机; (2)随机误差项i为一阶自回归形式: i=i-1+i.")
66
(3)回归模型中不应含有滞后应变量作为解释变量,即不应出现下列形式:
Yi=0+1X1i+kXki+Yi-1+i (4)回归含有截距项 D.W. 统计量: 针对原假设:H0: =0, 构如下造统计量:
回归含有截距项. D.W. 统计量: 针对原假设:H0: =0, 构如下造统计量:")
67
但是,他们成功地导出了临界值的下限dL和上限dU ,且这些上下限只与样本的容量n和解释变量的个数k有关,而与解释变量X的取值无关。

68
(2)给定,由n和k的大小查DW分布表,得临界值dL和dU (3)比较、判断
dL<D.W.<dU 不能确定 dU <D.W.<4-dU 无自相关

69
当D.W.值在2左右时,模型不存在一阶自相关。
4-dU <D.W.<4- dL 不能确定 4-dL <D.W.< 存在负自相关 正相关 不能确定 无自相关 负相关 dL dU dU 4-dL 当D.W.值在2左右时,模型不存在一阶自相关。

70
证明: 展开D.W.统计量: (*)
")
71
这里, 为一阶自回归模型 i=i-1+i 的参数估计。 如果存在完全一阶正相关,即=1,则 D.W. 0 完全一阶负相关,即= -1, 则 D.W. 4 完全不相关, 即=0,则 D.W.2

72
4. 拉格朗日乘数(Lagrange multiplier)检验
拉格朗日乘数检验克服了DW检验的缺陷,适合于高阶序列相关以及模型中存在滞后被解释变量的情形。 它是由布劳殊(Breusch)与戈弗雷(Godfrey)于1978年提出的,也被称为GB检验。
与戈弗雷(Godfrey)于1978年提出的,也被称为GB检验。")
73
对于模型: 如果怀疑随机扰动项存在p阶序列相关: GB检验可用来检验如下受约束回归方程: 约束条件为: H0: 1=2=…=p =0

74
约束条件H0为真时,大样本下: 其中,n为样本容量,R2为如下辅助回归的可决系数: 给定,查临界值2(p),与LM值比较,做出判断,实际检验中,可从1阶、2阶、…逐次向更高阶检验。
,与LM值比较,做出判断,实际检验中,可从1阶、2阶、…逐次向更高阶检验。")
75
如果模型被检验证明存在序列相关性,则需要发展新的方法估计模型。
四、序列相关的补救 如果模型被检验证明存在序列相关性,则需要发展新的方法估计模型。 最常用的方法是广义最小二乘法(GLS: Generalized least squares)和广义差分法(Generalized Difference)。
和广义差分法(Generalized Difference)。")
76
对于模型 1. 广义最小二乘法 Y=X+ 如果存在序列相关,同时存在异方差,即有 是一对称正定矩阵,存在一可逆矩阵D,使得
=DD’

77
变换原模型: D-1Y=D-1X +D-1 即 Y*=X* + * (*) 该模型具有同方差性和随机误差项互相独立性: (*)式的OLS估计:
式的OLS估计:")
78
对的形式进行特殊设定后,才可得到其估计值。
这就是原模型的广义最小二乘估计量(GLS estimators),是无偏的、有效的估计量。 如何得到矩阵? 对的形式进行特殊设定后,才可得到其估计值。
,是无偏的、有效的估计量。 如何得到矩阵? 对的形式进行特殊设定后,才可得到其估计值。")
79
如设定随机扰动项为一阶序列相关形式 i=i-1+i 则

80
广义差分法是将原模型变换为满足OLS法的差分模型,再进行OLS估计。
2. 广义差分法 广义差分法是将原模型变换为满足OLS法的差分模型,再进行OLS估计。 如果原模型 存在

81
广义差分法就是上述广义最小二乘法,但是却损失了部分样本观测值。
可以将原模型变换为: 该模型为广义差分模型,不存在序列相关问题。可进行OLS估计。 注意: 广义差分法就是上述广义最小二乘法,但是却损失了部分样本观测值。 如:一阶序列相关的情况下,广义差分是估计

82
这相当于: 去掉第一行后左乘原模型Y=X+ 。即运用了GLS法,但第一次观测值被排除了。

83
3. 随机误差项相关系数的估计 应用广义最小二乘法或广义差分法,必须已知随机误差项的相关系数1, 2, … , L 。 实际上,人们并不知道它们的具体数值,所以必须首先对它们进行估计。 常用的估计方法有: 科克伦-奥科特(Cochrane-Orcutt)迭代法 杜宾(durbin)两步法
迭代法. 杜宾(durbin)两步法.")
84
以一元线性模型为例: (1)科克伦-奥科特迭代法 首先,采用OLS法估计原模型 Yi=0+1Xi+i
i=1i-1+2i-2+Li-L+i

86
求出i新的“近拟估计值”, 并以之作为样本观测值,再次估计:
i=1i-1+2i-2+Li-L+i

87
类似地,可进行第三次、第四次迭代。 关于迭代的次数,可根据具体的问题来定。
一般是事先给出一个精度,当相邻两次1,2, ,L的估计值之差小于这一精度时,迭代终止。 实践中,有时只要迭代两次,就可得到较满意的结果。两次迭代过程也被称为科克伦—奥科特两步法。

88
该方法仍是先估计1,2,,l,再对差分模型进行估计。
(2)杜宾(durbin)两步法 该方法仍是先估计1,2,,l,再对差分模型进行估计。 第一步,变换差分模型为下列形式: 进行OLS估计,得各Yj(j=i-1, i-2, …,i-l)前的系数1,2, , l的估计值
杜宾(durbin)两步法. 该方法仍是先估计1,2,,l,再对差分模型进行估计。 第一步,变换差分模型为下列形式: 进行OLS估计,得各Yj(j=i-1, i-2, …,i-l)前的系数1,2, , l的估计值.")
90
应用软件中的广义差分法 在Eview/TSP软件包下,广义差分采用了科克伦-奥科特(Cochrane-Orcutt)迭代法估计。 在解释变量中引入AR(1)、AR(2)、…,即可得到参数和ρ1、ρ2、…的估计值。 其中AR(m)表示随机误差项的m阶自回归。在估计过程中自动完成了ρ1、ρ2、…的迭代。
表示随机误差项的m阶自回归。在估计过程中自动完成了ρ1、ρ2、…的迭代。")
91
注意: 如果能够找到一种方法,求得Ω或各序列相关系数j的估计量,使得GLS能够实现,则称为可行的广义最小二乘法(FGLS, Feasible Generalized Least Squares)。 FGLS估计量,也称为可行的广义最小二乘估计量(feasible general least squares estimators)
")
92
可行的广义最小二乘估计量不再是无偏的,但却是一致的,而且在科克伦-奥科特迭代法下,估计量也具有渐近有效性。
前面提出的方法,就是FGLS。

93
4. 虚假序列相关问题 由于随机项的序列相关往往是在模型设定中遗漏了重要的解释变量或对模型的函数形式设定有误,这种情形可称为虚假序列相关(false autocorrelation) ,应在模型设定中排除。 避免产生虚假序列相关性的措施是在开始时建立一个“一般”的模型,然后逐渐剔除确实不显著的变量。

94
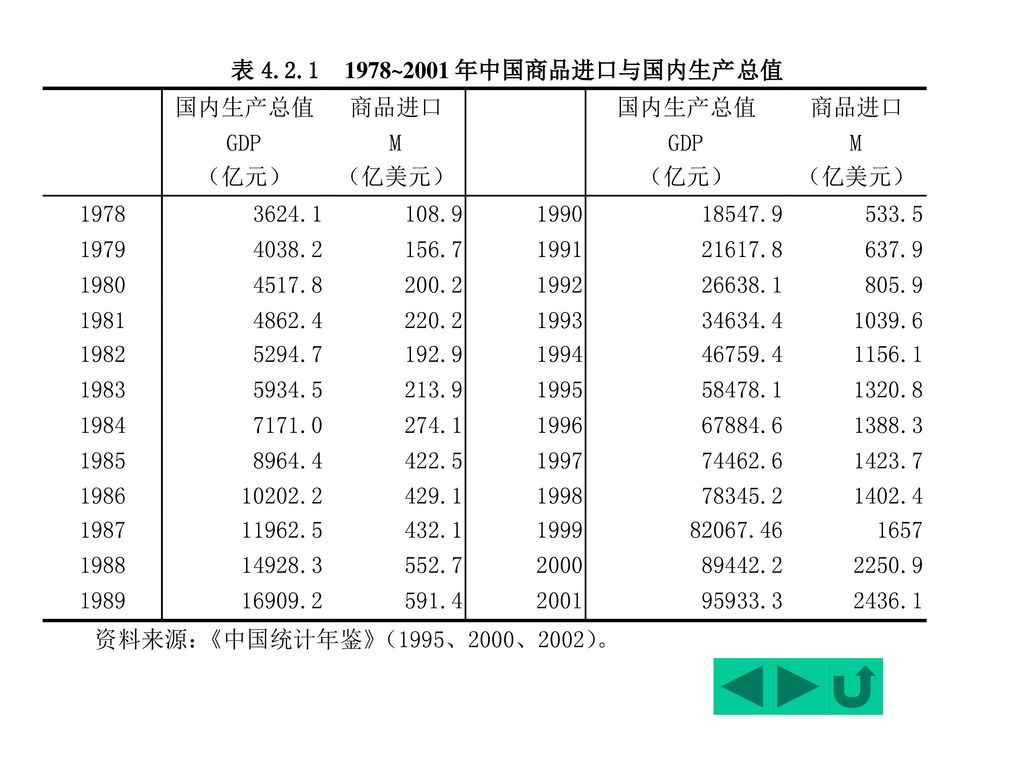
五、案例:中国商品进口模型 经济理论指出,商品进口主要由进口国的经济发展水平,以及商品进口价格指数与国内价格指数对比因素决定的。
由于无法取得中国商品进口价格指数,我们主要研究中国商品进口与国内生产总值的关系。(下表)。
。")
96
1.通过OLS法建立如下中国商品进口方程 (2.32) (20.12) 2. 进行序列相关性检验
 (20.12) 2. 进行序列相关性检验")
97
拉格朗日乘数检验 DW检验 dl=1.27, du=1.45 由于 DW=0.628< dl ,故: 存在正自相关。 2阶滞后:
取=5%,由于n=24,k=2(包含常数项),查表得: dl=1.27, du=1.45 由于 DW=0.628< dl ,故: 存在正自相关。 拉格朗日乘数检验 2阶滞后: (0.23) (-0.50) (6.23) (-3.69) R2=0.6614
,查表得: dl=1.27, du=1.45. 由于 DW=0.628< dl ,故: 存在正自相关。 拉格朗日乘数检验. 2阶滞后: (0.23) (-0.50) (6.23) (-3.69) R2=")
98
于是,LM=220.6614=14.55 取=5%,2分布的临界值20.05(2)=5.991
3.阶滞后: (0.22) (-0.497) (4.541) (-1.842) (0.087) R2=0.6615
 (-0.497) (4.541) (-1.842) (0.087) R2=")
99
于是,LM=210.6614=13.89 取=5%,2分布的临界值20.05(3)=7.815 LM > 20.05(3) 表明: 存在正自相关;但ět-3的参数不显著,说明不存在3阶序列相关性。
 表明: 存在正自相关;但ět-3的参数不显著,说明不存在3阶序列相关性。 .")
100
3. 运用广义差分法进行自相关的处理 (1)采用杜宾两步法估计 第一步,估计模型
3. 运用广义差分法进行自相关的处理 (1)采用杜宾两步法估计 第一步,估计模型 (1.76) (6.64) (-1.76) (5.88) (-5.19) (5.30)
采用杜宾两步法估计 第一步,估计模型. (1.76) (6.64) (-1.76) (5.88) (-5.19) (5.30)")
101
第二步,作差分变换: 则M*关于GDP*的OLS估计结果为: (2.76) (16.46)
 (16.46)")
102
取=5%,DW>du=1.43 (样本容量24-2=22)
表明:已不存在自相关 于是原模型为: 与OLS估计结果的差别只在截距项:

103
在Eviews软包下,2阶广义差分的结果为:
(2)采用科克伦-奥科特迭代法估计 在Eviews软包下,2阶广义差分的结果为: (3.81) (18.45) (6.11) (-3.61) 取=5% ,DW>du=1.66(样本容量:22) 表明:广义差分模型已不存在序列相关性。
采用科克伦-奥科特迭代法估计 在Eviews软包下,2阶广义差分的结果为: (3.81) (18.45) (6.11) (-3.61) 取=5% ,DW>du=1.66(样本容量:22) 表明:广义差分模型已不存在序列相关性。")
104
可以验证: 仅采用1阶广义差分,变换后的模型仍存在1阶自相关性;
采用3阶广义差分,变换后的模型不再有自相关性,但AR[3]的系数的t值不显著。

105
一、多重共线性的概念 二、实际经济问题中的多重共线性 三、多重共线性的后果 四、多重共线性的检验 五、克服多重共线性的方法 六、案例
§4.3 多重共线性 一、多重共线性的概念 二、实际经济问题中的多重共线性 三、多重共线性的后果 四、多重共线性的检验 五、克服多重共线性的方法 六、案例 *七、分部回归与多重共线性

106
如果某两个或多个解释变量之间出现了相关性,则称为多重共线性(Multicollinearity)。
一、多重共线性的概念 对于模型 Yi=0+1X1i+2X2i++kXki+i i=1,2,…,n 其基本假设之一是解释变量是互相独立的。 如果某两个或多个解释变量之间出现了相关性,则称为多重共线性(Multicollinearity)。
。")
107
如果存在 如果存在 c1X1i+c2X2i+…+ckXki=0 i=1,2,…,n
其中: ci不全为0,则称为解释变量间存在完全共线性(perfect multicollinearity)。 如果存在 c1X1i+c2X2i+…+ckXki+vi= i=1,2,…,n 其中ci不全为0,vi为随机误差项,则称为 近似共线性(approximate multicollinearity)或交互相关(intercorrelated)。
。 如果存在. c1X1i+c2X2i+…+ckXki+vi=0 i=1,2,…,n. 其中ci不全为0,vi为随机误差项,则称为 近似共线性(approximate multicollinearity)或交互相关(intercorrelated)。")
108
在矩阵表示的线性回归模型 Y=X+ 中,完全共线性指:秩(X)<k+1,即
中,至少有一列向量可由其他列向量(不包括第一列)线性表出。 如:X2= X1,则X2对Y的作用可由X1代替。
线性表出。 如:X2= X1,则X2对Y的作用可由X1代替。")
109
一般地,产生多重共线性的主要原因有以下三个方面:
二、实际经济问题中的多重共线性 一般地,产生多重共线性的主要原因有以下三个方面: (1)经济变量相关的共同趋势 时间序列样本:经济繁荣时期,各基本经济变量(收入、消费、投资、价格)都趋于增长;衰退时期,又同时趋于下降。
经济变量相关的共同趋势. 时间序列样本:经济繁荣时期,各基本经济变量(收入、消费、投资、价格)都趋于增长;衰退时期,又同时趋于下降。")
110
在经济计量模型中,往往需要引入滞后经济变量来反映真实的经济关系。
横截面数据:生产函数中,资本投入与劳动力投入往往出现高度相关情况,大企业二者都大,小企业都小。 (2)滞后变量的引入 在经济计量模型中,往往需要引入滞后经济变量来反映真实的经济关系。 例如,消费=f(当期收入, 前期收入) 显然,两期收入间有较强的线性相关性。
滞后变量的引入. 在经济计量模型中,往往需要引入滞后经济变量来反映真实的经济关系。 例如,消费=f(当期收入, 前期收入) 显然,两期收入间有较强的线性相关性。")
111
由于完全符合理论模型所要求的样本数据较难收集,特定样本可能存在某种程度的多重共线性。
(3)样本资料的限制 由于完全符合理论模型所要求的样本数据较难收集,特定样本可能存在某种程度的多重共线性。 一般经验: 时间序列数据样本:简单线性模型,往往存在多重共线性。 截面数据样本:问题不那么严重,但多重共线性仍然是存在的。
样本资料的限制. 由于完全符合理论模型所要求的样本数据较难收集,特定样本可能存在某种程度的多重共线性。 一般经验: 时间序列数据样本:简单线性模型,往往存在多重共线性。 截面数据样本:问题不那么严重,但多重共线性仍然是存在的。")
112
三、多重共线性的后果 1. 完全共线性下参数估计量不存在 的OLS估计量为: 如果存在完全共线性,则(X’X)-1不存在,无法得到参数的估计量。
-1不存在,无法得到参数的估计量。")
113
例:对离差形式的二元回归模型 如果两个解释变量完全相关,如x2= x1,则 这时,只能确定综合参数1+2的估计值:

114
近似共线性下,可以得到OLS参数估计量,
但参数估计量方差的表达式为 由于|X’X|0,引起(X’X) -1主对角线元素较大,使参数估计值的方差增大,OLS参数估计量非有效。
 -1主对角线元素较大,使参数估计值的方差增大,OLS参数估计量非有效。")
115
仍以二元线性模型 y=1x1+2x2+ 为例:
恰为X1与X2的线性相关系数的平方r2 由于 r2 1,故 1/(1- r2 )1
1.")
116
当完全不共线时, r2 =0 当近似共线时, 0< r2 <1 多重共线性使参数估计值的方差增大,1/(1-r2)为方差膨胀因子(Variance Inflation Factor, VIF) 当完全共线时, r2=1,
为方差膨胀因子(Variance Inflation Factor, VIF) 当完全共线时, r2=1, .")
117
如果模型中两个解释变量具有线性相关性,例如 X2= X1 ,
3. 参数估计量经济含义不合理 如果模型中两个解释变量具有线性相关性,例如 X2= X1 , 这时,X1和X2前的参数1、2并不反映各自与被解释变量之间的结构关系,而是反映它们对被解释变量的共同影响。 1、 2已经失去了应有的经济含义,于是经常表现出似乎反常的现象:例如1本来应该是正的,结果恰是负的。

118
4. 变量的显著性检验失去意义 存在多重共线性时 参数估计值的方差与标准差变大 容易使通过样本计算的t值小于临界值, 误导作出参数为0的推断 可能将重要的解释变量排除在模型之外

119
变大的方差容易使区间预测的“区间”变大,使预测失去意义。
5. 模型的预测功能失效 变大的方差容易使区间预测的“区间”变大,使预测失去意义。

120
注意: 除非是完全共线性,多重共线性并不意味着任何基本假设的违背; 因此,即使出现较高程度的多重共线性,OLS估计量仍具有线性性等良好的统计性质。 问题在于,即使OLS法仍是最好的估计方法,它却不是“完美的”,尤其是在统计推断上无法给出真正有用的信息。

121
四、多重共线性的检验 多重共线性检验的任务是:
多重共线性表现为解释变量之间具有相关关系,所以用于多重共线性的检验方法主要是统计方法:如判定系数检验法、逐步回归检验法等。 多重共线性检验的任务是: (1)检验多重共线性是否存在; (2)估计多重共线性的范围,即判断哪些变量之间存在共线性。
检验多重共线性是否存在; (2)估计多重共线性的范围,即判断哪些变量之间存在共线性。")
122
(1)对两个解释变量的模型,采用简单相关系数法
1. 检验多重共线性是否存在 (1)对两个解释变量的模型,采用简单相关系数法 求出X1与X2的简单相关系数r,若|r|接近1,则说明两变量存在较强的多重共线性。 (2)对多个解释变量的模型,采用综合统计检验法 若 在OLS法下:R2与F值较大,但t检验值较小,说明各解释变量对Y的联合线性作用显著,但各解释变量间存在共线性而使得它们对Y的独立作用不能分辨,故t检验不显著。
对两个解释变量的模型,采用简单相关系数法. 求出X1与X2的简单相关系数r,若|r|接近1,则说明两变量存在较强的多重共线性。 (2)对多个解释变量的模型,采用综合统计检验法. 若 在OLS法下:R2与F值较大,但t检验值较小,说明各解释变量对Y的联合线性作用显著,但各解释变量间存在共线性而使得它们对Y的独立作用不能分辨,故t检验不显著。")
123
如果存在多重共线性,需进一步确定究竟由哪些变量引起。
2. 判明存在多重共线性的范围 如果存在多重共线性,需进一步确定究竟由哪些变量引起。 (1) 判定系数检验法 使模型中每一个解释变量分别以其余解释变量为解释变量进行回归,并计算相应的拟合优度。 如果某一种回归: Xji=1X1i+2X2i+LXLi 的判定系数较大,说明Xj与其他X间存在共线性。
 判定系数检验法. 使模型中每一个解释变量分别以其余解释变量为解释变量进行回归,并计算相应的拟合优度。 如果某一种回归: Xji=1X1i+2X2i+LXLi. 的判定系数较大,说明Xj与其他X间存在共线性。")
124
具体可进一步对上述回归方程作F检验: 构造如下F统计量 式中:Rj•2为第j个解释变量对其他解释变量的回归方程的决定系数,

125
在模型中排除某一个解释变量Xj,估计模型;
若存在较强的共线性,则Rj•2较大且接近于1,这时(1- Rj•2 )较小,从而Fj的值较大。 因此,给定显著性水平,计算F值,并与相应的临界值比较,来判定是否存在相关性。 另一等价的检验是: 在模型中排除某一个解释变量Xj,估计模型; 如果拟合优度与包含Xj时十分接近,则说明Xj与其它解释变量之间存在共线性。
较小,从而Fj的值较大。 因此,给定显著性水平,计算F值,并与相应的临界值比较,来判定是否存在相关性。 另一等价的检验是: 在模型中排除某一个解释变量Xj,估计模型; 如果拟合优度与包含Xj时十分接近,则说明Xj与其它解释变量之间存在共线性。")
126
以Y为被解释变量,逐个引入解释变量,构成回归模型,进行模型估计。
(2)逐步回归法 以Y为被解释变量,逐个引入解释变量,构成回归模型,进行模型估计。 根据拟合优度的变化决定新引入的变量是否独立。 如果拟合优度变化显著,则说明新引入的变量是一个独立解释变量; 如果拟合优度变化很不显著,则说明新引入的变量与其它变量之间存在共线性关系。
逐步回归法. 以Y为被解释变量,逐个引入解释变量,构成回归模型,进行模型估计。 根据拟合优度的变化决定新引入的变量是否独立。 如果拟合优度变化显著,则说明新引入的变量是一个独立解释变量; 如果拟合优度变化很不显著,则说明新引入的变量与其它变量之间存在共线性关系。")
127
如果模型被检验证明存在多重共线性,则需要发展新的方法估计模型,最常用的方法有三类。
五、克服多重共线性的方法 如果模型被检验证明存在多重共线性,则需要发展新的方法估计模型,最常用的方法有三类。 1. 第一类方法:排除引起共线性的变量 找出引起多重共线性的解释变量,将它排除。 以逐步回归法得到最广泛的应用。 注意:这时,剩余解释变量参数的经济含义和数值都发生了变化。

128
时间序列数据、线性模型:将原模型变换为差分模型:
2. 第二类方法:差分法 时间序列数据、线性模型:将原模型变换为差分模型: Yi=1 X1i+2 X2i++k Xki+ i 可以有效地消除原模型中的多重共线性。 一般讲,增量之间的线性关系远比总量之间的线性关系弱得多。

129
例 如

130
由表中的比值可以直观地看到,增量的线性关系弱于总量之间的线性关系。
进一步分析: Y与C(-1)之间的判定系数为0.9988, △Y与△C(-1)之间的判定系数为0.9567
之间的判定系数为0.9988, △Y与△C(-1)之间的判定系数为")
131
3. 第三类方法:减小参数估计量的方差 多重共线性的主要后果是参数估计量具有较大的方差,所以采取适当方法减小参数估计量的方差,虽然没有消除模型中的多重共线性,但确能消除多重共线性造成的后果。 例如: ①增加样本容量,可使参数估计量的方差减小。

132
*②岭回归法(Ridge Regression)
70年代发展的岭回归法,以引入偏误为代价减小参数估计量的方差,受到人们的重视。 具体方法是:引入矩阵D,使参数估计量为 (*) 其中矩阵D一般选择为主对角阵,即 D=aI a为大于0的常数。 显然,与未含D的参数B的估计量相比,(*)式的估计量有较小的方差。
 其中矩阵D一般选择为主对角阵,即. D=aI. a为大于0的常数。 显然,与未含D的参数B的估计量相比,(*)式的估计量有较小的方差。")
133
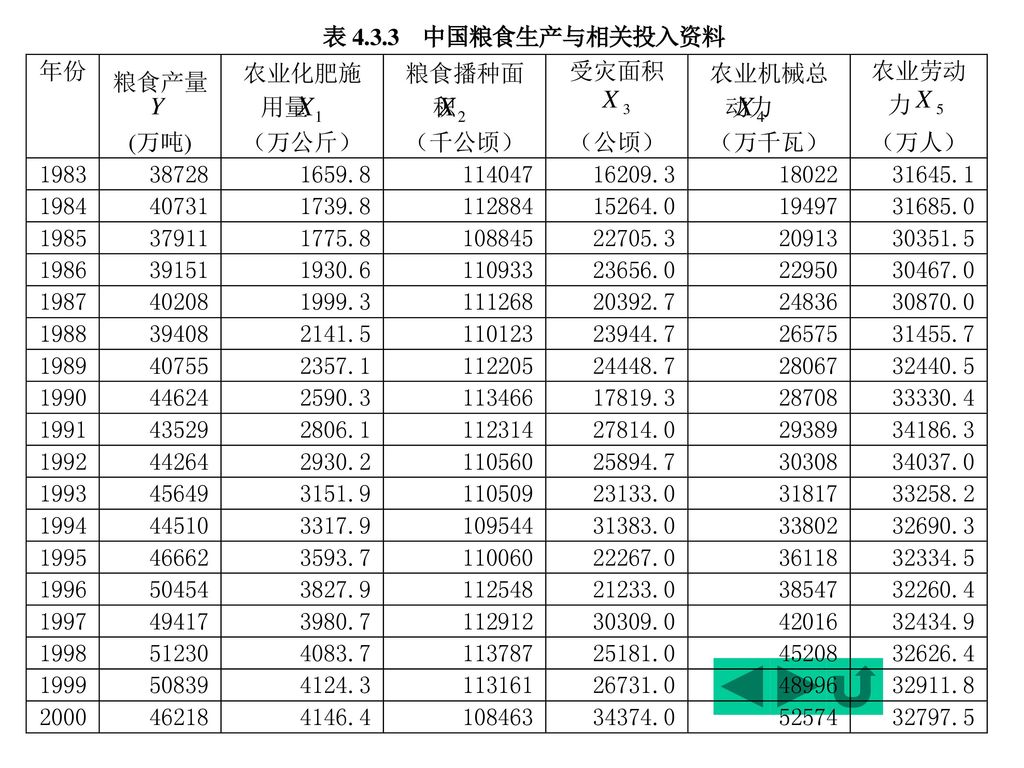
根据理论和经验分析,影响粮食生产(Y)的主要因素有:
六、案例——中国粮食生产函数 根据理论和经验分析,影响粮食生产(Y)的主要因素有: 农业化肥施用量(X1) 粮食播种面积(X2) 成灾面积(X3) 农业机械总动力(X4) 农业劳动力(X5) 已知中国粮食生产的相关数据,建立中国粮食生产函数: Y=0+1 X1 +2 X2 +3 X3 +4 X4 +4 X5 +
的主要因素有: 农业化肥施用量(X1) 粮食播种面积(X2) 成灾面积(X3) 农业机械总动力(X4) 农业劳动力(X5) 已知中国粮食生产的相关数据,建立中国粮食生产函数: Y=0+1 X1 +2 X2 +3 X3 +4 X4 +4 X5 +")
135
R2接近于1; 给定=5%,得F临界值 F0.05(5,12)=3.11
1. 用OLS法估计上述模型: (-0.91) (8.39) (3.32) (-2.81) (-1.45) (-0.14) R2接近于1; 给定=5%,得F临界值 F0.05(5,12)=3.11 F=638.4 > 15.19,故认上述粮食生产的总体线性关系显著成立。但X4 、X5 的参数未通过t检验,且符号不正确,故解释变量间可能存在多重共线性。
 (8.39) (3.32) (-2.81) (-1.45) (-0.14) R2接近于1; 给定=5%,得F临界值 F0.05(5,12)=3.11. F=638.4 > 15.19,故认上述粮食生产的总体线性关系显著成立。但X4 、X5 的参数未通过t检验,且符号不正确,故解释变量间可能存在多重共线性。")
136
2. 检验简单相关系数 列出X1,X2,X3,X4,X5的相关系数矩阵: 发现: X1与X4间存在高度相关性。

137
3. 找出最简单的回归形式 分别作Y与X1,X2,X4,X5间的回归: 可见,应选第一个式子为初始的回归模型。
3. 找出最简单的回归形式 分别作Y与X1,X2,X4,X5间的回归: (25.58) (11.49) R2= F= DW=1.56 (-0.49) (1.14) R2= F= DW=0.12 (17.45) (6.68) R2= F= DW=1.11 (-1.04) (2.66) R2= F= DW=0.36 可见,应选第一个式子为初始的回归模型。
 (11.49) R2= F=132.1 DW=1.56. (-0.49) (1.14) R2=0.075 F=1.30 DW=0.12. (17.45) (6.68) R2= F=48.7 DW=1.11. (-1.04) (2.66) R2= F=7.07 DW=0.36. 可见,应选第一个式子为初始的回归模型。")
138
4. 逐步回归 将其他解释变量分别导入上述初始回归模型,寻找最佳回归方程。

139
5. 结论 回归方程以Y=f(X1,X2,X3)为最优:
为最优:")
140
1. 分部回归法(Partitioned Regression)
*七、分部回归与多重共线性 1. 分部回归法(Partitioned Regression) 对于模型: 将解释变量分为两部分,对应的参数也分为两部分: 在满足解释变量与随机误差项不相关的情况下,可以写出关于参数估计量的方程组:
 对于模型: 将解释变量分为两部分,对应的参数也分为两部分: 在满足解释变量与随机误差项不相关的情况下,可以写出关于参数估计量的方程组:")
141
如果存在 则有 这就是仅以X1作为解释变量时的参数估计量 同样有 这就是仅以X2作为解释变量时的参数估计量。

142
2. 由分部回归法导出 如果一个多元线性模型的解释变量之间完全正交,可以将该多元模型分为多个一元模型、二元模型、…进行估计,参数估计结果不变; 实际模型由于存在或轻或重的共线性,如果将它们分为多个一元模型、二元模型、…进行估计,参数估计结果将发生变化;

143
当模型存在共线性,将某个共线性变量去掉,剩余变量的参数估计结果将发生变化,而且经济含义有发生变化;
严格地说,实际模型由于总存在一定程度的共线性,所以每个参数估计量并不 真正反映对应变量与被解释变量之间的结构关系。

144
§4.4 随机解释变量问题 一、随机解释变量问题 二、实际经济问题中的随机解释变量问题 三、随机解释变量的后果 四、工具变量法 五、案例

145
一、随机解释变量问题 对于模型: 基本假设:解释变量X1,X2,…,Xk是确定性变量。
如果存在一个或多个随机变量作为解释变量,则称原模型出现随机解释变量问题。 假设X2为随机解释变量。对于随机解释变量问题,分三种不同情况:

146
2. 随机解释变量与随机误差项同期无关(contemporaneously uncorrelated),但异期相关。
1. 随机解释变量与随机误差项独立(Independence) 2. 随机解释变量与随机误差项同期无关(contemporaneously uncorrelated),但异期相关。 3. 随机解释变量与随机误差项同期相关(contemporaneously correlated)。
 2. 随机解释变量与随机误差项同期无关(contemporaneously uncorrelated),但异期相关。 3. 随机解释变量与随机误差项同期相关(contemporaneously correlated)。")
147
在实际经济问题中,经济变量往往都具有随机性。
二、实际经济问题中的随机解释变量问题 在实际经济问题中,经济变量往往都具有随机性。 但是在单方程计量经济学模型中,凡是外生变量都被认为是确定性的。 于是随机解释变量问题主要表现于:用滞后被解释变量作为模型的解释变量的情况。

148
例如: (1)耐用品存量调整模型: 耐用品的存量Qt由前一个时期的存量Qt-1和当期收入It共同决定: Qt=0+1It+2Qt-1+t t=1,T 这是一个滞后被解释变量作为解释变量的模型。 但是,如果模型不存在随机误差项的序列相关性,那么随机解释变量Qt-1只与t-1相关,与t不相关,属于上述的第2种情况。

149
合理预期理论认为消费Ct是由对收入的预期Yte所决定的:
(2)合理预期的消费函数模型 合理预期理论认为消费Ct是由对收入的预期Yte所决定的: 预期收入Yte与实际收入Y间存如下关系的假设: 容易推出:
合理预期的消费函数模型. 合理预期理论认为消费Ct是由对收入的预期Yte所决定的: 预期收入Yte与实际收入Y间存如下关系的假设: 容易推出:")
150
Ct-1是一随机解释变量,且与 (t-t-1)高度相关(Why?)。属于上述第3种情况。
高度相关(Why )。属于上述第3种情况。")
151
三、随机解释变量的后果 计量经济学模型一旦出现随机解释变量,且与随机扰动项相关的话,如果仍采用OLS法估计模型参数,不同性质的随机解释变量会产生不同的后果。 下面以一元线性回归模型为例进行说明

152
随机解释变量与随机误差项相关图 拟合的样本回归线可能低估截距项,而高估斜率项。 拟合的样本回归线高估截距项,而低估斜率项。 (a)正相关
(b)负相关 拟合的样本回归线可能低估截距项,而高估斜率项。 拟合的样本回归线高估截距项,而低估斜率项。
负相关. 拟合的样本回归线可能低估截距项,而高估斜率项。 拟合的样本回归线高估截距项,而低估斜率项。")
153
1. 如果X与相互独立,得到的参数估计量仍然是无偏、一致估计量。
对一元线性回归模型: OLS估计量为: 随机解释变量X与随机项的关系不同,参数OLS估计量的统计性质也会不同。 1. 如果X与相互独立,得到的参数估计量仍然是无偏、一致估计量。 已经得到证明

154
2. 如果X与同期不相关,异期相关,得到的参数估计量有偏、但却是一致的。
kt的分母中包含不同期的X;由异期相关性知:kt与t相关,因此,

155
3. 如果X与同期相关,得到的参数估计量有偏、且非一致。
但是 3. 如果X与同期相关,得到的参数估计量有偏、且非一致。 前面证明中已得到

156
注意: 如果模型中带有滞后被解释变量作为解释变量,则当该滞后被解释变量与随机误差项同期相关时,OLS估计量是有偏的、且是非一致的。 即使同期无关,其OLS估计量也是有偏的,因为此时肯定出现异期相关。

157
四、工具变量法 模型中出现随机解释变量且与随机误差项相关时,OLS估计量是有偏的。
如果随机解释变量与随机误差项异期相关,则可以通过增大样本容量的办法来得到一致的估计量; 但如果是同期相关,即使增大样本容量也无济于事。这时,最常用的估计方法是工具变量法(Instrument variables)。
。")
158
工具变量:在模型估计过程中被作为工具使用,以替代模型中与随机误差项相关的随机解释变量。选择为工具变量的变量必须满足以下条件:
1. 工具变量的选取 工具变量:在模型估计过程中被作为工具使用,以替代模型中与随机误差项相关的随机解释变量。选择为工具变量的变量必须满足以下条件: (1)与所替代的随机解释变量高度相关; (2)与随机误差项不相关; (3)与模型中其它解释变量不相关,以避免出现多重共线性。
与所替代的随机解释变量高度相关; (2)与随机误差项不相关; (3)与模型中其它解释变量不相关,以避免出现多重共线性。")
159
以一元回归模型的离差形式为例说明如下: 2. 工具变量的应用
2. 工具变量的应用 以一元回归模型的离差形式为例说明如下: 用OLS估计模型,相当于用xi去乘模型两边、对i求和、再略去xii项后得到正规方程: 解得: (*)
")
160
由于Cov(Xi,i)=E(Xii)=0,意味着大样本下:
(xii)/n0 表明大样本下: 成立,即OLS估计量具有一致性。
/n0. 表明大样本下: 成立,即OLS估计量具有一致性。")
161
然而,如果Xi与i相关,即使在大样本下,也不存在 (xii)/n0 ,则
在大样本下也不成立,OLS估计量不具有一致性。 如果选择Z为X的工具变量,那么在上述估计过程可改为:

162
利用E(zii)=0,在大样本下可得到:
这种求模型参数估计量的方法称为工具变量法(instrumental variable method),相应的估计量称为工具变量法估计量(instrumental variable (IV) estimator)。
,相应的估计量称为工具变量法估计量(instrumental variable (IV) estimator)。")
163
对于矩阵形式: Y=X+ 采用工具变量法(假设X2与随机项相关,用工具变量Z替代)得到的正规方程组为: 参数估计量为: 其中:
称为工具变量矩阵

164
3. 工具变量法估计量是一致估计量 一元回归中,工具变量法估计量为: 两边取概率极限得:

165
如果工具变量Z选取恰当,即有 因此: 注意: 1. 在小样本下,工具变量法估计量仍是有偏的。

166
2. 工具变量并没有替代模型中的解释变量,只是在估计过程中作为“工具”被使用。
2. 工具变量并没有替代模型中的解释变量,只是在估计过程中作为“工具”被使用。 上述工具变量法估计过程可等价地分解成下面的两步OLS回归: 第一步,用OLS法进行X关于工具变量Z的回归:

167
容易验证仍有: 因此,工具变量法仍是Y对X的回归,而不是对Z的回归。

168
3. 如果模型中有两个以上的随机解释变量与随机误差项相关,就必须找到两个以上的工具变量。但是,一旦工具变量选定,它们在估计过程被使用的次序不影响估计结果(Why?)。
4. OLS可以看作工具变量法的一种特殊情况。 5. 如果1个随机解释变量可以找到多个互相独立的工具变量,人们希望充分利用这些工具变量的信息,就形成了广义矩方法(Generalized Method of Moments, GMM)
")
169
在GMM中,矩条件大于待估参数的数量,于是如何求解成为它的核心问题。 工具变量法是GMM的一个特例。
6. 要找到与随机扰动项不相关而又与随机解释变量相关的工具变量并不是一件很容易的事 可以用Xt-1作为原解释变量Xt的工具变量。

170
五、 案例——中国居民人均消费函数 例4.4.1 在例2.5.1的中国居民人均消费函数的估计中,采用OLS估计了下面的模型:
由于:居民人均消费支出(CONSP)与人均国内生产总值(GDPP)相互影响,因此,
与人均国内生产总值(GDPP)相互影响,因此,")
171
容易判断GDPP与同期相关(往往是正相关),OLS估计量有偏并且是非一致的(低估截距项而高估计斜率项 )。
(13.51) (53.47) R2= F= DW= SSR=
 (53.47) R2= F= DW= SSR=")
172
如果用GDPPt-1为工具变量,可得如下工具变量法估计结果:
(14.84) (56.04) R2 = F= DW= SSR=
 (56.04) R2 = F= DW= SSR=")
173
如果1个随机解释变量可以找到多个互相独立的工具变量,人们希望充分利用这些工具变量的信息,就形成了广义矩方法(GMM)。在GMM中,矩条件大于待估参数的数量,于是如何求解成为它的核心问题。
IV是GMM的一个特例。













>")




>")




