Download presentation
Presentation is loading. Please wait.

1
第七章 序 列

2
EWIEWS提供序列的各种统计图、统计方法及过程。当用第4、6章描述的方法向工作文件中读入数据后,你就可以对这些数据进行统计分析和图表分析。
EWIEWS可以计算一个序列的各种统计量并可用表单、表、图等形式将其表现出来。视图包括最简单的曲线图一直到核密度估计。通过过程可以用原有的序列创建新的序列。这些过程包括季节调整、指数平滑和Hodrick-Prescott滤波。 在第8章我们将讲述包括多个序列的组和组对象的统计方法及过程。 其中,§7.1~§7.6在序列的view下拉菜单里,§7.8~ §7.10在序列的procedure下拉菜单里。

3
§7.1 表单和图示 打开工作文件,双击一个序列名或者在单击序列名后单击“show”,即进入序列的对话框。单击“view”可看到菜单分为四个区,第一部分为序列显示形式,第二和第三部分提供数据统计方法,第四部分是转换选项和标签。

4
表单和图示: 表单: 用表单的形式显示原始数据。 曲线图: 按时间顺序或者将观测值一一连线显示。这种方法最适用于时间序列。
曲线图: 按时间顺序或者将观测值一一连线显示。这种方法最适用于时间序列。 直方图: 用柱形显示数据。这种方法适用于显示那些只有微小变化的序列。 钉形图: 用直线显示数据。即用垂直的钉形线显示数据。 季度分区图、季度连线图: 这些方法按季度或月度显示数据,适用于数据频度为季度和月度的工作文件。季度分区图把数据按季度分成四个区,每年同一季度的数据进行连线。同时每个季度的期望值水平也显示出来。季度连线图是在同一坐标轴上把每年同一季度的数据连线显示。 关于图表显示的制定与修改的技术讨论见第十章。

5
§7.2 描述统计量 以直方图显示序列的频率分布。直方图将序列的长度按等间距划分,显示观测值落入每一个区间的个数。
§7.2 描述统计量 以直方图显示序列的频率分布。直方图将序列的长度按等间距划分,显示观测值落入每一个区间的个数。 同直方图一起显示的还有一些标准的描述统计量。这些统计量都是由样本中的观测值计算出来的。如图:

6
均值 (mean) 即序列的平均值,用序列数据的总和除以数据的个数。
中位数 (median) 即从小到大排列的序列的中间值。是对序列分布中心的一个粗略估计。 最大最小值 (max and min) 序列中的最大最小值。 标准差(Standard Deviation) 标准差衡量序列的离散程度。计算公式如下 N是样本中观测值的个数, 是样本均值。
 即从小到大排列的序列的中间值。是对序列分布中心的一个粗略估计。 最大最小值 (max and min) 序列中的最大最小值。 标准差(Standard Deviation) 标准差衡量序列的离散程度。计算公式如下. N是样本中观测值的个数, 是样本均值。")
7
偏度(Skewness) 衡量序列分布围绕其均值的非对称性。计算公式如下
是变量方差的有偏估计。如果序列的分布是对称的,S值为0;正的S值意味着序列分布有长的右拖尾,负的S值意味着序列分布有长的左拖尾。

8
峰度(Kurtosis) 度量序列分布的凸起或平坦程度,计算公式如下
,正态分布的K值为3。如果K值大于3, 意义同S中 分布的凸起程度大于正态分布;如果K值小于3,序列分布相对于正态分布是平坦的。

9
Jarque-Bera 检验 检验序列是否服从正态分布。统计量计算公式如下
S为偏度,K为峰度,k是序列估计式中参数的个数 在正态分布的原假设下,J-B统计量是自由度为2的 分布。直方图中显示的概率值(P值)是J-B统计量超出原假设下的观测值的概率。如果该值很小,则拒绝原假设。当然,在不同的显著性水平下的拒绝域是不一样的。
是J-B统计量超出原假设下的观测值的概率。如果该值很小,则拒绝原假设。当然,在不同的显著性水平下的拒绝域是不一样的。")
10
§7.3 统计量的检验 这部分是对序列均值、中位数、方差的单假设检验。选择View/tests for descriptive stats/simple hypothesis tests, 就会出现下面的序列分布检验对话框:

11
1、均值检验 原假设是序列x的期望值 ,备选假设是 ,即
如果你不指定序列x的标准差,Eviews将在t – 统计量中使用该标准差的估计值s 。 是x的样本估计值,N是x的观测值的个数。在原假设下,如果x服从正态分布,t统计量是自由度为N-1的t分布。

12
如果你给定x的标准差,Eviews计算Z统计量:
是指定的x的标准差。在原假设下,如果x服从标准差为 的正态分布,则Z统计量服从标准正态分布。 要进行均值检验,在Mean内输入 值。如果已知标准差,想要计算Z统计量,在右边的框内输入标准差值。可以输入任何数或标准Eviews表达式,下页我们给出检验的输出结果。

13
表中的Probability值是P值(边际显著水平)。在双边假设下,如果这个值小于检验的显著水平,如0
。在双边假设下,如果这个值小于检验的显著水平,如0")
14
检验的原假设为序列x的方差等于 ,备选假设为双边的,x的方差不等于 ,即
2、方差检验 检验的原假设为序列x的方差等于 ,备选假设为双边的,x的方差不等于 ,即 Eviews计算 统计量,计算公式如下 N为观测值的个数, 为x的样本均值。在原假设下,如果x服从正态分布, 统计量是服从自由度为N-1的 分布。 要进行方差检验,在Variance处填入在原假设下的方差值。可以填入任何正数或表达式。

15
原假设为序列x的中位数等于m,备选假设为双边假设,x的中位数不等于m,即
3、中位数检验 原假设为序列x的中位数等于m,备选假设为双边假设,x的中位数不等于m,即 Eviews提供了三个以排序为基础的无参数的检验统计量。方法的主要参考来自于Conover(1980)和Sheskin(1997)。 要进行中位数检验,在Median右边的框内输入中位数的值,可以输入任何数字表达式。
和Sheskin(1997)。 要进行中位数检验,在Median右边的框内输入中位数的值,可以输入任何数字表达式。")
16
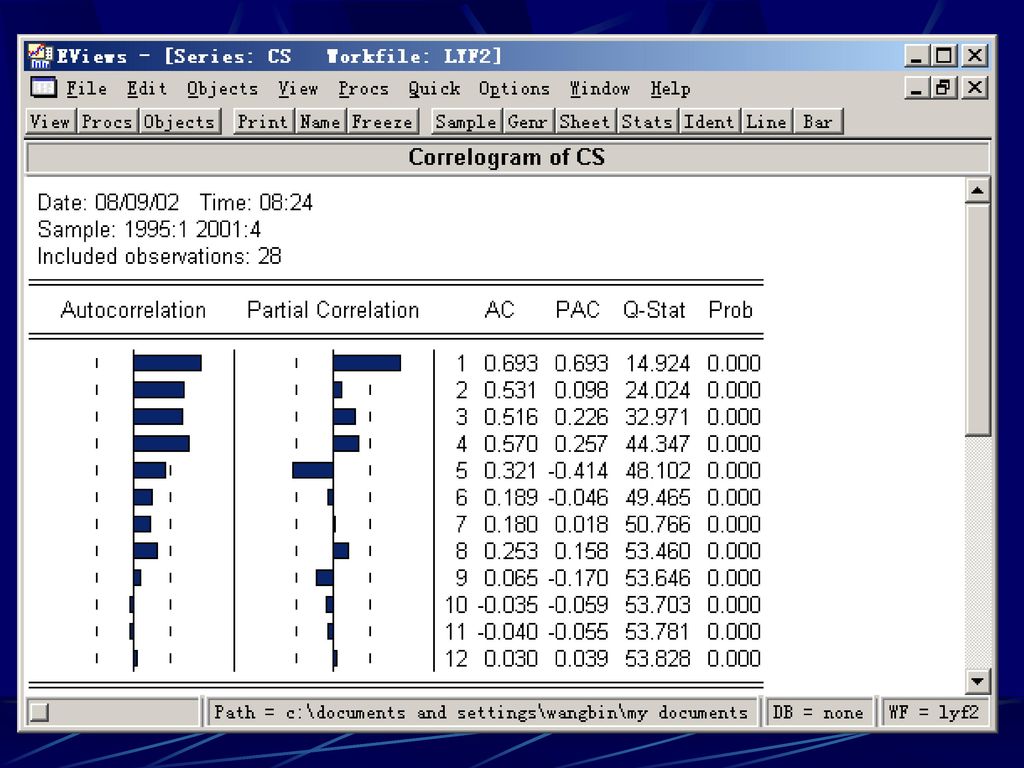
§7.4 相关图 显示确定滞后期的自相关函数以及偏相关函数。这些函数通常只对时间序列有意义。当你选择View/Correlogram…显示如下对话框(Correlogram Specification)。 一阶差分d(x)=x-x(-1)、二阶差分d(x)-d(x(-1))=x-2x(-1)+x(-2) 可选择水平值、一阶差分或二阶差分的相关图。你也可以指定显示相关图的最高滞后阶数。在框内输入一个正整数, 就可以显示相关图及相关统计量。
=x-x(-1)、二阶差分d(x)-d(x(-1))=x-2x(-1)+x(-2) 可选择水平值、一阶差分或二阶差分的相关图。你也可以指定显示相关图的最高滞后阶数。在框内输入一个正整数, 就可以显示相关图及相关统计量。")
18
§7.4.1 自相关(Autocorrelations, AC)
序列y 滞后k阶的自相关由下式估计 是样本y的均值,这是相距k期值的相关系数。如果 ,意味着序列是一阶序列相关。如果 随着滞后阶数k的增加而呈几何级数减小,表明序列服从低阶自回归过程。如果 在小的滞后阶数下趋于零,表明序列服从低阶动平均过程。13章有对AR及MA过程的更完整的描述。

19
注意Eviews的自相关估计与理论描述的估计有一点不同:
这个区别是为了计算简便而产生的。Eviews把整个样本均值作为和的均值。当所有的表达式是一致估计时,Eviews的方程在有限个样本中向零偏倚。 虚线之间的区域是由自相关中正负两倍于估计标准差所夹成的。如果自相关值在这个区域内,则在显著水平为5%的情形下与零没有显著区别。

20
§7.4.2 偏自相关(Partial Autocorrelations, PAC)
滞后k阶的偏相关是当 对 作回归时 的系数。叫它偏相关是因为它度量了k期间距的相关而不考虑k-1…期的相关。如果这种自相关的形式可由滞后小于k阶的自相关表示,那么偏相关在k期滞后下的值趋于零。 一个纯的P阶自回归过程AR(P)的偏相关在P阶截尾,而纯的动平均函数的偏相关过程渐进趋于零。
的偏相关在P阶截尾,而纯的动平均函数的偏相关过程渐进趋于零。")
21
Eviews在P阶滞后下估计偏相关的计算式如下
是在k阶滞后时的自相关的估计值。 这是偏相关的一致估计。要得到的更确切的估计,需进行回归 偏相关中的虚线表示的是估计标准差的正负二倍。如果偏相关落在该区域内,则在5%的显著水平下与零无显著差别(截尾)。
。")
22
相关图的最后两列显示的是Ljung-Box Q-统计量及它们的P值。 k阶滞后的Q-统计量是原假设为序列没有k阶自相关的统计量。计算式如下
是j阶自相关系数,T是观测值的个数。Q-检验经常用于检验一个序列是否是白噪声。在实际应用中选择检验的滞后期数是个问题。如果选得过小,检验就会检验不到高阶滞后的序列相关。但如果选得太大,检验就没有什么效果,因为在一个滞后水平上的显著相关会被其它滞后水平的不显著的相关所冲淡。

23
§7.5 单位根检验 13章将讨论了平稳及非平稳的时间序列,讨论了Dickey-Fuller和Phillips-Perren单位根检验,可检验序列是否平稳。选择检验类型,决定单位根检验是否用原始数据、一阶差分、二阶差分,是否包括截距或趋势以及检验回归的滞后阶数,以及在Eviews中进行单位根检验的更多细节问题。

24
§7.6 标签(label) 这部分是对序列的描述,表格如下: 除了Last Update,可以编辑序列标签中的任何项。Last Update显示序列上一次修改的时间。每一部分包括一行,只有Remarks and History包括20行,注意如果填入了一行(在20行中),最后一行将被删除。Name是序列在工作文件中显示的名字。可以通过编辑这一部分给序列改名。如果在Display Name中填入序列名,这个名字将会在图表中替换标准的对象的名字。Object Name、Display Name可包括空格、区分大小写。
,最后一行将被删除。Name是序列在工作文件中显示的名字。可以通过编辑这一部分给序列改名。如果在Display Name中填入序列名,这个名字将会在图表中替换标准的对象的名字。Object Name、Display Name可包括空格、区分大小写。")
25
§7.7 建立新序列 一、由方程创建Generate by Equation允许你使用已有序列的表达式来建立新的序列,序列表达式的书写规则见第5章。 二、重置样本Resampling 这一过程从序列观测值中随机选取并建立一个新序列。你可以指定提取新样本时置换(允许给定观测值被多次提取)或不置换。从序列窗口选择Procs/Resample,出现下列窗口,提示指定各种选择:
或不置换。从序列窗口选择Procs/Resample,出现下列窗口,提示指定各种选择:")
26
§7.8 季节调整(Seasonal Adjustment)
时间序列的季度、月度观测值常常显示出月和季度的循环变动。例如:冰激凌的销售在每一年的夏季很好,玩具的销售在12月圣诞节期间达到顶峰。季节调整从一个序列中除去季节变动,显示出序列潜在的趋势分量。只有季度、月度数据才能做季节调整。要对一个序列进行季节调整,在序列窗口的工具栏中单击Procs/Seasonal Adjustment,显示季节调整对话框: 有4种季节调整方法,Census X12方法、X11方法、Tramo/Seats方法和移动平均方法。

27
经济时间序列的分解 为了及时、准确地把握经济周期波动,一般都采用月度或季度数据来进行分析和预测,而对于每个经济指标的月度或季度时间序列来说,都包含着四种变动要素:长期趋势要素T (Trend)、循环要素C (Cylce)、季节变动要素S (Seasonal)和不规则要素I (Irregular)。 长期趋势要素代表经济时间序列长期的趋势特性。循环要素是以数年为周期的一种周期性变动,它可能是一种景气变动,经济变动或其他周期变动,它可以代表经济或某个特定工业的波动。季节变动要素是每年重复出现的循环变动,以12个月或4个季度为周期的周期性影响,是由温度、降雨、年中的月份,假期和政策等引起的。季节变动要素和循环要素的区别在于,季节变动要素是在固定间距(如年、季、月或周)中自我循环,而循环要素是从一个周期变动到另一个周期,间距比较长且不固定的一种周期性波动。不规则要素又称随机因子、残余变动或噪声,其变动无规则可循,这类因素是由偶然发生的事故引起的,如:故障、罢工、意外事故、地震、水灾、恶劣气候、战争、法令更改、测定误差等。
中自我循环,而循环要素是从一个周期变动到另一个周期,间距比较长且不固定的一种周期性波动。不规则要素又称随机因子、残余变动或噪声,其变动无规则可循,这类因素是由偶然发生的事故引起的,如:故障、罢工、意外事故、地震、水灾、恶劣气候、战争、法令更改、测定误差等。")
28
在经济分析中,季节变动要素和不规则要素往往遮盖或混淆了经济发展中的客观变化,给研究和分析经济发展趋势和判断目前经济处于什么状态带来困难,因此需要在经济分析之前,将经济时间序列进行分解,剔除其中的季节变动要素和不规则要素。经济时间序列分解模型,依据时间序列的四个构成要素在模型中的相互关系,可以表现为多种不同的形式,但就一般而言,基本的分解模型只有两类:即加法模型和乘法模型。 一、加法模型 加法模型的一般形式为: 式中T、C、S 和 I 均表现为绝对量。 二、乘法模型 乘法模型的一般形式为 式中T为绝对量;C、S 和 I 均为相对量。

29
下面是中国的工业总产值的时间序列基于乘法模型分解的四种变动要素的图形 。
我国工业总产值的时间序列图形

30
工业总产值的趋势·循环(TC)要素图形 注:利用X-11季节调整方法计算(乘法模型)
要素图形 注:利用X-11季节调整方法计算(乘法模型)")
31
工业总产值的循环要素(C)图形 注:利用阶段平均方法计算
图形 注:利用阶段平均方法计算")
32
工业总产值的季节变动要素(S)图形 注:利用X-11季节调整方法计算(乘法模型)
图形 注:利用X-11季节调整方法计算(乘法模型)")
33
工业总产值的不规则要素(I)图形 注:利用X-11季节调整方法计算(乘法模型)
图形 注:利用X-11季节调整方法计算(乘法模型)")
34
§ Census X12方法 EVIEWS是将美国国势调查局的X12季节调整程序直接安装到EVIEWS子目录中,建立了一个接口程序。EVIEWS进行季节调整时将执行以下步骤: 1.给出一个被调整序列的说明文件和数据文件; 2.利用给定的信息执行X12程序; 3.返回一个输出文件,将调整后的结果存在EVIEWS工作文件中。 X12的EVIEWS接口菜单只是一个简短的描述,EVIEWS还提供了一些菜单不能实现的接口功能,更一般的命令接口程序。

35
调用X12季节调整过程,在序列窗口选择Procs/Seasonal Adjustment / Census X12,打开一个对话框:

36
一、季节调整选择(Seasonal Ajustment Option)
① X11方法(X11 Method) 这一部分指定季节调整分解的形式:乘法;加法;伪加法(此形式必须伴随ARIMA说明);对数加法。注意乘法;伪加法和对数加法不允许有零和负数。 ② 季节滤波(Seasonal Filter) 当估计季节因子时,允许选择季节移动平均滤波(可能是月别移动平均项数),缺省是X12自动确定。近似地可选择(X11 defaul)缺省选择。需要注意以下几点: ·在对话框指定的季节滤波应用于所有频率。如果想对不同的频率用不同的滤波,应该使用更一般的X12命令语言。 ·如果序列短于20年,X12不允许指定3×15的季节滤波。 ③ 趋势滤波(Trend Filter (Henderson)) 当估计趋势—循环分量时,允许你指定亨德松移动平均的项数,可以输入大于1和小于等于101的奇数,缺省是由X12自动选择。
 这一部分指定季节调整分解的形式:乘法;加法;伪加法(此形式必须伴随ARIMA说明);对数加法。注意乘法;伪加法和对数加法不允许有零和负数。 ② 季节滤波(Seasonal Filter) 当估计季节因子时,允许选择季节移动平均滤波(可能是月别移动平均项数),缺省是X12自动确定。近似地可选择(X11 defaul)缺省选择。需要注意以下几点: ·在对话框指定的季节滤波应用于所有频率。如果想对不同的频率用不同的滤波,应该使用更一般的X12命令语言。 ·如果序列短于20年,X12不允许指定3×15的季节滤波。 ③ 趋势滤波(Trend Filter (Henderson)) 当估计趋势—循环分量时,允许你指定亨德松移动平均的项数,可以输入大于1和小于等于101的奇数,缺省是由X12自动选择。")
37
④ 存调整后的分量序列名(Component Series to save)
X12将被调整的序列名作为缺省列在Base name框中,可以改变序列名。在下面的多选钮中选择要保存的季节调整后分量序列,X12将加上相应的后缀存在工作文件中: ·最终的季节调整后序列(_SA); ·最终的季节因子(_SF); ·最终的趋势—循环序列(_TC); ·最终的不规则要素分量(_IR); ·季节/贸易日因子(_D16); ·假日/贸易日因子(_D18);
; ·最终的季节因子(_SF); ·最终的趋势—循环序列(_TC); ·最终的不规则要素分量(_IR); ·季节/贸易日因子(_D16); ·假日/贸易日因子(_D18);")
38
二、ARIMA选择(ARIMA Option)
X12还允许在季节调整前对被调整序列建立一个合适的ARIMA模型。

39
1.数据转换(Data Transformation)
在配备一个合适的ARMA模型之前允许转换序列。缺省是不转换;Auto选择是根据计算出来的AIC准则自动确定是不做转换还是进行对数转换;Logistic选择将序列y转换为log(y/(1-y)),序列的值被定义在0和1之间;Box-Cox power选择要求提供一个参数λ,做下列转换:
),序列的值被定义在0和1之间;Box-Cox power选择要求提供一个参数λ,做下列转换:")
40
2.ARIMA说明(ARIMA Spec) 允许你在2种不同的方法中选择ARIMA模型。 ·Specify in-line 选择
要求提供ARIMA模型阶数的说明(p d q)(P D Q) p 非季节的AR阶数 d 非季节的差分阶数 q 非季节的MA阶数 P 季节AR阶数 D 季节差分阶数 Q 季节MA阶数 缺省的指定是“(0 1 1)(0 1 1)”是指季节的IMA模型: L是滞后算子,这里季节差分是指,季度数据时s =4;月度数据时s =12。下面是一些例子: (1 0 0) (0 1 1) (1 0 1)(1 0 0)
(P D Q) p. 非季节的AR阶数. d. 非季节的差分阶数. q. 非季节的MA阶数. P. 季节AR阶数. D. 季节差分阶数. Q. 季节MA阶数. 缺省的指定是 (0 1 1)(0 1 1) 是指季节的IMA模型: L是滞后算子,这里季节差分是指,季度数据时s =4;月度数据时s =12。下面是一些例子: (1 0 0) (0 1 1) (1 0 1)(1 0 0)")
41
注意在模型中总的AR、MA、和差分的系数不超过25;AR或MA参数的最大延迟为24;在ARIMA因子中的最大差分阶数不超过3。
· Select from file 选择 X12将从一个外部文件提供的说明集合中选择ARIMA模型。EVIEWS将利用一个包含一系列缺省模型指定说明的文件(X12A.MDL): (0 1 1)(0 1 1) * (0 1 2)(0 1 1) X (2 1 0)(0 1 1) X (0 2 2)(0 1 1) X (2 1 2)(0 1 1) 缺省说明用“*”表示,除最后一个外,中间的用“X”结尾。有2个选择: ·Select best 检验列表中的所有模型,选一个最小预测误差的模型,缺省是第一个模型。 ·Select by out-of-sample-fit 对模型的评价用外部样本误差,缺省是用内部样本预测误差。
: (0 1 1)(0 1 1) * (0 1 2)(0 1 1) X. (2 1 0)(0 1 1) X. (0 2 2)(0 1 1) X. (2 1 2)(0 1 1) 缺省说明用 * 表示,除最后一个外,中间的用 X 结尾。有2个选择: ·Select best 检验列表中的所有模型,选一个最小预测误差的模型,缺省是第一个模型。 ·Select by out-of-sample-fit 对模型的评价用外部样本误差,缺省是用内部样本预测误差。")
42
3.回归因子选择(Regressors) 允许你在ARIMA模型中指定一些外生回归因子,利用多选钮可选择常数项,或季节虚拟变量,事先定义的回归因子可以捕捉贸易日和节假日的影响。
 允许你在ARIMA模型中指定一些外生回归因子,利用多选钮可选择常数项,或季节虚拟变量,事先定义的回归因子可以捕捉贸易日和节假日的影响。")
43
三、贸易日和节假日影响 可以在进行季节调整和利用ARIMA模型得到用于季节调整的向前/向后预测值之前,先去掉确定性的影响(例如节假日和贸易日影响)。首先要选择(Ajustment Option)是否进行这项调整?,确定在那一个步骤里调整:在ARIMA步骤,还是X-11步骤? · Trading Day Effects消除贸易日影响有2种选择,依赖于序列是流量序列还是存量序列(诸如存货)。对于流量序列还有2种选择,是对周工作日影响进行调整还是对仅对周日-周末影响进行调整。存量序列仅对月度序列进行调整,需给出被观测序列的月天数。 · Holiday effects 仅对流量序列做节假日调整。对每一个节日,你必须提供一个数,是到这个节日之前影响的持续天数。 Easter 复活节 Labor 劳动节 Thanksgiving 感恩节 Christmas 圣诞节 注意这些节日只针对美国,不能应用于其他国家。
。对于流量序列还有2种选择,是对周工作日影响进行调整还是对仅对周日-周末影响进行调整。存量序列仅对月度序列进行调整,需给出被观测序列的月天数。 · Holiday effects 仅对流量序列做节假日调整。对每一个节日,你必须提供一个数,是到这个节日之前影响的持续天数。 Easter 复活节. Labor 劳动节. Thanksgiving 感恩节. Christmas 圣诞节. 注意这些节日只针对美国,不能应用于其他国家。")
44
四、外部影响(Outlier Effects)
外部影响调整也是分别在ARIMA步骤和X11步骤中进行。然而,必须在X11步骤中作了贸易日/节日调整,才能在X11步骤中做外部调整,而且只能做附加的外部调整; 在ARIMA步骤中有4种外部调整: 附加的外部调整; 水平变换; 暂时的水平变化; 弯道影响。

45
五、诊断(Diagnostics) 这项选择提供了各种诊断: ① 季节因素的稳定性分析(Stability Analysis of Seasonals) · Sliding spans 移动间距 检验被调整序列在固定大小的移动样本上的变化; · Historical revisions 历史修正 检验被调整序列增加一个新观测值,即增加一个样本时的变化。 ② 其他诊断(Other Diagnostics) 还可以选择显示各种诊断输出: · Residual diagnostics 残差诊断 作为对所配备的ARIMA模型的检验,报告一个标准的残差诊断(例如自相关函数和Q-统计量),注意这个选择要求估计ARIMA模型,如果没有,则这个诊断被应用于原始序列。
 还可以选择显示各种诊断输出: · Residual diagnostics 残差诊断 作为对所配备的ARIMA模型的检验,报告一个标准的残差诊断(例如自相关函数和Q-统计量),注意这个选择要求估计ARIMA模型,如果没有,则这个诊断被应用于原始序列。")
46
· Outlier detection 外部探测 利用指定的ARIMA模型自动地查出和报告外部影响。这个选择要求指定一个ARIMA模型或至少一个外生回归因子,假如没有回归模型,这项选择被忽略。
· Spectral plot 谱图 显示被调整序列和经修正后的不规则序列的不同的谱图。红色垂直点线是季节频率,黑色垂线贸易日频率。如果你在这些垂线观测到峰,意味着不充分的调整。如果你选择了这一项,谱数据将以矩阵形式(名字给定为:序列名_SA_SP1和序列名_SA_SP2)被存在工作文件中。矩阵的第一列是频率,第二列是10个相应频率的对数谱。
被存在工作文件中。矩阵的第一列是频率,第二列是10个相应频率的对数谱。")
47
§ X11方法 X-11法是美国商务部标准的季节调整方法(乘法模型、加法模型),乘法模型适用于序列可被分解为趋势项与季节项的乘积,加法模型适用于序列可被分解为趋势项与季节项的和。乘法模型只适用于序列值都为正的情形。
,乘法模型适用于序列可被分解为趋势项与季节项的乘积,加法模型适用于序列可被分解为趋势项与季节项的和。乘法模型只适用于序列值都为正的情形。")
48
如果在季节调整对话框中选择X-11选项,调整后的序列及因子序列会被自动存入Eviews工作文件中,在过程的结尾X-11简要的输出及错误信息也会在序列窗口中显示。
关于调整后的序列的名字。Eviews在原序列名后加SA,但你也可以改变,这将被存储在工作文件中。 需要注意,季节调整的观测值的个数是有限制的。X-11只作用于含季节数据的序列,需要至少4整年的数据,最多能调整20年的月度数据及30年的季度数据。

49
§ 移动平均方法 X-11法与移动平均法的最大不同是:X-11法中季节因子年与年有可能不同,而在移动平均法中,季节因子被假设为是一样的。 § tramo/Seats Tramo(Time Series Regression with ARIMA Noise, Missing Observation, and Outliers)是对具有缺失观测值,ARIMA误差、几种外部影响的回归模型完成估计、预测和插值的程序。 Seats(Signal Extraction in ARIMA Time Series)是基于ARIMA模型的将可观测时间序列分解为不可观测分量的程序。这两个程序是有Victor Gomez 和Agustin Maravall 开发的。 当选择了Pross/Seasonal Adjustment/Tramo Seats时,EVIEWS执行外部程序,将数据输给外部程序,然后将结果返回EVIEWS。
是对具有缺失观测值,ARIMA误差、几种外部影响的回归模型完成估计、预测和插值的程序。 Seats(Signal Extraction in ARIMA Time Series)是基于ARIMA模型的将可观测时间序列分解为不可观测分量的程序。这两个程序是有Victor Gomez 和Agustin Maravall 开发的。 当选择了Pross/Seasonal Adjustment/Tramo Seats时,EVIEWS执行外部程序,将数据输给外部程序,然后将结果返回EVIEWS。")
50
§7.9 指数平滑 指数平滑是可调整预测的简单方法。当你只有少数观测值时这种方法是有效的。与使用固定系数的回归预测模型不同,指数平滑法的预测用过去的预测误差进行调整。下面,我们对 Eviews中的指数平滑法作简要讨论。 要用指数平滑法预测,选择Procs/Exponential Smoothing 显示如下对话框

51
1.平滑方法 在5种方法中选择一种方法。 2.平滑参数 你既可以指定平滑参数也可以让Eviews估计它们的值。要估计参数,在填充区内输入字母e,Eviews估计使误差平方和最小的参数值。如果估计参数值趋于1,这表明序列趋于随机游走,最近的值对估计将来值最有用。要指定参数值,在填充区内输入参数值,所有参数值在0-1之间,如果你输入的参数值超出这一区间,Eviews将会估计这个参数。 3.平滑后的序列名 你可以为平滑后的序列指定一个名字,Eviews在原序列后加SM指定平滑后的序列名,你也加以可以改变。 4.估计样本 你必须指定预测的样本区间(不管你是否选择估计参数)。缺省值是当前工作文件的样本区间。Eviews将从样本区间末尾开始计算预测值。 5.季节循环 你可以改变每年的季节数(缺省值为每年12个月、4个季度)。这个选项允许你预测不规则间距的数据,在空白处输入循环数。
。缺省值是当前工作文件的样本区间。Eviews将从样本区间末尾开始计算预测值。 5.季节循环 你可以改变每年的季节数(缺省值为每年12个月、4个季度)。这个选项允许你预测不规则间距的数据,在空白处输入循环数。")
52
这种单指数平滑方法适用于序列值在一个常数均值上下随机波动的情况,无趋势及季节要素。 平滑后的序列 计算式如下
1、单指数平滑(一个参数) 这种单指数平滑方法适用于序列值在一个常数均值上下随机波动的情况,无趋势及季节要素。 平滑后的序列 计算式如下 = 为平滑因子。 越小, 越平缓,重复迭代,可得到 由此可知为什么这种方法叫指数平滑,y的预测值是y过去值的加权平均,而权数被定义为以时间为指数的形式。 单指数平滑的预测对所有未来的观测值都是常数。这个常数为 (对所有的K>0),T是估计样本的期末值。要开始递归,我们需要 和 的初值。Eview使用原来观测值的均值来开始递归。Bowermen和O’Connell(1979)建议 值在0.01到0.03之间较好。你也可以让Eviews估计使一步预测误差平方和最小的 值。
 这种单指数平滑方法适用于序列值在一个常数均值上下随机波动的情况,无趋势及季节要素。 平滑后的序列 计算式如下. = 为平滑因子。 越小, 越平缓,重复迭代,可得到. 由此可知为什么这种方法叫指数平滑,y的预测值是y过去值的加权平均,而权数被定义为以时间为指数的形式。 单指数平滑的预测对所有未来的观测值都是常数。这个常数为 (对所有的K>0),T是估计样本的期末值。要开始递归,我们需要 和 的初值。Eview使用原来观测值的均值来开始递归。Bowermen和O’Connell(1979)建议 值在0.01到0.03之间较好。你也可以让Eviews估计使一步预测误差平方和最小的 值。")
53
这种方法是将单指数平滑进行两次(使用相同的参数)。适用于有线性趋势的序列。序列y的双指数平滑以递归形式定义为
2、双指数平滑(一个参数) 这种方法是将单指数平滑进行两次(使用相同的参数)。适用于有线性趋势的序列。序列y的双指数平滑以递归形式定义为 S是单指数平滑后的序列,D是双指数平滑序列。注意双指数平滑是阻尼因子为 的单指数平滑方法。 双指数平滑的预测如下 最后一个表达式表明双指数平滑的预测有线性趋势,截距为 ,斜率为
 这种方法是将单指数平滑进行两次(使用相同的参数)。适用于有线性趋势的序列。序列y的双指数平滑以递归形式定义为. S是单指数平滑后的序列,D是双指数平滑序列。注意双指数平滑是阻尼因子为 的单指数平滑方法。 双指数平滑的预测如下. 最后一个表达式表明双指数平滑的预测有线性趋势,截距为 ,斜率为.")
54
3、Holt-winters乘法模型(三个参数)
这种方法适用于序列具有线性时间趋势以及乘法模型的季节变差。 的平滑序列 由下式给出 其中:a表示截距 b表示趋势 为乘法模型的季节因子 在0-1之间,为阻尼因子。在Cycle for Season中指定s为季节频率,预测值由下式计算 季节因子用最后期的s估计。

55
4、Holt-Winter加法模型(三个参数)
该方法适用于具有线性时间趋势和加法模型的季节变差。 平滑后的序列 由下式给出 其中:a表示截距: b表示趋势: 为加法模型的季节因子: 在0-1之间,为阻尼因子。在Cycle for Season中指定s为季节频率,预测值由下式计算 季节因子用最后期的s估计。

56
5、Holt-Winters—无季节趋势(两个参数)
这种方法适用于具有线性时间趋势无季节变差的情形。这种方法与双指数平滑法一样以线性趋势无季节成分进行预测。双指数平滑法只用了一个参数,这种方法用两个参数。 平滑后的序列 由下式给出 a表示截距;b表示趋势。这两个参数由如下递归式定义 在0-1之间,为阻尼因子。这是一种有两个参数的指数平滑法。 预测值计算如下 这些预测值具有线性趋势,截距为 ,斜率为 。注意到无季节的Holt-Winters与 的加法及乘法模型并不相同, 只限制季节因子不变为非零常数。

57
§7.10 Hodrick-Prescott(HP)滤波
设经济时间序列为Y= ,趋势要素为T= ,n为样本长度。一般地,时间序列 中的不可观测部分趋势 常被定义为下面最小化问题的解: (1) 其中,正实数 表示在分解中长期趋势和周期波动占的权数, 是延迟算子多项式 (2) 将(2)代入(1)式,则HP滤波的问题就是使下面损失函数最小,即
 其中,正实数 表示在分解中长期趋势和周期波动占的权数, 是延迟算子多项式. (2) 将(2)代入(1)式,则HP滤波的问题就是使下面损失函数最小,即.")
58
最小化问题用 来调整趋势的变化,并随着 的增大而增大。这里存在一个权衡问题,要在趋势要素对实际序列的跟踪程度和趋势光滑度之间作一个选择。 =0时,满足最小化问题的趋势等于序列 ; 增加时,估计趋势中的变化总数相对于序列中的变化减少,即 越大,估计趋势越光滑; 趋于无穷大时,估计趋势将接近线性函数。一般经验地, 的取值如下: HP滤波的运用比较灵活,它不象阶段平均法那样依赖于经济周期峰和谷的确定。它把经济周期看成宏观经济波动对某些缓慢变动路径的偏离,这种路径在期间内单调地增长,所以称之为趋势。HP滤波增大了经济周期的频率,使周期波动减弱。

59
要使用Hodrick-Prescott滤波来平滑序列,选择Procs/ Hodrick Prescott Filter出现下面的HP滤波对话框:
首先对平滑后的序列给一个名字,Eviews将默认一个名字,也可填入一个新的名字。然后给定平滑参数的值,年度数据取100,季度和月度数据分别取1600和14400。不允许填入非整数的数据。点击OK后,Eviews与原序列一起显示处理后的序列。注意只有包括在当前工作文件样本区间内的数据才被处理,平滑后序列区间外的数据都为NA。

60
§ 命 令 命令的语法结构:序列名称、圆点、视图或过程名,再加上括号里的可选项。比如,如果要察看序列名为lwage的直方图和描述统计量,则命令形式为lwage.hist;如果要检验序列hrs的均值是否等于3,则命令形式为hrs.teststat(mean=3);如果要得到序列gdp滞后20阶的相关图,则命令形式为gdp.correl(20)。如果要用HP滤波光滑序列gdp,参数为1600,并且光滑后的序列保存为gdp_hp,则命令格式为gdp.hpf(1600) gdp_hp。要得到关于序列的命令和选项的详细说明,参见“命令和语法说明”(command and programming reference)。 返回
;如果要得到序列gdp滞后20阶的相关图,则命令形式为gdp.correl(20)。如果要用HP滤波光滑序列gdp,参数为1600,并且光滑后的序列保存为gdp_hp,则命令格式为gdp.hpf(1600) gdp_hp。要得到关于序列的命令和选项的详细说明,参见 命令和语法说明 (command and programming reference)。 返回.")
Similar presentations


: 写出 5 的倍数( 6 个) 2 , 4 , 6 , 8 , 10 , 12 , 14 , 16 , 18 , 20 5 , 10 , 15 , 20 , 25 , 30.>")















 10.4 探索三角形 相似的条件(2).>")
 , 单位毫秒 暂停程序执行使用Sleep函数 Sleep(持续时间), 单位毫秒 引用这两个函数时,必须包含头文件>")