Download presentation
1
第 6 章 複迴歸之一

2
6.1複迴歸模型 需要多個預測變數 雙預測變數的第一階模型 當有兩個預測變數X1與 X2時,迴歸模型為: (6.1)
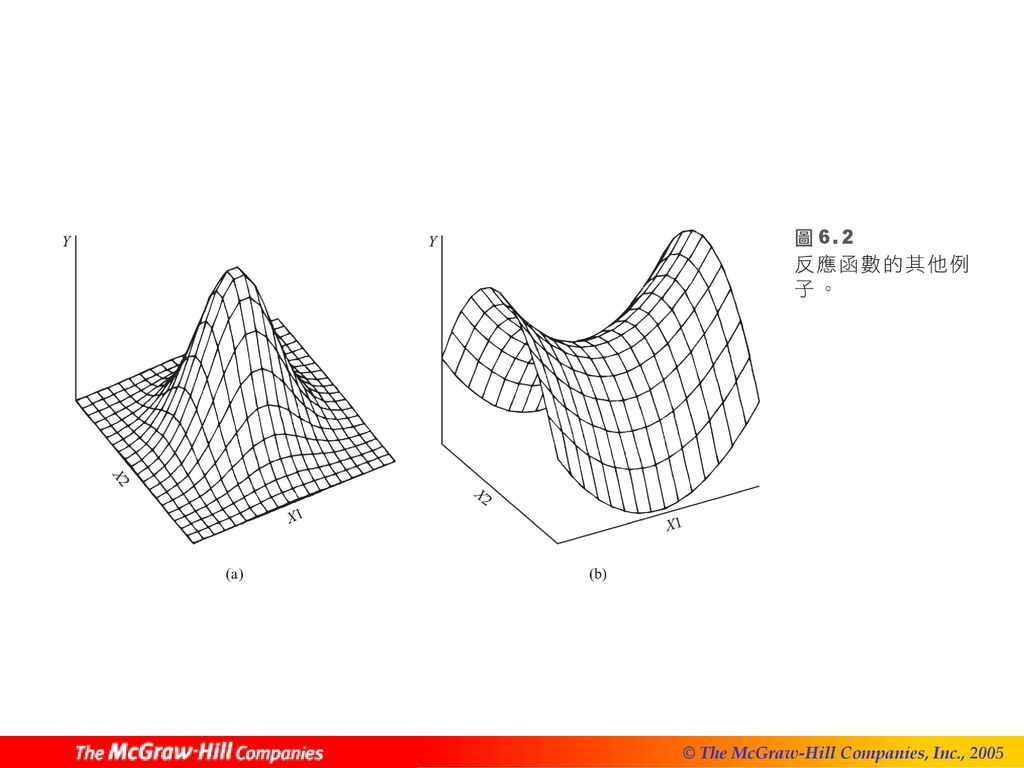
假設 ,則模型(6.1)迴歸函數為: (6.2) 圖6.1所示為以下反應平面的部份圖示: (6.3)
迴歸函數為: (6.2) 圖6.1所示為以下反應平面的部份圖示: (6.3)")
3
迴歸係數的意義 用前面的案例說明,當X2固定在水準X2 = 2時,迴歸函數(6.3)成為: (6.4)
成為: (6.4)")
5
超過兩個預測變數的第一階模型 現在考慮一個配適有p – 1 個預測變數 的迴歸模型: (6.5) 上面的迴歸模型稱為「具p – 1個預測變數的第一階模型」,此模型也可以寫成: (6.5a) 或令,則可以寫成: (6.5b) 假設,則迴歸模型(6.5)的反應函數為: (6.6)
 或令,則可以寫成: (6.5b) 假設,則迴歸模型(6.5)的反應函數為: (6.6)")
6
一般線性迴歸模型 在迴歸模型中變數 ,所代表的意義不一定是完全不同或沒有關係的預測變數(例如Xk可以是X1 · X2),因此我們定義下面的一般線性迴歸模型: (6.7) 其中, 為參數, 為已知之常數, 獨立服從 i = 1,…, n

7
如果令 ,則迴歸模型(6.7)可以寫成: (6.7a) 或 (6.7b) 因為 ,所以迴歸模型(6.7)的反應函數為 (6.8) 所以具有常態誤差項的一般線性迴歸模型隱含著觀 測值Yi為相互獨立、服從平均數 、變異數 之常態分配。

8
個預測變數 質性的預測變數 考慮利用病患年齡(X1)與性別(X2)預測在醫院中的住院天數(Y),定義X2如下: 則第一階迴歸模型為: (6.9) 其中
與性別(X2)預測在醫院中的住院天數(Y),定義X2如下: 則第一階迴歸模型為: (6.9) 其中")
9
迴歸模型(6.9)的反應函數為: (6.10) 對男性病患而言,X2 = 0,所以反應函數(6.10)成為: (6.10a) 對女性病患而言,X2 = 1,所以反應函數(6.10)成為: (6.10b) 一般而言,當質性變數有c種分類情形時,模型中需要c – 1個指標變數來描述,在住院天數的案例中,殘障程度是一個質性變數,它可以用下面的兩個指標變數來描述:

10
於是透過病患年齡、性別、殘障程度所構成的第一階迴歸模型為:
(6.11) 其中,
 其中,")
11
多項式迴歸 反應函數為曲線型式,下面是單一預測變數多項式迴歸模型的一種情形: (6.12) 經轉換後之變數 變數經過轉換後的模型可能含有複雜的曲線型式反應函數,不過它仍是一般線性迴歸模型的特例,考慮下面這個變數Y經轉換後的模型: (6.13) 此模型的反應曲面雖然複雜,不過還是可以依照一般線性迴歸模型來處理。令 ,則迴歸模型(6.13)成為:
 此模型的反應曲面雖然複雜,不過還是可以依照一般線性迴歸模型來處理。令 ,則迴歸模型(6.13)成為:")
12
很多模型可以轉換成一般線性迴歸模型,例如:
(6.14) 進行 的變數轉換,它就是一個一般線性迴歸 模型: 交互作用 一般線性迴歸模型(6.7)也包含了不可加性或具有交互作用效應的,例如下面的雙預測變數模型: (6.15) 此時由於交互作用項存在模型中,造成反應函數複雜化,但是迴歸模型(6.15)仍然是一個一般線性迴歸模型,當我們令,則迴歸模型(6.15)可以寫成:
 進行 的變數轉換,它就是一個一般線性迴歸. 模型: 交互作用. 一般線性迴歸模型(6.7)也包含了不可加性或具有交互作用效應的,例如下面的雙預測變數模型: (6.15) 此時由於交互作用項存在模型中,造成反應函數複雜化,但是迴歸模型(6.15)仍然是一個一般線性迴歸模型,當我們令,則迴歸模型(6.15)可以寫成:")
13
組合情形 考慮下面的迴歸模型: (6.16) 該模型中同時有預測變數的線性項、二次項與代表交互作用效應的交叉乘積項,我們定義: 則迴歸模型(6.16)可以寫成:
 該模型中同時有預測變數的線性項、二次項與代表交互作用效應的交叉乘積項,我們定義: 則迴歸模型(6.16)可以寫成:")
15
一般線性迴歸模型中的線性意義 所謂對參數線性是指模型可以寫成: (6.17) 其中 是由預測變數的水準所決定出的值
 其中 是由預測變數的水準所決定出的值")
16
6.2 矩陣形式下的一般線性迴歸模型 在將一般線性迴歸模型(6.7)用矩陣的形式來表示前,先定義下列矩陣: 其中 (6.18)
用矩陣的形式來表示前,先定義下列矩陣: 其中 (6.18)")
17
所以接下來可以用矩陣的形式來表示一般線性迴歸模型(6.7)如下:
(6.19) 其中 Y為反應向量, 為參數向量, X為常數矩陣, 為獨立常態隨機變數之向量
 其中. Y為反應向量, 為參數向量, X為常數矩陣, 為獨立常態隨機變數之向量.")
18
,共變異矩陣為: 因此隨機向量Y之期望值 為: (6.20) 而Y之共變異矩陣與 相同為: (6.21)
 而Y之共變異矩陣與 相同為: (6.21)")
19
6.3 迴歸係數的估計 將(1.8)中的最小平方準則推廣至一般線性迴歸模型(6.7)中,成為: (6.22)
最小平方估計量就是在滿足能使Q最小化的 ,用向量b表示所得到的最小平方估計量 : (6.23)
")
20
一般線性迴歸模型(6.19)的最小平方標準方程式為:
(6.24) 而最小平方估計量b為: (6.25) 根據常態誤差迴歸模型(6.19)所得到的最大概似估計 量與(6.25)的最小平方估計量b相同,我們可以先將 (1.26)的概似函數推廣至複迴歸模型,如下: (6.26)
 而最小平方估計量b為: (6.25) 根據常態誤差迴歸模型(6.19)所得到的最大概似估計. 量與(6.25)的最小平方估計量b相同,我們可以先將. (1.26)的概似函數推廣至複迴歸模型,如下: (6.26)")
21
6.4 配適值及殘差 將配適值 組成向量 ,殘差項 組成殘差向量e: (6.27)
")
22
我們可以將配適值向量 與殘差向量e分別表示成:
(6.28) (6.29) 將配適值 用H矩陣表示為: (6.30) 其中, (6.30a)
 (6.29) 將配適值 用H矩陣表示為: (6.30) 其中, (6.30a)")
23
同樣地,殘差向量e可以表示為: (6.31) 而共變異矩陣則可以表示為: (6.32) 其估計式為 (6.33)
 而共變異矩陣則可以表示為: (6.32) 其估計式為 (6.33)")
24
6.5 變異數分析的結果 平方和與均方 變異數分析的平方和透過(5.89)可以用矩陣表示為: (6.34) (6.35) (6.36)
可以用矩陣表示為: (6.34) (6.35) (6.36)")
25
在表6.1中列出了上面的變異數分析結果以及均方
MSR與MSE: (6.37) (6.38) 迴歸關係的F檢定 現在我們先考慮反應變數Y與預測變數 間是否存在迴歸關係之檢定,虛無假設與對立假設分別為: (6.39a)
 (6.38) 迴歸關係的F檢定. 現在我們先考慮反應變數Y與預測變數 間是否存在迴歸關係之檢定,虛無假設與對立假設分別為: (6.39a)")
26
採用檢定統計量: (6.39b) 控制型一錯誤的機率不大於 ,決策法則為: (6.39c)
 控制型一錯誤的機率不大於 ,決策法則為: (6.39c)")
27
複判定係數 我們用 表示,其定義為: (6.40) 它是用來表示Y的總變異中與預測變數 有關的部份,當p – 1 = 1時,則複判定係數 成為(2.72)的簡單判定係數 ,複判定係數 與簡單判定係數 有相同的範圍限制: (6.41) 當所有 為0時(k = 1,…, p–1), 之值為零,當所有的觀測值Y均落於所配適的迴歸曲面上時,亦即 ,此時 =1。
 當所有 為0時(k = 1,…, p–1), 之值為零,當所有的觀測值Y均落於所配適的迴歸曲面上時,亦即 ,此時 =1。")
28
由於 之值會因為採用大量的預測變數X而增大,
有些學者建議採用調整的複判定係數,用符號 表 示,其定義為: (6.42) 複相關係數 複相關係數是複判定係數 的正平方根R: (6.43) 當迴歸模型(6.19)中只有一個預測變數X,也就是當p–1 = 1時,複相關係數R等於(2.73)中相關係數r的絕對值。
 複相關係數. 複相關係數是複判定係數 的正平方根R: (6.43) 當迴歸模型(6.19)中只有一個預測變數X,也就是當p–1 = 1時,複相關係數R等於(2.73)中相關係數r的絕對值。")
29
6.6 迴歸參數的推論 最小平方估計量與最大概似估計量b為不偏之估計量: (6.44) 其共變異矩陣: (6.45)
 其共變異矩陣: (6.45)")
30
可以藉由下面的公式算出: (6.46) 而估計的共變異矩陣 : (6.47) (6.48)
 而估計的共變異矩陣 : (6.47) (6.48)")
31
的區間估計 對於常態誤差迴歸模型(6.19),有下面的推論: (6.49) 因此關於信賴係數 下 的信賴區間為: (6.50) 的檢定 關於的檢定: (6.51a)
,有下面的推論: (6.49) 因此關於信賴係數 下 的信賴區間為: (6.50) 的檢定 關於的檢定: (6.51a)")
32
可以採用檢定統計量: (6.51b) 檢定的法則為: (6.51c) 聯合推論 Bonferroni聯合信賴區間可用於同步估計數個迴歸係數,若要進行全族信賴係數 下的g個(g ≤ p)參數的聯合估計: (6.52) 其中, (6.52a)
 其中, (6.52a)")
33
6.7 平均反應的估計與新觀測值的預測 的區間估計 給定 的值為 ,其平均 反應為 ,定義向量 為: (6.53)
給定 的值為 ,其平均 反應為 ,定義向量 為: (6.53) 則所要估計的平均反應 為: (6.54)
 則所要估計的平均反應 為: (6.54)")
34
我們用 表示對應向量 的平均反應之估計: (6.55) 上面的估計量也是一個不偏的估計量: (6.56) 其變異數為: (6.57) 可以將上面的變異數轉換為估計係數的共變異矩陣 之函數: (6.57a)
")
35
估計的變異數 如下: (6.58) 的 信賴界線為: (6.59) 迴歸曲面的信賴域 在 的水準下 的信賴域之邊界點,可以根據下面的公式得到: (6.60) 其中, (6.60a)
 其中, (6.60a)")
36
多個平均反應的同步信賴區間 在全族信賴係數 下,要估計在不同的 水準下,多個平均反應 的同步信賴區間,可以採用下面的兩種方法: 1.對於所關心的 ,利用(6.60)的Working-Hotelling 信賴域界線: (6.61) 2.採用Bonferroni同步信賴區間,如果要同時進行g 個區間估計,則Bonferroni信賴界線為: (6.62)
 2.採用Bonferroni同步信賴區間,如果要同時進行g. 個區間估計,則Bonferroni信賴界線為: (6.62)")
37
其中, (6.62a) 新觀測值的預測 對應於一個特定水準 ,一個新觀測值 的 預測界線為: (6.63) (6.63a)
 新觀測值的預測 對應於一個特定水準 ,一個新觀測值 的 預測界線為: (6.63) (6.63a)")
38
預測 處下的m個觀測值之平均 如果我們在 處下抽選m個新觀測值,則可以預測其平均數 的 預測界線: (6.64) 其中, (6.64a) g個新觀測值的預測 在全族信賴係數 下,g個不同 水準下的新觀測值之預測問題,根據Scheffé同步預測程序,其預測界線為:

39
(6.65) 其中, (6.65a) 當然,我們也可以利用Bonferroni同步預測程序, 在全族信賴係數 下,對g個不同 水準下進 行新觀測值之預測: (6.66) (6.66a) 隱藏的外插之注意事項
 (6.66a) 隱藏的外插之注意事項.")
40
6.8 診斷與矯正測量

42
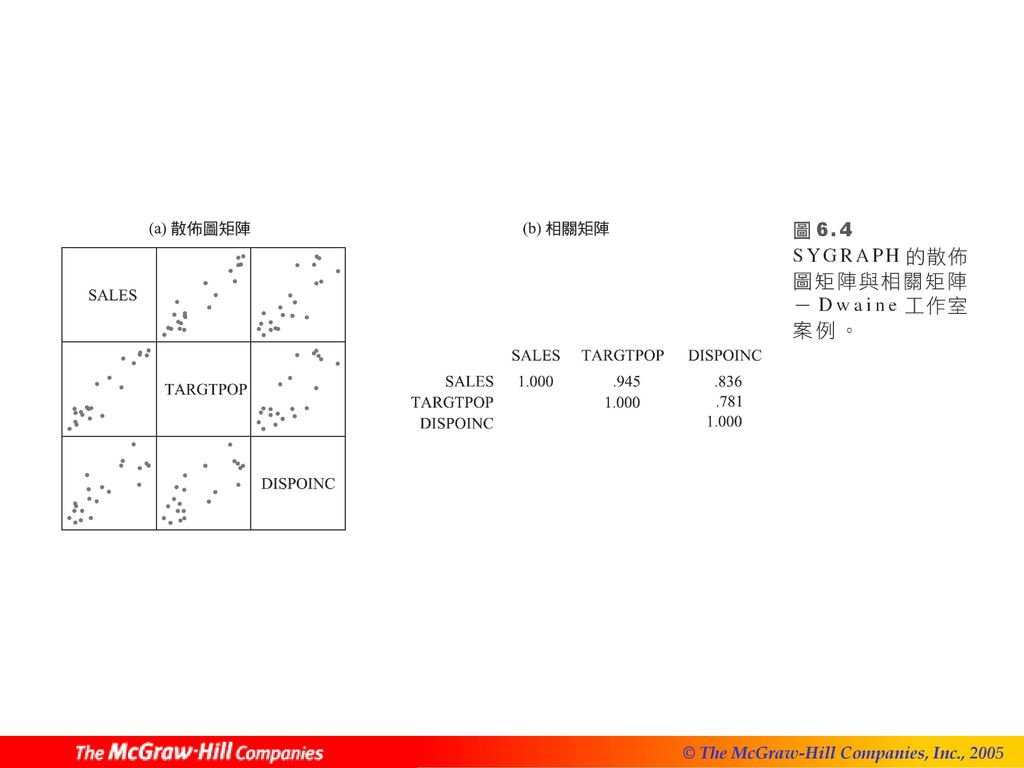
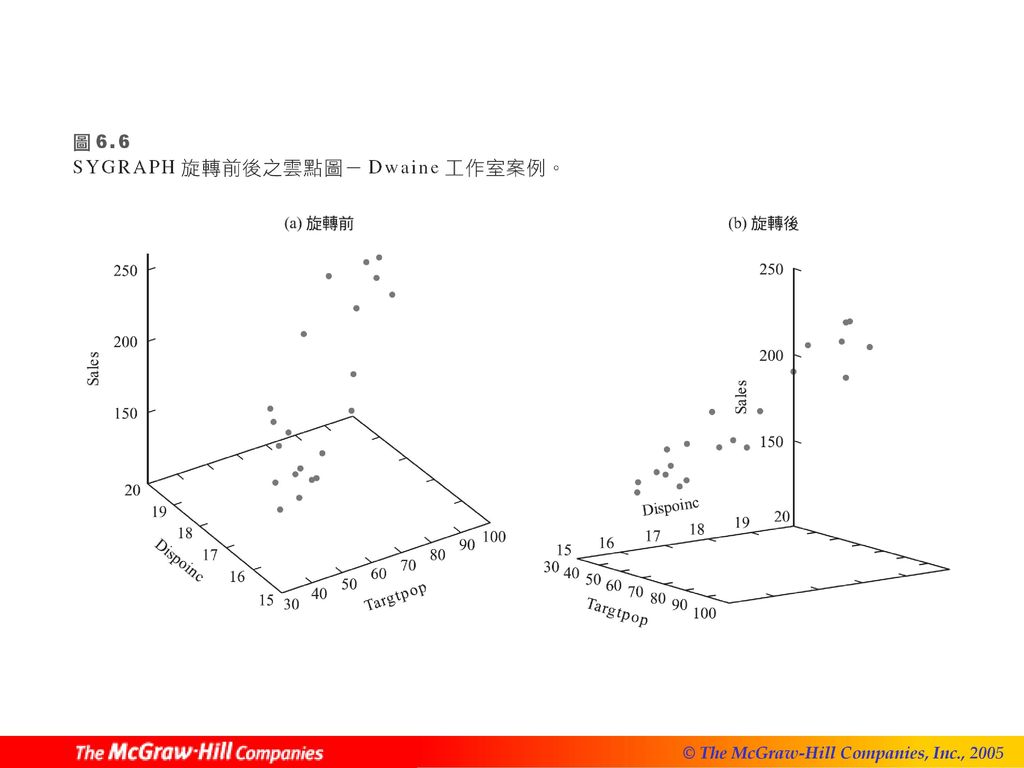
散佈圖矩陣 相關矩陣是散佈圖矩陣的一個有用的輔助工具,此矩陣包含了Y與其他預測變數間,兩兩的簡單相關係數,其排列形式如同散佈圖矩陣: (6.67) 三維散佈圖 殘差圖 常態性的相關檢定 常數變異數的Brown-Forsythe 檢定 常數變異數的Breusch-Pagan 檢定

43
配適不良的F檢定 SSPE的自由度為(n – c),SSLF的自由度為(n – p) – (n – c) = c – p,所以針對下面的檢定: (6.68a) 檢定統計量為: (6.68b) 其中SSLF與SSPE如(3.24)與(3.16)所示,最後我們有決策法則: (6.68c)
")
44
矯正測量 Box-Cox轉換

45
6.9 雙預測變數的複迴歸案例

47
案例介紹 從圖6.4a中的SYGRAPH散佈圖矩陣來看,似乎可以預期為具有常態誤差的第一階迴歸模型: (6.69) 基本計算 Dwaine工作室案例之X與Y如下: (6.70)
 基本計算 Dwaine工作室案例之X與Y如下: (6.70)")
48
我們需先計算: 1. 結果為: (6.71)
")
49
2. 結果為: (6.72)
")
50
3. 應用(5.23)可以得到結果: (6.73)
可以得到結果: (6.73)")
51
代數等式 在第一階迴歸模型(6.69)中的 為: 或是: (6.74)
中的 為: 或是: (6.74)")
52
關於雙預測變數下的第一階迴歸模型(6.69), 為:
(6.75) 迴歸函數的估計 從(6.25)中可以立即利用(6.72)與(6.73)計算最小平方估計量b:
 迴歸函數的估計. 從(6.25)中可以立即利用(6.72)與(6.73)計算最小平方估計量b:")
53
結果為: (6.76)
")
54
標準方程式的代數版本 雙預測變數下的標準方程式之代數式可以透過(6.74)與(6.75)得出:
因此有下面的標準方程式: (6.77)
")
55
配適值及殘差 模型配適度分析

56
變異數分析 迴歸關係的檢定 複判定係數

57
迴歸參數的估計 首先我們需先計算共變異矩陣的估計量 : 在圖6.5a中已經輸出了MSE,而 則在(6.73)中計算過,所以: (6.78)
中計算過,所以: (6.78)")
58
平均反應的估計 變異數估計量 的代數版本 利用(6.58) 在雙預測變數的第一階模型中,我們有: (6.79)
 在雙預測變數的第一階模型中,我們有: (6.79)")













 Wonnacott and Wonnacott. Introductory>")







