Download presentation
1
第七章 回归分析

2
变量之间的联系 确定型的关系:指某一个或某几个现象的变动必然会引起另一个现象确定的变动,他们之间的关系可以使用数学函数式确切地表达出来,即y=f(x)。当知道x的数值时,就可以计算出确切的y值来。如圆的周长与半径的关系:周长=2πr。 非确定关系:例如,在发育阶段,随年龄的增长,人的身高会增加。但不能根据年龄找到确定的身高,即不能得出11岁儿童身高一定就是1.40米公分。年龄与身高的关系不能用一般的函数关系来表达。研究变量之间既存在又不确定的相互关系及其密切程度的分析称为相关分析。

3
回归分析 如果把其中的一些因素作为自变量,而另一些随自变量的变化而变化的变量作为因变量,研究他们之间的非确定因果关系,这种分析就称为回归分析。 回归分析是研究一个自变量或多个自变量与一个因变量之间是否存在某种线性关系或非线性关系的一种统计学方法。

4
回归分析 线性回归分析; 曲线回归分析; 二维Logistic回归分析; 多维Logistic回归分析; 概率单位回归分析;
非线性回归分析; 权重估计分析; 二阶段最小二乘分析; 最优尺度回归。

5
一、线性回归 (一)一元线性回归方程 直线回归分析的任务就是根据若干个观测(xi,yi)i=1~n找出描述两个变量x、y之间关系的直线回归方程y^=a+bx。y^是变量y的估计值。求直线回归方程y^=a+bx,实际上是用回归直线拟合散点图中的各观测点。常用的方法是最小二乘法。也就是使该直线与各点的纵向垂直距离最小。即使实测值y与回归直线y^之差的平方和Σ(y-y^)2达到最小。Σ(y-y^)2也称为剩余(残差)平方和。因此求回归方程y^=a+bx的问题,归根到底就是求Σ(y-y^)2取得最小值时a和b的问题。a称为截距,b为回归直线的斜率,也称回归系数。
i=1~n找出描述两个变量x、y之间关系的直线回归方程y^=a+bx。y^是变量y的估计值。求直线回归方程y^=a+bx,实际上是用回归直线拟合散点图中的各观测点。常用的方法是最小二乘法。也就是使该直线与各点的纵向垂直距离最小。即使实测值y与回归直线y^之差的平方和Σ(y-y^)2达到最小。Σ(y-y^)2也称为剩余(残差)平方和。因此求回归方程y^=a+bx的问题,归根到底就是求Σ(y-y^)2取得最小值时a和b的问题。a称为截距,b为回归直线的斜率,也称回归系数。")
6
1、一元线性回归方程的适用条件 线形趋势:自变量与因变量的关系是线形的,如果不是,则不能采用线性回归来分析。
独立性:可表述为因变量y的取值相互独立,它们之间没有联系。反映到模型中,实际上就是要求残差间相互独立,不存在自相关。 正态性:自变量x的任何一个线形组合,因变量y均服从正态分布,反映到模型中,实际上就是要求随机误差项εi服从正态分布。 方差齐性:自变量的任何一个线形组合,因变量y的方差均齐性,实质就是要求残差的方差齐。

7
2、一元线性回归方程的检验 检验的假设是总体回归系数为0。另外要检验回归方程对因变量的预测效果如何。 (1)回归系数的显著性检验
对斜率的检验,假设是:总体回归系数为0。检验该假设的t值计算公式是;t=b/SEb,其中SEb是回归系数的标准误。 对截距的检验,假设是:总体回归方程截距a=0。检验该假设的t值计算公式是: t=a/SEa,其中SEa是截距的标准误。

8
(2) R2判定系数 在判定一个线性回归直线的拟合度的好坏时,R2系数是一个重要的判定指标。
R2判定系数等于回归平方和在总平方和中所占的比率,即R2体现了回归模型所能解释的因变量变异性的百分比。如果R2=0.775,则说明变量y的变异中有77.5%是由变量X引起的。当R2=1时,表示所有的观测点全部落在回归直线上。当R2=0时,表示自变量与因变量无线性关系。 为了尽可能准确的反应模型的拟合度,SPSS输出中的Adjusted R Square是消除了自变量个数影响的R2的修正值。

9
(3)方差分析 体现因变量观测值与均值之间的差异的偏差平方和SSt是由两个部分组成: SSt=SSr+SSe
SSr:回归平方和,反应了自变量X的重要程度; SSe :残差平方和,它反应了实验误差以及其他意外因素对实验结果的影响。这两部分除以各自的自由度,得到它们的均方。 统计量F=回归均方/残差均方。当 F值很大时,拒绝接受b=0的假设。

10
(4)Durbin-Watson检验 回归模型的诊断中,要诊断回归模型中误差项的独立性。如果误差项不独立,那么对回归模型的任何估计与假设所作出的结论都是不可靠的。其参数称为DW或D。D的取值范围是0<D<4,统计学意义如下: ①当残差与自变量互为独立时D≈2; ③当相邻两点的残差为正相关时,D<2; ③当相邻两点的残差为负相关时,D>2

11
(5)残差图示法 在直角坐标系中,以预测值y^为横轴,以y与y^之间的误差et为纵轴(或学生化残差),绘制残差的散点图。如果散点呈现出明显的规律性则,认为存在自相关性或者非线性或者非常数方差的问题。
残差图示法 在直角坐标系中,以预测值y^为横轴,以y与y^之间的误差et为纵轴(或学生化残差),绘制残差的散点图。如果散点呈现出明显的规律性则,认为存在自相关性或者非线性或者非常数方差的问题。")
14
(二)多元线性回归 1.多元线性回归的概念 多元线性回归:根据多个自变量的最优组合建立回归方程来预测因变量的回归分析称为多元回归分析。多元回归分析的模型为:y^=b0+b1x1+b2x2+ ····+bnxn 其中y^为根据所有自变量x计算出的估计值, b0为常数项, b1、b2····bn称为y对应于x1、x2··· xn的偏回归系数。偏回归系数表示假设在其他所有自变量不变的情况下,某一个自变量变化引起因变量变化的比率。 多元线性回归模型也必须满足一元线性回归方程中所述的假设理论。

15
2.多元线性回归分析中的参数 (l)复相关系数 R
复相关系数表示因变量y 与他的自变量xi 之间线性相关密切程度的指标,亦即观察Y与Y^之间的相关程度,复相关系数使用字母R表示。 复相关系数的取值范围在0-1之间。其值越接近1表示其线性关系越强,越接近0表示线性关系越差。

16
(2)R2判定系数与经调整的判定系数 与一元回归方程相同,在多元回归中也使用判定系数R2来解释回归模型中自变量的变异在因变量变异中所占比率。
但是,判定系数的值随着进入回归方程的自变量的个数(或样本容量的大小n)的增加而增大。因此,为了消除自变量的个数以及样本量的大小对判定系数的影响,引进了经调整的判定系数(Adjusted R Square)。 K为自变量的个数,n为观测量数目。自变量的个数大于1时,其值小于判定系数。自变量个数越多,与判定系数的差值越大。
的增加而增大。因此,为了消除自变量的个数以及样本量的大小对判定系数的影响,引进了经调整的判定系数(Adjusted R Square)。 K为自变量的个数,n为观测量数目。自变量的个数大于1时,其值小于判定系数。自变量个数越多,与判定系数的差值越大。")
17
(3)零阶相关系数、部分相关与偏相关系数 零阶相关系数(Zero-Order)各自变量与因变量之间的简单相关系数。
部分相关系数(Part Correlation)表示:在排除了其他自变量对 xi的影响后,当一个自变量进入回归方程模型后,复相关系数的平方增加量。 偏相关系数(Partial Correlation )表示:在排除了其他变量的影响后;自变量 Xi与因变量y之间的相关程度。 部分相关系数小于偏相关系数。偏相关系数也可以用来作为筛选自变量的指标,即通过比较偏相关系数的大小判别哪些变量对因变量具有较大的影响力。
表示:在排除了其他自变量对 xi的影响后,当一个自变量进入回归方程模型后,复相关系数的平方增加量。 偏相关系数(Partial Correlation )表示:在排除了其他变量的影响后;自变量 Xi与因变量y之间的相关程度。 部分相关系数小于偏相关系数。偏相关系数也可以用来作为筛选自变量的指标,即通过比较偏相关系数的大小判别哪些变量对因变量具有较大的影响力。")
18
3、多元线性回归分析的检验 建立了多元回归方程后,需要进行显著性检验,以确认建立的数学模型是否很好的拟和了原始数据,即该回归方程是否有效。利用残差分析,确定回归方程是否违反了假设理论。对方程式中各自变量的系数进行检验。其假设是总体的回归方程自变量系数或常数项为0。以便在回归方程中保留对因变量y值预测更有效的自变量。

19
(l)方差分析 多元回归方程也采用方差分析方法对回归方程进行检验,检验的H0假设是总体的回归系数均为0(无效假设),H1假设是总体的回归系数不全为0(备选假设)。它是对整个回归方程的显著性检验。使用统计量F进行检验。原理与一元回归的方程分析原理相同。
方差分析 多元回归方程也采用方差分析方法对回归方程进行检验,检验的H0假设是总体的回归系数均为0(无效假设),H1假设是总体的回归系数不全为0(备选假设)。它是对整个回归方程的显著性检验。使用统计量F进行检验。原理与一元回归的方程分析原理相同。")
20
(2)偏回归系数与常数项的检验 在多元回归分析中,可能有的自变量对因变量的影响很强,而有的影响很弱,甚至完全没有作用,这样就有必要对自变量进行选择,使回归方程中只包含对因变量有统计学意义的自变量; 检验的假设是:各自变量偏回归系数为0,常数项为0。它使用的统计量是t; t=偏回归系数/偏回归系数的标准误

21
(3)方差齐性检验 方差齐性是指残差的分布是常数,与自变量或因变量无关。一般是绘制因变量预测值与学生残差的散点图来检验。残差应随机的分布在一条穿过0点的水平直线的两侧。 在实际应用中,在线性回归Plots对话框中的源变量表中,选择SRESID(学生氏残差)做Y轴;选择ZPRED(标准化预测值)做X轴就可以在执行后的输出信息中显示检验方差齐性的散点图。
做Y轴;选择ZPRED(标准化预测值)做X轴就可以在执行后的输出信息中显示检验方差齐性的散点图。")
22
共线性诊断 在回归方程中,虽然各自变量对因变量都是有意义的,但某些自变量彼此相关,即存在共线性的问题。给评价自变量的贡献率带来困难。因此,需要对回归方程中的变量进行共线性诊断;并且确定它们对参数估计的影响。 当一组自变量精确共线性时,必须删除引起共线性的一个和多个自变量,否则不存在系数唯一的最小二乘估计。因为删除的自变量并不包含任何多余的信息,所以得出的回归方程并没有失去什么。当共线性为近似时,一般是将引起共线性的自变量删除,但需要掌握的原则是:务必使丢失的信息最少。

23
在只有两个自变量的情况下,自变量X1与X2之间共线性体现在两变量间相关系数r12上。精确共线性时对应r122=1,当它们之间不存在共线性时r122=0。 r122越接近于1,共线性越强。
多于两个自变量的情况, Xi与其他自变量X之间的复相关系数的平方体现其共线性,称它为Ri2。它的值越接近1,说明自变量之间的共线性程度越大。

24
进行共线性诊断常用的参数 (l)容许度(Tolerance) 容许度定义为Toli=l一Ri2 当容许度的值较小时,自变量Xi 与其他自变量X之间存在共线性。 使用容许度作为共线性量度指标的条件是,观测量应大致近似于正态分布。

25
(2)方差膨胀因子(VIF) 方差膨胀因于(VIF)定义为 VIF=1/(l一Ri2 ),即它是容许度的倒数。它的值越大,自变量之间存在共线性的可能性越大。 (3)条件指数(Condition Index) 条件参数是在计算特征值时产生的一个统计量,其数值越大,说明自变量之间的共线性的可能性越大;一般认为,条件参数≥15时认为有共线性存在的可能性, 特征值(Eigenvalue)如果很小,就应该怀疑共线性的存在。
如果很小,就应该怀疑共线性的存在。")
26
例 题 测得97名成年男性血常规和血清生化指标11项,分别是rbc(红细胞),hb(血红蛋白),wbc(白细胞),plt(血小板),tbil(直接胆红素),alt(谷丙转氨酶),ast(谷草转氨酶),alp(碱性磷酸酶),bun(尿素氮),cr(肌酐),见数据文件regression.sav。试以hb(血红蛋白)为因变量,其他为自变量进行回归。Regression.sav
,hb(血红蛋白),wbc(白细胞),plt(血小板),tbil(直接胆红素),alt(谷丙转氨酶),ast(谷草转氨酶),alp(碱性磷酸酶),bun(尿素氮),cr(肌酐),见数据文件regression.sav。试以hb(血红蛋白)为因变量,其他为自变量进行回归。Regression.sav.")
28
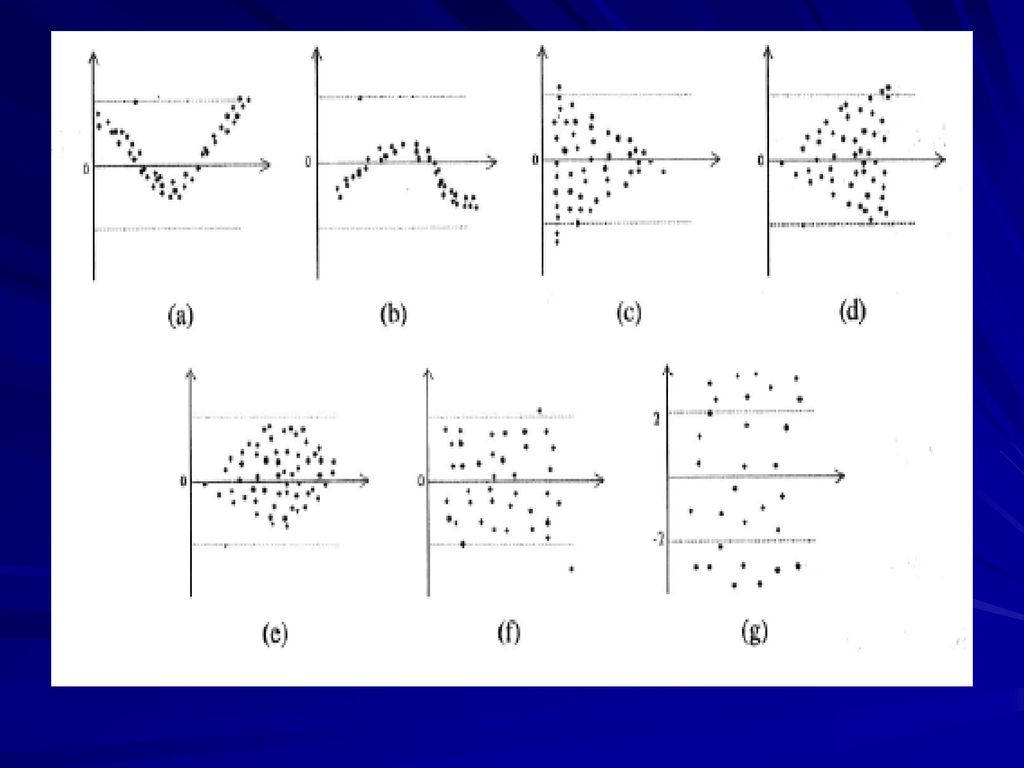
1.变量间线性关系的初步探索 在获得数据后,应将所得到的数据绘图,探索因变量随自变量变化的趋势。以便确定数据是否适合线性模型。如果数据之间大致呈线性关系,可以建立线性回归方程。如果图中数据不呈线性分布,那么还可以根据其他回归方程模型的观测量分布图形特点以及建立各方程后所得的判定系数R2进行比较后确定一种最佳模型。见曲线拟合及非线性回归。 通过散点图还可以发现奇异值。

29
2、选择自变量和因变量

30
3、选择回归分析方法 Enter选项,强行进入法,即所选择的自变量全部进人回归模型,该选项是默认方式。
Remove选项,消去法,建立的回归方程时,根据设定的条件剔除部分自变量。

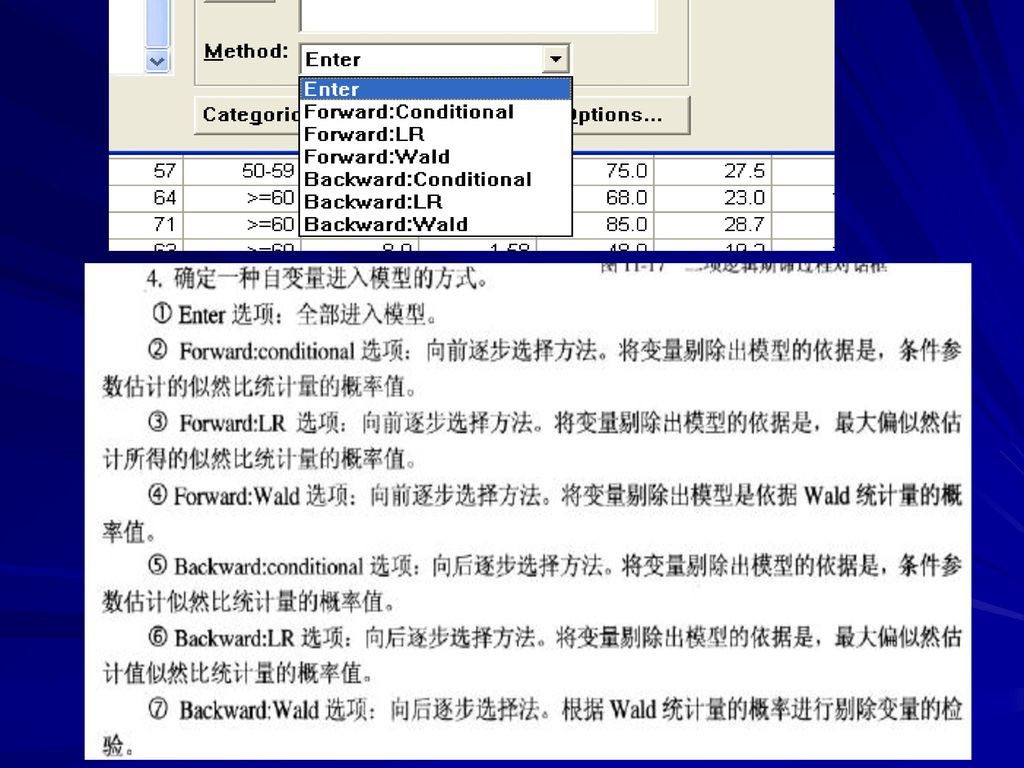
31
选择回归分析方法 Forward选项,向前选择法,根据在option对话框中所设定的判据,从无自变量开始。在拟合过程中,对被选择的自变量进行方差分析,每次加入一个F值最大的变量,直至所有符合判据的变量都进入模型为止。第一个引入归模型的变量应该与因变量间相关系数绝对值最大。

32
选择回归分析方法 Backward选项,向后剔除法,根据在option对话框中所设定的判据,先建立全模型,然后根据设置的判据,每次剔除一个使方差分析中的F值最小的自变量,直到回归方程中不再含有不符合判据的自变量为止。

33
选择回归分析方法 Stepwise选项,逐步进入法,它是向前选择变量法与向后剔除变量方法的结合。根据在 option对话框中所设定的判据,首先根据方差分析结果选择符合判据的自变量且对因变量贡献最大的进入回归方程。根据向前选择变量法则选入变量。然后根据向后剔除法,将模型中F值最小的且符合剔除判据的变量剔除出模型,重复进行直到回归方程中的自变量均符合进入模型的判据,模型外的自变量都不符合进入模型的判据为止。

34
4、选择参与回归的观测量 根据变量值选择参与回归分析的观测量,将作为参照的变量进入 Selection Variable框中,单击 Rule按钮。打开 Set Rule对话框。

35
5、Statistics按钮 Estimates:输出一般回归系数B、B的标准误、标准回归系数beta、B的t值及t值的双侧检验的显著性水平; Confidence interval:输出一般回归系数95%的可信区间; Covariance maxtrix:输出非标准化回归系数的协方差矩阵、各变量的相关系数矩阵;

36
Model fit(模型拟合):模型检验,输出复相关系数R,判定系数R2、调整的判定系数,方差分析表;
R squared change:表示回归方差中引入或剔除一个自变量后的R2变化量; Descriptives:输出每个变量的平均值、标准差、样本数、相关系数矩阵和单侧检验显著性水平

37
Part and partial correlations:输出部分相关系数、偏相关系数、零阶相关系数;
Collinearity diagnostics:输出方差膨胀因子及特征值; Durbin-Watson:输出Durbin-Watson统计量及可能的奇异值; Casewise diagnostics:个体诊断,给出残差和预测值,标准化残差和预测值。

38
6、plot按钮 Dependent:因变量; ZPRED:标准化预测值 ZRESID:标准化残差 DRESID:剔除残差
ADJPRED:修正后预测值 SRESID:学生化残差 SDRESID:学生化剔除残差

39
plot按钮 Histogrom:输出带有正态曲线的标准化残差的直方图;
Normal probability plot:残差的正态概率图,检查残差的正态性; Produce all partial plots:输出每一个自变量残差相对于因变量残差的散布图。

40
Option按钮 Stepping method criteria(设置变量引入模型或从模型中剔除的判据)
Use probability of F:采用F值所对应的P值作为变量引入模型或从模型中剔除的判据。 Entry:0.05回归模型检验时,若P≤0.05该变量被引入方程; Removal:0.10当回归模型检验时, 若P≥0.10该变量从回归方程剔除。

41
Option按钮 Use F values(采用F值作为变量引入模型或从模型中剔除的判据)
Entry:当一个变量的F值≥3.84时该变量被引入方程; Removal:当一个变量的F值≤2.71时该变量从回归方程剔除。

42
练习题 1 Data09-03美国某银行雇员情况调查,建立一个使用初始工资(salbegin)、工作经验(prevexp)、工作时间(jobtime)、工作类型(jobcat)、受教育年限(educ)预测当前工资(salary)的回归方程。
、工作经验(prevexp)、工作时间(jobtime)、工作类型(jobcat)、受教育年限(educ)预测当前工资(salary)的回归方程。")
43
二、曲线回归分析 线性回归可以满足许多数据分析,然而线性回归不会对所有的问题都适用,有时因变量与自变量是通过一个已知或未知的非线性函数关系相联系。尽管有可能通过一些函数的转换方法,在一定范围内将它们转变为线性关系,但这种转换有可能导致更为复杂的计算或数据失真。

44
曲线回归分析 在很多情况下有两个相关的变量,用户希望利用其中的一个变量对另一个变量进行预测,此时可采用的方法也很多;从简单的直线模型到复杂的时间序列模型。如果不能马上根据观测量数据确定一种最佳模型,可以利用曲线估计在众多的回归模型中来建立一个简单而又比较适合的模型。

45
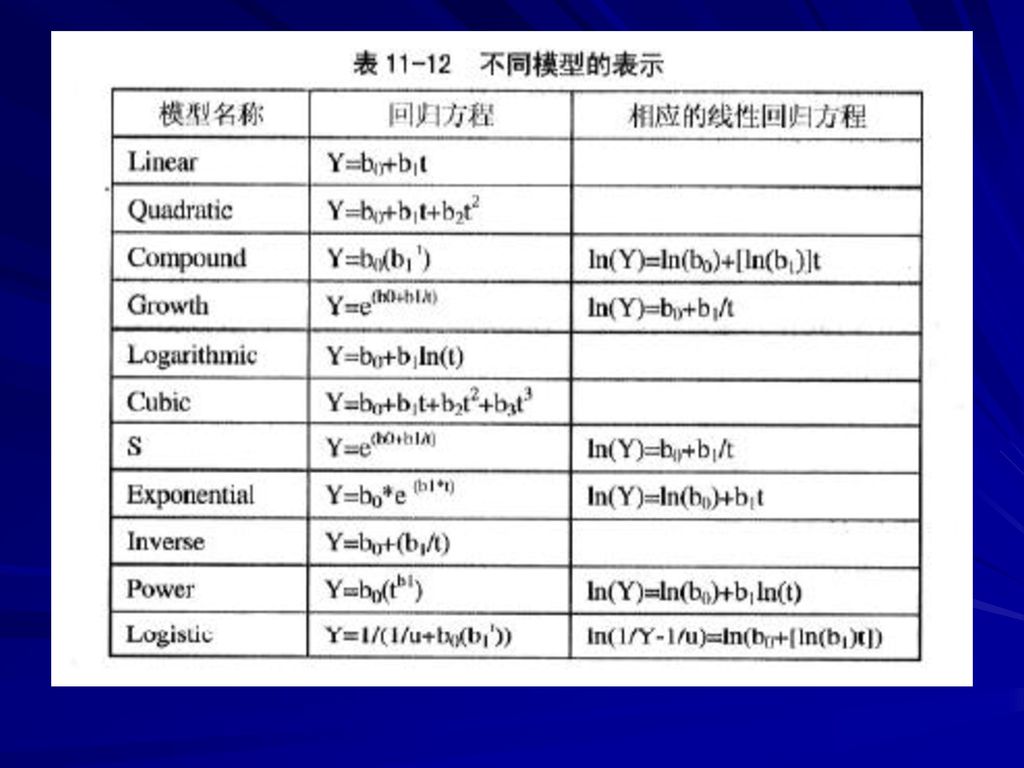
曲线回归分析 线形回归方程Y=b0+b1X 二次回归方程Y=b0+b1X+b2X2 复合曲线回归方程Y=b0(b1X) 生长回归方程
对数回归方程 三次回归方程Y=b0+b1X+b2X2+b3X3

47
例 题 为研究抗生素头孢派酮浓度(ug/ml)“x”与抑菌圈直径“y”的数据见下表,试做曲线拟合。 数据文件curvefit.sav
 x 与抑菌圈直径 y 的数据见下表,试做曲线拟合。 数据文件curvefit.sav")
49
练习题 汽车每加仑汽油行驶的里程数(mpg)与汽车重量(weight)建立回归方程。 Data13-01
与汽车重量(weight)建立回归方程。 Data13-01")
50
三、 Logistic回归分析 多元线性回归要求Y是呈正态分布的连续型随机变量。难以处理因变量为二值变量的情况。

51
Logistic回归分析 logistic回归的基本概念:
设P表示某事件发生的概率,取值范围为0~1,1-P是该事件不发生的概率,将比值 P/(1-P)取自然对数得ln(P/1-P),即对P作logit转换,记为logitP,则logitP的取值范围在-∝,+∝之间。以logitP为因变量,建立线形回归方程: logitP =b0+∑bixi p=exp( b0 +∑ bixi )/[1+ exp (b0 +∑ bixi )] OR=eв=expв
取自然对数得ln(P/1-P),即对P作logit转换,记为logitP,则logitP的取值范围在-∝,+∝之间。以logitP为因变量,建立线形回归方程: logitP =b0+∑bixi. p=exp( b0 +∑ bixi )/[1+ exp (b0 +∑ bixi )] OR=eв=expв.")
52
Logistic回归分析 可见:b0表示一个不接触危险因素(自变量取值全为0时)的个体发病(死亡或感染)的比值的对数。b0是常数。
bi 表示危险因素改变一个单位时,比值的对数的改变量。bi称为logistic回归系数。

53
例题 为研究急性肾衰竭(AFR)患者死亡的危险因素,经回顾性调查,获得某医院1990~2000年中所有发生AFR的422名患者的临床资料数据见数据文件logistic.sav。本资料共涉及29个变量,分别为:sex、age、社会支持、慢性病、手术、糖尿病、肿瘤、动脉硬化、器官移植、cr(血肌酐)、hg(血红蛋白)、肾毒性、少尿、lbp、黄疸、昏迷、辅助呼吸、心衰、肝衰、出血、呼衰、器官衰竭、胰腺炎、dic、败血症、感染、hbp、透析方式、死亡。其中,多分类变量有器官衰竭和透析方式,分别有6个水平和4个水平;定量变量age、cr、hg;其余均为二分类变量。
患者死亡的危险因素,经回顾性调查,获得某医院1990~2000年中所有发生AFR的422名患者的临床资料数据见数据文件logistic.sav。本资料共涉及29个变量,分别为:sex、age、社会支持、慢性病、手术、糖尿病、肿瘤、动脉硬化、器官移植、cr(血肌酐)、hg(血红蛋白)、肾毒性、少尿、lbp、黄疸、昏迷、辅助呼吸、心衰、肝衰、出血、呼衰、器官衰竭、胰腺炎、dic、败血症、感染、hbp、透析方式、死亡。其中,多分类变量有器官衰竭和透析方式,分别有6个水平和4个水平;定量变量age、cr、hg;其余均为二分类变量。")
54
练习题 数据背景(data13-02) 北京医科大学附属人民医院内分泌科卢纹凯教授课题。颈总动脉中层厚度imt>0.8mm或有斑块定义为动脉硬化,因变量type值为1;非硬化imt<0.8mm且无斑块,因变量type值为0。糖尿病患者123例数据。研究哪些指标可以判断糖尿病患者是否动脉硬化。自变量AGE年龄、ALB尿白蛋白、BMI体重指数、ISI胰岛素敏感指数、SBP收缩压、TG甘油三脂、CHO胆固醇、DURA糖尿病程。其中尿白蛋白、甘油三脂、胆固醇三项生化指标在回归估计过程中均使用他们的对数变量:ALBLN、TGLN、CHOLN。

56
Categorical 多分类变量的比较

58
Save 功能按钮

59
Option 功能按钮

60
Logistic回归分析 为研究急性肾衰(AFR)患者死亡的危险因素,经回顾性调查分析,获得某医院1999~2000年中所有发生AFR的422名患者的临床资料见数据文件logistic.sav。本资料共涉及29个变量,分别是:sex, age, 社会支持,慢性病,手术,肿瘤,糖尿病,动脉硬化,器官移植,cr(血肌酐),hg(血红蛋白),肾毒性,少尿,lbp,黄疸,昏迷,辅助呼吸,心衰,肝衰,出血,呼衰,器官衰竭,胰腺炎,dic,败血症,感染,hbp,透析方式,死亡。其中器官衰竭和透析方式为多分类变量,分别有5个和4个水平,定量变量有age,cr,hg;其余为二分类变量。
患者死亡的危险因素,经回顾性调查分析,获得某医院1999~2000年中所有发生AFR的422名患者的临床资料见数据文件logistic.sav。本资料共涉及29个变量,分别是:sex, age, 社会支持,慢性病,手术,肿瘤,糖尿病,动脉硬化,器官移植,cr(血肌酐),hg(血红蛋白),肾毒性,少尿,lbp,黄疸,昏迷,辅助呼吸,心衰,肝衰,出血,呼衰,器官衰竭,胰腺炎,dic,败血症,感染,hbp,透析方式,死亡。其中器官衰竭和透析方式为多分类变量,分别有5个和4个水平,定量变量有age,cr,hg;其余为二分类变量。")
61
Logistic回归分析 数据背景(data13-02)
北京医科大学附属人民医院内分泌科卢纹凯教授课题。颈总动脉中层厚度imt>0.8mm或有斑块定义为动脉硬化,因变量type值为1;非硬化imt<0.8mm且无斑块,因变量type值为0。糖尿病患者123例数据。研究哪些指标可以判断糖尿病患者是否动脉硬化。自变量AGE年龄、ALB尿白蛋白、BMI体重指数、ISI胰岛素敏感指数、SBP收缩压、TG甘油三脂、CHO胆固醇、DURA糖尿病程。其中尿白蛋白、甘油三脂、胆固醇三项生化指标在回归估计过程中均使用他们的对数变量:ALBLN、TGLN、CHOLN。

62
Logistic回归分析 Log.sav

















2 +(y-b)2=r2 x2+y2+Dx+Ey+F=0 Ax2+Bxy+Cy2+Dx+Ey+ F=0.>")

>")


>")


