Download presentation
Presentation is loading. Please wait.

1
與SEM共舞- 威脅潛伏 Amos advanced training
張偉豪 三星統計服務有限公司執行長 Amos 亞洲一哥

2
Best readings for SEM

3
Best readings for SEM

4
Best readings for SEM

5
Outline (第一天) 遺漏值的處理與應用 資料的多元常態檢定及例外值檢核
SEM模型P值顯著的因應 (Bollen and Stine p correction) 模型配適度的修正 Bootstrap的介紹與應用 結構模型的二階段準則 ( Anderson and Gerbing, 1988) SEM共線性的判斷及處理
 模型配適度的修正. Bootstrap的介紹與應用. 結構模型的二階段準則 ( Anderson and Gerbing, 1988) SEM共線性的判斷及處理.")
6
Outline (第二天) SEM處理順序尺度及類別尺度的研究設計 SEM小樣本的另一種解決方法 結構方程模型的檢定力計算及 樣本數決定
最佳模型的搜索 結構方程模型的報告準則

7
遺漏值與極端值 遺漏值指的是某些變數缺乏測量值 極端值指的是某些變數在數字上的距離遠離其他的變數
這兩種情形在SEM分析中可能造成參數估計的偏誤或模形無法正定,不可以等閒視之。

8
遺漏值的偵測 變數遺漏值 分析敘述性統計 次數分配表 將變數選入右側視窗確定

9
遺漏值的偵測 樣本遺漏值 轉換計算變數函數選擇Nmiss 將變數選入右側視窗確定 資料後方會新增一變數 “NMISS”

10
遺漏值的次數分配 分析敘述性統計次數分配表選入NMISS確定

11
遺漏值的處理 樣本數大的時候,可以直接移除具遺漏值的樣本。
註:在Amos 分析中請以SPSS16.0以上的版本移除,否則Amos將無法讀取檔案。 如果樣本數不大,可以資料插補的方式進行,如此可以維持一定的樣本,也可以保持足夠的統計檢定力。

12
遺漏值插補 Amos進行分析不可以有遺漏值存在,因此資料若有遺漏值需進行插補。插補方法有4種 最大概似插補法 迴歸插補法 隨機迴歸插補法
貝氏估計插補法 12

13
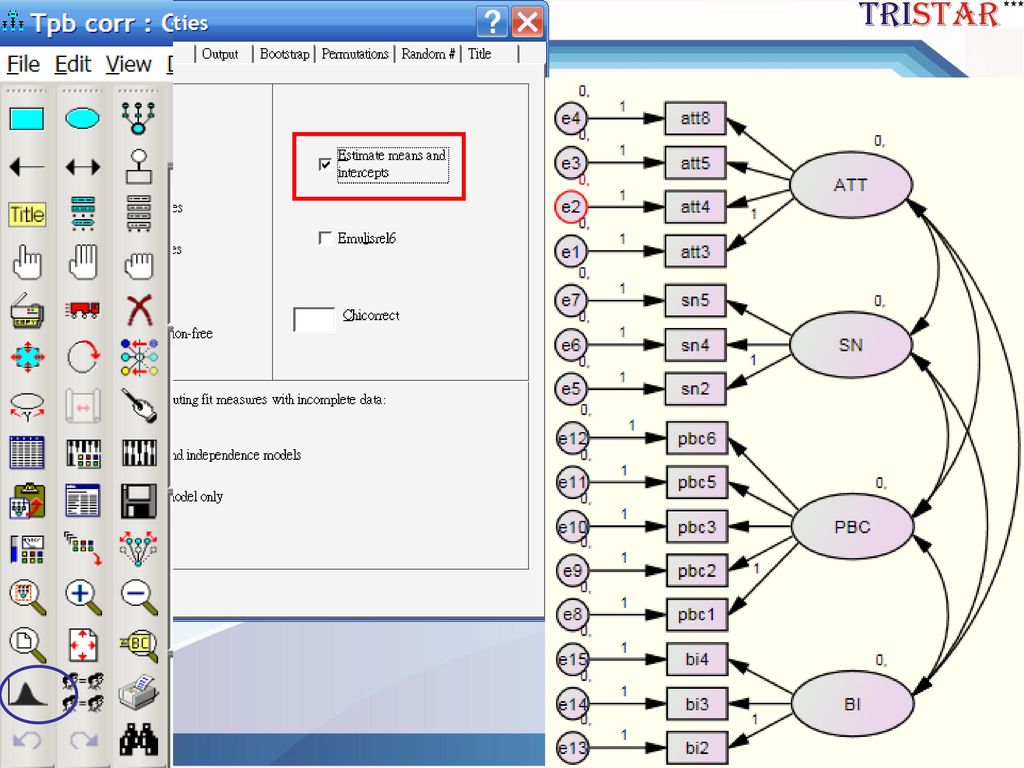
遺漏值插補-ML插補 View Analysis Properties Estimate Mean and Intercept 打勾 分析標準化輸出 13

14
遺漏值插補- Regression imputation
Analyze Data Imputation Regression imputation 14

15
遺漏值插補- Stochastic regression imputation
Analyze Data Imputation Stochastic regression imputation 15

16
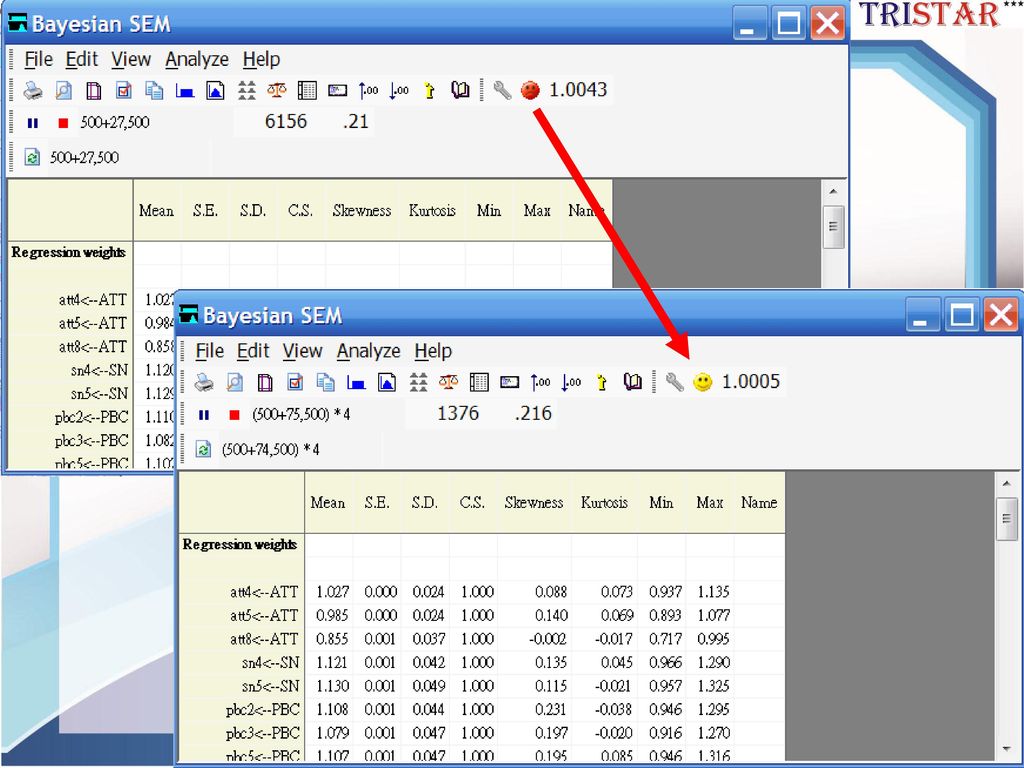
遺漏值插補-Bayesian imputation
Analyze Data Imputation Bayesian imputation 16

17
遺漏值插補-不同方法的比較 資料插補-ML插補法 資料插補-regression 資料插補-stochastic 資料插補-bayesian
17

18
遺漏值的插補 View Interface Properties Estimate Means and Intercepts打勾
Analyze Data Imputation Bayesian imputation 依右圖設定 貝氏估計由綠色臉變成 黃色笑臉 表收斂完成

19
遺漏值的插補 開啟data imputation_c 刪除「圖像」和「語文」等潛在構面的 變數存檔
Amos重新讀取data imputation_c 選擇Grouping Variable Imputation_ Group Value 選擇任一組樣本分析 直到所有組別測試完畢,留下估計值及配適度較好的樣本進入分析。

20
資料的多元常態檢定及例外值檢核

21
多元常態及極端值檢核

22
View Analysis Properties Output

23
多元常態檢定 偏態及峰度是檢查是否單變量常態的重點 多元常態則是看Multivariate 的c.r.≦5 顯示為非多元常態

24
資料常態及例外值檢定 Kline (2005, p49~52) 理論上常態峰是偏態為0,峰態為3,由於統計軟體峰態會減3,因此峰態為0及偏態為0視為常態)。 實務上偏態絕對值在2以內, 峰態絕對值在7以內可視為常態, skew>3為極端偏態, kurtosis>20為極端峰態。
 理論上常態峰是偏態為0,峰態為3,由於統計軟體峰態會減3,因此峰態為0及偏態為0視為常態)。 實務上偏態絕對值在2以內, 峰態絕對值在7以內可視為常態, skew>3為極端偏態, kurtosis>20為極端峰態。")
25
p2小於.001仍採保守原 則,表示該馬氏距離是 存在的。
極端值檢定 顯著代表該樣本距離樣本中心位置的存在很有信心,但是否為極端值,仍需考慮。 p2小於.001仍採保守原 則,表示該馬氏距離是 存在的。

26
P-value顯著與模型配適度修正 當模型P-value顯著時會被視為模型與樣本配適度不佳,但是P-value容易受到樣本數的影響而導致顯著拒絕H0。 H0的拒絕究竟是模型不好所造成或是樣本數太大所造成,可用Bollen-Stine p-value correction (1993) 評估。
 評估。")
27
P-value顯著與模型配適度修正 Bollen-Stine p-value correction (1993) 應用於輸入資料呈現非常態、模型卡方值膨脹及p-value顯著時校正: 如果分析資料為非多元常態易造成卡方值膨脹,可以利用Bollen-Stine加以修正卡方值 利用Bollen-Stine p-value估計的卡方值重新修正模型整體配適度 Bollen-Stine p-value估計評估p-value顯著是否為樣本數大所造成。

28
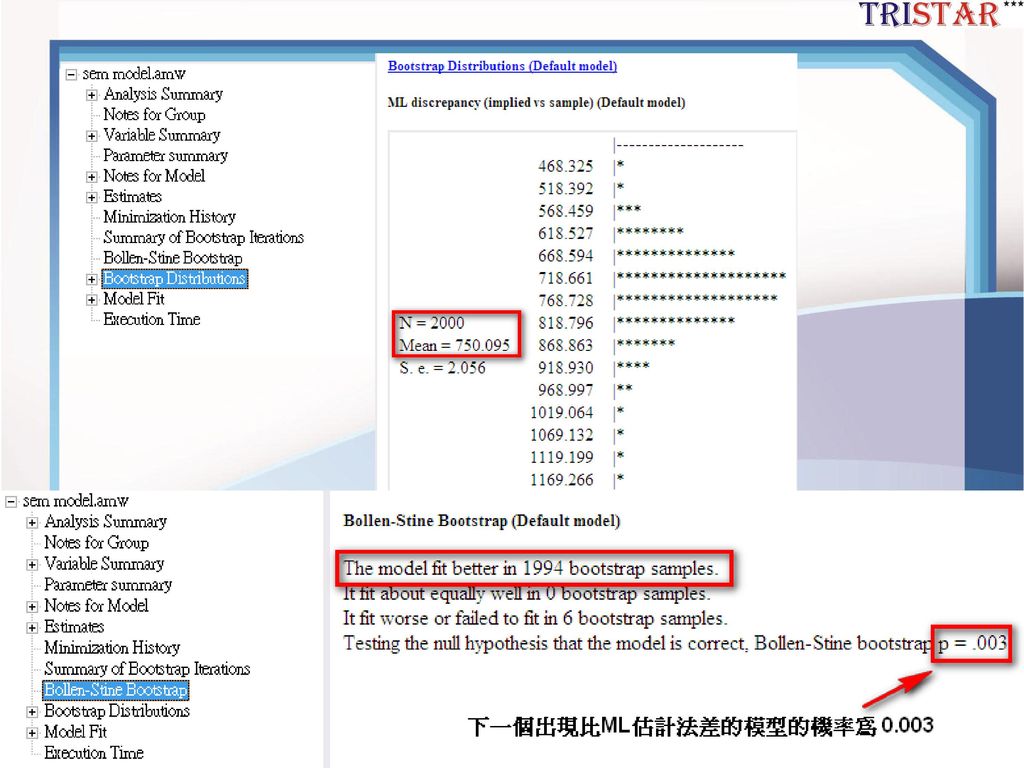
Bollen-Stine bootstrap

29
Bollen-Stine 計算結果 2000個模型收斂的迭代次數,次數愈少表模型愈好

30
Bollen-Stine p-value correction (Byrne 2001, 284~285)
H0:ML Χ2 = Bollen-Stine Χ2 估計的配適度一樣。 P<0.05表示ML與Bollen-Stine估計的Χ2不同 Bollen-Stine bootstrap p的意義為:下一個出現較差模型的機率為(240+1)/2001=
/2001=")
31
Bootstrap Distributions
4.94為執行2000次的估計所得卡方值加總平均值 卡方平均值

32
SEM模型Bollen-Stine配適度修正
Bollen-Stine bootstrap 2000次

34
Bollen-Stine p procedure correction

35
Bollen-Stine bootstrap p的意義
如果重複抽樣1000次,950次以上家戶所得均低於平均所得,當然有足夠的證據證明多數家戶所得是低於平均所得。 家戶所得(萬) 家戶數 120 ∞ 家戶平均所得
 家戶數 ∞ 家戶平均所得.")
36
Bootstrap 使用時機 樣本不夠大時,但仍不能小於100個樣本。 資料呈現非常態分佈,然而卻無法修正。
欲得到所有估計參數的 信賴區間及標準誤。

37
Bootstrap method (自助法)
利用抽出放回的方式重覆抽樣來增加樣本數 主要目的為了得到穩定的平均數分布 (常態分配)、信賴區間及標準誤估計
、信賴區間及標準誤估計.")
38
原始資料莖葉圖

39
原始資料直方圖

40
重新估計路徑值 (bootstrap 1000) 取消Bollen-Stine bootstrap,點選估計 95 %信賴區間,重新估計新的標準誤。 以SEM MODEL 為例
 取消Bollen-Stine bootstrap,點選估計 95 %信賴區間,重新估計新的標準誤。 以SEM MODEL 為例")
41
ML與Bootstrap估計值 Bootstrap的表要在點選estimate下的選項後,下面Bootstrap的結果才能點選

42
估計參數的信賴區間 Bias-corrected及Percentile是很重要的兩種bootstrap的信賴區間估計法

43
結構模式的二階段準則 (Bollen,1989) 重新界定 SR 模型成為 CFA 模型,並讓所有的因素有相關。
View the structural portion of the SR as a path model. 二階段模型估計準則是SEM分析的充份條件,假如在測量模型下可以正定,那麼整個模型就會正定。 除此之外,尚可了解模型是否有共線性的問題。

44
TPB結構模型 Figure 1.SEM結構模型

45
TPB的CFA Model 第一步:將模型重 新架構成一階CFA 完全有相關 Figure 2.TPB的CFA Model

46
高度共線性造成的問題 標準化迴歸係數 非標準化迴歸係數的標準誤
標準化迴歸係數應介於-1~1之間,當變數之間相關接近1時,表示這些變數代表同一件事,當這些變數同時去影響其它變數時,SEM估計過程會無法分出兩個近似的迴歸係數來,結果可能導致一個係數很高而另一個卻為負值。 非標準化迴歸係數的標準誤 SEM會估計會產生較大的標準誤,使得迴歸係數檢定不顯著。z value=estimate/s.e.

47
高度共線性造成的問題 參數估計的共變異數 變異數估計 R2 (SMC)不可相加性。
共線的兩個變數的共變異數會出現遠大於其它變數間的估計值,造成模型卡方值上升。 變異數估計 變數上可能會得到一個負的變異數,不合理的估計值, 一般稱為Heywood Case。 R2 (SMC)不可相加性。
不可相加性。")
48
高度共線性造成的問題 迴歸係數與相關係數符號不一致,甚至於標準化係數大於1。 x1 x2 y1 b1 r12 b2 d1

49
TPB Model SNBI出現不符合假設狀況的值

50
模型共線性的特徵 構面相關係數>0.75 模型標準化迴歸係數>構面相關 迴歸係數與構面相關不同號 迴歸係數與理論假設方向不同
標準化迴歸係數>1 標準化迴歸係數>0.2卻不顯著 R2<某一標準化迴歸係數的平方

51
共線性的處理 (Hebert et al., 2004) 將共線性構面的係數設等同重新估計,即可得到正確的估計值
 將共線性構面的係數設等同重新估計,即可得到正確的估計值")
52
係數設定等同前、後比較 迴歸係數由不顯著變顯著,正負符號也符合實際狀況

53
另一個共線的解決之道 實務上變數共線代表的另一個意義便是具有一個更高階的因素存在。 認知態度 行為意圖 情感態度 認知態度 整體態度
高度相關 行為意圖 情感態度 認知態度 整體態度 行為意圖 情感態度

54
共線性的處理-PLS

55
如何解決模型中潛在變項單一指標測量? O'Brien, Robert "Identification of Simple Measurement Models with Multiple Latent Variables and Correlated Errors." pp in Peter Marsden (Ed.) Sociological Methodology. Blackwell.
 Sociological Methodology. Blackwell.")
56
多指標迴歸結構模型 x1 x2 x3 y1 y2 y3 滿意度 忠誠度 x1 x2 x3 y1 y2 y3 y4 y5 y6 滿意度 忠誠度
d1 滿意度 忠誠度 x1 x2 x3 y1 y2 y3 y4 y5 y6 1 1 1 d1 d2 滿意度 忠誠度 績效

57
Two indicators rules

58
潛在變數單一指標測量 F x e x=F+e Var(x)=Var(F)+Var(e)
1 1 F x e x=F+e Var(x)=Var(F)+Var(e) 信度= Var(F)/Var(x) = [Var(x)-Var(e)]/Var(x) =1- Var(e)/Var(x) Var(e)=(1-信度) × Var(x)
=Var(F)+Var(e) 信度= Var(F)/Var(x) = [Var(x)-Var(e)]/Var(x) =1- Var(e)/Var(x) Var(e)=(1-信度) × Var(x)")
59
變異數的計算 Loading設1,殘差設0,表信度為1 Amos 結果 SPSS 結果

60
信度0.8的設定 e1=(1-0.8) ×Var=0.2×1.026=0.205 殘差設0.205,表信度為0.8
0.8為信度, 為標準化負荷量 的平方值 0.895為 標準化負荷量 變異數設1為 標準化設定

61
Item parceling

62
Advantage of Item Parceling
加總或平均後的分數會近似於常態分配 改善題目與樣本比(item:N) 增加構面的信度 估計參數較少 參數估計較為穩定 降低題目變異的不確定 簡化模型易於解釋
 增加構面的信度. 估計參數較少. 參數估計較為穩定. 降低題目變異的不確定. 簡化模型易於解釋.")
63
SEM TAM Parceling TAM

64
因素負荷量與測量誤差 Variable α 1-α Variance λ= √Var(x)α Error= Var(x)(1-α) ATT
0.75 0.25 1.004 0.868 0.251 EOU 0.784 0.216 0.715 0.749 0.154 UF 0.758 0.242 0.833 0.795 0.202 BI 0.888 0.112 1.030 0.956 0.115

65
SEM TAM Parceling TAM

66
SEM如何處理順序尺度及類別尺度的研究設計?

67
三種處理類別或順序尺度的方法 將資料轉為 polychoric 或 polyserial matrics Amos Bayesian 估計
Items to parcel (將類別、順序尺度變數轉為連續尺度)
")
68
polychoric 或 polyserial matrics
利用lisrel的prelis語法轉出適當的矩陣

69
SEM相關矩陣的應用 Both vars interval: Pearson r
Both vars dichotomous: Tetrachoric correlation Both vars ordinal: Polychoric correlation One var interval, the other a force dichotomy: Biserial correlation

70
SEM相關矩陣的應用 One var interval, the other ordinal: Polyserial correlation
One var interval, the other a true dichotomy: point-biserial Both true ordinal: Spearman rank correlation or Kendall’s tau Both true nominal: phi or contingency coefficient One true ordinal, one true nominal: gamma

71
SEM相關矩陣 interval ordinal nominal Pearson r polyserial Polychoric
Spearman or Kendall Biserial Poly-biserial gamma Tetrachoric Phi or contigency

72
Amos Bayesian估計 在ML估計及假設檢定,模式中的真實值是假設固定但未知,但估計值是 隨機但己知。
貝氏估計假設任何一個參數均為隨機參數,因此貝氏是指定一個機率分配;對貝氏估計而言,模式中的真實值是假設 隨機且未知。

75
Items to parcel的條件 變數本身至少5點尺度,峰度接近0,且偏態絕對值不大於1且同為正偏或負偏
假如變數5點以上尺度,通常第一點不成問題。 若變數為 yes or no尺度?

76
Dealing with yes or no questions
以內、外控量表為例,共15題,no編碼為0,yes編碼為1,答yes愈多 表示愈傾向內控,反之則傾向外控。 隨機將題目分成三群,每群5題 每群做分數加總成三個新變數 變數此時尺度介於0~5之間, 形成6點的連續尺度 帶入CFA驗證

77
內外控二點尺度量度的處理

78
結構方程模型的檢定力計算及 樣本數決定 檢定力 (power)的介紹及重要性 Power & sample sizes decision Satorra & Sarris (1985) MacCallum, Browne & Sugawara (1996)
的介紹及重要性 Power & sample sizes decision Satorra & Sarris (1985) MacCallum, Browne & Sugawara (1996)")
79
假設統計考驗的四種可能結果 真實狀況 統計決策 拒絕H0 不拒絕H0 H0為真 錯誤決定 型一錯誤 (α) 正確決定 接受H0 (1- α)
正確決定 拒絕H0 (power:1-β) 錯誤決定 型二錯誤 (β)
 錯誤決定 型二錯誤 (β)")
80
型I與型II錯誤 (Type I and II error)
Type II error A missed detection 失之交臂 Type I error A false alarm 無中生有

81
Effect size vs. power Effect size愈大,power愈大

82
型I錯誤 顯著水準5%是當母體並沒有關係存在,但研究卻宣稱有關係存在的機率不能超過5%。 5%機率的產生只是因為抽樣誤差所造成的偶然而已。

83
型II錯誤 事實上效果真的存在,但卻宣稱不存在。 樣本愈少,愈容易犯型II錯誤。

84
模型檢定統計結果 (Kline, 2011, p.193) Reject-support context
檢定結果是顯著的 (p<0.05) ,則支持研究者的理論,如相關分析、迴歸分析、ANOVA檢定及路徑分析等。 Accept-support context 檢定結果是不顯著的 (p>=0.05) ,則支持研究者的理論,如SEM、同質性、適合度檢定。
 ,則支持研究者的理論,如相關分析、迴歸分析、ANOVA檢定及路徑分析等。 Accept-support context. 檢定結果是不顯著的 (p>=0.05) ,則支持研究者的理論,如SEM、同質性、適合度檢定。")
85
檢定力 (power)的介紹及重要性 統計推論的正確性與 “樣本數” , “抽樣誤差”及 “檢定力”有關。
樣本數愈大,標準誤愈小,信賴區間愈小,統計推論較不會受到抽樣誤差的影響,所以「愈多愈好」通常是成立的。 自由度愈大,統計檢定力愈大

86
檢定力 (power) Power:正確的判定統計結果,有關群組之間有差異或變數之間有相關的機率
 Power:正確的判定統計結果,有關群組之間有差異或變數之間有相關的機率")
87
結構方程模型的 檢定力計算及樣本數決定 SEM模型整體的檢定力 (power)及樣本數採用MacCallum, R.C., Browne, M.W. & Sugawara, H.W. (1996) SEM模型每一條路徑係數的檢定力 採用Satorra & Saris (1985) Kline, p222

88
檢定力的假設 H0:ε≦0.05 (close fit) Ha:εa=0.08
H0:ε≧0.05 (not-close fit) Ha:εa=0.01
 Ha:εa=0.01.")
89
R語言執行SEM 檢定統計力 #Compute power if(rmsea0<rmseaa) {
cval <- qchisq(alpha,d,ncp=ncp0,lower.tail=F) pow <- pchisq(cval,d,ncp=ncpa,lower.tail=F) } if(rmsea0>rmseaa) { cval <- qchisq(1-alpha,d,ncp=ncp0,lower.tail=F) pow <- 1-pchisq(cval,d,ncp=ncpa,lower.tail=F) print(pow) #Power analysis for SEM alpha < #alpha level d <- 200 #degrees of freedom n <- 250 #sample size rmsea0 < #null hypothesized RMSEA rmseaa < #alternative hypothesized RMSEA #Code below this point need not be changed by user ncp0 <- (n-1)*d*rmsea0^2 ncpa <- (n-1)*d*rmseaa^2
 pow <- pchisq(cval,d,ncp=ncpa,lower.tail=F) } if(rmsea0>rmseaa) { cval <- qchisq(1-alpha,d,ncp=ncp0,lower.tail=F) pow <- 1-pchisq(cval,d,ncp=ncpa,lower.tail=F) print(pow) #Power analysis for SEM. alpha < #alpha level. d <- 200 #degrees of freedom. n <- 250 #sample size. rmsea0 < #null hypothesized RMSEA. rmseaa < #alternative hypothesized RMSEA. #Code below this point need not be changed by user. ncp0 <- (n-1)*d*rmsea0^2. ncpa <- (n-1)*d*rmseaa^2.")
90
R語言計算SEM 樣本數 #Computation of minimum sample size for test of fit
rmsea0 < #null hypothesized RMSEA rmseaa < #alternative hypothesized RMSEA d <- 200 #degrees of freedom alpha < #alpha level desired <- 0.8 #desired power #Code below need not be changed by user #initialize values pow <- 0.0 n <- 0 #begin loop for finding initial level of n while (pow<desired) { n <- n+100 ncp0 <- (n-1)*d*rmsea0^2 ncpa <- (n-1)*d*rmseaa^2 #compute power if(rmsea0<rmseaa) { cval <- qchisq(alpha,d,ncp=ncp0,lower.tail=F) pow <- pchisq(cval,d,ncp=ncpa,lower.tail=F) } else { cval <- qchisq(1-alpha,d,ncp=ncp0,lower.tail=F) pow <- 1-pchisq(cval,d,ncp=ncpa,lower.tail=F) }}
 { n <- n+100. ncp0 <- (n-1)*d*rmsea0^2. ncpa <- (n-1)*d*rmseaa^2. #compute power. if(rmsea0<rmseaa) { cval <- qchisq(alpha,d,ncp=ncp0,lower.tail=F) pow <- pchisq(cval,d,ncp=ncpa,lower.tail=F) } else { cval <- qchisq(1-alpha,d,ncp=ncp0,lower.tail=F) pow <- 1-pchisq(cval,d,ncp=ncpa,lower.tail=F) }}")
91
R語言計算SEM 樣本數 pow <- pchisq(cval,d,ncp=ncpa,lower.tail=F)
#begin loop for interval halving foo <- -1 newn <- n interval <- 200 powdiff <- pow - desired while (powdiff>.001) { interval <- interval*.5 newn <- newn + foo*interval*.5 ncp0 <- (newn-1)*d*rmsea0^2 ncpa <- (newn-1)*d*rmseaa^2 #compute power if(rmsea0<rmseaa) { cval <- qchisq(alpha,d,ncp=ncp0,lower.tail=F) pow <- pchisq(cval,d,ncp=ncpa,lower.tail=F) } else { cval <- qchisq(1-alpha,d,ncp=ncp0,lower.tail=F) pow <- 1-pchisq(cval,d,ncp=ncpa,lower.tail=F) powdiff <- abs(pow-desired) if (pow<desired) { foo <- 1 if (pow>desired) { foo <- -1 }} minn <- newn print(minn)
 { interval <- interval*.5. newn <- newn + foo*interval*.5. ncp0 <- (newn-1)*d*rmsea0^2. ncpa <- (newn-1)*d*rmseaa^2. #compute power. if(rmsea0<rmseaa) { cval <- qchisq(alpha,d,ncp=ncp0,lower.tail=F) pow <- pchisq(cval,d,ncp=ncpa,lower.tail=F) } else { cval <- qchisq(1-alpha,d,ncp=ncp0,lower.tail=F) pow <- 1-pchisq(cval,d,ncp=ncpa,lower.tail=F) powdiff <- abs(pow-desired) if (pow<desired) { foo <- 1. if (pow>desired) { foo <- -1. }} minn <- newn. print(minn)")
92
模型設定探索 (Model Specification Search)
模型探索主要為了找出多個模型中最精簡的模型。 研究者可以將迴歸路加以選擇,每條路徑均會產生顯著或不顯著的結果,因此如果選了4條迴歸線,就會產生24=16個模型,Amos會評估16個模型的優劣,進而挑選出與模型配適度最佳且較精簡的模型。

93
模型設定探索 Analyze Specification Search或
按 選擇要評估的路徑,點選後會由黑色變成紫色線。若要恢復則點 即可變回黑色。 按 ,Amos會立即進行分析

94
選擇路徑

95
多個模型分析結果

96
最終模型確認

97
SEM報告的準則 (ch.9) 概念模型及統計模型的敘述 樣本資料的細節 結果說明 資料分析矩陣 資料的分佈 估計方法 配適指標 參數的估計
競爭模型 等值模型

98
SEM報告的準則 (ch.9) 事後修正 測量誤差的相關 非標準化或特定的效果 模型配適的額外資訊 統計檢定力 交叉效度 解釋與推論
 事後修正 測量誤差的相關 非標準化或特定的效果 模型配適的額外資訊 統計檢定力 交叉效度 解釋與推論")
99
概念及統計模型的敘述 概念模型 實務上操作的概念關係圖形,不含 “指標” 、 “測量誤差” 、 “負荷量” 。
概念圖應對假設的每一條路加以解釋及判斷

100
概念及統計模型的敘述 統計模型 為概念模型的展開 包括觀察變數、潛在變數、負荷量、殘差、路徑、固定及自由參數

101
樣本資料的細節 資料分析矩陣 分析時以 “共變異數矩陣”取代 “相關矩陣” (Cudeck, 1989) ,若輸入為 “相關矩陣” 一定要提供標準差。 矩陣至少要到小數點後三位數。 共變異數矩陣需提供於附錄中。 資料的分佈 變數常態及多元常態檢定,提供skew及kurtosis等參數

102
結果說明 估計方法 配適指標 MLE(實務上的最佳法)是SEM的標準內定估計法,即使在小様本、過高的峰態仍有不錯的表現。
ADF(理論上的最佳法) ,不論資料呈現何種分佈,樣本需2000個以上。 配適指標 絕對配適指標 增值配適指標 精簡配適指標 競爭配適指標
 ,不論資料呈現何種分佈,樣本需2000個以上。 配適指標. 絕對配適指標. 增值配適指標. 精簡配適指標. 競爭配適指標.")
103
結果說明 參數的估計 估計參數值要在可接受的範圍內
Heywood cases (負的變異數) 超出範圍的共變異數(標準化估計值大於1) 不要使用希臘字母及下標代表參數名字 估計標準誤及臨界值 (critical ratio, estimate/standard error) 不要重新估計之前被固定非0的值 如每個因素都有一個觀察變數loading設為1 報告整體配適度的同時,也要在論文解釋每一個估計參數
 超出範圍的共變異數(標準化估計值大於1) 不要使用希臘字母及下標代表參數名字. 估計標準誤及臨界值 (critical ratio, estimate/standard error) 不要重新估計之前被固定非0的值. 如每個因素都有一個觀察變數loading設為1. 報告整體配適度的同時,也要在論文解釋每一個估計參數.")
104
結果說明 競爭模型 (alternative models)
或在分析過程中發現假設模型設定錯誤時,事後修正後的模型 (Model Specification)。 競爭模型分成巢形比較(Δχ2及ΔCFI檢定)及非巢形比較(ECVI及AIC)兩大類。
。 競爭模型分成巢形比較(Δχ2及ΔCFI檢定)及非巢形比較(ECVI及AIC)兩大類。")
105
結果說明 模型修正的兩個問題 MacCullum et.al.(1992) ,如果沒有具體而充份的理由,所有的修正都是不建議的。
測量誤差設定相關 測量誤差與其它測量變數設定相關 MacCullum et.al.(1992) ,如果沒有具體而充份的理由,所有的修正都是不建議的。
 ,如果沒有具體而充份的理由,所有的修正都是不建議的。")
106
結果說明 等值模型 統計上的等值模型是常忽略的競爭模型 等值模型與假設模型包含了相同的變數及精簡程度,應該要考慮進來。
MacCullum et.al.(1993)建議應該在文章中新增一節討論等值模型,以利了解為何模型要假設成這樣,而不是其它的關係。
建議應該在文章中新增一節討論等值模型,以利了解為何模型要假設成這樣,而不是其它的關係。")
107
模型配適的額外資訊 統計檢定力 交叉效度 在社會及行為科學研究中,有些研究人員會宣稱其分析樣本夠大足以達到研究目的代表性。
SEM的統計檢定力是模型樣本大小的函數 低的POWER會導致顯著的卡方值及模型配適度不佳時,無法拒絕模型。 交叉效度 可檢定模型本身是否具模型穩定性。

108
解釋與推論 解釋假設模型中每一個相關或因果關係,含標準化及非標準化係數。 如果樣本不夠大,可信度會降低,其估計值及推論應小心探討。
資料有非常態應該要報告並採取相對的分析策略。

109
Jackson and Gillaspy, 2009

Similar presentations


 如何建立資料. 原始資料範例 a1~a5 表示選擇題,輸入原始答案,如 A 、B、C、D b1~b5 表示填充題, c1~c5 表示計算題,輸入得分.>")




>")





 Wonnacott and Wonnacott. Introductory>")

 电 话:>")




