Download presentation
Presentation is loading. Please wait.

1
第四章 随机变量的数字特征 主讲教师:董庆宽 副教授 研究方向:密码学与信息安全 电子邮件:qkdong@xidian.edu.cn
本科生必修课:概率论与数理统计 第四章 随机变量的数字特征 主讲教师:董庆宽 副教授 研究方向:密码学与信息安全 个人主页:

2
第四章 随机变量的数字特征 §4.1 数学期望 §4.2 方差 §4.3 协方差及相关系数 §4.4 矩、协方差矩阵

3
§4.1 数学期望 概率分布虽然能够完整的描述随机变量的统计特征但却不直观。如: 本章重点讨论数学期望,方差,相关系数,矩等
研究水稻品种时,常关注的是稻穗的平均稻谷粒数,这从稻谷粒数的分布函数是不能直接看出来的,而且在实际生产中可能只关心该平均值,甚至不关心分布函数。 一篮球队上场比赛的运动员身高是一随机变量,常关心平均身高 研究信道上的随机噪声时,出于热噪声功率对系统可能产生较大影响的考虑,对噪声的均值很关心,而且还关心噪声电压的大小与噪声电压的均值的偏离程度。这两个量在实际系统中往往比知道随机变量的分布更重要 本章重点讨论数学期望,方差,相关系数,矩等

4
§4.1 数学期望 实例:一射手进行打靶练习,规定 以X记每次射击得分数,则X的分布律如下: X 0 1 2 pk p0 p1 p2
打中区域e0得0分 打中区域e1得1分 打中区域e2得2分 以X记每次射击得分数,则X的分布律如下: X pk p0 p1 p2

5
§4.1 数学期望 考察每次射击的平均得分数? 射击N次,其中得0分有a0次,得1分有a1次,得2分有a2次 即N=a0+a1+a2
这是有限次实验的算术平均值,其中 是事件P{X=k}的频率。 当N→∞时, 无限的接近一个稳定的常数pk,即事件P{X=k}发生的概率 也就是说,当N→∞时,算术平均值 → 一个稳定的常数值,就把该值称为随机变量X的数学期望或均值Expectation

6
§4.1 数学期望 定义 设离散型随机变量X的分布律为 P{X=xk}=pk,k=1,2,…
若级数 绝对收敛,则称级数 的和为随机变量X的数学期望,记为E(X), 即E(X)= 设连续型随机变量X的概率密度为f(x),若积分 绝对收敛,则称积分 的值为随机变量X的数学期望,记为E(X),
, 即E(X)= 设连续型随机变量X的概率密度为f(x),若积分. 绝对收敛,则称积分 的值为随机变量X的数学期望,记为E(X),")
7
§4.1 数学期望 数学期望简称期望,又称为均值 物理意义
E(X)是实数而非变量,它是一种加权平均,与一般变量的算术平均值不同。大量试验的算术平均值趋近于期望 质心的概念:可以把物体的质量看作是集中在一点处,如果一条直线的质量线密度为f(x),x为直线上任一质点的坐标,那么直线的质心的位置xc=? xc= / 现在如果f(x)是概率密度,则 xc= / = /1 即xc=E(X),数学期望相当于质心的坐标
是实数而非变量,它是一种加权平均,与一般变量的算术平均值不同。大量试验的算术平均值趋近于期望. 质心的概念:可以把物体的质量看作是集中在一点处,如果一条直线的质量线密度为f(x),x为直线上任一质点的坐标,那么直线的质心的位置xc=? xc= / 现在如果f(x)是概率密度,则. xc= / = /1. 即xc=E(X),数学期望相当于质心的坐标.")
8
§4.1 数学期望 只有级数的和或广义积分的值存在,数学期望才有意义,而有时是不存在的 数学期望E(X)完全由随机变量X的概率分布所确定
注意绝对收敛与条件收敛的区别,某些交错级数是条件收敛的,其和可能不为一,因此期望不存在。如果一个数项级数{un}的各项取绝对值后满足收敛,则称数项级数{un}绝对收敛,相应的如果绝对值的积分收敛,则绝对收敛 数学期望E(X)完全由随机变量X的概率分布所确定 若X服从某一分布,也称E(X)为这一分布的数学期望,比如二项分布,均匀分布等的数学期望
完全由随机变量X的概率分布所确定. 若X服从某一分布,也称E(X)为这一分布的数学期望,比如二项分布,均匀分布等的数学期望.")
9
§4.1 数学期望 例 设随机变量 X服从柯西分布,其密度函数为 求E(X). 解: 由于积分 因此柯西分布的数学期望不存在.
. 解: 由于积分 因此柯西分布的数学期望不存在.")
10
§4.1 数学期望 例:甲乙两人打靶,所得分数X和Y分布律为 X 0 1 2 Y 0 1 2
pk pk 试评定它们成绩的好坏 解 主要看多次射击的得分均值,即数学期望, 离散型:E(X)= E(X)=0×0+1×0.2+2×0.8=1.8分 E(Y)=0×0.6+1×0.3+2×0.1=0.5分 所以乙的成绩远不如甲的成绩
= E(X)=0×0+1×0.2+2×0.8=1.8分. E(Y)=0×0.6+1×0.3+2×0.1=0.5分. 所以乙的成绩远不如甲的成绩.")
11
§4.1 数学期望 例2 有两个相互独立工作的电子装置,寿命X1和X2服从同一指数分布 f(x)= ,θ>0.
若将二者串联成整机,求整机寿命N的数学期望E(N) 解 N=min(X1,X2),要求期望,先求概率密度,本题要先求N的分布函数 ∴Fmin(x)=1-[1-F(x)]2 //X1,X2独立同分布 又F(x)= , ∴Fmin(x)=1-[1-F(x)]2= ∴fmin(x)= ,服从参数为θ/2的指数分布 ∴E(N)= =θ/2,指数分布的均值即参数θ/2
 解 N=min(X1,X2),要求期望,先求概率密度,本题要先求N的分布函数. ∴Fmin(x)=1-[1-F(x)]2 //X1,X2独立同分布. 又F(x)= , ∴Fmin(x)=1-[1-F(x)]2= ∴fmin(x)= ,服从参数为θ/2的指数分布. ∴E(N)= =θ/2,指数分布的均值即参数θ/2.")
12
§4.1 数学期望 例3 如何确定投资决策方向? 某人有10万元现金, 想投资 于某项目, 欲估成功的机会为 30
例3 如何确定投资决策方向? 某人有10万元现金, 想投资 于某项目, 欲估成功的机会为 30 %, 可得利润8万元 , 失败的机会 为70%, 将损失 2 万元.若存入银 行, 同期间的利率为5% , 问是否 作此项投资? 解 设 X 为投资利润,则 存入银行的利息: 故应选择投资.

13
§4.1 数学期望 例 设随机变量X服从 求E(X) 解 E(X)=
 解 E(X)=")
14
§4.1 数学期望 例 到站时刻 概率

15
§4.1 数学期望 解

16
§4.1 数学期望 随机变量的函数的数学期望 比如:飞机机翼受到的正压力W=kV2是风速V的函数,如果V的分布已知,如何求得W的数学期望,而无需先求出W的分布 先由V的分布求其函数W的分布,再求数学期望是可以的,而还有更简单直接的求解方法

17
§4.1 数学期望 定理 这样求E(Y)而不必算出Y的分布 设Y是随机变量X的函数:Y=g(X),其中g是连续函数
(i) X是离散型随机变量,分布律为 P{X=xk}=pk,k=1,2,… 若级数 绝对收敛,则有 E(Y)=E(g(X))= (ii)X是连续型随机变量,概率密度为f(x), 若积分 绝对收敛,则有 E(Y)=E(g(X))= 这样求E(Y)而不必算出Y的分布
 X是离散型随机变量,分布律为. P{X=xk}=pk,k=1,2,… 若级数 绝对收敛,则有 E(Y)=E(g(X))= (ii)X是连续型随机变量,概率密度为f(x), 若积分 绝对收敛,则有. E(Y)=E(g(X))= 这样求E(Y)而不必算出Y的分布.")
18
§4.1 数学期望 定理的证明(略),以下对离散型X进行简要说明 E(Y)= = = = = 实际上是对所有的X的取值的概率的加权求和
= = = 实际上是对所有的X的取值的概率的加权求和 E(Y) = 连续型的特例情况下证明,请参看教材
 = 连续型的特例情况下证明,请参看教材.")
19
§4.1 数学期望 推广:多维随机变量(X1,X2,…,Xn)的函数Y=g(X1,X2,…,Xn)也满足以上定理。
例如:若Z=g(X,Y),且g是连续函数,则 若(X,Y)是连续型随机变量,概率密度为f(x,y),那么 E(Z)=E(g(X,Y))= 只要该积分绝对收敛则存在 若(X,Y)是离散型随机变量,分布律P{X=xi,Y=yj}=pij,i,j=1,2, …那么 E(Z)=E(g(X,Y))= , 右边级数绝对收敛
,且g是连续函数,则. 若(X,Y)是连续型随机变量,概率密度为f(x,y),那么. E(Z)=E(g(X,Y))= 只要该积分绝对收敛则存在. 若(X,Y)是离散型随机变量,分布律P{X=xi,Y=yj}=pij,i,j=1,2, …那么. E(Z)=E(g(X,Y))= , 右边级数绝对收敛.")
20
§4.1 数学期望 例9:设随机变量(X,Y)的概率密度为 f(x,y)= 求数学期望E(Y),E(1/(XY))
解 此时可以看成是函数z=g(x,y)=y 这样E(Z)=E(Y)= = = =3/4 也可以先求Y的边缘概率密度,再用数学期望定义求解 对于第2个问题 E(Z)=E(1/(XY))= = =3/5
=y. 这样E(Z)=E(Y)= = = =3/4. 也可以先求Y的边缘概率密度,再用数学期望定义求解. 对于第2个问题. E(Z)=E(1/(XY))= = =3/5.")
21
§4.1 数学期望 例10 设 (X ,Y) 的分布律为 解
 的分布律为 解")
22
§4.1 数学期望 由于

23
§4.1 数学期望

24
§4.1 数学期望 例10:某公司计划开发一种新产品市场,并试图确定该产品的产量,他们估计 售一件产品可获利m元,积压一件产品亏损n元
现在可预测销售量Y服从参数为θ的指数分布 f(x)= ,θ>0. 问若要获得利润的数学期望最大,应生产多少件产品? 解:显然获利多少Q是生产产品数量x(确定量)和销售量Y(随机变量)的函数 Q=Q(x,Y)= , 从随机变量的角度看,Q是一个随机变量,它是Y的函数,而Y的分布已知
= ,θ>0. 问若要获得利润的数学期望最大,应生产多少件产品? 解:显然获利多少Q是生产产品数量x(确定量)和销售量Y(随机变量)的函数. Q=Q(x,Y)= , 从随机变量的角度看,Q是一个随机变量,它是Y的函数,而Y的分布已知.")
25
§4.1 数学期望 固有E(Q)= = = + =(m+n)θ-(m+n)θe-x/θ-nx
= + =(m+n)θ-(m+n)θe-x/θ-nx 令dE(Q)/dx=(m+n)θe-x/θ-n =0得到x= 又d2E(Q)/dx2= , 所以x= 时E(Q)取唯一极大值,即最大值
θ-(m+n)θe-x/θ-nx. 令dE(Q)/dx=(m+n)θe-x/θ-n =0得到x= 又d2E(Q)/dx2= , 所以x= 时E(Q)取唯一极大值,即最大值.")
26
§4.1 数学期望 数学期望的性质 1°设C是常数,则有E(C)=C 2°设X是一个随机变量,C是常数,则有 E(CX)=CE(X)
相当于X=C为必然事件,分布律为P{X=C}=1 所以,E(C)=C×1=C 2°设X是一个随机变量,C是常数,则有 E(CX)=CE(X) 证:令Y=CX,则Y是X的函数,则 E(Y)=E(CX)= = =CE(X)
=C×1=C. 2°设X是一个随机变量,C是常数,则有. E(CX)=CE(X) 证:令Y=CX,则Y是X的函数,则. E(Y)=E(CX)= = =CE(X)")
27
§4.1 数学期望 3°设X,Y是两个随机变量,则有 E(X+Y)=E(X)+ E(Y) 证:仅就连续型的随机变量加以证明
可推广到任意有限个随机变量之和的情况 证:仅就连续型的随机变量加以证明 设二维随机变量(X,Y)的概率密度f(x,y),边缘概率密度为fX(x), fY(y) E(X+Y)= = + = + =E(X)+ E(Y)
的概率密度f(x,y),边缘概率密度为fX(x), fY(y) E(X+Y)= = + = + =E(X)+ E(Y)")
28
§4.1 数学期望 4°设X,Y是相互独立的随机变量,则有 E(XY)=E(X)E(Y) 证:仅证连续型 E(XY)= =
可以推广到任意有限个独立随机变量之积的情况 证:仅证连续型 E(XY)= = =[ ][ ]=E(X)E(Y) 有了以上性质后,再求解数学期望的问题时就可利用性质,简化求解复杂度
= = =[ ][ ]=E(X)E(Y) 有了以上性质后,再求解数学期望的问题时就可利用性质,简化求解复杂度.")
29
§4.1 数学期望 例12 随机变量分解 解

30
§4.1 数学期望 将X分解成数个随机变量之和,然后利用随机变量和的数学期望等于随机变量数学期望之和来求解数学期望
典型的例子是二项分布的随机变量可以分解为若干个0-1分布的随机变量只和

31
§4.1 数学期望 例 设 求: 解

32
§4.1 数学期望 例4 解 I和R相互独立

33
§4.2 方差 方差主要考虑的是随机变量的取值与其均值偏离程度
例如:电子器件的热噪声,其产生的噪声电压的均值可能为0,但是噪声电压的大小可能很不一样,从而对信号处理的影响也不一样,噪声的功率也不同,因此我们常常关心噪声电压与均值电压的偏离程度, 设噪声电压为X,均值为E(X),则偏离程度Y很容易用二者之差来描述,即 Y=|X-E(X)| 而我们通常考察平均偏离程度,即考察 E{|X-E(X)|} 由于该式中含有绝对值,运算不方便,通常用下式来描述X与均值的偏离程度 E{[X-E(X)]2}
,则偏离程度Y很容易用二者之差来描述,即 Y=|X-E(X)| 而我们通常考察平均偏离程度,即考察 E{|X-E(X)|} 由于该式中含有绝对值,运算不方便,通常用下式来描述X与均值的偏离程度 E{[X-E(X)]2}")
34
§4.2 方差 定义 设X是一个随机变量,若E{[X-E(X)]2}存在,则称E{[X-E(X)]2}为X的方差,记为D(X)或Var(X),Variance 即 D(X)=Var(X)=E{[X-E(X)]2} 应用上还引入与随机变量X具有相同量纲的量 ,记为σ(X),称为标准差或均方差 方差的含义: 由定义可知,方差表达了随机变量X取值与其数学期望的偏离程度,并表达了以E(X)为X的代表性的好坏 如果X取值比较集中,则偏离程度小,D(X)也较小, E(X) 的代表性好 如果X取值比较分散,则偏离程度大,D(X)也较大 所以说D(X)是描述X分散程度的量
![§4.2 方差 定义 设X是一个随机变量,若E{[X-E(X)]2}存在,则称E{[X-E(X)]2}为X的方差,记为D(X)或Var(X),Variance. 即 D(X)=Var(X)=E{[X-E(X)]2}](http://slidesplayer.com/slide/11609274/62/images/34/%C2%A74.2+%E6%96%B9%E5%B7%AE+%E5%AE%9A%E4%B9%89+%E8%AE%BEX%E6%98%AF%E4%B8%80%E4%B8%AA%E9%9A%8F%E6%9C%BA%E5%8F%98%E9%87%8F%EF%BC%8C%E8%8B%A5E%7B%5BX%EF%BC%8DE%28X%29%5D2%7D%E5%AD%98%E5%9C%A8%EF%BC%8C%E5%88%99%E7%A7%B0E%7B%5BX%EF%BC%8DE%28X%29%5D2%7D%E4%B8%BAX%E7%9A%84%E6%96%B9%E5%B7%AE%EF%BC%8C%E8%AE%B0%E4%B8%BAD%28X%29%E6%88%96Var%28X%29%EF%BC%8CVariance.+%E5%8D%B3+D%28X%29%EF%BC%9DVar%28X%29%EF%BC%9DE%7B%5BX%EF%BC%8DE%28X%29%5D2%7D.jpg "应用上还引入与随机变量X具有相同量纲的量 ,记为σ(X),称为标准差或均方差. 方差的含义: 由定义可知,方差表达了随机变量X取值与其数学期望的偏离程度,并表达了以E(X)为X的代表性的好坏. 如果X取值比较集中,则偏离程度小,D(X)也较小, E(X) 的代表性好. 如果X取值比较分散,则偏离程度大,D(X)也较大. 所以说D(X)是描述X分散程度的量.")
35
§4.2 方差 方差的计算方法:(1)利用定义 由定义,方差实际上是X的函数g(X)=[X-E(X)]2的数学期望 对于离散型随机变量X:
D(X)=E{g(X)}= = , 其中,X的分布律为P{X=xk}=pk,k=1,2,… 对于连续型随机变量X: D(X)=E{g(X)}= = 其中f(x)是X的概率密度
![§4.2 方差 方差的计算方法:(1)利用定义 由定义,方差实际上是X的函数g(X)=[X-E(X)]2的数学期望 对于离散型随机变量X:](http://slidesplayer.com/slide/11609274/62/images/35/%C2%A74.2+%E6%96%B9%E5%B7%AE+%E6%96%B9%E5%B7%AE%E7%9A%84%E8%AE%A1%E7%AE%97%E6%96%B9%E6%B3%95%EF%BC%9A%281%29%E5%88%A9%E7%94%A8%E5%AE%9A%E4%B9%89+%E7%94%B1%E5%AE%9A%E4%B9%89%EF%BC%8C%E6%96%B9%E5%B7%AE%E5%AE%9E%E9%99%85%E4%B8%8A%E6%98%AFX%E7%9A%84%E5%87%BD%E6%95%B0g%28X%29%3D%5BX%EF%BC%8DE%28X%29%5D2%E7%9A%84%E6%95%B0%E5%AD%A6%E6%9C%9F%E6%9C%9B+%E5%AF%B9%E4%BA%8E%E7%A6%BB%E6%95%A3%E5%9E%8B%E9%9A%8F%E6%9C%BA%E5%8F%98%E9%87%8FX%EF%BC%9A.jpg "D(X)=E{g(X)}= = , 其中,X的分布律为P{X=xk}=pk,k=1,2,… 对于连续型随机变量X: D(X)=E{g(X)}= = 其中f(x)是X的概率密度.")
36
§4.2 方差 方差的计算方法:(2)利用方差恒等式 D(X)=E(X2)-[E(X)]2; 更重要的是E(X2)=D(X)+[E(X)]2
证:由数学期望的性质 D(X)=E{[X-E(X)]2}=E{X2-2XE(X)+[E(X)]2} =E{X2}-2E(X)E(X)+[E(X)]2=E(X2)-[E(X)]2 这样,求解方差时,除定义式外,可直接利用以上公式 首先计算E(X), 然后计算E(X2), 最后计算D(X)=E(X2)-[E(X)]2
![§4.2 方差 方差的计算方法:(2)利用方差恒等式 D(X)=E(X2)-[E(X)]2; 更重要的是E(X2)=D(X)+[E(X)]2](http://slidesplayer.com/slide/11609274/62/images/36/%C2%A74.2+%E6%96%B9%E5%B7%AE+%E6%96%B9%E5%B7%AE%E7%9A%84%E8%AE%A1%E7%AE%97%E6%96%B9%E6%B3%95%EF%BC%9A%282%29%E5%88%A9%E7%94%A8%E6%96%B9%E5%B7%AE%E6%81%92%E7%AD%89%E5%BC%8F+D%28X%29%EF%BC%9DE%28X2%29%EF%BC%8D%5BE%28X%29%5D2%EF%BC%9B+%E6%9B%B4%E9%87%8D%E8%A6%81%E7%9A%84%E6%98%AFE%28X2%29%EF%BC%9DD%28X%29%EF%BC%8B%5BE%28X%29%5D2.jpg "证:由数学期望的性质. D(X)=E{[X-E(X)]2}=E{X2-2XE(X)+[E(X)]2} =E{X2}-2E(X)E(X)+[E(X)]2=E(X2)-[E(X)]2. 这样,求解方差时,除定义式外,可直接利用以上公式. 首先计算E(X), 然后计算E(X2), 最后计算D(X)=E(X2)-[E(X)]2.")
37
§4.2 方差 随机变量的标准化: 所以X*的数学期望0,方差1,X*称为X的标准化变量
设随机变量X具有数学期望E(X)=μ,方差D(X)=σ2≠0,记X*=(X-μ)/σ, 则E(X*)=E(X-μ)/σ=(E(X)-μ)/σ=0 D(X*)=E(X*2)-[E(X*)]2=E([(X-μ)/σ]2)-0 =(1/σ2)E((X-μ)2) =(1/σ2)σ2=1 所以X*的数学期望0,方差1,X*称为X的标准化变量
=μ,方差D(X)=σ2≠0,记X*=(X-μ)/σ, 则E(X*)=E(X-μ)/σ=(E(X)-μ)/σ=0. D(X*)=E(X*2)-[E(X*)]2=E([(X-μ)/σ]2)-0. =(1/σ2)E((X-μ)2) =(1/σ2)σ2=1. 所以X*的数学期望0,方差1,X*称为X的标准化变量.")
38
§4.2 方差 方差的性质 1°设 C 是常数, 则有 证明 2°设 X 是一个随机变量, C 是常数, 则有 证明

39
§4.2 方差 3°设X,Y是两个随机变量,则有 D(X+Y)=D(X)+D(Y)+2E{[X-E(X)][Y-E(Y)]},
这一性质可以推广到任意有限多个相互独立的随机变量之和的情况。 证:D(X+Y)=E{[(X+Y)-E(X+Y)]2}= E{[(X-E(X))+(Y-E(Y))]2} =E{[X-E(X)]2}+E{[Y-E(Y)]2}+2E{[X-E(X)][Y-E(Y)]} =D(X)+D(Y)+2E{[X-E(X)][Y-E(Y)]} 又E{[X-E(X)][Y-E(Y)]}=E{XY-XE(Y)-YE(X)+E(X)E(Y)} =E(XY)-E(X)E(Y)-E(Y)E(X)+E(X)E(Y) =E(XY)-E(X)E(Y) 当X,Y相互独立时,由数学期望的性质有E(XY)=E(X)E(Y),从而有 D(X+Y)=D(X)+D(Y)
![§4.2 方差 3°设X,Y是两个随机变量,则有 D(X+Y)=D(X)+D(Y)+2E{[X-E(X)][Y-E(Y)]},](http://slidesplayer.com/slide/11609274/62/images/39/%C2%A74.2+%E6%96%B9%E5%B7%AE+3%C2%B0%E8%AE%BEX%2CY%E6%98%AF%E4%B8%A4%E4%B8%AA%E9%9A%8F%E6%9C%BA%E5%8F%98%E9%87%8F%EF%BC%8C%E5%88%99%E6%9C%89+D%28X%EF%BC%8BY%29%EF%BC%9DD%28X%29%EF%BC%8BD%28Y%29%EF%BC%8B2E%7B%5BX%EF%BC%8DE%28X%29%5D%5BY%EF%BC%8DE%28Y%29%5D%7D%EF%BC%8C.jpg "这一性质可以推广到任意有限多个相互独立的随机变量之和的情况。 证:D(X+Y)=E{[(X+Y)-E(X+Y)]2}= E{[(X-E(X))+(Y-E(Y))]2} =E{[X-E(X)]2}+E{[Y-E(Y)]2}+2E{[X-E(X)][Y-E(Y)]} =D(X)+D(Y)+2E{[X-E(X)][Y-E(Y)]} 又E{[X-E(X)][Y-E(Y)]}=E{XY-XE(Y)-YE(X)+E(X)E(Y)} =E(XY)-E(X)E(Y)-E(Y)E(X)+E(X)E(Y) =E(XY)-E(X)E(Y) 当X,Y相互独立时,由数学期望的性质有E(XY)=E(X)E(Y),从而有. D(X+Y)=D(X)+D(Y)")
40
§4.2 方差 推广 “以概率1”的含义:对于连续型随机变量,如果存在一些孤立的点其随机变量的取值不为常数,那么不影响结论,这和独立性中几乎处处成立有点类似 所以在这一前提下,X不一定等于C 另外,不难证明有如下不等式成立

41
§4.2 方差 契比雪夫(Chebyshev)不等式
定理 设随机变量X具有数学期望E(X)=μ,方差D(X)=σ2,则对于任意正数ε,以下不等式成立 契比雪夫不等式是一个重要的理论工具,应用极为普遍,很多重要结论都来自于该不等式,对于任意的数学期望和方差都存在的随机变量都成立 证:
=μ,方差D(X)=σ2,则对于任意正数ε,以下不等式成立. 契比雪夫不等式是一个重要的理论工具,应用极为普遍,很多重要结论都来自于该不等式,对于任意的数学期望和方差都存在的随机变量都成立. 证:")
42
§4.2 方差 契比雪夫不等式的变形 该不等式给出了随机变量X分布未知的情况下事件概率的下限的估计,具有普适性。如取ε=3σ,有 ,这一结果具有普遍意义的3σ准则,可以与正态分布的3σ准则比较一下, 又 概率值近1

43
契比雪夫资料 Pafnuty Chebyshev
Born: 16 May 1821 in Okatovo, Russia Died: 8 Dec 1894 in St Petersburg, Russia

44
§4.2 方差 几种重要分布的数学期望和方差 (一) (0-1)分布 X 0 1 pk 1-p p E(X)=0×(1-p)+1×p=p
D(X)=E(X2)-[E(X)]2=p-p2=p(1-p)
=E(X2)-[E(X)]2=p-p2=p(1-p)")
45
§4.2 方差 (二) 二项分布 X~b(n,p) 分布律为P{X=k}= pkqn-k,k=0,1,…,n,(q=1-p)
(i)直接法:组合拆分 E(X)= ,而 = 所以E(X)= = = =np E(X2)= , 而 = + = + E(X2)= = =n(n-1)p2+np D(X)=E(X2)-[E(X)]2=n(n-1)p2+np-(np)2=np(1-p)
直接法:组合拆分. E(X)= ,而 = 所以E(X)= = = =np. E(X2)= , 而 = + = + E(X2)= = =n(n-1)p2+np. D(X)=E(X2)-[E(X)]2=n(n-1)p2+np-(np)2=np(1-p)")
46
§4.2 方差 (ii)间接法:随机变量分解(变量拆分)
随机变量X表示n重伯努利实验中n次相互独立的重复实验中事件A发生的次数,引入n个随机变量Xi,i=1, 2,…, 其中,Xi= , 于是有X=X1+X2+…+Xn Xi 且由题设易知Xi服从同一(0-1)分布 pk 1-p p X可以分解为n个参数为p的(0-1)分布的独立同分布的变量之和 由Xi的独立性,及数学期望和方差的性质易得 E(X)=E(X1+X2+…+Xn)=E(X1)+E(X2)+…+E(Xn)=np D(X)=D(X1+X2+…+Xn)=D(X1)+D(X2)+…+D(Xn)=np(1-p)
分布 pk 1-p p. X可以分解为n个参数为p的(0-1)分布的独立同分布的变量之和. 由Xi的独立性,及数学期望和方差的性质易得. E(X)=E(X1+X2+…+Xn)=E(X1)+E(X2)+…+E(Xn)=np. D(X)=D(X1+X2+…+Xn)=D(X1)+D(X2)+…+D(Xn)=np(1-p)")
47
§4.2 方差 (三) 泊松分布X~π(λ),(期望等于方差) E(X)= = = =λ E(X2)= = + = +λ=λ2+λ
= +λ=λ2+λ D(X)=E(X2)-[E(X)]2=λ2+λ-λ2=λ
=E(X2)-[E(X)]2=λ2+λ-λ2=λ.")
48
§4.2 方差 (四) 均匀分布X~U(a,b) E(X)= = = E(X2)= = = D(X)=E(X2)-[E(X)]2 = - =
![§4.2 方差 (四) 均匀分布X~U(a,b) E(X)= = = E(X2)= = = D(X)=E(X2)-[E(X)]2.](http://slidesplayer.com/slide/11609274/62/images/48/%C2%A74.2+%E6%96%B9%E5%B7%AE+%28%E5%9B%9B%29+%E5%9D%87%E5%8C%80%E5%88%86%E5%B8%83X%EF%BD%9EU%28a%2Cb%29+E%28X%29%EF%BC%9D+%3D+%3D+E%28X2%29%EF%BC%9D+%EF%BC%9D+%EF%BC%9D+D%28X%29%EF%BC%9DE%28X2%29%EF%BC%8D%5BE%28X%29%5D2..jpg "= - =")
49
§4.2 方差 (五) 指数分布 f(x)= ,θ>0. E(X)= = = =θ E(X2)= = = =2θ 2
= =θ E(X2)= = = =2θ 2 D(X)=E(X2)-[E(X)]2=2θ 2-θ 2=θ 2
= = = =2θ 2. D(X)=E(X2)-[E(X)]2=2θ 2-θ 2=θ 2.")
50
§4.2 方差 (六) 正态分布X~N(μ,σ 2) 正态分布稍复杂,先求标准正态分布 Z= ~N(0,1),
φ(Z)= ,-∞<z<∞ E(Z)= = = =0 D(Z)=E(Z2)-[E(Z)]2=E(Z2)= = + =1
= ,-∞<z<∞ E(Z)= = = =0. D(Z)=E(Z2)-[E(Z)]2=E(Z2)= = + =1.")
51
§4.2 方差 这样由于X=σZ+μ E(X)=E(σZ+μ)= E(σZ)+μ=σE(Z)+μ=μ
D(X)=D(σZ+μ) = E{[(σZ+μ)-E(σZ+μ)]2} = E{(σZ)2} =σ2E(Z2) =σ2D(Z) =σ2 所以在正态分布中,两个参数μ,σ2分别为数学期望和方差 有限个相互独立的正态随机变量的任意线性组合仍然服从正态分布 因此由数学期望和方差的性质易知, Z=a1X1+ a2X2+,…,+ anXn~N(a1μ1+a2μ2+…+anμn,(a1σ1)2+(a2σ2)2+…+(anσn)2)
=D(σZ+μ) = E{[(σZ+μ)-E(σZ+μ)]2} = E{(σZ)2} =σ2E(Z2) =σ2D(Z) =σ2. 所以在正态分布中,两个参数μ,σ2分别为数学期望和方差. 有限个相互独立的正态随机变量的任意线性组合仍然服从正态分布. 因此由数学期望和方差的性质易知, Z=a1X1+ a2X2+,…,+ anXn~N(a1μ1+a2μ2+…+anμn,(a1σ1)2+(a2σ2)2+…+(anσn)2)")
52
分 布 参数 数学期望 方差 (0-1)分布 二项分布 泊松分布 几何分布 均匀分布 指数分布 正态分布 分布
分布 二项分布 泊松分布 几何分布 均匀分布 指数分布 正态分布 分布")
53
§4.2 方差 例1 解 于是

54
§4.2 方差 例 解

55
§4.2 方差

56
§4.2 方差 因此有

57
§4.2 方差

58
§4.2 方差 例 证明

59
§4.2 方差

60
§4.2 方差 故得

61
§4.2 方差 例5 解

62
§4.3 协方差及相关系数 对于二维随机变量(X,Y) 若X和Y相互独立,根据独立性的相关定理
则显然有X-E(X)和Y-E(Y)也相互独立 于是有E{[X-E(X)][Y-E(Y)]}=0 若X和Y不相互独立,则E{[X-E(X)][Y-E(Y)]}不一定等于0 这表明了X和Y之间的相关性,而我们以X-E(X)和Y-E(Y)来讨论相关性,是与方差的概念相适应,我们有如下协方差的定义 协方差定义 量E{[X-E(X)][Y-E(Y)]}称为随机变量X与Y的协方差,记为Cov(X,Y),即 Cov(X,Y)=E{[X-E(X)][Y-E(Y)]}
和Y-E(Y)也相互独立. 于是有E{[X-E(X)][Y-E(Y)]}=0. 若X和Y不相互独立,则E{[X-E(X)][Y-E(Y)]}不一定等于0. 这表明了X和Y之间的相关性,而我们以X-E(X)和Y-E(Y)来讨论相关性,是与方差的概念相适应,我们有如下协方差的定义. 协方差定义 量E{[X-E(X)][Y-E(Y)]}称为随机变量X与Y的协方差,记为Cov(X,Y),即. Cov(X,Y)=E{[X-E(X)][Y-E(Y)]}")
63
§4.3 协方差及相关系数 方差与协方差之间的关系: 1) Cov(X,X)=D(X) 2) 对任意的X和Y,下列等式成立
D(X+Y)=E{[(X+Y)-E(X+Y)]2} =E{[(X-E(X))+(Y-E(Y))]2} =E{[X-E(X)]2}+E{[Y-E(Y)]2} +2E{[X-E(X)][Y-E(Y)]} =D(X)+D(Y)+2Cov(X,Y) 当X和Y相互独立时,协方差为0,此时D(X+Y)=D(X)+D(Y)
=E{[(X+Y)-E(X+Y)]2} =E{[(X-E(X))+(Y-E(Y))]2} =E{[X-E(X)]2}+E{[Y-E(Y)]2} +2E{[X-E(X)][Y-E(Y)]} =D(X)+D(Y)+2Cov(X,Y) 当X和Y相互独立时,协方差为0,此时D(X+Y)=D(X)+D(Y)")
64
§4.3 协方差及相关系数 协方差的一个计算公式 Cov(X,Y)=E(XY)-E(Y)E(Y) 协方差的性质:
1°Cov(X,Y)=Cov(Y,X) 2°Cov(aX,bY)=abCov(X, Y),a,b是常数 3°Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y) 相关系数定义 称为随机变量X和Y的相关系数 ρXY是一个无量纲的量
=Cov(Y,X) 2°Cov(aX,bY)=abCov(X, Y),a,b是常数. 3°Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y) 相关系数定义. 称为随机变量X和Y的相关系数. ρXY是一个无量纲的量.")
65
§4.3 协方差及相关系数 相关系数的性质 先来看一个问题:对于任意的两个随机变量X和Y,以X的线性函数a+bX来近似表示Y,并以Y和a+bX的均方误差e来衡量a+bX近似表达Y的好坏程度。其中均方误差定义为: e=E{[Y-(a+bX)]2}=E(Y2)+b2E(X2)+a2 -2bE(XY)+2abE(X)-2aE(Y) 显然e的值越小近似程度越好 这种方法类似于最小二乘法
]2}=E(Y2)+b2E(X2)+a2. -2bE(XY)+2abE(X)-2aE(Y) 显然e的值越小近似程度越好. 这种方法类似于最小二乘法.")
66
§4.3 协方差及相关系数 现在来确定一下a和b取何值时该均方误差最小
(2)-(1)×E(X)得:2bE(X2)-2E(XY)+2E(X)E(Y)-2b(E(X))2=0 即bD(X)=E(XY)-E(X)E(Y)=Cov(X,Y) ∴b0=Cov(X,Y)/D(X) a0=E(Y)-b0E(X)=E(Y)-E(X)[Cov(X,Y)/D(X)]
-(1)×E(X)得:2bE(X2)-2E(XY)+2E(X)E(Y)-2b(E(X))2=0. 即bD(X)=E(XY)-E(X)E(Y)=Cov(X,Y) ∴b0=Cov(X,Y)/D(X) a0=E(Y)-b0E(X)=E(Y)-E(X)[Cov(X,Y)/D(X)]")
67
§4.3 协方差及相关系数 即当a=a0,b=b0时均方误差e取最小值 = = D(Y)+ = D(Y)(1- )=(1- )D(Y)
由上式很容易得到相关系数的两个性质

68
§4.3 协方差及相关系数 相关系数的性质 定理: 证明 又D(Y)和 非负,对任意的X,Y都成立
和 非负,对任意的X,Y都成立")
69
§4.3 协方差及相关系数 2°充分性: 若|ρXY|=1, 则 =(1- )D(Y)=0 又E(X2)=D(X)+(E(X))2
所以:E{[Y-(a0+b0X)]2}=D(Y-(a0+b0X))+[E(Y-(a0+b0X))]2=0 两个非负数和为0,固有D(Y-(a0+b0X))=0,E(Y-(a0+b0X))=0 由方差性质4°知P{Y-(a0+b0X)=C}=1, 而E{Y-(a0+b0X)}=C=0 所以P{Y-(a0+b0X)=0}=1
]2}=D(Y-(a0+b0X))+[E(Y-(a0+b0X))]2=0. 两个非负数和为0,固有D(Y-(a0+b0X))=0,E(Y-(a0+b0X))=0. 由方差性质4°知P{Y-(a0+b0X)=C}=1, 而E{Y-(a0+b0X)}=C=0. 所以P{Y-(a0+b0X)=0}=1.")
70
§4.3 协方差及相关系数 必要性: 若存在常数a*,b*使得P{Y=(a*+b*X)}=1, 即P{Y-(a*+b*X)=0}=1
所以[Y-(a*+b*X)]2的期望E{[Y-(a*+b*X)]2}=0 固有0=E{[Y-(a*+b*X)]2} =(1- )D(Y) 即(1- )D(Y)=0,对任意Y都成立,所以1- =0 即|ρXY|=1
]2的期望E{[Y-(a*+b*X)]2}=0. 固有0=E{[Y-(a*+b*X)]2} =(1- )D(Y) 即(1- )D(Y)=0,对任意Y都成立,所以1- =0. 即|ρXY|=1.")
71
§4.3 协方差及相关系数 由前述推导表明: 1°单调递减性:给定随机变量Y及a+bX,均方误差e的最小值是|ρXY|的单调减函数
∴|ρXY|增大,误差越小,Y与a+bX的线性关系就越明显,近似程度就越好 |ρXY|=1时,P{Y=a+bX}=1 2°|ρXY|大小与线性关系 ρXY可以表征X和Y线性关系紧密程度的量 ρXY越大,线性相关程度越好

72
§4.3 协方差及相关系数 3°不相关与独立性: 定义:当ρXY=0时称X和Y不相关 =
如果X和Y相互独立,则有ρXY=0,于是X和Y不相关 反之,如果X和Y不相关,则ρXY=0,从而有E(XY)-E(X)E(Y)=0 但仅有这一结果,X和Y不一定独立。 ∴独立性是就一般关系而言,很广泛,而相关性仅指线性关系,独立性中还包括非线性的情况
-E(X)E(Y)=0. 但仅有这一结果,X和Y不一定独立。 ∴独立性是就一般关系而言,很广泛,而相关性仅指线性关系,独立性中还包括非线性的情况.")
73
注意 (1) 不相关与相互独立的关系 相互独立 不相关 (2) 不相关的充要条件
 不相关与相互独立的关系 相互独立 不相关 (2) 不相关的充要条件")
74
§4.3 协方差及相关系数 例 设(X,Y)的分布律为 Y X -2 -1 1 2 P{Y=j} 1 0 ¼ ¼ 0 ½
¼ ¼ ½ ¼ ¼ ½ P{X=i} ¼ ¼ ¼ ¼ 易知E(X)=0,E(Y)=2.5,E(XY)=0,于是X和Y的相关系数XY=0,X和Y不相关,即X和Y不存在线性关系。 但P{X=-2,Y=1} P{X=-2 }P{Y=1},知X和Y不相互独立.事实上X和Y具有关系Y=X2,是非线性的
=0,E(Y)=2.5,E(XY)=0,于是X和Y的相关系数XY=0,X和Y不相关,即X和Y不存在线性关系。 但P{X=-2,Y=1} P{X=-2 }P{Y=1},知X和Y不相互独立.事实上X和Y具有关系Y=X2,是非线性的.")
75
§4.3 协方差及相关系数 例1 解

76
§4.3 协方差及相关系数

77
§4.3 协方差及相关系数

78
§4.3 协方差及相关系数 结论

79
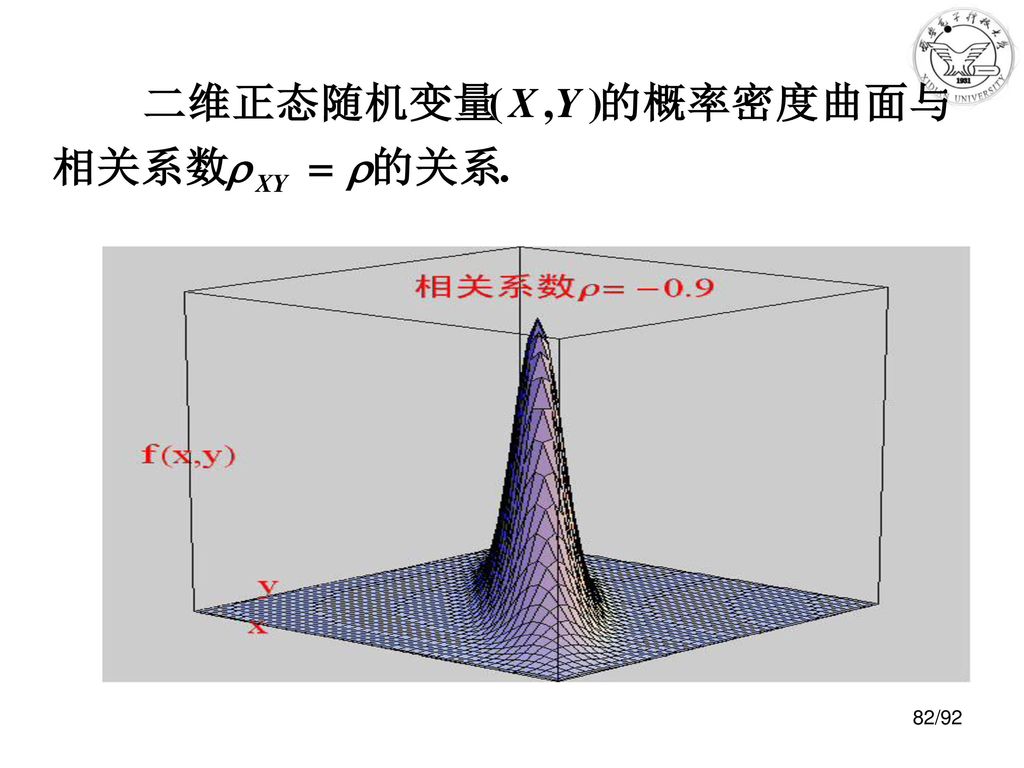
例2 解

83
§4.4 矩、协方差矩阵 本节引入随机变量的另外几个数字特征 定义:X和Y是随机变量
1°若E(Xk)存在,k=1,2,…,称它为X的k阶原点矩,简称k阶矩 当k=1时即为数学期望E(X),它是X的一阶原点矩 2°若E{[X-E(X)]k}存在,k=1,2,…,称它为X的k阶中心矩 当k=2时即为方差D(X),它是X的二阶中心矩 3°若E(XkYl)存在,k,l=1,2,…,称它为X和Y的k+l阶混合矩 4°若E{[X-E(X)]k[Y-E(Y)]l}存在,k,l=1,2,…,称它为X和Y的k+l阶混合中心矩 当k=l=1时即为协方差Cov(X,Y),它是X和Y二阶混合中心矩
存在,k=1,2,…,称它为X的k阶原点矩,简称k阶矩. 当k=1时即为数学期望E(X),它是X的一阶原点矩. 2°若E{[X-E(X)]k}存在,k=1,2,…,称它为X的k阶中心矩. 当k=2时即为方差D(X),它是X的二阶中心矩. 3°若E(XkYl)存在,k,l=1,2,…,称它为X和Y的k+l阶混合矩. 4°若E{[X-E(X)]k[Y-E(Y)]l}存在,k,l=1,2,…,称它为X和Y的k+l阶混合中心矩. 当k=l=1时即为协方差Cov(X,Y),它是X和Y二阶混合中心矩.")
84
§4.4 矩、协方差矩阵 n维随机变量的协方差矩阵 首先考虑二维随机变量的协方差矩阵
二维随机变量(X1,X2)有四个二阶中心矩,设它们都存在,分别记为 c11=E{[X1-E(X1)]2} D(X1) c12=E{[X1-E(X1)][X2-E(X2)]} Cov(X1,X2) c21=E{[X2-E(X2)][X1-E(X1)]} Cov(X2,X1) c22=E{[X2-E(X2)]2} D(X2) 将它们排成矩阵的形式, 这个矩阵称为随机变量(X1,X2)的协方差矩阵
有四个二阶中心矩,设它们都存在,分别记为. c11=E{[X1-E(X1)]2} D(X1) c12=E{[X1-E(X1)][X2-E(X2)]} Cov(X1,X2) c21=E{[X2-E(X2)][X1-E(X1)]} Cov(X2,X1) c22=E{[X2-E(X2)]2} D(X2) 将它们排成矩阵的形式, 这个矩阵称为随机变量(X1,X2)的协方差矩阵.")
85
§4.4 矩、协方差矩阵

86
§4.4 矩、协方差矩阵 对于n维随机变量(X1,X2,…,Xn)的协方差矩阵。由于cij=cji,(i≠j, i,j=1,2,…,n)因而是一个对称矩阵 在实际中,由于n维随机变量的分布是不知道的,或者太复杂,数学上不易处理,因此协方差矩阵尤为重要 n维正态随机变量的概率密度的协方差矩阵表示 首先将二维正态随机变量的概率密度改写成另一种形式 二维正态随机变量(X1,X2)的概率密度为 ,-∞<x1<∞,-∞<x2<∞。 现在将指数中括号内的部分写成矩阵的行列式形式
的概率密度为. ,-∞<x1<∞,-∞<x2<∞。 现在将指数中括号内的部分写成矩阵的行列式形式.")
87
§4.4 矩、协方差矩阵 令X= ,μ= ,记(X1,X2)的协方差矩阵为 C= = , 其中12=
=Cov(X1,X2)=Cov(X2,X1) C的行列式|C|=1222(1- 2) , 于是C的逆阵C-1= =
=Cov(X2,X1) C的行列式|C|=1222(1- 2) , 于是C的逆阵C-1= =")
88
§4.4 矩、协方差矩阵 做如下计算 (X-μ)C-1(X-μ) = (x1-μ1,x2-μ2) 展开 =
展开 = 于是(X1,X2)的概率密度可写为 f(x1,x2)= , -∞<x1<∞,-∞<x2<∞
的概率密度可写为. f(x1,x2)= , -∞<x1<∞,-∞<x2<∞")
89
§4.4 矩、协方差矩阵 推广到n维正态随机变量(X1,X2,…,Xn)的情况 引入矩阵 X= ,μ= = ,
f(x1,x2,…,xn)= , -∞<xi<∞,i=1,2,…,n C是(X1,X2,…,Xn)的协方差矩阵
= , -∞<xi<∞,i=1,2,…,n. C是(X1,X2,…,Xn)的协方差矩阵.")
90
§4.4 矩、协方差矩阵 n维正态随机变量的四条重要性质:
1°n维正态随机变量(X1,X2,…,Xn)的每一个分量Xi,i=1,2,…,n,都是正态变量;反之若X1,X2,…,Xn都是正态变量,且相互独立,则(X1,X2,…,Xn)是正态变量 证明:对于第一个问题,由归纳法,正态变量的边缘概率密度都是正态变量 反之,若相互独立,则协方差为0,协方差矩阵只有主对角线元素不为0且是各正态变量的方差。 2°n维正态随机变量(X1,X2,…,Xn)服从n维正态分布的充要条件是X1,X2,…,Xn的任意线性组合: l1X1+l2X2+…+lnXn 服从一维正态分布(其中l1,l2,…,ln不全为0)
的每一个分量Xi,i=1,2,…,n,都是正态变量;反之若X1,X2,…,Xn都是正态变量,且相互独立,则(X1,X2,…,Xn)是正态变量. 证明:对于第一个问题,由归纳法,正态变量的边缘概率密度都是正态变量. 反之,若相互独立,则协方差为0,协方差矩阵只有主对角线元素不为0且是各正态变量的方差。 2°n维正态随机变量(X1,X2,…,Xn)服从n维正态分布的充要条件是X1,X2,…,Xn的任意线性组合: l1X1+l2X2+…+lnXn. 服从一维正态分布(其中l1,l2,…,ln不全为0)")
91
§4.4 矩、协方差矩阵 3°正态变量的线性变换不变性:若(X1,X2,…,Xn)服从n维正态分布,设Y1,Y2,…,Yk是Xj,j=1,2,…,n的线性函数,则(Y1,Y2,…,Yk)也服从多维正态分布 4°设(X1,X2,…,Xn)服从n维正态分布,则“X1,X2,…,Xn相互独立”与“X1,X2,…,Xn两两不相关”是等价的。 这是因为,正态变量的性质由协方差矩阵完全确定,而矩阵中的元素为两两分量的协方差,反映了两两相关性
服从n维正态分布,则 X1,X2,…,Xn相互独立 与 X1,X2,…,Xn两两不相关 是等价的。 这是因为,正态变量的性质由协方差矩阵完全确定,而矩阵中的元素为两两分量的协方差,反映了两两相关性.")
92
本章小结

93
本章小结(2)
")
94
本章作业 第一次: 第二次: 第三次: P113:1(3),2,4,6,7 P115:9(2),10,14,15,18,22(2),25
,2,4,6,7 P115:9(2),10,14,15,18,22(2),25")
95
谢谢!

Similar presentations







2 +(y-b)2=r2 x2+y2+Dx+Ey+F=0 Ax2+Bxy+Cy2+Dx+Ey+ F=0.>")
和方差二种。>")



 常数项级数的概念 袁安锋 2016.7.>")








