Download presentation
1
第三章 多元正态分布 §3.1 多元正态分布的定义 §3.2 多元正态分布的性质 §3.3 极大似然估计及估计量的性质
第三章 多元正态分布 §3.1 多元正态分布的定义 §3.2 多元正态分布的性质 §3.3 极大似然估计及估计量的性质 §3.4 复相关系数和偏相关系数 § 和(n − 1) S的抽样分布 *§3.6 二次型分布
 S的抽样分布. *§3.6 二次型分布.")
2
§3.1 多元正态分布的定义 一元正态分布N(μ,σ2)的概率密度函数为 若随机向量 的概率密度函数为
§3.1 多元正态分布的定义 一元正态分布N(μ,σ2)的概率密度函数为 若随机向量 的概率密度函数为 则称x服从p元正态分布,记作x~Np(μ, Σ),其中,参数μ和Σ分别为x的均值和协差阵。
的概率密度函数为. 若随机向量 的概率密度函数为. 则称x服从p元正态分布,记作x~Np(μ, Σ),其中,参数μ和Σ分别为x的均值和协差阵。")
3
例3.1.1(二元正态分布 ) 设x~N2(μ, Σ),这里 易见,ρ是x1和 x2的相关系数。当|ρ|<1时,可得x的概率密度函数为
 设x~N2(μ, Σ),这里 易见,ρ是x1和 x2的相关系数。当|ρ|<1时,可得x的概率密度函数为")
4
二元正态分布的密度曲面图 下图是当 时二元正态分布的钟形密度曲面图。

5
二元正态分布等高线 等高(椭圆)线: 上述等高线上的密度值
线: 上述等高线上的密度值")
6
二元正态分布的密度等高线族 (使用SAS/INSIGHT,由10000个二维随机数生成)
")
7
{x:(x−μ)′Σ−1(x−μ)=c2} 这是一个(超)椭球曲面,中心在μ,而Σ决定了其形状和方向。
概率密度等高面 {x:(x−μ)′Σ−1(x−μ)=c2} 这是一个(超)椭球曲面,中心在μ,而Σ决定了其形状和方向。
′Σ−1(x−μ)=c2} 这是一个(超)椭球曲面,中心在μ,而Σ决定了其形状和方向。")
8
§3.2 多元正态分布的性质 *(1)略。 (2) 。 性质(2)常可用来证明随机向量服从多元正态分布。
§3.2 多元正态分布的性质 *(1)略。 (2) 。 性质(2)常可用来证明随机向量服从多元正态分布。 (3)设x~Np (μ, Σ),y=Cx+b,其中C为r×p 常数矩阵,则 该性质表明,(多元)正态变量的任何线性变换仍为(多元)正态变量。
略。 (2) 。 性质(2)常可用来证明随机向量服从多元正态分布。 (3)设x~Np (μ, Σ),y=Cx+b,其中C为r×p 常数矩阵,则. 该性质表明,(多元)正态变量的任何线性变换仍为(多元)正态变量。")
9
例3.2.2 设x~Np(μ, Σ),a为p维常数向量,则由上述性质(2)或(3)知,
(4)设x~Np(μ, Σ),则x的任何子向量也服从(多元)正态分布,其均值为μ的相应子向量,协方差矩阵为Σ的相应子矩阵。 该性质说明了多元正态分布的任何边缘分布仍为(多元)正态分布。 需注意,随机向量的任何边缘分布皆为(多元)正态分布⇏该随机向量服从多元正态分布。 反例:习题2.3。
设x~Np(μ, Σ),则x的任何子向量也服从(多元)正态分布,其均值为μ的相应子向量,协方差矩阵为Σ的相应子矩阵。 该性质说明了多元正态分布的任何边缘分布仍为(多元)正态分布。 需注意,随机向量的任何边缘分布皆为(多元)正态分布⇏该随机向量服从多元正态分布。 反例:习题2.3。")
10
还需注意,正态变量的线性组合未必就是正态变量。
这是因为: x1,x2,⋯,xn均为一元正态变量 ⟸(⇏)x1,x2,⋯,xn的联合分布为多元正态分布 ⟺x1,x2,⋯,xn的一切线性组合是一元正态变量 例 设x~N4(μ, Σ),这里
x1,x2,⋯,xn的联合分布为多元正态分布. ⟺x1,x2,⋯,xn的一切线性组合是一元正态变量. 例3.2.4 设x~N4(μ, Σ),这里.")
11
则 (i) ; (ii) ; (iii) 。
 。")
12
(5)设x1,x2,⋯,xn相互独立,且xi~Np(μi, Σi) ,i=1,2,⋯,n,则对任意n个常数k1,k2,⋯,kn,有
此性质表明,独立的多元正态变量(维数相同)的任意线性组合仍为多元正态变量。 (6)设x~Np(μ, Σ),对x, μ, Σ(>0)作如下的剖分:
的任意线性组合仍为多元正态变量。 (6)设x~Np(μ, Σ),对x, μ, Σ(>0)作如下的剖分:")
13
则子向量x1和x2相互独立,当且仅当Σ12=0。 可作一般化推广,并对于多元正态变量而言,其子向量之间互不相关和相互独立是等价的。 例 设x~N3(μ,Σ),其中 则x2和x3不独立,x1和(x2,x3)独立。 (7)设x~Np(μ, Σ), Σ>0,则 *(8)略
设x~Np(μ, Σ), Σ>0,则. *(8)略.")
14
*(9)略 *(10)略 (11)设x~Np(μ, Σ), Σ>0,作如下剖分 则给定x2时x1的条件分布为 ,其中 μ1·2和Σ11·2分别是条件数学期望和条件协方差矩阵,Σ11·2通常称为偏协方差矩阵。

15
这一性质可作一般化推广,并对于多元正态变量,其子向量的条件分布仍是(多元)正态的。
例 设x~N3(μ, Σ),其中 试求给定x1+2x3时 的条件分布。
,其中. 试求给定x1+2x3时 的条件分布。")
16
解 令 ,于是

17
给定y2时y1的条件均值和条件协差阵分别为 所以

18
§3.3 极大似然估计及估计量的性质 简单随机样本(简称样本): 满足:x1,x2,⋯,xn独立,且与总体分布相同。
§3.3 极大似然估计及估计量的性质 简单随机样本(简称样本): 满足:x1,x2,⋯,xn独立,且与总体分布相同。 设x~Np(μ, Σ) , Σ>0,x1,x2,⋯,xn是从中抽取的一个样本。 数据矩阵或观测值矩阵: 一、极大似然估计 二、估计量的性质
: 满足:x1,x2,⋯,xn独立,且与总体分布相同。 设x~Np(μ, Σ) , Σ>0,x1,x2,⋯,xn是从中抽取的一个样本。 数据矩阵或观测值矩阵: 一、极大似然估计. 二、估计量的性质.")
19
一、极大似然估计 1. μ和Σ的极大似然估计 2.相关系数的极大似然估计

20
1.μ和Σ的极大似然估计 似然函数:是样本联合概率密度 f (x1,x2,⋯,xn)的任意正常数倍,记为L(μ, Σ)。不妨取
的任意正常数倍,记为L(μ, Σ)。不妨取")
21
极大似然估计 一元正态情形: 多元正态情形: 其中 称为样本均值向量(简称为样本均值), 称为样本离差矩阵, 称为样本协方差矩阵。
, 称为样本离差矩阵, 称为样本协方差矩阵。")
22
2.相关系数的极大似然估计 相关系数ρij的极大似然估计为 其中 。称rij为样本相关系数、 为样本相关矩阵。

23
二、估计量的性质 1.无偏性 2.有效性 3.一致性 4.充分性

24
1.无偏性 如果 ,则称估计量 是被估参数θ的一个无偏估计,否则就称为有偏的。 。 , 是Σ的有偏估计。 E(S)=Σ。
=Σ。")
25
证明

26
2.有效性 设 是θ的一个无偏估计,若对θ的任一无偏估计 有 即 为非负定矩阵,则称 为θ的一致最优无偏估计。
设 是θ的一个无偏估计,若对θ的任一无偏估计 有 即 为非负定矩阵,则称 为θ的一致最优无偏估计。 可以证明,对于多元正态总体, 和S分别是μ和Σ的一致最优无偏估计。

27
3.一致性 如果未知参数θ(可以是一个向量或矩阵)的估计量 随着样本容量n的不断增大,而无限地逼近于真值θ,则称 为θ的一致估计,或称相合估计。 估计量的一致性是在大样本情形下提出的一种要求,而对于小样本,它不能作为评价估计量好坏的准则。 可以证明, 和 (或S)分别是μ和Σ的一致估计 (无需总体正态性的假定)。
分别是μ和Σ的一致估计 (无需总体正态性的假定)。")
28
4.充分性 如果一个统计量能把含在样本中的有关总体(或有关未知参数)的信息一点都不损失地充分提取出来,则这种统计量就称为充分统计量。
可以证明,对于总体Np(μ,Σ),当Σ已知时, 是μ的充分统计量;当μ已知时, 是Σ的充分统计量;当μ和Σ均未知时,( ,A)是(μ,Σ)的充分统计量。 用来作为估计量的充分统计量称为充分估计量。A, ,S这三者之间只相差一个常数倍,所含的信息完全相同,故当μ和Σ均未知时, 也都是(μ, Σ)的充分统计量。 若按无偏性的准则,则可采用( ,S)作为未知参数(μ,Σ)的充分估计量。
,当Σ已知时, 是μ的充分统计量;当μ已知时, 是Σ的充分统计量;当μ和Σ均未知时,( ,A)是(μ,Σ)的充分统计量。 用来作为估计量的充分统计量称为充分估计量。A, ,S这三者之间只相差一个常数倍,所含的信息完全相同,故当μ和Σ均未知时, 也都是(μ, Σ)的充分统计量。 若按无偏性的准则,则可采用( ,S)作为未知参数(μ,Σ)的充分估计量。")
29
§3.4 复相关系数和偏相关系数 一、复相关系数 *二、最优线性预测 三、偏相关系数

30
一、复相关系数 (简单)相关系数度量了一个随机变量x与另一个随机变量y之间线性关系的强弱。
复相关系数度量了一个随机变量y与一组随机变量x1,x2,…,xp之间线性关系的强弱。 设

31
则y和x的线性函数l′x(l ≠0)间的最大相关系数称为y和x间的复(或多重)相关系数(multiple correlation coefficient),记作ρy·x或ρy·1,2,…,p,它度量了一个变量y和一组变量x1,x2,…,xp间的相关程度。 若x1,x2,⋯,xp互不相关,则有

32
例3.4.1 试证随机变量x1, x2,⋯, xp的任一线性函数F=a1x1+a2x2+⋯+apxp与x1, x2,⋯, xp的复相关系数为1。
证明

33
ρy∙x的极大似然估计 设 这里n>p,则在多元正态的假定下,复相关系数ρy·x的极大似然估计为 称为样本复相关系数。

34
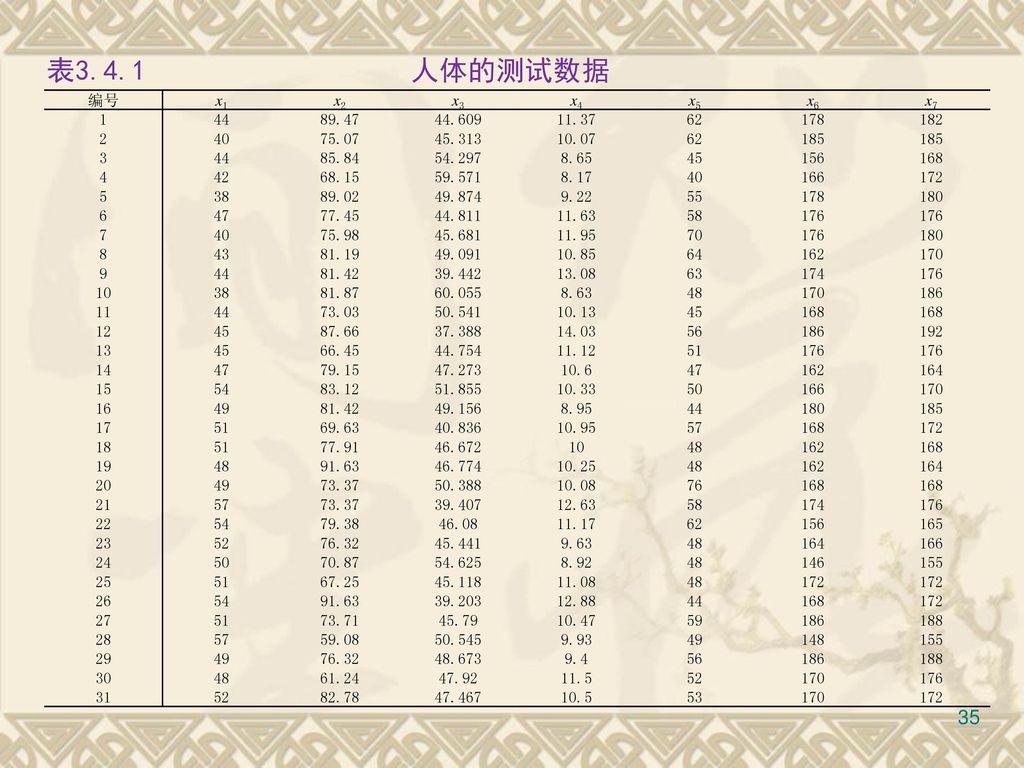
例3. 4. 2 今对31个人进行人体测试,考察或测试的七个指标是: 年龄(x1)、体重(x2)、肺活量(x3)、1
例 今对31个人进行人体测试,考察或测试的七个指标是: 年龄(x1)、体重(x2)、肺活量(x3)、1.5英里跑的时间(x4)、休息时的脉搏(x5)、跑步时的脉搏(x6)和跑步时记录的最大脉搏(x7)。数据列于表3.4.1。 可算得x3与x1,x2,x4,x5,x6,x7的样本复相关系数
、体重(x2)、肺活量(x3)、1.5英里跑的时间(x4)、休息时的脉搏(x5)、跑步时的脉搏(x6)和跑步时记录的最大脉搏(x7)。数据列于表3.4.1。 可算得x3与x1,x2,x4,x5,x6,x7的样本复相关系数.")
35
表 人体的测试数据 编号 x1 x2 x3 x4 x5 x6 x7 1 44 89.47 44.609 11.37 62 178 182 2 40 75.07 45.313 10.07 185 3 85.84 54.297 8.65 45 156 168 4 42 68.15 59.571 8.17 166 172 5 38 89.02 49.874 9.22 55 180 6 47 77.45 44.811 11.63 58 176 7 75.98 45.681 11.95 70 8 43 81.19 49.091 10.85 64 162 170 9 81.42 39.442 13.08 63 174 10 81.87 60.055 8.63 48 186 11 73.03 50.541 10.13 12 87.66 37.388 14.03 56 192 13 66.45 44.754 11.12 51 14 79.15 47.273 10.6 164 15 54 83.12 51.855 10.33 50 16 49 49.156 8.95 17 69.63 40.836 10.95 57 18 77.91 46.672 19 91.63 46.774 10.25 20 73.37 50.388 10.08 76 21 39.407 12.63 22 79.38 46.08 11.17 165 23 52 76.32 45.441 9.63 24 70.87 54.625 8.92 146 155 25 67.25 45.118 11.08 26 39.203 12.88 27 73.71 45.79 10.47 59 188 28 59.08 50.545 9.93 148 29 48.673 9.4 30 61.24 47.92 11.5 31 82.78 47.467 10.5 53
36
*二、最优线性预测 当我们用x的函数g(x)来预测y时,可用均方误差E[y− g(x)]2作为预测精度的度量。如果限制g(x)为线性函数,则使 E[y− g(x)]2达到最小的线性预测函数是 即有 称 为用x对y的最优线性预测。
![*二、最优线性预测 当我们用x的函数g(x)来预测y时,可用均方误差E[y− g(x)]2作为预测精度的度量。如果限制g(x)为线性函数,则使 E[y− g(x)]2达到最小的线性预测函数是.](http://slidesplayer.com/slide/11358397/61/images/36/%2A%E4%BA%8C%E3%80%81%E6%9C%80%E4%BC%98%E7%BA%BF%E6%80%A7%E9%A2%84%E6%B5%8B+%E5%BD%93%E6%88%91%E4%BB%AC%E7%94%A8x%E7%9A%84%E5%87%BD%E6%95%B0g%28x%29%E6%9D%A5%E9%A2%84%E6%B5%8By%E6%97%B6%EF%BC%8C%E5%8F%AF%E7%94%A8%E5%9D%87%E6%96%B9%E8%AF%AF%E5%B7%AEE%5By%E2%88%92+g%28x%29%5D2%E4%BD%9C%E4%B8%BA%E9%A2%84%E6%B5%8B%E7%B2%BE%E5%BA%A6%E7%9A%84%E5%BA%A6%E9%87%8F%E3%80%82%E5%A6%82%E6%9E%9C%E9%99%90%E5%88%B6g%28x%29%E4%B8%BA%E7%BA%BF%E6%80%A7%E5%87%BD%E6%95%B0%EF%BC%8C%E5%88%99%E4%BD%BF+E%5By%E2%88%92+g%28x%29%5D2%E8%BE%BE%E5%88%B0%E6%9C%80%E5%B0%8F%E7%9A%84%E7%BA%BF%E6%80%A7%E9%A2%84%E6%B5%8B%E5%87%BD%E6%95%B0%E6%98%AF..jpg "即有. 称 为用x对y的最优线性预测。")
37
最优线性预测 的均方误差 的精度与σyy和ρy·x有关。 被预测变量y可作如下分解: =最优线性预测 + 预测误差 (受x线性影响部分) (不受x线性影响部分)
 (不受x线性影响部分)")
38
预测误差部分可看作是从y中扣除x的线性影响后剩余的部分,它不受x的线性影响,因为
称之为总体复判定系数,它表示y的方差可由x1,x2,…,xp联合解释的比例,该值越大,表明预测效果越好。

39
在y对x1,x2,…,xp的多元线性回归模型中,可以证明:
(1)y与预测值 的样本相关系数等于y与x1,x2,…,xp的样本复相关系数,即 (2)(样本)复判定系数为 例 在例3.4.2中,建立x3对x1,x2,x4,x5,x6,x7的六元线性回归模型,拟合函数为 可用来对x3进行预测,复判定系数R2=0.8480,(样本)复相关系数 , 也是x3与预测值 的样本相关系数。
y与预测值 的样本相关系数等于y与x1,x2,…,xp的样本复相关系数,即. (2)(样本)复判定系数为. 例3.4.3 在例3.4.2中,建立x3对x1,x2,x4,x5,x6,x7的六元线性回归模型,拟合函数为. 可用来对x3进行预测,复判定系数R2=0.8480,(样本)复相关系数 , 也是x3与预测值 的样本相关系数。")
40
三、偏相关系数 两个变量之间的相关性,除了受这两个变量彼此间的影响外,常常还受其他一系列变量的影响。由于这个原因,相关系数有时也称为总(或毛,gross)相关系数,其意思是包含了由一切影响带来的相关性。 顺便指出,相关系数有时亦称为简单相关系数或皮尔逊(Pearson)相关系数或零阶偏相关系数。
相关系数或零阶偏相关系数。")
41
例3.4.4 x1——家庭的饮食支出 x2——家庭的衣着支出 x3——家庭的收入 x1和x2之间存在着较强的正相关性。 x3分别与x1和x2的强正相关性导致了x1和x2的较强正相关性。 如果我们能用某种方式把x3的影响消除掉,或者说控制了x3(即x3保持不变),则x1和x2之间(反映净关系)的相关性可能就很不一样了,很有可能会显示负相关性。
,则x1和x2之间(反映净关系)的相关性可能就很不一样了,很有可能会显示负相关性。")
42
将x, Σ(>0),S剖分如下: 称 为给定x2时x1的偏协方差矩阵。记 ,称 为偏协方差,它是剔除了 的(线性)影响之后,xi和xj之间的协方差。
影响之后,xi和xj之间的协方差。")
43
给定x2时xi 和xj的偏相关系数(partial correlation coefficient)定义为
其中 。 ρij∙k+1,⋯,p度量了剔除xk+1,⋯,xp的(线性)影响之后,xi和xj间相关关系的强弱。 对于多元正态变量x,由于Σ11∙2也是条件协方差矩阵,故此时偏相关系数与条件相关系数是同一个值,从而ρij∙k+1,⋯,p同时也度量了在xk+1,⋯,xp值给定的条件下xi和xj间相关关系的强弱。
影响之后,xi和xj间相关关系的强弱。 对于多元正态变量x,由于Σ11∙2也是条件协方差矩阵,故此时偏相关系数与条件相关系数是同一个值,从而ρij∙k+1,⋯,p同时也度量了在xk+1,⋯,xp值给定的条件下xi和xj间相关关系的强弱。")
44
一阶偏相关系数可直接由相关系数算得。设x1,x2,x3是三个随机变量,则有
(1)ρ12=0并不意味着ρ12•3=0,反之亦然。 (2) ρ12与ρ12•3未必同号。 此外,ρ12与ρ12•3之间孰大孰小也没有必然的结论。
ρ12=0并不意味着ρ12•3=0,反之亦然。 (2) ρ12与ρ12•3未必同号。 此外,ρ12与ρ12•3之间孰大孰小也没有必然的结论。")
45
偏相关系数的一般递推公式: 在多元正态性的假定下,ρij∙k+1,⋯,p的极大似然估计为 其中 。称rij∙k+1,⋯,p为样本偏相关系数。

46
例3.4.5 假设对16个婴儿测量了出生体重(盎司)、出生天数(日)及舒张压(mmHg),数据见表3.4.2。
表 个婴儿的出生体重、年龄及血压的数据 编号 出生体重(x1) 出生天数(x2) 舒张压(x3) 1 135 3 89 2 120 4 90 100 83 105 77 5 130 92 6 125 98 7 82 8 85 9 96 10 95 11 80 12 79 13 86 14 150 97 15 160 16 88
 出生天数(x2) 舒张压(x3)")
47
在控制出生天数后,舒张压与出生体重的样本偏相关系数为
在控制出生体重后,舒张压与出生天数的样本偏相关系数为

48
§ 和(n − 1)S的抽样分布 一、 的抽样分布 *二、(n − 1)S的抽样分布
S的抽样分布 一、 的抽样分布 *二、(n − 1)S的抽样分布")
49
一、 的抽样分布 1.正态总体 设x~Np(μ, Σ), Σ>0 ,x1,x2,⋯,xn是从总体x中抽取的一个样本,则
一、 的抽样分布 1.正态总体 设x~Np(μ, Σ), Σ>0 ,x1,x2,⋯,xn是从总体x中抽取的一个样本,则 2.非正态总体(多元中心极限定理) 设x1,x2,⋯,xn是来自总体x的一个样本,μ和Σ存在,则当n很大且n相对于p也很大时,
, Σ>0 ,x1,x2,⋯,xn是从总体x中抽取的一个样本,则. 2.非正态总体(多元中心极限定理) 设x1,x2,⋯,xn是来自总体x的一个样本,μ和Σ存在,则当n很大且n相对于p也很大时,")
50
vech(X)= (x11,…,xp1,x22,…,xp2,…, xp−1,p−1,xp,p−1,xpp)′
*二、(n−1)S的抽样分布 设随机矩阵X=(x1,x2,⋯,xq)=(xij):p×q, 称“vec”为拉直运算。当X′=X时,因xij=xji,故只需取其下三角部分组成一个缩减了的长向量,记作vech(X),即 vech(X)= (x11,…,xp1,x22,…,xp2,…, xp−1,p−1,xp,p−1,xpp)′ X的分布是指vec(X)或(当X′=X时)vech(X)的分布。 拉直运算将矩阵分布问题转化为了向量分布的问题。
S的抽样分布. 设随机矩阵X=(x1,x2,⋯,xq)=(xij):p×q, 称 vec 为拉直运算。当X′=X时,因xij=xji,故只需取其下三角部分组成一个缩减了的长向量,记作vech(X),即. vech(X)= (x11,…,xp1,x22,…,xp2,…, xp−1,p−1,xp,p−1,xpp)′ X的分布是指vec(X)或(当X′=X时)vech(X)的分布。 拉直运算将矩阵分布问题转化为了向量分布的问题。")
51
设随机向量x1,x2,⋯,xn独立同分布于Np(0, Σ),Σ>0,n≥p,则p阶矩阵
设随机向量x1,x2,⋯,xn独立同分布于Np(0, Σ),Σ>0,n≥p,则p阶矩阵 的分布称为自由度为n的(p阶)威沙特(Wishart)分布,记作Wp(n, Σ)。当p=1,Σ=σ2=1时,显然有 ,即有 W1(n,1)=χ2(n) 因此,威沙特分布是卡方分布在多元场合下的一种推广。
,Σ>0,n≥p,则p阶矩阵 的分布称为自由度为n的(p阶)威沙特(Wishart)分布,记作Wp(n, Σ)。当p=1,Σ=σ2=1时,显然有. ,即有. W1(n,1)=χ2(n) 因此,威沙特分布是卡方分布在多元场合下的一种推广。")
52
W1+W2+⋯+Wk~Wp(n1+n2+⋯+nk, Σ)
威沙特分布的性质 (1)设Wi~Wp(ni, Σ),i=1,2,⋯,k,且相互独立,则 W1+W2+⋯+Wk~Wp(n1+n2+⋯+nk, Σ) (2)设W~Wp(n, Σ),C为q×p常数矩阵,则 CWC′~Wq(n, CΣC′) 设x1,x2,⋯,xn是取自Np(μ, Σ),Σ>0的一个样本,n>p,则可以证明, 和S相互独立,且有 (n−1)S~Wp(n−1, Σ)
设Wi~Wp(ni, Σ),i=1,2,⋯,k,且相互独立,则. W1+W2+⋯+Wk~Wp(n1+n2+⋯+nk, Σ) (2)设W~Wp(n, Σ),C为q×p常数矩阵,则. CWC′~Wq(n, CΣC′) 设x1,x2,⋯,xn是取自Np(μ, Σ),Σ>0的一个样本,n>p,则可以证明, 和S相互独立,且有. (n−1)S~Wp(n−1, Σ)")









>")


 常数项级数的概念 袁安锋 2016.7.>")







