Download presentation
Presentation is loading. Please wait.

1
第六章 定性研究方法 第一节 定性研究方法概述 第二节 实地研究方法 第三节 访谈方法 第四节 文献研究方法 第五节 扎根理论的研究方法

2
第一节 定性研究概述 一、定性研究的方法论基础 1、人文主义方法论 社会文化领域不同于自然世界,人有自由意志;
第一节 定性研究概述 一、定性研究的方法论基础 1、人文主义方法论 社会文化领域不同于自然世界,人有自由意志; 自然科学研究方法不适合社会文化领域,应该采取理解、阐释的方法,深入了解人的行为动机、意义,全面理解各种具体、独特的社会历史现象;

3
2、韦伯的阐释社会学 社会现象不是完全外在于人类的客观事物,而是由人及有意义的社会性的构成; 对人们行动的理解是社会研究的基本方法;

4
二、定性研究方法与定量研究方法比较 详见498页的表格。

5
第二节 实地研究方法 一、参与观察法 参与观察法:研究者长期深入到所研究的群体或社区之中,直接参与研究对象的日常生活,对置身其中的社会现象进行深入观察。 严景耀 罪犯研究; 神秘顾客 马林诺夫斯基的原始部落研究‘ 怀特的街角社会研究

6
非参与观察:研究者在被观察现象或群体之外,它是对现象发生、发展和变化的过程进行远距离观察。
涂鸦研究;

7
二、参与观察法的优点 1、获得丰富的一手资料; 2、能从研究对象的真实生活中掌握和记录资料;
3、采用无结构式观察,根据资料提炼理论,而不把自己的观点强加给研究对象。

8
三、参与观察法的局限性 1、研究结论的推论范围受限制。 2、代表性较低。 3、容易价值介入,丧失客观立场。

9
四、参与观察法的技巧 1、如何进入田野:如何让被研究者接纳? 2、掌握好观察进度。 3、不但要进得去,还要出得来。

10
五、实地观察的过程 准备 实施 资料处理

11
六、实地观察的信度和效度 1、效度 在观察阶段选择适当的观察方法和界定观察对象;
在实施阶段影响效度的因素:被观察者的反应、观察者的主观因素、观察者本人的感官和记忆影响。 2、信度 不同观察者的相关度; 同一观察者在不同时间观察的符合度; 不同观察者在不同时间观察的符合度。

12
第三节 访谈法 一、访谈法的类型 (一)、根据访谈对象 个别访谈 群组访谈(座谈会):将若干访谈对象集中起来同时进行访谈。
、根据访谈对象 个别访谈 群组访谈(座谈会):将若干访谈对象集中起来同时进行访谈。")
13
(二)、根据访谈内容和访谈方式 结构式访谈: 无结构式访谈:不是根据一定的程序和事先设计好的问卷进行,而是围绕访谈主题或访谈范围,由访问员与被访者进行比较自由、深入和细致的交谈。
、根据访谈内容和访谈方式 结构式访谈: 无结构式访谈:不是根据一定的程序和事先设计好的问卷进行,而是围绕访谈主题或访谈范围,由访问员与被访者进行比较自由、深入和细致的交谈。")
14
无结构式访谈的类型: 焦点访问:主要搜集经过某一特殊经验之后的态度变迁资料。 深度访谈 客观陈述法:访问者鼓励被访者把自己的意见、观点、行为以及他所了解的社会事实客观地加以陈述,主要用于全面地了解客观事实及各种被访者的意见、态度。

15
二、深度访谈法 深度访谈法是指研究者与受访者之间反复交谈,其目的是为了受访者用自己的语言表述的其生活、经历或状态的观点。

16
(一)、深度访谈法的特点 1、访谈是平等的相互交谈; 2、问题是无结构化或半结构化; 3、面对面听取被访者的理解; 4、要反复访谈,也可以群体访谈。
、深度访谈法的特点 1、访谈是平等的相互交谈; 2、问题是无结构化或半结构化; 3、面对面听取被访者的理解; 4、要反复访谈,也可以群体访谈。")
17
(二)、深度访谈的类型 非正式的、聊天式的访谈; 半标准化的访谈 标准化的开放式访谈
、深度访谈的类型 非正式的、聊天式的访谈; 半标准化的访谈 标准化的开放式访谈")
18
(三)、深度访谈的技术 1.提问的技术 提问题要清楚; 每次只问一个问题; 提出真正的开放式问题; 先问经验和行为的问题; 从一般到特殊; 深入挖掘问题和廓清回答; 应当避免敏感性的问题。
、深度访谈的技术 1.提问的技术 提问题要清楚; 每次只问一个问题; 提出真正的开放式问题; 先问经验和行为的问题; 从一般到特殊; 深入挖掘问题和廓清回答; 应当避免敏感性的问题。")
19
2、记录手段 3、访谈过程注意事项 一开始介绍访谈的意义和内容,价值中立; 不要使自己影响被访者; 放和收的把握; 建立和谐的气氛。 4、访谈资料的分析

20
三、焦点群体访谈法 焦点群体访谈法:围绕一个“焦点”内容,在小型群体内进行集中讨论和访谈的方法。通常在一段时间内的多种场合进行。

21
焦点群体访谈法的特点(优点和缺点) 优点: 1、能获得其他方法不易获得的访谈对象的态度、情感、信仰和反应。
2、该方法可以应用到研究的各个阶段。 3、该方法有助于形成研究假设,有助于设计问卷和访谈提纲,还有助于定性研究和定量研究的结合。 4、互动性强。

22
缺点: 代表性差 被访者相互影响

23
四、个案研究方法 个案研究的目的是为了深刻揭示蕴涵在研究对象中丰富的个体特性和详细的事件发展过程,通过深入的观察或访谈详细、具体和生动的研究资料,并对个体行为或现状进行具体的个性解释。 比如:《金翼》《江村经济》

24
个案研究的局限: 代表性问题; 忽视宏观社会因素;

25
扩展个案研究法: 扩充个案的类型和数量; 将宏观研究和微观研究的视角结合起来。 如:《我们台湾这些年》

26
第四节 文献研究方法 一、文献法的类型和特点 定性方法 文 献 法 二次数据分析 定量方法 现存统计文献分析 历史文本分析 话语分析
个人文献分析 文 献 法 历史比较分析 二次数据分析 定量方法 现存统计文献分析

27
文献法的优点: 1、可研究那些不可能接近的研究对象; 2、具有非介入性和无干扰性的优点; 3、适于做纵贯研究和趋势研究; 4、费用较低。

28
文献法的缺点: 1、文献质量无法控制; 2、重要文献不易获得; 3、编码困难,难以数量化; 4、缺乏统一格式,资料间难以对比;

29
二、口述史方法 1、定义 口述史方法主要依赖对于老年人进行访谈的方法,这些老年人提供各个人生阶段的事件、态度和活动的回顾性资料。

30
2、口述史的优点 可以填补文字历史的遗漏或纠正文字历史上的非真实记载,更完整地展历史全貌; 可以获得边缘群体的资料。

31
3、口述史方法的缺点 回忆不确切,信息不可靠; 故意隐瞒 受限于一定时期、场域和场合。

32
4、口述史方法的操作

33
三、内容分析方法 内容分析方法是对各种文献资料的内容进行客观、系统的和定量的描述和分析,它是将定量方法和定性方法相结合的文献法。
案例:美国通过分析德国报纸,获取法西斯的重要情报; 日本通过分析三年的人民日报( ),准确判断大庆油田的位置、产量,设计所需设备,击败竞争对手。
,准确判断大庆油田的位置、产量,设计所需设备,击败竞争对手。")
34
第五节 扎根理论的研究方法 一、扎根理论的概念 扎根理论是使用一整套系统的程序,建立或发展出归纳性理论的定性研究方法。

35
二、扎根理论研究过程 1、研究者根据理论洞察力不断归纳和比较所收集到的调查资料,把握其中相同的主要特质。
2、研究者将这些主要特质与其他有关现象进行比较,建立起变量间的假设关系。 3、进一步调查,验证研究假设。

36
三、扎根理论研究的方法和技术 1、开行性编码 将资料分解、检视、比较和概念化的过程。 2、轴向编码
研究者根据所分析现象的条件、背景、行动或互动的策略和结构,将各个概念联系起来。 3、选择性编码 选择核心概念,将它系统地与其他范畴联系起来,验证它们之间的关系,并将概念化为完备的范畴补充完成的过程。

37
4、过程分析 5、撰写备忘录

38
第七章 资料的处理 第一节 原始资料的审核 第二节 定性资料的整理 第三节定量资料的整理

39
第一节 原始资料的审核 一、定性资料的审核 1、实地观察记录的审核 重点对观察者与被观察者之间的“观察距离”进行审核。具体来说:
(1)随时检查观察结果是否在研究项目所设定的范围内; (2)对比检查其他参与研究人员的观察结果; (3)利用其他相关研究获得相关资料,对观察结果进行对比检验; (4)对观察时间长短进行检验。
随时检查观察结果是否在研究项目所设定的范围内; (2)对比检查其他参与研究人员的观察结果; (3)利用其他相关研究获得相关资料,对观察结果进行对比检验; (4)对观察时间长短进行检验。")
40
2、无结构式访谈记录的审核 重点是要对访谈双方在互动交流过程中的相互影响进行审核。 (1)要对被访问者对访问者的态度进行审核; (2)要对被访问者对访问的内容和意义的理解进行审核; (3)要对访问者的提问方式进行审核; (4)侧面审核。
侧面审核。")
41
3、文字形式资料的审核 主要包括对资料的外在形式和内在内容两方面的审核。 (1)作者的背景; (2)形成时间; (3)注重事实与推断、价值判断的区分 (4)真伪性
作者的背景; (2)形成时间; (3)注重事实与推断、价值判断的区分 (4)真伪性")
42
二、定量资料的审核 1、问卷资料审核 完整性:样本容量、回收率、有效回收率等。 真实性:回答的真实性和调查过程的真实性。 准确性
2、二次数据资料的审核

43
第二节 定性资料的整理 一、资料的分类 二、资料的汇编

44
第三节 定量资料的整理 一、问卷编码 问卷编码就是将问卷中以文字形式表述的问题和答案转换成计算机能够识别的数字或其他符号的过程。 预编码
后编码

45
二、数据录入 Spss(社会科学软件统计包) 三、数据清理 人为误差的清理; 对统计分析结果影响较大的特殊数值;
 三、数据清理 人为误差的清理; 对统计分析结果影响较大的特殊数值;")
46
人为误差清理: 有效范围清理; 逻辑一致性清理; 数据质量抽查;

47
第八章 单变量的统计描述 第一节 描述频数分布 第二节 分布趋势测量 第三节 正态分布与标准值

48
第一节 描述频数分布 一、指标描述 频数(f):变量具有共同性质的取值出现的次数。 比例(P):f/N 比率(R) 对比值 累计频数(cf)
:变量具有共同性质的取值出现的次数。 比例(P):f/N 比率(R) 对比值 累计频数(cf)")
49
累计频数(F) 向上累计——以变量数 列首组的频数为始点,逐 个累计各组的频数,展示 小于该组上限的频数和。 向下累计——以变量数
列末组的频数为始点,逐 个累计各组的频数,展示 大于该组下限的频数和。

50
二、图形描述 1、圆形比例图:用一个圆代表现象总体,然后按某一类现象所占比例对圆进行分割,以表示其在总体中所占的百分比。 定类

51
2、条形图:以长方形的长度表示变量不同取值的频数或百分比分布,其长方形的宽度没有实际意义。
定序

52
直方图:由紧挨着的长方形构成,其长度和宽度都有意义,宽度表示组据,长度表示频数或百分比。
定距

53
折线图:用直线连接直方图中长方形顶端的中点面而成的。
定距

54
第二节 分布趋势测量 一、集中趋势测量 集中趋势是从一组数据中计算出的一个典型数值,以反映数据的集中程度。 算术平均数 中位数 众数

55
一个人到某公司求职,经过调查,得出关于该公司工资的一些数据,如果是你,应该如何选择?
下面是一个小故事: 一个人到某公司求职,经过调查,得出关于该公司工资的一些数据,如果是你,应该如何选择? 第四章 集中趋势的应用 55

56
挠头的数值 公司员工的月薪如下: 员工 经理 副经理 职员A 职员B 职员C 职员D 职员E 职员F 职员G 6000 4000 1700
月薪(元) 6000 4000 1700 1300 1200 1100 500
")
57
1、算术平均数 适用于定距及定比层次变量。

58
2、中位数 把总体单位某一数量标志的各个数值按大小顺序排列,位于正中处的变量值,即为中位数,可用于定序、定距、定比资料。

59
1. 对未分组资料 (1)、先把所有数据按大小顺序排列,如果总体单位数为奇数,则取第(N+1)/2 位上的变量值为中位数;
1. 对未分组资料 (1)、先把所有数据按大小顺序排列,如果总体单位数为奇数,则取第(N+1)/2 位上的变量值为中位数; (2)、如果总体单位数为偶数。因为居中的数值不存在,按惯例,取第 N/2位和第(N/2+1 )位上的两个变量值的平均作为中位数。 第四章 集中趋势的应用 59
、先把所有数据按大小顺序排列,如果总体单位数为奇数,则取第(N+1)/2 位上的变量值为中位数; (2)、如果总体单位数为偶数。因为居中的数值不存在,按惯例,取第 N/2位和第(N/2+1 )位上的两个变量值的平均作为中位数。 第四章 集中趋势的应用. 59.")
60
例 求54,65,78,66,43这些数字的中位数。 例、求54,65,78,66,43,38 这些数字的中位数。 第四章 集中趋势的应用
例 求54,65,78,66,43这些数字的中位数。 例、求54,65,78,66,43,38 这些数字的中位数。 第四章 集中趋势的应用 60

61
(2)分组资料 按中位数所在组的下限: 当根据组距数列求中位数时,要采用所谓的比例插值法:先根据N/2在累计频数分布中找到中位数所在组,然后假定该组中各变量值是均匀分布的,再用以下任何一种方法求出中位数(注意:此处用的是向上累计)。 61

62
[例]某年级学生身高如下,求中位数 第四章 集中趋势的应用 62
![[例]某年级学生身高如下,求中位数 第四章 集中趋势的应用 62](http://slidesplayer.com/slide/11402570/61/images/62/%5B%E4%BE%8B%5D%E6%9F%90%E5%B9%B4%E7%BA%A7%E5%AD%A6%E7%94%9F%E8%BA%AB%E9%AB%98%E5%A6%82%E4%B8%8B%EF%BC%8C%E6%B1%82%E4%B8%AD%E4%BD%8D%E6%95%B0+%E7%AC%AC%E5%9B%9B%E7%AB%A0+%E9%9B%86%E4%B8%AD%E8%B6%8B%E5%8A%BF%E7%9A%84%E5%BA%94%E7%94%A8+62.jpg "[例]某年级学生身高如下,求中位数 第四章 集中趋势的应用 62")
63
第一种方法 =168+ ×6 =171.12(厘米) 第四章 集中趋势的应用 63
 第四章 集中趋势的应用 63")
64
3、众数 众数是在一组资料中,出现次数(或频 数)呈现出“峰”值的那些变量值。 可以用于定类、定序、定距、定比层次变量。
呈现出 峰 值的那些变量值。 可以用于定类、定序、定距、定比层次变量。")
65
二、离散趋势测量

66
全距(R):最大值和最小值之差。也叫极差。全距越大,表示变动越大。
1.全距(Range) R =Xmax– Xmin [例] 求74,84,69,91,87,74,69这些数字 的全距。 [解] 把数字按顺序重新排列:69,69,74, 74,84,87,91,显然有 R =Xmax– Xmin =91—69=22 全距(R):最大值和最小值之差。也叫极差。全距越大,表示变动越大。 2017/3/12 66
 R =Xmax– Xmin. [例] 求74,84,69,91,87,74,69这些数字. 的全距。 [解] 把数字按顺序重新排列:69,69,74, 74,84,87,91,显然有. R =Xmax– Xmin =91—69=22. 全距(R):最大值和最小值之差。也叫极差。全距越大,表示变动越大。 2017/3/")
67
2、平均差 平均差是离差绝对值的算术平均数。 A · D= 2017/3/12 67

68
3、 标准差S(standard deviation)
定义:各变量值对其算术平均数的离差平方的算术平均数的平方根。(均方差) S= =
 S= =")
69
4、方差 方差(variance, 2, S2 ):各数据与平均数差数的平方和的平均值称为方差,也称为变异数。
:各数据与平均数差数的平方和的平均值称为方差,也称为变异数。")
70
异众比率能表明众数所不能代表的那一部分变量值在总体中的比重。
2. 异众比率 所谓异众比率,是指非众数的频数与总体单位数 的比值,用V· R来表示 其中: 为众数的频数; 是总体单位数 异众比率能表明众数所不能代表的那一部分变量值在总体中的比重。 2017/3/12 70

71
中位数所有单位被等分为两部分,因而被称为二分
6. 四分位数与四分位差 中位数所有单位被等分为两部分,因而被称为二分 位数。类似于求中位数,我们还可求出四分位数、十分 位数、百分位数。 将总体中的各单位分割成相等的四部分,则这三个 分割的变量值就是四分位数。若以Q1、Q2、Q3分别代表 第一、第二、第三四分位数。Q2 即中位数,Q1、Q3的算 法分别是 第四章 集中趋势的应用 71

72
四分位差(Quartile deviation) 第三四分位数和第一四分位数的半距。 避免全距受极端值影响大的缺点。
1、原始数据 求下列两组成绩的四分位差: A: B: 2017/3/12 72

73
第三节 正态分布与标准值 在正常状况下,大多数定距变量的分布都是正态分布。

74
1. 正态分布的数学形式 正态分布性质: (1)正态曲线以x=μ呈钟型对称 均值=中位数=众数 (2)在x=μ处,概率密度最大;当区间离
1. 正态分布的数学形式 正态分布性质: (1)正态曲线以x=μ呈钟型对称 均值=中位数=众数 (2)在x=μ处,概率密度最大;当区间离 μ越远,x落在这个区间的概率越小。
正态曲线以x=μ呈钟型对称. 均值=中位数=众数. (2)在x=μ处,概率密度最大;当区间离. μ越远,x落在这个区间的概率越小。")
75
(3)正态曲线的外形由σ值确定。对于固定的 σ值,不同均值μ的正态曲线的外形完全相同,差别 只在于曲线在横轴方向上整体平移了一个位置 。
(4)对于固定的 μ值,改变σ值,σ 值越小,正态曲线越 陡峭;σ值越大,正 态曲线越低平。 (总之,正态分布曲线 的位置是由μ决定的,而正态 分布曲线的“高、矮、胖、瘦” 由σ决定的。) (5)E(X)= μ D(X)= σ2
对于固定的. μ值,改变σ值,σ. 值越小,正态曲线越. 陡峭;σ值越大,正. 态曲线越低平。 (总之,正态分布曲线. 的位置是由μ决定的,而正态. 分布曲线的 高、矮、胖、瘦 由σ决定的。) (5)E(X)= μ. D(X)= σ2.")
76
2. 标准正态分布 Z分数(标准正态变量) 用Z分数表达的标准正态分布,其概率密度为 一般正态分布的表示 标准正态分布的表示
 用Z分数表达的标准正态分布,其概率密度为 一般正态分布的表示 标准正态分布的表示")
77
3. 正态曲线下的面积 但积分毕竟太麻烦了,更何况许多人对积分运算不熟悉,为 此须计算出现成的数值表供使用者查找。由于正态曲线的优良性
3. 正态曲线下的面积 但积分毕竟太麻烦了,更何况许多人对积分运算不熟悉,为 此须计算出现成的数值表供使用者查找。由于正态曲线的优良性 质,这项工作可以卓有成效地完成:①经过X的标准分 ,可以将任何正态分布N(μ,σ2)转换成标准正态分布 N(0,1);②运用分布函数的定义,并利用正态曲线的对称性,通 过下式(分布函数)可以计算编制出正态分布表(见附4)。
转换成标准正态分布. N(0,1);②运用分布函数的定义,并利用正态曲线的对称性,通. 过下式(分布函数)可以计算编制出正态分布表(见附4)。")
78
采用标准正态变量表达正态分布,使标准差得到了进一步阐明。我们看到,标准差是计算总体单位分布及其标志值变异范围的主要依据,下图说明了这一点。
(1)变量值在【 μ-σ, μ+σ 】之间的概率为0.6826。 (2)变量值在【 μ-2σ, μ+2σ 】之间的概率为0.9546。 (3)变量值在【 μ-3σ, μ+3σ 】之间的概率为0.9973。
变量值在【 μ-σ, μ+σ 】之间的概率为0.6826。 (2)变量值在【 μ-2σ, μ+2σ 】之间的概率为0.9546。 (3)变量值在【 μ-3σ, μ+3σ 】之间的概率为0.9973。")
79
第九章 统计推论 第一节 抽样与统计推论 第二节 参数估计 第三节 假设检验

80
第一节 抽样与统计推论 一、抽样的意义与问题
以随机变量的概率分布理论为基础,通过分析某一抽样的样本信息,来对总体情况作出判断的统计分析方法,就是统计推论。推论时对或错的概率是多少。 统计推论包括参数估计和假设检验。

81
二、抽样分布 样本是从总体中抽样而产生的,如果抽一次,就产生一个样本,假如不停地抽下去的话,就会产生N个样本。
抽样分布式根据概率的原则而建立的理论性分布,显示由同一总体中反复不断抽取不同样本时,各个可能出现的样本统计值的分布情况。

82
二、抽样分布 在推论统计中,理论和实际的一个重要结合就是通过抽样分布和抽样调查这两者的联系来实现的。
抽样分布特指样本统计量作为随机变量的概率分布。用数学语言来说,抽样分布是运用数理统计的方法,把具体概率赋予样本的所有可能结果的一种理论分布。

83
二、抽样分布 比如,从上海财大12000名学生中随机抽500名,研究其英语的成绩,一共抽C 次,将会产生如下平均数。

84
样本 平均成绩 1 2 3 4 . 80 82 78 85 77

85
每一个样本统计量发生的概率是不同的,用概率分布来表示抽样分布;

86
大家务必分清总体分布、样本分布、抽样分布:
均值 标准差 总体分布 样本分布 抽样分布 μ σ S

87
三、中心极限定理 推论统计需要有一座能够架通抽样调查和抽样分布的桥梁。

88
中心极限定理 我们知道,概率论中用来阐明大量随机现象平均结果的稳定性的定理,是著名的大数定理。其具体内容是:频率稳定于概率,平均值稳定于期望值。但是,大量随机现象的稳定性不仅表现在平均结果上,同时也表现在分布上,这就是中心极限定理所要阐明的内容。 中心极限定理告诉我们:如果从任何一个具有均值μ和方差σ2的总体(可以具有任何分布形式)中重复抽取容量为n的随机样本,那么当n变得很大时,样本均值的抽样分布接近正态,并具有均值μ和方差 。
中重复抽取容量为n的随机样本,那么当n变得很大时,样本均值的抽样分布接近正态,并具有均值μ和方差 。")
89
无疑,中心极限定理大大拓展了正态分布的适用面,同时我们得到了以下重要信息: (1)虽然样本的均值可能和总体均值有差别,但我们可期望这些将聚集在μ的周围。因此均值抽样分布的算术平均数能和总体的均值很好地重合,这就是为什么总体均值和抽样分布的均值用同一个μ来表示的缘故。 (2)由于抽样分布的标准 差要比总体标准差小, 并且 ,所以如右图所示,样本容量越大,抽样分 布的峰态愈陡峭,由样本结果来推断总体参数的可靠性也随之提高。
由于抽样分布的标准. 差要比总体标准差小, 并且. ,所以如右图所示,样本容量越大,抽样分. 布的峰态愈陡峭,由样本结果来推断总体参数的可靠性也随之提高。")
90
第二节 参数估计 通俗地说,就是根据抽样结果来合理地、科学地猜一猜总体的参数大概是什么?或者在什么范围。 参数估计分为点估计和区间估计。
所谓点估计,就是根据样本数据算出一个单一的估计值,用来估计总体的参数值。 例如,为了研究上海个人收入,抽样调查发现样本中个人收入的平均数是6000元,以此估计上海市个人收入的情况。

91
所谓区间估计,就是计算抽样平均误差,指出估计的可信程度,进而在点估计的基础上,确定总体参数的所在范围或区间。我们经常预测参数在点估计值两侧的给定的区间内。
例如前面例子,估计上海市个人收入的平均数在5900元和6100元之间。

92
置信区间:是我们为了增加参数被估计到的信心而在点估计两边设置的估计区间。
置信度:用置信区间估计的可靠性(把握度)1-a
1-a.")
93
一、均值的区间估计

94
[ , ] 例,从某校随机地抽取100名男学生,测得平均身高为170厘米,标准差为7.5厘米,试求该校学生平均身高95%和99%的置信区间。
![[ - , + ] 例,从某校随机地抽取100名男学生,测得平均身高为170厘米,标准差为7.5厘米,试求该校学生平均身高95%和99%的置信区间。](http://slidesplayer.com/slide/11402570/61/images/94/%5B+-+%2C+%2B+%5D+%E4%BE%8B%EF%BC%8C%E4%BB%8E%E6%9F%90%E6%A0%A1%E9%9A%8F%E6%9C%BA%E5%9C%B0%E6%8A%BD%E5%8F%96100%E5%90%8D%E7%94%B7%E5%AD%A6%E7%94%9F%EF%BC%8C%E6%B5%8B%E5%BE%97%E5%B9%B3%E5%9D%87%E8%BA%AB%E9%AB%98%E4%B8%BA170%E5%8E%98%E7%B1%B3%EF%BC%8C%E6%A0%87%E5%87%86%E5%B7%AE%E4%B8%BA7%EF%BC%8E5%E5%8E%98%E7%B1%B3%EF%BC%8C%E8%AF%95%E6%B1%82%E8%AF%A5%E6%A0%A1%E5%AD%A6%E7%94%9F%E5%B9%B3%E5%9D%87%E8%BA%AB%E9%AB%9895%EF%BC%85%E5%92%8C99%EF%BC%85%E7%9A%84%E7%BD%AE%E4%BF%A1%E5%8C%BA%E9%97%B4%E3%80%82.jpg "[ - , + ] 例,从某校随机地抽取100名男学生,测得平均身高为170厘米,标准差为7.5厘米,试求该校学生平均身高95%和99%的置信区间。")
95
例,从某校随机地抽取100名男学生,测得平均身高为170厘米,标准差为7.5厘米,试求该校学生平均身高95%和99%的置信区间。

96
二、百分比的区间估计 在社会研究中我们碰到许多定类变量,其估计不是均值,而是比率,这便提出了总体成数的估计问题。 比如某城市是否属于老年型,
比如电视节目的收视率

97
从总体的均值估计过渡到总体的成数估计,其方法和思路完全相同。
只要用 代替 , 用 代替 可以得出成数区间估计的置信区间: [ , ]

98
根据中心极限定理,在大样本情况下, 分布近似正态分布。因此用 和 代替p和 q。

99
假若从某社区抽取一个由200个家庭组成的样本,发现其中有36%的家庭由丈夫在家庭开支上做决定的次数超过半数。试问,家庭开支的半数以上由丈夫决定的家庭的置信区间是多少(使用95和99%的置信水平)?
")
100
例,设根据某地100户的随机调查,其中60户拥有电冰箱,求该地拥有冰箱比例的置信区间。(置信度为95%和99%)
")
101
四、决定样本的大小 在能够付出的研究代价限度内,选取最大的样本; 一项研究能容忍的误差; 总体的异质性情况。

102
第三节 假设检验 假设检验是指先成立一个关于总体情况的假设,继而抽取一个随机样本,然后以样本的统计量或者统计性质来验证假设。

103
一、假设检验的逻辑 经过随机抽样获得一组数据,即一个来自于总体的随机样本。
如果根据样本计算的某个或某几个统计量表明在原假设H0成立的条件下几乎是不可能发生,就拒绝或否定这个原假设,并继而接受它的对立面——备择假设H1。

104
反之,如果在原假设H0成立的条件下,根据样本所计算的某个统计量,发生的概率可能性不是很小的话,那么就接受原假设。

105
假设检验与小概率原理 小概率原理 大数定理表明就大量观察而言,事件的发生具有一定的规律性。 根据概率的大小,人们处理的态度和方式很不一样。
在日常生活中,人们往往习惯于把概率很小的事件,当作一次观察中是不可能发生的事件。

106
例如,人们出门做事会遇到不测事故,但没有人在出门前在意这事。原因是:认为小概率事件在每次出门不会发生。

107
“小概率事件”:概率必须很小,那么,究竟要小到什么程度?在社会统计中一般认为在0.05以下为小。

108
总而言之,小概率原理可以归纳为两个方面:一是可以认为小概率事件在一次观察中是不可能出现的;二是如果在一次观察中出现了小概率事件,那么应该否定原有事件具有小概率的说法或者假设。

109
例 通过以往大规模调查,已知某地一般新生儿的头围均数为34. 50cm,标准差为1
例 通过以往大规模调查,已知某地一般新生儿的头围均数为34.50cm,标准差为1.99cm。为研究某矿区新生儿的发育状况,现从该地某矿区随机抽取新生儿55人,测得其头围均数为33.89cm,问该矿区新生儿的头围总体均数与一般新生儿头围总体均数是否不同?

110
① 抽样误差造成的; ② 本质差异造成的。 假设检验的目的——就是判断差别是由哪种原因造成的。

111
一种假设H0 矿区新生儿头围 34.50cm 另一种假设H1 抽样误差 矿区新生儿头围 34.50cm 33.89cn 总体不同

112
例、妻子从一年中随机选择一天跟踪丈夫,发现他和别的女人约会。丈夫对妻子说,这一次非常偶然,是那个女人纠缠自己,除这次外,从来没有和其他女人约会。请问,丈夫的解释合理吗?

113
二、假设检验的基本概念 (一)虚无假设与研究假设 1、选择谁作为原假设? 在统计检验中,通常把被检验的那个假设称为虚无假设,用符号H0表示.
又称之为零假设、原假设或者解消假设。

114
原假设往往根据已有资料或者深思熟虑确定的,是具有稳定性的经验看法,没有充分的根据,是不会被轻易否定的。

115
比如,根据以往多年的统计表明,上海财大英语的平均成绩为90分,随机抽取100个学生,其平均成绩为80分,问今年财大学生的英语成绩是否下降?
对上述情况,原假设应该为今年财大学生的英语成绩为90分。

116
2、选择谁作为备择假设 备择假设用H1 又称之为研究假设。 原假设是保守、稳定的,但是并非不能否定,否则就没有必要研究了。 备择假设有三种写法:

117
备择假设有三种写法: 第一种:H0: μ =90 H1: μ >90 第二种:H0: μ =90 H1: μ<90 第三中:H0: μ =90 H1: μ =90

118
一个完整的假设应该包括原假设和备择假设。

119
3、临界值、接受域和否定域、显著性水平 在统计检验中,这些不大可能的结果称为否定域。如果这类结果真的发生了,我们将否定原假设;反之就不否定原假设。 接受域与否定域之间的分界值就是临界值。

120
以抽样分布是正态分布为例: 找出临界值、否定域和接受域。

121
(三)双尾检验和单尾检验 根据否定域位置的不同,可以讲假设检验分为双尾检验和单尾检验。 1、双尾检验 在统计中,必须把否定域分配到抽样分布的两端的检验,被称为双尾检验。
双尾检验和单尾检验 根据否定域位置的不同,可以讲假设检验分为双尾检验和单尾检验。 1、双尾检验 在统计中,必须把否定域分配到抽样分布的两端的检验,被称为双尾检验。")
122
在双尾检验中,如果显著性水平为a,则每侧否定域的概率应该是a/2,临界值则是Za/2
双侧检验往往写成这种方式: H0: μ =90 H1: μ =90 Z > Z a/2 ,否定原假设,反之则接受。

123
单尾检验 所谓单尾检验,就是把否定域集中到抽样分布更合适的一侧。这样,在显著性水平相同的条件下,可以得到一个比较大的尾端。 根据否定域在左侧还是右侧,可以将单侧检验分为左侧检验和右侧检验。

124
(1)右侧检验 往往写成这种方式 第一种:H0: μ =90 H1: μ >90 如果Z >Za,就拒绝原假设,反之则接受
右侧检验 往往写成这种方式 第一种:H0: μ =90 H1: μ >90 如果Z >Za,就拒绝原假设,反之则接受")
125
(2)左侧检验 H0: μ =90 H1: μ<90 如果Z <Za,则拒绝原假设。反之则然。
左侧检验 H0: μ =90 H1: μ<90 如果Z <Za,则拒绝原假设。反之则然。")
126
5、两类错误及其关系 在假设检验中,无论是拒绝或者接受原假设,都不可能做到百分之百的正确,都有一定的错误。

127
(1)、第一类错误——弃真的错误 第一类错误是,零假设H0实际上是正确的,却被否定了。 犯第一类错误的大小就是显著性水平。 因此,有人也把第一类措施称之为 错误 (2)、第二类错误——取伪错误 H0实际上是错误的,却被接受了。

128
可能发生的两类错误

129
两类错误是对立的,成反比。如果要减少第一类误差,将会增加第二类误差。
完全消除两种误差是不可能的,只有靠增大样本

130
我们事先选定的可以犯第一类错误的概率,叫做检验的显著性水平(用α表示),它决定了否定域的大小。
当显著性水平a 减少时,弃真的错误会减少;但纳伪的错误会增大。

131
三、假设检验的基本步骤 假设检验是直接检验原假设,间接检验备择假设。 (1)建立假设; (2)选择适当的统计检验方法 (3)求抽样分布;
(4)选择显著性水平和否定域; (5)计算检验统计量; (6)判定。
选择显著性水平和否定域; (5)计算检验统计量; (6)判定。")
132
例,已知初婚年龄服从正态分布,根据9个人的抽样调查表明,平均初婚年龄为23.5岁,标准差为3岁。
问是否可以认为该地区平均初婚年龄已超过20岁(α=0.05)?
?")
133
(1)建立假设 H0:μ=20(岁) H1:μ>20(岁)
建立假设 H0:μ=20(岁) H1:μ>20(岁)")
134
(2)总体正态,小样本的t分布 (3)对自由度8来讲,单侧检验和显著性水平0.05,查表知否定域为t值等于或大于 1.86。
总体正态,小样本的t分布 (3)对自由度8来讲,单侧检验和显著性水平0.05,查表知否定域为t值等于或大于 1.86。")
135
(4)计算统计量 t= 计算得出
计算统计量 t= 计算得出")
136
(5)判定 否定原假设,即可以认为该地区的平均初婚年龄已经超过20岁。
判定 否定原假设,即可以认为该地区的平均初婚年龄已经超过20岁。")
137
第三节 双变量分析 第一节 列联表和相关测量 第二节 简单线性回归与积距相关

138
第一节列联表和相关测量 一、相关概述 相关是指一个变量的值与另一个变量的值有连带性,即一个变量值发生变化,另一个变量的值也发生变化。
无相关:0 完全相关:1 正相关 负相关

139
列联表,是按品质标志把两个变量的频数分布进
一. 列联表 列联表,是按品质标志把两个变量的频数分布进 行交互分类,由于表内的每一个频数都需同时满足两个 变量的要求,所以列联表又称条件频数表。 例如,某区调查了357名选民,考察受教育程度与投 票行为之间的关系,将所得资料作成下表,便是一种关 于频数的列联表。

140
2×2频数分布列联表的一般形式 习惯上把因变量Y放在表侧,把自变量X放在表头。 2×2列联表是最简单的交互分类表。
r×c列联表 r(row)、c(column)
、c(column)")
141
r×c频数分布列联表的一般形式

142
自己志愿 知心朋友志愿 总数 快乐家庭 理想工作 增广见闻 28 9 3 40 2 41 7 50 4 10 32 54 14 100

143
两个边际分布:

144
出现的相对频数(或者频率)。将频数 化成相对 频数 有两种做法:
在相对频数分布列联表中,各数据为各分类 出现的相对频数(或者频率)。将频数 化成相对 频数 有两种做法: ①相对频数联合分布 两个边际分布 或 ②相对频数条件分布 或
。将频数 化成相对. 频数 有两种做法: ①相对频数联合分布. 两个边际分布 或. ②相对频数条件分布. 或.")
145
r×c相对频数联合分布列联表

146
化为自变量受到控制的相对频数条件分布列联 表,并加以相关分析。 投票行为Y 受教育程度X 大学以上 大学以下 投票 弃权 160 7 129
[例A1]试把下表所示的频数分布列联表,转 化为自变量受到控制的相对频数条件分布列联 表,并加以相关分析。 投票行为Y 受教育程度X 大学以上 大学以下 投票 弃权 160 7 129 61 289 68 合计: 167 190 357

147
投票行为Y 受教育程度X 大学以上 大学以下 投票 弃权 95.8%(160/167) 4.2%(7/167) 67.9%(129/190) 32.1%(61/190) 81.0%(289/357) 19.0%(68/357) 100.0% (167)) (190) (357) 从上表可知,受过大学以上教育的被调查者绝大多 数(占95.8%)是投票的,受教育程度在大学以下的被调 查者虽多数也参与投票(占67.9%),但后者参与投票的百 分比远小于前者;前者只有4.2%弃权,而后者则有32.1% 弃权。两相比较可知,受教育程度不同,参与投票的行 为不同,因此两个变量是相关的。
 100.0% (167)) (190) (357) 从上表可知,受过大学以上教育的被调查者绝大多. 数(占95.8%)是投票的,受教育程度在大学以下的被调. 查者虽多数也参与投票(占67.9%),但后者参与投票的百. 分比远小于前者;前者只有4.2%弃权,而后者则有32.1% 弃权。两相比较可知,受教育程度不同,参与投票的行. 为不同,因此两个变量是相关的。")
148
二、用卡方进行显著性检验 根据样本中两个变量的关系推论总体两个变量的关系,如果这两个变量是定类或者一个定类(另一个是定序)时,就可以用卡发检验来推论总体。
时,就可以用卡发检验来推论总体。")
150
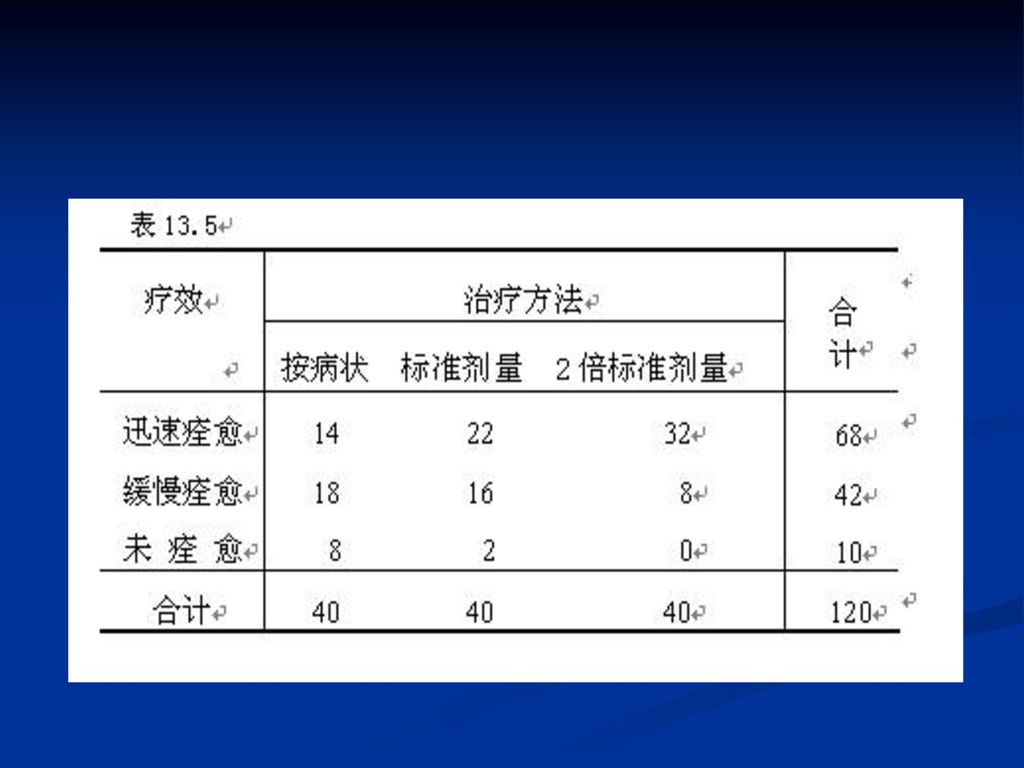
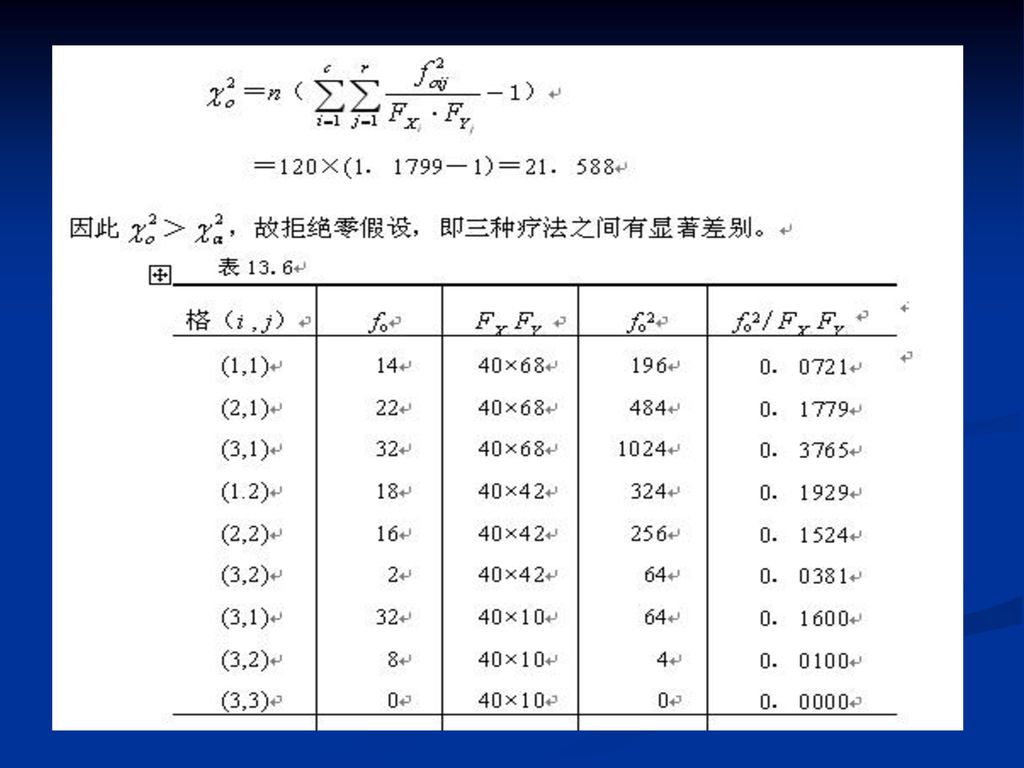
例:在某种流行病流行的时候,共有120个病人进行了治疗,其中40个病人按标准剂量服用某种新药,另有40个病人按标准剂量的2倍服用了这种新药,其余40个病人只按病状治疗(而不是按病因治疗),治疗结果按迅速痊愈、缓慢痊愈、未痊愈分为三类,最后交叉分类的情况列于表13.5中,试问这三种疗法之间有没有差别(α取0.05)。
,治疗结果按迅速痊愈、缓慢痊愈、未痊愈分为三类,最后交叉分类的情况列于表13.5中,试问这三种疗法之间有没有差别(α取0.05)。")
154
三、相关系数 1、PRE性质 PRE(proportionate reduction in error)是指消减误差比例。
社会研究的目的就是要预测或解释社会现象的变化。 比如,有一种社会现象Y(例如大学生的最大志愿),在预测或解释这种现象时,难免会有误差。假定另一社会现象X(比如性别)是与Y有关系。
,在预测或解释这种现象时,难免会有误差。假定另一社会现象X(比如性别)是与Y有关系。")
155
如果我们根据X的值来预测Y的值(比如根据性别来预测大学生的最大志愿),理应减少若干误差。而且X和Y的关系愈强,所能减少的预测误差就会越多。
,理应减少若干误差。而且X和Y的关系愈强,所能减少的预测误差就会越多。")
156
现在假定不知道X的值,我们在预测Y 的值时所产生的全部误差是E1,如果知道X的值,我们可以根据X的值来预测Y的值,假定误差是E2,则用X的值来预测Y时,所减少的误差就(E1- E2)
则所减少误差比例 PRE= (E1- E2)/ E1
/ E1.")
157
PRE数值范围在1和0之间。 讨论:通过PRE的值如何反映变量之间的关系? PRE数值的意义就是用一个现象来解释另外一个现象时能够减少百分之几的错误。

158
2、Phi相关系数

159
3、克拉默V相关系数

160
4、Lambda相关系数

161
式中: m 为X的每一分类中Y分布的众数的频数; My 为Y边际分布中的众数的频数; n为样本单位数。

162
课堂练习: 为了研究饮食习惯与地区之间的关系,做了100人的抽样调查。问其关系度如何?

163
合计: 南方 北方 面食 米食 10 40 30 20 60 合计:Fx 50 n=100

164
第二节 简单线性回归与积距相关 一、散点图与回归线

165
散点图表示的相关的类型 ★正相关 ★负相关 ★完全正相关 ★完全负相关 ★称零相关

166
二、简单线性回归方程 线性回归分析,一般是先依据相关表做出 散点图,直观地估计X和Y关联性。如果两变量 的确呈现出一定的线性相关趋势,便可以设所 要求的回归直线方程为 是因变量Y的预测值或称估计值。 回归方程的建立: ① 先做散点图;②利 用最小二乘法。

167
运用最小平方法可以在所有可能的直线中找到使
Y X 运用最小平方法可以在所有可能的直线中找到使 Q达到最小的回归直线。 分别对a、b求偏导并令其为零,求得两个标准方程: 解联立方程,得到 a 和 b 的计算公式:

168
在回归方程中,b有十分重要的意 义,被称为回归系数。b值的大小, 反映了X对Y有多大的影响,即b值就 是当X增加一个单位时Y值的增量。

169
例:为了研究受教育年限和职业声望之间的关系,设 解:
以下是8名社会成员抽样调查的结果,求直线回归方程。 解: 直线回归方程是

170
调查对象 年x 声望y xy x2 1 12 70 840 144 2 16 80 1280 256 3 9 50 450 81 4 19 86 1634 361 5 21 90 1890 441 6 10 65 650 100 7 44 220 25 8 75 900 合计 104 560 7864 1552

171
三、 决定系数(r2) 三种变差平方和 总变差 SST Y 回归变差 SSB 剩余变差 SSW X 总变差 = 回归变差 + 剩余变差
 三种变差平方和 总变差 SST Y 回归变差 SSB 剩余变差 SSW X 总变差 = 回归变差 + 剩余变差")
172
是r2而非r 具有PRE意义 决定系数也可以表达为回归变差在总变差中所占比例

173
四、积矩相关系数 积钜相关系数又称之为皮尔逊相关系数。 r中的X 和Y位置互换,系数大小不变; 【-1,1】; r具有方向性;
r不具有PRE性质。

175
五、r和b的显著性检验 假设检验知识的应用。

176
第十一章撰写研究报告 第一节 研究报告的类型和结构 第二节 学术性研究报告的写作
社会研究报告是反映社会研究成果的一种书面形式,它通过文字、图表等形式将整个调查研究的过程、方法和结果表现出来。

177
第一节 研究报告的类型和结构 一、研究报告的类型 应用性研究报告; 学术性研究报告;

178
二、研究报告的结构 1、标题 标题要有特点; 要高度精炼,才能给调查报告的读者带来良好而深刻的第一印象。

179
(1)、单标题简单陈述法 ,用一个简单的陈述句标明调查研究对象和主要问题。如《中国企业社会责任调查报告》、《上海市区的邻里关系调查》、《图书馆读者满意度研究》、《关于农民工短缺现状的调查》等等。这种标题方法主题突出、开门见山,相对来说比较简单,在实际使用当中最为广泛,但缺点是平铺直叙,虽然直白客观,但有时也略显平淡。

180
(2)、单标题提问法 与单标题简单陈述法相比,这种标题方法也是一种单标题法,但它不是用陈述而是以提问的方式出现,用一个简单的问句点明调查研究的内容和关键问题。如《怎样缓解女大学生的就业压力?》、《“就近”升初中为何难调众人口?》、《“上网”何时能够成为大众消费?》等等。这种标题方法直面问题,简洁明快,又发人深省,往往很能吸引眼球,对读者具有较强的吸引力。

181
(3)、复式标题法 由主标题和副标题共同构成。复式标题法的主标题往往是对调查研究的总结和提炼,而副标题的形式和内容则与单标题简单陈述法类似,主要是表明调查研究对象和基本内容。如《“台湾村”:一个移民村落的想象、构建与认同——河南邓州高山族村落田野调查报告》、
、复式标题法 由主标题和副标题共同构成。复式标题法的主标题往往是对调查研究的总结和提炼,而副标题的形式和内容则与单标题简单陈述法类似,主要是表明调查研究对象和基本内容。如《 台湾村 :一个移民村落的想象、构建与认同——河南邓州高山族村落田野调查报告》、")
182
2、导言 调查报告正文的开始内容是导言。导言说白了就是调查报告的开头,它对文章起着总揽和引导作用,提供调查的背景资料和相关信息,使得读者能够大致的了解进行该项调查的原因和需要解决的问题,以及实施调查的必要性和重要性。

183
导言一般要覆盖以下内容: 研究背景。对研究缘起或接受委托进行某项研究的原因作分析、说明时,可能要引用有关的背景资料为依据,分析调查主题的研究现状、问题等方面。 研究目的。研究目的通常是针对研究背景分析,以及所存在问题的基础上提出来的,比如为了获得某些方面的资料或对某些假设进行检验。 调查过程与研究方法。调查地区、调查对象、访问完成情况、样本构成、资料采集、访问员介绍、资料处理方法及工具。

184
3、主体 主体是调查报告的中心部分,它的写作至少要考虑到调查主题、调查材料的状况以及谋篇布局这三方面的因素。如果把主题比作调查报告的灵魂,那么材料就是报告文章的血肉,结构或布局就是报告的骨架。 调查报告的主体,最常见的有两种写法:即并列法和逐步深入法。

185
4、结尾 社会调查报告结尾部分是报告的关键内容,往往也是读者最感兴趣的地方。应该根据对调查选题、调查目的,依据定量和定性分析结果做出结论,并且在调查结论的基础上提出建议和思考。

186
5、参考文献

187
第二节学术性研究报告的写作 一、确认问题和文献评论 1、确认问题 问题的来源 2、文献评论

188
二、方法介绍

189
三、结果与讨论 四、其他写作要点 1、写作风格 语言客观、准确和简洁; 表述的口吻是客观的陈述和证明; 第三人称或非人称代词。

190
2、引用和注释 夹注 脚注 尾注。

191
谢谢

Similar presentations


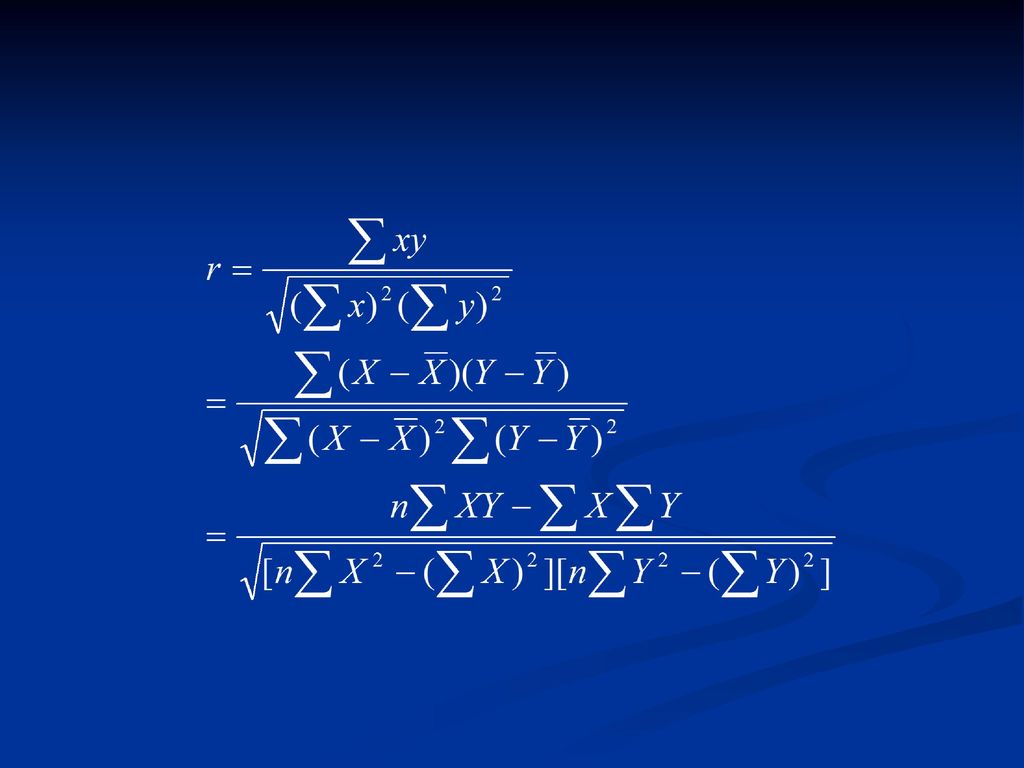


: 写出 5 的倍数( 6 个) 2 , 4 , 6 , 8 , 10 , 12 , 14 , 16 , 18 , 20 5 , 10 , 15 , 20 , 25 , 30.>")







 在百数表上依次将 2 的倍数找出 并用红色的彩笔涂上颜色。>")
2 +(y-b)2=r2 x2+y2+Dx+Ey+F=0 Ax2+Bxy+Cy2+Dx+Ey+ F=0.>")







